

Engineering\CADD Systems Office CADD Manager's Series Customizing the Interface.
Upload
yana-valasatavaCategory
view
44download
1
Apache Spark is a fast and general engine for large-‐scale data processing • In-‐memory processing Successor of Hadoop (MapReduce) • File-‐based processing
hDp://spark.apache.org/
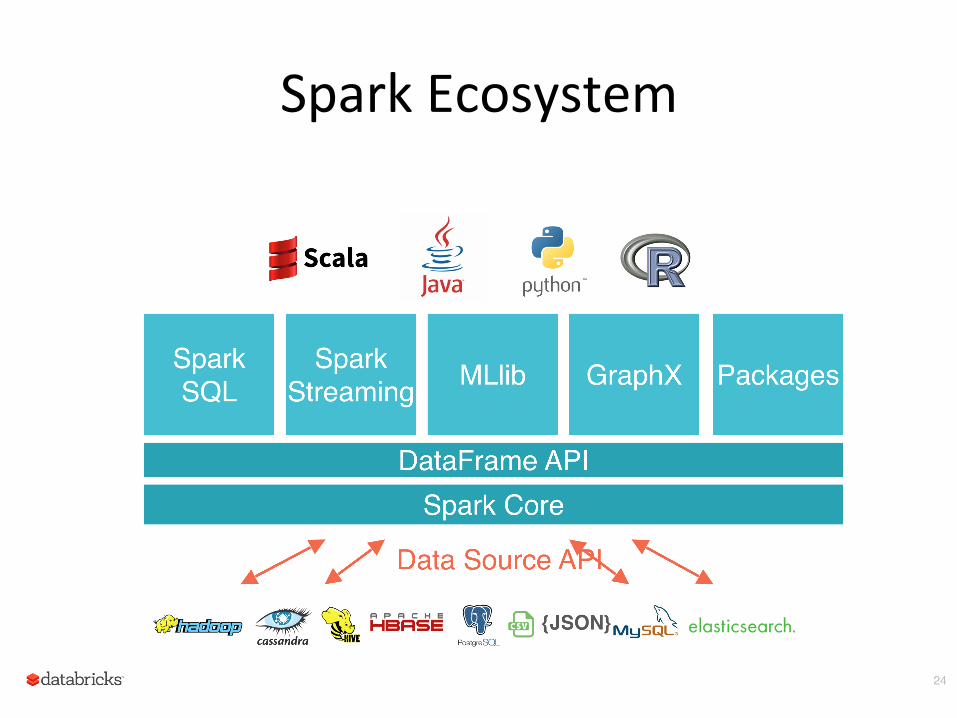
Spark Ecosystem
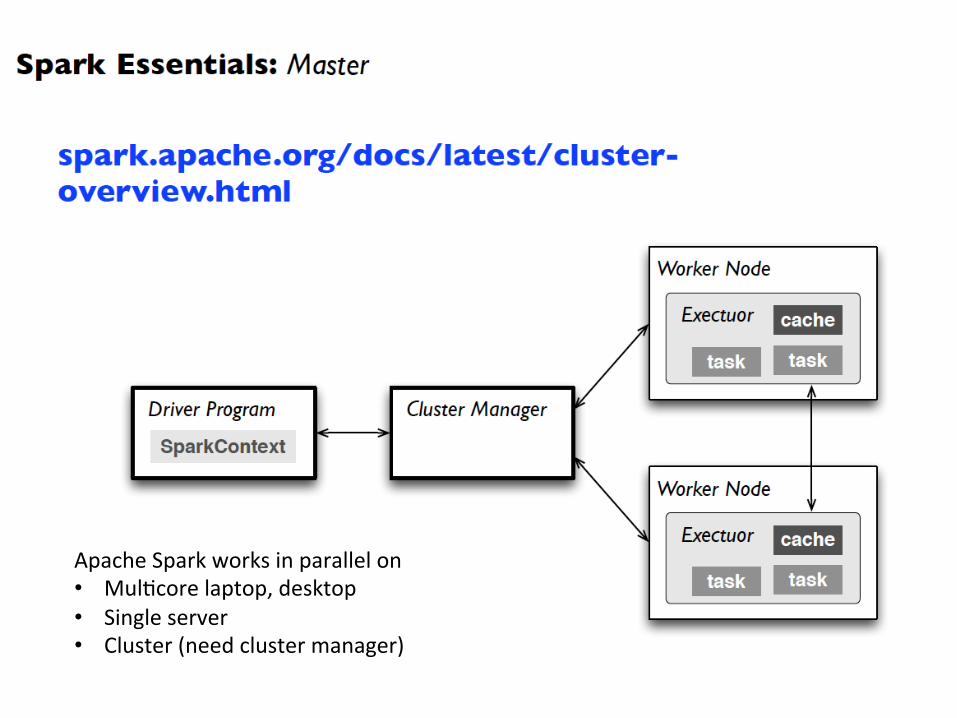
