
Research Article On-Chip Power Minimization Using...
15
Research Article On-Chip Power Minimization Using Serialization-Widening with Frequent Value Encoding Khader Mohammad, 1 Ahsan Kabeer, 2 and Tarek Taha 3 1 Birzeit University, P.O. Box 14, Birzeit, West Bank, Palestine 2 Clemson University, Clemson, SC 29634, USA 3 University of Dayton, Dayton, OH 45469, USA Correspondence should be addressed to Khader Mohammad; [email protected] Received 19 January 2014; Accepted 2 April 2014; Published 6 May 2014 Academic Editor: Qiaoyan Yu Copyright © 2014 Khader Mohammad et al. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. In chip-multiprocessors (CMP) architecture, the L2 cache is shared by the L1 cache of each processor core, resulting in a high volume of diverse data transfer through the L1-L2 cache bus. High-performance CMP and SoC systems have a significant amount of data transfer between the on-chip L2 cache and the L3 cache of off-chip memory through the power expensive off-chip memory bus. is paper addresses the problem of the high-power consumption of the on-chip data buses, exploring a framework for memory data bus power consumption minimization approach. A comprehensive analysis of the existing bus power minimization approaches is provided based on the performance, power, and area overhead consideration. A novel approaches for reducing the power consumption for the on-chip bus is introduced. In particular, a serialization-widening (SW) of data bus with frequent value encoding (FVE), called the SWE approach, is proposed as the best power savings approach for the on-chip cache data bus. e experimental results show that the SWE approach with FVE can achieve approximately 54% power savings over the conventional bus for multicore applications using a 64-bit wide data bus in 45 nm technology. 1. Introduction ere is a need for high-performance, high-end products to reduce their power consumption. e high-performance systems require complex design and a large power budget having considerable temperature impact to integrate several powerful components. erefore, low energy consumption is a major design criterion in today’s design. Low energy consumption improves battery longevity and reliability, and a reduction in energy consumption lowers both the packaging and overall system costs [1]. As the technology scaling down the power consumption is also decreasing and results in more sensitivity to soſt errors so reliability would be affected. ere are tradeoffs between power consumption and reliability in different ways. In future work overall reliability will be discussed and it will be evaluated how it can be improved by reducing the power consumption. e primary goal of this research is for bus power minimization by reducing the switching activity while at the same time improving bus bandwidth for the compression technique and reducing the bus capacitance for the SW approach. e goal is similar to using switching activity and capacitance reduction in bus power savings; the key difference between the prior work and the work presented here is that the primary focus of this work is to explore a framework for bus power minimization approaches from an architectural point of view. As a result, this paper presents a comprehensive analysis of most of the possible bus power minimization approaches for the on-chip. is research explores a framework for power minimization approaches for an on-chip memory bus from an architectural point of view. It also considers the impact of coupling capacitance for estimating the on-chip bus power consumption. Finally this paper proposes a serialized-widened bus with frequent value encoding (FVE) as the best power savings approach for the on-chip (L1-L2 cache) data bus. e organization of the rest of the paper is as follows. Section 2 presents background. Section 3 presents framework Hindawi Publishing Corporation VLSI Design Volume 2014, Article ID 801241, 14 pages http://dx.doi.org/10.1155/2014/801241
Transcript of Research Article On-Chip Power Minimization Using...

Research ArticleOn-Chip Power Minimization Using Serialization-Wideningwith Frequent Value Encoding
Khader Mohammad1 Ahsan Kabeer2 and Tarek Taha3
1 Birzeit University PO Box 14 Birzeit West Bank Palestine2 Clemson University Clemson SC 29634 USA3University of Dayton Dayton OH 45469 USA
Correspondence should be addressed to Khader Mohammad hajkhadergmailcom
Received 19 January 2014 Accepted 2 April 2014 Published 6 May 2014
Academic Editor Qiaoyan Yu
Copyright copy 2014 Khader Mohammad et al This is an open access article distributed under the Creative Commons AttributionLicense which permits unrestricted use distribution and reproduction in any medium provided the original work is properlycited
In chip-multiprocessors (CMP) architecture the L2 cache is shared by the L1 cache of each processor core resulting in a highvolume of diverse data transfer through the L1-L2 cache bus High-performance CMP and SoC systems have a significant amountof data transfer between the on-chip L2 cache and the L3 cache of off-chip memory through the power expensive off-chip memorybus This paper addresses the problem of the high-power consumption of the on-chip data buses exploring a framework formemory data bus power consumption minimization approach A comprehensive analysis of the existing bus power minimizationapproaches is provided based on the performance power and area overhead consideration A novel approaches for reducing thepower consumption for the on-chip bus is introduced In particular a serialization-widening (SW) of data bus with frequent valueencoding (FVE) called the SWE approach is proposed as the best power savings approach for the on-chip cache data bus Theexperimental results show that the SWE approach with FVE can achieve approximately 54 power savings over the conventionalbus for multicore applications using a 64-bit wide data bus in 45 nm technology
1 Introduction
There is a need for high-performance high-end productsto reduce their power consumption The high-performancesystems require complex design and a large power budgethaving considerable temperature impact to integrate severalpowerful components Therefore low energy consumptionis a major design criterion in todayrsquos design Low energyconsumption improves battery longevity and reliability and areduction in energy consumption lowers both the packagingand overall system costs [1] As the technology scaling downthe power consumption is also decreasing and results inmoresensitivity to soft errors so reliability would be affectedThereare tradeoffs between power consumption and reliabilityin different ways In future work overall reliability will bediscussed and it will be evaluated how it can be improved byreducing the power consumption
The primary goal of this research is for bus powerminimization by reducing the switching activity while at the
same time improving bus bandwidth for the compressiontechnique and reducing the bus capacitance for the SWapproach The goal is similar to using switching activityand capacitance reduction in bus power savings the keydifference between the prior work and the work presentedhere is that the primary focus of this work is to explore aframework for bus power minimization approaches from anarchitectural point of view As a result this paper presentsa comprehensive analysis of most of the possible bus powerminimization approaches for the on-chip This researchexplores a framework for power minimization approachesfor an on-chip memory bus from an architectural point ofview It also considers the impact of coupling capacitance forestimating the on-chip bus power consumption Finally thispaper proposes a serialized-widened bus with frequent valueencoding (FVE) as the best power savings approach for theon-chip (L1-L2 cache) data bus
The organization of the rest of the paper is as followsSection 2 presents background Section 3 presents framework
Hindawi Publishing CorporationVLSI DesignVolume 2014 Article ID 801241 14 pageshttpdxdoiorg1011552014801241
2 VLSI Design
Wire 1
Wire 2
Load capacitance CL
Load capacitance CL
Coupling capacitance CC
Figure 1 Load capacitance of a wire and coupling capacitancebetween the wires
and proposed on-chip bus power model a frameworkfor bus power minimization approaches and their efficacySection 4 present experiment setup followed by Section 5which presents the experiment results a thorough compar-ison of the proposed technique with the other approaches
2 Background
Memory bus power minimization techniques can be cat-egorized as bus serialization [2ndash4] encoding [5ndash8] andcompression techniques [9ndash14] Non-cache-based encodingtechniques reduce power by reordering the bus signals Busserialization reduces the number of wire lines eventuallyreducing the area overheadA serialized-widened bus reducesthe capacitance of on-chip interconnections Cache-basedencoding techniques reduce the number of switching transi-tions using encoded hot-codeThese techniques keep track ofsome of the previous transmitted data using a small cache onboth sides of the data bus Compression techniques reducethe number of wire lines contributing a reduction on inarea overhead and an increase in the bus bandwidth Thesecompression techniques also reduce the switching activitySerialization changes the data ordering transmitted throughthe data bus This method contributes to reducing theswitching activity as well It may also improve the chance ofdatamatching by incorporating it with cache-based encodingtechniques because partial data matching is three times morefrequent than full-length data matching [7]
Jacob andCuppu [3] explored the dynamic randomaccessmemory (DRAM) system and memory bus organization interms of performance presenting design tradeoffs for thebank channel bandwidth and burst size They also mea-sured the performance in relation to optimize the memorybandwidth and bus width Suresh et al [7] presented a databus transmit protocol called the power protocol to reduce thedynamic power dissipation of off-chip data buses Hatta et al[2] proposed the concept of bus serialization-widening (SW)to reduce wire capacitance their work focused on the powerminimization of the on-chip cache address and data bus Liet al [15] proposed reordering the bus transactions to reducethe off-chip bus power
In this chapter we present on-chip bus power model aframework for bus powerminimization approaches and theirefficacyWe also discuss in detail the proposed technique andpresent a thorough comparison of our proposed technique tothe possible approaches from power savings stand point
The general equation of the bus power calculation is givenas follows
119875 = 1205721198911198821198621198812
119863119863 (1)
where 120572 is the switching activity 119891 is the frequency of thebus 119882 is the number of parallel data bus lines 119862 is thetotal capacitance of the bus and 119881
119863119863is the swing voltage
The capacitance 119862 of (1) can be divided into two parts asload capacitance 119862
119871which is the parasitic capacitance to
substrate with a constant potential and coupling capacitance119862119862which is the parasitic capacitance between the adjacent
lines (see Figure 1) In a deep submicron technology thetotal capacitance no longer only depends on load capacitanceof the wire Coupling capacitance between the wires is alarge factor as coupling capacitance is some order of loadcapacitance of the wire line [16ndash20]
The total capacitance is the sum of the load capacitanceand coupling capacitance and it can be expressed as119862 = 119862
119871+
2119862119862[2 16 21ndash23] The equation of the power consumption
calculation of the conventional bus line will be
119875119862= (120572119862119871119862119862119871+ 120572119862119862119862119862119862) 1198911198621198821198621198812
119863119863 (2)
where 120572119862119871
is the signal transition switching activity 119862119862119871
isthe load capacitance120572
119862119862is the coupling transitions switching
activity and119862119862119862
is the coupling capacitance between the con-ventional bus lines The signal transition switching activity[2 22] is given by
120572119862119871= 0 if data transition from 0 997888rarr 0 or 1 997888rarr lowast1 if data transition from 0 997888rarr 1
(3)
The coupling switching activity [2 22] depends on thetransitions activity between two adjacent bus lines as follows
120572119862119862=
0 if wire 1 transition 0 997888rarr 1 andwire 2 transition 0 997888rarr 11 if wire 1 transition 0 997888rarr 1 and
wire 2 transition 0 997888rarr 01 if wire 1 transition 0 997888rarr 1 and
wire 2 transition 1 997888rarr 12 if wire 1 transition 0 997888rarr 1 and
wire 2 transition 1 997888rarr 0
(4)
Two of the main approaches to minimize the power con-sumption of a bus are to reduce the bus switching activity andthe bus wire capacitance Switching activity can be reducedthrough encoding techniques while the wire capacitance canbe reduced by changing the wire width and spacing
21 Bus Serialization and Widening Bus serializationinvolves reducing the number of wires on the bus If thenumber of transmission lines in a conventional bus isNC and the serialization factor is S then the number oftransmission of lines in the serialized version of the bus isgiven by NS = NCS The serialization factor can be any
VLSI Design 3
Table 1 Serialization may increase or decrease switching activityParts (a) and (b) illustrate two different 16-bit data streams passingthrough a conventional 8-bit bus and a serialized 4-bit bus Inexample (a) switching activity decreases while in (b) it increases
(a) 16-bit data streamrarr 0011 0011 0011 0011
Passingthrough 8-bitbusrarr
Datasequence Signal Coupling
0000 0000 mdash mdash0011 0011 4 30011 0011 0 0
Total numberof transitions 4 3
Passingthrough 4-bitbusrarr
Datasequence Signal Coupling
0000 mdash mdash0011 2 10011 0 00011 0 00011 0 0
Total numberof transitions 2 1
(b) 16-bit data streamrarr 0011 1100 0011 1100
Passingthrough - bitbusrarr
Datasequence Signal Coupling
0000 0000 mdash mdash0011 1100 4 20011 1100 0 0
Total numberof transitions 4 2
Passingthrough 4bit-busrarr
Datasequence Signal Coupling
0000 mdash mdash0011 2 11100 2 20011 2 21100 2 2
Total numberof transitions 8 7
integer multiple of 2 The throughput of a bus serializedby a factor of two is halved To prevent a reduction in thethroughput the bus frequency can be doubled This requiresthe increasing of the wire widths to support higher switchingspeedsThe advantage of serialization is that the bus occupiesless area than a conventional bus Serialization on its ownmay not necessarily reduce the switching activity and thusthe energy consumption of a bus (see Table 1) Loghi et al[5] examined the use of bus serialization combined with dataencoding for power minimization In this case the bus area
L1cache
L2cachet
Serializer Deserializer
Driver
NCNCNSNS
Figure 2 Basic structure and position of serializer and deserializer
Serialization = 2
Conventional bus Serialized-wider bus
WS
DS
WC
DC
Figure 3 Basic structure of conventional and serialized bus lines
was smaller but the throughput of the bus was halved (sincethe frequency remained the same)
In a deep submicron technology the switching energyconsumed due to coupling capacitance is dominant [1617 24ndash26] The disadvantage of bus widening is that thebus occupies more area than a conventional bus Hattaet al [2] looked at combining bus serialization with buswidening in order to reduce bus power without increasingthe bus area In that study the bus frequency was increasedto keep the throughput constant Although this requiredincreasing the width of the wires the extra spacing betweenthe wires allowed this to be accommodated without a busarea overhead Hatta et al [2] also looked at combining aserialized-widened bus with differential data encoding andfound that it helped on the address bus but not on the databus
