Prof. Giovanni Capelli - - Università degli Studi di Cassino · Errori in Epidemiologia Precisione...
59
Gli errori e i bias negli studi epidemiologici osservazionali e sperimentali Prof. Giovanni Capelli Cattedra di Igiene Dipartimento di Scienze Motorie e della Salute Facoltà di Scienze Motorie - Università di Cassino CdLM Classe LM-67 - Scienze e tecniche delle attività motorie preventive ed adattate C.I. Epidemiologia e valutazione degli stili di vita sulla salute Modulo: Metodologia epidemiologica
Transcript of Prof. Giovanni Capelli - - Università degli Studi di Cassino · Errori in Epidemiologia Precisione...

Gli errori e i bias negli studi epidemiologici osservazionali e sperimentali
Prof. Giovanni Capelli
Cattedra di IgieneDipartimento di Scienze Motorie e della Salute
Facoltà di Scienze Motorie - Università di Cassino
CdLM Classe LM-67 - Scienze e tecniche delle attività motorie preventive ed adattate
C.I. Epidemiologia e valutazione degli stili di vita sulla saluteModulo: Metodologia epidemiologica

Errori e Bias: concetti
ErroreUn atto, asserzione o una convinzione che devia dal
giusto In matematica errore è la differenza tra un
valore calcolato o misurato e il valore vero oquello eroicamente corretto
Ma attenzione! La lunghezza di “1 metro” è stata, nel tempo,
definita come: una frazione della lunghezza del quadrante del meridiano
terrestre che attraversa Parigi la distanza tra due segni su una barra di metallo il tragitto percorso dalla luce nel vuoto in un particolare lasso
di tempo
Quindi, la “giusta” lunghezza di un metro è decisaarbitrariamente, accordandosi su una definizione Importanza dei metodi standardizzati di misura

Errori e bias: concetti
BiasE’ qualcosa di più sottile dell’errore
Si tratta piuttosto di una “preferenza”, diuna “inclinazione” Che impedisce un giudizio imparziale O porta a decisioni o azioni ingiuste a causa di un
pregiudizio
In statistica, Bias è un errore dovuto al fatto che sistematicamente
alcuni gruppi o esiti sono favoriti rispetto ad altri
In pratica, il bias è Un errore che si presenta in misura diversa nei diversi
gruppi considerati• intenzionalmente o involontariamente
Ovvero una inappropriata generalizzazione dei risultatidi uno studio ad una popolazione che differisce da quellastudiata

Errori in Epidemiologia
PrecisioneErrori random
ValiditàErrori sistematici
Confondimento
Misclassificazione
Selezione

Validità e precisione

Precisione
È di solito espressa utilizzando gliintervalli di confidenza
Dipende dalla grandezza del campione edall’efficienza dello studio

