
Exploring Coverage and Distribution of Scholarly Identifiers on the Web
22
1 b b www.know-center.at Exploring Coverage and Distribution of Scholarly Identifiers on the Web 14th International Symposium of Information Science Zadar, 21 May 2015 Peter Kraker , Asura Enkhbayar & Elisabeth Lex
-
Upload
peter-kraker -
Category
Education
-
view
589 -
download
4
Transcript of Exploring Coverage and Distribution of Scholarly Identifiers on the Web

1
b
b
www.know-center.at
Exploring Coverage and Distribution of
Scholarly Identifiers on the Web14th International Symposium of Information Science
Zadar, 21 May 2015
Peter Kraker, Asura Enkhbayar & Elisabeth Lex
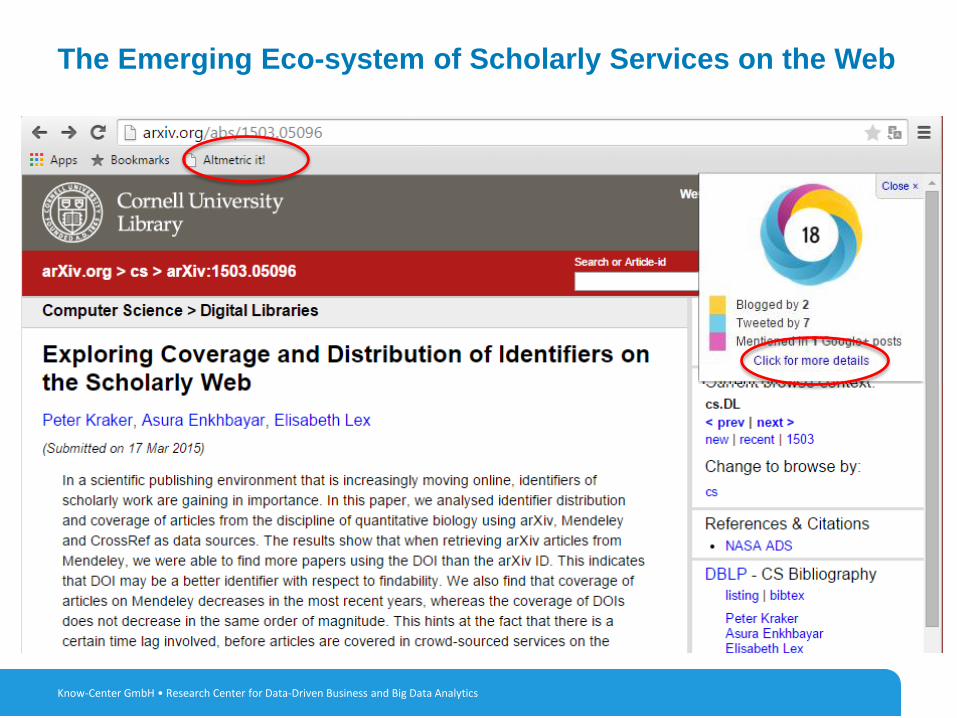
2Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
The Emerging Eco-system of Scholarly Services on the Web
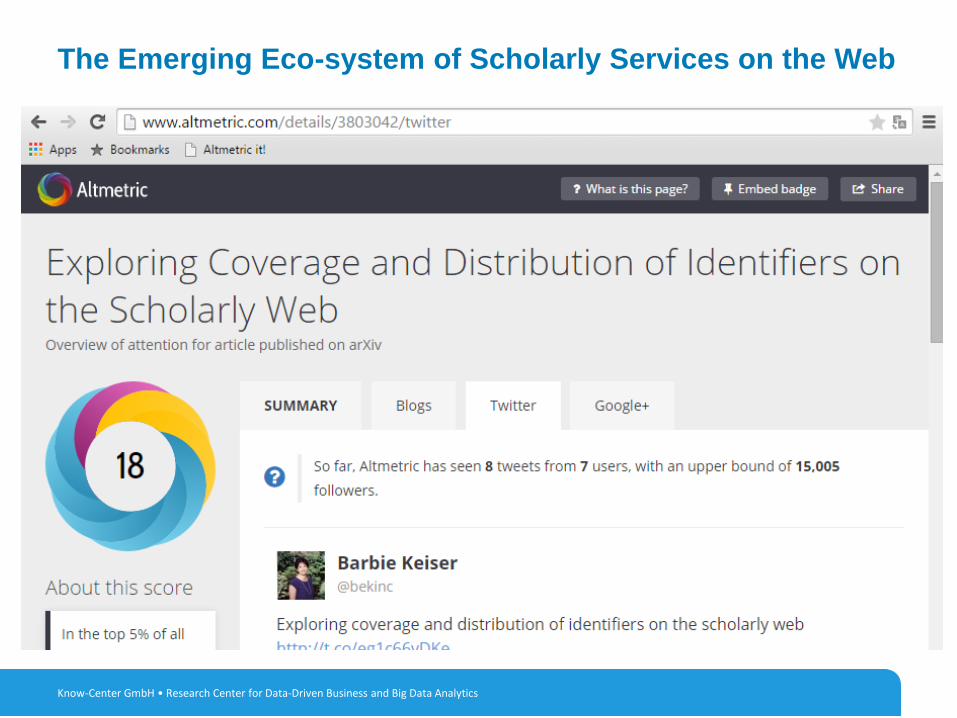
3Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
The Emerging Eco-system of Scholarly Services on the Web

4Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics

5
Research Questions
• How are scholarly identifiers distributed in crowd-
sourced systems on the Web?
• Does the provision of different identifiers have an
influence on findability of scientific publications in other
bibliographic and bibliometric sources?
• Who are the top providers of identifiers?
• Which identifier combinations are the most common?
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics

6
Indentifiers on the Scholarly Web
Article level
Publication levelAuthor level
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
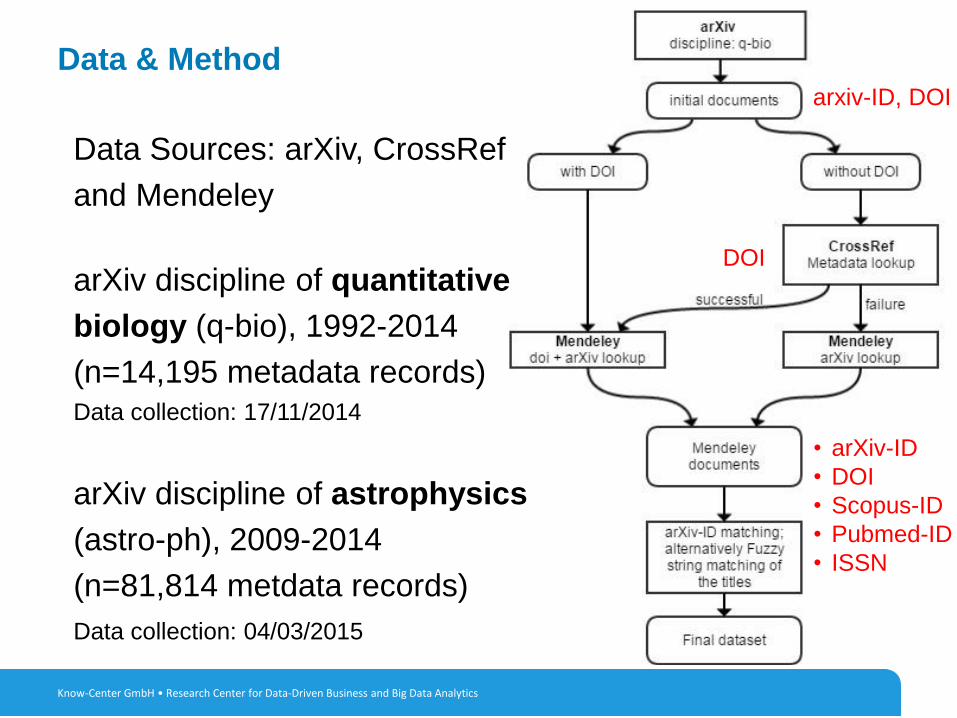
7
Data & Method
Data Sources: arXiv, CrossRef
and Mendeley
arXiv discipline of quantitative
biology (q-bio), 1992-2014
(n=14,195 metadata records)Data collection: 17/11/2014
arXiv discipline of astrophysics
(astro-ph), 2009-2014
(n=81,814 metdata records)
Data collection: 04/03/2015
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
arxiv-ID, DOI
DOI
• arXiv-ID
• DOI
• Scopus-ID
• Pubmed-ID
• ISSN
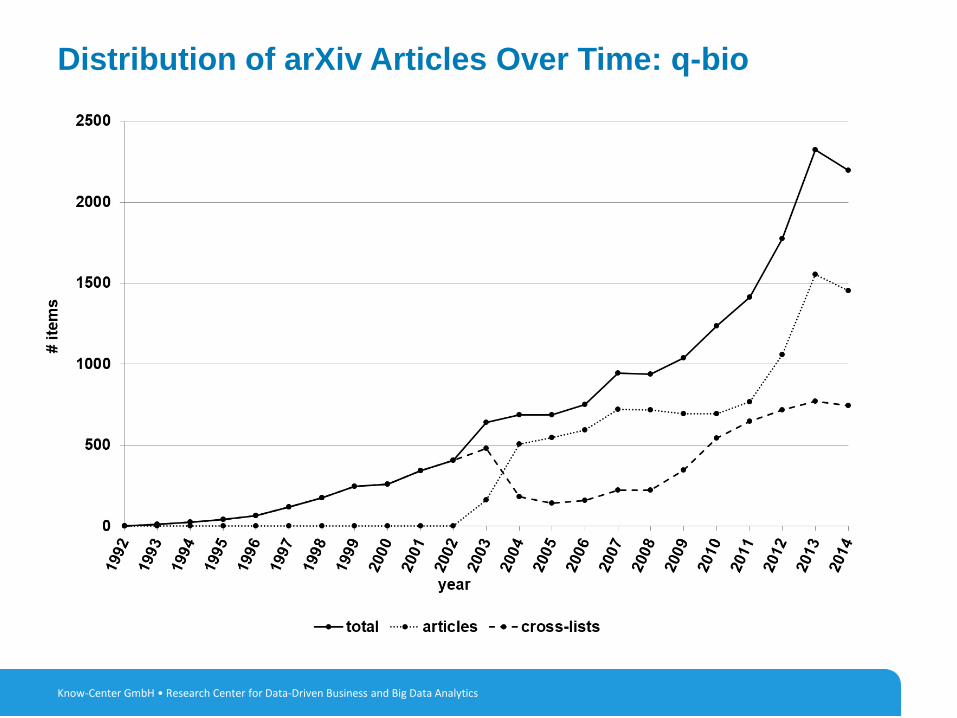
8
Distribution of arXiv Articles Over Time: q-bio
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics

9
Distribution of arXiv Articles Over Time: astro-ph
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
10
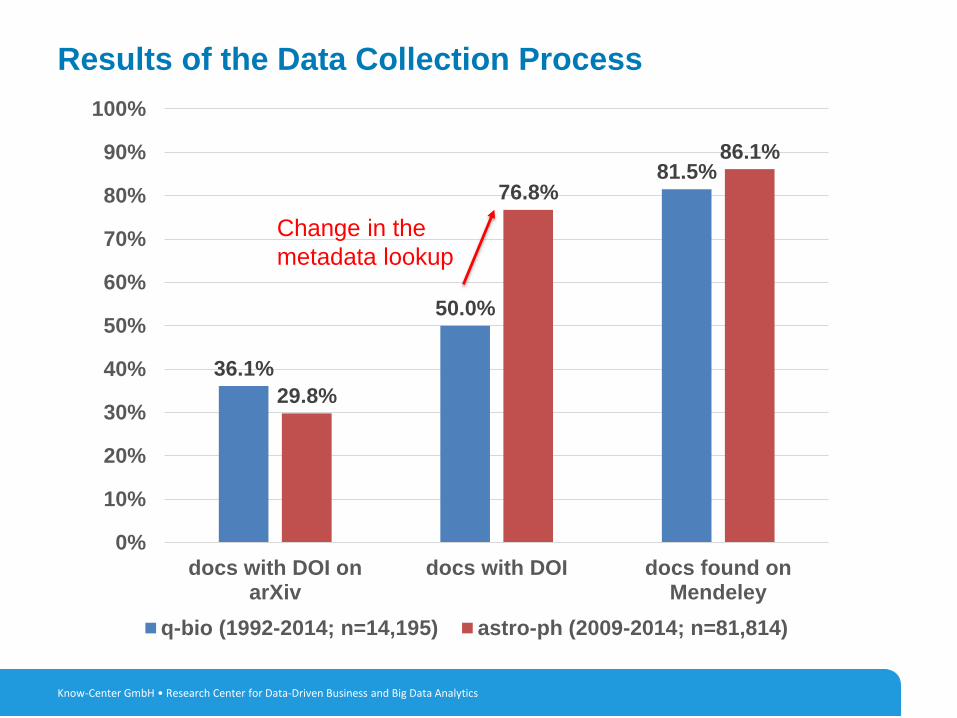
Results of the Data Collection Process
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
36.1%
50.0%
81.5%
29.8%
76.8%
86.1%
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
docs with DOI onarXiv
docs with DOI docs found onMendeley
q-bio (1992-2014; n=14,195) astro-ph (2009-2014; n=81,814)
Change in the
metadata lookup

