
(01BITOV) - areeweb.polito.it · Costruire un modello di rete neurale per la classificazione degli...
16
Intelligenza artificiale (01BITOV) Ship or iceberg, can you decide from space? Prof. Elio Piccolo Andrea Grippi, Elisa Wan
-
Upload
nguyenthuan -
Category
Documents
-
view
213 -
download
0
Transcript of (01BITOV) - areeweb.polito.it · Costruire un modello di rete neurale per la classificazione degli...

Intelligenza artificiale (01BITOV)
Ship or iceberg, can you decide from space?
Prof. Elio Piccolo
Andrea Grippi, Elisa Wan

1
Indice Ship or iceberg, can you decide from space? .................................................................... 0
Contesto ............................................................................................................................... 2
Obiettivo................................................................................................................................ 3
Input ...................................................................................................................................... 3
Analisi dei dati di input ................................................................................................... 3
Strategia ............................................................................................................................... 4
Strumenti utilizzati ................................................................................................................. 4
Python 2.7 ...................................................................................................................... 4
Tensorflow ..................................................................................................................... 4
Keras ............................................................................................................................. 4
CNN (Convolutional Neural Network) .................................................................................... 4
Funzioni di attivazione ........................................................................................................... 6
Relu ............................................................................................................................... 6
Sigmoide ........................................................................................................................ 6
Modello base ........................................................................................................................ 6
Matrice di numeri reali .................................................................................................... 6
Immagini in formato jpg .................................................................................................. 6
Immagini ritagliate .......................................................................................................... 7
Immagini con parti annerite ............................................................................................ 7
Con quale tipo di input si ottengono i risultati migliori? ................................................... 8
Image Generator ................................................................................................................... 9
Modello completo ................................................................................................................ 10
Immagini RGB..................................................................................................................... 12
Modello finale ...................................................................................................................... 13
Risultato .............................................................................................................................. 13
Bibliografia .......................................................................................................................... 15

2
Contesto
Gli iceberg alla deriva nei mari del nord
rappresentano un pericolo per la
navigazione. Attualmente, molte istituzioni
usano tecniche di ricognizione aerea e
supporto dalla terra ferma per monitorare
la situazione e valutare i rischi derivati
dalla presenza di iceberg. Tuttavia, in aree
remote e in condizioni meteo
particolarmente avverse, queste tecniche
non sono possibili e bisogna ricorrere
all’uso di satelliti.
A 600 chilometri sopra la superficie della
