
Reproducible Research in the Mathematical Sciencesvcs/papers/PCAM_20140620-VCS.pdf · Python, and...
12
Reproducible Research in the Mathematical Sciences 1 D. Donoho, V. Stodden Department of Statistics, Stanford University Stanford, CA 94305 Department of Statistics, Columbia University New York, NY 10027 1 Introduction Traditionally, mathematical research was con- ducted via mental abstraction and manual sym- bolic manipulation. Mathematical journals pub- lished theorems and completed proofs, while other sorts of evidence were gathered privately and remained in shadow. For example, long af- ter Riemann had passed away, historians discov- ered that he had developed advanced techniques for calculating the Riemann zeta function, and that his formulation of the Riemann hypothesis – often depicted as a triumph of pure thought – was actually based on painstaking numerical work. In fact Riemann’s computational methods remained for decades after his death far ahead of what was available to others. This example shows that mathematical researchers have been ‘covering their (computational) tracks’ for a long time. Times have been changing: on the one hand, Mathematics has grown into the so-called Math- ematical Sciences, and in this larger endeavor, proposing new computational methods takes cen- ter stage, and documenting the behavior of pro- posed methods in test cases became an important part of research activity - witness current pub- lications throughout the mathematical sciences, including statistics, optimization, and computer science. On the other hand, even pure mathemat- ics has been a↵ected by the trend towards com- putational evidence; Tom Hales’ brilliant article Mathematics in the Age of the Turing Machine points to several examples of important mathe- matical regularities that were discovered empir- ically and have driven much mathematical re- search subsequently, the Birch and Swinnerton- Dyer conjecture being his lead example. This 1 We would like to thank Jennifer Seiler for outstanding research assistance. conjecture posits deep relationships between the zeta function of elliptic curves and the rank of el- liptic curves, and was discovered by counting the number of rational points on individual elliptic curves in the early 1960’s. We can expect that over time, an ever- increasing fraction of what we know about math- ematical structures will be based on computa- tional experiments, either because our work (in applied areas) is explicitly about the behavior of computations, or because (in pure mathematics) the leading questions of the day concern empirical regularities uncovered computationally. Indeed, with the advent of cluster comput- ing, cloud computing, GPU processor boards and other computing innovations, it is now possible for a researcher to direct overwhelming amounts of computational power at specific problems. With the advent of mathematical programming environments like Mathematica, MATLAB, and Sage, it is possible to easily prototype algorithms which can then be quickly scaled up using the cloud. Such direct access to computational power is an irresistible force. Reflect for a moment on the fact that the Birch and Swinnerton-Dyer conjecture was discovered using the rudimentary computational resources of the early 1960’s. Re- search in the mathematical sciences can now be dramatically more ambitious in scale and scope. This opens very exciting possibilities for discovery and exploration, as explained in experimental applied mathematics [VIII.xy]. The expected scaling up of experimental and computational mathematics is, at the same time, problematic. Much of the knowledge currently being generated using computers is not of the same quality as traditional mathematical knowl- edge. Mathematicians are very strict and de- manding when it comes to understanding the ba- sis of a theorem, the assumptions used, the prior theorems on which it depends, and the chain of in- ference that establishes the theorem. As it stands, the way evidence based on computations is typi- cally published leaves ‘a great deal to the imag- ination’ and so computational evidence simply does not have the same epistemological status as a rigorously proved theorem. Algorithms are becoming ever more compli- cated. Figure 1 shows the number of lines of 1
Transcript of Reproducible Research in the Mathematical Sciencesvcs/papers/PCAM_20140620-VCS.pdf · Python, and...

Reproducible Research in the
Mathematical Sciences
1
D. Donoho, V. Stodden
Department of Statistics, Stanford UniversityStanford, CA 94305
Department of Statistics, Columbia UniversityNew York, NY 10027
1 Introduction
Traditionally, mathematical research was con-ducted via mental abstraction and manual sym-bolic manipulation. Mathematical journals pub-lished theorems and completed proofs, whileother sorts of evidence were gathered privatelyand remained in shadow. For example, long af-ter Riemann had passed away, historians discov-ered that he had developed advanced techniquesfor calculating the Riemann zeta function, andthat his formulation of the Riemann hypothesis– often depicted as a triumph of pure thought– was actually based on painstaking numericalwork. In fact Riemann’s computational methodsremained for decades after his death far aheadof what was available to others. This exampleshows that mathematical researchers have been‘covering their (computational) tracks’ for a longtime.Times have been changing: on the one hand,
Mathematics has grown into the so-called Math-ematical Sciences, and in this larger endeavor,proposing new computational methods takes cen-ter stage, and documenting the behavior of pro-posed methods in test cases became an importantpart of research activity - witness current pub-lications throughout the mathematical sciences,including statistics, optimization, and computerscience. On the other hand, even pure mathemat-ics has been a↵ected by the trend towards com-putational evidence; Tom Hales’ brilliant articleMathematics in the Age of the Turing Machinepoints to several examples of important mathe-matical regularities that were discovered empir-ically and have driven much mathematical re-search subsequently, the Birch and Swinnerton-Dyer conjecture being his lead example. This
1We would like to thank Jennifer Seiler for outstandingresearch assistance.
conjecture posits deep relationships between thezeta function of elliptic curves and the rank of el-liptic curves, and was discovered by counting thenumber of rational points on individual ellipticcurves in the early 1960’s.
