
Autonomic Computing - Dataflow Programming and Reactive State Machines
19
AUTONOMIC COMPUTING MEETUP MARCH 6, 2017 LOS ANGELES
-
Upload
peter-lee -
Category
Data & Analytics
-
view
102 -
download
0
Transcript of Autonomic Computing - Dataflow Programming and Reactive State Machines

AUTONOMIC COMPUTING MEETUP MARCH 6, 2017
LOS ANGELES

DATAFLOW PROGRAMMING AND REACTIVE STATE MACHINES
Peter Lee @ Corenova Technologies
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017

INTELLIGENCE IS THE ABILITY TO ADAPT TO CHANGE. Stephen Hawking

WHAT IS AN AUTONOMIC SYSTEM?
▸ An approach to enable systems to manage themselves without direct human intervention
▸ Inspired by human autonomic nervous system which controls important bodily functions without conscious intervention
▸ A methodology for reducing the complexity of maintaining distributed systems
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
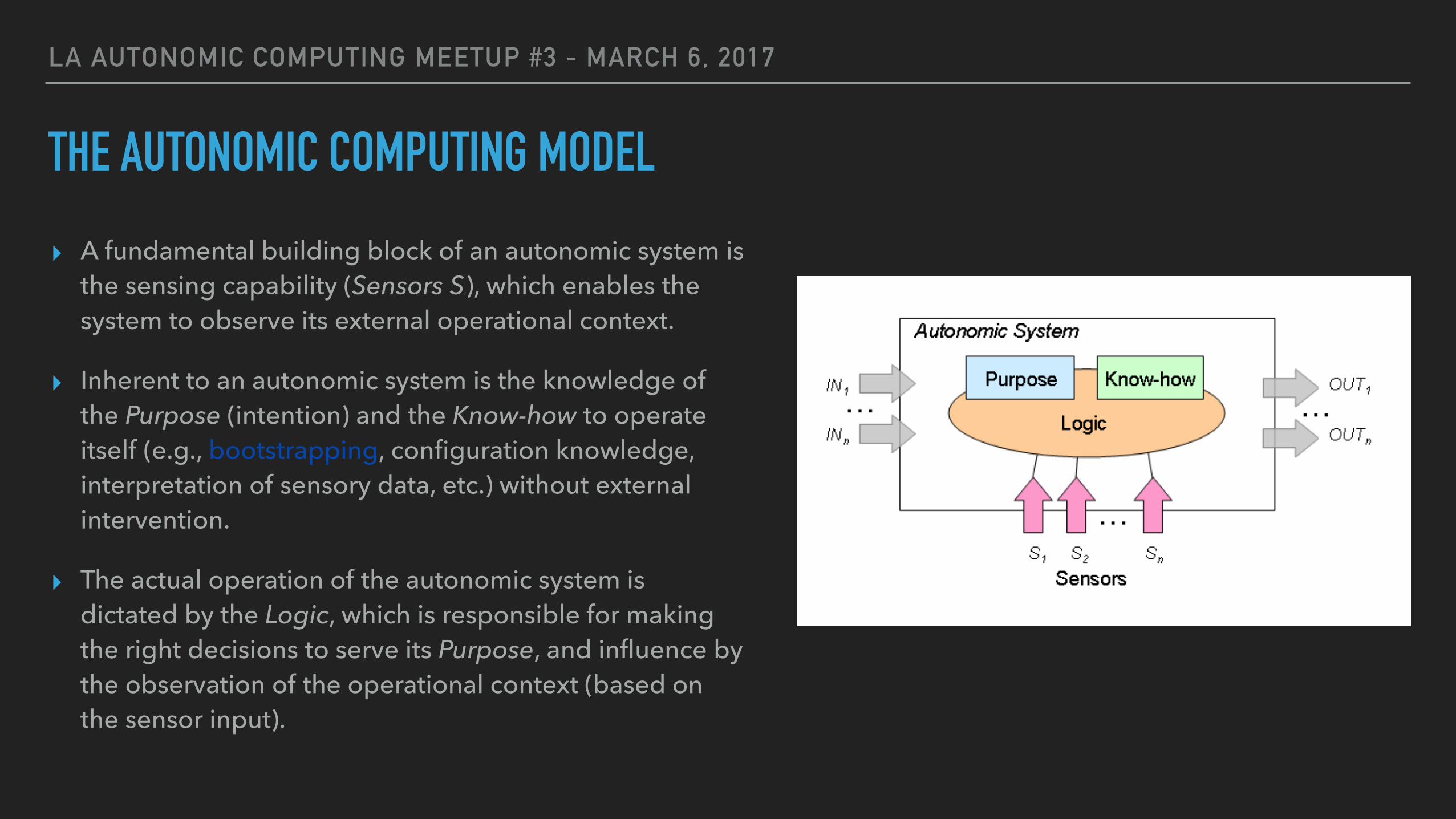
THE AUTONOMIC COMPUTING MODEL
▸ A fundamental building block of an autonomic system is the sensing capability (Sensors Si), which enables the system to observe its external operational context.
▸ Inherent to an autonomic system is the knowledge of the Purpose (intention) and the Know-how to operate itself (e.g., bootstrapping, configuration knowledge, interpretation of sensory data, etc.) without external intervention.
▸ The actual operation of the autonomic system is dictated by the Logic, which is responsible for making the right decisions to serve its Purpose, and influence by the observation of the operational context (based on the sensor input).
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017

