
Using Fault Model Enforcement (FME) to Improve Availability EASY ’02 Workshop Kiran Nagaraja,...
25
Using Fault Model Enforcement (FME) to Improve Availability EASY ’02 Workshop Kiran Nagaraja, Ricardo Bianchini, Richard Martin, Thu Nguyen Department of Computer Science Rutgers University
-
date post
22-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of Using Fault Model Enforcement (FME) to Improve Availability EASY ’02 Workshop Kiran Nagaraja,...

Using Fault Model Enforcement (FME) to Improve Availability
EASY ’02 Workshop
Kiran Nagaraja, Ricardo Bianchini,Richard Martin, Thu Nguyen
Department of Computer ScienceRutgers University

Motivation
Network services are extremely complex Typically many software and hardware
components Numerous fault points and types
E.g, nodes, disks, cables, links, switches, etc.
Extremely difficult for services to tolerate all these faults Hard to reason about all possible faults Difficult to determine actual fault
Many faults exhibit same runtime symptoms

FME Approach
Define a reduced abstract fault model Components, faults, symptoms, component behavior
during faults
Enforce this fault model at run-time If an “unexpected” fault occurs, map to one that was
planned for in the abstract model “If the facts don’t fit the theory, change the facts.”
- Albert Einstein
Allow designer to concentrate on tolerating a well-defined, yet limited in complexity, set of faults

Our Study
Estimate potential impact of FME Have not yet implemented FME
Case study: PRESS cluster-based web server PRESS has simple abstract fault model In companion study, only achieve around three 9’s
Study hypothetical improvement if FME was used to enforce PRESS’s abstract fault model
FME can reduce the unavailability by up to 50%

Outline
FME in more detail Evaluation methodology PRESS web server Availability study Related work Conclusions Future directions

Fault Model Enforcement (FME)
Enforce a reduced fault model at runtime Allow service to perform correct recovery action to
regain full functionality
How to enforce a reduced fault model? Two ideas so far
Map an unexpected fault to an expected fault E.g., crash a node if the network link connecting it to the switch fails
Fail outer component if sub-component fails E.g., crash a node if the disk fails
How is it different from fail-stop ? Allows reasoning about failures at a desired abstraction

Evaluation Methodology
Want to evaluate FME’s potential impact Two phase methodology
Phase I - Single fault injection analysis Define and inject faults on “live” system Monitor system performance (throughput T) and
availability(A) = fraction of successful requests
Phase II - Use an analytical model to determine performability
Computes average availability and average throughput

Case Study: PRESS Web Server
Cluster-based, locality-conscious web server Serve requests out of global memory pool Exclusion from pool lower performance
Simple fault model Connection failure/lost heartbeats = node failure Recovery through rejoin of “new” node
Several versions developed over time TCP, VIA Different fault detection mechanism
Heart-beat for TCP Connection breaks for VIA

Fault Set
Fault LoadLink downSwitch downSCSI timeoutNode crashNode freezeApplication crashApplication hang
All faults are modeled as fail-stop

PRESS with FME
Recovery upon fault model mismatch Restart 0, 1 or all nodes?
FME approach: reboot the appropriate node after a fault and its recovery have occurred Link down – reboot unreachable node Switch down – reboot all nodes Disk failure – reboot node with faulty disk Node, application crash – do nothing

Single-Fault Experiments
Setup: 4 PC cluster running at 90% load
3 versions: TCP, TCP-HB, VIA
Use results to evaluate impact of FME

Single Fault - ResultsLink Failure
Application Hang

Modeling – Seven Stage Model
Input: measured throughput and availability Parameters: MTTF, MTTR, operator on site time Output: average availability & average throughput

Modeling Availability
Assumptions: Effects of faults are independent Fault arrivals are exponential
Overall unavailability = ΣT(unavailability of all faults)