Validità - Tipologie di bias (errore “sistematico”)
Di selezione (selection bias)Scelta della popolazione
Deviata sistematicamente
Di informazione (information bias)Raccolta
Analisi
Interpretazione dei dati
Deviate sistematicamente
Confondimento (confounding)Le variabili misurate e considerate nell’analisi
sono scelte in modo “erroneo”
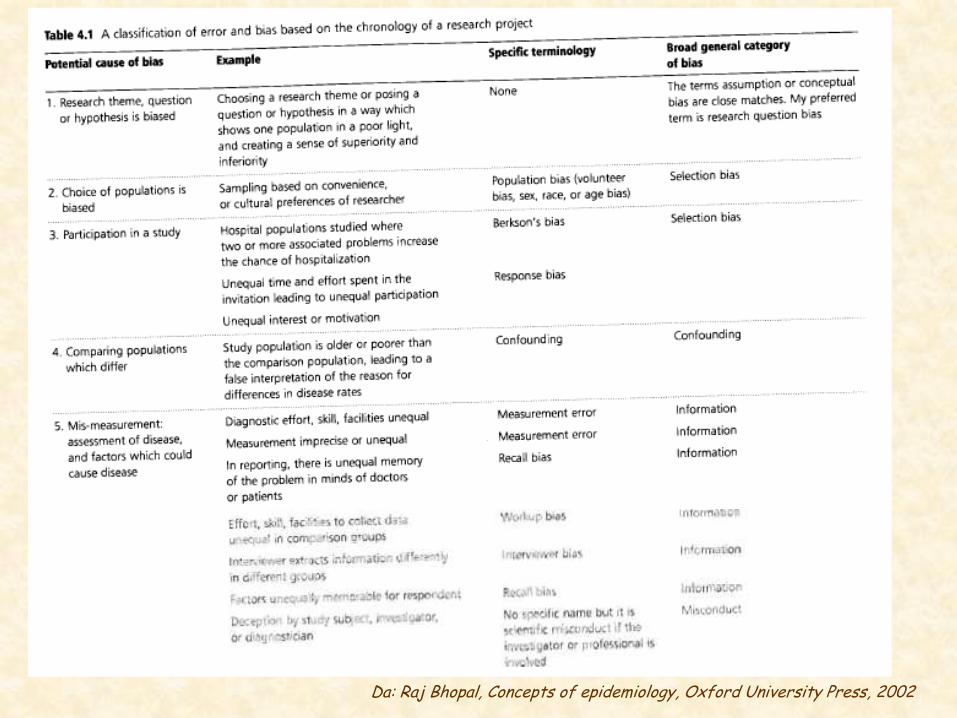
Da: Raj Bhopal, Concepts of epidemiology, Oxford University Press, 2002

Da: Raj Bhopal, Concepts of epidemiology, Oxford University Press, 2002

Rischi nella scelta della popolazione in studio
Da: Raj Bhopal, Concepts of epidemiology, Oxford University Press, 2002

Filosofia della valutazione di causalità
Teorie probabilistiche della causalitàIl problema principale di queste teorie è il
soddisfacimento della terza condizione (chel’associazione non sia “spuria”)
che implica identificazione ed eliminazionedei fattori “disturbanti” (confoundingfactors)
Che X sia causa di Y secondo la definizioneprobabilistica può dipendere, dunque
da quali fattori sono presi in considerazione e quindi X resta una causa a meno di altri
fattori, a noi sconosciuti, potenzialmenterilevanti

Il confondimento
In ambito epidemiologico e di sanitàpubblica siamo interessati allaassociazione tra esposizione ed effettoCapita spesso di dover verificare che la nostra
analisi di associazione non sia distorta da unaterza variabile correlata sia alla esposizione che all’ effetto
Definiremo questa variabile di confondimento sesi tratta di una variabile estranea che soddisfaentrambe le seguenti condizioni: E’ fattore di rischio per l’ effetto E’ associata alla’esposizione, ma non ne è una
conseguenza

La stratificazione
Per controllare per i fattori diconfondimento possiamo utilizzare lastratificazione. L’idea di base è:Suddividiamo il campione in strati
Facciamo confronti all’interno degli strati
confrontando similia cum similibusRicombiniamo per una stima complessiva (overall)
Spesso la decisione se trattare o no unavariabile come confondenteè legata a considerazione non statistiche, quali
la conoscenza della storia naturale di malattia il giudizio soggettivo una revisione della letteratura

Confondimento:una definizione operativa
Se una analisi “cruda” ( “unadjusted”) fornisce una risposta sostanzialmente diversa
da una analisi stratificata che controlli per lavariabile Z,
Z è un fattore di confondimento
Il confondimento non è tutto o nullaè un bias (distorsione) e le distorsioni possono
essere grandi o piccole

Confondimento
Un errore nella stima di una misuraepidemiologica o nella stima di uneffetto che deriva da uno squilibrionegli altri fattori causali della malattiatra i gruppi posti a confronto
Un confondenteÈ associato con la malattia tra i non esposti
È associato con l’esposizione nella popolazioneche dà origine ai casi
Non è una causa intermedia