In a serialized-widened bus the operating frequencycan be increased to keep the throughput the same as in aconventional bus In this case the serialized frequency isgiven by fS = S sdot fC where S is the serialization factorand fC is the frequency of the conventional bus In order toimplement bus serialization at a higher frequency a serializerand deserializer are required at the sending and receivingends of the bus respectively (as shown in Figure 2)
Figure 3 shows the structure of data lines of a con-ventional bus and those of a serialized-widened bus Therelationship of the wire width and spacing between the wiresof a conventional bus and a serialized-widened bus is
WS + DS = (WC + DC) S (5)
where WC is the wire width of the conventional bus DC iswire spacing between the lines in the conventional bus WS isthe wire width of a serialized-widened bus DS is wire spacingbetween the lines in the serialized-widened bus and S is theserialization factor
4 VLSI Design
Table 2 Comparison of possible approaches to reduce on-chip data bus power
Approach Bus freq Switching activity Line cap Bus area1 C (conventional) f 120572C CC Original bus area2 S (serial) 2f 120572S CS Reduced3 W (widened) f 120572C CW At least double4 E (encoded) f 120572E CC Unchanged5 SW 2f 120572S CSW Unchanged6 SE 2f 120572SE CS Reduced7 WE f 120572E CW At least double8 SWE 2f 120572SE CSW Unchanged
CC
CL
Metal 1
Metal 2
Metal 3
Figure 4 Line-to-line and crossover capacitance of a multilevelmetal layer
The width WC is different from the width WS to allow ahigher frequency Since the wire widths have to be changedto accommodate the higher operating frequency the loadcapacitance of the bus wires (given in (5)) will change Inaddition the increase in wire spacing changes the cross-coupling capacitanceThus the power consumption of the busis given by
119875S = (120572SL119862SL + 120572SC119862SC) 119891S119882S1198812
119863119863 (6)
where 120572SL is the signal transition switching activity 120572SC is thecoupling switching activity 119862SL is the load capacitance and119862SC is the coupling capacitance of the serialized-widened busFigure 4 shows the capacitance values in a multilevel metallayer The wire configurations values are taken from ITRS2004 Update [27] and those values are used in the Chernet al [23] equations to calculate the capacitance values Thefrequency of the bus is given by the Kawaguchi and Sakurai[28] equation1
119891asymp (163 sdot
119862119862
119862119862+ 119862119871
+ 037) sdot 119877 sdot (119862119862+ 119862119871) (7)
Here 119877 is the resistance of the wire given by its width 119882thickness 119879 and rate of resistance 120572 (dependent on materialproperty)
Consider
119877 =120572
119882119879 (8)
Equations (7) and (8) can be used to determine the optimumwire width for the serialized-widened bus at the higherfrequency
3 Framework and Proposed Technique
The three fundamental approaches discussed earlier in thissection to reduce bus power are serialization (S) encoding(E) and widening (W) of the bus Combinations of theseapproaches are also possible and in fact yield better resultsTable 2 lists the possible types of buses based on these threeapproaches and their combinations (the first of which is aconventional bus (C) not employing any of the approaches)These approaches reduce the power through changes in theswitching activity and the line capacitance of the bus
Table 2 lists the relation between the switching activityand the line capacitance of the different approaches Italso lists the change in bus area and frequency due to theapproaches Two other important methods to reduce buspower are variations in the swing voltage and operating fre-quency These two techniques can be applied in conjunctionwith all of the methods listed in Table 2 The frameworkshown in Table 2 can be used to categorize many of theapproaches used to minimize the bus switching activity andwire capacitance The encoding techniques proposed in [12ndash23 27ndash47] fall under the category E listed in the table Thenarrow bus encoding technique presented by Loghi et al [5]falls under the category SE while Hattarsquos serialized-widenedbus [2] falls under the category SW
There are four unique capacitance values and switchingactivities listed in Table 2 The relation between these capac-itance values can generally be described as CW lt CSW ltCS lt CC If the serialized bus is running at a higherfrequency to preserve the bus throughput the wires andtheir spacing may have to be widened thus possibly reducingtheir capacitance CS from the original bus value CC Inthe widened bus the wires spacing is increased making thistype of bus having the lowest wire capacitance Howeverthere is a significant bus area overhead in this approachThe serialized-widened bus running at a higher frequency topreserve the throughput will have slightly less wire spacingthan the widened bus since the wires will have to be madewider for the higher frequency Thus the capacitance of thisbus CSW will be more than that of the widened bus CW but
VLSI Design 5
Table 3 Architectural configuration of the simulator used in theexperiment
System ParametersNumber of processor cores 2 4 8Super scalar width 4 out-of-orderL1 instruction cache 163264KB direct-mapped 1-cycleL1 data cache 163264KB 4-way 1-cycleL1 block size 32 BShared L2 cache 1MB 4-way unified 12-cycleL2 block size 64 BRUULSQ 168Memory ports 2TLB 128-entries 4-way 30-cycleMemory latency 96-cycleMemory bus width 1248 B
still less than the serialized bus CS (since the wires are morespaced out than a serialized bus)
The relation between the switching activities is highlydependent on the data values passed on the bus Thereforea strict relation between the switching activities cannot beshown However in general it can be expected that anencoded bus will have less switching than a conventional bus(hence 120572E lt 120572C) In addition the serialized-encoded bus(SE) will also likely have a lower switching activity than aconventional bus (hence120572SE lt 120572C)The relation between theswitching activity of a serialized bus (120572S) and a conventionalbus (120572C) is hard to predict
This paper proposes data bus power reduction techniquesfor the SWE approachThis work compares these approacheswith existing power reduction methods that fall under thedifferent categories in Table 2 This work finds that the SWEapproach works best since this method reduces both the wirecapacitance and the switching activity significantly
4 Experimental Setup
This section discusses the target systemof the experiment andthe memory structure used to collect the memory tracesThefirst subsection describes the architecture of sim-outorderthe superscalar simulator from the Simplescalar tool suite[48] In the subsection followed we discusses the benchmarkssuite and the input sets that are used in this paper In thelast part of this section we present the switching activitycomputation methodology
41 Simulator This experiment uses a modified version ofSimplescalar 30drsquos sim-outorder simulator [48] to collectour cache request traces The model architecture has mid-range configuration Table 3 summarizes the architecturalconfiguration of our simulator The baseline configurationparameters are typical those of a modern chip multiproces-sors and out-of-order simulatorThis work keeps the L1 cachesize smaller to get morememory access which results inmoreaccurate behavior of memory access and memory bus This
Table 4 Benchmarks types and number of warm up instructionsused in the experiment
Benchmarks Type Warm up instructionsgzip (pro) Int 2000Mgzip (src) Int 1400MWupwise FP 2000MGcc Int 2000MMesa FP 700MArt FP 2000MMcf Int 1000Mbzip2 (pro) Int 2000Mbzip2 (src) Int 2000MTwolf Int 900Mmpeg2d MB 0MGsm MB 0Mmpeg2e MB 0M
work develops another simulator written in program C tocalculate the switching activity for the bus power estimation
42 Benchmark Suites This experiment uses 6 integers and3 floating point benchmarks from SPEC2000 suite [49] and3 benchmarks from MediaBench suite [47] This selection ismotivated by finding somememory intensive programs (mcfart gcc gzip and twolf) [3] and some memory nonintensiveprogramsThe simulation wants to use reference inputs of theSPEC2000 suite because of having smaller data sets of testor training inputs For each of the benchmark of SPEC2000suite this work divides the total run length by 5 and warmup for the first 3 portions with a maximum of 2 billioninstructions using fast-forward mode cycle-level simulationA 200 million instruction window is simulated using thedetailed simulator ForMediaBench suite this work simulatesthe whole program to generate the required traces withoutany fast forwarding Table 3 lists the reference inputs thatare chosen from the SPEC2000 benchmark and MediaBenchsuite and the number of instructions for which the simulatoris warmed up Among these benchmarks a group of bench-marks are selected to run in multicore processor units qs inTable 4This selection gives importance to group thememoryintensive programs to get more accurate behavior of memoryaccess than to groupmemory nonintensive programs Table 5summarizes the list of benchmarks used for 8 4 and 2 coresprocessing units
43 Switching Activity Computation Apower simulatorwrit-ten in C is integrated with the modified Simplescalar sim-outorder simulator [48] to calculate the switching activity ofthe data transitions between L1 and L2 cache through L1-L2 cache bus The simulator has several functionalities forcalculating the switching activity for all six different kinds ofencoding techniques listed in Table 6
During serialization-widening the simulator uses twosets of value cache (VC) for LSB and MSB data matchinginstead of using one unified VC Figure 5 shows the different
6 VLSI Design
Table 5 Combination of benchmarks used for multiprocessingcores
Number of cores Set Name of benchmarks
8
1mcf art gcc twolfmpeg2d gzip (pro) mesabzip2 (pro)
2gzip (src) mcf gcc gsmwupwise mpeg2e artbzip2 (src)
4
1 mcf art mpeg2e gzip (pro)2 twolf bzip2 (pro) mesa art
3 gcc gzip (src) bzip2 (src)gsm
21 mcf art2 gcc twolf
Table 6 Listing of different encoding techniques implemented inthis experiment
Name AbbreviationBus-invert coding biTransition signaling xorFrequent value encoding with one hot-code FvFrequent value encoding with two hot-code fv2TUBE with one hot-code TubeTUBE with two hot-code tube2
structures of two sets of VC with serialization The databus size is varied frequently to compare the effectivenessof different possible approaches and encoding techniqueskeeping the total amount of data the same For example ifa data stream of 64-bit wide requires 1 transition using 64-bitwide data bus it requires 8 transitions using 8-bit wide databus
5 Results and Analysis
This section presents the experimental results It has ageneral comparison of the cache bus power minimizationusing the seven possible approaches listed in Table 2 Itfurther examines in detail three of the approaches that donot change the bus area and finds that the SWE approachperforms the best It also presents an in depth analysis ofthe SWE approach performance under various architectureand technology configurations At the end of this section wediscuss the performance power and area overhead for theproposed technique
51 Power Savings for Different Possible Approaches Theseven possible bus power savings approaches listed in Table 2earlier are different combinations of serialization (S) buswidening (W) and encoding (E) Figure 6 shows the powersavings on the L1-L2 cache data bus for the differentarchitecture-benchmark combinations listed in Table 5 usingthese approaches A 64-bit data bus implemented on 45 nmtechnology is assumed The techniques reduce bus power by
L1 L2cache
Serializer DeserializerDriver
NCNC NSNS
LSBVC
LSBVC
Externalcontrol line
NS MSBVC
MSBVC
cache
Figure 5 Structure of 2 sets of value cache combined withserialization
minus30
minus15
0
15
30
45
60
75
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
SWESW
SEWESWE
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 6 Comparison of the of power savings using the differentdata bus power reduction approaches Results are compared to aconventional 64-bit L1-L2 cache data bus at 45 nm technology
minimizing bus switching activity bus wire capacitance orboth
When the three approaches for power reduction areapplied on their own bus widening performs the best Theserialization (S) approach performs poorly for most of thearchitecture configurations listed in Figure 6 (the bus poweris generally increased) This is primarily due to the fact thatserialization generally increases switching activity The buscapacitance is actually reduced partially since the wires arespaced out further to allow the frequency to be doubledHowever this reduction in capacitance is not enough to offsetthe increased switching activity The widening (W) approachperforms very well since it reduces the bus wire capacitancesignificantly The disadvantage of the approach is that italmost doubles the bus area There are six different encodingtechniques (E) that are tested (seeTable 6) Figure 6 shows theresult from the best encoding technique for each architectureconfiguration Encoding reduces switching activity withoutaffecting the bus capacitance and so does minimizing thebus power This approach does not change the bus area orfrequency
When using combinations of the three approaches theserialized-widened-encoded (SWE) method performs thebest The serialized-widened (SW) approach reduces the buscapacitance by widening the wire spacing but generallyincreases the switching activity through serializationThe net
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

2 VLSI Design
Wire 1
Wire 2
Load capacitance CL
Load capacitance CL
Coupling capacitance CC
Figure 1 Load capacitance of a wire and coupling capacitancebetween the wires
and proposed on-chip bus power model a frameworkfor bus power minimization approaches and their efficacySection 4 present experiment setup followed by Section 5which presents the experiment results a thorough compar-ison of the proposed technique with the other approaches
2 Background
Memory bus power minimization techniques can be cat-egorized as bus serialization [2ndash4] encoding [5ndash8] andcompression techniques [9ndash14] Non-cache-based encodingtechniques reduce power by reordering the bus signals Busserialization reduces the number of wire lines eventuallyreducing the area overheadA serialized-widened bus reducesthe capacitance of on-chip interconnections Cache-basedencoding techniques reduce the number of switching transi-tions using encoded hot-codeThese techniques keep track ofsome of the previous transmitted data using a small cache onboth sides of the data bus Compression techniques reducethe number of wire lines contributing a reduction on inarea overhead and an increase in the bus bandwidth Thesecompression techniques also reduce the switching activitySerialization changes the data ordering transmitted throughthe data bus This method contributes to reducing theswitching activity as well It may also improve the chance ofdatamatching by incorporating it with cache-based encodingtechniques because partial data matching is three times morefrequent than full-length data matching [7]
