
Expert Systems with Applications - Open Repository of...
16
kNN processing with co-space distance in SoLoMo systems Xianke Zhou, Sai Wu ⇑ , Gang Chen, Lidan Shou College of Computer Science, Zhejiang University, Hangzhou 310027, PR China article info Article history: Available online 12 June 2014 Keywords: kNN SoLoMo SVM Crowdsourcing Location-based search abstract With the increasing popularity of smart phones, SoLoMo (Social-Location-Mobile) systems are expected to be fast-growing and become a popular mobile social networking platform. A main challenge in such systems is on the creation of stable links between users. For each online user, the current SoLoMo system continuously returns his/her kNN (k Nearest Neighbor) users based on their geo-locations. Such a recom- mendation approach is simple, but fails to create sustainable friendships. Instead, it would be more effec- tive to tap onto the existing social relationships in conventional social networks, such as Facebook and Twitter, to provide a ‘‘better’’ friend recommendations. To measure the similarity between users, we propose a new metric, co-space distance, by considering both the user distances in the real world (physical distance) and the virtual world (social distance). The co-space distance measures the similarity of two users in the SoLoMo system. We compute the social distances between users based on their public information in the conventional social networks, which can be achieved by a few MapReduce jobs. To facilitate efficient computation of the social distance, we build a distributed index on top of the key-value store, and maintain the users’ geo-locations using an R-tree. For each query on finding potential friends around a location, we return kNN neighbors to each user based on their co-space distances. We propose a progressive top-k processing strategy and an adap- tive-caching strategy to facilitate efficient query processing. Experiments with Gowalla dataset 1 show the effectiveness and efficiency of our recommendation approach. Ó 2014 Elsevier Ltd. All rights reserved. 1. Introduction In conventional online social networks, users set up a new friendship with the others, when either they know each other per- sonally or they are recommended/connected by some common friends. However, mobile users are also keen to have a real-time view of all nearby users and extend social networks to include potential friends who are geographically close to them. They can translate the on-the-fly relationship to a more stable one by adding other users as their permanent friends. Example SoLoMo systems include Color, 2 Sonar, 3 Path 4 , MoMo 5 , WeChat 6 and Near. 7 Fig. 1 shows the iPhone application of Sonar, in which the system returns a set of nearby checked in users after the user checks into the system. SoLoMo systems extend the social networking systems to improve the user experience by allowing mobiles users to discover and interact with other users who are within their vicinity. In most SoLoMo systems, the location-based relationship is considered as the weak connection between people, while the social-based rela- tionship is assumed to be a strong connection. SoLoMo systems assume that people can transfer the weak connections to strong connections via their services. However, since people are typically reluctant to accept the invitations from strangers, most users in SoLoMo systems fail to fulfil such transformation. To address the above problem, Sonar shows the number of shared friends in other social networks between its users. The intu- ition is that as 99.4% 8 of location-based service users also use social networks such as Facebook, MySpace, and Twitter, we can link their SoLoMo accounts with their accounts in these conventional online social networks. Suppose a user, Alice, refreshes her location in the SoLoMo system and finds a group of nearby users. By linking with http://dx.doi.org/10.1016/j.eswa.2014.06.008 0957-4174/Ó 2014 Elsevier Ltd. All rights reserved. ⇑ Corresponding author. E-mail addresses: [email protected] (X. Zhou), [email protected] (S. Wu), [email protected] (G. Chen), [email protected] (L. Shou). 1 http://gowalla.com/. 2 http://www.color.com/. 3 http://www.sonar.me/. 4 https://path.com/. 5 https://itunes.apple.com/cn/app/momo-discover-meet-friend/ id571534636?mt=8. 6 http://www.wechat.com/en/. 7 http://us.playstation.com/psvita/apps/psvita-app-near.html. 8 http://www.marketingprofs.com/charts/2011/4940/can-geolocation-apps-win- over-smartphone-users. Expert Systems with Applications 41 (2014) 6967–6982 Contents lists available at ScienceDirect Expert Systems with Applications journal homepage: www.elsevier.com/locate/eswa
Transcript of Expert Systems with Applications - Open Repository of...

