
Introducing the SILS Learner Corpus Victoria Muehleisen Waseda University.
34
Victoria Muehleisen Waseda University
-
Upload
arthur-fisher -
Category
Documents
-
view
223 -
download
0
Transcript of Introducing the SILS Learner Corpus Victoria Muehleisen Waseda University.

Victoria MuehleisenWaseda University

SILS = School of International Liberal Studies at Waseda University in Tokyo.
Waseda was founded in 1882, but SILS was only started in April 2004.

The SILS curriculum is mainly taught in English.
The majority of students are Japanese who have been educated in Japan, but a growing number come from other (mainly Asian) countries and/or have been educated outside of Japan.

Based on the results of a placement test (TOEFL-PBT), about 2/3 of entering students take extra classes in English reading and listening.
ALL students (regardless of English ability) take English writing courses.

There are three levels of writing class, and students are placed by means of an in-house placement test.
All students must complete the Advanced Level before graduating: most do this within the first three semesters, before study abroad.

We are collecting the essays from the required writing classes for the SILS corpus.
In the first few weeks of their first writing class, the corpus project is explained to students, and they are asked for their permission.

Those who agree also fill out a survey about their language background.
All essays for the writing classes are submitted on-line, so after permission has been given, the teachers and students don’t have to do anything else. The essays are automatically collected.

At any time until they graduate, students can ask for particular essays to be excluded, or even for all essays to be removed (but no one has done this so far.)

The essays are downloaded class-by-class throughout the semester.
The background survey data and essays are entered by graduate student workers into a custom-made database.

Gender, age, TOEFL score, native language(s), etc.
Where they have lived and studied, and what languages they used in these contexts…



Each semester, we make a class list for all the students in each class who are participating in the project.
The class lists are used to organize the data entry.
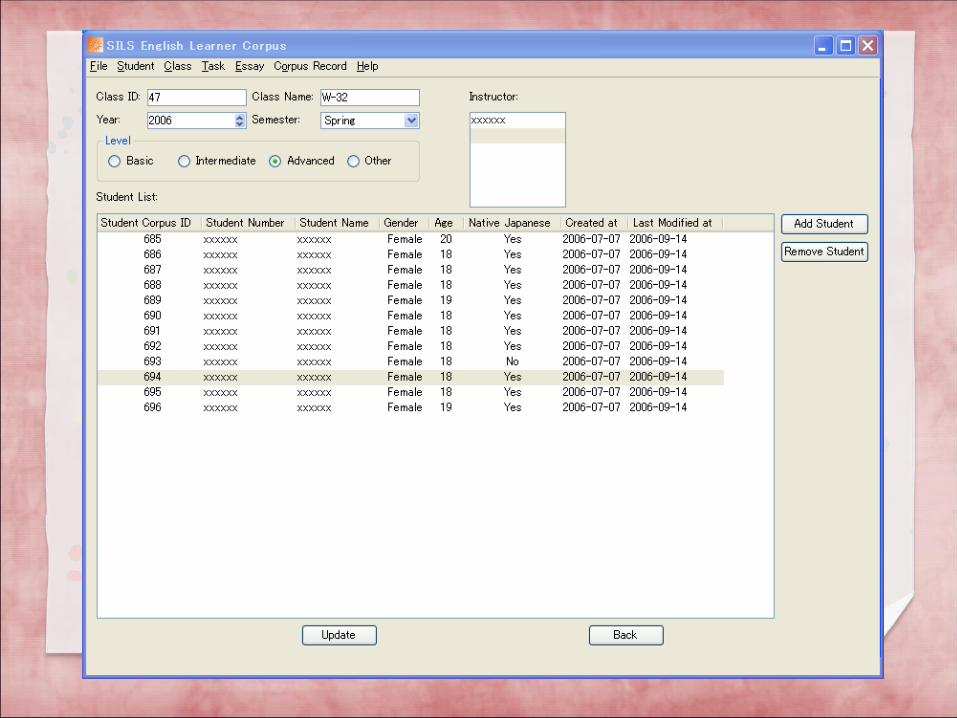

The database also includes detailed information about the assignments the students were given.


Students upload their essays using their preferred word-processing program (usually a version of Word, but some as plain text).
After we download the essays, we use cut-and-paste to put them into the database. They become plain text (unicode).

Entering essays is a slow procedure! But we can’t change the way the essays are submitted for the courses, and we need to be sure that we only include essays by students who have given permission.