Jacob andCuppu [3] explored the dynamic randomaccessmemory (DRAM) system and memory bus organization interms of performance presenting design tradeoffs for thebank channel bandwidth and burst size They also mea-sured the performance in relation to optimize the memorybandwidth and bus width Suresh et al [7] presented a databus transmit protocol called the power protocol to reduce thedynamic power dissipation of off-chip data buses Hatta et al[2] proposed the concept of bus serialization-widening (SW)to reduce wire capacitance their work focused on the powerminimization of the on-chip cache address and data bus Liet al [15] proposed reordering the bus transactions to reducethe off-chip bus power
In this chapter we present on-chip bus power model aframework for bus powerminimization approaches and theirefficacyWe also discuss in detail the proposed technique andpresent a thorough comparison of our proposed technique tothe possible approaches from power savings stand point
The general equation of the bus power calculation is givenas follows
119875 = 1205721198911198821198621198812
119863119863 (1)
where 120572 is the switching activity 119891 is the frequency of thebus 119882 is the number of parallel data bus lines 119862 is thetotal capacitance of the bus and 119881
119863119863is the swing voltage
The capacitance 119862 of (1) can be divided into two parts asload capacitance 119862
119871which is the parasitic capacitance to
substrate with a constant potential and coupling capacitance119862119862which is the parasitic capacitance between the adjacent
lines (see Figure 1) In a deep submicron technology thetotal capacitance no longer only depends on load capacitanceof the wire Coupling capacitance between the wires is alarge factor as coupling capacitance is some order of loadcapacitance of the wire line [16ndash20]
The total capacitance is the sum of the load capacitanceand coupling capacitance and it can be expressed as119862 = 119862
119871+
2119862119862[2 16 21ndash23] The equation of the power consumption
calculation of the conventional bus line will be
119875119862= (120572119862119871119862119862119871+ 120572119862119862119862119862119862) 1198911198621198821198621198812
119863119863 (2)
where 120572119862119871
is the signal transition switching activity 119862119862119871
isthe load capacitance120572
119862119862is the coupling transitions switching
activity and119862119862119862
is the coupling capacitance between the con-ventional bus lines The signal transition switching activity[2 22] is given by
120572119862119871= 0 if data transition from 0 997888rarr 0 or 1 997888rarr lowast1 if data transition from 0 997888rarr 1
(3)
The coupling switching activity [2 22] depends on thetransitions activity between two adjacent bus lines as follows
120572119862119862=
0 if wire 1 transition 0 997888rarr 1 andwire 2 transition 0 997888rarr 11 if wire 1 transition 0 997888rarr 1 and
wire 2 transition 0 997888rarr 01 if wire 1 transition 0 997888rarr 1 and
wire 2 transition 1 997888rarr 12 if wire 1 transition 0 997888rarr 1 and
wire 2 transition 1 997888rarr 0
(4)
Two of the main approaches to minimize the power con-sumption of a bus are to reduce the bus switching activity andthe bus wire capacitance Switching activity can be reducedthrough encoding techniques while the wire capacitance canbe reduced by changing the wire width and spacing
21 Bus Serialization and Widening Bus serializationinvolves reducing the number of wires on the bus If thenumber of transmission lines in a conventional bus isNC and the serialization factor is S then the number oftransmission of lines in the serialized version of the bus isgiven by NS = NCS The serialization factor can be any
VLSI Design 3
Table 1 Serialization may increase or decrease switching activityParts (a) and (b) illustrate two different 16-bit data streams passingthrough a conventional 8-bit bus and a serialized 4-bit bus Inexample (a) switching activity decreases while in (b) it increases
(a) 16-bit data streamrarr 0011 0011 0011 0011
Passingthrough 8-bitbusrarr
Datasequence Signal Coupling
0000 0000 mdash mdash0011 0011 4 30011 0011 0 0
Total numberof transitions 4 3
Passingthrough 4-bitbusrarr
Datasequence Signal Coupling
0000 mdash mdash0011 2 10011 0 00011 0 00011 0 0
Total numberof transitions 2 1
(b) 16-bit data streamrarr 0011 1100 0011 1100
Passingthrough - bitbusrarr
Datasequence Signal Coupling
0000 0000 mdash mdash0011 1100 4 20011 1100 0 0
Total numberof transitions 4 2
Passingthrough 4bit-busrarr
Datasequence Signal Coupling
0000 mdash mdash0011 2 11100 2 20011 2 21100 2 2
Total numberof transitions 8 7
integer multiple of 2 The throughput of a bus serializedby a factor of two is halved To prevent a reduction in thethroughput the bus frequency can be doubled This requiresthe increasing of the wire widths to support higher switchingspeedsThe advantage of serialization is that the bus occupiesless area than a conventional bus Serialization on its ownmay not necessarily reduce the switching activity and thusthe energy consumption of a bus (see Table 1) Loghi et al[5] examined the use of bus serialization combined with dataencoding for power minimization In this case the bus area
L1cache
L2cachet
Serializer Deserializer
Driver
NCNCNSNS
Figure 2 Basic structure and position of serializer and deserializer
Serialization = 2
Conventional bus Serialized-wider bus
WS
DS
WC
DC
Figure 3 Basic structure of conventional and serialized bus lines
was smaller but the throughput of the bus was halved (sincethe frequency remained the same)
In a deep submicron technology the switching energyconsumed due to coupling capacitance is dominant [1617 24ndash26] The disadvantage of bus widening is that thebus occupies more area than a conventional bus Hattaet al [2] looked at combining bus serialization with buswidening in order to reduce bus power without increasingthe bus area In that study the bus frequency was increasedto keep the throughput constant Although this requiredincreasing the width of the wires the extra spacing betweenthe wires allowed this to be accommodated without a busarea overhead Hatta et al [2] also looked at combining aserialized-widened bus with differential data encoding andfound that it helped on the address bus but not on the databus
In a serialized-widened bus the operating frequencycan be increased to keep the throughput the same as in aconventional bus In this case the serialized frequency isgiven by fS = S sdot fC where S is the serialization factorand fC is the frequency of the conventional bus In order toimplement bus serialization at a higher frequency a serializerand deserializer are required at the sending and receivingends of the bus respectively (as shown in Figure 2)
Figure 3 shows the structure of data lines of a con-ventional bus and those of a serialized-widened bus Therelationship of the wire width and spacing between the wiresof a conventional bus and a serialized-widened bus is
WS + DS = (WC + DC) S (5)
where WC is the wire width of the conventional bus DC iswire spacing between the lines in the conventional bus WS isthe wire width of a serialized-widened bus DS is wire spacingbetween the lines in the serialized-widened bus and S is theserialization factor
4 VLSI Design
Table 2 Comparison of possible approaches to reduce on-chip data bus power
Approach Bus freq Switching activity Line cap Bus area1 C (conventional) f 120572C CC Original bus area2 S (serial) 2f 120572S CS Reduced3 W (widened) f 120572C CW At least double4 E (encoded) f 120572E CC Unchanged5 SW 2f 120572S CSW Unchanged6 SE 2f 120572SE CS Reduced7 WE f 120572E CW At least double8 SWE 2f 120572SE CSW Unchanged
CC
CL
Metal 1
Metal 2
Metal 3
Figure 4 Line-to-line and crossover capacitance of a multilevelmetal layer
The width WC is different from the width WS to allow ahigher frequency Since the wire widths have to be changedto accommodate the higher operating frequency the loadcapacitance of the bus wires (given in (5)) will change Inaddition the increase in wire spacing changes the cross-coupling capacitanceThus the power consumption of the busis given by
119875S = (120572SL119862SL + 120572SC119862SC) 119891S119882S1198812
119863119863 (6)
where 120572SL is the signal transition switching activity 120572SC is thecoupling switching activity 119862SL is the load capacitance and119862SC is the coupling capacitance of the serialized-widened busFigure 4 shows the capacitance values in a multilevel metallayer The wire configurations values are taken from ITRS2004 Update [27] and those values are used in the Chernet al [23] equations to calculate the capacitance values Thefrequency of the bus is given by the Kawaguchi and Sakurai[28] equation1
119891asymp (163 sdot
119862119862
119862119862+ 119862119871
+ 037) sdot 119877 sdot (119862119862+ 119862119871) (7)
Here 119877 is the resistance of the wire given by its width 119882thickness 119879 and rate of resistance 120572 (dependent on materialproperty)
Consider
119877 =120572
119882119879 (8)
Equations (7) and (8) can be used to determine the optimumwire width for the serialized-widened bus at the higherfrequency
3 Framework and Proposed Technique
The three fundamental approaches discussed earlier in thissection to reduce bus power are serialization (S) encoding(E) and widening (W) of the bus Combinations of theseapproaches are also possible and in fact yield better resultsTable 2 lists the possible types of buses based on these threeapproaches and their combinations (the first of which is aconventional bus (C) not employing any of the approaches)These approaches reduce the power through changes in theswitching activity and the line capacitance of the bus
Table 2 lists the relation between the switching activityand the line capacitance of the different approaches Italso lists the change in bus area and frequency due to theapproaches Two other important methods to reduce buspower are variations in the swing voltage and operating fre-quency These two techniques can be applied in conjunctionwith all of the methods listed in Table 2 The frameworkshown in Table 2 can be used to categorize many of theapproaches used to minimize the bus switching activity andwire capacitance The encoding techniques proposed in [12ndash23 27ndash47] fall under the category E listed in the table Thenarrow bus encoding technique presented by Loghi et al [5]falls under the category SE while Hattarsquos serialized-widenedbus [2] falls under the category SW
There are four unique capacitance values and switchingactivities listed in Table 2 The relation between these capac-itance values can generally be described as CW lt CSW ltCS lt CC If the serialized bus is running at a higherfrequency to preserve the bus throughput the wires andtheir spacing may have to be widened thus possibly reducingtheir capacitance CS from the original bus value CC Inthe widened bus the wires spacing is increased making thistype of bus having the lowest wire capacitance Howeverthere is a significant bus area overhead in this approachThe serialized-widened bus running at a higher frequency topreserve the throughput will have slightly less wire spacingthan the widened bus since the wires will have to be madewider for the higher frequency Thus the capacitance of thisbus CSW will be more than that of the widened bus CW but
VLSI Design 5
Table 3 Architectural configuration of the simulator used in theexperiment
System ParametersNumber of processor cores 2 4 8Super scalar width 4 out-of-orderL1 instruction cache 163264KB direct-mapped 1-cycleL1 data cache 163264KB 4-way 1-cycleL1 block size 32 BShared L2 cache 1MB 4-way unified 12-cycleL2 block size 64 BRUULSQ 168Memory ports 2TLB 128-entries 4-way 30-cycleMemory latency 96-cycleMemory bus width 1248 B
still less than the serialized bus CS (since the wires are morespaced out than a serialized bus)
The relation between the switching activities is highlydependent on the data values passed on the bus Thereforea strict relation between the switching activities cannot beshown However in general it can be expected that anencoded bus will have less switching than a conventional bus(hence 120572E lt 120572C) In addition the serialized-encoded bus(SE) will also likely have a lower switching activity than aconventional bus (hence120572SE lt 120572C)The relation between theswitching activity of a serialized bus (120572S) and a conventionalbus (120572C) is hard to predict
This paper proposes data bus power reduction techniquesfor the SWE approachThis work compares these approacheswith existing power reduction methods that fall under thedifferent categories in Table 2 This work finds that the SWEapproach works best since this method reduces both the wirecapacitance and the switching activity significantly
4 Experimental Setup
This section discusses the target systemof the experiment andthe memory structure used to collect the memory tracesThefirst subsection describes the architecture of sim-outorderthe superscalar simulator from the Simplescalar tool suite[48] In the subsection followed we discusses the benchmarkssuite and the input sets that are used in this paper In thelast part of this section we present the switching activitycomputation methodology
41 Simulator This experiment uses a modified version ofSimplescalar 30drsquos sim-outorder simulator [48] to collectour cache request traces The model architecture has mid-range configuration Table 3 summarizes the architecturalconfiguration of our simulator The baseline configurationparameters are typical those of a modern chip multiproces-sors and out-of-order simulatorThis work keeps the L1 cachesize smaller to get morememory access which results inmoreaccurate behavior of memory access and memory bus This
Table 4 Benchmarks types and number of warm up instructionsused in the experiment
Benchmarks Type Warm up instructionsgzip (pro) Int 2000Mgzip (src) Int 1400MWupwise FP 2000MGcc Int 2000MMesa FP 700MArt FP 2000MMcf Int 1000Mbzip2 (pro) Int 2000Mbzip2 (src) Int 2000MTwolf Int 900Mmpeg2d MB 0MGsm MB 0Mmpeg2e MB 0M
work develops another simulator written in program C tocalculate the switching activity for the bus power estimation
42 Benchmark Suites This experiment uses 6 integers and3 floating point benchmarks from SPEC2000 suite [49] and3 benchmarks from MediaBench suite [47] This selection ismotivated by finding somememory intensive programs (mcfart gcc gzip and twolf) [3] and some memory nonintensiveprogramsThe simulation wants to use reference inputs of theSPEC2000 suite because of having smaller data sets of testor training inputs For each of the benchmark of SPEC2000suite this work divides the total run length by 5 and warmup for the first 3 portions with a maximum of 2 billioninstructions using fast-forward mode cycle-level simulationA 200 million instruction window is simulated using thedetailed simulator ForMediaBench suite this work simulatesthe whole program to generate the required traces withoutany fast forwarding Table 3 lists the reference inputs thatare chosen from the SPEC2000 benchmark and MediaBenchsuite and the number of instructions for which the simulatoris warmed up Among these benchmarks a group of bench-marks are selected to run in multicore processor units qs inTable 4This selection gives importance to group thememoryintensive programs to get more accurate behavior of memoryaccess than to groupmemory nonintensive programs Table 5summarizes the list of benchmarks used for 8 4 and 2 coresprocessing units
43 Switching Activity Computation Apower simulatorwrit-ten in C is integrated with the modified Simplescalar sim-outorder simulator [48] to calculate the switching activity ofthe data transitions between L1 and L2 cache through L1-L2 cache bus The simulator has several functionalities forcalculating the switching activity for all six different kinds ofencoding techniques listed in Table 6