Expert Systems with Applications 41 (2014) 6967–6982
Contents lists available at ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
kNN processing with co-space distance in SoLoMo systems
http://dx.doi.org/10.1016/j.eswa.2014.06.0080957-4174/� 2014 Elsevier Ltd. All rights reserved.
⇑ Corresponding author.E-mail addresses: [email protected] (X. Zhou), [email protected] (S. Wu),
[email protected] (G. Chen), [email protected] (L. Shou).1 http://gowalla.com/.2 http://www.color.com/.3 http://www.sonar.me/.4 https://path.com/.5 h t t p s : / / i t u n e s . a p p l e . c o m / c n / a p p / m o m o - d i s c o v e r - m e e t - f r i e n d /
id571534636?mt=8.6 http://www.wechat.com/en/.7 http://us.playstation.com/psvita/apps/psvita-app-near.html.
8 http://www.marketingprofs.com/charts/2011/4940/can-geolocation-aover-smartphone-users.
Xianke Zhou, Sai Wu ⇑, Gang Chen, Lidan ShouCollege of Computer Science, Zhejiang University, Hangzhou 310027, PR China
a r t i c l e i n f o a b s t r a c t
Article history:Available online 12 June 2014
Keywords:kNNSoLoMoSVMCrowdsourcingLocation-based search
With the increasing popularity of smart phones, SoLoMo (Social-Location-Mobile) systems are expectedto be fast-growing and become a popular mobile social networking platform. A main challenge in suchsystems is on the creation of stable links between users. For each online user, the current SoLoMo systemcontinuously returns his/her kNN (k Nearest Neighbor) users based on their geo-locations. Such a recom-mendation approach is simple, but fails to create sustainable friendships. Instead, it would be more effec-tive to tap onto the existing social relationships in conventional social networks, such as Facebook andTwitter, to provide a ‘‘better’’ friend recommendations.
To measure the similarity between users, we propose a new metric, co-space distance, by consideringboth the user distances in the real world (physical distance) and the virtual world (social distance).The co-space distance measures the similarity of two users in the SoLoMo system. We compute the socialdistances between users based on their public information in the conventional social networks, whichcan be achieved by a few MapReduce jobs. To facilitate efficient computation of the social distance, webuild a distributed index on top of the key-value store, and maintain the users’ geo-locations using anR-tree. For each query on finding potential friends around a location, we return kNN neighbors to eachuser based on their co-space distances. We propose a progressive top-k processing strategy and an adap-tive-caching strategy to facilitate efficient query processing. Experiments with Gowalla dataset1 show theeffectiveness and efficiency of our recommendation approach.
� 2014 Elsevier Ltd. All rights reserved.
1. Introduction
In conventional online social networks, users set up a newfriendship with the others, when either they know each other per-sonally or they are recommended/connected by some commonfriends. However, mobile users are also keen to have a real-timeview of all nearby users and extend social networks to includepotential friends who are geographically close to them. They cantranslate the on-the-fly relationship to a more stable one by addingother users as their permanent friends. Example SoLoMo systemsinclude Color,2 Sonar,3 Path4, MoMo5, WeChat6 and Near.7 Fig. 1shows the iPhone application of Sonar, in which the system returns
a set of nearby checked in users after the user checks into thesystem.
SoLoMo systems extend the social networking systems toimprove the user experience by allowing mobiles users to discoverand interact with other users who are within their vicinity. In mostSoLoMo systems, the location-based relationship is considered asthe weak connection between people, while the social-based rela-tionship is assumed to be a strong connection. SoLoMo systemsassume that people can transfer the weak connections to strongconnections via their services. However, since people are typicallyreluctant to accept the invitations from strangers, most users inSoLoMo systems fail to fulfil such transformation.
To address the above problem, Sonar shows the number ofshared friends in other social networks between its users. The intu-ition is that as 99.4%8 of location-based service users also use socialnetworks such as Facebook, MySpace, and Twitter, we can link theirSoLoMo accounts with their accounts in these conventional onlinesocial networks. Suppose a user, Alice, refreshes her location in theSoLoMo system and finds a group of nearby users. By linking with
pps-win-

Fig. 1. Mobile apps of sonar.