Confondimento
ESPOSIZIONE MALATTIA
CONFONDENTE

Esempio di confondimento
Dati grezzi
Esposti Non esposti
Casi 40 101
Tempo-persona 1100 1100
RR=0.4
Giovani Anziani
Esposti Non esposti Esposti Non esposti
Casi 20 1 Casi 20 100
Tempo-
persona
1000 100 Tempo-
persona
100 1000
RR=2.0 RR=2.0

Confondimento
MisuraCambiamento nella stima dell’effetto
ControlloPrevenzione
Restrizione Randomizzazione Appaiamento
Terapia
Analisi stratificata Modelli multivariabili

Confondimento: esempio
Shapiro et al. (Lancet, 1979) hannorealizzato uno studio caso-controllo su utilizzo di contraccettivi orali (OC)
e infarto del miocardio
stratificando per età
C’è associazione tra uso di OC e Infarto,controllando per classi di età?
Infarto Controlli Infarto Controlli
Uso recente di SI 13 59 72 Uso recente di SI 12 14 26
contraccettivi NO 45 720 765 contraccettivi NO 158 663 821
orali 58 779 837 orali 170 677 847
^OR1= 3.53 ^OR2= 3.60
Età 30-39 Età 40-49

Confondimento:una definizione operativa
Se una analisi “cruda” ( “unadjusted”) fornisce una risposta sostanzialmente diversa
da una analisi stratificata che controlli per lavariabile X,
X è un fattore di confondimento
Il confondimento non è tutto o nullaè un bias (distorsione) e le distorsioni possono
essere grandi o piccole
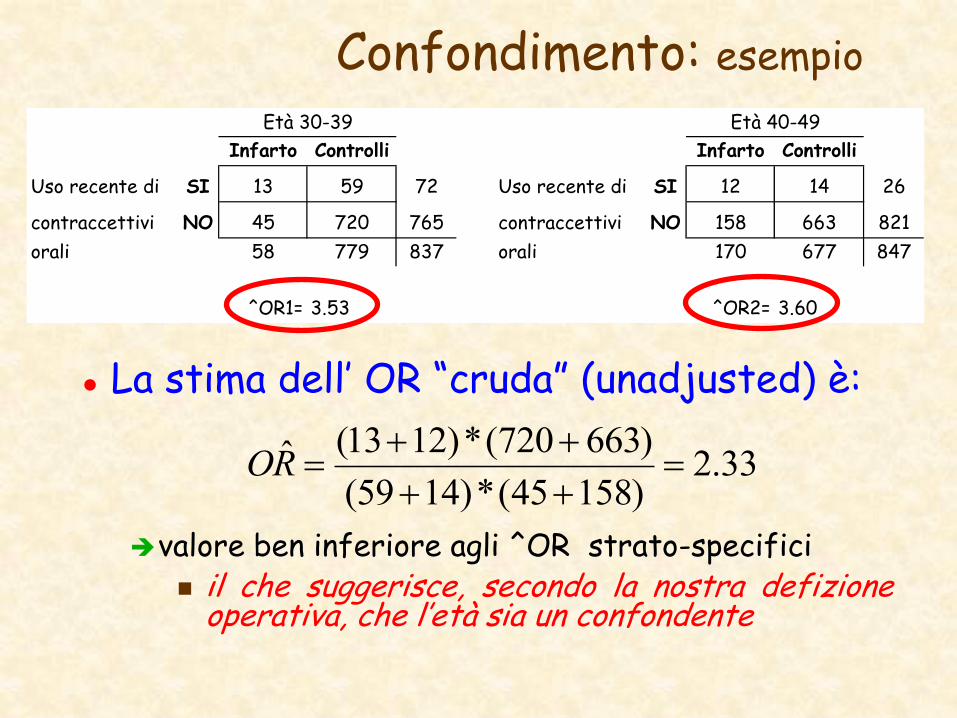
Confondimento: esempio
La stima dell’ OR “cruda” (unadjusted) è:
valore ben inferiore agli ^OR strato-specifici il che suggerisce, secondo la nostra defizione
operativa, che l’età sia un confondente
Infarto Controlli Infarto Controlli
Uso recente di SI 13 59 72 Uso recente di SI 12 14 26
contraccettivi NO 45 720 765 contraccettivi NO 158 663 821
orali 58 779 837 orali 170 677 847
^OR1= 3.53 ^OR2= 3.60
Età 30-39 Età 40-49
33.2)15845(*)1459(
)663720(*)1213(ˆ
RO