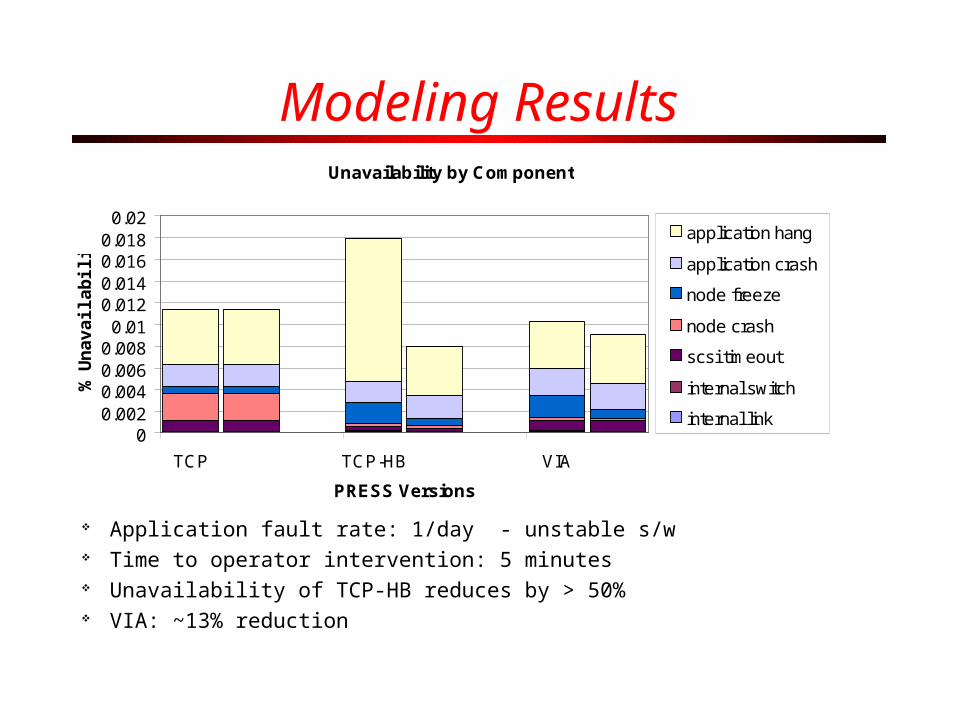
Modeling Results
Application fault rate: 1/month Time to operator intervention: 5 minutes Unavailability of TCP-HB reduced by ~50% VIA: ~36% reduction
Unavailability by Component
00.0005
0.0010.0015
0.0020.0025
0.0030.0035
0.0040.0045
0.005
TCP TCP-HB VIA
PRESS Versions
% U
na
va
ilab
ility
application hang
application crash
node freeze
node crash
scsi timeout
internal switch
internal link
Modeling Results
Application fault rate: 1/day - unstable s/w Time to operator intervention: 5 minutes Unavailability of TCP-HB reduces by > 50% VIA: ~13% reduction
Unavailability by Component
00.0020.0040.0060.008
0.010.0120.0140.0160.018
0.02
TCP TCP-HB VIA
PRESS Versions
% U
na
va
ilab
ility
application hang
application crash
node freeze
node crash
scsi timeout
internal switch
internal link

Related Work
Enforcing fail-stop Tandem Non-Stop – process pairs
Robust design with rigorous internal assertions
Fault detection and fail-over HA-Linux
Reactive and proactive rejuvenation Recursive restartability(ROC) – Berkeley & Stanford Software rejuvenation – Duke

Conclusion
FME allows for very simple fault models
FME can cut the unavailability by up to 50%
Fault detection mechanism is crucial for effectiveness Benefits increase with fault coverage

FME - Future Directions
How extensive should the fault model be? Determines programming complexity/effort
How to prevent FME from reducing availability? Bugs within enforcement? When to declare a symptom a fault?
FME reduces human intervention Are humans better at deciding?
8-23 % of recovery procedures are botched [Brown 2001]

Thank you.
http://www.panic-lab.rutgers.edu/Projects/vivo

Communication Architecture
All operations by main thread are non-blocking
Separate send, receive and multiple disk helper threads
Filling up of queues could stall the entire node

Performability
Model computes 2 metrics: Average throughput (AT) Average Availability (AA)
PerformabilityP = Tn x log(AI)
log(AA) AI : Availability of Ideal system with 99.999 Log scale ratio allows a linear relationship
with unavailability

Experiments: Single-Fault Loads
4 800Mhz PIII PCs, 206MB, 2x10000 SCSI disks, 1Gb/s cLan interconnect (TCP or VIA)
PRESS: 128MB file cache, static content Clients: constant rate ~ 90% server
capacity Modified sclient [Banga 97] Rutgers trace; file size = avg. request size

Mendosus – Fault Injection
Central Controller
Fast & Reliable SAN
Node A Node B
Events
Kernel
User-Level
SCSI
Process Ctrl
Daemon
MlibApplications E.g. PRESS
emulation
n/w faults
n/w stack
comLib glibc sys_calls
Node/OS

Phase II – Modeling Performability
5 minutes duration for operator intervention(E) and restart(F) stages
Fault MTTF MTTRLink down 6 months 3
minutes
Switch down 1 year 1 hour
SCSI timeout 1 year 1 hour
Node crash 2 weeks 3 minutes
Node freeze 2 weeks 3 minutes
Application Crash 2 months 3 minutes
Application Hang 2 months 3 minutes


