During serialization-widening the simulator uses twosets of value cache (VC) for LSB and MSB data matchinginstead of using one unified VC Figure 5 shows the different
6 VLSI Design
Table 5 Combination of benchmarks used for multiprocessingcores
Number of cores Set Name of benchmarks
8
1mcf art gcc twolfmpeg2d gzip (pro) mesabzip2 (pro)
2gzip (src) mcf gcc gsmwupwise mpeg2e artbzip2 (src)
4
1 mcf art mpeg2e gzip (pro)2 twolf bzip2 (pro) mesa art
3 gcc gzip (src) bzip2 (src)gsm
21 mcf art2 gcc twolf
Table 6 Listing of different encoding techniques implemented inthis experiment
Name AbbreviationBus-invert coding biTransition signaling xorFrequent value encoding with one hot-code FvFrequent value encoding with two hot-code fv2TUBE with one hot-code TubeTUBE with two hot-code tube2
structures of two sets of VC with serialization The databus size is varied frequently to compare the effectivenessof different possible approaches and encoding techniqueskeeping the total amount of data the same For example ifa data stream of 64-bit wide requires 1 transition using 64-bitwide data bus it requires 8 transitions using 8-bit wide databus
5 Results and Analysis
This section presents the experimental results It has ageneral comparison of the cache bus power minimizationusing the seven possible approaches listed in Table 2 Itfurther examines in detail three of the approaches that donot change the bus area and finds that the SWE approachperforms the best It also presents an in depth analysis ofthe SWE approach performance under various architectureand technology configurations At the end of this section wediscuss the performance power and area overhead for theproposed technique
51 Power Savings for Different Possible Approaches Theseven possible bus power savings approaches listed in Table 2earlier are different combinations of serialization (S) buswidening (W) and encoding (E) Figure 6 shows the powersavings on the L1-L2 cache data bus for the differentarchitecture-benchmark combinations listed in Table 5 usingthese approaches A 64-bit data bus implemented on 45 nmtechnology is assumed The techniques reduce bus power by
L1 L2cache
Serializer DeserializerDriver
NCNC NSNS
LSBVC
LSBVC
Externalcontrol line
NS MSBVC
MSBVC
cache
Figure 5 Structure of 2 sets of value cache combined withserialization
minus30
minus15
0
15
30
45
60
75
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
SWESW
SEWESWE
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 6 Comparison of the of power savings using the differentdata bus power reduction approaches Results are compared to aconventional 64-bit L1-L2 cache data bus at 45 nm technology
minimizing bus switching activity bus wire capacitance orboth
When the three approaches for power reduction areapplied on their own bus widening performs the best Theserialization (S) approach performs poorly for most of thearchitecture configurations listed in Figure 6 (the bus poweris generally increased) This is primarily due to the fact thatserialization generally increases switching activity The buscapacitance is actually reduced partially since the wires arespaced out further to allow the frequency to be doubledHowever this reduction in capacitance is not enough to offsetthe increased switching activity The widening (W) approachperforms very well since it reduces the bus wire capacitancesignificantly The disadvantage of the approach is that italmost doubles the bus area There are six different encodingtechniques (E) that are tested (seeTable 6) Figure 6 shows theresult from the best encoding technique for each architectureconfiguration Encoding reduces switching activity withoutaffecting the bus capacitance and so does minimizing thebus power This approach does not change the bus area orfrequency
When using combinations of the three approaches theserialized-widened-encoded (SWE) method performs thebest The serialized-widened (SW) approach reduces the buscapacitance by widening the wire spacing but generallyincreases the switching activity through serializationThe net
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
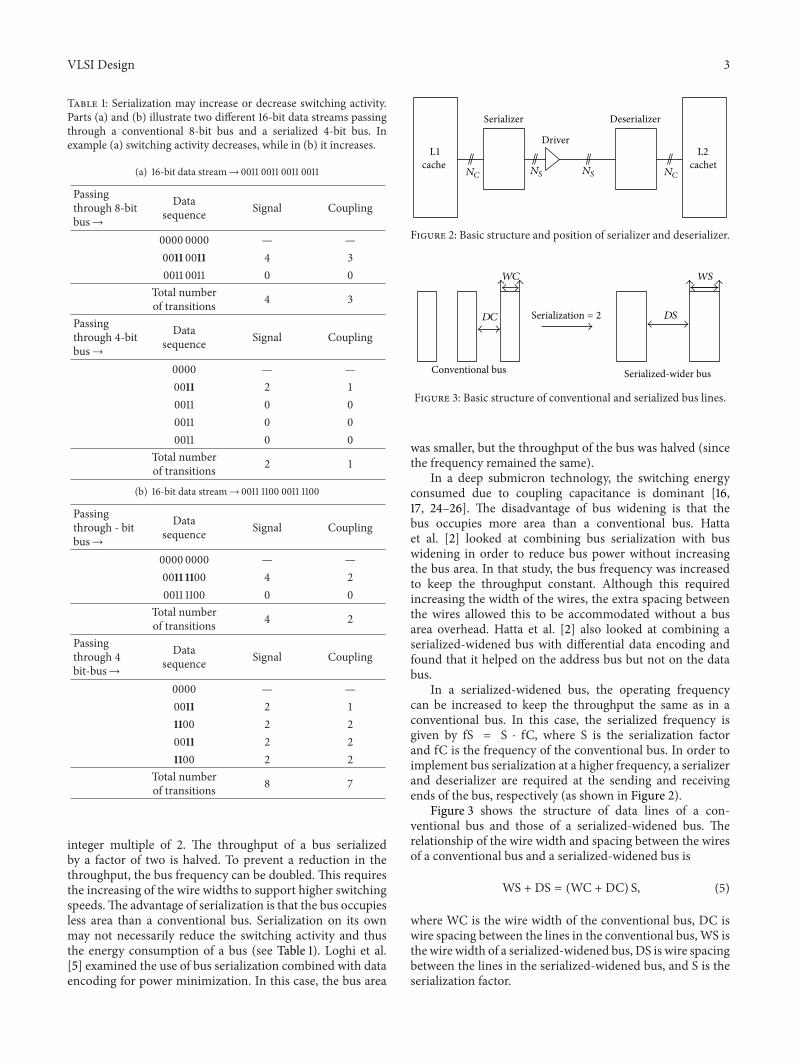
VLSI Design 3
Table 1 Serialization may increase or decrease switching activityParts (a) and (b) illustrate two different 16-bit data streams passingthrough a conventional 8-bit bus and a serialized 4-bit bus Inexample (a) switching activity decreases while in (b) it increases
(a) 16-bit data streamrarr 0011 0011 0011 0011
Passingthrough 8-bitbusrarr
Datasequence Signal Coupling
0000 0000 mdash mdash0011 0011 4 30011 0011 0 0
Total numberof transitions 4 3
Passingthrough 4-bitbusrarr
Datasequence Signal Coupling
0000 mdash mdash0011 2 10011 0 00011 0 00011 0 0
Total numberof transitions 2 1
(b) 16-bit data streamrarr 0011 1100 0011 1100
Passingthrough - bitbusrarr
Datasequence Signal Coupling
0000 0000 mdash mdash0011 1100 4 20011 1100 0 0
Total numberof transitions 4 2
Passingthrough 4bit-busrarr
Datasequence Signal Coupling
0000 mdash mdash0011 2 11100 2 20011 2 21100 2 2
Total numberof transitions 8 7
integer multiple of 2 The throughput of a bus serializedby a factor of two is halved To prevent a reduction in thethroughput the bus frequency can be doubled This requiresthe increasing of the wire widths to support higher switchingspeedsThe advantage of serialization is that the bus occupiesless area than a conventional bus Serialization on its ownmay not necessarily reduce the switching activity and thusthe energy consumption of a bus (see Table 1) Loghi et al[5] examined the use of bus serialization combined with dataencoding for power minimization In this case the bus area
L1cache
L2cachet
Serializer Deserializer
Driver
NCNCNSNS
Figure 2 Basic structure and position of serializer and deserializer
Serialization = 2
Conventional bus Serialized-wider bus
WS
DS
WC
DC
Figure 3 Basic structure of conventional and serialized bus lines
was smaller but the throughput of the bus was halved (sincethe frequency remained the same)
In a deep submicron technology the switching energyconsumed due to coupling capacitance is dominant [1617 24ndash26] The disadvantage of bus widening is that thebus occupies more area than a conventional bus Hattaet al [2] looked at combining bus serialization with buswidening in order to reduce bus power without increasingthe bus area In that study the bus frequency was increasedto keep the throughput constant Although this requiredincreasing the width of the wires the extra spacing betweenthe wires allowed this to be accommodated without a busarea overhead Hatta et al [2] also looked at combining aserialized-widened bus with differential data encoding andfound that it helped on the address bus but not on the databus
In a serialized-widened bus the operating frequencycan be increased to keep the throughput the same as in aconventional bus In this case the serialized frequency isgiven by fS = S sdot fC where S is the serialization factorand fC is the frequency of the conventional bus In order toimplement bus serialization at a higher frequency a serializerand deserializer are required at the sending and receivingends of the bus respectively (as shown in Figure 2)
Figure 3 shows the structure of data lines of a con-ventional bus and those of a serialized-widened bus Therelationship of the wire width and spacing between the wiresof a conventional bus and a serialized-widened bus is
WS + DS = (WC + DC) S (5)
where WC is the wire width of the conventional bus DC iswire spacing between the lines in the conventional bus WS isthe wire width of a serialized-widened bus DS is wire spacingbetween the lines in the serialized-widened bus and S is theserialization factor
4 VLSI Design
Table 2 Comparison of possible approaches to reduce on-chip data bus power
Approach Bus freq Switching activity Line cap Bus area1 C (conventional) f 120572C CC Original bus area2 S (serial) 2f 120572S CS Reduced3 W (widened) f 120572C CW At least double4 E (encoded) f 120572E CC Unchanged5 SW 2f 120572S CSW Unchanged6 SE 2f 120572SE CS Reduced7 WE f 120572E CW At least double8 SWE 2f 120572SE CSW Unchanged
CC
CL
Metal 1
Metal 2
Metal 3
Figure 4 Line-to-line and crossover capacitance of a multilevelmetal layer
The width WC is different from the width WS to allow ahigher frequency Since the wire widths have to be changedto accommodate the higher operating frequency the loadcapacitance of the bus wires (given in (5)) will change Inaddition the increase in wire spacing changes the cross-coupling capacitanceThus the power consumption of the busis given by
119875S = (120572SL119862SL + 120572SC119862SC) 119891S119882S1198812
119863119863 (6)
where 120572SL is the signal transition switching activity 120572SC is thecoupling switching activity 119862SL is the load capacitance and119862SC is the coupling capacitance of the serialized-widened busFigure 4 shows the capacitance values in a multilevel metallayer The wire configurations values are taken from ITRS2004 Update [27] and those values are used in the Chernet al [23] equations to calculate the capacitance values Thefrequency of the bus is given by the Kawaguchi and Sakurai[28] equation1
119891asymp (163 sdot
119862119862
119862119862+ 119862119871
+ 037) sdot 119877 sdot (119862119862+ 119862119871) (7)
Here 119877 is the resistance of the wire given by its width 119882thickness 119879 and rate of resistance 120572 (dependent on materialproperty)
Consider
119877 =120572
119882119879 (8)
Equations (7) and (8) can be used to determine the optimumwire width for the serialized-widened bus at the higherfrequency
3 Framework and Proposed Technique
The three fundamental approaches discussed earlier in thissection to reduce bus power are serialization (S) encoding(E) and widening (W) of the bus Combinations of theseapproaches are also possible and in fact yield better resultsTable 2 lists the possible types of buses based on these threeapproaches and their combinations (the first of which is aconventional bus (C) not employing any of the approaches)These approaches reduce the power through changes in theswitching activity and the line capacitance of the bus
Table 2 lists the relation between the switching activityand the line capacitance of the different approaches Italso lists the change in bus area and frequency due to theapproaches Two other important methods to reduce buspower are variations in the swing voltage and operating fre-quency These two techniques can be applied in conjunctionwith all of the methods listed in Table 2 The frameworkshown in Table 2 can be used to categorize many of theapproaches used to minimize the bus switching activity andwire capacitance The encoding techniques proposed in [12ndash23 27ndash47] fall under the category E listed in the table Thenarrow bus encoding technique presented by Loghi et al [5]falls under the category SE while Hattarsquos serialized-widenedbus [2] falls under the category SW
There are four unique capacitance values and switchingactivities listed in Table 2 The relation between these capac-itance values can generally be described as CW lt CSW ltCS lt CC If the serialized bus is running at a higherfrequency to preserve the bus throughput the wires andtheir spacing may have to be widened thus possibly reducingtheir capacitance CS from the original bus value CC Inthe widened bus the wires spacing is increased making thistype of bus having the lowest wire capacitance Howeverthere is a significant bus area overhead in this approachThe serialized-widened bus running at a higher frequency topreserve the throughput will have slightly less wire spacingthan the widened bus since the wires will have to be madewider for the higher frequency Thus the capacitance of thisbus CSW will be more than that of the widened bus CW but
VLSI Design 5
Table 3 Architectural configuration of the simulator used in theexperiment
System ParametersNumber of processor cores 2 4 8Super scalar width 4 out-of-orderL1 instruction cache 163264KB direct-mapped 1-cycleL1 data cache 163264KB 4-way 1-cycleL1 block size 32 BShared L2 cache 1MB 4-way unified 12-cycleL2 block size 64 BRUULSQ 168Memory ports 2TLB 128-entries 4-way 30-cycleMemory latency 96-cycleMemory bus width 1248 B
still less than the serialized bus CS (since the wires are morespaced out than a serialized bus)
The relation between the switching activities is highlydependent on the data values passed on the bus Thereforea strict relation between the switching activities cannot beshown However in general it can be expected that anencoded bus will have less switching than a conventional bus(hence 120572E lt 120572C) In addition the serialized-encoded bus(SE) will also likely have a lower switching activity than aconventional bus (hence120572SE lt 120572C)The relation between theswitching activity of a serialized bus (120572S) and a conventionalbus (120572C) is hard to predict
This paper proposes data bus power reduction techniquesfor the SWE approachThis work compares these approacheswith existing power reduction methods that fall under thedifferent categories in Table 2 This work finds that the SWEapproach works best since this method reduces both the wirecapacitance and the switching activity significantly
4 Experimental Setup
This section discusses the target systemof the experiment andthe memory structure used to collect the memory tracesThefirst subsection describes the architecture of sim-outorderthe superscalar simulator from the Simplescalar tool suite[48] In the subsection followed we discusses the benchmarkssuite and the input sets that are used in this paper In thelast part of this section we present the switching activitycomputation methodology
41 Simulator This experiment uses a modified version ofSimplescalar 30drsquos sim-outorder simulator [48] to collectour cache request traces The model architecture has mid-range configuration Table 3 summarizes the architecturalconfiguration of our simulator The baseline configurationparameters are typical those of a modern chip multiproces-sors and out-of-order simulatorThis work keeps the L1 cachesize smaller to get morememory access which results inmoreaccurate behavior of memory access and memory bus This
Table 4 Benchmarks types and number of warm up instructionsused in the experiment
Benchmarks Type Warm up instructionsgzip (pro) Int 2000Mgzip (src) Int 1400MWupwise FP 2000MGcc Int 2000MMesa FP 700MArt FP 2000MMcf Int 1000Mbzip2 (pro) Int 2000Mbzip2 (src) Int 2000MTwolf Int 900Mmpeg2d MB 0MGsm MB 0Mmpeg2e MB 0M
work develops another simulator written in program C tocalculate the switching activity for the bus power estimation
42 Benchmark Suites This experiment uses 6 integers and3 floating point benchmarks from SPEC2000 suite [49] and3 benchmarks from MediaBench suite [47] This selection ismotivated by finding somememory intensive programs (mcfart gcc gzip and twolf) [3] and some memory nonintensiveprogramsThe simulation wants to use reference inputs of theSPEC2000 suite because of having smaller data sets of testor training inputs For each of the benchmark of SPEC2000suite this work divides the total run length by 5 and warmup for the first 3 portions with a maximum of 2 billioninstructions using fast-forward mode cycle-level simulationA 200 million instruction window is simulated using thedetailed simulator ForMediaBench suite this work simulatesthe whole program to generate the required traces withoutany fast forwarding Table 3 lists the reference inputs thatare chosen from the SPEC2000 benchmark and MediaBenchsuite and the number of instructions for which the simulatoris warmed up Among these benchmarks a group of bench-marks are selected to run in multicore processor units qs inTable 4This selection gives importance to group thememoryintensive programs to get more accurate behavior of memoryaccess than to groupmemory nonintensive programs Table 5summarizes the list of benchmarks used for 8 4 and 2 coresprocessing units