11
Findability on Mendeley: q-bio (1992-2014)
11Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
Total documents
14,195
Documents
with DOI & arXiv-ID
7,100 (50.02%)
Documents
with arXiv-ID
7,095 (49.98%)
Documents retrieved
on Mendeley
with DOI
6,492 (91.44%)
Documents retrieved
on Mendeley
with arXiv-ID
4,896 (69.01%)
Documents retrieved
on Mendeley
with arXiv-ID
5,414 (76.25%)

12
Findability on Mendeley: astro-ph (2009-2014)
12Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
Total documents
81,814
Documents
with DOI & arXiv-ID
62,800 (76.8%)
Documents
with arXiv-ID
19,014 (23.2%)
Documents retrieved
on Mendeley
with DOI
54,093 (86.1%)
Documents retrieved
on Mendeley
with arXiv-ID
12,812 (67.4%)
Documents retrieved
on Mendeley
with arXiv-ID
45,586 (72.6%)

13
Findability on Mendeley & DOI Coverage: q-bio
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
14
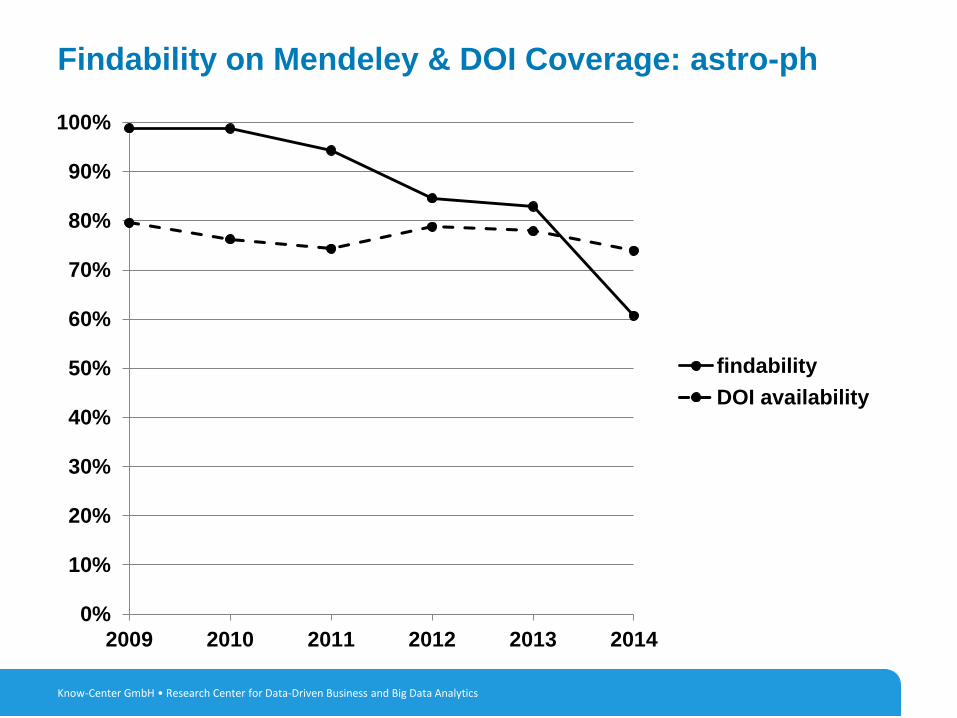
Findability on Mendeley & DOI Coverage: astro-ph
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2009 2010 2011 2012 2013 2014
findability
DOI availability
15
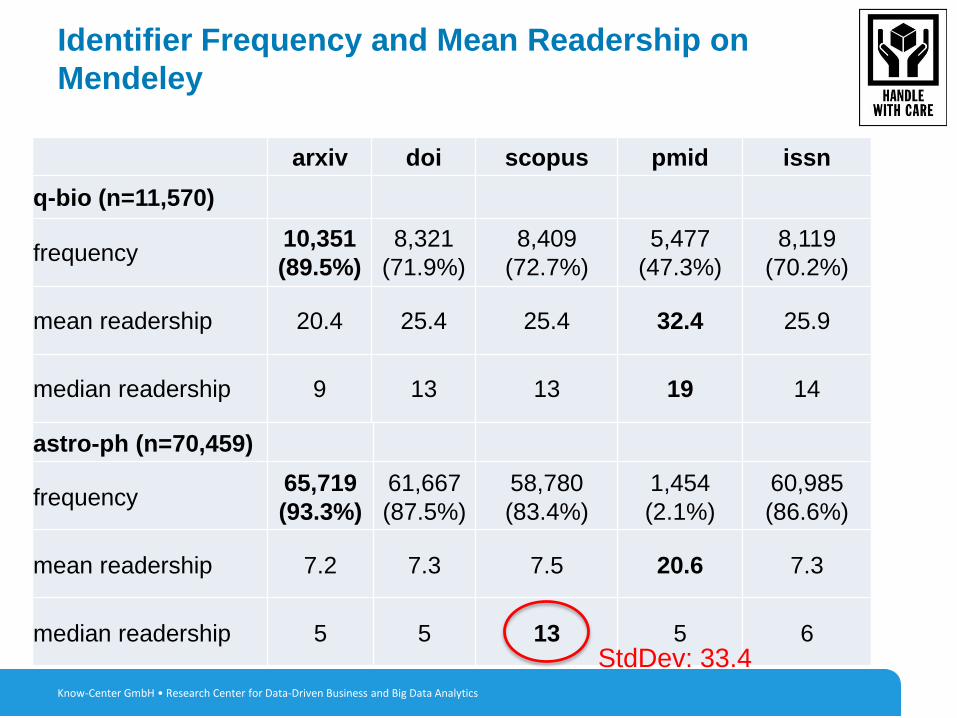