Terra, si trova la costellazione di satelliti
Sentinel-1, utilizzati per monitorare la terra
e gli oceani. Orbitano 14 volte al giorno, e catturano immagini della superficie terrestre ad
una determinata ora e in un determinato posto. Il radar C-Band lavora ad una frequenza tale
da permettergli di “vedere” attraverso l’oscurità, la pioggia, le nuvole e la nebbia. Quando un
radar rileva un oggetto, non riesce a distinguere un iceberg da una nave o altri oggetti solidi.
Le immagini utilizzate in questa analisi sono ottenute tramite due canali, HH
(trasmissione/ricezione orizzontale) e HV(trasmissione orizzontale e ricezione verticale).
Nonostante alcuni oggetti possano essere facilmente riconoscibili a occhio nudo, il
riconoscimento in un immagine con centinaia di oggetti può impiegare anche molto tempo.
Alcuni esempi semplici:
Figura 1: Sentinel-1 può trasmettere e ricevere lungo il piano orizontale e verticale
Figura 2: Immagini di navi
Figura 3: Immagini di Iceberg
3
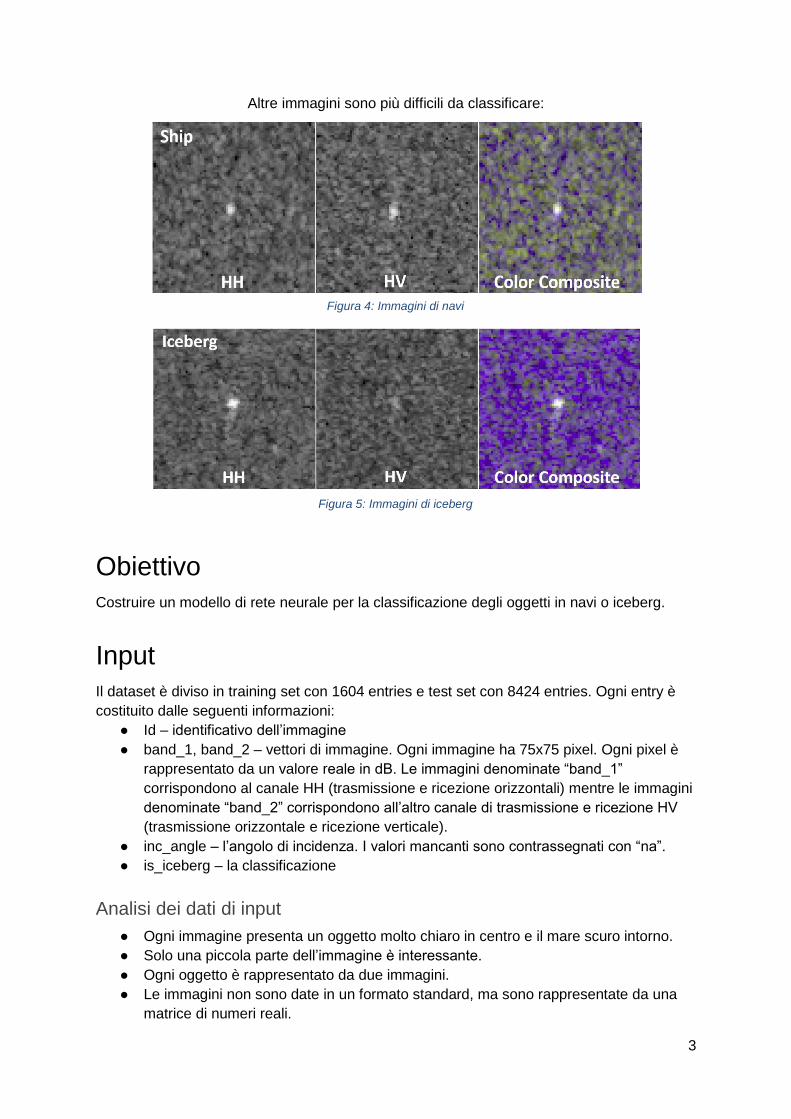
Altre immagini sono più difficili da classificare:
Obiettivo
Costruire un modello di rete neurale per la classificazione degli oggetti in navi o iceberg.
Input
Il dataset è diviso in training set con 1604 entries e test set con 8424 entries. Ogni entry è
costituito dalle seguenti informazioni:
● Id – identificativo dell’immagine
● band_1, band_2 – vettori di immagine. Ogni immagine ha 75x75 pixel. Ogni pixel è
rappresentato da un valore reale in dB. Le immagini denominate “band_1”
corrispondono al canale HH (trasmissione e ricezione orizzontali) mentre le immagini
denominate “band_2” corrispondono all’altro canale di trasmissione e ricezione HV
(trasmissione orizzontale e ricezione verticale).
● inc_angle – l’angolo di incidenza. I valori mancanti sono contrassegnati con “na”.
● is_iceberg – la classificazione
Analisi dei dati di input
● Ogni immagine presenta un oggetto molto chiaro in centro e il mare scuro intorno.
● Solo una piccola parte dell’immagine è interessante.
● Ogni oggetto è rappresentato da due immagini.
● Le immagini non sono date in un formato standard, ma sono rappresentate da una
matrice di numeri reali.
Figura 4: Immagini di navi
Figura 5: Immagini di iceberg

4
Strategia
Reti neurali con stati convoluzionali con semplice pre-processamento delle immagini.
Strumenti utilizzati
Python 2.7
Linguaggio di programmazione scelto per la sua versatilità e la sua diffusione in questo
campo di studi. Dispone di librerie quali Tensorflow e Keras che abbiamo utilizzato per
svolgere il progetto
Tensorflow
Tensorflow è una libreria di software open source per il calcolo numerico tramite l’utilizzo di
grafici per rappresentare il flusso di dati.
I nodi nel grafico rappresentano operazioni matematiche, mentre gli archi rappresentano i
vettori di dati multidimensionali (tensori) comunicati.
Keras
Keras è una API di alto livello per lo sviluppo di reti neurali scritta in Python e può essere
utilizzata con Tensorflow, CNTK o Theano. Con Keras, i modelli si possono creare in due
modi differenti:
● API sequenziale: per la creazione livello per livello di modelli molto semplici.
● API funzionale: per la creazione di modelli più complessi. Nella nostra analisi,
abbiamo dovuto utilizzare l’API funzionale per poter creare un modello con più di un
input.
CNN (Convolutional Neural Network)
Le reti neurali convoluzionali sono un tipo di rete neurale feed-forward che è stato ispirato al
funzionamento dei neuroni della corteccia visiva degli animali , i cui neuroni individuali sono
disposti in maniera tale da rispondere alle regioni di sovrapposizione che tassellano il campo
Figura 6: Rete neurale convoluzionale

5
visivo. Sono spesso utilizzate nel riconoscimento di immagini, per cui sono particolarmente
adatte e non richiedono pre-elaborazione delle immagini.
In letteratura si possono trovare differenti architetture di reti convoluzionali, la famiglia LeNet
utilizza i seguenti strati:
● Convolutional layer
● Non-linearity layer
● Pooling layer
● Fully connected layer
Lo strato convoluzionale ha il compito di estrarre caratteristiche dalle immagini. Più strati
convoluzionali usiamo, più complicati saranno le caratteristiche che la nostra rete riuscirà ad
imparare. L’estrazione di queste caratteristiche avviene tramite l’operazione di convoluzione,
che consiste nell’applicare il prodotto matriciale della matrice (filtro) su tutta l’estensione
dell’immagine.