We can expect that over time, an ever-increasing fraction of what we know about math-ematical structures will be based on computa-tional experiments, either because our work (inapplied areas) is explicitly about the behavior ofcomputations, or because (in pure mathematics)the leading questions of the day concern empiricalregularities uncovered computationally.
Indeed, with the advent of cluster comput-ing, cloud computing, GPU processor boards andother computing innovations, it is now possiblefor a researcher to direct overwhelming amountsof computational power at specific problems.With the advent of mathematical programmingenvironments like Mathematica, MATLAB, andSage, it is possible to easily prototype algorithmswhich can then be quickly scaled up using thecloud. Such direct access to computational poweris an irresistible force. Reflect for a momenton the fact that the Birch and Swinnerton-Dyerconjecture was discovered using the rudimentarycomputational resources of the early 1960’s. Re-search in the mathematical sciences can now bedramatically more ambitious in scale and scope.This opens very exciting possibilities for discoveryand exploration, as explained in experimental
applied mathematics [VIII.xy].
The expected scaling up of experimental andcomputational mathematics is, at the same time,problematic. Much of the knowledge currentlybeing generated using computers is not of thesame quality as traditional mathematical knowl-edge. Mathematicians are very strict and de-manding when it comes to understanding the ba-sis of a theorem, the assumptions used, the priortheorems on which it depends, and the chain of in-ference that establishes the theorem. As it stands,the way evidence based on computations is typi-cally published leaves ‘a great deal to the imag-ination’ and so computational evidence simplydoes not have the same epistemological status asa rigorously proved theorem.
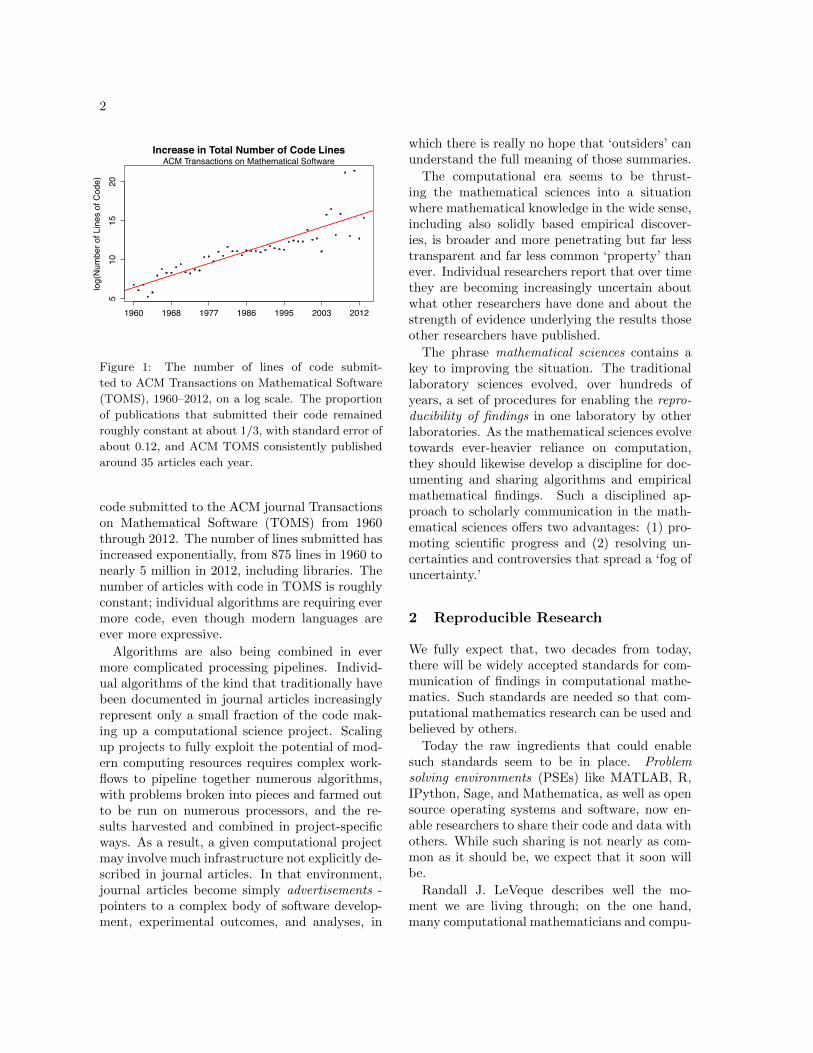
Algorithms are becoming ever more compli-cated. Figure 1 shows the number of lines of
1
2
Increase in Total Number of Code Lines
log(
Num
ber o
f Lin
es o
f Cod
e)
ACM Transactions on Mathematical Software
1960 1968 1977 1986 1995 2003 2012
510
1520
Figure 1: The number of lines of code submit-
ted to ACM Transactions on Mathematical Software
(TOMS), 1960–2012, on a log scale. The proportion
of publications that submitted their code remained
roughly constant at about 1/3, with standard error of
about 0.12, and ACM TOMS consistently published
around 35 articles each year.
