
estadistica inferencial
13
República Bolivariana de Venezuela Ministerio Del Poder Popular Para la Educación Instituto Universitario de Tecnología “Antonio José De Sucre” Barquisimeto-Edo Lara Nayibis Mendoza C.I:18.430.020
Transcript of estadistica inferencial

República Bolivariana de VenezuelaMinisterio Del Poder Popular Para la Educación
Instituto Universitario de Tecnología“Antonio José De Sucre”Barquisimeto-Edo Lara
Nayibis MendozaC.I:18.430.020

La Estadística descriptiva y la teoría de la Probabilidad son los pilares de
La (Estadística Inferencial) con los que se va a estudiar el comportamiento
global de un fenómeno. La probabilidad y los modelos de distribución junto
con las técnicas descriptivas, constituyen la base de una nueva forma de
interpretar la información suministrada por una parcela de la realidad que
interesa
investigar.
En el siguiente esquema representa el tema a tratar y que será desarrollado a
continuación.
Estadística
Descriptiva
Probabilidad
y
modelos
Intervalo
s
INFERENCIA
Puntual
Estimación
Contraste

.

Los métodos básicos de la estadística Inferencial son la estimación y el contraste de
hipótesis, que juegan un papel fundamental en la investigación.
Por tanto, algunos de los objetivos que se persiguen en este tema son:
•Calcular los parámetros de la distribución de medias o proporciones
muéstrales
de tamaño n, extraídas de una población de media y varianza conocidas.
• Estimar la media o la proporción de una población a partir de la media o
proporción muestral.
• Utilizar distintos tamaños muéstrales para controlar la confianza y el error
admitido.
• Contrastar los resultados obtenidos a partir de muestras.
• Visualizar gráficamente, mediante las respectivas curvas normales, las
estimaciones realizadas.
Muestra
Datos Numéricos
Estadísticos
Población
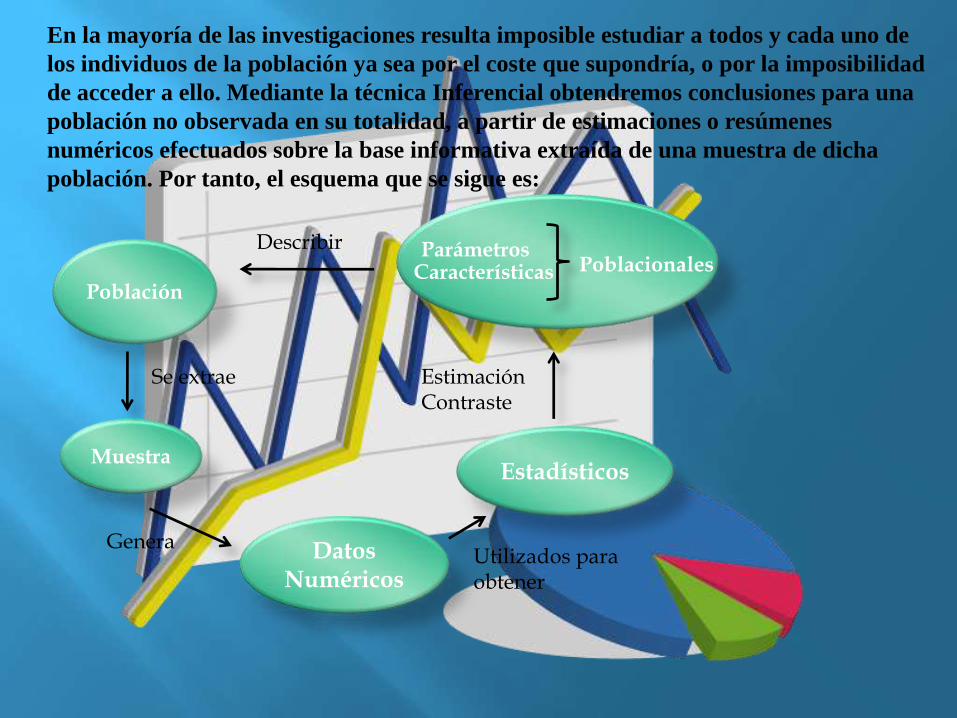
En la mayoría de las investigaciones resulta imposible estudiar a todos y cada uno de
los individuos de la población ya sea por el coste que supondría, o por la imposibilidad
de acceder a ello. Mediante la técnica Inferencial obtendremos conclusiones para una
población no observada en su totalidad, a partir de estimaciones o resúmenes
numéricos efectuados sobre la base informativa extraída de una muestra de dicha
población. Por tanto, el esquema que se sigue es:
Describir
Se extrae
GeneraUtilizados para obtener
Estimación Contraste
ParámetrosCaracterísticas Poblacionales

En definitiva, la idea es, a partir de una población se extrae una muestra por
algunos de los métodos existentes, con la que se generan datos numéricos que se van a
utilizar para generar estadísticos con los que realizar estimaciones o contrastes
poblacionales.
Existen dos formas de estimar parámetros: la estimación puntual y la estimación por
intervalo de confianza. En la primera se busca, con base en los datos muéstrales, un
único valor estimado para el parámetro. Para la segunda, se determina un intervalo
dentro del cual se encuentra el valor del parámetro, con una probabilidad
determinada.
El objetivo de la inferencia es efectuar una generalización de los resultados de la
muestra de la población, es decir, variables aleatorias asociadas al muestreo o
estadísticos muéstrales. Éstos serán útiles para hacer inferencia respecto a los
parámetros desconocidos de una población. Por ello se habla de distribuciones
muéstrales, ya que están basados en el comportamiento de las muestras.
El primer objetivo es conocer el concepto de distribución muestral de un estadístico; su
comportamiento probabilístico dependerá del que tenga la variable X y del tamaño de las
muestras.