43 Switching Activity Computation Apower simulatorwrit-ten in C is integrated with the modified Simplescalar sim-outorder simulator [48] to calculate the switching activity ofthe data transitions between L1 and L2 cache through L1-L2 cache bus The simulator has several functionalities forcalculating the switching activity for all six different kinds ofencoding techniques listed in Table 6
During serialization-widening the simulator uses twosets of value cache (VC) for LSB and MSB data matchinginstead of using one unified VC Figure 5 shows the different
6 VLSI Design
Table 5 Combination of benchmarks used for multiprocessingcores
Number of cores Set Name of benchmarks
8
1mcf art gcc twolfmpeg2d gzip (pro) mesabzip2 (pro)
2gzip (src) mcf gcc gsmwupwise mpeg2e artbzip2 (src)
4
1 mcf art mpeg2e gzip (pro)2 twolf bzip2 (pro) mesa art
3 gcc gzip (src) bzip2 (src)gsm
21 mcf art2 gcc twolf
Table 6 Listing of different encoding techniques implemented inthis experiment
Name AbbreviationBus-invert coding biTransition signaling xorFrequent value encoding with one hot-code FvFrequent value encoding with two hot-code fv2TUBE with one hot-code TubeTUBE with two hot-code tube2
structures of two sets of VC with serialization The databus size is varied frequently to compare the effectivenessof different possible approaches and encoding techniqueskeeping the total amount of data the same For example ifa data stream of 64-bit wide requires 1 transition using 64-bitwide data bus it requires 8 transitions using 8-bit wide databus
5 Results and Analysis
This section presents the experimental results It has ageneral comparison of the cache bus power minimizationusing the seven possible approaches listed in Table 2 Itfurther examines in detail three of the approaches that donot change the bus area and finds that the SWE approachperforms the best It also presents an in depth analysis ofthe SWE approach performance under various architectureand technology configurations At the end of this section wediscuss the performance power and area overhead for theproposed technique
51 Power Savings for Different Possible Approaches Theseven possible bus power savings approaches listed in Table 2earlier are different combinations of serialization (S) buswidening (W) and encoding (E) Figure 6 shows the powersavings on the L1-L2 cache data bus for the differentarchitecture-benchmark combinations listed in Table 5 usingthese approaches A 64-bit data bus implemented on 45 nmtechnology is assumed The techniques reduce bus power by
L1 L2cache
Serializer DeserializerDriver
NCNC NSNS
LSBVC
LSBVC
Externalcontrol line
NS MSBVC
MSBVC
cache
Figure 5 Structure of 2 sets of value cache combined withserialization
minus30
minus15
0
15
30
45
60
75
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
SWESW
SEWESWE
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 6 Comparison of the of power savings using the differentdata bus power reduction approaches Results are compared to aconventional 64-bit L1-L2 cache data bus at 45 nm technology
minimizing bus switching activity bus wire capacitance orboth
When the three approaches for power reduction areapplied on their own bus widening performs the best Theserialization (S) approach performs poorly for most of thearchitecture configurations listed in Figure 6 (the bus poweris generally increased) This is primarily due to the fact thatserialization generally increases switching activity The buscapacitance is actually reduced partially since the wires arespaced out further to allow the frequency to be doubledHowever this reduction in capacitance is not enough to offsetthe increased switching activity The widening (W) approachperforms very well since it reduces the bus wire capacitancesignificantly The disadvantage of the approach is that italmost doubles the bus area There are six different encodingtechniques (E) that are tested (seeTable 6) Figure 6 shows theresult from the best encoding technique for each architectureconfiguration Encoding reduces switching activity withoutaffecting the bus capacitance and so does minimizing thebus power This approach does not change the bus area orfrequency
When using combinations of the three approaches theserialized-widened-encoded (SWE) method performs thebest The serialized-widened (SW) approach reduces the buscapacitance by widening the wire spacing but generallyincreases the switching activity through serializationThe net
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

4 VLSI Design
Table 2 Comparison of possible approaches to reduce on-chip data bus power
Approach Bus freq Switching activity Line cap Bus area1 C (conventional) f 120572C CC Original bus area2 S (serial) 2f 120572S CS Reduced3 W (widened) f 120572C CW At least double4 E (encoded) f 120572E CC Unchanged5 SW 2f 120572S CSW Unchanged6 SE 2f 120572SE CS Reduced7 WE f 120572E CW At least double8 SWE 2f 120572SE CSW Unchanged
CC
CL
Metal 1
Metal 2
Metal 3
Figure 4 Line-to-line and crossover capacitance of a multilevelmetal layer
The width WC is different from the width WS to allow ahigher frequency Since the wire widths have to be changedto accommodate the higher operating frequency the loadcapacitance of the bus wires (given in (5)) will change Inaddition the increase in wire spacing changes the cross-coupling capacitanceThus the power consumption of the busis given by
119875S = (120572SL119862SL + 120572SC119862SC) 119891S119882S1198812
119863119863 (6)
where 120572SL is the signal transition switching activity 120572SC is thecoupling switching activity 119862SL is the load capacitance and119862SC is the coupling capacitance of the serialized-widened busFigure 4 shows the capacitance values in a multilevel metallayer The wire configurations values are taken from ITRS2004 Update [27] and those values are used in the Chernet al [23] equations to calculate the capacitance values Thefrequency of the bus is given by the Kawaguchi and Sakurai[28] equation1
119891asymp (163 sdot
119862119862
119862119862+ 119862119871
+ 037) sdot 119877 sdot (119862119862+ 119862119871) (7)
Here 119877 is the resistance of the wire given by its width 119882thickness 119879 and rate of resistance 120572 (dependent on materialproperty)
Consider
119877 =120572
119882119879 (8)
Equations (7) and (8) can be used to determine the optimumwire width for the serialized-widened bus at the higherfrequency
3 Framework and Proposed Technique
The three fundamental approaches discussed earlier in thissection to reduce bus power are serialization (S) encoding(E) and widening (W) of the bus Combinations of theseapproaches are also possible and in fact yield better resultsTable 2 lists the possible types of buses based on these threeapproaches and their combinations (the first of which is aconventional bus (C) not employing any of the approaches)These approaches reduce the power through changes in theswitching activity and the line capacitance of the bus
Table 2 lists the relation between the switching activityand the line capacitance of the different approaches Italso lists the change in bus area and frequency due to theapproaches Two other important methods to reduce buspower are variations in the swing voltage and operating fre-quency These two techniques can be applied in conjunctionwith all of the methods listed in Table 2 The frameworkshown in Table 2 can be used to categorize many of theapproaches used to minimize the bus switching activity andwire capacitance The encoding techniques proposed in [12ndash23 27ndash47] fall under the category E listed in the table Thenarrow bus encoding technique presented by Loghi et al [5]falls under the category SE while Hattarsquos serialized-widenedbus [2] falls under the category SW
There are four unique capacitance values and switchingactivities listed in Table 2 The relation between these capac-itance values can generally be described as CW lt CSW ltCS lt CC If the serialized bus is running at a higherfrequency to preserve the bus throughput the wires andtheir spacing may have to be widened thus possibly reducingtheir capacitance CS from the original bus value CC Inthe widened bus the wires spacing is increased making thistype of bus having the lowest wire capacitance Howeverthere is a significant bus area overhead in this approachThe serialized-widened bus running at a higher frequency topreserve the throughput will have slightly less wire spacingthan the widened bus since the wires will have to be madewider for the higher frequency Thus the capacitance of thisbus CSW will be more than that of the widened bus CW but
VLSI Design 5
Table 3 Architectural configuration of the simulator used in theexperiment
System ParametersNumber of processor cores 2 4 8Super scalar width 4 out-of-orderL1 instruction cache 163264KB direct-mapped 1-cycleL1 data cache 163264KB 4-way 1-cycleL1 block size 32 BShared L2 cache 1MB 4-way unified 12-cycleL2 block size 64 BRUULSQ 168Memory ports 2TLB 128-entries 4-way 30-cycleMemory latency 96-cycleMemory bus width 1248 B
still less than the serialized bus CS (since the wires are morespaced out than a serialized bus)
The relation between the switching activities is highlydependent on the data values passed on the bus Thereforea strict relation between the switching activities cannot beshown However in general it can be expected that anencoded bus will have less switching than a conventional bus(hence 120572E lt 120572C) In addition the serialized-encoded bus(SE) will also likely have a lower switching activity than aconventional bus (hence120572SE lt 120572C)The relation between theswitching activity of a serialized bus (120572S) and a conventionalbus (120572C) is hard to predict
This paper proposes data bus power reduction techniquesfor the SWE approachThis work compares these approacheswith existing power reduction methods that fall under thedifferent categories in Table 2 This work finds that the SWEapproach works best since this method reduces both the wirecapacitance and the switching activity significantly
4 Experimental Setup
This section discusses the target systemof the experiment andthe memory structure used to collect the memory tracesThefirst subsection describes the architecture of sim-outorderthe superscalar simulator from the Simplescalar tool suite[48] In the subsection followed we discusses the benchmarkssuite and the input sets that are used in this paper In thelast part of this section we present the switching activitycomputation methodology
41 Simulator This experiment uses a modified version ofSimplescalar 30drsquos sim-outorder simulator [48] to collectour cache request traces The model architecture has mid-range configuration Table 3 summarizes the architecturalconfiguration of our simulator The baseline configurationparameters are typical those of a modern chip multiproces-sors and out-of-order simulatorThis work keeps the L1 cachesize smaller to get morememory access which results inmoreaccurate behavior of memory access and memory bus This
Table 4 Benchmarks types and number of warm up instructionsused in the experiment
Benchmarks Type Warm up instructionsgzip (pro) Int 2000Mgzip (src) Int 1400MWupwise FP 2000MGcc Int 2000MMesa FP 700MArt FP 2000MMcf Int 1000Mbzip2 (pro) Int 2000Mbzip2 (src) Int 2000MTwolf Int 900Mmpeg2d MB 0MGsm MB 0Mmpeg2e MB 0M
work develops another simulator written in program C tocalculate the switching activity for the bus power estimation
42 Benchmark Suites This experiment uses 6 integers and3 floating point benchmarks from SPEC2000 suite [49] and3 benchmarks from MediaBench suite [47] This selection ismotivated by finding somememory intensive programs (mcfart gcc gzip and twolf) [3] and some memory nonintensiveprogramsThe simulation wants to use reference inputs of theSPEC2000 suite because of having smaller data sets of testor training inputs For each of the benchmark of SPEC2000suite this work divides the total run length by 5 and warmup for the first 3 portions with a maximum of 2 billioninstructions using fast-forward mode cycle-level simulationA 200 million instruction window is simulated using thedetailed simulator ForMediaBench suite this work simulatesthe whole program to generate the required traces withoutany fast forwarding Table 3 lists the reference inputs thatare chosen from the SPEC2000 benchmark and MediaBenchsuite and the number of instructions for which the simulatoris warmed up Among these benchmarks a group of bench-marks are selected to run in multicore processor units qs inTable 4This selection gives importance to group thememoryintensive programs to get more accurate behavior of memoryaccess than to groupmemory nonintensive programs Table 5summarizes the list of benchmarks used for 8 4 and 2 coresprocessing units
43 Switching Activity Computation Apower simulatorwrit-ten in C is integrated with the modified Simplescalar sim-outorder simulator [48] to calculate the switching activity ofthe data transitions between L1 and L2 cache through L1-L2 cache bus The simulator has several functionalities forcalculating the switching activity for all six different kinds ofencoding techniques listed in Table 6
During serialization-widening the simulator uses twosets of value cache (VC) for LSB and MSB data matchinginstead of using one unified VC Figure 5 shows the different
6 VLSI Design
Table 5 Combination of benchmarks used for multiprocessingcores
Number of cores Set Name of benchmarks
8
1mcf art gcc twolfmpeg2d gzip (pro) mesabzip2 (pro)
2gzip (src) mcf gcc gsmwupwise mpeg2e artbzip2 (src)
4
1 mcf art mpeg2e gzip (pro)2 twolf bzip2 (pro) mesa art
3 gcc gzip (src) bzip2 (src)gsm
21 mcf art2 gcc twolf
Table 6 Listing of different encoding techniques implemented inthis experiment
Name AbbreviationBus-invert coding biTransition signaling xorFrequent value encoding with one hot-code FvFrequent value encoding with two hot-code fv2TUBE with one hot-code TubeTUBE with two hot-code tube2
structures of two sets of VC with serialization The databus size is varied frequently to compare the effectivenessof different possible approaches and encoding techniqueskeeping the total amount of data the same For example ifa data stream of 64-bit wide requires 1 transition using 64-bitwide data bus it requires 8 transitions using 8-bit wide databus
5 Results and Analysis
This section presents the experimental results It has ageneral comparison of the cache bus power minimizationusing the seven possible approaches listed in Table 2 Itfurther examines in detail three of the approaches that donot change the bus area and finds that the SWE approachperforms the best It also presents an in depth analysis ofthe SWE approach performance under various architectureand technology configurations At the end of this section wediscuss the performance power and area overhead for theproposed technique
51 Power Savings for Different Possible Approaches Theseven possible bus power savings approaches listed in Table 2earlier are different combinations of serialization (S) buswidening (W) and encoding (E) Figure 6 shows the powersavings on the L1-L2 cache data bus for the differentarchitecture-benchmark combinations listed in Table 5 usingthese approaches A 64-bit data bus implemented on 45 nmtechnology is assumed The techniques reduce bus power by
