Comparación de los lenguajes de Dataflow LabVIEW y VEE
30
Universidad Politécnica de Madrid Facultad de Informática Paradigmas de Programación Comparación de los lenguajes de Dataflow LabVIEW y VEE Javier Isaac Espinosa Muñoz MUSS Enero 2015
-
Upload
isaac-espinosa -
Category
Documents
-
view
61 -
download
0
Transcript of Comparación de los lenguajes de Dataflow LabVIEW y VEE

Universidad Politécnica de Madrid
Facultad de Informática
Paradigmas de Programación
Comparación de los lenguajes de Dataflow LabVIEW y VEE
Javier Isaac Espinosa Muñoz
MUSS
Enero 2015

2
ÍNDICE DE CONTENIDOS
1. INTRODUCCIÓN…………………………………………………………… 3
1.1 PERSPECTIVA HISTORICA……………………………………. 3
2. CARACTERÍSTICAS DEL PARADIGMA DE DATAFLOW…………… 4
3. DATAFLOW………………………………………………………………… 5
4. ESTRUCTURA DE UN PROGRAMA EN DATAFLOW……………….. 7
5. LENGUAJES DATAFLOW……………………………………………….. 9
6 LABVIEW……………………………………………………………………. 11
6.1 DESARROLLO DE UN EJEMPLO EN LABVIEW…………… 16
7 AGILENT VEE……………………………………………………………… 17
7.1 DESARROLLO DE UN EJEMPLO EN AGILENT VEE……… 20
8. RESULTADOS……………………………………………………………... 21
8.1 VENTAJAS DE LABVIEW ……………………………………… 22
8.2 VENTAJAS DE VEE …………………………………………….. 23
8.3 INCONVENIENTES DE LABVIEW …………………………….. 24
8.4 INCONVENIENTES DE VEE …………………………………… 24
9. OPORTUNIDADES DE INVESTIGACIÓN………………………………. 26
10. CONCLUSIONES ………………………………………………………… 27
11. FUENTES Y BIBLIOGRAFIA …………………………………………… 30

3
1. INTRODUCCIÓN
El desarrollo de la programación gráfica ha cambiado dramáticamente la forma en
que el software de prueba y medida se utilizan en la actualidad. Además ha hecho
posible la creación de software y prototipos de forma más sencilla y rápida qué
antes.
En este trabajo se abordara la perspectiva histórica, hasta llegar a la parte qué
comprende la comparación, qué más qué eso es ver las cualidades, ventajas y
desventajas qué tienen ambos lenguajes frente a la filosofía de dataflow, para
realizar esto de la manera justa, se tratara un ejemplo idéntico con aplicación en
ambos entornos.
1.1 PERSPECTIVA HISTORICA
La motivación original para la investigación en el flujo de datos fue la explotación
del paralelismo masivo. Por lo tanto, se trabajó mucho para desarrollar la forma de
programar procesadores paralelos. Sin embargo, una escuela de pensamiento
sostenía que los procesadores "Von Neumann" convencionales eran
inherentemente inadecuados para la explotación del paralelismo, esto debido a su
contador del programa global y a la memoria qué al igual actualiza de manera
global, estas dos cualidades se convirtieron en un cuello de botella para el modelo.
Así qué la alternativa propuesta fue la arquitectura basada en flujos de datos
(dataflow) [1]. Lo que evita estos cuellos de botella es el uso de memoria sólo
local y mediante la ejecución de instrucciones tan pronto como sus operadores
estén disponibles. El nombre de dataflow viene de la idea conceptual que un
programa usado en un computador mediante el paradigma dataflow es un grafo
dirigido y que los flujos de datos entre instrucciones, a lo largo de sus arcos, hasta
pasar por los nodos o transformadores qué serán elementos pasivos en el modelo
[2].
Junto con el desarrollo del paradigma de flujo de datos, también lo hizo la
arquitectura basada en dataflow para hardware, frente a esto, los investigadores
encontraron problemas en la compilación de lenguajes de programación
imperativo convencionales para ejecutarse en hardware de flujo de datos, en
particular los relacionados con los efectos secundarios y localidad, la manera de
resolver esto fue hacer uso de modelos híbridos entre dataflow y “Von Neumann”
de manera qué se pudiera agrupar instrucciones y ejecutadas de manera
secuencial, esto último basado siempre en el principio del modelo de ejecución de
dataflow [3].

4
En la década de los 90s se vio un crecimiento en el campo de lenguajes de
programación visual de flujo de datos. Algunos de estos, tales como LabVIEW y
HP VEE se debió principalmente a la industria, y se han convertido en un producto
comercial exitoso que sigue siendo utilizado en la actualidad. Fueron creados
para la investigación. Todos tienen en la ingeniería de software como su principal
motivación, mientras que programación de flujo de datos fue tradicionalmente se
ocupa de la explotación del paralelismo.
2. CARACTERÍSTICAS DEL PARADIGMA DE DATAFLOW
En el modelo de ejecución del flujo de datos, un programa es representado por un
gráfico directo. los nodos del gráfico son instrucciones primitivas tales como las
operaciones aritméticas o de comparación. Los arcos dirigidos entre los nodos
representan las dependencias de datos entre las instrucciones. De forma
conceptual, los flujos de datos actúan como señales a lo largo de los arcos que se
comportan como canales ilimitados de datos, primero en entrar, primero en salir
(first-in, first-out-FIFO) esto en las colas de entrada. Los arcos que fluyen hacia el
ánodo se dice que son los arcos de entrada a ese nodo, mientras que los que
provienen de distancia se dice que son los arcos de salida de ese nodo.
Cuando comience el programa, la activación especial de nodos da lugar a los
datos en ciertos arcos de entrada clave, lo que provocó que el resto del programa
.Siempre qué un conjunto específico de los arcos de entrada de un nodo llamado
firingset tiene datos en él, el nodo se dice que es fireable. Un nodo fireable se
ejecuta en un tiempo indefinido después de que se activado. El resultado es que
elimina un dato contador de cada nodo en el conjunto de disparo, realiza su
operación, y coloca una nueva muestra de datos sobre todos o algunos de sus
arcos de salida. Ella a continuación, deja de ejecución y espera para convertirse
fireable de nuevo. Por este método, las instrucciones están programadas para su
ejecución tan pronto como sus operadores estén disponibles. Este se encuentra
en contraste con el modelo de ejecución “von Neumann”, en el que una instrucción
es sólo se ejecuta cuando el contador de programa la alcanza,
independientemente de que se pueda ejecutar antes.
La ventaja clave es que, en el dataflow, más de una instrucción puede ser
ejecutada a la vez. Por lo tanto, si se convierten en fireable varias instrucciones al
mismo tiempo, pueden ser ejecutadas en paralelo. Este sencillo principio ofrece la
posibilidad de masiva paralela la ejecución en el nivel de instrucción.