10 Gowalla is a location-based social network, where users are able to check in at‘‘Spots’’ in their local vicinity. It has more than 6 millions users and was acquired by
6968 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
other social accounts, the SoLoMo system suggests Bob and Tom aspotential new friends to Alice, since Bob is a friend of Alice’s sisterin Facebook and Tom follows Alice in Twitter. In this way, Alicecan set up new connections with her nearby friends more easily.
As a matter of fact, the number of shared friends can be consid-ered a type of social distance between users. In this paper, to pre-cisely model the social distance, we take into account the friendlinks, interests, personal profiles and other public information inthe social network. We define a new similarity metric betweenusers, the co-space distance, by combining both the physical dis-tance and social distance into a co-space distance. In SoLoMo sys-tems, when a user checks in, we measure his/her co-spacedistances to the other checked in users and provide him/her thek nearest neighbors as suggested friends.
The challenge of introducing such a hybrid distance is twofold.First, computing social distance incurs high overhead. In a typicalsocial network, such as Facebook, there are more than a few hun-dred millions of active users. Computing the social distancebetween all pairs of users is costly, even in an offline manner. Inthis paper, we propose an efficient social distance computationalgorithm based on the parallel processing framework of MapRe-duce. The results of the MapReduce jobs are indices for the socialdistances between users (social index), which are inserted into akey-value store, such as Hbase.9 To reduce the index lookup over-head, top social distances are kept in the adaptive cache.
Second, if user u0 issues a kNN (k Nearest Neighbor) query, thequery engine needs to look up two indices, the location index (e.g.,the R-tree index) and the social index. Because the users updatetheir geo-locations continuously, we have to dynamically computethe co-space distances between u0 and other users at query time.One problem of the social index is its high I/O access costs, because
9 http://hbase.apache.org/.
key-value store only supports random accesses. To reduce the I/Ocost, we should avoid the computation of co-space distances asmuch as possible. In the ideal case, the nearby users are also theusers with the least social distances to u0. The query engine canretrieve the users via the location index and generate kNN resultsefficiently. Otherwise, the query engine needs to enlarge its searchrange iteratively to include more nearby users. We adopt two tech-niques, a progressive query processing approach and an adaptivecaching approach, to optimize our kNN algorithm.
� The progressive query processing approach maintains an esti-mated upper bound of the similarity for the unseen users. Itupdates the upper bound as more users are checked. If theupper bound is less than the current kth similarity, we can stopthe processing without missing any correct result.� To reduce the cost of retrieving social distances from the key-
value store on the fly, we buffer the top values for users in amemory cache. Given limited size of memory, the caching strat-egy estimates an optimal buffer size for each user. When thememory is full, the cache is updated based on the querydistribution.
We evaluate our approach using a Gowalla’s dataset.10 Theexperiments show that our approach can provide a better recom-mendation with less cost, which can facilitate the creation of newfriend links in the SoLoMo systems.
The remainder of the paper is organized as follows. In Section 2,we review the related work on SoLoMo system and top-k queryprocessing. In Section 3, we give an overview of our approachand formalize the problem. Next, we define the co-space distanceand explain how to efficient compute the distance in Section 4.The query processing algorithm is introduced in Section 5 andwe evaluate our approach in Section 6. The paper is concluded inSection 7.
2. Related work
2.1. SoLoMo system
How to incorporate location information into the social networkto improve the user’s experience has been studied for years(Melinger, Bonna, Sharon, & SantRam, 2004; Tsai, Han, Xu, &Chua, 2009). However, the full-fledged SoLoMo system onlyappears recently, when the smart phones dominate the market.Most SoLoMo systems come as an application for the android oriOS system. Popular SoLoMo Apps include WeChat11 and Path12,which have more than millions of online users.