Confondimento: esempio
Infatti, l’età è associata sia conl’effetto che con l’esposizionenel gruppo più anziano ci sono PIU’ infarti
170/847=0.201 contro 58/837=0.069nel gruppo più anziano c’è MENO uso di OC
26/847=0.031 contro 72/837=0.086ma l’età più avanzata non è una conseguenza
dell’ uso di OC
Perciò, concluderemo che l’età èfattore di confondimento dellaassociazione tra uso di OC e infartodel miocardio

Confondimento ed interazione
ConfondimentoE’ una distorsione sistematica della associazione esposizione-
effetto dovuta ad una terza variabile Zc, il fattore diconfondimento
Può talvolta essere controllato con una analisi appropriata (analisi stratificata) con un disegno apposito (matching)
E’ un bias e quindi va EVITATO!
Modificazione di effetto (interazione)E’ la variazione della associazione esposizione-effetto per
livelli di una terza variabile, Ze, il modificatore di effettoE’ una proprietà intrinseca del fenomeno esposizione-effetto
e non c’è disegno che la possa evitare se c’èE’ un fenomeno interessante, e quindi va DESCRITTO!

Stratificazione
Immaginiamo di suddividere lapopolazione in studio in stratiper ogni strato considereremo una associazione
esposizione-effetto
avremo dunque numerose tabelle 2x2, una perstrato
Se non c’è relazione tra esposizione edeffettogli OR calcolati per ogni strato saranno tutti =1
L’ipotesi nulla di non associazione è dunque H0: OR1=OR2=OR3=Ork=1
Se c’è associazione positiva (fattore dirischio) costante in ogni strato OR1>1, OR2>1, OR3>1, ORk>1

Stratificazione
Se gli OR negli strati sono più o meno gli stessiOR1~OR2~OR3~ORk~ OR*
Una stima di OR*m sarà una utiule misura della associazionetra esposizione ed effetto nella intera popolazione
Se invece i valori di OR differisconosostanzialmente tra gli stratiparleremo di modificazione di effetto (in epidemiologia) o di
interazione (in statistica)
non sarà possibile stimare un valore riassuntivo per tutta lapopolazione
perchè l’effetto cambia nei doversi strati!
La stratificazione può essere usata per: controllare per i fattori di confondimento
descrivere l’interazione (modificatori di effetto)

Confondimento ed interazione
ConfondimentoE’ una distorsione sistematica della associazione esposizione-
effetto dovuta ad una terza variabile X, il fattore diconfondimento
Può talvolta essere controllato
con una analisi appropriata (analisi stratificata)
con un disegno apposito (matching)
E’ un bias e quindi va EVITATO!
Modificazione di effetto (interazione)E’ la variazione della associazione esposizione-effetto per
livelli di una terza variabile, X, il modificatore di effetto
E’ una proprietà intrinseca del fenomeno esposizione-effetto
e non c’è disegno che la possa evitare se c’è
E’ un fenomeno interessante, e quindi va DESCRITTO!

Una strategia per l’analisi di tabelle 2x2 stratificate (1)
Determinare i potenziali fattori diconfondimento o le variabili categoriche perle quali il campione è stato stratificatosulla base delle conoscenze mediche ed
epidemiologiche
Dare un’occhiata agli ^ORi per avere unaidea della situazionese si ha un piccolo numero di strati con numerosi
soggetti ciascuno,
Svolgere il test di non associazione diMantel-Haenszelse non sono evidenti interazioni qualitative (alcuni
^ORi >1 ed altri < 1)

Una strategia per l’analisi di tabelle 2x2 stratificate (2)
Svolgere un test di omogeneitàper valutare se si può ritenere comune l’OR tra gli
strati
esempio il test di Woolf per l’omogeneità di unpiccolo numero di strati numerosi
Se non ci sono elementi per rifiutarel’assunzione di un OR comunestimarlo con lo stimatore di Mantel-Haenszel, e
stimare i relativi intervalli di confidenza
Se invece si rifiuta l’assunzione diomogeneità degli ORè necessario riportare OR e intervalli di confidenza
separati per ogni strato