5
3. DATAFLOW
Un ejemplo de flujo de datos en comparación con un programa secuencial
tradicional se muestra en la Figura 1(a) se coloca un fragmento de código de
programa secuencial y la Figura 1 (b) muestra cómo esto se representa como un
grafica de flujo de datos .las flechas representan arcos y los círculos representan
los nodos de instrucciones. El cuadrado representa un valor constante, con código
de duro en el programa. Las letras representan donde los flujos de datos entran o
salen del resto del programa. Cuando más de una flecha emana de una misma
entrada dada, significa que el valor único se duplica y transmitida por cada ruta o
arco.
X Y 10
+ /
*
C
(a) (b)
Fig.1. Un simple programa secuencial (a) y su equivalente en dataflow (b)
Bajo el modelo de ejecución “von Neumann”, el programa en la Figura 1 (a) sería
ejecutar secuencialmente en tres unidades de tiempo(ciclos de procesador). En 1,
se añaden y se asignan a la unidad de A. En tiempo 2 Y se divide por 10 y se
asigna a B. En unidad de tiempo 3, A y B se multiplican entre sí y se asignan a C.
Bajo el modelo de ejecución de flujo de datos, donde el gráfico de la figura 1 (b) es
el código de la máquina, la adición y la división son tanto inmediatamente fireable
(activados), ya que todos sus datos están presentes inicialmente. En unidad de
tiempo 1, X e Y se añaden en paralelo con Y se divide por 10. Los resultados se
colocan en los arcos de salida, que representa las variables A y B.
A:= X+Y B:= Y/10 C:= A*B

6
En la unidad de tiempo 2, el nodo de la multiplicación se convierte en fireable y se
ejecuta, la colocación de la resultado en el arco que representa la variable C. (En
el flujo de datos, cada arco puede decirse que representa una variable.) en este
escenario, la ejecución toma sólo dos unidades de tiempo bajo un modelo de
ejecución en paralelo.
Está claro que el flujo de datos proporciona el potencial de proporcionar una
mejora en la velocidad sustancial, mediante la utilización de las dependencias de
datos para localizar el paralelismo. Además, si el cálculo debe ser realizado sobre
más de un conjunto de datos, los cálculos en la segunda ola de valores de X y Y
puede comenzar antes de los de la primer conjunto se ha completado. Es
conocido como flujo de datos encauzados ( pipelined data flow) [1] y puede utilizar
un grado sustancial de paralelismo, en particular en bucles, aunque existen
técnicas para utilizar mayor paralelismo en bucles. Un gráfico de flujo de datos que
produce un único conjunto de fichas de salida para cada conjunto único de fichas
de entrada se dice que es de buen comportamiento.
Otro punto clave es que la operación de cada nodo es funcional. Esto se debe a
que los datos nunca se modifica (nuevas fichas de datos se crea cuando un nodo
es fireable, ningún nodo tiene efectos secundarios, y la ausencia de un almacén
de datos global significa que existe localidad de efecto. Como resultado de ser
funcional, y el hecho de que los datos viajan en las colas ordenadas, un programa
expresado en el modelo de flujo de datos pura es determinista. Esto significa que,
para un determinado conjunto de entradas, un programa producirá siempre el
mismo conjunto de salidas.
Esto puede ser una propiedad importante en ciertas aplicaciones. Algunos han
realizado investigaciones sobre las consecuencias de un comportamiento no
determinada, pero ese tema no se abarcara en este trabajo de investigación.
En la Figura 1 (b) los dos arcos que emanan de la entrada Y significan que ese
valor está listo para ser duplicado. Bifurcar arcos de esta manera es esencial si un
contador de datos es necesario por dos nodos diferentes. Una ficha de datos que
llega a un arco en forma de horquilla se duplica y una copia enviada por cada
rama. Esto preserva la independencia de los datos y la funcionalidad del sistema.
Para preservar la determinación del modelo de red en el flujo, no está permitido
fusionar arbitrariamente dos arcos durante el flujo de fichas de datos. Si esto se
permite, los datos podrían llegar a un nodo fuera de orden y poner en peligro el
cálculo. Es obvio, sin embargo, que sería difícil el hecho de expresar un programa

7
en el modelo de flujo de datos si arcos sólo podían ser divididas y nunca se
fusionaron.
Así, el modelo de flujo de datos proporciona nodos de control especiales llamadas
puertas que permiten pasar dentro de unos límites bien controlados.
T F
(a) Mezcla Control (b) Switch Control
T F
Fig.2. Puertas en el gráfico de dataflow
La Figura 2 (a) muestra una puerta de mezcla. Estas puertas llevan dos arcos de
entrada de datos, con la etiqueta de verdadero y falso, así como un arco de
entrada "control" que lleva un valor booleano. Cuando se dispara el nodo, el
testigo de control se absorbe primero. Si el valor es verdadero, el token en la
entrada verdadera se absorbe y se coloca en la salida. Si es falso, entonces el
token en la entrada falsa se absorbe y se coloca en la salida. La Figura 2 (b)
muestra una puerta Switch. Esta puerta opera de la misma manera, excepto que
hay una sola entrada y la señal de control determina en cuál de las dos salidas se
coloca.
4. ESTRUCTURA DE UN PROGRAMA EN DATAFLOW
En el paradigma dataflow de forma teórica, existen dos formas de implementar un
programa.
1. Modelo dirigido por los datos (Data-Driven model)
Este término es un poco engañoso ya que ambos enfoques se puede decir que
sea impulsado por los datos, en la medida en que siguen los principios de flujo de
datos. Este enfoque debería ser realmente denominado el enfoque basado en
datos de disponibilidad (data-availability-driven) [1] impulsado porque la ejecución
depende de la disponibilidad de datos. Esencialmente un nodo está inactivo
mientras los datos no lleguen a sus entradas. Es responsabilidad de un dispositivo
de gestión global para que notifique y active nodos cuando sus datos han llegado.
El enfoque basado en datos es un proceso de dos fases donde:
1. Un nodo se activa cuando sus entradas están disponibles
2. Recibe sus entradas y coloca las fichas (Tokens) en sus arcos de salida.