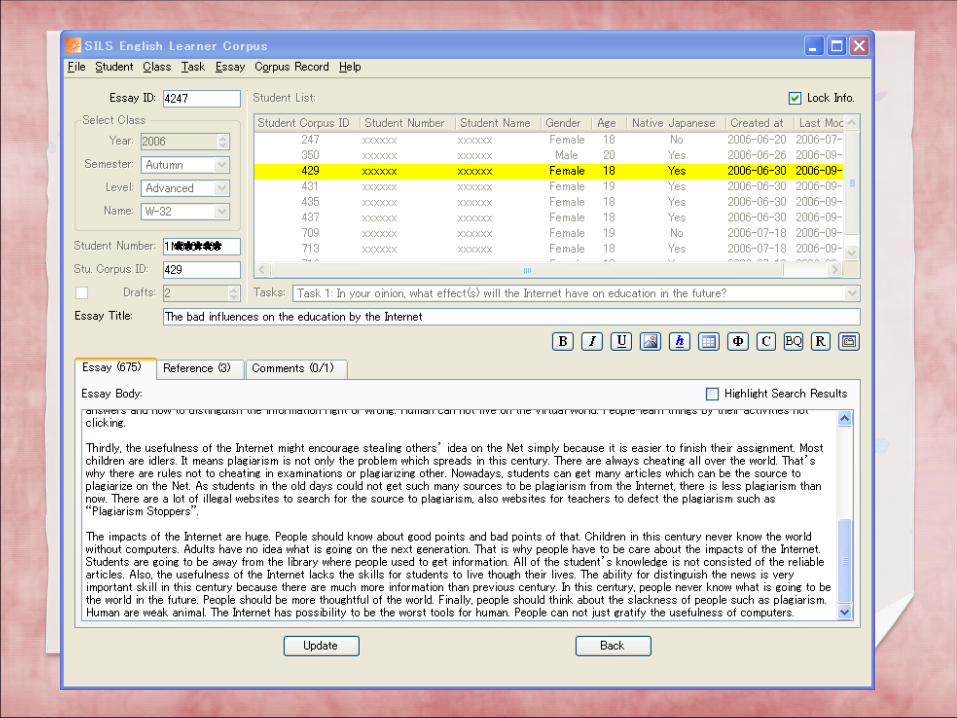
When putting the essays into the database, some formatting is lost (e.g., margins, font), but we make sure to keep some kinds: paragraph breaks, font styles (italic, bold, underline).
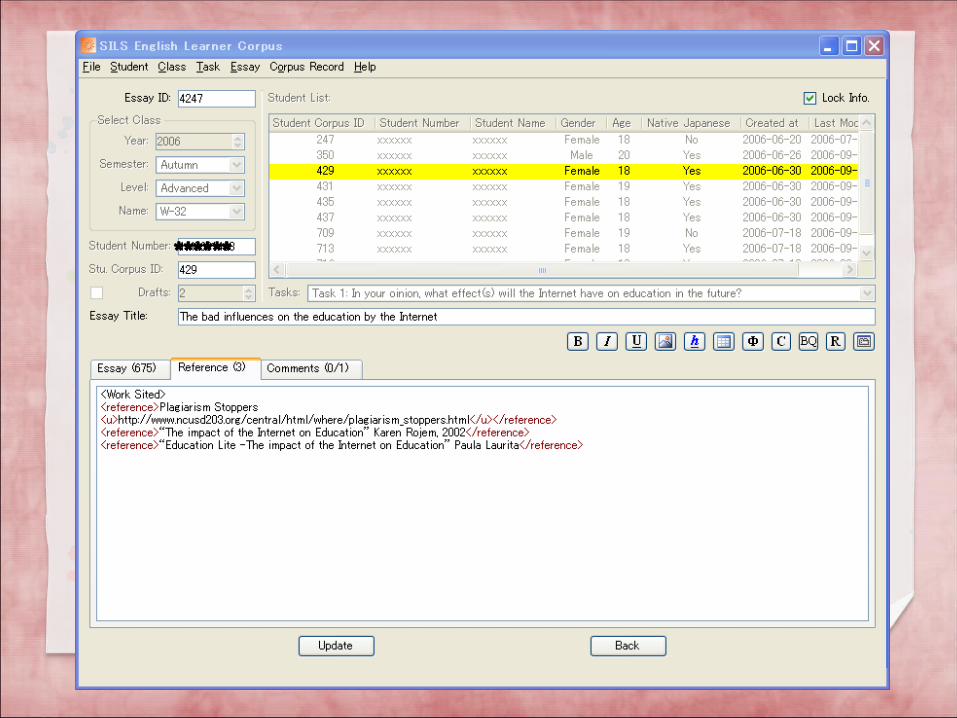
We also have ways to describe tables
or pictures which are removed.

The title, essay body, and references are put into separate sections. Students’ names are removed, of course.
Both first drafts and second drafts (when available) are included in the database.

There are no plans to annotate the whole corpus for errors or POS, but we may try it with small sub-corpora at some future time.

After three semesters (Fall 2005, Spring 2006, and Fall 2006) , we have 2800 first drafts, and more than 5000 essays including both first and second drafts.

The total number of words is around 1,650,000 for first drafts only, 3,180,000 for both first and second drafts.

There are essays by about 700 different students.
Most of these have Japanese as their native language, but there are also 39 students whose native language is Chinese, 33 for Korean, 13 for English, and 6 for others.

We are currently inputting the essays from the Spring 2007 semester (which starts in April and runs through the end of July).

We can output a tailor-made corpus created using the variables mentioned already.
For example, we can create a corpus of all the essays written by women whose native language is Chinese.

We can make a corpus of first drafts of a particular assignment and compare it to the second drafts.
We can even make a corpus of essays written for the advanced class in Fall 2006 by students with Japanese as a native language who started out in the intermediate class in spring and who went to high school in Japan.


Examining the effectiveness of the curriculum and materials used in the writing classes, e.g.students' use of quotation and
paraphrasing, which are emphasized in our writing courses.
differences in first and second drafts, to see how much and what students actually change.

We also plan to look at students’ overuse and underuse of collocations found in academic writing.
The extensive language background data should also make the corpus useful for people studying L1 influence in L2 writing.

At some point, data from the corpus will probably be publicly available, but I don’t know when. (It’s not clear who at the university would have to approve use of the data outside of Waseda.)

http://www.f.waseda.jp/vicky/learner/ index.html
A research report describing the creation of the corpus will be available on-line soon. Please check the website above for details.


















