
Finding Eigenvalues and Eigenvectors What is really important?
43
Finding Eigenvalues and Eigenvectors What is really important?
-
Upload
hilary-mills -
Category
Documents
-
view
263 -
download
10
Transcript of Finding Eigenvalues and Eigenvectors What is really important?

Finding Eigenvalues and Eigenvectors
What is really important?

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD2
Approaches
Find the characteristic polynomial– Leverrier’s Method
Find the largest or smallest eigenvalue– Power Method– Inverse Power Method
Find all the eigenvalues – Jacobi’s Method– Householder’s Method– QR Method– Danislevsky’s Method

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD3
Finding the Characteristic Polynomial
Reduces to finding the coefficients of the polynomial for the matrix A
Recall |I-A| = n+ann-1+an-1n-2+…+a21+a1
Leverrier’s Method– Set Bn = A and an = -trace(Bn)
– For k = (n-1) down to 1 computeBk = A (Bk+1 + ak+1I)
ak = - trace(Bk)/(n – k + 1)

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD4
Vectors that Span a Space and Linear Combinations of Vectors
Given a set of vectors v1, v2,…, vn The vectors are said span a space V, if given
any vector x ε V, there exist constants c1, c2,…, cn so that c1v1 + c2v2 +…+ cnvn = x and x is called a linear combination of the vi

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD5
Linear Independence and a Basis
Given a set of vectors v1, v2,…, vn and constants c1, c2,…, cn
The vectors are linearly independent if the only solution to c1v1 + c2v2 +…+ cnvn = 0 (the zero vector) is c1= c2=…=cn = 0
A linearly independent, spanning set is called a basis

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD6
Example 1: The Standard Basis
Consider the vectors v1 = <1, 0, 0>, v2 = <0, 1, 0>, and v3 = <0, 0, 1>
Clearly, c1v1 + c2v2 + c3v3 = 0 c1= c2= c3 = 0 Any vector <x, y, z> can be written as a linear
combination of v1, v2, and v3 as<x, y, z> = x v1 + y v2 + z v3
The collection {v1, v2, v3} is a basis for R3; indeed, it is the standard basis and is usually denoted with vector names i, j, and k, respectively.

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD7
Another Definition and Some Notation
Assume that the eigenvalues for an n x n matrix A can be ordered such that|1| > |2| ≥ |3| ≥ … ≥ |n-2| ≥ |n-1| > |n|
Then 1 is the dominant eigenvalue and |1| is the spectral radius of A, denoted (A)
The ith eigenvector will be denoted using superscripts as xi, subscripts being reserved for the components of x

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD8
Power Methods: The Direct Method
Assume an n x n matrix A has n linearly independent eigenvectors e1, e2,…, en ordered by decreasing eigenvalues|1| > |2| ≥ |3| ≥ … ≥ |n-2| ≥ |n-1| > |n|
Given any vector y0 ≠ 0, there exist constants ci, i = 1,…,n, such that y0 = c1e1 + c2e2 +…+ cnen

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD9
The Direct Method (continued)
If y0 is not orthogonal to e1, i.e., (y0)Te1≠ 0, y1 = Ay0 = A(c1e1 + c2e2 +…+ cnen)
= Ac1e1 + Ac2e2 +…+ Acnen
= c1Ae1 + c2Ae2 +…+ cnAen
Can you simplify the previous line?

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD10
The Direct Method (continued)
If y0 is not orthogonal to e1, i.e., (y0)Te1≠ 0, y1 = Ay0 = A(c1e1 + c2e2 +…+ cnen)
= Ac1e1 + Ac2e2 +…+ Acnen
= c1Ae1 + c2Ae2 +…+ cnAen
y1 = c11e1 + c22e2 +…+ cnnen
What is y2 = Ay1?