8
2. Modelo dirigido por la demanda (Demand-Driven model)
En este enfoque, un nodo se activa sólo cuando se recibe una solicitud de datos
de sus arcos de salida. En este punto, exige datos de todos los arcos de entrada
correspondientes. Una vez que haya recibido sus datos, ejecuta y coloca las fichas
de datos sobre sus arcos de salida.
El enfoque basado en la demanda es por tanto un proceso de cuatro fases [4] en
la que:
1. Las solicitudes de entorno de datos de un nodo.
2. El nodo se activa y solicita los datos de su entorno.
3 El medio ambiente responde con datos.
4. El nodo coloca fichas en sus arcos de salida.
La ejecución del programa se inicia cuando el entorno del gráfico exige alguna
salida.
Cada uno de estos enfoques de implementación tiene ciertas ventajas. El enfoque
basado en datos (Data-Driven model) tiene la ventaja de que no tiene la
sobrecarga adicional de propagar las peticiones de datos el gráfico de flujo de
datos. Por otra parte, el enfoque basado en la demanda (Demand-Driven model)
tiene la ventaja de que ciertos tipos de nodos pueden ser eliminados, Esto es
porque sólo los datos necesarios serán exigidos.
Por ejemplo, el nodo de conmutación (switch), que se muestra en la Figura 2 (b),
no se requiere bajo un enfoque basado en la demanda, ya que sólo una de las
salidas Verdadero o Falso exigirá la entrada, pero no ambos.
Por lo tanto, ambos pueden estar unidos directamente a la entrada. Este es un
ejemplo de cómo la programación con el flujo de datos puede ser afectada por la
elección de la implementación física, o al menos por la elección del modelo de
ejecución.
También se puede argumentar que el enfoque basado en la demanda (Demand-
Driven model) impide la creación de ciertos tipos de programas. Por ejemplo, en
el software moderno es a menudo basado en eventos, como por ejemplo los
desarrollos en tiempo real. En estos no es suficiente para el entorno simplemente
exigir de entrada. Este ejemplo parece requerir un enfoque impulsado por los
datos (Data-Driven model).

9
5. LENGUAJES DATAFLOW
Desde la creación del paradigma dataflow han sido diversos el número de
lenguajes propuestos para desarrollar este enfoqué de programación, algunos de
ellos se describen a continuación:
TDFL. (The Textual Data-Flow Language) fue desarrollado por Weng en 1975,
como fue uno de los primeros lenguajes de flujo de datos. Fue diseñado para ser
compilados en un gráfico de flujo de datos con flujos de datos de una manera
relativamente sencilla y con el apoyo de detección de estancamientos de tiempo
durante la compilación.
Un programa expresado en TDFL consistió en una serie de módulos, de forma
análoga a los procedimientos en otros Lenguajes de programación. Cada módulo
se compone de una serie de declaraciones que eran o asignaciones que
obedecen la regla de asignación individual (single-assignment rule), sentencias
condicionales, o una llamada a otro módulo. La iteración no se proporcionaba
directamente, pero los módulos podía llamarse a sí mismos de forma recursiva.
LAU. Desarrollado en 1976 por el Grupo de Estructuras de ordenador de ONERA-
CERT en Francia.
Era una lengua de asignación única e incluyó bifurcación condicional y bucle que
eran compatibles con esta regla mediante el uso de la palabra clave de edad (the
old keyword). Era uno de los pocos lenguajes de flujo de datos que proporcionaron
paralelismo explícito a través de la palabra clave que especifica ampliar
asignación paralela. LAU tenía algunas características que eran similares a los
lenguajes orientados a objetos, tales como la capacidad de encapsular los datos y
operaciones.
Lucid. Originalmente desarrollado de forma independientemente del campo de
flujo de datos por Ashcroft y Wadge en 1977, Lucid era un lenguaje funcional
diseñado para permitir pruebas formales. La recursividad se consideraba
demasiado restrictivo para construcciones de bucle, pero se dio cuenta de que la
iteración introdujo dos características no matemáticas en la programación: la
transferencia y asignación.

10
Por lo tanto, Lucid fue diseñado para permitir la iteración de una manera que era
matemáticamente respetable, a través de la asignación individual y el uso de la
palabra clave definir el valor de la variable en la siguiente iteración. Pronto se hizo
evidente, sin embargo, que la semántica de asignación funcionales e individuales
de Lucid fueron similares a las requeridas para las máquinas de flujo de datos, y
Ashcroft y Wadge en 1985 publico un libro en el que estableció firmemente la
afirmación de Lucid de ser un lenguaje de flujo de datos.
Desde la perspectiva de la ingeniería de software, la principal novedad en flujo de
datos en los últimos 25 años ha sido el crecimiento de programación visual de flujo
de datos (dataflow visual programming languages). Aunque la teoría detrás
DFVPLs ha estado en existencia durante muchos años, es sólo la disponibilidad
hardware gráfica de bajo costo en los años 90’s que ha hecho que sea una
práctica y fructífera área de investigación.
Las investigaciones de DFVPLs han indicado muchas soluciones a los problemas
existentes en ingeniería de software, un punto que se ampliará a continuación.
También tiene conducido a la introducción de nuevos problemas y desafíos,
particularmente aquellos asociados con los lenguajes de programación visuales en
general, así como la persistencia de los problemas, como la representación de
estructuras de datos y estructuras de control de flujo.
La investigación ha sido bastante intensa en la última década, y es el tema de
esta sección para identificar algunas de las principales tendencias en la
programación de flujo de datos durante este período.