Lo strato di pooling serve a ridurre la dimensione dell’immagine. In particolare, il Max
Pooling, prende il massimo valore da una finestra 𝑛 ∗ 𝑛. Questa operazione è utile nella
prevenzione dall’overfitting e rende la rete resistente a piccole variazioni di input.
Infine, lo strato completamente connesso è un Multi Layer Perceptron che combinando le
caratteristiche estratte degli strati convoluzionali precedenti classifica l’immagine originale
nelle varie classi.
Figura 8: Filtro di convoluzione
Figura 7: Immagine
Figura 9: Operazione di convoluzione
6
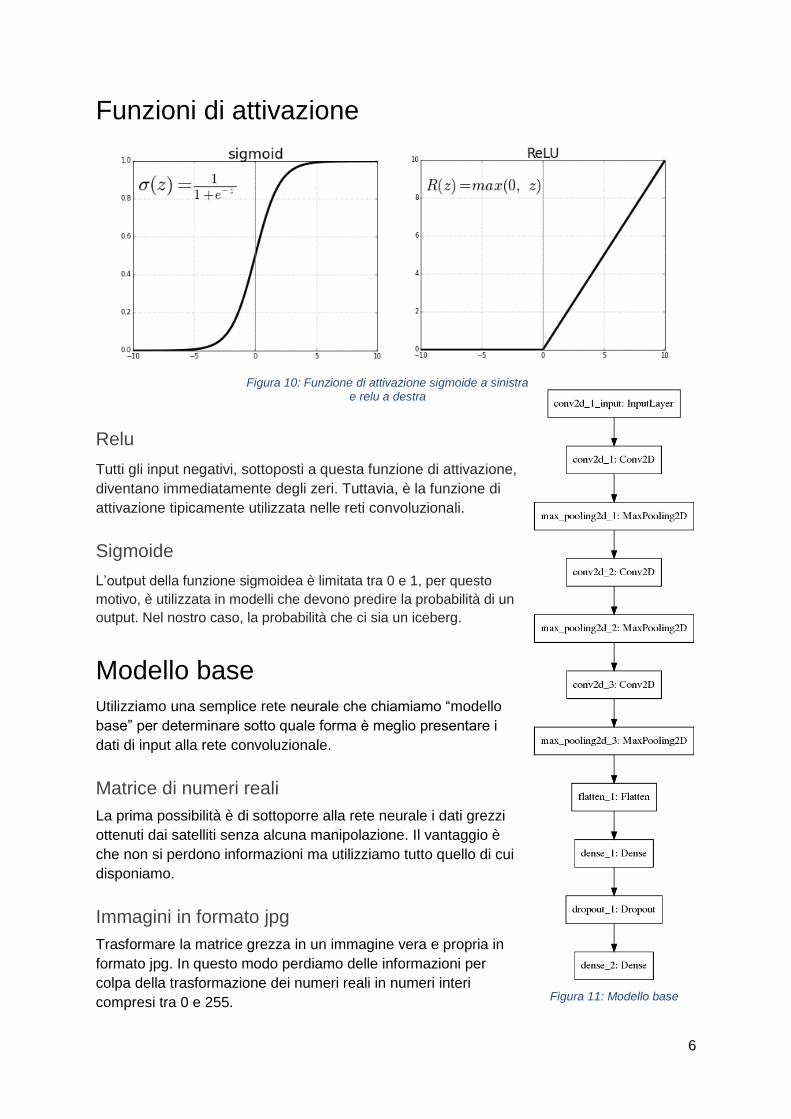
Funzioni di attivazione
Relu
Tutti gli input negativi, sottoposti a questa funzione di attivazione,
diventano immediatamente degli zeri. Tuttavia, è la funzione di
attivazione tipicamente utilizzata nelle reti convoluzionali.
Sigmoide
L’output della funzione sigmoidea è limitata tra 0 e 1, per questo
motivo, è utilizzata in modelli che devono predire la probabilità di un
output. Nel nostro caso, la probabilità che ci sia un iceberg.
Modello base
Utilizziamo una semplice rete neurale che chiamiamo “modello
base” per determinare sotto quale forma è meglio presentare i
dati di input alla rete convoluzionale.
Matrice di numeri reali
La prima possibilità è di sottoporre alla rete neurale i dati grezzi
ottenuti dai satelliti senza alcuna manipolazione. Il vantaggio è
che non si perdono informazioni ma utilizziamo tutto quello di cui
disponiamo.
Immagini in formato jpg
Trasformare la matrice grezza in un immagine vera e propria in
formato jpg. In questo modo perdiamo delle informazioni per
colpa della trasformazione dei numeri reali in numeri interi
compresi tra 0 e 255.