Stima dell’OR combinato secondo M-H
Lo stimatore di Mantel-Haenszelpuò essere in pratica considerato una media
ponderata degli OR strato-specifici
Lo stimatore di Mantel-Haenszel dell’OR combinato lavora benesia per un piccolo numero (K) di strati numerosi
che per un grande numero di strati piccoli

La regressione logistica
Se la variabile che misura l’effetto, èbinomiale, possiamo estendere i metodidella regressione per “prevederla”?
Se applichiamo la regressione lineareabbiamo un problemail valore previsto può essere inferiore a 0 o
maggiore di 1
Ci serve allora un’altra funzione, che sia vincolataa non oltrepassare 0 e 1
Ma cosa possiamo prevedere?Non tanto il valore della variabile di effetto, quanto
la probabilità che essa assuma uno dei due valoripossibili (1-> l’effetto verificato)

La regressione logistica
Potremmo prendere in considerazioneuna quantità L che sia una funzionelineare del valori assunto dal fattore dirischio considerato:L=b0+ b1 x1
Ed operare su di essa unatrasformazione che produca unaquantità obbligata a non assumerevalori esterni all’intervallo 0-1un trasformazione logistica:
LeLeffettoy
1
1)|Pr(

La regressione logistica
Infatti, se L=0, avremo:
Se L va ad , avremo:
E se L va a - , avremo:
5.011
1
1
1)|Pr(
0
eLeffettoy
11
1
1
1)|Pr(
eLeffettoy
01
1
1
1)|Pr(
eLeffettoy
Le1
1

La regressione logistica
E con alcuni passaggi, arriviamofacilamente a:
LeLeffettoy
1
1)|Pr( )( 1101
1)|Pr(
xe
Leffettoybb
)( 110)1( xe
y
y bb
110)1(
log xy
ybb
110
))|Pr(1(
)|Pr(log x
Leff
Leffbb
p/(1-p)=odds!

La regressione logistica
La regressione logistica si utilizza percostruire un modello della probabilità che siverifichi una certo risultato binario infunzione di una serie di variabili che si ritienesiano collegate al fenomeno (covariate)
Regressione logistica semplice:
Regressione logistica multipla:
)exp(1
)exp(
10
10
x
xpx
bb
bb
)...exp(1
)...exp(
22110
22110
xxxx
xxxp
bbbb
bbbb

I parametri nella regressione logistica
CalcoloLa stima avviene attraverso un
procedimento matematico ricorsivo(maximum likelihood), non può esserefatto a mano
SignificatoI coefficenti b corrispondono al
logaritmo degli Odds Ratio checonfrontano i soggetti esposti con inon esposti (o l’esposizione “baseline”)
e dunque: OR = exp(b)

Odds Ratio: problemi Gli OR sono difficili da comprendere direttamente
e sono solitamente interpretati come equivalentidel Rischio RelativoTuttavia, va ricordato che gli OR non approssimano
bene il RR quando il rischio iniziale (la prevalenza ol’incidenza del fenomeno di interesse) è alto
sovrastimano la dimensione del rischio, sia in sensonegativo che protettivo Davies HTO, Crombie IK, Tavakoli M, When can odds ratios
mislead?, BMJ, 316: 989-991, 1998
Le uniche situazione sicure in cui utilizzare gli ORsono gli studi caso-controllo e le regressionilogistiche, situazioni in cui essi consentono lemigliori stime possibili del Rischio Relativo
Deeks J, Letters to the Editor, BMJ, 317: 1155, 1998

Vantaggi della regressione logistica
Si può operare un aggiustamento per più fattori diconfondimento contemporaneamente
Si possono considerare sia covariate qualitative chequantitative
Si possono testare direttamente le interazioni(modificatori di effetto)
Si possono valutare i possibili fattori diconfondimento
Si ottengono stime puntuali ed intervalli diconfidenza degli OR
Matematicamente conveniente se si ha un softwareadatto

Svantaggi della regressione logistica
E’ astratta e matematica
Può creare una barriera tra il ricercatore ed i dati ci si potrebbe trovare a migliore agio valutando i risultati di
un metodo classico (es. Mantel-Haenszel)
Fa assunzioni implicite, delle quali può esserdifficile verificare l’applicabilità
Molti modelli potrebbero “fittare” bene, e non èfacile scegliere
Possibilità di troppa fiducia nei risultati “Ho fatto una analisi estensiva sul computer: allora le mie
conclusioni sono corrette”

Un esempio di regressione logistica. logistic lowbwt gestwks mothsmok
Logit Estimates Number of obs = 680
chi2(2) = 62.09
Prob > chi2 = 0.0000
Log Likelihood = -123.84356 Pseudo R2 = 0.2004
------------------------------------------------------------------------------
lowbwt | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
gestwks | .5432452 .0508903 -6.514 0.000 .4521233 .6527322
mothsmok | 2.697852 1.005295 2.663 0.008 1.29968 5.600151
------------------------------------------------------------------------------
. logit
Logit Estimates Number of obs = 680
chi2(2) = 62.09
Prob > chi2 = 0.0000
Log Likelihood = -123.84356 Pseudo R2 = 0.2004
------------------------------------------------------------------------------
lowbwt | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
gestwks | -.6101944 .0936783 -6.514 0.000 -.7938004 -.4265884
mothsmok | .9924558 .3726281 2.663 0.008 .262118 1.722794
_cons | 20.41724 3.588344 5.690 0.000 13.38421 27.45026
------------------------------------------------------------------------------
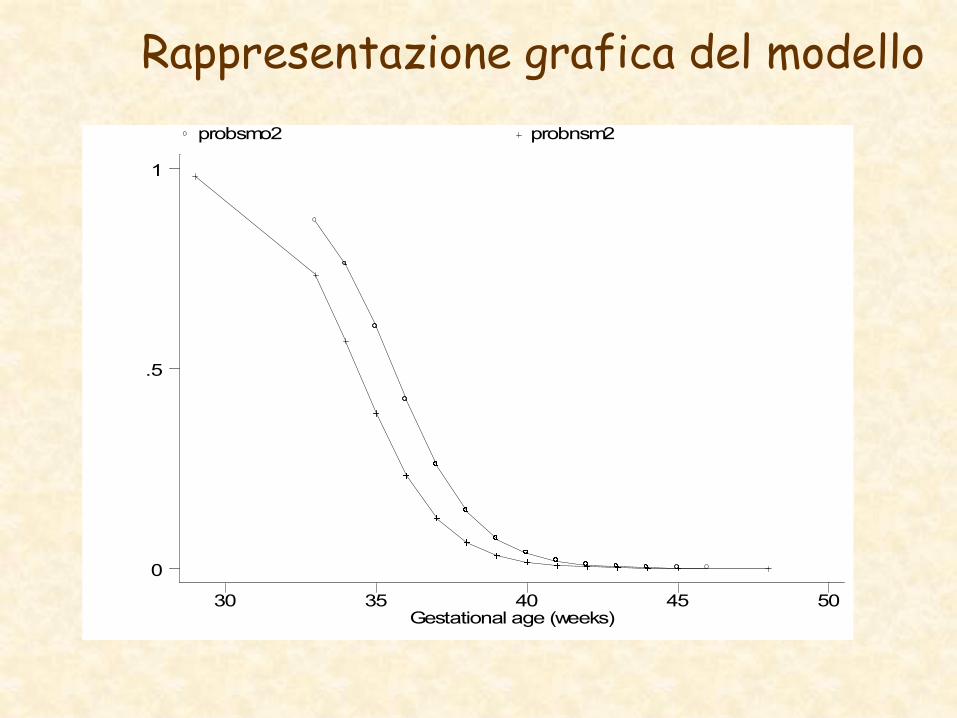
Rappresentazione grafica del modello
Gestational age (weeks)
probsmo2 probnsm2
30 35 40 45 50
0
.5
1