11
6. LABVIEW
LabVIEW es un DFVPL de conocido desarrollado a mediados de la década de
80’s, nace con el objetivo de permitir la construcción de instrumentos "virtuales"
para el análisis de datos en los laboratorios. Como tal, fue diseñado para ser
utilizado por personas que no eran ellos mismos los programadores profesionales.
Un programa en LabVIEW se construye mediante la conexión de funciones
(nodos) predefinidos visualizados como cajas con iconos, además usando arcos
de rutas de datos. Cada programa también tiene una interfaz visual para permitir
el diseño del instrumento virtual. Los componentes que tienen una representación
visual aparecen tanto en la interfaz y el programa, mientras que las funciones sólo
aparecen en la ventana del programa.
Todo el programa se ejecuta según las reglas de flujo de datos.
LabVIEW hace que la experiencia de programación menos engorrosa
proporcionando construcciones iterativas y una forma de refinamiento paso a paso
mediante el cual los programadores pueden producir sus propios nodos de
función.

12
LabVIEW, cuenta con dos tipos de bucle, un bucle for y un bucle while.
Un bucle for es un nodo especial que encierra todos los nodos a ser ejecutado de
forma iterativa. A diferencia de Show-and Tell, tiene un puerto de entrada adicional
que especifica el número de veces que el ciclo se va a ejecutar. Todos los demás
valores que se emiten puertos conceptualmente vuelven a entrar en los puertos de
entrada idénticos. Otro puerto visible sólo dentro del bucle especifica el valor
actual de la variable de bucle.
El bucle while opera de una manera similar, excepto que no tiene la variable de
bucle. En cambio, tiene un puerto único visible dentro del bucle que termina
después de la iteración actual una vez que se recibe un valor de "falsa". Una
construcción única de LabVIEW permite a los horarios del bucle que se
especifiquen, por ejemplo, bucle cada 250 ms. Esto es debido a su aplicación de
lectura de instrumentos científicos.

13
Además de esto es necesario qué en las estructuras de bucle los objetos queden
dentro de la área circundante por la función, esto con la finalidad de se repitan en
dentro un cuadro la estructura o función. Los Pines de entrada y salida en el
cuadro se pueden configurar para indexar los datos entrantes o salida. Los
Registros de desplazamiento también se pueden añadir al bucle para pasar
información de una iteración a la siguiente.
Para el desarrollo de los programas se utilizan objetos gráficos, los cuales se
utilizan para cuatro funciones básicas:
1. Crear flujos de datos
2. Analizar flujos de datos
3. Tratar flujos de datos
4. Mostrar los resultados del flujo de datos
Los objetos en LabVIEW son llamados VI’s (Virtual Instrument)
Un PIN es un punto de un objeto que indica que una conexión puede hacerse en
esa ubicación.
Las líneas o arcos representan los datos y/ o pueden ser entradas al objeto o
salidas del objeto, también pueden ser utilizados para secuenciar la ejecución del
objeto.
Tipo de línea Escalar Arreglo 1D Arreglo 2D Color Numérico Naranja (Punto flotante)
Numérico Azul (Entero)
Booleano Verde
Cadena Rosa
El color y el estilo de las líneas indican el tipo de datos representados por las
líneas [6].
14
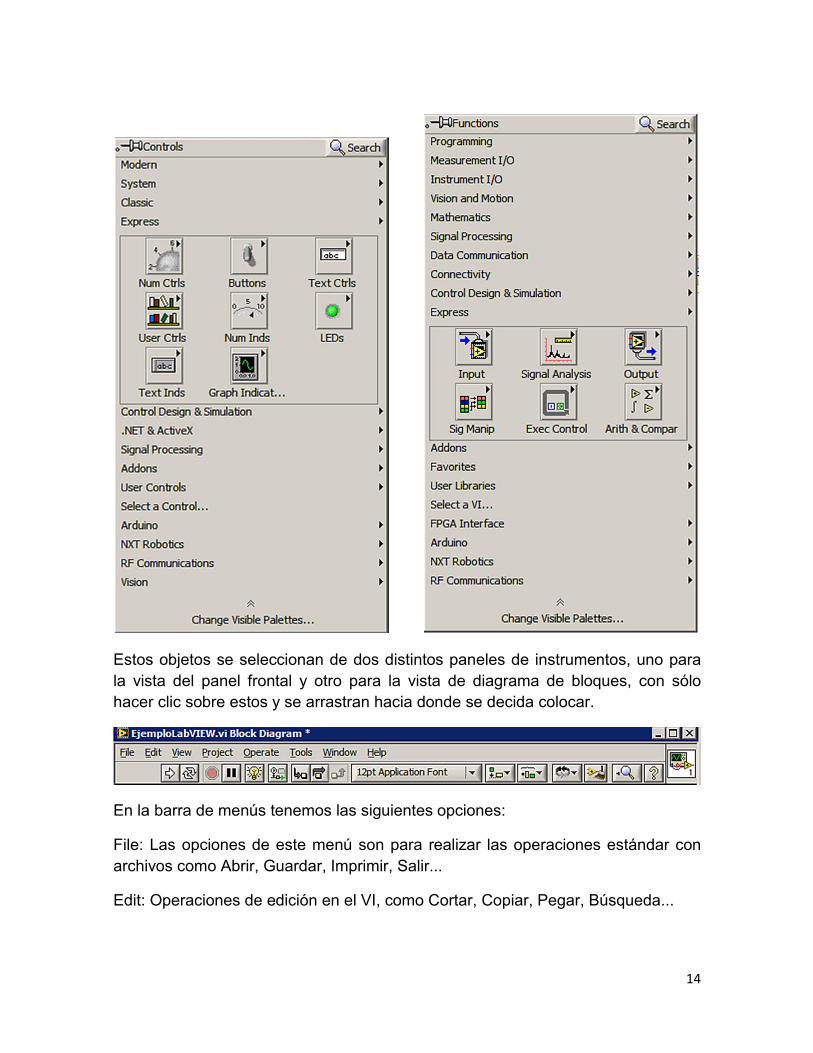
Estos objetos se seleccionan de dos distintos paneles de instrumentos, uno para
la vista del panel frontal y otro para la vista de diagrama de bloques, con sólo
hacer clic sobre estos y se arrastran hacia donde se decida colocar.
En la barra de menús tenemos las siguientes opciones:
File: Las opciones de este menú son para realizar las operaciones estándar con
archivos como Abrir, Guardar, Imprimir, Salir...
Edit: Operaciones de edición en el VI, como Cortar, Copiar, Pegar, Búsqueda...