Figura 10: Funzione di attivazione sigmoide a sinistra e relu a destra
Figura 11: Modello base

7
Immagini ritagliate
Cerchiamo di eliminare le informazioni inutili per facilitare il lavoro della rete neurale
ritagliando l’area interessante. L’oggetto da analizzare è sempre caratterizzato un colore
molto chiaro, ritagliamo, quindi i pixel con un valore sopra di una soglia euristica.
Le immagini con sfondo molto chiaro non vengono
ritagliate perché la soglia stabilita non è abbastanza discriminante.
Immagini con parti annerite
Un altro modo semplice per eliminare informazioni non utili è quello di annullare tutti i pixel
con valori sotto una certa soglia euristica decisa a priori. I risultati migliori sono stati ottenuti
con una soglia pari a 150. In seguito, le immagini ottenute, come si può vedere anche in
questo caso, l’area interessante è difficile da evidenziare se lo sfondo è troppo chiaro.
Figure 12: Immagine originale a sinistra e
corrispondente immagine ritagliata a destra.
Figure 13: Immagine originale con sfondo molto chiaro a sinistra e corrispondente
immagine ritagliata a destra.
Figure 14: Immagine originale a sinistra e corrispondente immagine manipolata a destra.
Figure 11: Immagine originale con sfondo chiaro a sinistra e corriposndente immagine manipolata a destra.
8
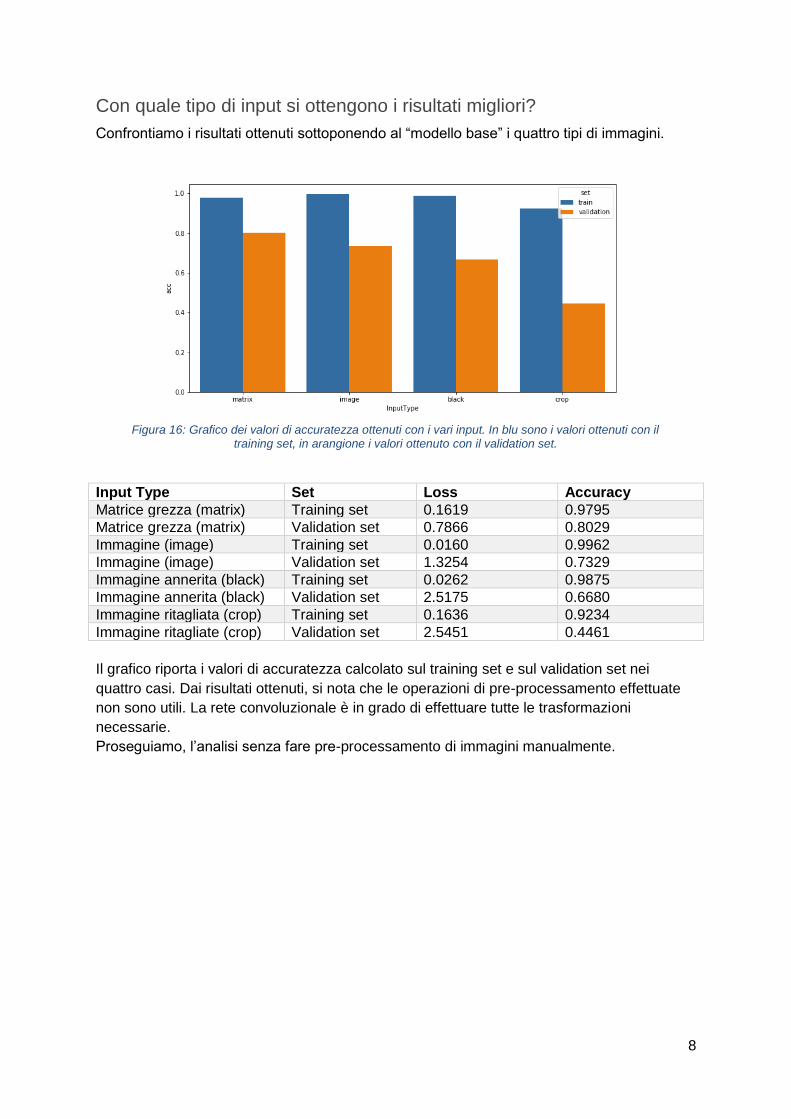
Con quale tipo di input si ottengono i risultati migliori?
Confrontiamo i risultati ottenuti sottoponendo al “modello base” i quattro tipi di immagini.
Input Type Set Loss Accuracy
Matrice grezza (matrix) Training set 0.1619 0.9795
Matrice grezza (matrix) Validation set 0.7866 0.8029
Immagine (image) Training set 0.0160 0.9962
Immagine (image) Validation set 1.3254 0.7329
Immagine annerita (black) Training set 0.0262 0.9875
Immagine annerita (black) Validation set 2.5175 0.6680
Immagine ritagliata (crop) Training set 0.1636 0.9234
Immagine ritagliate (crop) Validation set 2.5451 0.4461
Il grafico riporta i valori di accuratezza calcolato sul training set e sul validation set nei
quattro casi. Dai risultati ottenuti, si nota che le operazioni di pre-processamento effettuate
non sono utili. La rete convoluzionale è in grado di effettuare tutte le trasformazioni
necessarie.