code submitted to the ACM journal Transactionson Mathematical Software (TOMS) from 1960through 2012. The number of lines submitted hasincreased exponentially, from 875 lines in 1960 tonearly 5 million in 2012, including libraries. Thenumber of articles with code in TOMS is roughlyconstant; individual algorithms are requiring evermore code, even though modern languages areever more expressive.Algorithms are also being combined in ever
more complicated processing pipelines. Individ-ual algorithms of the kind that traditionally havebeen documented in journal articles increasinglyrepresent only a small fraction of the code mak-ing up a computational science project. Scalingup projects to fully exploit the potential of mod-ern computing resources requires complex work-flows to pipeline together numerous algorithms,with problems broken into pieces and farmed outto be run on numerous processors, and the re-sults harvested and combined in project-specificways. As a result, a given computational projectmay involve much infrastructure not explicitly de-scribed in journal articles. In that environment,journal articles become simply advertisements -pointers to a complex body of software develop-ment, experimental outcomes, and analyses, in
which there is really no hope that ‘outsiders’ canunderstand the full meaning of those summaries.
The computational era seems to be thrust-ing the mathematical sciences into a situationwhere mathematical knowledge in the wide sense,including also solidly based empirical discover-ies, is broader and more penetrating but far lesstransparent and far less common ‘property’ thanever. Individual researchers report that over timethey are becoming increasingly uncertain aboutwhat other researchers have done and about thestrength of evidence underlying the results thoseother researchers have published.
The phrase mathematical sciences contains akey to improving the situation. The traditionallaboratory sciences evolved, over hundreds ofyears, a set of procedures for enabling the repro-ducibility of findings in one laboratory by otherlaboratories. As the mathematical sciences evolvetowards ever-heavier reliance on computation,they should likewise develop a discipline for doc-umenting and sharing algorithms and empiricalmathematical findings. Such a disciplined ap-proach to scholarly communication in the math-ematical sciences o↵ers two advantages: (1) pro-moting scientific progress and (2) resolving un-certainties and controversies that spread a ‘fog ofuncertainty.’
2 Reproducible Research
We fully expect that, two decades from today,there will be widely accepted standards for com-munication of findings in computational mathe-matics. Such standards are needed so that com-putational mathematics research can be used andbelieved by others.
Today the raw ingredients that could enablesuch standards seem to be in place. Problemsolving environments (PSEs) like MATLAB, R,IPython, Sage, and Mathematica, as well as opensource operating systems and software, now en-able researchers to share their code and data withothers. While such sharing is not nearly as com-mon as it should be, we expect that it soon willbe.
Randall J. LeVeque describes well the mo-ment we are living through; on the one hand,many computational mathematicians and compu-

3
tational scientists do not work reproducibly (LeV-eque, 2006):
Even brilliant and well intentionedcomputational scientists often do a poorjob of presenting their work in a repro-ducible manner. The methods are of-ten very vaguely defined, and even ifthey are carefully defined they wouldnormally have to be implemented fromscratch by the reader in order to testthem. Most modern algorithms are socomplicated that there is little hope ofdoing this properly . . .
On the other hand, LeVeque continues, the in-gredients exist:
The idea of “reproducible research”in scientific computing is to archive andmake publicly available all of the codesused to create the figures or tables in apaper in such a way that the reader candownload the codes and run them to re-produce the results. The program canthen be examined to see exactly whathas been done. The development of veryhigh level programming languages hasmade it easier to share codes and gen-erate reproducible research. ... Thesedays many algorithms can be written inlanguages such as MATLAB in a waythat is both easy for the reader to com-prehend and also executable, with alldetails intact.”
While the technology needed for reproducibleresearch exists today, mathematical scientistsdon’t yet agree on exactly how to use this tech-nology in a disciplined way. As we write this ar-ticle there is a great deal of activity to define andpromote standards for reproducible research incomputational mathematics.A number of publications address reproducibil-
ity and verification in computational mathemat-ics; topics covered include: computational scaleand proof checking, probabilistic model check-ing, verification of numerical solutions, standardmethods in uncertainty quantification, and repro-ducibility in computational research. This is notan exhaustive account of the literature in these
areas of course, merely a starting point for fur-ther investigation.
In this article we review some of the availabletools that can enable reproducible research, andconclude with a series of “best practice” recom-mendations based on modern examples and re-search methods.
3 Script Sharing Based on PSEs
3.1 PSEs O↵er Power and Simplicity
A key precondition for reproducible computa-tional research is the ability for researchers to runthe code that generated results in some publishedpaper of interest. Traditionally this has beenproblematic. Often researchers were unpreparedor unwilling to share code, and even if they didshare it the impact was minimal, as the code de-pended on a specific computational environment(hardware, operating system, compiler, etc.) thatothers could not access. Traditionally, researchlaboratory computing environments often reliedupon proprietary or hardware-specific software.
PSEs likeR, Mathematica, and MATLAB haveover the last decade dramatically simplified anduniformized much computational science.