15
Operate: Control de la ejecución del archivo activo, como Ejecutar, Parar,Cambiar
a Modo de Ejecución...
Tools: Varias utilidades como Guía de Soluciones DAQ, Historial del VI...
Browse: Menú para ver diversos aspectos del VI actual, como archivos que llaman
al VI, los subVIs que utiliza este VI, Puntos de Ruptura...
Window: Acceso y personalización de diferentes vistas del VI, como Ver
Diagrama, Ver Lista de Errores, y opciones para las paletas y ventanas
Help: Acceso a varios tipos de ayuda como Ayuda LV, ejemplos de VIs y enlaces a
los recursos de ayuda de National Intruments en internet.
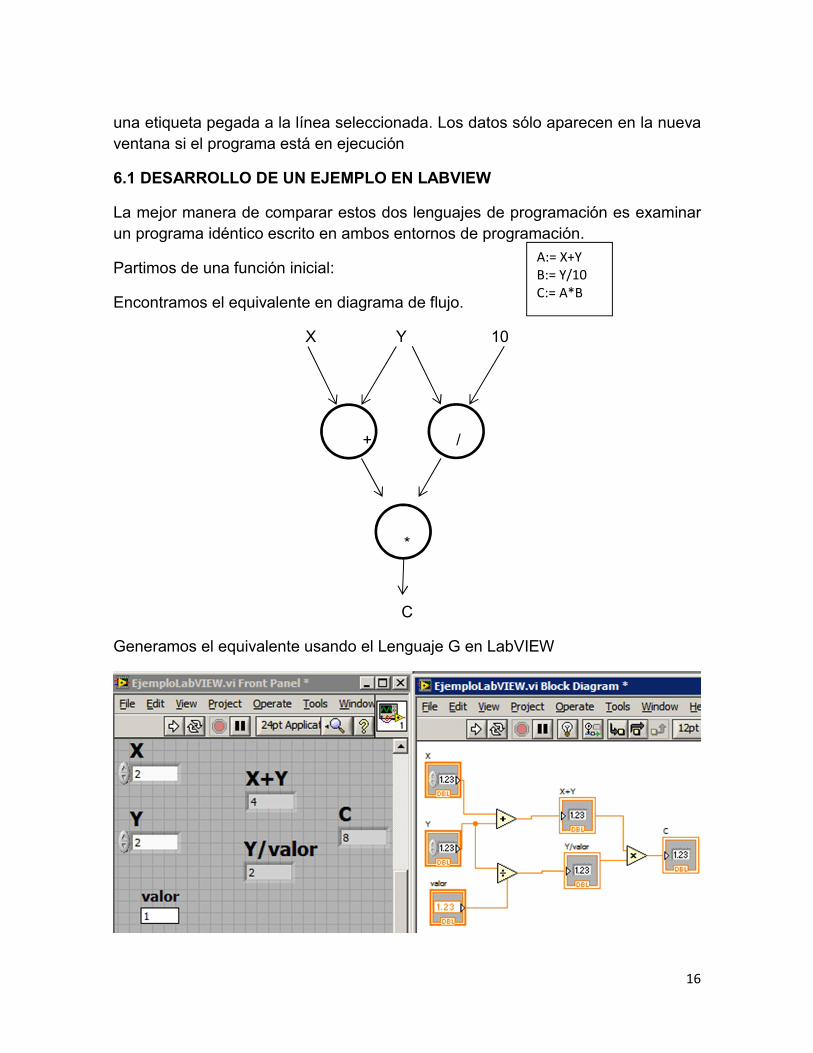
Para crear una prueba en LabVIEW, la herramienta de la prueba debe ser utilizada
para seleccionar una línea. Una nueva ventana aparecerá para mostrar los datos
que fluyen en la línea seleccionada. La etiqueta de la nueva ventana coincide con
16
una etiqueta pegada a la línea seleccionada. Los datos sólo aparecen en la nueva
ventana si el programa está en ejecución
6.1 DESARROLLO DE UN EJEMPLO EN LABVIEW
La mejor manera de comparar estos dos lenguajes de programación es examinar
un programa idéntico escrito en ambos entornos de programación.
Partimos de una función inicial:
Encontramos el equivalente en diagrama de flujo.
X Y 10
+ /
*
C
Generamos el equivalente usando el Lenguaje G en LabVIEW
A:= X+Y B:= Y/10 C:= A*B

17
7. AGILENT VEE
Al igual que LabVIEW se utilizan objetos gráficos, los cuales se utilizan para cuatro
funciones básicas:
1. Crear flujos de datos
2. Analizar flujos de datos
3. Tratar flujos de datos
4. Mostrar los resultados del flujo de datos
Los objetos en Agilent VEE son llamados funciones de usuario (User function)
Un PIN es un punto de una función que indica que una conexión puede hacerse
en esa ubicación.
Las líneas o arcos representan los datos y/ o pueden ser entradas a la función
del usuario o salida, también pueden ser utilizados para secuenciar la ejecución de
la función.
Los Bucles VEE se definen mediante objetos y pasadores de secuencia. Un
objeto de coleccionista se utiliza para recoger datos salientes en una matriz.
Estos objetos se seleccionan del panel de instrumentos con sólo hacer clic sobre
estos y se arrastran al área de trabajo

18
El color y el estilo de las líneas indican el tipo de datos representados por las
líneas.
Tipo de línea Dato Color Entero o Real Azul obscuro
Complejo Azul obscuro
Cadena Naranja
Secuencia de salida
Gris
Tipo de dato desconocido
Negro
Error Rojo
destacado Magenta
Bucles en VEE se expresan más de cerca al modelo de flujo de datos puros, es
decir, a través de ciclos en el gráfico. Sin embargo, el modelo ha sido aumentado
con un número de nodos adicionales a fin de simplificar la aparición de los ciclos.
En un bucle for, genera una serie de índices de un rango que están en la cola. El
programador no tiene que preocuparse por incrementar y retroalimentar la variable
de bucle, ser libre en lugar de concentrarse en los valores que se calculan. Un
bucle while se puede configurar mediante el uso de tres nodos relacionados.