The new SoLoMo system also attracts the interest from the var-ious research communities. Chang et al. proposed a general frame-work for such applications (Chang, Liu, Chou, Chen, & Shin, 2006),while Pietilainen designed a middleware for the existing social net-works to support the mobile features (Pietilainen, Oliver, LeBrun,Varghese, & Diot, 2009). In Dong, Song, Xie, and Wang (2009),experiments are conducted on the real data to study the character-istics of SoLoMo systems. The main difference between SoLoMosystem and the conventional social networks is the usage of GPSlocation data. Instead of providing a stable friend relationships,SoLoMo prefers the ad hoc network based on the users’ locations.WeChat and Path provide the user a view of nearby people, sortedby their geo-distances to the user. These applications try to help
Facebook recently.11 http://www.wechat.com/en/.12 http://path.com.

X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982 6969
the user make new friends with the nearby strangers. This is a typeof friend recommendation.
In fact, friend recommendation is an old topic and has been stud-ied since the emergence of social networks. The techniques of friendrecommendations can be classified as link-based approach and con-tent-based approach. Getoor and Diehl (2005) surveyed the effortsof applying the data mining approach for the friend link prediction.In Popescul and Ungar (2003), a structured logistic regressionmodel was proposed to predict the existence of a graph link. InO’Madadhain, Hutchins, and Smyth (2005), based on the graph’sstructure and node’s attributes, the authors constructed a probabil-ity model for the link prediction. The users can be also grouped intocommunities based on their social graphs (Romdhane, Chaabani, &Zardi, 2013). However, as pointed by many researchers (Rattigan &Jensen, 2005; O’Madadhain et al., 2005), link prediction is very chal-lenging. The probabilistic model lacks enough training samples andthe prior probability of an edge is normally very small, whichresults in low recall and precision in the friend recommendation.Different from the link-based approach, the content-basedapproach analyze the users’ interests and their published contents.MySpace (Moricz, Dosbayev, & Berlyant, 2010) sampled the nearbyusers and recommended the users with the same school/companyas the potential friends. WMR (Lo & Lin, 2006) modeled the users’relationship using their message interaction and designed a newrecommendation algorithm named weighted minimum-messageratio. The user uploaded photos were also considered as the recom-mendation clue in Wu, Jiang, and Huang (2009); Kim, Saddik, andJung (2012). The mutual resource fusion scheme is proposed inChen, Zeng, and Yuan (2013) for item and friend recommendations,while in Liu and Lee (2010), the social network information is usedto enhance collaborative filtering performance used by many con-ventional recommendation algorithms.
As mentioned before, SoLoMo system adopts a different friendrecommendation technique based on the GPS data of users’ mobilephones. For example, Zheng, Zhang, Ma, Xie, and Ma (2011) pro-posed a friend recommendation approach based on the users’ his-torical locations and they extended the approach to consider theusers’ preferences as well (Bao, Zheng, & Mokbel, 2012). Ye, Yin,and Lee (2010) developed a friend-based collaborative filtering(FCF) approach for location recommendation based on collabora-tive ratings of places. In GeoLife (Zheng, Chen, Xie, & Ma, 2009),the users’ trajectories are collected and the similarities of usersare computed via their trajectory distances. Note that our approachis orthogonal to the previous work. None of above schemes com-bine the social distance and physical distance together as a newdistance metric for users. Our experiment results show an promis-ing result for the new distance-based recommendation.
Fig. 2. Illustration of friendships in co-space.
2.2. Top-k query processing
Top-k query return the most interest results to the users. It hasbeen implemented in many systems to support different applica-tions. Ilyas, Beskales, and Soliman (2008) provided a good surveyon how to implement the top-k operator in the relational databasesystems. Among all the existing top-k algorithms, FA (Fagin, 1999)and TA (Fagin, Lotem, & Naor, 2001) are the most popular ones.TA’s stopping mechanism enables it to stop scanning the lists muchearly than the FA. The performance of TA is analyzed in Fagin,Lotem, and Naor (2003). To speed up the query processing andreduce the I/O cost, many variants of TA algorithm have been pro-posed, such as Bast, Majumdar, Schenkel, Theobald, and Weikum(2006); Chang and Hwang (2002) and Das, Gunopulos, andKoudas (2006). Moreover, the corresponding approaches are alsoextended to the distributed systems (Cao & Wang, 2004; Michel& Triantafillou, 2005) and P2P systems (Akbarinia, Pacitti, &
Valduriez, 2007; Balke, Nejdl, Siberski, & Thaden, 2005; Kim, Kim,& Cho, 2008).