WHAT IS DATAFLOW PROGRAMMING?
▸ A programming paradigm that models a program as a directed graph of the data flowing between operations, thus implementing dataflow principles and architecture.
▸ Emphasizes the movement of data and models programs as a series of connections. Explicitly defined inputs and outputs connect operations, which function like black boxes. An operation runs as soon as all of its inputs become valid. Thus, dataflow languages are inherently parallel and can work well in large, decentralized systems.
▸ Dataflow Programming - Concept, Languages and Applications
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017

BASIC DATAFLOW MODELS
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
OUTPUT BINPUT A f
OUTPUT DINPUT B
fINPUT C
INPUT D fOUTPUT E
OUTPUT F
REACTOR FUNCTIONS
ONE-TO-ONE
MANY-TO-ONE
ONE-TO-MANY
INPUT Ff
INPUT G
OUTPUT H
OUTPUT IMANY-TO-MANY

IMPERATIVE VS. DATAFLOW PROGRAMMING
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
MODULE/SUPERAGENT
HTTP/REQUEST/GET/URLHTTP/RESPONSE
REQUIRE f
var request = require(“superagent”); request.get(“http://www.google.com") request.end((err, response) => { // logic to deal with response })
f
IMPERATIVE JAVASCRIPT CODE
require “superagent" http/request/get/url “http://www.google.com"
DATAFLOW TRIGGERS
synchronous, must return expected module
asynchronous, must supply callback function asynchronous, sequence of
triggers doesn’t matter

IMPERATIVE EXAMPLE: REACTING TO ENVIRONMENT
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
try { var request = require(“superagent”); makeRequest(request, “http://www.google.com") } catch (err) { var npm = require(“npm”); npm.load({}, (err, loaded) => { npm.install(“superagent”, (err, installed) => { // deal with error, otherwise continue let request = require(“superagent”) makeRequest(request, “http://www.google.com") } }) }
IMPERATIVE JAVASCRIPT CODE
function makeRequest(request, url) { request.get(url) request.end((err, response) => { // logic to deal with response }) }
nested async callbacks, still need to deal with errors at each level
break out common function to deal with
multiple entry points for execution
Logic to deal with missing library dependency, “superagent”

DATAFLOW EXAMPLE: REACTING TO ENVIRONMENT
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
require “npm” require “superagent” http/request/get/url “http://www.google.com"
DATAFLOW TRIGGERS
MODULE/NPM
NPM/INSTALL
REQUIRE
MODULE/SUPERAGENT
HTTP/REQUEST/GET/URLHTTP/RESPONSEf
f f
NPM/INSTALLEDf
NPM/LOADED
additional dataflow to support NPM workflows

WHAT IS A DATA PIPELINE?
▸ In computing, a pipeline is a set of data processing elements connected in series, where the output of one element is the input of the next one.
▸ Software pipelines, where commands can be written where the output of one operation is automatically fed to the next, following operation. The Unix system call pipe is a classic example of this concept, although other operating systems do support pipes as well.
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017

TRADITIONAL DATA PIPELINE
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
FORMAT BFORMAT A f FORMAT Cf
▸ All data chunks of format A runs through a processing node (which internally buffers incoming/outgoing chunks) and generates stream of format B chunks
▸ All data chunks of format B then runs through another processing node which generates a stream of format C chunks
▸ You can create a sequence of transforms to achieve desired final outcome

DATAFLOW PIPELINE
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
OUTPUT BINPUT A
OUTPUT Cf
f OUTPUT EINPUT C
OUTPUT FINPUT D
f
INPUT F OUTPUT D
INPUT B
f
CIRCULAR FEEDBACK FLOW!
INPUT OUTPUT