19
El nodo until break activa repetidamente el gráfico que está conectado a, hasta
que el gráfico se activa un nodo break relacionado que detiene la repetición. En
lugar de datos que llegan en el nodo next, este desencadena la próxima iteración.
Para crear una prueba en Agilent VEE, la herramienta de la prueba debe ser
utilizada para seleccionar una línea. Una nueva ventana aparecerá para mostrar
los datos que fluyen en la línea seleccionada. La etiqueta de la nueva ventana
coincide con una etiqueta pegada a la línea seleccionada. Los datos sólo
aparecen en la nueva ventana si el programa está en ejecución, la diferencia
respecto a LabVIEW es qué no es necesario ejecutar el programa para hacer la
prueba

20
7.1 DESARROLLO DE UN EJEMPLO EN AGILENT VEE
La mejor manera de comparar estos dos lenguajes de programación es examinar
un programa idéntico escrito en ambos entornos de programación.
Partimos de una función inicial:
Encontramos el equivalente en diagrama de flujo.
X Y 10
+ /
*
C
Generamos el equivalente en Agilent VEE.
(a) muestra la función con bloques cerrados
A:= X+Y B:= Y/10 C:= A*B

21
(b) muestra la función con bloques abiertos
8. RESULTADOS
LabVIEW:Para llegar a cabo el programa fue necesario realizar cuatro iteraciones.
El programa soporta errores de tipo lógico (valor/0).

22
Agilent VEE:Para llegar a cabo el programa fue necesario realizar 6 iteraciones.
El programa no soporta errores de tipo lógico (valor/0) y aborta.
8.1 VENTAJAS DE LABVIEW
● Los objetos al ser bastante gráficos, sugieren al usuario su utilización durante el
desarrollo del programa, por lo que también ayuda a entender a personas ajenas
al proyecto, ya que con solo mirar las formas, colores y etiquetas sabrá cual es la
finalidad de cada parte del programa.
● Los tipos de datos de LabVIEW y las formas son muy similares a los tipos de
datos lenguaje de programación tradicionales
● El programa soporta errores de tipo lógico (valor/0).

23
8.2 VENTAJAS DE VEE
● Las funciones de usuario pueden cambiar las proporciones de tamaño gráfico
● Las funciones de usuario tienen dos vistas (cerrado y abierto)
● Las funciones tienen pasadores de secuencia: Un pasador en la parte superior
del objeto y uno en la parte inferior. Estas patillas se utilizan para el flujo de
ejecución de la secuencia y típicamente se usan sólo si el flujo de ejecución del
programa no puede seguir el flujo de datos o si hay flujo disponible para la
secuenciación hay datos.
● Los cables de unión entre las funciones convierten al tipo de dato qué es
necesario, evitando qué el programador se preocupe por esta tarea.
● Para realizar alguna extracción de datos de un arreglo sólo es necesario
especificar el tipo de dato qué se requiere.
● Las funciones de usuario se pueden colocar en el diagrama y cablear con datos,
pero pueden ser llamados desde un objeto fórmula o secuenciador.

24
8.3 INCONVENIENTES DE LABVIEW
● El detalle con los objetos es qué para cambiar el tamaño es necesario agregar
más entradas o salidas al mismo con el consecuente cambio en el flujo del
programa.
● Los objetos de LabVIEW no disponen de pines de secuencia. Los objetos se
secuenciaran por el flujo de datos y sí esto no es posible, entonces se utilizará un
sistema de ventana se requiere de múltiples capas.
● A pesar que los cables de unión entre nodos usan color para comunicar el tipo
de dato que llevan, este no convierte el a este tipo de dato, sólo es para fin
informativo.
● Programadores de LabVIEW necesitan utilizar objetos específicos para el tipo
de datos con los que trabajan y el tipo de extracción que quieren llevar a cabo. La
matriz o clúster junto con las constantes se debe conectar al objeto de extracción
para extraer los datos deseados
● Para llamar a un VI de LabVIEW que tiene que ser colocado en el diagrama de
cableado y con los datos
8.4 INCONVENIENTES DE VEE
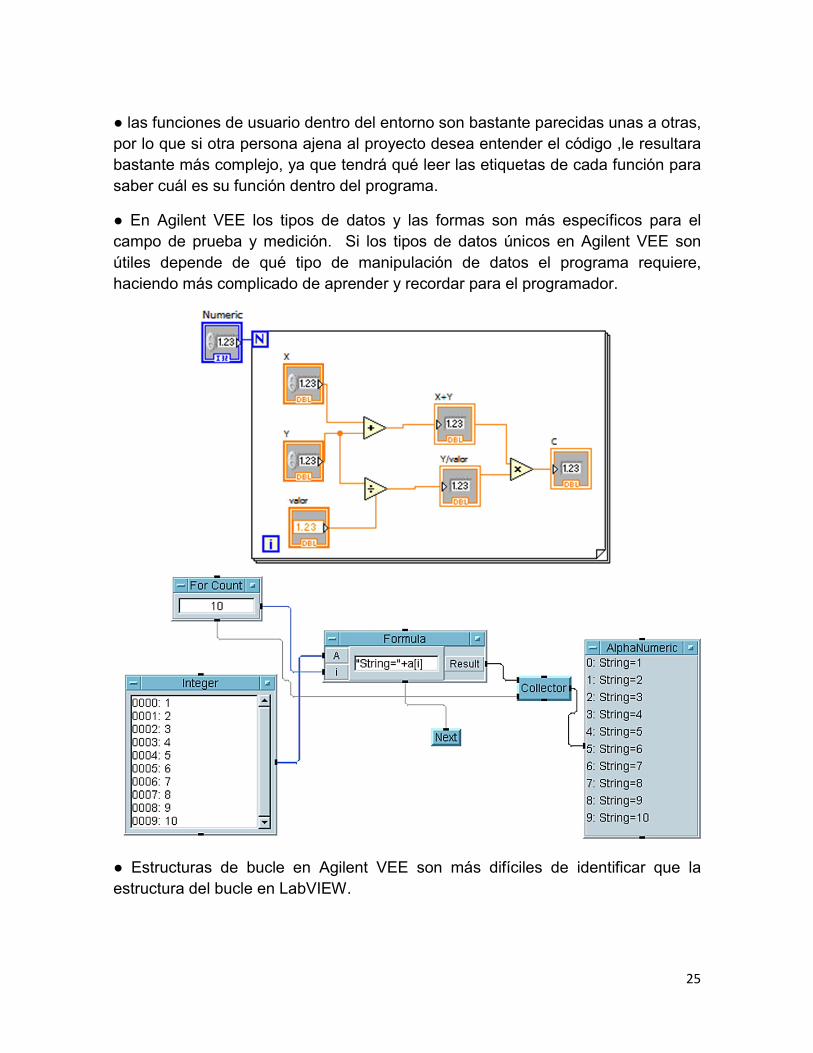
25
● las funciones de usuario dentro del entorno son bastante parecidas unas a otras,
por lo que si otra persona ajena al proyecto desea entender el código ,le resultara
bastante más complejo, ya que tendrá qué leer las etiquetas de cada función para
saber cuál es su función dentro del programa.
● En Agilent VEE los tipos de datos y las formas son más específicos para el
campo de prueba y medición. Si los tipos de datos únicos en Agilent VEE son
útiles depende de qué tipo de manipulación de datos el programa requiere,
haciendo más complicado de aprender y recordar para el programador.
● Estructuras de bucle en Agilent VEE son más difíciles de identificar que la
estructura del bucle en LabVIEW.