Proseguiamo, l’analisi senza fare pre-processamento di immagini manualmente.
Figura 16: Grafico dei valori di accuratezza ottenuti con i vari input. In blu sono i valori ottenuti con il training set, in arangione i valori ottenuto con il validation set.
9
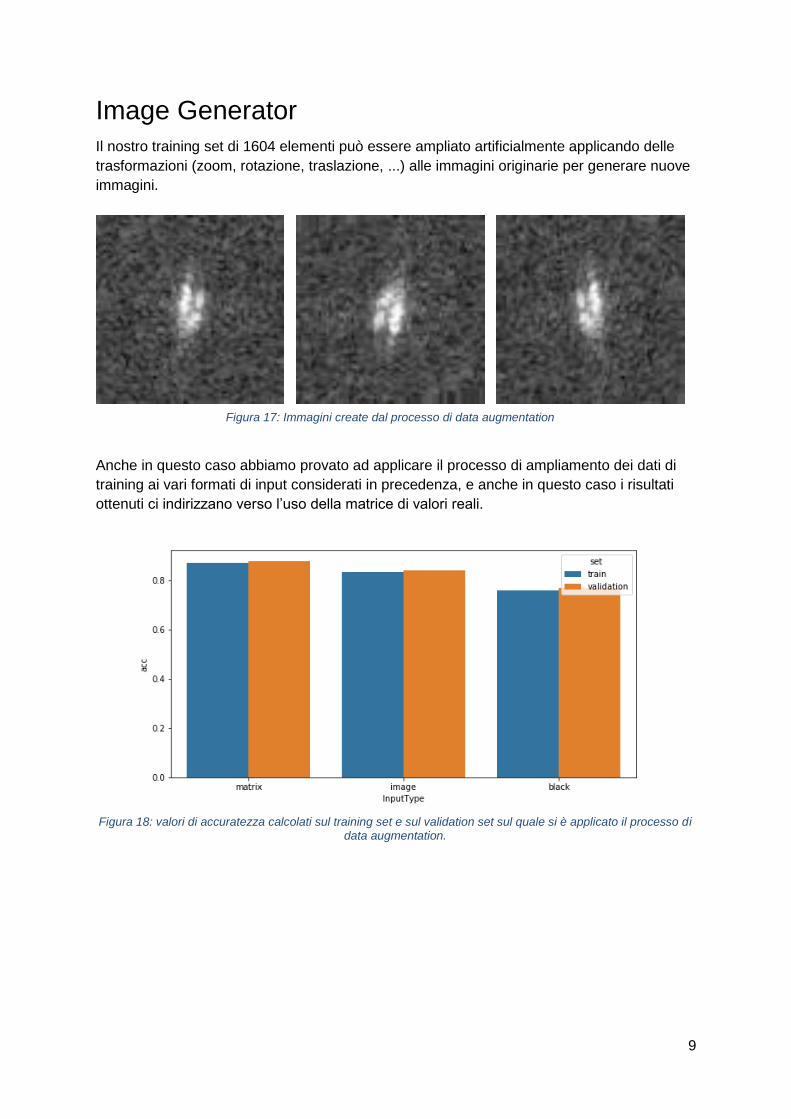
Image Generator
Il nostro training set di 1604 elementi può essere ampliato artificialmente applicando delle
trasformazioni (zoom, rotazione, traslazione, ...) alle immagini originarie per generare nuove
immagini.
Anche in questo caso abbiamo provato ad applicare il processo di ampliamento dei dati di
training ai vari formati di input considerati in precedenza, e anche in questo caso i risultati
ottenuti ci indirizzano verso l’uso della matrice di valori reali.
Figura 17: Immagini create dal processo di data augmentation
Figura 18: valori di accuratezza calcolati sul training set e sul validation set sul quale si è applicato il processo di data augmentation.

10
Modello completo
Modello in grado di accettare tre diversi input:
● Band_1
● Band_2
● Inc_angle
Due immagini “band_1” e “band_2” passano attraverso una serie di strati convoluzionali, il
risultato di queste convoluzioni viene unito a “inc_angle” e un MultiLayer Perceptron si
occupa della classificazione in nave o iceberg.