Each PSE o↵ers a high-level language for de-scribing computations, often a language that isvery compatible with standard mathematical no-tation. PSEs also o↵er graphics capabilities thatmake it easy to produce often quite sophisticatedfigures for inclusion in research papers. The re-searcher is gaining extreme ease of access to fun-damental capabilities like matrix algebra, sym-bolic integration and optimization, and statisti-cal model fitting; in many cases a whole researchproject, involving a complex series of variationson some basic computation, can be encoded in afew compact command scripts.
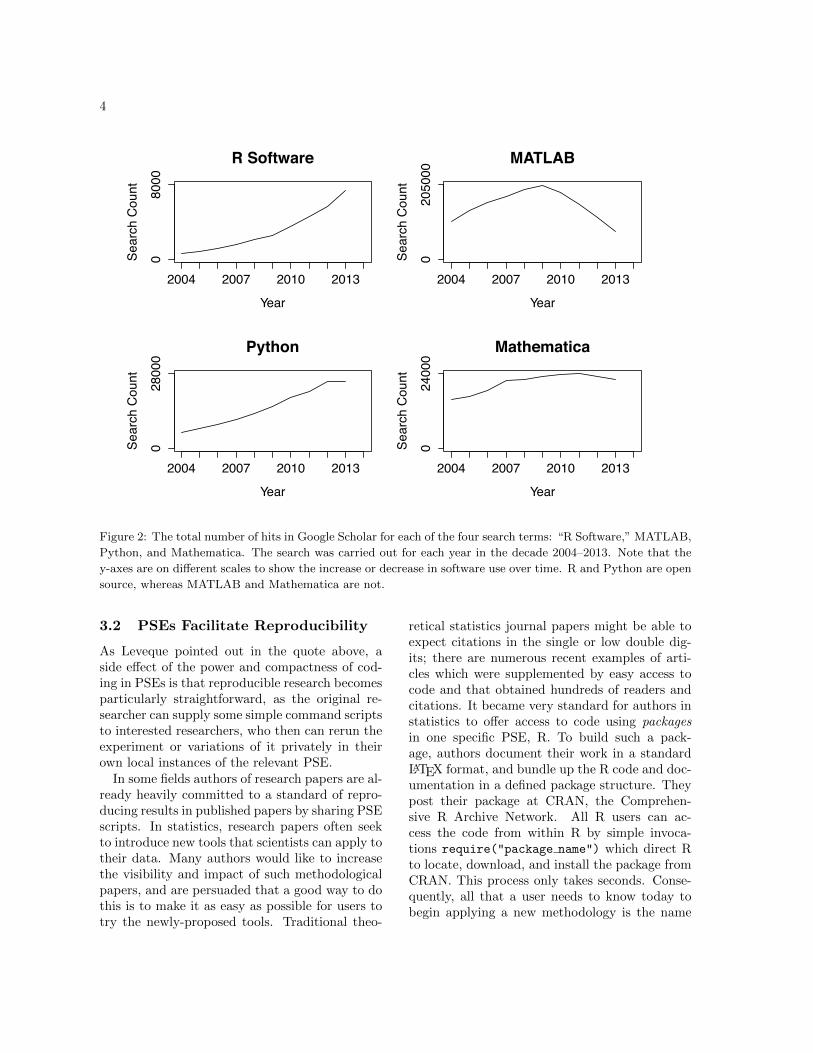
The popularity of this approach to computingis impressive. Figure 2 shows that the PSEs withthe most impact on research - by citations - arethe commercial closed-source packages Mathe-matica and MATLAB, which revolutionized tech-nical computing in the 80’s and 90’s. However,these systems are no longer rapidly growing inimpact; while the recent growth in popularity ofR and Python is dramatic.
4
R Software
Year
Sear
ch C
ount
2004 2007 2010 2013
080
00MATLAB
Year
Sear
ch C
ount
2004 2007 2010 2013
020
5000
Python
Year
Sear
ch C
ount
2004 2007 2010 2013
028
000
Mathematica
Year
Sear
ch C
ount
2004 2007 2010 2013
024
000
Figure 2: The total number of hits in Google Scholar for each of the four search terms: “R Software,” MATLAB,
Python, and Mathematica. The search was carried out for each year in the decade 2004–2013. Note that the
y-axes are on di↵erent scales to show the increase or decrease in software use over time. R and Python are open
source, whereas MATLAB and Mathematica are not.