26
9. OPORTUNIDADES DE INVESTIGACIÓN
Es ampliamente aceptado que hay muchas aplicaciones que en realidad requieren
estados de no determinación. Se trata de sistemas que están operando
fundamentalmente en entornos no deterministas, como los sistemas de reserva y
sistemas de acceso a la base de datos.
Esto fue reconocido tempranamente en el desarrollo de flujo de datos. De manera
que se probó que el modelo era muy limitado, ya que podría producir programas
sólo deterministas.
La fusión no determinística parece ser capaz de resolver muchos de los problemas
asociados con la falta de la no determinación.
Semánticamente, es un nodo que tiene dos arcos de entrada y un arco de salida y
fusiones las dos corrientes en una forma completamente arbitraria. En la mayoría
de los casos, como una reserva sistema, esto es todo el no determinismo que se
requiere.
La ventaja de esto es que el no determinismo puede identificarse fácilmente.
Incluso es posible tener sub-programas no deterministas dentro de un gráfico que
en otro caso sería siempre determinado. Por lo tanto, puede ser posible aplicar los
principios matemáticos para el gráfico incluso si no tiene secciones no
deterministas.
La dicotomía en cuanto a no determinismo parece ser el resultado de una división
entre aquellos que desean utilizar el flujo de datos como un medio para facilitar la
prueba formal y el análisis de los programas y los que desean utilizar el flujo de
datos para todas las variedades de problemas de programación. Mientras que este
último requiere funciones no determinísticas como algo esencial. Además de tener
el inconveniente qué para realizar pruebas formales, las funciones no
determinísticos, hacen más engorroso el proceso de ingeniería de software al
hacer una depuración más difícil. Por lo tanto, la cuestión es cómo controlar con el
uso de sistemas híbridos en los programas de flujo de datos, sin perder nunca de
vista la prestación inicial de permitir al ingeniero de software escribir programas
utilizables de manera sencilla y rápida.
Otro de los puntos bastante importante es el desarrollo de representaciones para
estructuras de control en flujos de datos, así como su visualización de la
ejecución.

27
10. CONCLUSIONES
Los entornos basados en DFVPLs como LabVIEW y Agilent VEE permiten al
desarrollador proceder con el diseño e implementación de su propio orden, con lo
que el diseño es más libre y fácil en comparación con un lenguaje no gráfico.
En cuanto a la elección del programador de cuál es el mejor lenguaje o entorno de
comparación, de una de las cuestiones más complicadas de responder.
Lo qué se puede concretar es conocer ambas opciones y dependiendo de ese
conocimiento y del problema que se enfrente es lo que hará realizar la elección de
la forma más correcta, aunque se puede concluir que LabVIEW es el que cumple
de manera rigurosa el uso del paradigma de dataflow, mientras que Agilent VEE
utiliza un modelo hibrido de dataflow basado en diagramas de flujo y tablas de
decisión.
Para la gran mayoría de aplicaciones comerciales en la industria y en el ámbito de
investigación qué involucre adquisición de señales, comunicación análoga y
digital, el uso de este tipo de software para desarrollo de prototipos rápidos es
altamente recomendado, además qué ambos soportan Multithreading y Multi-core
para aumentar el rendimiento de la prueba, esto significa que el compilador
incorporado trabaja continuamente en segundo plano para identificar las secciones
paralelas de código. Siempre que el código G tiene alguna secuencia paralela de
nodos en el diagrama, el compilador intenta ejecutar el código en paralelo dentro
de un conjunto de hilos que LabVIEW maneja automáticamente.
En términos informáticos, esto se llama "paralelismo implícito" porque no es
necesario que el programador escriba código específicamente con el propósito de
ejecutarlo en paralelo; el lenguaje G se encarga de paralelismo por su cuenta.
En el caso de Multithreading en un sistema Multi-core, G puede proporcionar aún
mayor ejecución en paralelo mediante la ampliación de la programación gráfica
implementada para dispositivos FPGAs, estos son chips de silicio reprogramables
que trabajan de forma masiva en paralelo, con cada tarea de procesamiento
independiente asignado a una sección específica del chip sin estar limitados por el
número de núcleos de procesamiento disponibles. Como resultado, el rendimiento
de una parte de la aplicación no se ve afectada negativamente cuando se añade
más procesamiento.