The conventional top-k approaches cannot be directly appliedto our system, as (1) the geo-locations of users are changed overtime and we need to compute the co-space distance between userson the fly; and (2) we cannot generate and maintain a sorted listfor each user based on the co-space distance due to the high pro-cessing cost. Therefore, in this paper, we design a new variant ofTA approach, which exploits the R-tree index and adaptive cacheto facilitate the top-k processing. Although grid index (Park,2014) can also support efficient location-based search, we chooseR-tree index as given a query point, it can progressively returnthe k nearest neighbors and its performance is less affected bythe skewed data distribution.
3. Problem overview
The intuition of merging the other social relationships into theSoLoMo system is to increase the possibility of discovering newfriends. Fig. 2 illustrates the idea. Suppose the mobile applicationcan only display two nearby users in the small screen of a handset.When user A checks in, the SoLoMo system provides him the first 2nearest neighbors. For example, user C and D will be returned asanswers if we only consider the locations of users for friend recom-mendation. However, such recommendation may not be very use-ful, since user B and E have more common friends to user A, whoare potential friends of A with high probability. Therefore, insteadof recommending friends via the geo-locations, in this paper, wemeasure the users’ similarities by both the physical distance andthe social distance. Specifically, we define the metadata of usersin the SoLoMo systems as below:
Definition 1 (Metadata of users in SoLoMo systems). The meta-data of a user u in the SoLoMo system are represented ashðuÞ ¼ ðx; y; S0; S1; . . . ; SnÞ, where x and y represent the geo-locationof u and Si is the other social networks that u has participated in.
The metadata consists of two parts:
1. The geo-locations are updated in real-time when the userscheck in. Most users access the SoLoMo service via their mobilephones. To increase the battery life, the SoLoMo application

6970 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
only reports the users’ locations, when they check in. A tablehas to be maintained for recording the user’s last reported loca-tion. We build an R-tree index for the table to speed up the spa-tial range query processing.
2. The social information is precomputed and maintained in thekey-value store. We update the social data periodically in anoffline manner.
To measure the similarity between users, we define the co-spacedistance based on users’ metadata.
Definition 2 (Co-space distance in SoLoMo systems). For twousers u0 and u1, their co-space distance is determined by twofunctions, f and g:
Fig. 3. Work flow of friend recommendation.
13 AMT (http://aws.amazon.com/mturk/) is a crowdsourcing platform which has apool of human workers waiting to answer the customized questions published byusers. AMT can be used to get highly accurate results for complex jobs, such as imagetagging and classification.
f ðeðu0;u1Þ; minni¼0ðgðu0:Si;u1:SiÞÞÞ
eðu0; u1Þ returns the physical distance between the two users, whilefunction g describes how to compute the social distance. Function fis used to merge the physical distance and social distance (namely,our co-space function).
The similarity of two users, u0 and u1, is inversely proportionalto their co-space distance. When computing the social distances,we should consider all possible social networks. If only u0 joins asocial network Si, the social distance between u0 and u1 in Si isþ1. When u0 and u1 join more than one social networks, we usetheir minimal social distance in all networks. The intuition is tomaximize the impact of social relationship. For example, even ifLady Gaga is not my Facebook friend, the fact that I follow her inTwitter indicates that I would like to know her events and activi-ties. We do not use average social distances as:
1. Two users may join different sets of social networks. It is diffi-cult to define a correct average social distance between them.
2. Different social networks measure different relationships. E.g.,Facebook links friends and families, while LinkedIn connectsprofessional people. We cannot simply merge the social dis-tances to produce an average value.
3. As mentioned in our example, if two people in one social net-work are connected, they are close enough. Therefore, we canuse the minimal distance as our recommendation metric.