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD11
The Direct Method (continued)
n
k
i
kk
ii
n
k
ikk
ninn
iii
n
kkk
nnn
cc
cccc
cccc
2 1
111
1
222
111
1
222222
1211
or
...
general,in
...
k
k
k2
eey
eeeey
eeeey

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD12
The Direct Method (continued)
what?So
2 1
111
n
k
i
kk
ii cc keey
i as 0 so ,1 that Recall
11
i
kk

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD13
The Direct Method (continued)
i as
then
Since
111
2 1
111
ey
eey k
c
cc
ii
n
k
i
kk
ii

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD14
The Direct Method (continued)
Note: any nonzero multiple of an eigenvector is also an eigenvector
Why? Suppose e is an eigenvector of A, i.e., Ae=e
and c0 is a scalar such that x = ce Ax = A(ce) = c (Ae) = c (e) = (ce) = x

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD15
The Direct Method (continued)
1
1
1111
gnormalizinby
lyinordinate growing from prevent can weand
reigenvectoan toclosey arbitraril become will
reigenvectoan is and Since
i
ii
i
i
ii c
Ay
Ayy
y
y
eey

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD16
Direct Method (continued)
Given an eigenvector e for the matrix AWe have Ae = e and e0, so eTe 0 (a
scalar) Thus, eTAe = eTe = eTe 0 So = (eTAe) / (eTe)

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD17
Direct Method (completed)
ii
ii
iTi
iTi
i
y0r
yAIr
yy
Ayy
r eigenvecto with eigenvaluean is when
and
orerror vect residual theis
eigenvaluedominant theesapproximat
i
i

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD18
Direct Method Algorithm
m)(i and )r( While3.
1i i
x-yr
yy
xy
Ay x
x
xy
Do 2.
. and compute and 0 iSet
. and 0,m 0, Choose 1.
T
T
Ayx
0y

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD19
Jacobi’s Method
Requires a symmetric matrixMay take numerous iterations to converge Also requires repeated evaluation of the
arctan function
Isn’t there a better way? Yes, but we need to build some tools.

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD20
What Householder’s Method Does
Preprocesses a matrix A to produce an upper-Hessenberg form B
The eigenvalues of B are related to the eigenvalues of A by a linear transformation
Typically, the eigenvalues of B are easier to obtain because the transformation simplifies computation

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD21
Definition: Upper-Hessenberg Form
A matrix B is said to be in upper-Hessenberg form if it has the following structure:
nn,1-nn,
n1,-n1-n1,-n
4,3
n3,1-n3,3,33,2
n2,1-n2,2,32,22,1
n1,1-n1,1,31,21,1
bb000
bb
b00
bbbb0
bbbbb
bbbbb
B

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD22
A Useful Matrix Construction
Assume an n x 1 vector u 0 Consider the matrix P(u) defined by
P(u) = I – 2(uuT)/(uTu)Where
– I is the n x n identity matrix– (uuT) is an n x n matrix, the outer product of u
with its transpose– (uTu) here denotes the trace of a 1 x 1 matrix and
is the inner or dot product

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD23
Properties of P(u)
P2(u) = I – The notation here P2(u) = P(u) * P(u)– Can you show that P2(u) = I?
P-1(u) = P(u)– P(u) is its own inverse
PT(u) = P(u) – P(u) is its own transpose– Why?
P(u) is an orthogonal matrix

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD24
Householder’s Algorithm
Set Q = I, where I is an n x n identity matrix For k = 1 to n-2
– = sgn(Ak+1,k)sqrt((Ak+1,k)2+ (Ak+2,k)2+…+ (An,k)2)– uT = [0, 0, …, Ak+1,k+ , Ak+2,k,…, An,k]– P = I – 2(uuT)/(uTu)– Q = QP– A = PAP
Set B = A

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD25
Example
55143)sgn(3)sgn(aThen
1.k valueonly the k takes1, 2-n since and 3n Clearly,
.
984
653
321
Let
22231
22121
33
aa
x
A

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD26
Example
?
4
8
0
480
480
4
8
0
2
100
010
001
2
]480[]4530[
],,0[],...,,,0,...,0[ 312113121
uu
uuIP
u
T
T
nT
,,,,
aaaaa