28
Históricamente, la programación FPGA fue diseñada para un experto
especializado con un profundo conocimiento de hardware digital de lenguajes de
diseño.
Cada vez más, los ingenieros sin experiencia FPGA quieren utilizar hardware
personalizado basado en FPGA para la sincronización única y rutinas de
activación, el control de ultra alta velocidad, interfaz con protocolos digitales,
procesamiento de señal digital (DSP), RF y las comunicaciones, y muchas otras
aplicaciones que requieren alta velocidad confiabilidad del hardware, la
personalización, y el determinismo apretado. G es especialmente adecuado para
la programación FPGA, ya que representa claramente el paralelismo y el flujo de
datos y está creciendo rápidamente en popularidad como una herramienta de
elección para los desarrolladores que buscan el procesamiento paralelo y
ejecución determinista.
Ambos entornos permiten combinar el lenguaje G con otros basados en texto.
La Formula Node en LabVIEW es un cómodo nodo, basado en texto que se puede
utilizar para realizar operaciones matemáticas complicadas en un diagrama de
bloques utilizando la sintaxis de C ++.
29
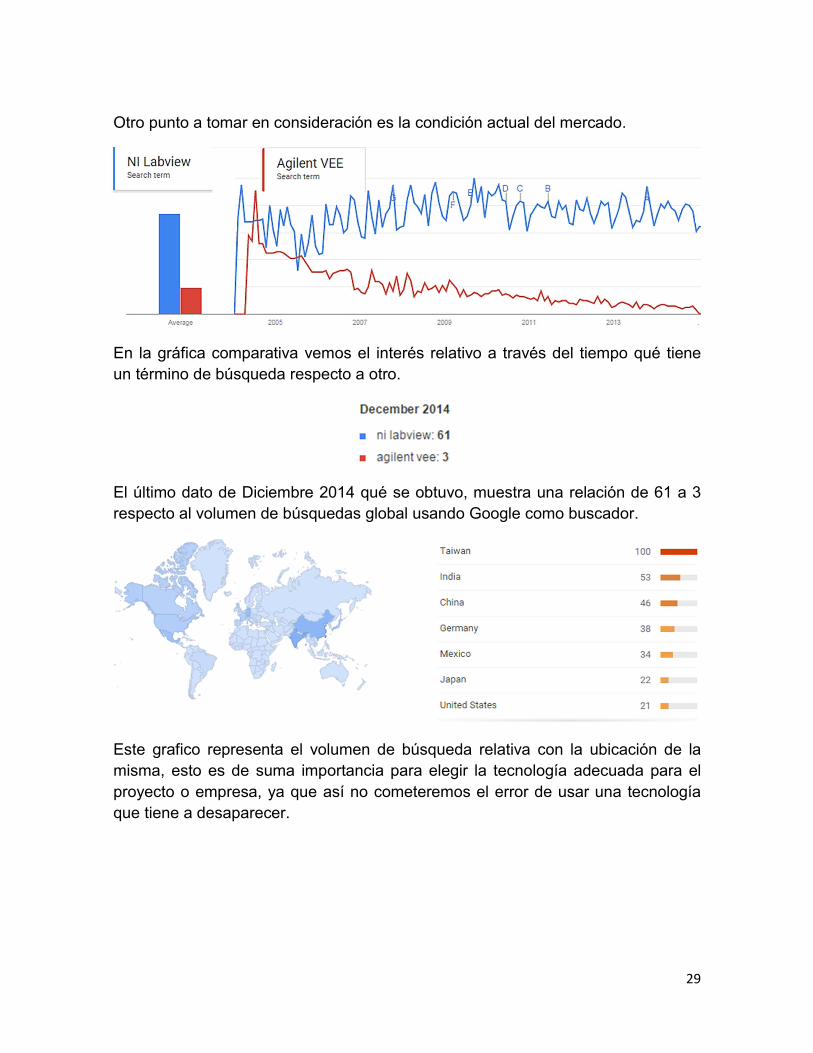
Otro punto a tomar en consideración es la condición actual del mercado.
En la gráfica comparativa vemos el interés relativo a través del tiempo qué tiene
un término de búsqueda respecto a otro.
El último dato de Diciembre 2014 qué se obtuvo, muestra una relación de 61 a 3
respecto al volumen de búsquedas global usando Google como buscador.
Este grafico representa el volumen de búsqueda relativa con la ubicación de la
misma, esto es de suma importancia para elegir la tecnología adecuada para el
proyecto o empresa, ya que así no cometeremos el error de usar una tecnología
que tiene a desaparecer.

30
En el caso de Agilent VEE, de manera relativa sólo dos países muestran el interés
por el producto, esto puede causar una alerta a la hora de elegir un producto.
11. FUENTES Y BIBLIOGRAFIA
[1] Johnston, Wesley M.; Hanna, J. R. Paul.; Millar, Richard J.:” Advances in
dataflow programming languages”. ACM Computing Surveys, 2004.
[2] Alonso, F.; Lara, J. A.; Lizcano, D.; Martínez, L.: "Paradigmas de
Programación". Administración Digital, 2013.
[3] Klaus Erik Schauser, David E. Culler, Thorsten von Eicken.:” Compiler-Controlled
Multithreading for Lenient Parallel Languages”. Computer Science Division- Electrical
Engineering and Computer Science- University of California, Berkeley.1991.
[4] Alan L. Davis, Robert M. Keller.;” Data Flow Program Graphs”. IEEE Computer Society
Computer (Volume: 15 , Issue: 2 );1982
[5] Bruce Elliott.: “Cuiting your test development time with HP VEE, an iconic programming
language” .Hewlett-Packard Professional Books.1994
[6] Agilent Technologies.:” VEE Advanced Techniques”. Manual.2004