Apache Spark works in parallel on • Mul)core laptop, desktop • Single server • Cluster (need cluster manager)

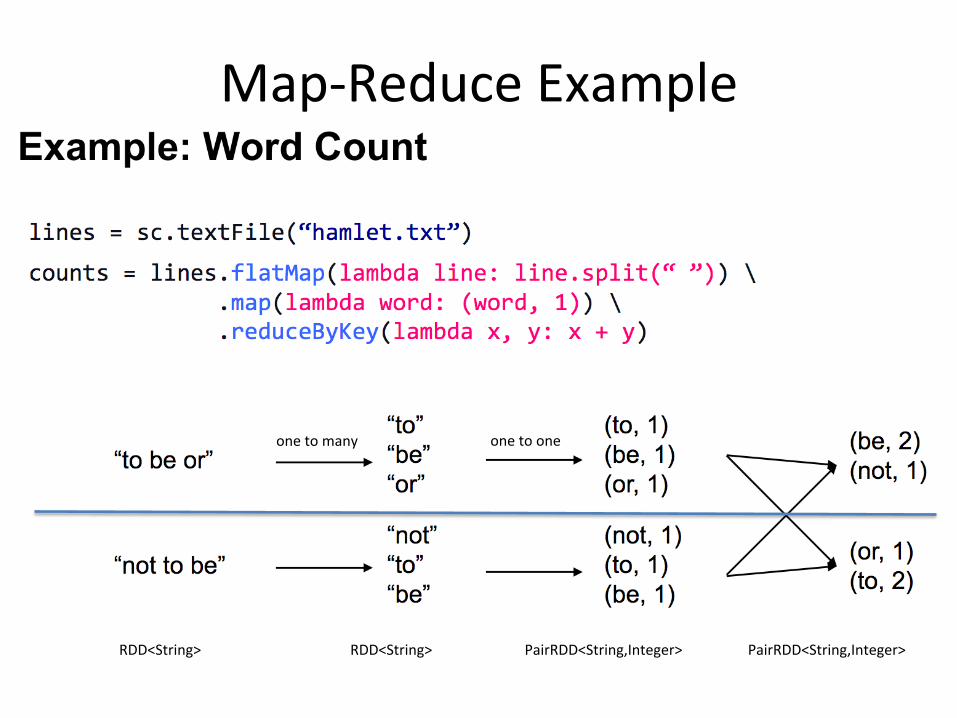
RDD<String> RDD<String> PairRDD<String,Integer> PairRDD<String,Integer>
Map-‐Reduce Example
one to many one to one
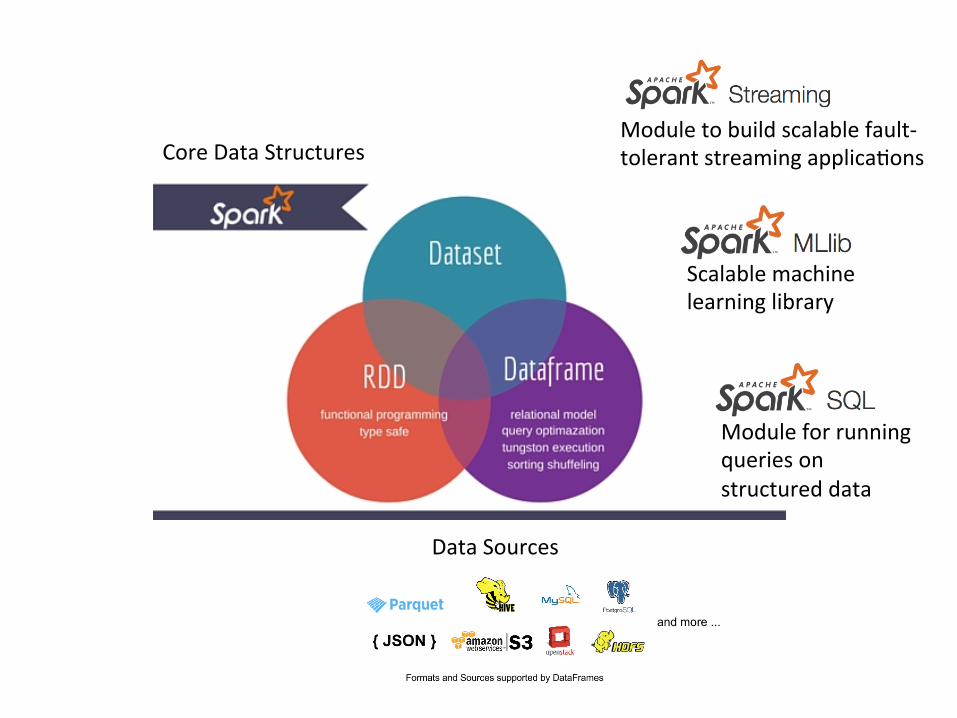
Scalable machine learning library
Module for running queries on structured data
Data Sources
Module to build scalable fault-‐tolerant streaming applica)ons Core Data Structures


