#band_1 images
visible1 = Input(shape=(75,75,1)) #Immagini
conv11 = Conv2D(32, kernel_size=3, activation='relu')(visible1)
pool11 = MaxPooling2D(pool_size=(2, 2))(conv11)
conv12 = Conv2D(64, kernel_size=3, activation='relu')(pool11)
pool12 = MaxPooling2D(pool_size=(2, 2))(conv12)
conv13 = Conv2D(64, kernel_size=3, activation='relu')(pool12)
pool13 = MaxPooling2D(pool_size=(2, 2))(conv13)
flat1 = Flatten()(pool13)
#band_2 images
visible2 = Input(shape=(75,75,1)) #Immagini
conv21 = Conv2D(32, kernel_size=3, activation='relu')(visible2)
pool21 = MaxPooling2D(pool_size=(2, 2))(conv21)
conv22 = Conv2D(64, kernel_size=3, activation='relu')(pool21)
pool22 = MaxPooling2D(pool_size=(2, 2))(conv22)
conv23 = Conv2D(64, kernel_size=3, activation='relu')(pool22)
pool23 = MaxPooling2D(pool_size=(2, 2))(conv23)
flat2 = Flatten()(pool23)
#inc_angles
visible3 = Input(shape=(1,)) #Vettore con gli angoli
flat3 = Dense(32, input_shape=(1,))(visible3)
#merge
merge = concatenate([flat1, flat2, flat3])
hidden1 = Dense(32, activation='relu')(merge)
hidden2 = Dropout(0.5)(hidden1)
hidden3 = Dense(32, activation='relu')(hidden2)
output = Dense(1, activation='sigmoid')(hidden3)
model = Model(inputs=[visible1, visible2, visible3], outputs=output)
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
metrics=['accuracy'])
history=model.fit([band_1_train,band_2_train,angoli_train],[train_classes],
validation_data=([band_1_val, band_2_val, angoli_val], [val_classes]),
epochs=15, verbose=2)
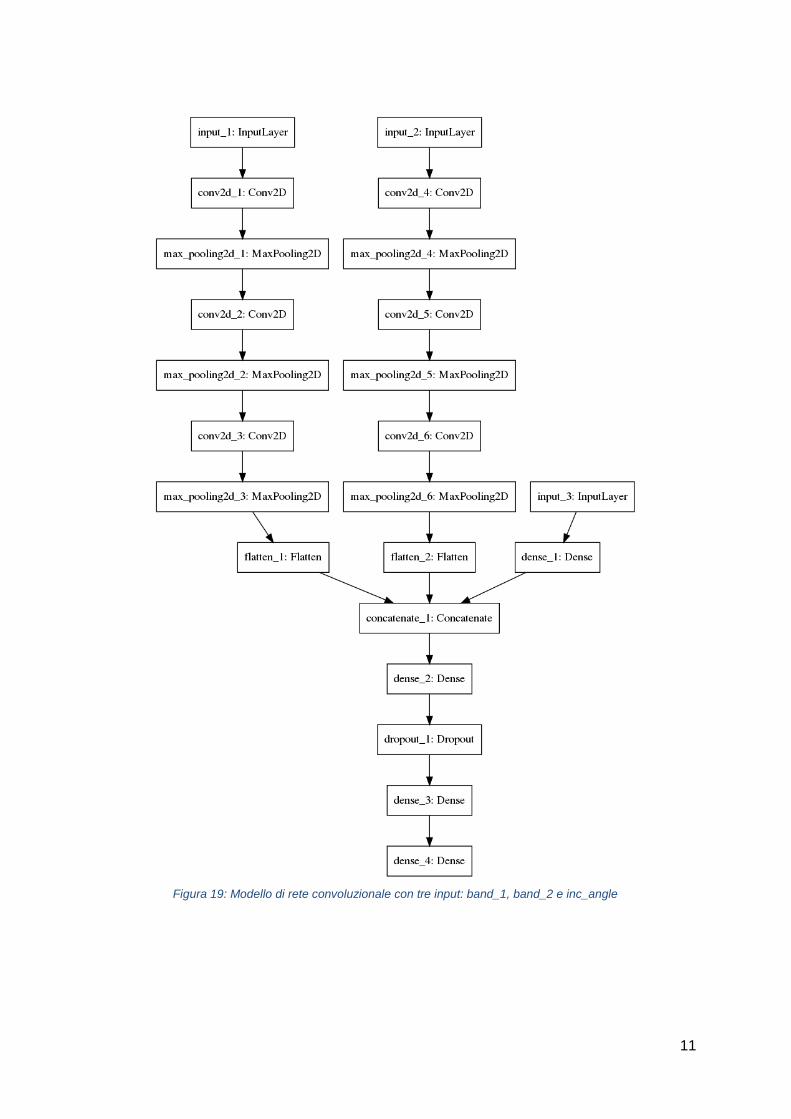
11
Figura 19: Modello di rete convoluzionale con tre input: band_1, band_2 e inc_angle
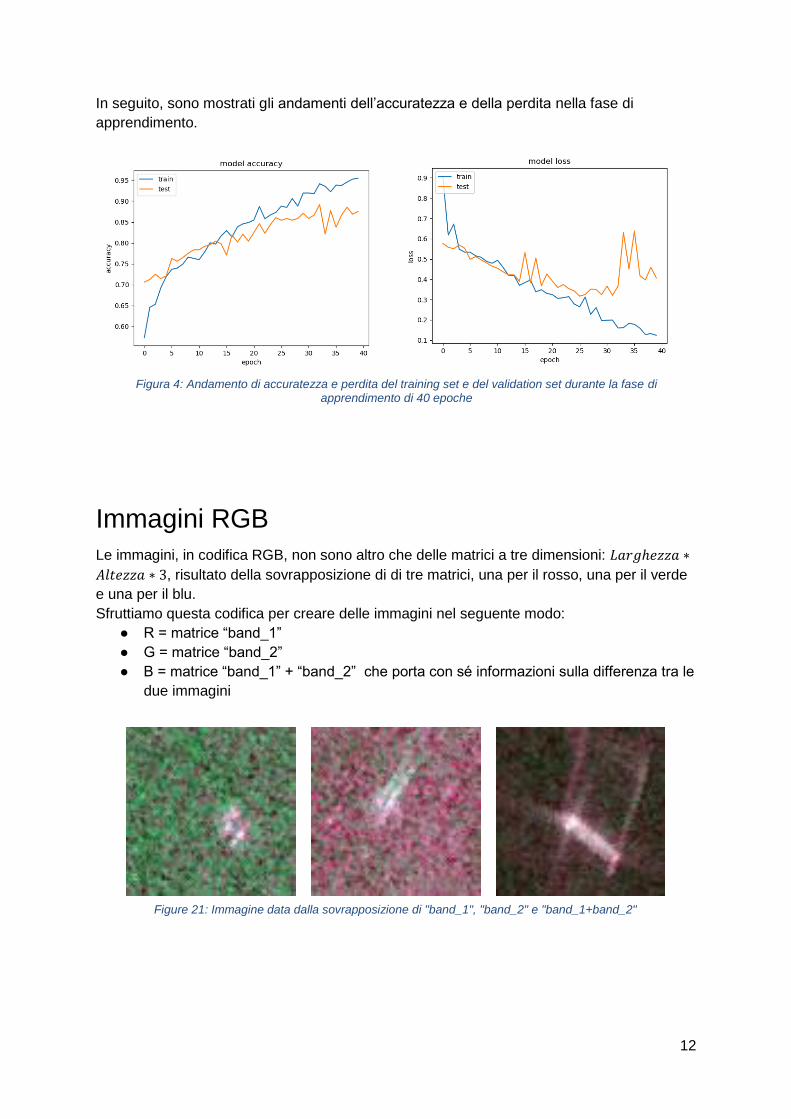
12
In seguito, sono mostrati gli andamenti dell’accuratezza e della perdita nella fase di
apprendimento.
Immagini RGB