Using minimal distance can also reduce the complexity of com-puting the social distance when users join multiple social net-works. As shown in Section 4.2.2, we compute the distancebetween any two users for all joined social networks in the prepro-cessing and select the minimal value as their social distance, whichare maintained in a distributed key-value system. Therefore, thecomputation process of social distance is not affected by the num-ber of involved social networks. Moreover, in our Android applica-tion, users are also allowed to join multiple social networks and weupdate their social distance as the minimal distance among alljoined networks. In the following discussion, to simplify the nota-tions, we only use the relationships in Facebook as our social graphto demonstrate our main idea.
In our design, function f and g can be configured arbitrarily basedon the users’ application. Currently, f is defined as a linear functionand g is designed to measure the common community of users. Theco-space distance between u0 and u1 is represented as:
f ðu0;u1Þ ¼ b0gðu0;u1Þ þ b1eðu0;u1Þ þ b2
where b0;b1 and b2 denote the tunable parameters and eðu0;u1Þreturns the Euclidean distance between u0 and u1. Function f com-bines the social distance and physical distance. The tunableparameter values are trained by SVM (Support Vector Model)algorithm (Chang & Lin, 2011). SVM is a classic supervised learning
model and normally used for classification and regression analysis.SVM can provide high accuracies for many real applications. Wesubmit classification jobs to AMT (Amazon Mechanical Turk) plat-form13, and collect the results as the training dataset. The detailsfor the tuning of f is deferred to Section 4.
Given the definition of co-space distance, we can now formalizethe query in the SoLoMo system.
Definition 3 (Query model in SoLoMo systems). The query issuedby user u0 will retrieve k users in the system, who have thesmallest co-space distances to u0. k is a tunable parameter, basedon the mobile phone’s screen size.
When a user checks in, we submit a kNN query to the SoLoMosystem and the results are returned to the user. Fig. 3 shows theoverview of the query processing system. The user’s geo-locationsare indexed by the R-tree index and updated as the user performs anew check-in operation. The social graph of users is transformedinto the social distances via the MapReduce jobs and indexed inthe key-value store. To merge the two types of distances into theco-space distance, we train a SVM model by publishing the classi-fication question to the AMT (Amazon Mechanical Turk). Theanswers are used as our training set and we then generate a modelto compute the co-space distance from the social distance andphysical distance. Finally, given a query from the mobile applica-tion, the query engine exploits the R-tree index and social indexto retrieve the distances between users. The engine will rank theusers by their co-space distances and generate the top-K users asthe query result.
Algorithm 1 summarizes the key steps of query processing. Ini-tially, we estimate a range r0 and use the R-tree index to retrieve allnearby users (line 4). For each user, we compute his/her co-spacedistance to the query initiator u0 (line 5–9). The users are sortedbased on their co-space distances and k-nearest neighbors are gen-erated. The similarity between current kth user and u0 (d) is used toestimate the upper bound of the similarities of the unseen users

X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982 6971
(line 12). If the similarities between u0 and the unseen users cannotbe greater than d, we return current kNN results (line 13–15).Otherwise, we increase the search region to include more nearbyusers and repeat the same procedure (line 17).
Algorithm 1. QueryProcessing (User u0)
1: r0 = initRange ()2: double r ¼ r0, boolean stop = false3: while not stop do4: UserSet U = lookupRTree (u0:x; u0:y; r)5: for i = 0 to U.size do6: u1=U.get (i)7: double distsocial = getSocialDistance (u0;u1)8: double distphysical=getEuclideanDistance (u0;u1)9: double distcospace½u1� = f ðdistsocial; distphysicalÞ
10: sort users in U by their co-space distances11: double d = getKthNeighborSimilarity ()12: double threshold = estimateUpperBoundOfUnseenUser (d)13: if d P threshold then14: result = current kNN15: stop = true16: else17: r ¼ r þ r0
18: return result
Clearly, we need to address the following questions in order todesign an efficient query processing strategy in the SoLoMo system.
1. How to estimate the upper bound of unseen users and stop thekNN query processing as early as possible?
2. Given two random users in the social network, such as Face-book, how should we estimate and index their social distance(namely how function g works in Definition 2)?
3. What is an effective way to merge the social distance andphysical distance (a precise description of function f inDefinition 2)?