L1 L2cache
Serializer DeserializerDriver
NCNC NSNS
LSBVC
LSBVC
Externalcontrol line
NS MSBVC
MSBVC
cache
Figure 5 Structure of 2 sets of value cache combined withserialization
minus30
minus15
0
15
30
45
60
75
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
SWESW
SEWESWE
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 6 Comparison of the of power savings using the differentdata bus power reduction approaches Results are compared to aconventional 64-bit L1-L2 cache data bus at 45 nm technology
minimizing bus switching activity bus wire capacitance orboth
When the three approaches for power reduction areapplied on their own bus widening performs the best Theserialization (S) approach performs poorly for most of thearchitecture configurations listed in Figure 6 (the bus poweris generally increased) This is primarily due to the fact thatserialization generally increases switching activity The buscapacitance is actually reduced partially since the wires arespaced out further to allow the frequency to be doubledHowever this reduction in capacitance is not enough to offsetthe increased switching activity The widening (W) approachperforms very well since it reduces the bus wire capacitancesignificantly The disadvantage of the approach is that italmost doubles the bus area There are six different encodingtechniques (E) that are tested (seeTable 6) Figure 6 shows theresult from the best encoding technique for each architectureconfiguration Encoding reduces switching activity withoutaffecting the bus capacitance and so does minimizing thebus power This approach does not change the bus area orfrequency
When using combinations of the three approaches theserialized-widened-encoded (SWE) method performs thebest The serialized-widened (SW) approach reduces the buscapacitance by widening the wire spacing but generallyincreases the switching activity through serializationThe net
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
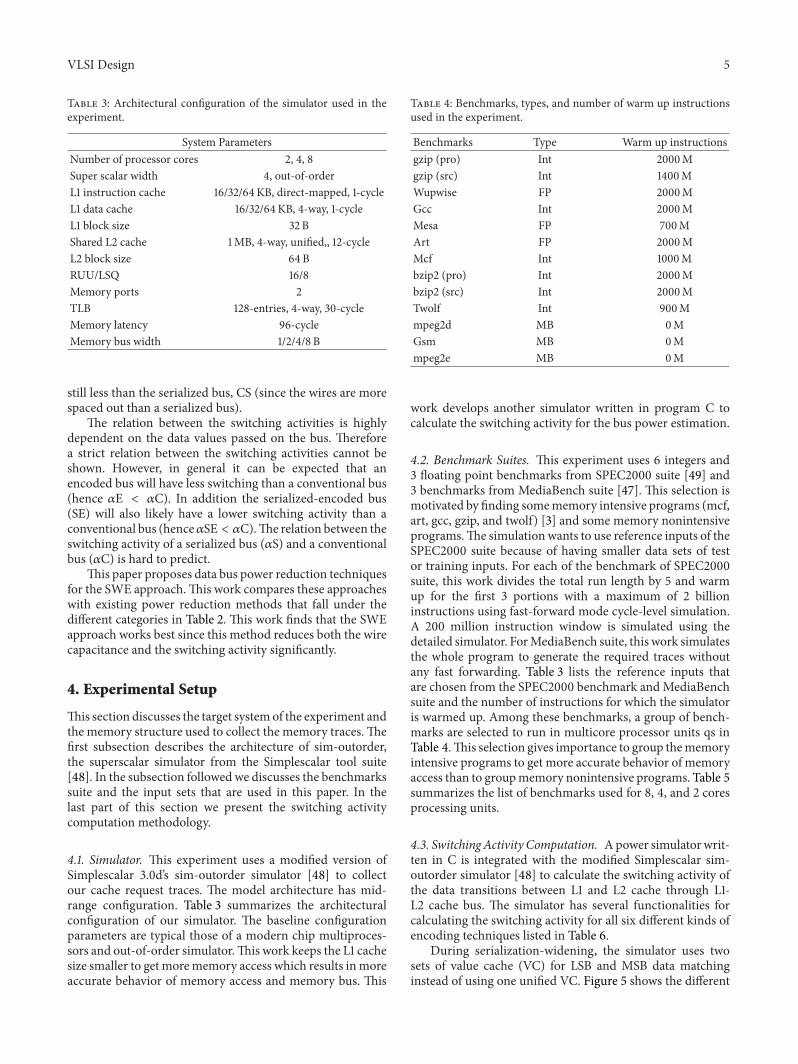
VLSI Design 5
Table 3 Architectural configuration of the simulator used in theexperiment
System ParametersNumber of processor cores 2 4 8Super scalar width 4 out-of-orderL1 instruction cache 163264KB direct-mapped 1-cycleL1 data cache 163264KB 4-way 1-cycleL1 block size 32 BShared L2 cache 1MB 4-way unified 12-cycleL2 block size 64 BRUULSQ 168Memory ports 2TLB 128-entries 4-way 30-cycleMemory latency 96-cycleMemory bus width 1248 B
still less than the serialized bus CS (since the wires are morespaced out than a serialized bus)
The relation between the switching activities is highlydependent on the data values passed on the bus Thereforea strict relation between the switching activities cannot beshown However in general it can be expected that anencoded bus will have less switching than a conventional bus(hence 120572E lt 120572C) In addition the serialized-encoded bus(SE) will also likely have a lower switching activity than aconventional bus (hence120572SE lt 120572C)The relation between theswitching activity of a serialized bus (120572S) and a conventionalbus (120572C) is hard to predict
This paper proposes data bus power reduction techniquesfor the SWE approachThis work compares these approacheswith existing power reduction methods that fall under thedifferent categories in Table 2 This work finds that the SWEapproach works best since this method reduces both the wirecapacitance and the switching activity significantly
4 Experimental Setup
This section discusses the target systemof the experiment andthe memory structure used to collect the memory tracesThefirst subsection describes the architecture of sim-outorderthe superscalar simulator from the Simplescalar tool suite[48] In the subsection followed we discusses the benchmarkssuite and the input sets that are used in this paper In thelast part of this section we present the switching activitycomputation methodology
41 Simulator This experiment uses a modified version ofSimplescalar 30drsquos sim-outorder simulator [48] to collectour cache request traces The model architecture has mid-range configuration Table 3 summarizes the architecturalconfiguration of our simulator The baseline configurationparameters are typical those of a modern chip multiproces-sors and out-of-order simulatorThis work keeps the L1 cachesize smaller to get morememory access which results inmoreaccurate behavior of memory access and memory bus This
Table 4 Benchmarks types and number of warm up instructionsused in the experiment
Benchmarks Type Warm up instructionsgzip (pro) Int 2000Mgzip (src) Int 1400MWupwise FP 2000MGcc Int 2000MMesa FP 700MArt FP 2000MMcf Int 1000Mbzip2 (pro) Int 2000Mbzip2 (src) Int 2000MTwolf Int 900Mmpeg2d MB 0MGsm MB 0Mmpeg2e MB 0M
work develops another simulator written in program C tocalculate the switching activity for the bus power estimation
42 Benchmark Suites This experiment uses 6 integers and3 floating point benchmarks from SPEC2000 suite [49] and3 benchmarks from MediaBench suite [47] This selection ismotivated by finding somememory intensive programs (mcfart gcc gzip and twolf) [3] and some memory nonintensiveprogramsThe simulation wants to use reference inputs of theSPEC2000 suite because of having smaller data sets of testor training inputs For each of the benchmark of SPEC2000suite this work divides the total run length by 5 and warmup for the first 3 portions with a maximum of 2 billioninstructions using fast-forward mode cycle-level simulationA 200 million instruction window is simulated using thedetailed simulator ForMediaBench suite this work simulatesthe whole program to generate the required traces withoutany fast forwarding Table 3 lists the reference inputs thatare chosen from the SPEC2000 benchmark and MediaBenchsuite and the number of instructions for which the simulatoris warmed up Among these benchmarks a group of bench-marks are selected to run in multicore processor units qs inTable 4This selection gives importance to group thememoryintensive programs to get more accurate behavior of memoryaccess than to groupmemory nonintensive programs Table 5summarizes the list of benchmarks used for 8 4 and 2 coresprocessing units
43 Switching Activity Computation Apower simulatorwrit-ten in C is integrated with the modified Simplescalar sim-outorder simulator [48] to calculate the switching activity ofthe data transitions between L1 and L2 cache through L1-L2 cache bus The simulator has several functionalities forcalculating the switching activity for all six different kinds ofencoding techniques listed in Table 6
During serialization-widening the simulator uses twosets of value cache (VC) for LSB and MSB data matchinginstead of using one unified VC Figure 5 shows the different
6 VLSI Design
Table 5 Combination of benchmarks used for multiprocessingcores
Number of cores Set Name of benchmarks
8
1mcf art gcc twolfmpeg2d gzip (pro) mesabzip2 (pro)
2gzip (src) mcf gcc gsmwupwise mpeg2e artbzip2 (src)
4
1 mcf art mpeg2e gzip (pro)2 twolf bzip2 (pro) mesa art
3 gcc gzip (src) bzip2 (src)gsm
21 mcf art2 gcc twolf
Table 6 Listing of different encoding techniques implemented inthis experiment
Name AbbreviationBus-invert coding biTransition signaling xorFrequent value encoding with one hot-code FvFrequent value encoding with two hot-code fv2TUBE with one hot-code TubeTUBE with two hot-code tube2
structures of two sets of VC with serialization The databus size is varied frequently to compare the effectivenessof different possible approaches and encoding techniqueskeeping the total amount of data the same For example ifa data stream of 64-bit wide requires 1 transition using 64-bitwide data bus it requires 8 transitions using 8-bit wide databus
5 Results and Analysis
This section presents the experimental results It has ageneral comparison of the cache bus power minimizationusing the seven possible approaches listed in Table 2 Itfurther examines in detail three of the approaches that donot change the bus area and finds that the SWE approachperforms the best It also presents an in depth analysis ofthe SWE approach performance under various architectureand technology configurations At the end of this section wediscuss the performance power and area overhead for theproposed technique
51 Power Savings for Different Possible Approaches Theseven possible bus power savings approaches listed in Table 2earlier are different combinations of serialization (S) buswidening (W) and encoding (E) Figure 6 shows the powersavings on the L1-L2 cache data bus for the differentarchitecture-benchmark combinations listed in Table 5 usingthese approaches A 64-bit data bus implemented on 45 nmtechnology is assumed The techniques reduce bus power by
L1 L2cache
Serializer DeserializerDriver
NCNC NSNS
LSBVC
LSBVC
Externalcontrol line
NS MSBVC
MSBVC
cache
Figure 5 Structure of 2 sets of value cache combined withserialization
minus30
minus15
0
15
30
45
60
75
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
SWESW
SEWESWE
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 6 Comparison of the of power savings using the differentdata bus power reduction approaches Results are compared to aconventional 64-bit L1-L2 cache data bus at 45 nm technology
minimizing bus switching activity bus wire capacitance orboth
When the three approaches for power reduction areapplied on their own bus widening performs the best Theserialization (S) approach performs poorly for most of thearchitecture configurations listed in Figure 6 (the bus poweris generally increased) This is primarily due to the fact thatserialization generally increases switching activity The buscapacitance is actually reduced partially since the wires arespaced out further to allow the frequency to be doubledHowever this reduction in capacitance is not enough to offsetthe increased switching activity The widening (W) approachperforms very well since it reduces the bus wire capacitancesignificantly The disadvantage of the approach is that italmost doubles the bus area There are six different encodingtechniques (E) that are tested (seeTable 6) Figure 6 shows theresult from the best encoding technique for each architectureconfiguration Encoding reduces switching activity withoutaffecting the bus capacitance and so does minimizing thebus power This approach does not change the bus area orfrequency
When using combinations of the three approaches theserialized-widened-encoded (SWE) method performs thebest The serialized-widened (SW) approach reduces the buscapacitance by widening the wire spacing but generallyincreases the switching activity through serializationThe net
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

6 VLSI Design
Table 5 Combination of benchmarks used for multiprocessingcores
Number of cores Set Name of benchmarks
8
1mcf art gcc twolfmpeg2d gzip (pro) mesabzip2 (pro)
2gzip (src) mcf gcc gsmwupwise mpeg2e artbzip2 (src)
4
1 mcf art mpeg2e gzip (pro)2 twolf bzip2 (pro) mesa art
3 gcc gzip (src) bzip2 (src)gsm
21 mcf art2 gcc twolf
Table 6 Listing of different encoding techniques implemented inthis experiment
Name AbbreviationBus-invert coding biTransition signaling xorFrequent value encoding with one hot-code FvFrequent value encoding with two hot-code fv2TUBE with one hot-code TubeTUBE with two hot-code tube2
structures of two sets of VC with serialization The databus size is varied frequently to compare the effectivenessof different possible approaches and encoding techniqueskeeping the total amount of data the same For example ifa data stream of 64-bit wide requires 1 transition using 64-bitwide data bus it requires 8 transitions using 8-bit wide databus
5 Results and Analysis
This section presents the experimental results It has ageneral comparison of the cache bus power minimizationusing the seven possible approaches listed in Table 2 Itfurther examines in detail three of the approaches that donot change the bus area and finds that the SWE approachperforms the best It also presents an in depth analysis ofthe SWE approach performance under various architectureand technology configurations At the end of this section wediscuss the performance power and area overhead for theproposed technique
51 Power Savings for Different Possible Approaches Theseven possible bus power savings approaches listed in Table 2earlier are different combinations of serialization (S) buswidening (W) and encoding (E) Figure 6 shows the powersavings on the L1-L2 cache data bus for the differentarchitecture-benchmark combinations listed in Table 5 usingthese approaches A 64-bit data bus implemented on 45 nmtechnology is assumed The techniques reduce bus power by
L1 L2cache
Serializer DeserializerDriver
NCNC NSNS
LSBVC
LSBVC
Externalcontrol line
NS MSBVC
MSBVC
cache
Figure 5 Structure of 2 sets of value cache combined withserialization
minus30
minus15
0
15
30
45
60
75
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
SWESW
SEWESWE
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 6 Comparison of the of power savings using the differentdata bus power reduction approaches Results are compared to aconventional 64-bit L1-L2 cache data bus at 45 nm technology
minimizing bus switching activity bus wire capacitance orboth
When the three approaches for power reduction areapplied on their own bus widening performs the best Theserialization (S) approach performs poorly for most of thearchitecture configurations listed in Figure 6 (the bus poweris generally increased) This is primarily due to the fact thatserialization generally increases switching activity The buscapacitance is actually reduced partially since the wires arespaced out further to allow the frequency to be doubledHowever this reduction in capacitance is not enough to offsetthe increased switching activity The widening (W) approachperforms very well since it reduces the bus wire capacitancesignificantly The disadvantage of the approach is that italmost doubles the bus area There are six different encodingtechniques (E) that are tested (seeTable 6) Figure 6 shows theresult from the best encoding technique for each architectureconfiguration Encoding reduces switching activity withoutaffecting the bus capacitance and so does minimizing thebus power This approach does not change the bus area orfrequency
When using combinations of the three approaches theserialized-widened-encoded (SWE) method performs thebest The serialized-widened (SW) approach reduces the buscapacitance by widening the wire spacing but generallyincreases the switching activity through serializationThe net
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
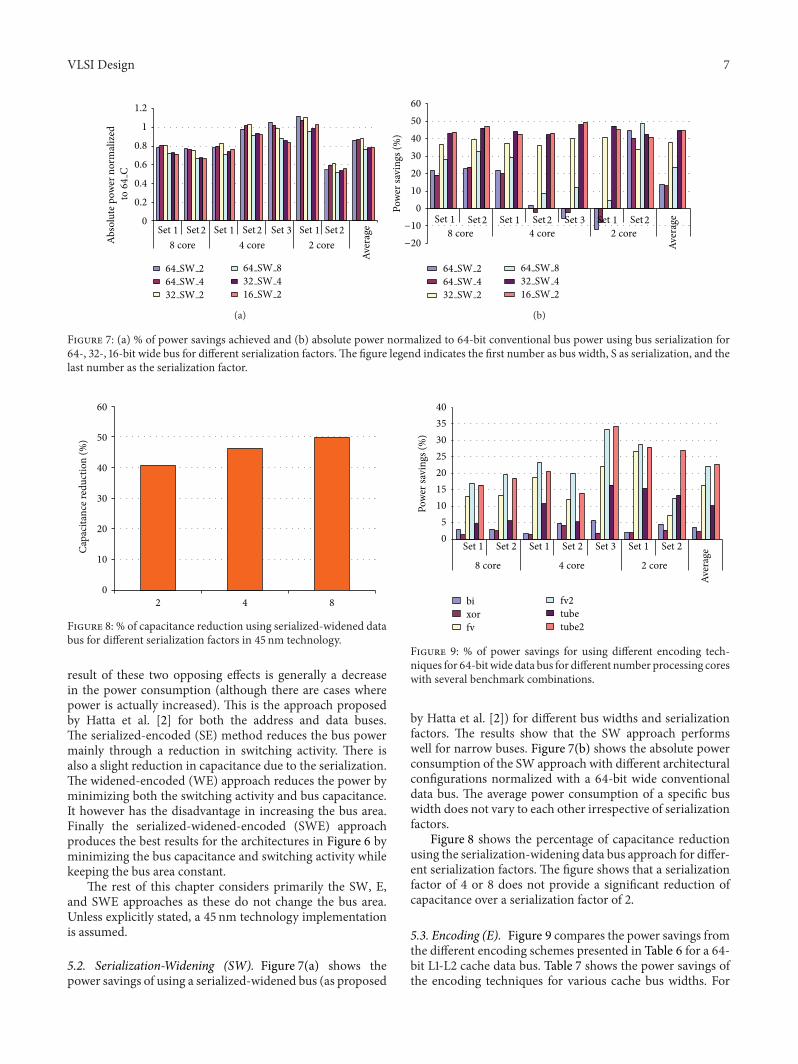
VLSI Design 7
0
02
04
06
08
1
12
8 core 4 core 2 core
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
Set2 Set2 Set2Set 1 Set 1Set 1 Set 3
Abso
lute
pow
er n
orm
aliz
ed64
C to
(a)
Aver
age
64 SW 2
64 SW 4
32 SW 2
64 SW 8
32 SW 4
16 SW 2
minus20
minus10
0
10
20
30
40
50
60
Pow
er sa
ving
s (
)
8 core 4 core 2 coreSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 7 (a) of power savings achieved and (b) absolute power normalized to 64-bit conventional bus power using bus serialization for64- 32- 16-bit wide bus for different serialization factorsThe figure legend indicates the first number as bus width S as serialization and thelast number as the serialization factor
0
10
20
30
40
50
60
2 4 8
Capa
cita
nce r
educ
tion
()
Figure 8 of capacitance reduction using serialized-widened databus for different serialization factors in 45 nm technology