Sea x1 ....... xn, una muestra1 aleatoria simple (m.a.s) de la variable aleatoria X, con
función de distribución F0, se define el estadístico T como cualquier función de la
muestra que no contiene ninguna cantidad desconocida.
Sea una población donde se observa la variable aleatoria X. Esta variable X, tendrá
una distribución de probabilidad, que puede ser conocida o desconocida, y ciertas
características o parámetros poblacionales. El problema será encontrar una función
que proporcione el mejor estimador de θ. El estimador, T, del parámetro θ debe tener
una distribución concentrada alrededor de θ y la varianza debe ser lo menor posible.
Los estadísticos más usuales en inferencia y su distribución asociada considerando
una población P sobre la que se estudia un carácter cuantitativo son:
Media muestral: X = 1
n
∑n
i = 1X
i
•Cuasivarianza: S2
=1
n - 1
∑n
i = 1 (xi - x )
2

Una estadística muestral proveniente de una muestra aleatoria simple tiene un patrón
de comportamiento (predecible) en repetidas muestras. Este patrón es
llamado la distribución muestral de la estadística.
Si conocemos la distribución muestral podemos hacer inferencia.
Las distribuciones muéstrales adoptan diferentes formas según las estadísticas
investigadas y las características de la población estudiada.
Si P representa la proporción de elementos en una población con cierta característica de
interés, es decir, la proporción de “éxitos”, donde “éxito” corresponde a tener la
característica.
Si sacamos muestras aleatorias simples de tamaño n de la población donde la
proporción de “éxitos” es P , entonces la distribución muestral de la proporción
muestral tiene las siguientes propiedades:
1. El promedio de todos los valores posibles de p es igual al parámetro P . En otras
palabras, p es un estimador insesgado
de P .

Es la desviación estándar de las posibles medias muéstrales.
El error estándar disminuye si el tamaño de la muestra aumenta.
Si la población original tiene distribución normal, entonces para cualquier tamaño
muestral n la distribución de la media muestral es también normal.
Si la población de origen no es Normal, pero n es “suficientemente” grande la
distribución de la media muestral es aproximadamente Normal

El teorema del límite central garantiza una distribución normal cuando n es
suficientemente grande.
Existen diferentes versiones del teorema, en función de las condiciones utilizadas para
asegurar la convergencia. Una de las más simples establece que es suficiente que las
variables que se suman sean independientes, idénticamente distribuidas, con valor
esperado y varianza finitas.
La aproximación entre las dos distribuciones es, en general, mayor en el centro de las
mismas que en sus extremos o colas, motivo por el cual se prefiere el nombre
"teorema del límite central" ("central" califica al límite, más que al teorema).
Este teorema, perteneciente a la teoría de la probabilidad, encuentra aplicación en
muchos campos relacionados, tales como la inferencia estadística o la teoría de
renovación.

Una distribución de probabilidad indica toda la gama de valores que pueden
representarse como resultado de un experimento si éste se llevase a cabo.
Es decir, describe la probabilidad de que un evento se realice en el futuro, constituye
una herramienta fundamental para la prospectiva, puesto que se puede diseñar un
escenario de acontecimientos futuros considerando las tendencias actuales de diversos
fenómenos naturales.
Toda distribución de probabilidad es generada por una variable (porque puede tomar
diferentes valores) aleatoria x (porque el valor tomado es totalmente al azar), y puede
ser de dos tipos:

Es una variable que sólo puede tomar valores dentro de un conjunto numerable, es
decir, no acepta cualquier valor sino sólo aquellos que pertenecen al conjunto. En
estas variables se dan de modo inherente separaciones entre valores observables
sucesivos. Dicho con más rigor, se define una variable discreta como la variable
que hay entre dos valores observables (potencialmente), hay por lo menos un valor
no observable (potencialmente). Como ejemplo, el número de animales en una
granja (0, 1, 2, 3...).
Una variable continua puede tomar un valor cualquiera dentro de un intervalo
predeterminado. Y siempre entre dos valores observables va a existir un tercer valor
intermedio que también podría tomar la variable continua. Una variable continua
toma valores a lo largo de un continuo, esto es, en todo un intervalo de valores. Un
atributo esencial de una variable continua es que, a diferencia de una variable
discreta, nunca puede ser medida con exactitud; el valor observado depende en gran
medida de la precisión de los instrumentos de medición. Con una variable continua
hay inevitablemente un error de medida. Como ejemplo, la estatura de una persona
(1.710m, 1.715m, 1.174m....)

La distribución normal es también un caso particular de probabilidad de variable
aleatoria continua, fue reconocida por primera vez por el francés Abraham de Moivre
(1667-1754). Posteriormente, Carl Friedrich Gauss (1777-1855) elaboró desarrollos más
profundos y formuló la ecuación de la curva; de ahí que también se le conozca, más
comúnmente, como la "campana de Gauss". La distribución de una variable normal
está completamente determinada por dos parámetros, su media (µ) y su desviación
estándar. Con esta notación, la densidad de la normal viene dada por la ecuación:














