Investigating Data Augmentation Strategies for Advancing ...
31
Winston H. Hsu () Professor, National Taiwan University Director, NVIDIA AI Lab (NTU) Investigating Data Augmentation Strategies for Advancing Deep Learning Training Office: R512, CSIE Building Communication and Multimedia Lab () http://winstonhsu.info March 26, 2018 GTC 2018 – Winston Hsu Outline § Why data augmentation in deep learning? § Data augmentation strategies by – Data crawling – Weakly supervised learning (least effort for data) – Data transformation – Synthesizing § Summary 2
Transcript of Investigating Data Augmentation Strategies for Advancing ...

Winston H. Hsu (���)Professor, National Taiwan UniversityDirector, NVIDIA AI Lab (NTU)
Investigating Data Augmentation Strategies for Advancing Deep Learning Training
Office: R512, CSIE BuildingCommunication and Multimedia Lab (�������)http://winstonhsu.info
March 26, 2018
GTC 2018 – Winston Hsu
Outline
§ Why data augmentation in deep learning?
§ Data augmentation strategies by– Data crawling– Weakly supervised learning (least effort for data)– Data transformation– Synthesizing
§ Summary
2

GTC 2018 – Winston Hsu
Deep Learning – A Paradigm Shift in Machine Learning
§ Competitive “deep” neural network
§ Automatic feature learning (convolution)
§ Huge improvements in image/video recognition tasks; so do in audio/speech applications; but marginally in text analytics
§ For example, classification track in ILSVRC (Top 5 Error)
3
Year Team Result Note
2012 SuperVision 0.15 1st Place (CNN)
2012 ISI 0.26 2nd Place (Conventional)
2015 MSRA 0.036 1st Place (CNN)
over 96% accuracy if 5 guesses are provided
GTC 2018 – Winston Hsu
Why Deep Neural Networks So Powerful?
§ “End-to-end training” by – Huge training data, GPUs, advanced algorithms, etc.
training label
“dog”
training image
backpropagation
f(Y |X;Θ)f(Y |X;Θ)f(Y |X;Θ)
4

GTC 2018 – Winston Hsu 5
Deficiencies in Convolutional Neural Networks for Industry Products
Positive Examples
Negative Examples
Feature Extraction & Learning(CNN)
huge training data required, collected manually now
bulky parameters & computations
multimodal data ignored
Prediction
proper network structures?
GTC 2018 – Winston Hsu
Data is Vital across Learning Paradigms – Example via the (Old) Computer Vision Methods
§ PASCAL VOC detection challenge provides realistic benchmark of object detection performance
6Zhu et al. Do We Need More Training Data or Better Models for Object Detection? BMVC 2012

GTC 2018 – Winston Hsu
Data is Vital for Deep Learning
§ AI algorithm is biased?
§ Story covered in “Facial Recognition Is Accurate, if You’re a White Guy,” The New York Times, Feb. 9, 2018
§ Actually, “gender classification” error caused by lacking quality data in certain categories– e.g., the darker the skin, the more
errors arise
– More specific training data will help
7https://www.nytimes.com/2018/02/09/technology/facial-recognition-race-artificial-intelligence.html
GTC 2018 – Winston Hsu
training label
“dog”
training data
backpropagation
f(Y |X;Θ)f(Y |X;Θ)f(Y |X;Θ)
8
Where/How to Get Quality Training Data in an Efficient and Effective Way?
?

GTC 2018 – Winston Hsu 9
Data Crawling
GTC 2018 – Winston Hsu
Rich Image/Videos, Comments, Metadata (GPS, Tags, Time, etc.) in Social Media
10
Why? Sharing for organizationand social communication[Ames, et al., CHI’07]
GTC 2018 – Winston Hsu
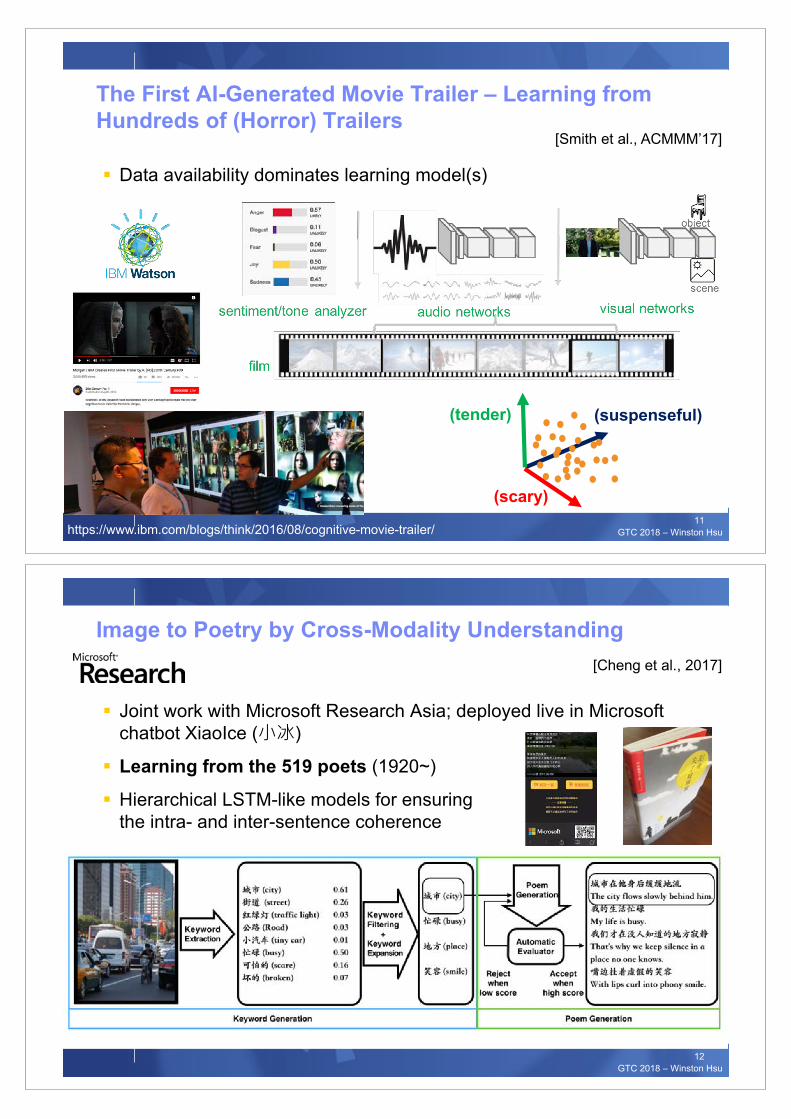
The First AI-Generated Movie Trailer – Learning from Hundreds of (Horror) Trailers
(tender)
(scary)
(suspenseful)
https://www.ibm.com/blogs/think/2016/08/cognitive-movie-trailer/
[Smith et al., ACMMM’17]
11
§ Data availability dominates learning model(s)
GTC 2018 – Winston Hsu
Image to Poetry by Cross-Modality Understanding
§ Joint work with Microsoft Research Asia; deployed live in Microsoft chatbot XiaoIce (��)
§ Learning from the 519 poets (1920~)
§ Hierarchical LSTM-like models for ensuring the intra- and inter-sentence coherence
[Cheng et al., 2017]
12

GTC 2018 – Winston Hsu
Netizen-Style Commenting by Learning from Fashion Communities – NetiLook (Public) Dataset
§ Contributing the first (large-scale) clothing dataset named NetiLookto discover netizen-style comments; 355,205 images from 11,034users and 5 million associated comments collected from Lookbook.
§ Investigating commenting diversity by topic-parameterized neural networks (NSC)
13Lin et al., Netizen-Style Commenting on Fashion Photos – Dataset and Diversity Measures, WWW 2018
GTC 2018 – Winston Hsu
14
Social Media are Noisy and Biased
§ Subjective and inaccurate for social tagging [Chang, 08]
§ Bias in many aspects: gender, length, etc. (e.g., NetiLook Dataset)
Locations Precision
Brooklyn Br. 0.38
Chrysler Building 0.65
Columbia University 0.30
Empire State Building 0.18
New York Landmark Labels (Flickr)
Longest : 1,314
Avg: 3.78
word freq.
23661739
277
Unknown Female �ale

GTC 2018 – Winston Hsu 15
Data Annotation – Gaming with a Purpose
§ ESP Game: labeling image as games [von Ahn, SIGCHI’04]
– Two people see the same image, and type keywords until they match
§ Other variants: – PeekABoom, Google Labeler, and more in www.gwap.com
– Label Me
GTC 2018 – Winston Hsu 16
Data Annotation – Advanced Approaches
§ Information beyond images / videos– speech, semantic network, location, hybrid tag/browse and … mind-reading
http://www.expertsystem.net
Yahoo! ZoneTag
IBM Speech Recognition Brain-Computer Interface(Pic. From www.ice.hut.fi)
Hybrid Tag-BrowseLabeler[Yan et al., 2008]

GTC 2018 – Winston Hsu
Data Annotation – Outsourcing Labeling Task
§ Goal – outsourcing tasks to a distributed group of people– to share the annotation efforts– to reduce the personal bias
§ Paid crowd-sourcing byAmazon Mechanical Turk
§ Mechanisms for ensuring quality– Being completely answered in a HIT– Consistence for the “duplicated” questions in a HIT– Avoiding robots– …
§ Nice tutorial for annotations for numerous visual learning tasks in [Kovashka et al.]
17
Worker Requester
12 + 33
Kovashka et al., Crowdsourcing in Computer Vision. Foundations and Trends in Computer Graphics and Vision. 2016
GTC 2018 – Winston Hsu
Leveraging Product Images for Fine-Grained Vehicle Detection and Visual Census Estimation
§ Goal – data-driven, machine learning-driven approaches are cheaper for collecting (predicting) census data (e.g., income, per capita carbon emission, crime rates, etc.) from Google Street View images
§ Dataset – the largest fine-grained dataset reported to date consisting of over 2600 classes of cars comprised of images from Street View and other web sources, classified by car experts and AMT (object)
18Gebru et al. Fine-Grained Car Detection for Visual Census Estimation. AAAI 2017
Expensive/Cheap clusters of cars in Chicago
Zip code level median household income in Chicago.

GTC 2018 – Winston Hsu
“Automatically” Acquiring Effective Training Images for Learning Facial Attributes
§ Challenges:
– Noise
– Visual diversity
– Geographical diversity
§ Goals
– Effectiveness for general facial attributes à data/feature selection
– More diversity in training data à enhanced by contexts19
malebeard
Africankid
femalesunglasses
by visual relevance
by textual relevance
Geographically Uneven user-contributed photos
Chen et al. Automatic Training Image Acquisition and Effective Feature Selection From Community-Contributed Photos for Facial Attribute Detection. IEEE TMM 2013
GTC 2018 – Winston Hsu
Balancing Content and Context from Social Images
20
Textual
Relevance
Visual
Consistency
Regularization
22)(min kkk
K
kkkp
ppgtp gb +--å
GvBg kG
k)(1-=
Limit the number of images from a
grid
: votes from pseudo positives
(negatives), weighted by
: relative in a grid
pk: annotation quality; selection indicator [0, 1]
kv
kvkgmx

GTC 2018 – Winston Hsu
Geographical Diversity for Training Facial Recognizers
21
without geo-context
with geo-context
elder kid maleClassificationError Rate (%) 26.33 (-0.00) 18.66 (-0.67) 24.50 (-3.00)
GTC 2018 – Winston Hsu 22
Least Effort for the Data

GTC 2018 – Winston Hsu
Learning from Noisy Labels – Annotation is Very Expensive (1/2)
§ A multi-task network that jointly learns to clean noisy annotations and to accurately classify images
§ Using the small clean dataset to learn a mapping between noisy and clean annotations (in a residual manner).
23Veit at al. Learning From Noisy Large-Scale Datasets With Minimal Supervision. CVPR 2017
encoder + decoder
residual connection
GTC 2018 – Winston Hsu
Learning from Noisy Labels – Annotation is Very Expensive (2/2)
§ Using the clean labels to directly fine-tune a network trained on the noisy labels does not fully leverage the information
§ Clean labels are used to reduce the noise in the large dataset beforefine-tuning the network using both the clean labels and the full dataset with reduced noise.
§ Experiments in Open Images dataset, – Noisy set: ∼9 million images over
6000 unique classes– Small clean set: ∼40k images.
24

GTC 2018 – Winston Hsu
Network in Network (NIN) – Compact Networks with Global Average Pooling
25
NIN for ImageNet Object Classification
Parameter Number Performance Time to train (GTX Titan)
AlexNet 60 Million (230 Megabytes) 40.7% (Top 1) 8 days
NIN 7.5 Million (29 Megabytes) 39.2% (Top 1) 4 days
A simple 4 layer NIN + Global Average Pooling:
GTC 2018 – Winston Hsu
Global Average Pooling – Huge Parameter Saving by Removing FC Layers
§ Global average pooling layer produces spatial average of feature maps as confidence of categories
§ Correspondence between feature maps and categories preserved; more meaningful and interpretable.
§ No parameters (compared to fully connected layers) à prevent overfitting
§ Robust to spatial translations of input26
Global Average Pooling
Save a large portion of parameters
CNN NIN
Explicitly confidence map of each category CNN NIN

GTC 2018 – Winston Hsu
Side Product for Global Average Pooling – Visualizing Learned Spatial Correspondence
27
1. airplane, 2. automobile, 3. bird, 4. cat, 5. deer, 6. dog, 7. frog, 8. horse, 9. ship, 10. truck
GTC 2018 – Winston Hsu
Class Activation Map for Weakly Supervised Object Localization (1/3)
§ Investigating what CNN is looking in image classification– Global Average Pooling (GAP): (1) Does not harm classification results,
(2) Remarkable localization ability– Class Activation Map (CAM)
28Zhou et al. Learning Deep Features for Discriminative Localization. CVPR 2016

GTC 2018 – Winston Hsu
Class Activation Map for Weakly Supervised Object Localization (2/3)
§ The CAMs of two classes from ILSVRC. The maps highlight the discriminative image regions used for image classification, the head of the animal for “briard” and the plates in “barbell”.
29
GTC 2018 – Winston Hsu
Class Activation Map for Weakly Supervised Object Localization (3/3)
30* Green: Groundtruth* Red: Prediect

GTC 2018 – Winston Hsu
Weakly Supervised Object Detection
§ Usual object detector is trained by dataset annotated with bounding boxes– Collecting those labels can be very costly and labor intensive.– For fields like medical imaging, the labels are even more
expensive.– Image-level annotation is much easier to get
§ Weakly Supervised object detection– Aim to train the model to localize the
object with only image level supervision (only class label, no bounding boxes)
31
GTC 2018 – Winston Hsu
Weakly Supervised Learning for Localizing Thoracic Diseases – Problem Definition
§ Bounding box labels for medical images require professionals to generate the training data. It’s rather time-consuming and expensive.
§ Goal – train the network to automatically localize the lesions with only image level supervision. (no bounding box info)
32Wang et al., ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. CVPR 2017
Red: Ground truth bboxGreen: Predicted bbox
Infiltration

GTC 2018 – Winston Hsu
NIH Chest X-Ray 8 Dataset
§ Training: 108,948, 8 frontal view X-ray images of 32,717 unique patients with the recording containing disease image class labels (noisy)
§ 985 human annotated bounding boxes on 880 images by 8 chest pathologies
33Wang et al., ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. CVPR 2017
GTC 2018 – Winston Hsu
Baseline Proposal and Results
§ A multi-label classifier with pooling layer (LSE) to increase the localize capability of the network (mixture of GAP and GMP).
§ Multiply the weights from prediction layers with the conv feature map to generate the activation heatmap of a specific class, similar to CAM
34
Mass
Wang et al., ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. CVPR 2017

GTC 2018 – Winston Hsu 35
Data Transformation
GTC 2018 – Winston Hsu
Recent Data Augmentation Methods
§ Summarized by Thoma in arXiv’17
§ Further operations– Adding noise– Elastic deformations– Color casting– Vignetting– Lens distortion
36Martin Thoma. Analysis and Optimization of Convolutional Neural Network Architectures. arXiv 2017.
horizontal flipcrops

GTC 2018 – Winston Hsu
Deep Image: Scaling up Image Recognition –Wu et al., arxiv, 2015 (Baidu)
§ Data augmentation– Cropping, shifting, color casting, lens
distortion, vignetting, etc.
§ Training on multi-scale images, including high-resolution ones– 512x512 vs. 224x224
§ Hardware/software co-design for parallel computation– The number of weights is 212.7M– Estimated with 1GB for parameters
37
Deep Image: Scaling up Image Recognition
Figure 4. Validation set accuracy for different numbers of GPUs.
4. Training Data4.1. Data Augmentation
The phrase “the more you see, the more you know” is truefor humans as well as neural networks, especially for mod-ern deep neural networks.
We are now capable of building very large deep neural net-works up to hundreds of billions parameters thanks to ded-icated supercomputers such as Minwa. The available train-ing data is simply not sufficient to train a network of thissize. Additionally, the examples collected are often just ina form of ‘good’ data - or a rather small and heavily bi-ased subset of the possible space. It is desired to show thenetwork with more data with broad coverage.
The authors of this paper believe that data augmentationis fundamentally important for improving the performanceof the networks. We would like the network to learn theimportant features that are invariant for the object classes,rather than the artifact of the training images. We have ex-plored many different ways of doing augmentation, someof which are discussed in this section.
It is clear that an object would not change its class if am-bient lighting changes, or if the observer is replaced by an-other. More specifically, this is to say that the neural net-work model should be less sensitive to colors that are drivenby the illuminants of the scene, or the optical systems fromvarious observers. This observation has led us to focus onsome of the key augmentations, such as color casting, vi-gnetting, and lens distortion, as shown in the Figure 5.
Different from the color shifting in (Krizhevsky et al.,2012), we perform color casting to alter the intensities ofthe RGB channels in training images. Specifically, for eachimage, we generate three Boolean values to determine if theR, G and B channels should be altered, respectively. If onechannel should be altered, we add a random integer ranging
Original photo Red color casting Green color casting Blue color casting
RGB all changed Vignette More vignette Blue casting + vignette
Left rotation, crop Right rotation, crop Pincushion distortion Barrel distortion
Horizontal stretch More Horizontal stretch Vertical stretch More vertical stretch
Figure 5. Effects of data augmentation.
from -20 to +20 to that channel.
Vignetting means making the periphery of an image darkcompared to the image center. In our implementation, thereare two randomly changeable variables for a vignette effect.The first is the area to add the effect. The second is howmuch brightness is reduced.
Lens distortion is a deviation from rectilinear projectioncaused by the lens of camera. The type of distortion andthe degree of distortion are randomly changeable. The hor-izontal and vertical starching of images can also be viewedas special kind of lens distortion.
We also adopt some augmentations that were proposed bythe previous work, such as flipping and cropping (Howard,2013), (Krizhevsky et al., 2012). To ensure that the wholeaugmented image feeds into the training net, all the aug-mentations are performed on the cropped image (exceptcropping).
An interesting fact worth pointing out is that both profes-sional photographers and amateurs often use color casting
GTC 2018 – Winston Hsu
Deep Image: Scaling up Image Recognition –Wu et al., arxiv, 2015 (Baidu)
§ Configurations– 36 server nodes; each with 4 nvidia Tesla K40; FDR InfiniBand (56Gb/s)– Data parallelism in convolutional layers and model parallelism in FC layers– SGD synchronization: asynchronous updates
§ Impacts
38
Figure 3: Left: The scalability of different parallel approaches. The hybrid parallelism is
better when number of GPUs is less than 16. The scalability of data parallelism is better with large numbers of GPU because the communication consuming is constant. Right: The
speedup of going through images. The larger the batch size is, the larger the speedup is.
Figure 4: Validation set accuracy for different numbers of GPUs.
4 Training Data 4 .1 Da ta Aug menta t io n
The phrase “the more you see, the more you know” is true for humans as well as neural networks, especially for modern deep neural networks.
We are now capable of building very large deep neural networks up to hundreds of billions parameters thanks to dedicated supercomputers such as Minwa. The available training data is simply not sufficient to train a network of this size. Additionally, the examples collected are often just in a form of ‘good’ data – or a rather small and heavily biased subset of the possible space. It is desired to show the network with more data with broad coverage.
The authors of this paper believe that data augmentation is fundamentally important for improving the performance of the networks. We would like the network to learn the important features that are invariant for the object classes, rather than the artifact of the training images. We have explored many different ways of doing augmentation, some of which are discussed in this section.
It is clear that an object would not change its class if ambient lighting changes, or if the observer is replaced by another. More specifically, this is to say that the neural network model should be less sensitive to colors that are driven by the illuminants of the scene, or the
0
0.2
0.4
0.6
0.8
1
1.2
1 4 16 32 64
Spee
dup
/ GPU
num
ber
GPU number
slices=64, model-data parallelslices=64, data parallel
0
10
20
30
40
50
16 32 64
Spee
dup
GPU number
batch size 256batch size 512batch size 1024
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.25 0.5 1 2 4 8 16 32 64 128 256
Accu
racy
Time (hours)
32 GPU16 GPU1 GPU
Accuracy 80%
32 GPU: 8.6 hours 1 GPU: 212 hours Speedup: 24.7x
the algorithms for large scale image classification. There are more than 15 million images belonging to about 22,000 categories in the ImageNet dataset, and ILSVRC uses a subset of about 1.2 million images which contains 1,000 categories. After the great success of convolutional networks (ConvNets) for this challenge, there is increasing attention both from industry and academic communities to build a more accurate ConvNet system with the help of powerful computing platforms, such as GPU and CPU clusters.
As shown in Table 3, the accuracy has been optimized a lot during the last three years. The best result of ILSVRC 2014, top-5 error rate of 6.66%, is not far from human recognition performance of 5.1% [18]. Our work marks yet another exciting milestone with the top-5 error rate of 5.98%, not just setting the new record but also closing the gap between computers and humans by almost half.
We only use the provided data from the dataset of ILSVRC 2014. Taking advantage of data augmentation and random crops from high-resolution training images, we are able to reduce the risk of overfitting, despite our larger models. As listed in Table 2, one basic configuration has 16 layers and is similar with VGG’s work [20]. The number of weights in our configuration is 212.7M. For other models we have varied the number of the filters at convolutional layers and the neurons at fully-connected layers up to 1024 and 8192, respectively. Six trained models with different configurations, each focusing on various image scales and data augmentation methods respectively, are combined by simple averaging of the softmax class posteriors. The independent training procedure of these models makes them complementary and gives better results than each individual.
Table 2: Basic configuration for one of our models. Layers Conv 1-2 Max pool Conv 3-4 Max pool Conv 5-6-7 Max pool # filters 64 128 256
Conv 8-9-10 Max pool
Conv 11-12-13 Max pool
FC 1-2 FC 3 Softmax
512 512 6144 1000
Inspired by [19], a transformed network with only convolutional layers is used to test images and the class scores from the feature map of the last layer are averaged to attain the final score. We also tested single images at multiple scales and combined the results, which will cover portions of the images with different sizes, and allow the network to recognize the object in a proper scale. The horizontal flipping of the images are also tested and combined.
Table 3: ILSVRC classification task top-5 performance (with provided training data only). Team Year Place Top-5 error
SuperVision 2012 1 16.42% ISI 2012 2 26.17% VGG 2012 3 26.98% Clarifai 2013 1 11.74% NUS 2013 2 12.95% ZF 2013 3 13.51% GoogLeNet 2014 1 6.66% VGG 2014 2 7.32% MSRA 2014 3 8.06% Andrew Howard 2014 4 8.11% DeeperVision 2014 5 9.51% Deep Image - - 5.98%
Table 4: Single model comparison. Team Top-1 val. error Top-5 val. error
GoogLeNet [21] - 7.89% VGG [20] 25.9% 8.0% Deep Image 24.88% 7.42%
As shown in Table 3, the top-5 accuracy has been improved a lot in last three years. Deep Image has set the new record of 5.98% top-5 error rate for test dataset, a 10.2% relative improvement than the previous best result.

GTC 2018 – Winston Hsu
Industry Example – Image Recognition for Consumer Photo Management by Synology Inc. (1/2)
§ Securing robustness in recognizing consumer photos, often suffering from varying lighting conditions
39
w/o augmentation
w/ augmentation
Confidence score for label “beach”
GTC 2018 – Winston Hsu
Industry Example – Image Recognition for Consumer Photo Management by Synology Inc. (2/2)
§ Random flip, random crop
§ Python open source image augmentation library: imgaug– Using blur, gaussian noise, brightness, hue, contrast and gray scale
40

GTC 2018 – Winston Hsu
“Shrinking Image” for Learning Super-Resolution (or Face Hallucination)
§ 1/16 or 1/64 size of the original (high quality) one for measuring the reconstruction quality (pixel level or perceptual level)
§ Mostly with encoder-decoder structure
41
• Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. CVPR 2017 ‘• Johnson et al. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. ECCV 2016 • Dong et al. Accelerating the Super-Resolution Convolutional Neural Network. ECCV 2016
Face Hallucination
12 x 14 96 x 112
LowResolution Generated
by our method
groundtruth
[Zhang et al., 2018]
GTC 2018 – Winston Hsu
“Simulated Blurred Images” for Learning De-blurring
§ Simulated blurred data from the original (high quality) one
42
• Gong et al., From Motion Blur to Motion Flow: a Deep Learning Solution for Removing Heterogeneous Motion Blur. CVPR 2017• Liang et al., Dual Motion GAN for Future-Flow Embedded Video Prediction. ICCV 2017

GTC 2018 – Winston Hsu 43
Synthesizing Data
GTC 2018 – Winston Hsu
Learning Object Detector from 3D Models (1/5)
§ Motivations – labelling images for detection is time-consuming.– Every object must be marked with a bounding box.
§ Augmenting the training data with synthetic images rendered from 3D CAD models (e.g., 3dwarehouse)
44Peng et al. Learning Deep Object Detectors from 3D Models. ICCV 2015.

GTC 2018 – Winston Hsu
Learning Object Detector from 3D Models (2/5)
§ How variations in low-level cues affect the features by CNN on the object detection (e.g., PASCAL VOC2007 dataset).– Object color, texture and context
– Synthetic image pose
– 3D Shape
45
GTC 2018 – Winston Hsu
Learning Object Detector from 3D Models (3/5)– Object color, Texture and Context
46
the network has learned to be invariant to the color and texture of the object and its background.

GTC 2018 – Winston Hsu
Learning Object Detector from 3D Models (4/5)– Experiments in Synthetic Pose
§ Adding side view to front view gives a boost.
§ Less invariance.
47
GTC 2018 – Winston Hsu
Learning Object Detector from 3D Models (5/5) –Training Object Detection with Limited Real Images
§ When the number of real training images is limited, 3D models performs better than traditional RCNN over limited training data.
48

GTC 2018 – Winston Hsu
Augmented Reality for Data Generation (1/3) –Motivations
§ Creating realistic 3D content is challenging and labor-intensive.
§ Real-world images at large scale is easy and directly provides real background appearances without complex 3D models
§ Augmented imagery generalizes better than synthetic 3D data or limited real data
49Alhaija et al., Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes. BMVC 2017
GTC 2018 – Winston Hsu
Augmented Reality for Data Generation (2/3) –Augmentation Pipeline
§ Given a set of 3D car models, locations (manual or automatic) and environment maps
§ Rendering high quality cars and overlay them on top of real images.
§ The final post-processing step ensures better visual matching between the rendered and real parts of the resulting image.
50Alhaija et al., Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes. BMVC 2017

GTC 2018 – Winston Hsu
Augmented Reality for Data Generation (3/3) – Impacts Measured by Instance (Car) Segmentation
§ More data – real or augmented – are both helpful
§ Augmented foreground cars with real backgrounds are effective
51Alhaija et al., Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes. BMVC 2017
GTC 2018 – Winston Hsu
Face Recognition (Verification or Identification) by Varying (Multi-Tasking) Loss and Datasets
52
Metric learning
CNNdata loss
feature
Dataset #Images #Persons #Images per personCASIA 0.49M 10K 50VGGFace 2M 2K 1000Megaface2 4.8M 672K 7MS-celeb 10M 100K 100UMDFace 0.37M 8.5K 40
1 : 1
Gallery setProbe set
1 : N
Face verification
Face Identification

GTC 2018 – Winston Hsu
Industry Example – Augmented Glasses for Face Recognition (1/2) by Video Surveillance SBU, LiteOn
§ Problem – Each pair is the same person but predicted to different people (red pairs) by the deep methods because of thick glasses
§ Why? Few faces with glasses in most face datasets but common in Asian
53
GTC 2018 – Winston Hsu
Industry Example – Augmented Glasses for Face Recognition (2/2) by Video Surveillance SBU, LiteOn
§ Glass invariance augmentation by overlapping variant glass models
§ Impacts on proprietary benchmarks include 21,570 face (glass) pairs
54
w/o glasses aug. w/ glasses aug.
Accuracy 99.207% 99.420%Error case on glasses 109 40

GTC 2018 – Winston Hsu
(Real-Time) Style Transfer by Perceptual Losses
Johnson et al. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. ECCV 2016
encoder-decoder
55
GTC 2018 – Winston Hsu
CycleGAN for Synthesizing “Realistic” Training Data
56
• Zhu et al., Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks ICCV 2017• Zhang et al., Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency
Generative Adversarial Network. CVPR 2018

GTC 2018 – Winston Hsu
CycleGAN for Synthesizing “Realistic” Training Data
§ Purposes for synthesized medical images – as an intermedium in cross-modality image registration or learning – as supplementary training samples to boost the generalization capability
§ Our modified CybleGAN for multimodal recognition for utilizing MRI and CT (here CT à MRI) in Nasopharyngeal Carcinoma (NPC)
57
synthesized or real?
synthesized or real?
GTC 2018 – Winston Hsu
Summary – Utilizing Data Efficiently and Effectively
data crawling
weakly supervised
transformation
intra-domain
synthesizing
cross-domain
58

GTC 2018 – Winston Hsu 59
Take Home Messages
GTC 2018 – Winston Hsu
Take Home Messages
§ Data are vital for learning paradigms but very costly
§ Collecting more training data from public datasets
– Used for multi-task learning or pre-training
§ Augment data with
– Social media
– Synthesized data: transformed data, 3D, AR, GAN,
– Work with the noisy data
– Weakly supervised methods for minimizing human costs
§ Data augmentation is vital for industry applications and will emerge as an important technical component
§ Privacy! Privacy! Privacy!
60

GTC 2018 – Winston Hsu 61
Facebook, LinkedIn: “Winston Hsu”