Identifier Frequency and Mean Readership on
Mendeley
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
arxiv doi scopus pmid issn
q-bio (n=11,570)
frequency10,351
(89.5%)
8,321
(71.9%)
8,409
(72.7%)
5,477
(47.3%)
8,119
(70.2%)
mean readership 20.4 25.4 25.4 32.4 25.9
median readership 9 13 13 19 14
astro-ph (n=70,459)
frequency65,719
(93.3%)
61,667
(87.5%)
58,780
(83.4%)
1,454
(2.1%)
60,985
(86.6%)
mean readership 7.2 7.3 7.5 20.6 7.3
median readership 5 5 13 5 6StdDev: 33.4
16Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
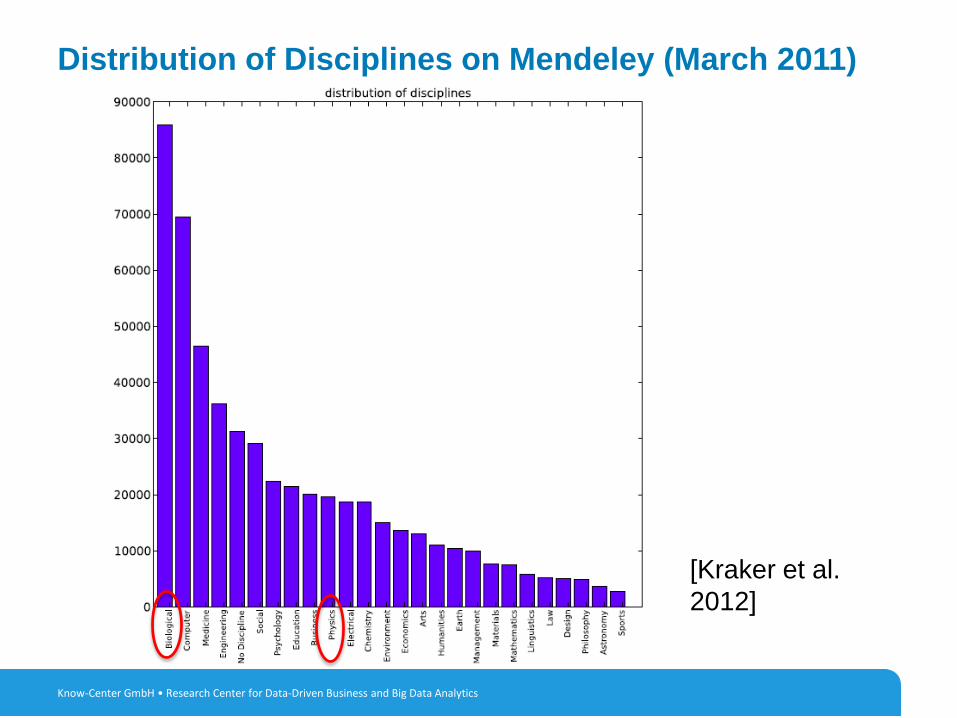
Distribution of Disciplines on Mendeley (March 2011)
[Kraker et al.
2012]
17
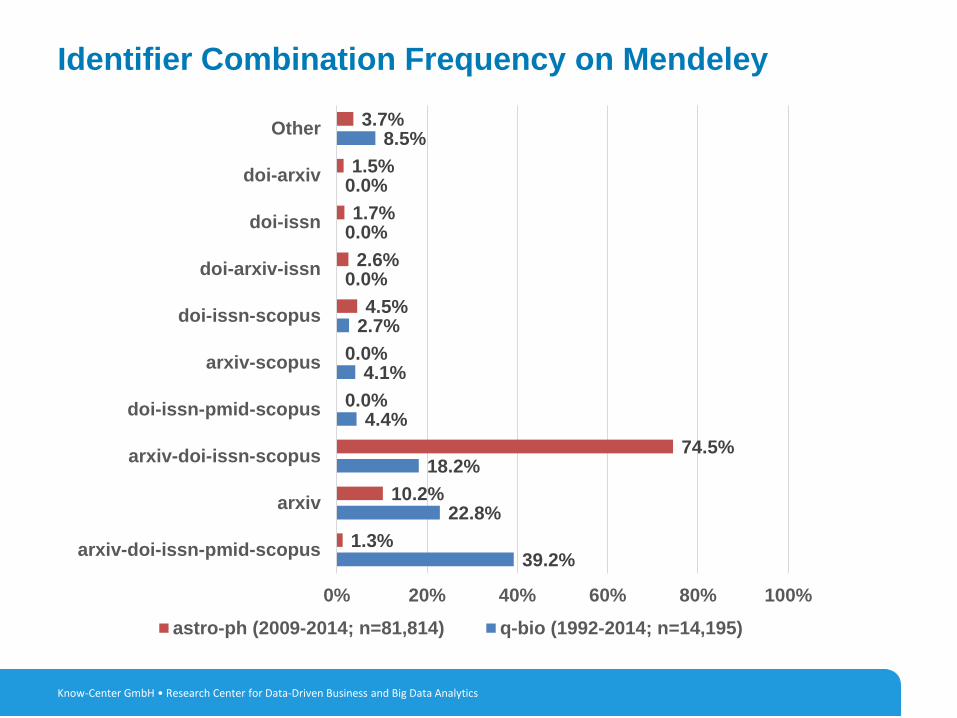
Identifier Combination Frequency on Mendeley
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
39.2%
22.8%
18.2%
4.4%
4.1%
2.7%
0.0%
0.0%
0.0%
8.5%
1.3%
10.2%
74.5%
0.0%
0.0%
4.5%
2.6%
1.7%
1.5%
3.7%
0% 20% 40% 60% 80% 100%
arxiv-doi-issn-pmid-scopus
arxiv
arxiv-doi-issn-scopus
doi-issn-pmid-scopus
arxiv-scopus
doi-issn-scopus
doi-arxiv-issn
doi-issn
doi-arxiv
Other
astro-ph (2009-2014; n=81,814) q-bio (1992-2014; n=14,195)