In the remaining sections, we shall present our solutions for theabove problems and conduct extensive experimental studies.
14 http://techcrunch.com/2011/11/22/facebookdata/.
4. Co-space distance
The computation of co-space distance is based on three sub-functions, namely, e; g and f. In this section, we shall define thesefunctions and discuss them in detail.
4.1. Physical distance
Physical distances between users are calculated based on theirreal-time locations. For two users u0 and u1, their physical distanceis denoted as eðu0;u1Þ. When the information of road network is notunknown, we adopt the Euclidean distance. An R-Tree index is builtto maintain users’ locations and support the kNN query processing.
If the road network information is available, we can estimate amore precise distance between users. The issue has been well stud-ied in previous work (Cao & Krumm, 2009; Machuca & Mandow,2012; Zhong, Li, Tan, & Zhou, 2013). For a road network shownin Fig. 4, we build a R-tree like index, G-tree (Zhong et al., 2013).Similar to the R-tree, G-tree partitions the space into sub-spaces.In Fig. 4, node G0 represents the whole space, while its two childnodes G1 and G2 partition the space into two sub-spaces. G1 andG2 maintain the road network vertices that have edges to the othersub-spaces. For example, G1 stores vertex v4;v6 and v11 as the
border vertices. The partitioning strategy is applied recursively,until we get small enough sub-spaces for efficient search. Thesearch process of G-tree is exactly same as the R-tree. Given aquery location and a set of candidate objects in a road network,G-tree provides a kNN search interface which returns the k nearestobjects to the query point based on the road network distance. Wediscard the details of G-tree search for space limitation. Interestingusers can refer to the original paper (Zhong et al., 2013).
As G-tree and R-tree share the similar search algorithm, in thefollowing discussion, we will use R-tree as an example to illustrateour main idea.
4.2. Social distance
Social distances between users can be estimated based on thestructure of the social graph. Fig. 5 shows an example, where eachvertex represents a user and the friends are linked by an edge. UserB, C, E and F are friends of user A. They should have the shortestsocial distance to A. On the other hand, both user D and G are A’s2-hop friends (the users which can be reached from A by followingat least two friend links). But D is closer to A than G, because Dshares two common friends with A.
4.2.1. k-Hop user vectorThe k-hop user vector of user ui denotes the users which can be
reached within k friend links from ui. To formalize the friend linkrelationship, we firstly define the user vector, which is exactlythe 1-hop user vector.
Definition 4 (User vector). The user vector of ui in a socialnetwork is represented as:
v1i ¼ ðhðu0;uiÞ; hðu1;uiÞ; . . . ; hðun;uiÞÞ
where hðuj;uiÞ returns 1 or 0, depending on whether uj and ui arefriends or not.
The user vector records the friend links. It is used in ourcomputation of social distance. The number of shared friendsbetween user ui and uj can be easily computed as jv1
i ^ v1j j, where
^ denotes the bit-wise AND and jv1i j returns the number of 1s in the
vector.Similarly, we can represent all 2-hop friends of ui as:
v2i ¼ v1
i ½0�v10 _ v1
i ½1�v11 _ . . . _ v1
i ½n�v1n
where _ is the bit-wise OR. Generally, we have the k-hop uservector as:
Definition 5 (k-Hop user vector). The k-hop user vector of ui iscomputed based on the k� 1-hop user vector:
vki ¼ vk�1
i ½0�v10 _ vk�1
i ½1�v11 _ . . . _ vk�1
i ½n�v1n
The social distance between ui and uj (namely gðui;ujÞ) is com-puted as:
gðui;ujÞ ¼1
w0v1i ½ j� þ
PLx¼1wx j vx
i ^ v j jð1Þ
where wx is the weight parameter and L denotes the maximal num-ber of hops between users. If both ui and uj are friends of all otherusers, their social distance converges to 0. In Facebook, the averagehops between users is about 4.74.14 Therefore, in our calculation, welimit L to 3 to reduce the computation cost. If two users are linked by

Fig. 4. A road network example.
Fig. 5. Social graph.