Le immagini, in codifica RGB, non sono altro che delle matrici a tre dimensioni: 𝐿𝑎𝑟𝑔ℎ𝑒𝑧𝑧𝑎 ∗
𝐴𝑙𝑡𝑒𝑧𝑧𝑎 ∗ 3, risultato della sovrapposizione di di tre matrici, una per il rosso, una per il verde
e una per il blu.
Sfruttiamo questa codifica per creare delle immagini nel seguente modo:
● R = matrice “band_1”
● G = matrice “band_2”
● B = matrice “band_1” + “band_2” che porta con sé informazioni sulla differenza tra le
due immagini
Figura 4: Andamento di accuratezza e perdita del training set e del validation set durante la fase di apprendimento di 40 epoche
Figure 21: Immagine data dalla sovrapposizione di "band_1", "band_2" e "band_1+band_2"
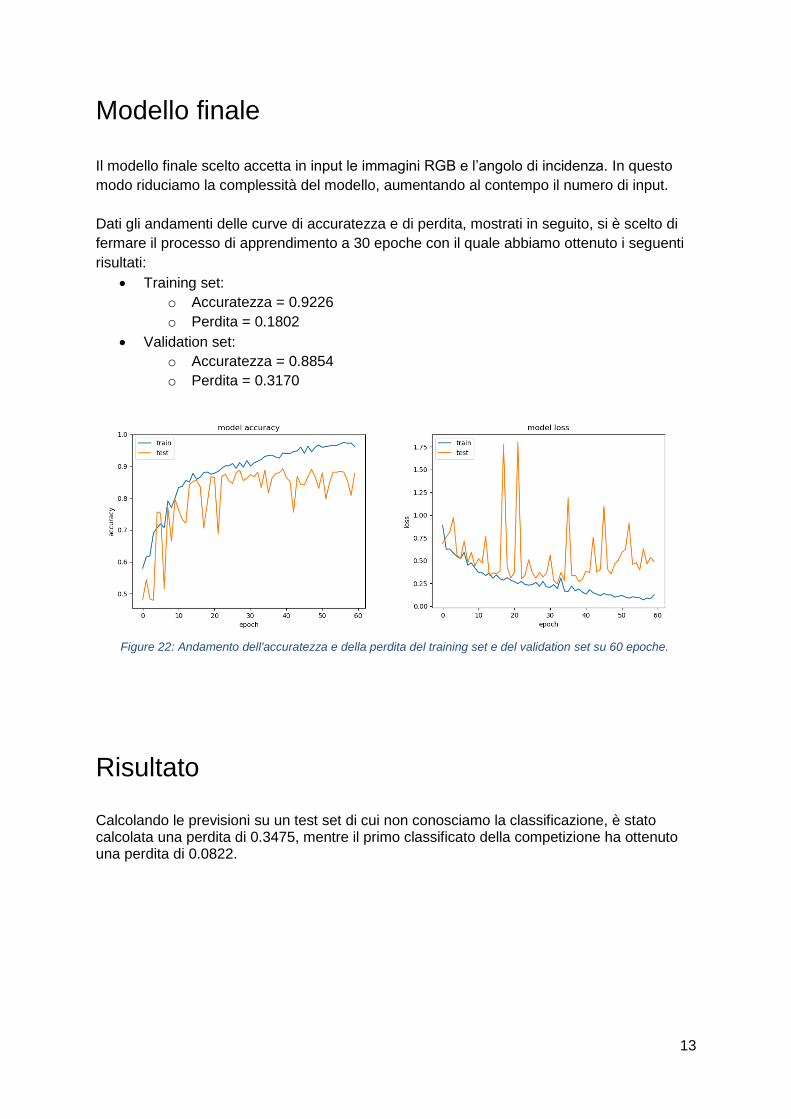
13
Modello finale
Il modello finale scelto accetta in input le immagini RGB e l’angolo di incidenza. In questo
modo riduciamo la complessità del modello, aumentando al contempo il numero di input.
Dati gli andamenti delle curve di accuratezza e di perdita, mostrati in seguito, si è scelto di
fermare il processo di apprendimento a 30 epoche con il quale abbiamo ottenuto i seguenti
risultati:
• Training set:
o Accuratezza = 0.9226
o Perdita = 0.1802
• Validation set:
o Accuratezza = 0.8854
o Perdita = 0.3170
Risultato
Calcolando le previsioni su un test set di cui non conosciamo la classificazione, è stato calcolata una perdita di 0.3475, mentre il primo classificato della competizione ha ottenuto una perdita di 0.0822.
Figure 22: Andamento dell'accuratezza e della perdita del training set e del validation set su 60 epoche.

14