18
Conclusions
• As expected, crowd-sourced systems show big differences
in identifier coverage and distribution crowd-sourced
data needs to be amended automatically
• When retrieving arXiv articles from Mendeley, we were able
to obtain more articles using the DOI than the arXiv-ID
• BUT: a single arXiv-ID is the second most popular identifier
combination on Mendeley. This suggests that pre-prints are
being read – if at a lower level
• There is, however, a certain time lag concerning the
adoption of articles from arXiv on Mendeley
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics

19
Conclusions
• The distribution of identifiers in a collection of papers
gives hints at the nature of papers in this collection
• As with citations, field normalization will be essential for
cross-comparison of altmetrics scores
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics

20
Limitations & Future Work
• Choice of arXiv as primary data source introduces a bias
• We only looked at two disciplines from natural sciences
• Using a random sample of 381 articles from Web of Science,
Zahedi et al. (2014) report that they were able to retrieve only
47.7% of articles on Mendeley using the DOI or the title.
Expand this study to further disciplines and fields using
more data sources
Look more deeply into the reasons for disciplinary and
tool-related differences
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
21
Open Source Crawling Framework
Know-Center GmbH • Research Center for Data-Driven Business and Big Data Analytics
https://github.com/Bubblbu/crawling-framework

22
b
SAVE THE DATE: i-KNOW Conference
Special Track on Science 2.0 & Open Science
21-23 October 2015, Graz, Austria
Submission Deadline (extended): 22 June 2015 (Abstracts due: June 8)


