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD27
Example
? Find .
5
3
5
40
5
4
5
30
001
16320
32640
000
80
2
100
010
001
4
8
0
480
480
4
8
0
2
100
010
001
2
2P
uu
uuIP
T
T
04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD28
Example
5
3
5
40
5
4
5
30
001
5
3
5
40
5
4
5
30
001
100
010
001
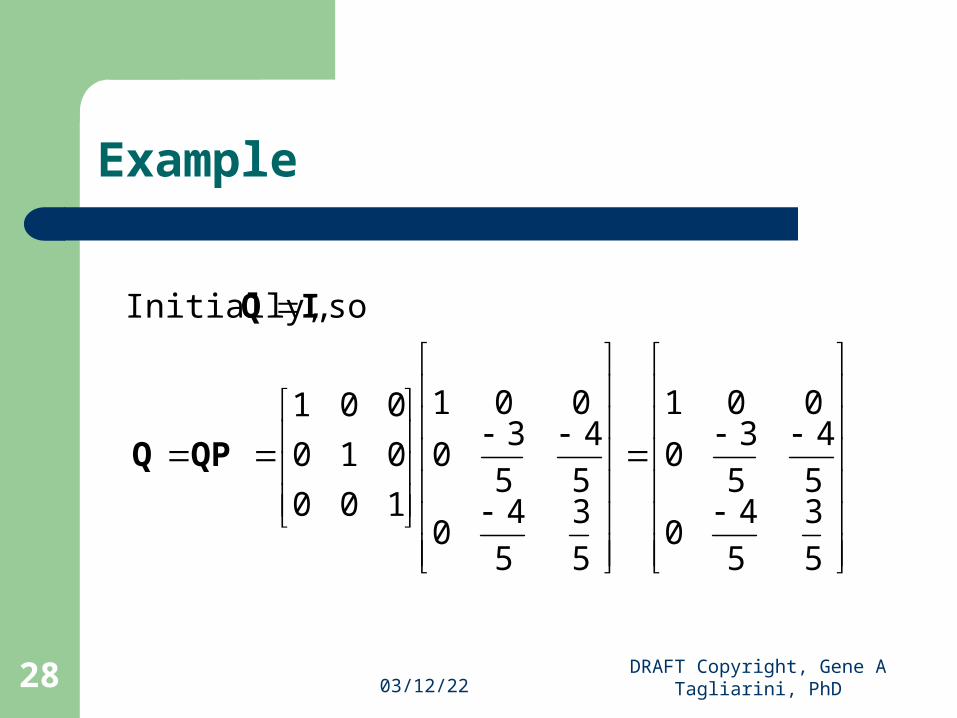
so , Initially,
QPQ
IQ
04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD29
Example
?
5
3
5
40
5
4
5
30
001
984
653
321
5
3
5
40
5
4
5
30
001
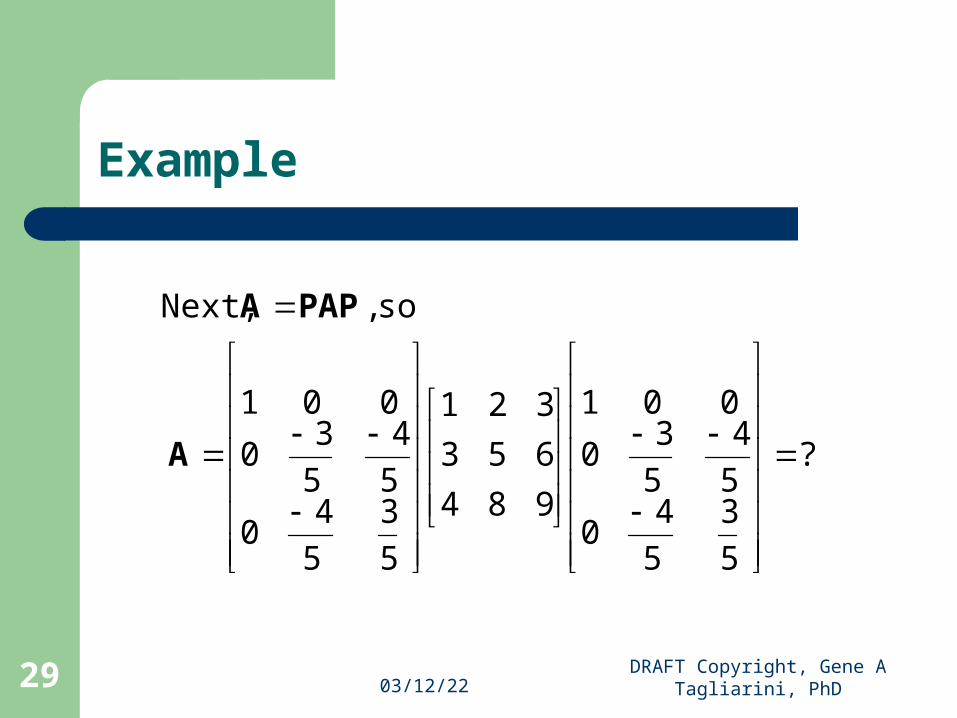
so , Next,
A
PAPA