#create model input1 = Input(shape=(75,75,3)) #Immagini conv11 = Conv2D(64, kernel_size=3, activation='relu')(input1) pool11 = MaxPooling2D(pool_size=(2, 2))(conv11) drop11 = Dropout(0.2)(pool11) conv12 = Conv2D(128, kernel_size=3, activation='relu')(drop11) pool12 = MaxPooling2D(pool_size=(2, 2))(conv12) drop12 = Dropout(0.2)(pool12) conv13 = Conv2D(128, kernel_size=3, activation='relu')(drop12) pool13 = MaxPooling2D(pool_size=(2, 2))(conv13) drop13 = Dropout(0.2)(pool13) conv14 = Conv2D(64, kernel_size=3, activation='relu')(pool13) pool14 = MaxPooling2D(pool_size=(2, 2))(conv14) drop14 = Dropout(0.2)(pool14) flat1 = Flatten()(drop14) input2 = Input(shape=(1,)) #Vettore con gli angoli merge = concatenate([flat1, input2]) dense1 = Dense(512, activation='relu')(merge) drop1 = Dropout(0.2)(dense1) dense2 = Dense(512, activation='relu')(drop1) drop2 = Dropout(0.2)(dense2) dense3 = Dense(256, activation='relu')(dense2) drop3 = Dropout(0.2)(dense3) output = Dense(1, activation='sigmoid')(drop3) model = Model(inputs=[input1, input2], outputs=output) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
Figure 23: Modello della rete neurale
finale

15
Bibliografia
Descrizione competizione:
https://www.kaggle.com/c/statoil-iceberg-classifier-challenge#description
Descrizione background:
https://www.kaggle.com/c/statoil-iceberg-classifier-challenge#Background
QUASI-SCATTERING MATRIX REGISTRATION IN REPEAT PASS MODE:[L. Zakharova and
A. Zakharov]
https://earth.esa.int/workshops/polinsar2009/participants/419/paper_419_p6_8zakh.pdf
Combining polarimetric channels for better ship detection results [Tonje Nanette Arnesen
Hannevik]:
https://earth.esa.int/c/document_library/get_file?folderId=409229&name=DLFE-5566.pdf
Getting started with the Keras Sequential model
https://keras.io/getting-started/sequential-model-guide/
Overfitting
http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf
Convolutional neural networks
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
http://cs231n.github.io/


