DISTRIBUTED DATAFLOW PIPELINE: MICRO-SERVICES
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
OUTPUT BINPUT A
OUTPUT Cf
f OUTPUT EINPUT C
OUTPUT FINPUT D
fINPUT B
ANY DATA f SOCKET ANY DATAfSOCKET
▸ You can build data pipelines across any instance of the Flow running anywhere!
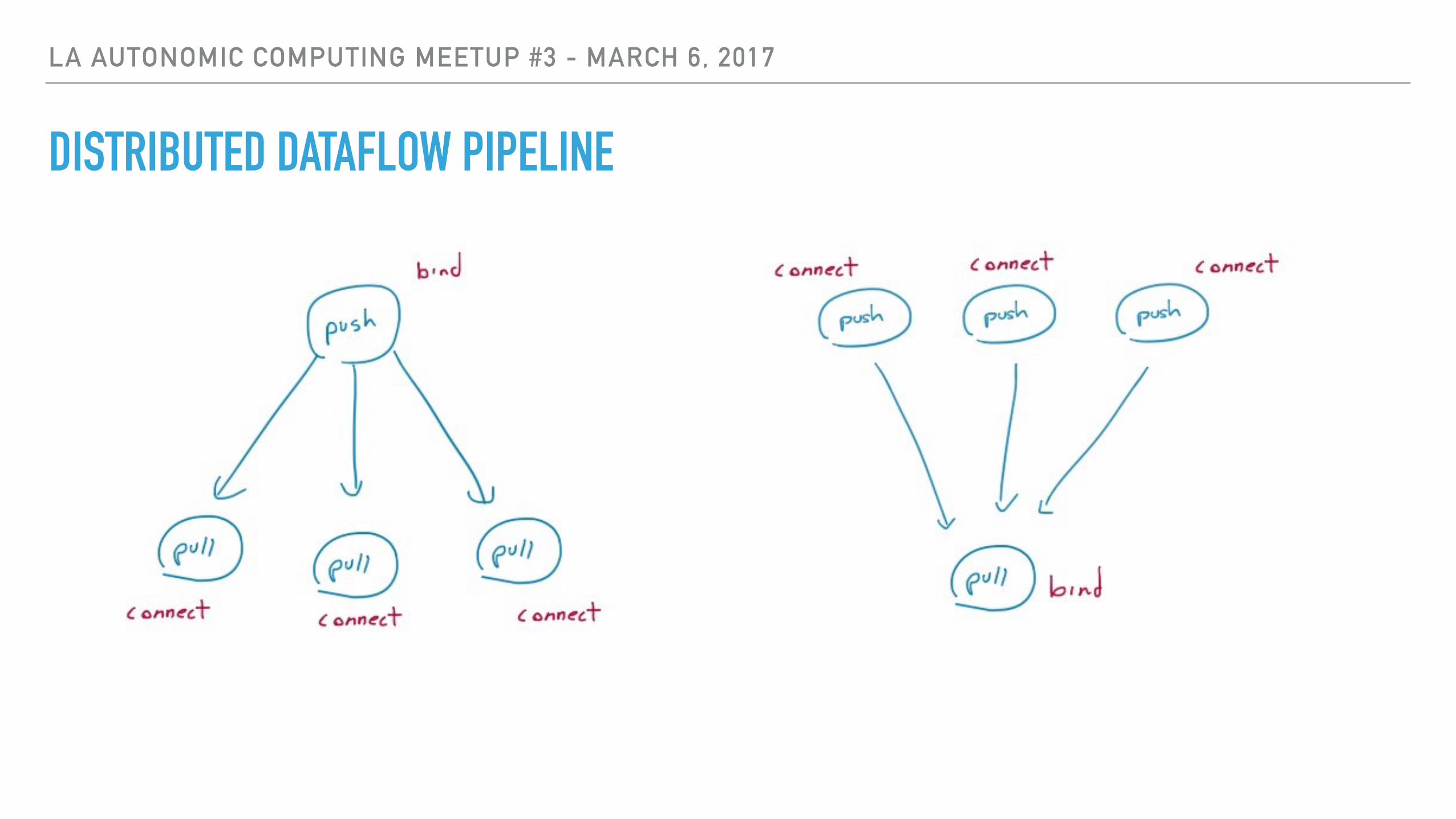
DISTRIBUTED DATAFLOW PIPELINE
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017

CREATIVITY IS JUST CONNECTING THINGS.
Steve Jobs

KOS: A DATAFLOW STREAMING FRAMEWORK FOR CREATING AWESOME DATA PIPELINES
LA AUTONOMIC COMPUTING MEETUP #3 - MARCH 6, 2017
▸ JavaScript (Node.js and the web browser)
▸ Open-Source License
▸ https://github.com/corenova/kos

LET’S CONNECT THINGS!

THANKS FOR COMING!
SEE YOU NEXT TIME
LA Autonomic Computing Meetup


















![Reactive Behavior in Object-oriented Applications: An ... · [Functional reactive animation, Elliott and Hudak. IFP ’97] •More recently: –FrTime [Embedding dynamic dataflow](https://static.fdocuments.net/doc/165x107/5ece27e2f6bb9c0f493019cf/reactive-behavior-in-object-oriented-applications-an-functional-reactive-animation.jpg)