Regressione lineare e logistica: alcuni suggerimenti
Non sempre conviene utilizzare unavariabile numerica come talese il suo comportamento non è lineare,
spezzarla in classi (ed analizzarla come piùvariabili “dummy”) aiuta ad avere risultati piùattendibili
Come decidere le classi? Valori rilevanti di letteratura Classi di eguale ampiezza Gruppi di eguale numerosità
• quartili, quintili

Regressione lineare e logistica: scelta del modello
Valutare modelli di regressione è una operazionecomplicata
Può essere necessario considerare molte covariatee le interazioni tra loro ricordate, per avere risultati attendibili bisogna avere
almeno 10 osservazioni per ogni variabile considerata nelmodello (ogni interazione è una nuova variabile…)
E’ talvolta necessario considerare trasformazionidei dati, relazioni non lineari
Bisogna partire da strutture semplici e poicomplicare via via facendosi guidare dalle conoscenze sull’argomento, dal buon
senso e dai risultati dei test formali

Regressione lineare e logistica: scelta del modello
Il primo passo utile è fare uno “screening”attraverso una analisi “univariata”modelli che considerano 1 sola covariata
Hosmer e Lemeshow consigliano di prendere inconsiderazione le variabili che in questa fase hanno uncoefficiente con un p<0.25
E poi costruire un modello multivariato cheincludono tutte le variabili considerate rilevantonella IPOTESI formulata e le variabili che hannosuperato lo “screening” univariato
Quando ci sembra di essere vicini ad un modellofinale cominciamo a testare le interazioni, le trasformate, i
termini “quadratici”, ecc.

Regressione lineare e logistica: scelta del modello
NON esiste UN SOLO modello finale!Si può arrivare a più soluzioni logiche, plausibili e
supportate dai dati
Bisgna usare attenzione, logica, buon senso eplausibilità biologica nel costruire un modelloma bisogna anche saper essere “creativi”
la scelta dei modelli è altrettanto “arte” quanto“scienza”
La significatività statistica non è l’unica ragioneper la quale vale la pena di mantenere una variabilenei modelli definitivi le variabili “essenziali” (l’esposizione “principale”, i
confondenti noti, ecc.) vanno mantunuti nel modellocomunque!

Esempi di confondimento
Da: Raj Bhopal, Concepts of epidemiology, Oxford University Press, 2002

Misclassificazione
Assegnazione dei soggetti in studio allacategoria sbagliata di una variabilecategorica
Misclassificazione non differenzialeNon dipende da altre variabili in esame
Misclassificazione differenzialeÈ influenzata da altre variabili in esame

Effetto senza misclassificazione dell’esposizione
ESPOSTI
Effetto senza misclassificazione
NON ESPOSTI

Effetto con misclassificazione dell’esposizione
ESPOSTI NON ESPOSTI
Effetto con misclassificazione
Effetto senza misclassificazione