3.2 PSEs Facilitate Reproducibility
As Leveque pointed out in the quote above, aside e↵ect of the power and compactness of cod-ing in PSEs is that reproducible research becomesparticularly straightforward, as the original re-searcher can supply some simple command scriptsto interested researchers, who then can rerun theexperiment or variations of it privately in theirown local instances of the relevant PSE.In some fields authors of research papers are al-
ready heavily committed to a standard of repro-ducing results in published papers by sharing PSEscripts. In statistics, research papers often seekto introduce new tools that scientists can apply totheir data. Many authors would like to increasethe visibility and impact of such methodologicalpapers, and are persuaded that a good way to dothis is to make it as easy as possible for users totry the newly-proposed tools. Traditional theo-
retical statistics journal papers might be able toexpect citations in the single or low double dig-its; there are numerous recent examples of arti-cles which were supplemented by easy access tocode and that obtained hundreds of readers andcitations. It became very standard for authors instatistics to o↵er access to code using packagesin one specific PSE, R. To build such a pack-age, authors document their work in a standardLATEX format, and bundle up the R code and doc-umentation in a defined package structure. Theypost their package at CRAN, the Comprehen-sive R Archive Network. All R users can ac-cess the code from within R by simple invoca-tions require("package name") which direct Rto locate, download, and install the package fromCRAN. This process only takes seconds. Conse-quently, all that a user needs to know today tobegin applying a new methodology is the name

5
of the package. CRAN o↵ered 5519 packages asof May 8, 2014. A side e↵ect of authors makingtheir methodology available in order to attractreaders, is of course that results in their originalarticles may become easily reproducible.1
3.3 Notebooks for Sharing Results
A notebook interface to a PSE stores computerinstructions alongside accompanying narrative,which can include mathematical expressions, andallows the user to execute the code and store theoutput, including figures, all in one document.Because all the steps leading to the results aresaved in a single file, notebooks can be sharedonline, which provides a way to communicate re-producible computational results.The IPython Notebook, illustrated in figure 3,
provides an interface to backend computations,for example in Python or R, that displays codeand output, including figures, with mathematicalnotation typeset in LATEX. An IPython Notebookpermits the researcher to track and document thecomputational steps that generate results, andcan be shared with others online using nbviewer;see for example http://nbviewer.ipython.
org/url/jakevdp.github.com/downloads/
notebooks/XKCD_plots.ipynb).
4 Open Source Software: A KeyEnabler
PSEs and notebook interfaces are having a verysubstantial e↵ect in promoting reproducibility,but they have their limits. They make manyresearch computations convenient and easy toshare with others, but ambitious computationsoften demand more capability than they can of-fer. Historically, this would have meant that am-
1In fields like statistics, code alone is not su�cientto reproduce published results. Computations are per-formed on datasets from specific scientific projects; thedata may result from experiments, surveys or costly mea-surements. Increasingly data repositories are being usedby researchers to share such data across the internet.Since 2010, arXiv has partnered with the Data Conser-vancy to facilitate external hosting of data associatedwith publications uploaded to arXiv. See for examplehttp://arxiv.org/abs/1110.3649v1, where the data filesare accessible from the paper’s arXiv page. Such prac-tices are not yet widespread but they are occurring withincreasing frequency.
Figure 3: Snapshot of the IPython Interactive Note-
book.
bitious projects have to be idiosyncratically codedand di�cult to export to new computing environ-ments.
The open source revolution has largely changedthis. Today, it is often possible to develop all ofan ambitious computational project using codethat is freely available to others. Moreover, thiscode can be hosted on an open source operatingsystem (Linux) and run within a standard virtualmachine that hides hardware details. The opensource ‘spirit’ also makes researchers more opento sharing code; attribution-only open source li-censes may also allow them to do this while re-taining some assurance that the shared code willnot be misappropriated.
Several broad classes of software are now beingshared in ways that we describe in this section.These various classes of software are becomingor have already become part of the standard ap-proaches to reproducible research.
4.1 Fundamental Algorithms andPackages
In Tables 1–10 we consider some of the fundamen-tal problems that underly modern computationalmathematics, such as fast Fourier trans-
forms [II.FFT], linear equations [IV.NLA],and nonlinear optimization [IV.opt], and

6
give examples of some of the many families ofopen-source codes that have become available forenabling high-quality mathematical computation.The tables include their inception date, their cur-rent release number, and the total number of ci-tations these packages have garnered since incep-tion.2 The di↵erent packages within one tablemay o↵er very di↵erent approaches to the sameunderlying problem. As the reader can see, astaggering amount of basic functionality is beingdeveloped worldwide by many teams and authorsin particular subdomains - and made available forbroad use. The citation figures in the tables tes-tify to the significant impact these enablers arehaving on published research.
Table 1: Dense linear algebra
Package Date Release CitesLAPACK 1992 3.4.2 7600JAMA 1998 1.0.3 129IT++ 2006 4.2 14Armadillo 2010 3.900.7 105EJML 2010 0.23 22Elemental 2010 0.81 51
Table 2: Sparse-direct solvers
Package Date Release CitesSuperLU 1997 4.3 317MUMPS 1999 4.10.0 2029Amesos 2004 11.4 104PaStiX 2006 5.2.1 114Clique 2010 0.81 12
4.2 Specialized Systems
The packages tabulated in the last subsection arebroadly useful in computational mathematics; itis perhaps not surprising that developers would
2Data for citation counts collected via Google Scholarin August 2013. Note that widely used packages such asLAPACK, FFTW, ARPACK and Suitesparse are used inother software (e.g., MATLAB), which do not generatecitations directly.