result of these two opposing effects is generally a decreasein the power consumption (although there are cases wherepower is actually increased) This is the approach proposedby Hatta et al [2] for both the address and data busesThe serialized-encoded (SE) method reduces the bus powermainly through a reduction in switching activity There isalso a slight reduction in capacitance due to the serializationThe widened-encoded (WE) approach reduces the power byminimizing both the switching activity and bus capacitanceIt however has the disadvantage in increasing the bus areaFinally the serialized-widened-encoded (SWE) approachproduces the best results for the architectures in Figure 6 byminimizing the bus capacitance and switching activity whilekeeping the bus area constant
The rest of this chapter considers primarily the SW Eand SWE approaches as these do not change the bus areaUnless explicitly stated a 45 nm technology implementationis assumed
52 Serialization-Widening (SW) Figure 7(a) shows thepower savings of using a serialized-widened bus (as proposed
0
5
10
15
20
25
30
35
40
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 3
8 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
bixorfv
fv2tube
2tube
Figure 9 of power savings for using different encoding tech-niques for 64-bitwide data bus for different number processing coreswith several benchmark combinations
by Hatta et al [2]) for different bus widths and serializationfactors The results show that the SW approach performswell for narrow buses Figure 7(b) shows the absolute powerconsumption of the SW approach with different architecturalconfigurations normalized with a 64-bit wide conventionaldata bus The average power consumption of a specific buswidth does not vary to each other irrespective of serializationfactors
Figure 8 shows the percentage of capacitance reductionusing the serialization-widening data bus approach for differ-ent serialization factors The figure shows that a serializationfactor of 4 or 8 does not provide a significant reduction ofcapacitance over a serialization factor of 2
53 Encoding (E) Figure 9 compares the power savings fromthe different encoding schemes presented in Table 6 for a 64-bit L1-L2 cache data bus Table 7 shows the power savings ofthe encoding techniques for various cache bus widths For
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
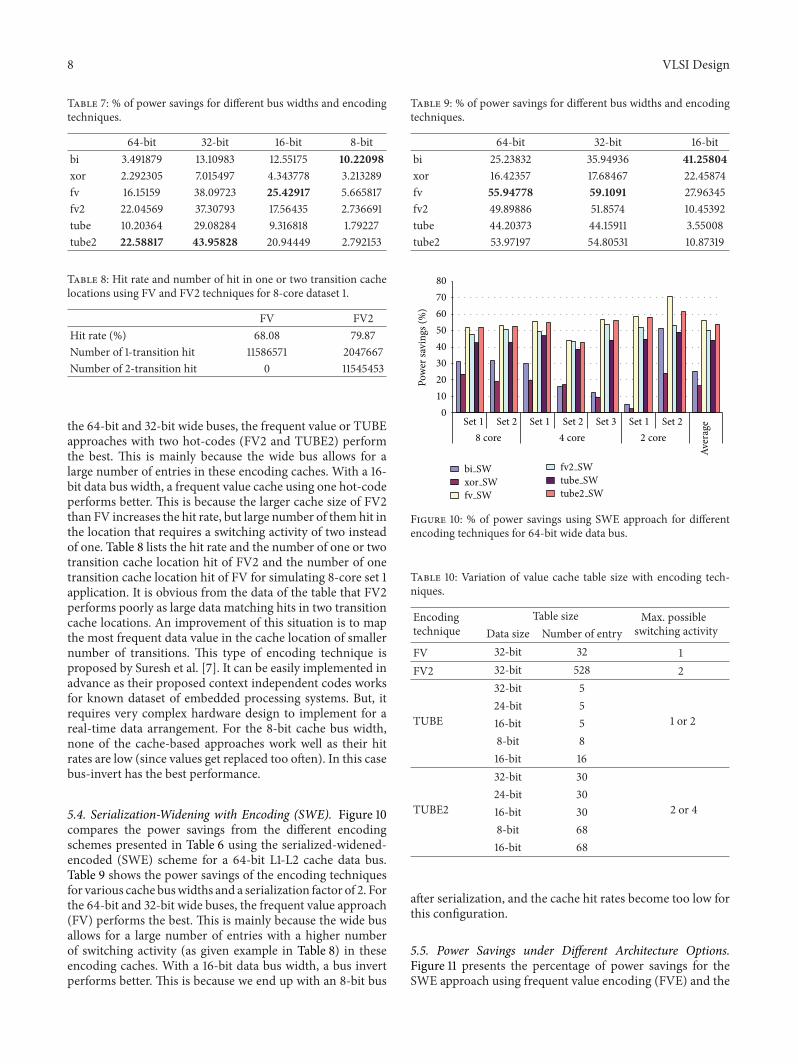
8 VLSI Design
Table 7 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bit 8-bitbi 3491879 1310983 1255175 1022098xor 2292305 7015497 4343778 3213289fv 1615159 3809723 2542917 5665817fv2 2204569 3730793 1756435 2736691tube 1020364 2908284 9316818 179227tube2 2258817 4395828 2094449 2792153
Table 8 Hit rate and number of hit in one or two transition cachelocations using FV and FV2 techniques for 8-core dataset 1
FV FV2Hit rate () 6808 7987Number of 1-transition hit 11586571 2047667Number of 2-transition hit 0 11545453
the 64-bit and 32-bit wide buses the frequent value or TUBEapproaches with two hot-codes (FV2 and TUBE2) performthe best This is mainly because the wide bus allows for alarge number of entries in these encoding caches With a 16-bit data bus width a frequent value cache using one hot-codeperforms better This is because the larger cache size of FV2than FV increases the hit rate but large number of them hit inthe location that requires a switching activity of two insteadof one Table 8 lists the hit rate and the number of one or twotransition cache location hit of FV2 and the number of onetransition cache location hit of FV for simulating 8-core set 1application It is obvious from the data of the table that FV2performs poorly as large data matching hits in two transitioncache locations An improvement of this situation is to mapthe most frequent data value in the cache location of smallernumber of transitions This type of encoding technique isproposed by Suresh et al [7] It can be easily implemented inadvance as their proposed context independent codes worksfor known dataset of embedded processing systems But itrequires very complex hardware design to implement for areal-time data arrangement For the 8-bit cache bus widthnone of the cache-based approaches work well as their hitrates are low (since values get replaced too often) In this casebus-invert has the best performance
54 Serialization-Widening with Encoding (SWE) Figure 10compares the power savings from the different encodingschemes presented in Table 6 using the serialized-widened-encoded (SWE) scheme for a 64-bit L1-L2 cache data busTable 9 shows the power savings of the encoding techniquesfor various cache buswidths and a serialization factor of 2 Forthe 64-bit and 32-bit wide buses the frequent value approach(FV) performs the best This is mainly because the wide busallows for a large number of entries with a higher numberof switching activity (as given example in Table 8) in theseencoding caches With a 16-bit data bus width a bus invertperforms better This is because we end up with an 8-bit bus
Table 9 of power savings for different bus widths and encodingtechniques
64-bit 32-bit 16-bitbi 2523832 3594936 4125804xor 1642357 1768467 2245874fv 5594778 591091 2796345fv2 4989886 518574 1045392tube 4420373 4415911 355008tube2 5397197 5480531 1087319
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
0
10
20
30
40
50
60
70
80
Pow
er sa
ving
s (
)
bi SWxor SWfv SW
fv2 SWSWtube2 SWtube
Figure 10 of power savings using SWE approach for differentencoding techniques for 64-bit wide data bus
Table 10 Variation of value cache table size with encoding tech-niques
Encodingtechnique
Table size Max possibleswitching activityData size Number of entry
FV 32-bit 32 1FV2 32-bit 528 2
TUBE
32-bit 5
1 or 224-bit 516-bit 58-bit 816-bit 16
TUBE2
32-bit 30
2 or 424-bit 3016-bit 308-bit 6816-bit 68
after serialization and the cache hit rates become too low forthis configuration
55 Power Savings under Different Architecture OptionsFigure 11 presents the percentage of power savings for theSWE approach using frequent value encoding (FVE) and the
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
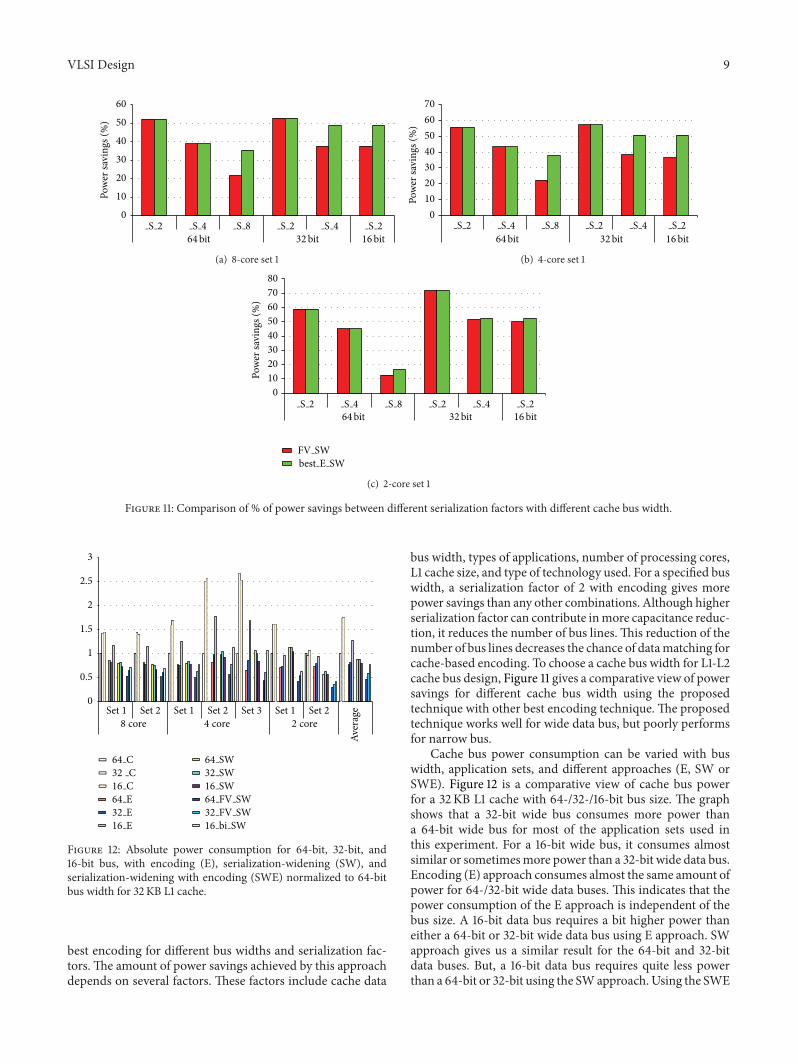
VLSI Design 9
0
10
20
30
40
50
60
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(a) 8-core set 1
0
10
20
30
40
50
60
70
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
(b) 4-core set 1
0
10
20
30
40
50
60
70
80
S 2 S 4 S 8 S 2 S 4 S 2
64bit 32bit 16bit
Pow
er sa
ving
s (
)
FV SWE SWbest
(c) 2-core set 1
Figure 11 Comparison of of power savings between different serialization factors with different cache bus width
64 C32 C16 C64 E32 E16 E
0
05
1
15
2
25
3
Set 1 Set 2 Set 1 Set 2Set 1 Set 2 Set 38 core 4 core 2 core
Aver
age
64 SW32 SW16 SW64 FV SW32 FV SW16 bi SW
Figure 12 Absolute power consumption for 64-bit 32-bit and16-bit bus with encoding (E) serialization-widening (SW) andserialization-widening with encoding (SWE) normalized to 64-bitbus width for 32KB L1 cache
best encoding for different bus widths and serialization fac-tors The amount of power savings achieved by this approachdepends on several factors These factors include cache data
bus width types of applications number of processing coresL1 cache size and type of technology used For a specified buswidth a serialization factor of 2 with encoding gives morepower savings than any other combinations Although higherserialization factor can contribute inmore capacitance reduc-tion it reduces the number of bus linesThis reduction of thenumber of bus lines decreases the chance of datamatching forcache-based encoding To choose a cache bus width for L1-L2cache bus design Figure 11 gives a comparative view of powersavings for different cache bus width using the proposedtechnique with other best encoding technique The proposedtechnique works well for wide data bus but poorly performsfor narrow bus
Cache bus power consumption can be varied with buswidth application sets and different approaches (E SW orSWE) Figure 12 is a comparative view of cache bus powerfor a 32KB L1 cache with 64-32-16-bit bus size The graphshows that a 32-bit wide bus consumes more power thana 64-bit wide bus for most of the application sets used inthis experiment For a 16-bit wide bus it consumes almostsimilar or sometimesmore power than a 32-bit wide data busEncoding (E) approach consumes almost the same amount ofpower for 64-32-bit wide data buses This indicates that thepower consumption of the E approach is independent of thebus size A 16-bit data bus requires a bit higher power thaneither a 64-bit or 32-bit wide data bus using E approach SWapproach gives us a similar result for the 64-bit and 32-bitdata buses But a 16-bit data bus requires quite less powerthan a 64-bit or 32-bit using the SWapproach Using the SWE
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
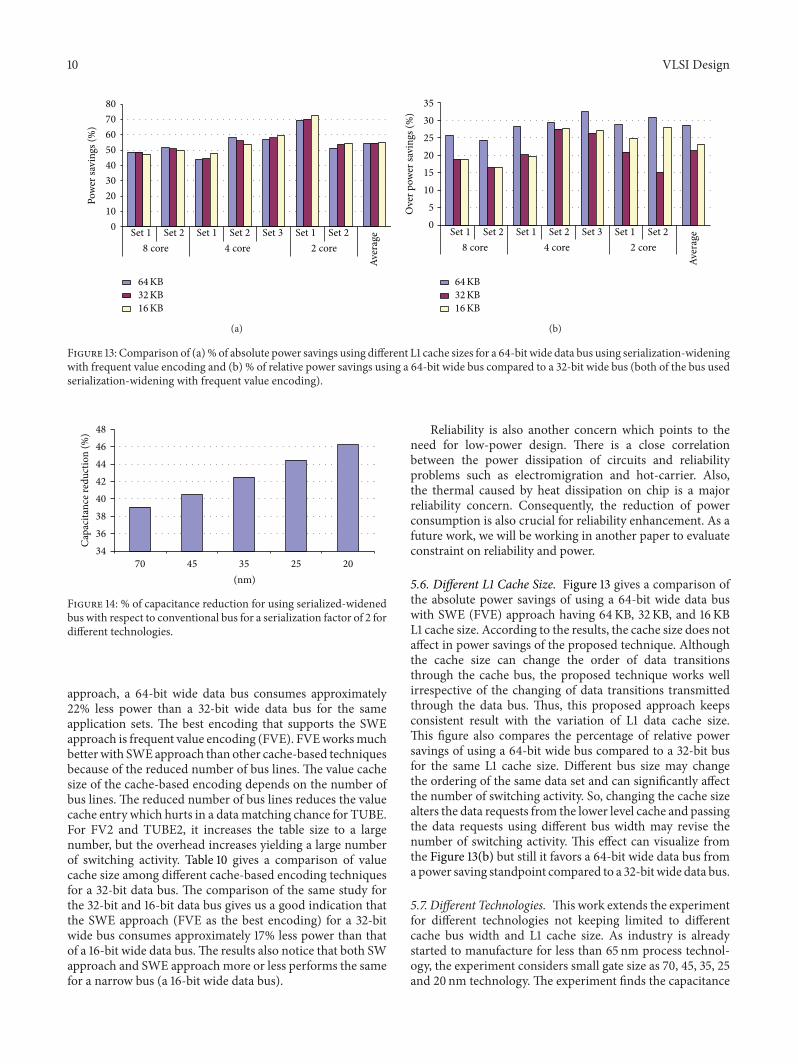
10 VLSI Design
0
10
20
30
40
50
60
70
80
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Pow
er sa
ving
s (
)
64KB32KB16KB
(a)
Set 1 Set 2 Set 1 Set 2 Set 1 Set 2Set 38 core 4 core 2 core
Aver
age
Ove
r pow
er sa
ving
s (
)
64KB32KB16KB
0
5
10
15
20
25
30
35
(b)
Figure 13 Comparison of (a) of absolute power savings using different L1 cache sizes for a 64-bit wide data bus using serialization-wideningwith frequent value encoding and (b) of relative power savings using a 64-bit wide bus compared to a 32-bit wide bus (both of the bus usedserialization-widening with frequent value encoding)
34
36
38
40
42
44
46
48
70 45 35 25 20
Capa
cita
nce r
educ
tion
()
(nm)
Figure 14 of capacitance reduction for using serialized-widenedbus with respect to conventional bus for a serialization factor of 2 fordifferent technologies
approach a 64-bit wide data bus consumes approximately22 less power than a 32-bit wide data bus for the sameapplication sets The best encoding that supports the SWEapproach is frequent value encoding (FVE) FVEworksmuchbetterwith SWEapproach than other cache-based techniquesbecause of the reduced number of bus lines The value cachesize of the cache-based encoding depends on the number ofbus lines The reduced number of bus lines reduces the valuecache entry which hurts in a datamatching chance for TUBEFor FV2 and TUBE2 it increases the table size to a largenumber but the overhead increases yielding a large numberof switching activity Table 10 gives a comparison of valuecache size among different cache-based encoding techniquesfor a 32-bit data bus The comparison of the same study forthe 32-bit and 16-bit data bus gives us a good indication thatthe SWE approach (FVE as the best encoding) for a 32-bitwide bus consumes approximately 17 less power than thatof a 16-bit wide data busThe results also notice that both SWapproach and SWE approach more or less performs the samefor a narrow bus (a 16-bit wide data bus)
Reliability is also another concern which points to theneed for low-power design There is a close correlationbetween the power dissipation of circuits and reliabilityproblems such as electromigration and hot-carrier Alsothe thermal caused by heat dissipation on chip is a majorreliability concern Consequently the reduction of powerconsumption is also crucial for reliability enhancement As afuture work we will be working in another paper to evaluateconstraint on reliability and power
56 Different L1 Cache Size Figure 13 gives a comparison ofthe absolute power savings of using a 64-bit wide data buswith SWE (FVE) approach having 64KB 32KB and 16KBL1 cache size According to the results the cache size does notaffect in power savings of the proposed technique Althoughthe cache size can change the order of data transitionsthrough the cache bus the proposed technique works wellirrespective of the changing of data transitions transmittedthrough the data bus Thus this proposed approach keepsconsistent result with the variation of L1 data cache sizeThis figure also compares the percentage of relative powersavings of using a 64-bit wide bus compared to a 32-bit busfor the same L1 cache size Different bus size may changethe ordering of the same data set and can significantly affectthe number of switching activity So changing the cache sizealters the data requests from the lower level cache and passingthe data requests using different bus width may revise thenumber of switching activity This effect can visualize fromthe Figure 13(b) but still it favors a 64-bit wide data bus fromapower saving standpoint compared to a 32-bit wide data bus
57 Different Technologies This work extends the experimentfor different technologies not keeping limited to differentcache bus width and L1 cache size As industry is alreadystarted to manufacture for less than 65 nm process technol-ogy the experiment considers small gate size as 70 45 35 25and 20 nm technology The experiment finds the capacitance
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
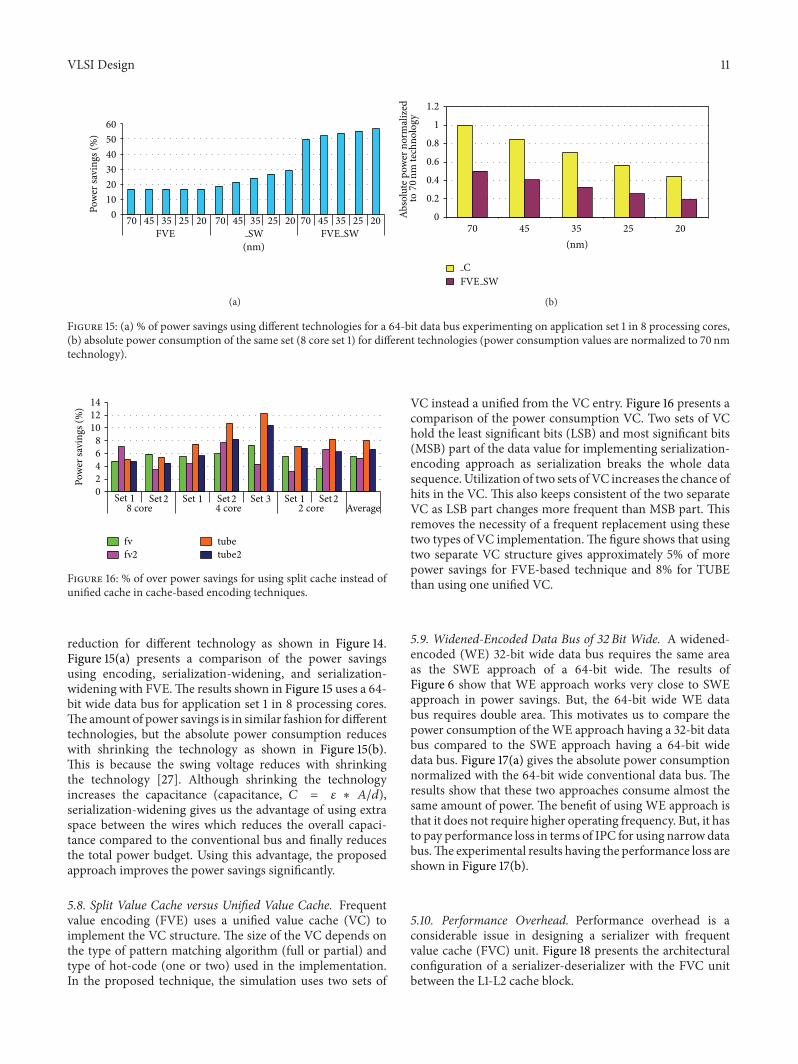
VLSI Design 11
70 45 35 25 20 70 45 35 25 20 70 45 35 25 20
60
50
40
30
20
10
0
(nm)FVE SW FVE SW
Pow
er sa
ving
s (
)
(a)
70 45 35 25 20
(nm)
FVE SW
0
02
04
06
08
1
12
70
nm te
chno
logy
toAb
solu
te p
ower
nor
mal
ized
C
(b)
Figure 15 (a) of power savings using different technologies for a 64-bit data bus experimenting on application set 1 in 8 processing cores(b) absolute power consumption of the same set (8 core set 1) for different technologies (power consumption values are normalized to 70 nmtechnology)
0
2
4
6
8
10
12
14
Pow
er sa
ving
s (
)
fvfv2
tubetube2
8 core 4 core 2 core AverageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
Figure 16 of over power savings for using split cache instead ofunified cache in cache-based encoding techniques
reduction for different technology as shown in Figure 14Figure 15(a) presents a comparison of the power savingsusing encoding serialization-widening and serialization-widening with FVEThe results shown in Figure 15 uses a 64-bit wide data bus for application set 1 in 8 processing coresThe amount of power savings is in similar fashion for differenttechnologies but the absolute power consumption reduceswith shrinking the technology as shown in Figure 15(b)This is because the swing voltage reduces with shrinkingthe technology [27] Although shrinking the technologyincreases the capacitance (capacitance 119862 = 120576 lowast 119860119889)serialization-widening gives us the advantage of using extraspace between the wires which reduces the overall capaci-tance compared to the conventional bus and finally reducesthe total power budget Using this advantage the proposedapproach improves the power savings significantly
58 Split Value Cache versus Unified Value Cache Frequentvalue encoding (FVE) uses a unified value cache (VC) toimplement the VC structure The size of the VC depends onthe type of pattern matching algorithm (full or partial) andtype of hot-code (one or two) used in the implementationIn the proposed technique the simulation uses two sets of
VC instead a unified from the VC entry Figure 16 presents acomparison of the power consumption VC Two sets of VChold the least significant bits (LSB) and most significant bits(MSB) part of the data value for implementing serialization-encoding approach as serialization breaks the whole datasequence Utilization of two sets of VC increases the chance ofhits in the VC This also keeps consistent of the two separateVC as LSB part changes more frequent than MSB part Thisremoves the necessity of a frequent replacement using thesetwo types of VC implementationThe figure shows that usingtwo separate VC structure gives approximately 5 of morepower savings for FVE-based technique and 8 for TUBEthan using one unified VC