Misclassificazione non differenziale dell’esposizione
Dati corretti Esposti Non esposti
Casi 240 200
Controlli 240 600
OR = 3,00
Sensibilità = 0,6
Specificità = 1,0 Esposti Non esposti
Casi 144 296
Controlli 144 696
OR = 2,35
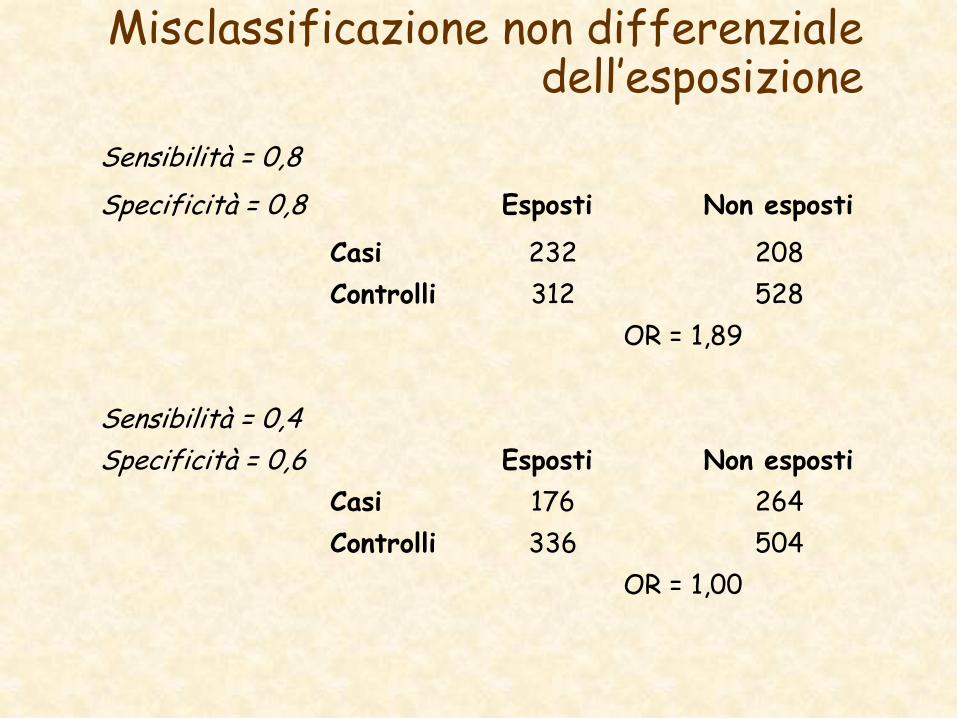
Misclassificazione non differenziale dell’esposizione
Sensibilità = 0,8
Specificità = 0,8 Esposti Non esposti
Casi 232 208
Controlli 312 528
OR = 1,89
Sensibilità = 0,4
Specificità = 0,6 Esposti Non esposti
Casi 176 264
Controlli 336 504
OR = 1,00

Misclassificazione non differenziale dell’effetto
Imperfetta specificitàFalsi positivi
Differenza tra rischi (o tassi) inalterata Rapporto tra rischi (o tassi) sottostimato
Imperfetta sensibilitàFalsi negativi
Differenza tra rischi (o tassi) sottostimata Rapporto tra rischi (o tassi) inalterato

Matching
Selezione di un gruppo di confronto cheha una identica o simile distribuzione peruna o più covariate
L’appaiamento è molto comune negli studicaso-controllo, poiché negli studi dicoorte è molto costoso
Le conseguenze sono però diverse trastudi di coorte e caso-controllo

Popolazione ipotetica
N Rischio N. casi
Esposti Uomini 90,000 5% 4,500
Donne 10,000 1% 100
N Rischio N. casi
Non esposti Uomini 10,000 0.5% 50
Donne 90,000 0.1% 90
RR grezzo=4600/140=32.9

Studio di coorte appaiato(10% degli esposti)
N Rischio N. casi
Esposti Uomini 9,000 5% 450
Donne 1,000 1% 10
N Rischio N. casi
Non esposti Uomini 9,000 0.5% 45
Donne 1,000 0.1% 1
RR grezzo=460/46=10.0

Studio caso-controllo appaiato(tutti i casi, 1 controllo per caso)
Casi
4,550 maschi 4500 esposti 50 non esposti
190 femmine 100 esposti 90 non esposti
4740 totale 4600 esposti 140 non esposti
Controlli
4,550 maschi 4095 esposti 455 non esposti
190 femmine 19 esposti 171 non esposti
4740 totale 4114 esposti 626 non esposti

Studio caso-controllo appaiato(tutti i casi, 1 controllo per caso)
Esposti Non esposti
Casi 4600 140
Controlli 4114 626
ORgrezzo=(4600*626)/(140*4114)=5.0

Studio caso-controllo appaiato(tutti i casi, 1 controllo per caso)
Uomini Donne
Esposti Non esposti Esposti Non esposti
Casi 4500 50 Casi 100 90
Controlli 4095 455 Controlli 19 171
OR=10.0 OR=10.0

Evitare i bias

Evitare i bias