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD30
Example
25
7-
25
24-0
25
26
25
3575-
5
1
5
18-1
5
3
5
40
5
4
5
30
001
5
3
5
40
5
54
5
475
321
5
3
5
40
5
4
5
30
001
984
653
321
5
3
5
40
5
4
5
30
001
Hence,
A

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD31
Example
what?So
.
25
7-
25
24-0
25
26
25
3575-
5
1
5
18-1
once executesonly loop thesince Finally,
AB

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD32
How Does It Work?
Householder’s algorithm uses a sequence of similarity transformationsB = P(uk) A P(uk)to create zeros below the first sub-diagonal
uk=[0, 0, …, Ak+1,k+ , Ak+2,k,…, An,k]T
= sgn(Ak+1,k)sqrt((Ak+1,k)2+ (Ak+2,k)2+…+ (An,k)2) By definition,
– sgn(x) = 1, if x≥0 and– sgn(x) = -1, if x<0

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD33
How Does It Work? (continued)
The matrix Q is orthogonal – the matrices P are orthogonal– Q is a product of the matrices P– The product of orthogonal matrices is an
orthogonal matrix
B = QT A Q hence Q B = Q QT A Q = A Q– Q QT = I (by the orthogonality of Q)

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD34
How Does It Work? (continued)
If ek is an eigenvector of B with eigenvalue k, then B ek = k
ek
Since Q B = A Q,A (Q ek) = Q (B ek) = Q (k ek) = k (Q ek)
Note from this:– k is an eigenvalue of A
– Q ek is the corresponding eigenvector of A

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD35
The QR Method: Start-up
Given a matrix A Apply Householder’s Algorithm to obtain a
matrix B in upper-Hessenberg form
Select >0 and m>0– is a acceptable proximity to zero for sub-
diagonal elements– m is an iteration limit

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD36
The QR Method: Main Loop
m)(i and ngular)block triaupper not is ( While}
;i
;
}
;
;
s;PP c;PP ;Set
;s ; c
1{-n to1kFor
Set
{ Do
TT
1kk,k1,k1k1,kkk,
2,1
2,
,1
2,1
2,
,
B
BQB
PQQ
PBB
IP
IQT
kkkk
kk
kkkk
kk
BB
B
BB
B

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD37
The QR Method: Finding The ’s
.2
)det(4)()(then
, i.e., 2x2, isblock diagonal a If
. then , i.e., 1x1, isblock diagonal a If
. blocks diagonal its of seigenvalue the
are of eigvalues thely,Specifical . of blocks diagonal the
from computemay one ngular,block triaupper is Since
2
1,
k
k
kkkkk
kk
kkk
tracetrace
dc
ba
aa
BBB
BB
BB
B
BB
B

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD38
Details Of The Eigenvalue Formulae
?
. Suppose
k
k
k
dc
ba
dc
ba
BI
BI
B

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD39
Details Of The Eigenvalue Formulae
)det()(
)(
))((
Given
2
2
kk
k
k
trace
bcadda
bcda
dc
ba
BB
BI
BI

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD40
Finding Roots of Polynomials
Every n x n matrix has a characteristic polynomial
Every polynomial has a corresponding n x n matrix for which it is the characteristic polynomial
Thus, polynomial root finding is equivalent to finding eigenvalues

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD41
Example Please!?!?!?
Consider the monic polynomial of degree nf(x) = a1 +a2x+a3x2+…+anxn-1 +xn
and the companion matrix
01000
0000
0010
0001121
aaaa nn
A

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD42
Find The Eigenvalues of the Companion Matrix
?
01000
0000
0010
0001121
aaaa nn
IAI

04/19/23DRAFT Copyright, Gene A
Tagliarini, PhD43
Find The Eigenvalues of the Companion Matrix
100
00
001)1()(
1000
000
0010
001
121
1
121
aaa
a
aaaa
n
nn
nn
AI


