59 Widened-Encoded Data Bus of 32 Bit Wide A widened-encoded (WE) 32-bit wide data bus requires the same areaas the SWE approach of a 64-bit wide The results ofFigure 6 show that WE approach works very close to SWEapproach in power savings But the 64-bit wide WE databus requires double area This motivates us to compare thepower consumption of theWE approach having a 32-bit databus compared to the SWE approach having a 64-bit widedata bus Figure 17(a) gives the absolute power consumptionnormalized with the 64-bit wide conventional data bus Theresults show that these two approaches consume almost thesame amount of power The benefit of using WE approach isthat it does not require higher operating frequency But it hasto pay performance loss in terms of IPC for using narrow databusThe experimental results having the performance loss areshown in Figure 17(b)
510 Performance Overhead Performance overhead is aconsiderable issue in designing a serializer with frequentvalue cache (FVC) unit Figure 18 presents the architecturalconfiguration of a serializer-deserializer with the FVC unitbetween the L1-L2 cache block
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
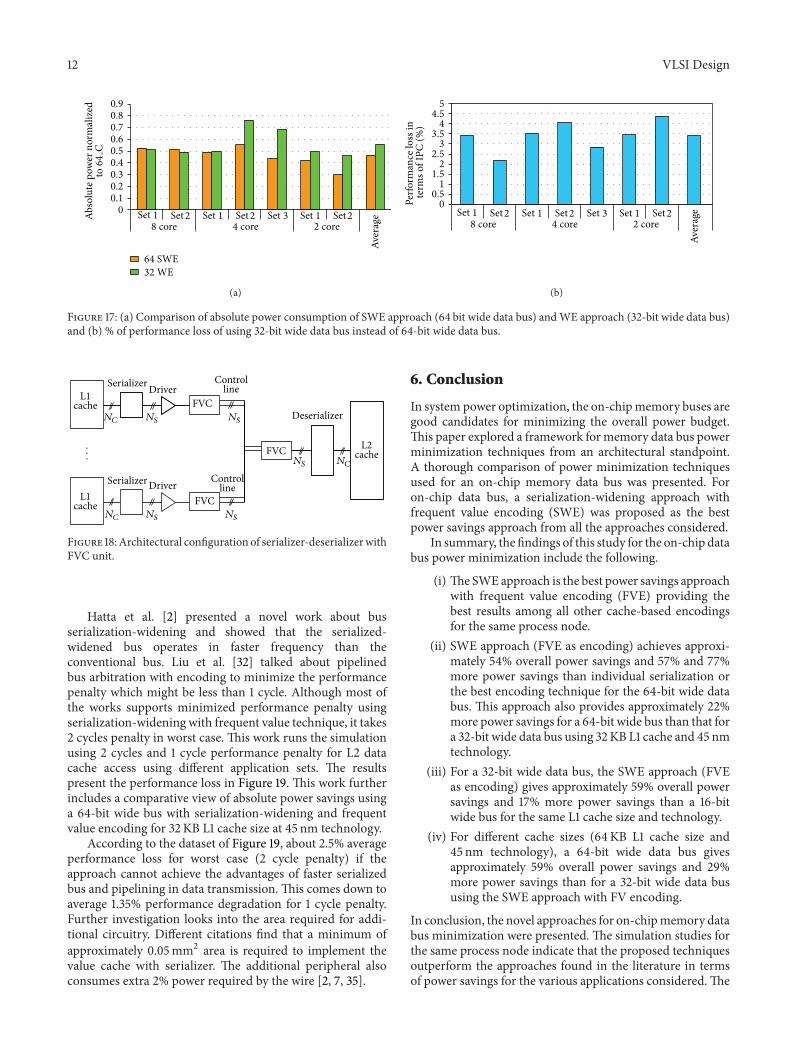
12 VLSI Design
0
01
02
03
04
05
06
07
08
09
64 SWE32 WE
Abso
lute
pow
er n
orm
aliz
ed64
Cto
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
0
05
1
15
2
25
3
35
4
45
5
Perfo
rman
ce lo
ss in
te
rms o
f IPC
()
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 17 (a) Comparison of absolute power consumption of SWE approach (64 bit wide data bus) andWE approach (32-bit wide data bus)and (b) of performance loss of using 32-bit wide data bus instead of 64-bit wide data bus
L1cache
L1cache
L2cache
Deserializer
NC
NC
NC
NS
NS NS
NS NS
FVC
FVC
FVC
Controlline
Controlline
Serializer
Serializer
Driver
Driver
Figure 18Architectural configuration of serializer-deserializerwithFVC unit
Hatta et al [2] presented a novel work about busserialization-widening and showed that the serialized-widened bus operates in faster frequency than theconventional bus Liu et al [32] talked about pipelinedbus arbitration with encoding to minimize the performancepenalty which might be less than 1 cycle Although most ofthe works supports minimized performance penalty usingserialization-widening with frequent value technique it takes2 cycles penalty in worst case This work runs the simulationusing 2 cycles and 1 cycle performance penalty for L2 datacache access using different application sets The resultspresent the performance loss in Figure 19 This work furtherincludes a comparative view of absolute power savings usinga 64-bit wide bus with serialization-widening and frequentvalue encoding for 32KB L1 cache size at 45 nm technology
According to the dataset of Figure 19 about 25 averageperformance loss for worst case (2 cycle penalty) if theapproach cannot achieve the advantages of faster serializedbus and pipelining in data transmission This comes down toaverage 135 performance degradation for 1 cycle penaltyFurther investigation looks into the area required for addi-tional circuitry Different citations find that a minimum ofapproximately 005mm2 area is required to implement thevalue cache with serializer The additional peripheral alsoconsumes extra 2 power required by the wire [2 7 35]
6 Conclusion
In system power optimization the on-chipmemory buses aregood candidates for minimizing the overall power budgetThis paper explored a framework formemory data bus powerminimization techniques from an architectural standpointA thorough comparison of power minimization techniquesused for an on-chip memory data bus was presented Foron-chip data bus a serialization-widening approach withfrequent value encoding (SWE) was proposed as the bestpower savings approach from all the approaches considered
In summary the findings of this study for the on-chip databus power minimization include the following
(i) The SWEapproach is the best power savings approachwith frequent value encoding (FVE) providing thebest results among all other cache-based encodingsfor the same process node
(ii) SWE approach (FVE as encoding) achieves approxi-mately 54 overall power savings and 57 and 77more power savings than individual serialization orthe best encoding technique for the 64-bit wide databus This approach also provides approximately 22more power savings for a 64-bit wide bus than that fora 32-bit wide data bus using 32KB L1 cache and 45 nmtechnology
(iii) For a 32-bit wide data bus the SWE approach (FVEas encoding) gives approximately 59 overall powersavings and 17 more power savings than a 16-bitwide bus for the same L1 cache size and technology
(iv) For different cache sizes (64KB L1 cache size and45 nm technology) a 64-bit wide data bus givesapproximately 59 overall power savings and 29more power savings than for a 32-bit wide data bususing the SWE approach with FV encoding
In conclusion the novel approaches for on-chipmemory databus minimization were presented The simulation studies forthe same process node indicate that the proposed techniquesoutperform the approaches found in the literature in termsof power savings for the various applications consideredThe
VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 13
Performance loss ()
0
05
1
15
2
25
3
35
4
2 cycles1 cycle
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(a)
Power savings ()
0
10
20
30
40
50
60
70
8 core 4 core 2 core
Aver
ageSet2 Set2 Set2Set 1 Set 1Set 1 Set 3
(b)
Figure 19 (a) of performance degradation in term of instruction per cycle (IPC) for using 64-bit serialized bus with encoding for 21 cycleperformance penalty instead of using conventional bus and (b) of power savings
work in this paper primarily involved the software simulationof the proposed techniques for bus power minimizationconsidering performance overhead As far as future work wewill continue to evaluate the proposed approach with lowerprocess node (14 and 10 nm) for reliability especially with newprocess
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
References
[1] M R Stan and K Skadron ldquoPower-aware computingrdquo IEEEComputer vol 36 no 12 pp 35ndash38 2003
[2] N Hatta N D Barli C Iwama et al ldquoBus serialization forreducing power consumptionrdquo Proceedings of SWoPP 2004
[3] B Jacob and V Cuppu ldquoOrganizational design trade-offs atthe DRAM memory bus and memory controller level initialresultsrdquo Tech Rep UMD-SCA-TR-1999-2 University of Mary-land Systems amp Computer Architecture Group 1999
[4] Rambus Inc Rambus Signaling Technologies RSL QRSL andSerDes Technology Overview Rambus Inc 2000
[5] M Loghi M Poncino and L Benini ldquoCycle-accurate poweranalysis for multiprocessor systems-on-a-chiprdquo in Proceedingsof the ACM Great lakes Symposium on VLSI pp 401ndash406 April2004
[6] K Mohanram and S Rixner ldquoContext-independent codes foroff-chip interconnectsrdquo in Power-Aware Computer Systems vol3471 of Lecture Notes in Computer Science pp 107ndash119 2005
[7] D C Suresh B Agrawal W A Najjar and J Yang ldquoVALVEvariable Length Value Encoder for off-chip data busesrdquo inProceedings of the International Conference on Computer Design(ICCD rsquo05) pp 631ndash633 San Jose Calif USA October 2005
[8] M R Stan and W P Burleson ldquoCoding a terminated bus forlow powerrdquo in Proceedings of the 5th Great Lakes Symposium onVLSI pp 70ndash73 March 1995
[9] K Basu A Choudhury J Pisharath and M Kandemir ldquoPowerprotocol reducing power dissipation on off-chip data busesrdquo
in Proceedings of the 35th Annual ACMIEEE InternationalSymposium on Microarchitecture pp 345ndash355 2002
[10] N R Mahapatra J Liu K Sundaresan S Dangeti and B VVenkatrao ldquoA limit study on the potential of compression forimproving memory system performance power consumptionand costrdquo Journal of Instruction-Level Parallelism vol 7 pp 1ndash372005
[11] A Park and M Farrens ldquoAddress compression through baseregister cachingrdquo in Proceedings of the Annual ACMIEEEInternational Symposium on Microarchitecture pp 193ndash199November 1990
[12] M Farrens and A Park ldquoDynamic base register caching atechnique for reducing address bus widthrdquo in Proceedings ofthe 18th International Symposium on Computer Architecture pp128ndash137 May 1991
[13] D Citron and L Rudolph ldquoCreating a wider bus using cachingtechniquesrdquo in Proceedings of the International Symposium onHigh Performance Computer Architecture pp 90ndash99 January1995
[14] K Sunderasan and N Mahapatra ldquoCode compression tech-niques for embedded systems and their effectivenessrdquo in Pro-ceedings of the IEEE Computer Society Annual Symposium onVLSI pp 262ndash263 February 2003
[15] L Li N Vijaykrishnan M Kandemir M J Irwin and IKadayif ldquoCCC crossbar connected caches for reducing energyconsumption of on-chip multiprocessorsrdquo in Proceedings of theEuromicro Symposium on Digital Systems Design (DSD rsquo03)2003
[16] P P Sotiriadis and A P Chandrakasan ldquoA bus energymodel fordeep submicron technologyrdquo IEEE Transactions on Very LargeScale Integration (VLSI) Systems vol 10 no 3 pp 341ndash349 2002
[17] P P Sotiriadis and A Chandrakasan ldquoLow power bus codingtechniques considering inter-wire capacitancesrdquo in Proceedingsof the IEEE 22nd Annual Custom Integrated Circuits Conference(CICC rsquo00) pp 507ndash510 May 2000
[18] J Henkel and H Lekatsas ldquoA2BC adaptive address bus codingfor low power deep sub-micron designsrdquo in Proceedings of theIEEE 38th Design Automation Conference pp 744ndash749 June2001
[19] T Lindkvist ldquoAdditional knowledge of bus invert codingschemesrdquo in Proceedings of the IEEE 5th InternationalWorkshopon System-on-Chip for Real-Time Applications (IWSOC rsquo05) pp301ndash303 Alberta Canada July 2005
14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

14 VLSI Design
[20] T Lindkvist J Lofvenberg and O Gustafsson ldquoDeep sub-micron bus invert codingrdquo in Proceedings of the 6th NordicSignal Processing Symposium (NORSIG rsquo04) pp 133ndash136 EspooFinland June 2004
[21] K-W Kim K-H Baek N Shanbhag C L Liu and S-MKang ldquoCoupling-driven signal encoding scheme for low-powerinterface designrdquo in Proceedings of the IEEEACM InternationalConference on Computer-Aided Design pp 318ndash321 San JoseCalif USA 2000
[22] S Komatsu M Ikeda and K Asada ldquoBus power encoding withcoupling-driven adaptive code-book method for low powerdata transmissionrdquo in Proceedings of the European Solid-StateCircuits Conference 2001
[23] J-H Chern J Huang L Arledge P-C Li and P YangldquoMultilevel metal capacitance models for CAD design synthesissystemsrdquo Electron Device Letters vol 13 no 1 pp 32ndash34 1992
[24] K Mohammad A Dodin B Liu and S Agaian ldquoReducedvoltage scaling in clock distribution networksrdquoVLSIDesign vol2009 Article ID 679853 7 pages 2009
[25] K Mohammad B Liu and S Agaian ldquoEnergy efficient swingsignal generation circuits for clock distribution networks sys-temsrdquo in Proceedings of the IEEE International Conference onMan and Cybernetics pp 3495ndash3498 2009
[26] K Mohammad S Agaian and F Hudson ldquoEfficient FPGAimplementation of convolutionrdquo in Proceedings of the IEEEInternational Conference on Systems Man and Cybernetics SanAntonio Tex USA October 2009 paper ID 3922
[27] ldquoInternational Technology Roadmap for Semiconductorsrdquohttpwwwitrsnet
[28] H Kawaguchi and T Sakurai ldquoDelay and noise formulas forcapacitively coupled distributed RC linesrdquo in Proceedings of the3rd Conference of the Asia and South Pacific Design Automation(ASP-DAC rsquo98) pp 35ndash43 February 1998
[29] C-L Su C-Y Tsui and A M Despain ldquoSaving power in thecontrol path of embedded processorsrdquo IEEE Design and Test ofComputers vol 11 no 4 pp 24ndash30 1994
[30] M R Stan and W P Burleson ldquoBus-invert coding for low-power IOrdquo IEEE Transactions on VLSI Systems vol 3 no 1 pp49ndash58 1995
[31] L Benini G de Micheli E Macii D Sciuto and C Sil-vano ldquoAsymptotic zero-transition activity encoding for addressbusses in low-power microprocessor-based systemsrdquo in Pro-ceedings of the 7th Great Lakes Symposium on VLSI pp 77ndash82March 1997
[32] C Liu A Sivasubramaniam and M Kandemir ldquoOptimizingbus energy consumption of on-chip multiprocessors usingfrequent valuesrdquo inProceedings of the 12th Euromicro Conferenceon Parallel Distributed and Network-based Proceedings (PDPrsquo04) pp 340ndash347 February 2004
[33] J Yang and R Gupta ldquoFrequent value locality and its applica-tionsrdquoACMTransactions on Embedded Computing Systems vol1 no 1 pp 79ndash105 2002
[34] J Yang R Gupta and C Zhang ldquoFrequent value encoding forlow power data busesrdquo ACM Transactions on Design Automa-tion of Electronic Systems vol 9 no 3 pp 354ndash384 2004
[35] D C Suresh B Agrawal J Yang and W Najjar ldquoA tunablebus encoder for off-chip data busesrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 319ndash322 San Diego Calif USA August 2005
[36] W-C Cheng and M Pedram ldquoMemory bus encoding for lowpower a tutorialrdquo in Proceedings of the International Symposiumon Quality Electronic Design (ISQED rsquo01) p 1999 2001
[37] T Lang EMusoll and J Cortadella ldquoExtension of theworking-zone-encoding method to reduce the energy on the micro-processor data busrdquo in Proceedings of the IEEE InternationalConference on Computer Design pp 414ndash419 October 1998
[38] L Benini G de Micheli E Macii M Poncino and S QuerldquoSystem-level power optimization of special purpose applica-tions the beach solutionrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design pp 24ndash29Monterey Calif USA August 1997
[39] L Benini G DeMicheli E Macii M Poncino and C SilvanoldquoAddress bus encoding techniques for system level poweroptimizationrdquo in Proceeding of the Design Automation and Testin Europe pp 861ndash866 Paris France February 1998
[40] N Chang K Kim and J Cho ldquoBus encoding for low-powerhigh-performance memory systemsrdquo in Proceedings of the 37thDesign Automation Conference (DAC rsquo00) pp 800ndash805 June2000
[41] W-C Cheng and M Pedram ldquoPower-optimal encoding forDRAM address busrdquo in Proceedings of the Symposium on LowPower Electronics and Design (ISLPED rsquo00) pp 250ndash252 July2000
[42] S Ramprasad N R Shanbhag and I N Hajj ldquoA codingframework for low-power address and data bussesrdquo IEEETransactions on Very Large Scale Integration (VLSI) Systems vol7 no 2 pp 212ndash221 1999
[43] E Musoll T Lang and J Cortadella ldquoExploiting the localityof memory references to reduce the address bus energyrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 202ndash207 Monterey Calif USAAugust 1997
[44] Y Shin S-I Chae and K Choi ldquoPartial bus-invert coding forpower optimization of system level busrdquo in Proceedings of theInternational Symposium on Low Power Electronics and Designpp 127ndash129 August 1998
[45] M R Stan andW P Burleson ldquoTwo-dimensional codes for lowpowerrdquo in Proceedings of the International Symposium on LowPower Electronics and Design pp 335ndash340 August 1996
[46] S Yoo and K Choi ldquoInterleaving partial bus-invert coding forlow power reconfiguration of FPGAsrdquo in Proceedings of the 6thInternational Conference on VLSI and CAD pp 549ndash552 1999
[47] C Lee M Potkonjak and W H Mangione-Smith ldquoMedia-Bench a tool for evaluating and synthesizing multimedia andcommunications systemsrdquo in Proceedings of the 30th AnnualIEEEACM International Symposium on Microarchitecture pp330ndash335 December 1997
[48] SimpleScalar Simulator ldquoSimpleScalar LLCrdquo httpwwwsim-plescalarcom
[49] SPEC ldquoSPEC CPU2000 Benchmark Suite Ver 12rdquo httpwwwspecorgosgcpu2000
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of


