Table 3: Krylov-subspace eigensolvers
Package Date Release CitesARPACK 1998 3.1.3 2624SLEPc 2002 3.4.1 293Anasazi 2004 11.4 2422PRIMME 2006 1.1 61
Table 4: Fourier-like transforms
Package Date Release CitesFFTW 1997 3.3.3 1478P3DFFT 2007 2.6.1 14DIGPUFFT 2011 2.4 17DistButterfly 2013 27PNFFT 2013 215
Table 5: Fast multipole methods
Package Date Release CitesKIFMM3d 2003 1780Puma-EM 2007 0.5.7 32PetFMM 2009 29GemsFMM 2010 16ExaFMM 2011 28
arise to create such broadly-useful tools. We havebeen surprised to see the rise of systems whichattack very specific problem areas and o↵er ex-tremely powerful environments to formulate andsolve problems in those narrow domains. We givethree examples.
4.2.1 Hyperbolic partial di↵erentialequations
Clawpack is an open-source software package de-signed to compute numerical solutions to hyper-bolic partial di↵erential equations (PDEs) usinga wave propagation approach. According to sys-tem’s lead author, Randall J. LeVeque, “[t]he de-velopment and use of the Clawpack software im-plementing [high-resolution finite volume meth-ods for solving hyperbolic PDEs] serves as a casestudy for a more general discussion of mathe-

7
matical aspects of software development and theneed for more reproducibility in computationalresearch.”
The package has been used in creating repro-ducible mathematical research. For example thefigures for LeVeque’s book, Finite Volume Meth-ods for Hyperbolic Problems, were generated usingClawpack; instructions are provided for recreat-ing those figures.
Clawpack is now a framework o↵ering numer-ous extensions including PyClaw, with a Pythoninterface to a number of advanced capabilities,and GeoClaw, developed for tsunami modeling[V.xy] and modeling of other geophysical flows.Apparently, the open source software practicesenabled not only reproducibility but also code ex-tension and expansion into new areas.
Table 6: PDE Frameworks
Package Date Release CitesPETSc 1997 3.4 2695Cactus 1998 4.2.0 669deal.II 1999 8.0 576Clawpack 2001 4.6.3 131Hypre 2001 2.9.0 384libMesh 2003 0.9.2.1 260Trilinos 2003 11.4 3483Feel++ 2005 0.93.0 405Lis 2005 1.4.11 29
Table 7: Finite element analysis
Package Date Release CitesCode Aster 11.4.03 48CalculiX 1998 2.6 69deal.II 1999 8.0 576DUNE 2002 2.3 325Elmer 2005 6.2 97FEniCS Project 2009 1.2.0 418FEBio 2010 1.6.0 32
Table 8: Optimization
Package Date Release CitesMINUIT/MINUIT2 2001 94.1 2336CUTEr 2002 r152 1368IPOPT 2002 3.11.2 1517CONDOR 2005 1.11 1019OpenOpt 2007 0.50.0 24ADMB 2009 11.1 175
Table 9: Graph partitioning
Package Date Release CitesScotch 1992 6.0.0 435ParMeTIS 1997 4.0.3 4349kMeTIS 1998 1.5.3 3449Zoltan-HG 2008 r362 125KaHIP 2011 0.52 71
Table 10: Adaptive mesh refinement
Package Date Release CitesAMRClaw 1994 4.6.3 4800PARAMESH 1999 4.1 409SAMRAI 1998 185Carpet 2001 4 579BoxLib 2000 155Chombo 2000 3.1 198AMROC 2003 1.1 342p4est 2007 0.3.4.1 227
4.2.2 Parabolic and Elliptic PDEs:DUNE
The Distributed and Unified Numerics Environ-ment (DUNE) is an open-source modular soft-ware toolbox for solving PDEs using grid-basedmethods. It was developed by Mario Ohlbergerand other contributors and supports the imple-mentation of methods such as finite elements, fi-nite volumes, finite di↵erences, and discontinuousGalerkin methods.
DUNE was envisioned to permit the integrateduse of both legacy and new libraries. The soft-

8
ware uses modern C++ programming techniquesto enable very di↵erent implementations of thesame concepts (i.e. grids, solvers, linear algebra,etc.) using a common interface with low over-head, meaning that DUNE prioritizes e�ciencyin scientific computations and supports high-performance computing applications. DUNE hasa variety of downloadable modules including vari-ous grid implementations, linear algebra, quadra-ture formulas, shape functions, and discretizationmodules.DUNE is based on the following main princi-
ples: the separation of data structures and algo-rithms by abstract interfaces; the e�cient imple-mentation of these interfaces using generic pro-gramming techniques; and reuse of existing finiteelement packages with a large body of function-ality. The finite element codes UG, ALBERTA,and ALUGrid have been adapted to the DUNEframework, showing the value of open source de-velopment not only for reproducibility but for ac-celeration of discovery through code reuse.3
4.2.3 Computer-Aided Theorem Proving
Computer-aided theorem proving [VII.xy]
has been making extremely impressive stridesin the last decade. This rests ultimately onthe underlying computational tools which areopenly available and which a whole communityof researchers is contributing to and using. In-deed, one can only have justified belief in acomputationally-enabled proof with transparentaccess to the underlying technology and broaddiscussion.There are broadly speaking two approaches
to computer-aided theorem proving tools in ex-perimental mathematics. The first type encom-passes machine-human collaborative proof assis-tants and interactive theorem proving systems toverify mathematics and computation, while thesecond type includes automatic proof checkingwhich occurs when the machine verifies previouslycompleted human proofs or conjectures.Interactive theorem proving systems include
coq, Mizar, HOL4, HOL Light, Isabelle, LEGO,ACL2, Veritas, NuPRL, and PVS. Such systemshave been used to verify the Four Color Theorem
3See also FEniCS http://fenicsproject.org for an-other example of an open source finite element package.
Figure 4: Example of the Kepler interface, showing a
workflow solving the classic Lotka-Volterra predator
prey dynamics model.
and to reprove important classical mathematicalresults. Thomas Hales’ Flyspeck project is cur-rently producing a formal proof of the Kepler con-jecture, using HOL Light and Isabelle. The soft-ware produces machine-readable code that can bere-used and repurposed into other proof e↵orts.Examples of open-source software for automatictheorem proving include E and Prover9/Mace 4.
5 Scientific Workflows
Highly ambitious computations today often gobeyond single algorithms to combine di↵erentpieces of software in complex pipelines. More-over, modern research often considers a wholepipeline as a single object of study and makesexperiments varying the pipeline itself. Experi-ments involving many moving parts that must becombined to produce a complete result are oftencalled workflows.
Kepler is an open source project structuredaround scientific workflows – “an executable rep-resentation of the steps required to generate re-sults,” or the capture of experimental details thatpermit others to reproduce computational find-ings.
Kepler provides a graphical interface that al-

9
lows users to create and share these workflows.An example of a Kepler workflow is given in Fig-ure 4, solving a model of two coupled di↵eren-tial equations, and plotting the output. Keplermaintains a Component Repository where work-flows can be uploaded, downloaded, searched andshared with the community or designated users,and it contains a searchable library with morethan 350 processing components. Kepler operateson data stored in a variety of formats, locally andover the internet, and can merge software fromdi↵erent sources such as R scripts and compiledC code by linking in their inputs and outputs toperform the desired overall task.
6 Dissemination Platforms
Dissemination platforms are websites that servespecialized content to interested visitors. Theyo↵er an interesting method to facilitate repro-ducibility; we describe here the platforms ImageProcessing OnLine (IPOL) project and Research-Compendia.org.IPOL is an open source journal infrastructure
developed in Python that publishes relevant im-age processing and image analysis algorithms.The journal peer reviews article contributions, in-cluding code, and publishes accepted papers in astandardized format that includes:
1. a manuscript containing the detailed descrip-tion of the algorithm, its bibliography, anddocumented examples;
2. a downloadable software implementation ofthe algorithm;
3. an online demo, where the algorithm can betested on data sets, for example images, up-loaded by the users;
4. an archive containing a history of the onlineexperiments.
Figure 5 displays these components, for a sampleIPOL publication.ResearchCompendia, which one of the authors
is developing, is an open source platform designedto link the published article with the code anddata that generated the results. The idea is basedon the notion of a “research compendium” – a
bundle including the article and the code anddata needed to recreate the findings. For a pub-lished paper, a webpage is created that links tothe article and provides access to code and dataas well as meta-data, descriptions and documen-tation, and code and data citation suggestions.Figure 6 shows an example compendium page.
ResearchCompendia assigns a Digital ObjectIdentifier (DOI) to all citable objects: code,data, compendium page, in such a way to en-able bi-directional linking between related dig-ital scholarly objects, such as the publicationand the data and code that generated its results(see http://www.stm-assoc.org/2012_06_14_
STM_DataCite_Joint_Statement.pdf). DOIsare established and widely used unique persis-tent identifiers for digital scholarly objects. Thereare other PSE-independent methods of shar-ing such as GitHub.com (which can now assignDOIs to code https://guides.github.com/
activities/citable-code) and supplementarymaterials on journal websites. A DOI is a�xedto a certain version of software or data that gen-erates a certain set of results. For this reasonamong others, version control [VIII.VC §2]
for scientific codes and data is important for re-producibility.4
7 Best practices for reproduciblecomputational mathematics
Best practices for communicating computationalmathematics have not yet become standard-ized. The workshop “Reproducibility in Compu-tational and Experimental Mathematics”, held atthe Institute for Computational and Experimen-tal Research in Mathematics (ICERM) at BrownUniversity in 2012, recommended the followingfor every paper in computational mathematics.
• A precise statement of assertions made in thepaper.
• A statement of the computational approach,and why it constitutes a rigorous test of thehypothesized assertions.
4Other reasons include: good coding practices enablingre-use; assigning explicit credit for bug fixing and codeextensions or applications; e�ciency in code organizationand development; and the ability to join collaborative cod-ing communities such as GitHub.com.

10
Figure 5: An example IPOL publication. The three panels from left to right include the manuscript, the
cloud-executable demo, and the archive of all previous executions.
Figure 6: An example compendium page on Re-
searchCompendia.org. The page links to a published
article and provides access to the code and data that
generated the published results.
• Complete statements of, or references to, ev-ery algorithm employed.
• Salient details of auxiliary software (both re-search and commercial software) used in thecomputation.
• Salient details of the test environment, in-
cluding hardware, system software and thenumber of processors utilized.
• Salient details of data reduction and statis-tical analysis methods.
• Discussion of the adequacy of parameterssuch as precision level and grid resolution.
• Full statement (or at least a valid summary)of experimental results.
• Verification and validation tests performedby the author(s).
• Availability of computer code, input dataand output data, with some reasonable levelof documentation.
• Curation: where are code and data avail-able? With what expected persistence andlongevity? Is there a site for future updates,e.g. a version control repository of the codebase?
• Instructions for repeating computational ex-periments described in the paper.
• Terms of use and licensing. Ideally code anddata “default to open,” i.e. a permissive re-use license, if nothing opposes it.

11
• Avenues of exploration examined throughoutdevelopment, including information aboutnegative findings.
• Proper citation of all code and data used,including that generated by the authors.
These guidelines can, and should, be adaptedto di↵erent research contexts but the goal isto provide readers with the information (suchas meta-data including parameter settings andworkflow documentation), data, and code, theyrequire to independently verify computationalfindings.
8 The Outlook
The recommendations of the ICERM workshoplisted in the previous section are the least wewould hope for today. They commendably pro-pose that authors give enough information so thatreaders can understand at some high level whatwas done.They do not actually require sharing of all
code and data in a form that allows precise re-execution and reproduction of results. Hence,these recommendations are very far from wherewe hope to be in twenty years.One can envision a day when every published
research document will be truly reproducible ina deep sense, where others can repeat publishedcomputations utterly mechanically. The reader ofsuch a reproducible research article would be ableto deeply study any specific figure: for example,viewing the source code and data which under-lie the figure, recreating the original figure fromscratch, examining input parameters that definethis particular figure and even changing their set-tings, to study the e↵ect on the resulting figure.Reproducibility at this ambitious level would
enable more than just individual understanding– it would enable meta-research. Consider the“dream applications” mentioned in Gavish andDonoho (2012), where robots automatically crawlthrough, reproduce and vary research results. Re-producible work can be automatically extendedand generalized: it can be optimized, di↵eren-tiated, extrapolated and interpolated. A repro-ducible data analysis can be statistically boot-
strapped to automatically place confidence state-ments on the whole analysis.
Coming back to earth, what is likely to hap-pen in the near future? We confidently projectincreasing computational transparency and in-creasing computational reproducibility in comingyears. We suppose that PSEs will continue to bevery popular, and authors will increasingly sharetheir scripts and data, if only to attract read-ership. Specialized platforms like Clawpack andDune will come to be seen as standard platformsfor whole research communities who will natu-rally then be able to reproduce work in those ar-eas. We expect that as the use of cloud comput-ing grows and workflows become more complex,researchers will increasingly document and sharethe workflows that produce their most ambitiousresults. We expect that code will be developedon common platforms and will be stored in thecloud, enabling the code to run for many yearsafter publication.
We expect that over the next two decades suchpractices will become standard, and will be basedon tools of the kind discussed in this article. Thedirection of increasing transparency and increas-ing sharing seem clear, but it’s still unclear whichcombinations of tools and approaches will cometo be standard.
Further Reading
1. Hales, T., 2013 Mathematics in the Age of theTuring Machine. http://arxiv.org/abs/1302.2898. To appear in Turing’s Legacy, ASL Lec-ture Notes in Logic, editor Rodney G. Downey.
2. LeVeque, R., 2006 Wave propagation soft-ware, computational science, and reproducibleresearch. Proceedings of the InternationalCongress of Mathematicians Madrid, August 22-30: invited lectures.
3. Bailey, D. H., Borwein, J., and Stodden, V. 2013Set the Default to ‘Open’ Notices of the AMSJune/July, 679–680.
4. AMS Workshop 2011 Reproducible Research:Tools and Strategies for Scientific Computing.July 13-16. http://stodden.net/AMP2011
5. Donoho, D., Maleki, A., Shahram, M., Ur Rah-man, I., and Stodden, V. 2009 ReproducibleResearch in Computational Harmonic Analysis.IEEE Computing in Science and Engineering 11(1), 8–18.
6. Stodden, V. 2009 The Legal Framework for Re-producible Scientific Research: Licensing and

12
Copyright. Computing in Science and Engineer-ing 11 (1), 35–40.
7. Stodden, V. 2009 Enabling Reproducible Re-search: Licensing for Scientific Innovation. In-ternational Journal of Communications Law andPolicy 13, 1–25.
8. Stodden, V., Guo, P., and Ma, Z. 2013 TowardReproducible Computational Research: An Em-pirical Analysis of Data and Code Policy Adop-tion by Journals. PLoS ONE 8 (6).
9. Gentleman, R., and Temple Lang, D. 2007 Sta-tistical analyses and reproducible research Jour-nal of Computational and Graphical Statistics16, 1–23.
10. Buckheit, J., and Donoho, D. 1995 Wavelab andreproducible research. In: Antoniadis A, edi-tor. Wavelets and Statistics. New York, NY:Springer, 55–81.
11. Gavish. M., and Donoho, D. 2012 Three DreamApplications of Verifiable Computational Re-sults. Computing in Science and Engineering14(4), 26–31


