6972 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
at least Lþ 1 hops, we consider their social distance to be þ1. Theweight in Eq. (1) is defined as an aging factor (Zhang, Izmailov,Reininger, Ott, & Nec, 1999) for the impact of friends. We setwxþ1 ¼ wx
L and w0 ¼ 1 respectively. The social distance is symmetric,as shown in the following Theorem.
Theorem 1. Based on the definition of k-hop user vector, the socialdistance is symmetric, namely gðui;ujÞ ¼ gðuj;uiÞ.
Proof. vki ½j� ¼ 1 indicates that uj is ui’s k-hop friend. Therefore,
based on the definition, we have vkj ½i� ¼ 1. Eq. (1) will return same
result for gðui;ujÞ and gðuj;uiÞ. h
Besides the social graph, we also consider the user’s profile. Forexample, in Facebook, users can write a short introduction forthemselves and create a short CV for their working and educationexperience. Such information are handled by the bag-of-words(Sivic, 2009) model. Specifically, we transform the user’s profileinto a set of keywords pðuiÞ ¼ ðt0; t1; . . . ; tkÞ. We modify our defini-tion of gðui;ujÞ to include the profiles.
gðui;ujÞ ¼1
w0ðv1i ½j� þ cosineðpðuiÞ; pðujÞÞÞ þ
PLx¼1wxjvx
i ^ v jjð2Þ
cosine returns the cosine distance between two profile vectors
4.2.2. Computation of social distance
Algorithm 2. Map (Object key, BinaryWritable value,Context context)
1: UserID i = parseID (key)2: vk
i =parseVector (value)
3: if vki is a 1-hop vector then
4: emitNewKeyValue (i;vki )
5: else6: for j = 0 to n do7: if vk
i ½j� ¼¼ 1 then8: emitNewKeyValue (j; i)
Algorithm 3. Reduce(Object key, Iterable values,Context context)
1: Set IDs ¼ ;, Vector �v2: for Object v : values do3: if v is 1-hop vector then4: �v ¼ v5: else6: IDs.add(v)7: for i = 0 to IDs.size do8: emitNewKeyValue (IDs.get (i), �v)
Algorithm 4. Map (Object key, BinaryWritable value,Context context)
1: UserID i = parseID (key)2: vk
i =parseVector (value)
3: emitNewKeyValue (i;vki )
Algorithm 5. Reduce (Object key, Iterable values,Context context)
1: UserID i = parseID (key)2: vkþ1
i =init ()3: for Object v : values do4: vkþ1
i =doBitWiseOR (vkþ1i ;v)
5: emitNewKeyValue (i;vkþ1i )

h Applications 41 (2014) 6967–6982 6973
In a hot social network with millions of users, it is costly tocompute the social distance for every pair of users, even as an off-
line process. To speed up the computation, we exploit the parallelprocessing framework of MapReduce (Dean & Ghemawat, 2010).Algorithms 2 and 3, illustrate how we generate the kþ 1-hopuser vector for each user, when k-hop user vectors are alreadyknown. Two MapReduce jobs are created. The first job generatesvk
i ½j�v1j (0 6 j 6 n) for each user, while the second one applies the
bit-wise OR to combine the results. For the first mapper (Algorithm2), we have two types of inputs, the k-hop vector and the 1-hopvector. We handle them differently based on Definition 5.
After the k-hop user vectors are generated, we can start a map-only job to compute the social distance between users. For eachuser ui, we compute the social distances between ui and all otherusers, whose least hops to ui are less than Lþ 1. We discard thedetails as the process is quite straightforward.
The social distances of users are subsequently maintained in akey-value store, such as HBase. The key is generated by combiningtwo users’ IDs and the value that denotes their distance. The scal-able key-value store serves to yield high-throughput performance.However, in our query processing, the query engine needs toretrieve all social distances to a specific user. If we generate arequest for each user pair, the query engine incurs too many ran-dom I/Os. To efficiently support such queries, an in-memory cacheis applied. For a user ui, we maintain a sorted buffer BðuiÞ of M users,who have minimal social distances to ui. M is adaptive tuned basedon the query distribution. If the query involves a user not in BðuiÞ,we still need to retrieve the entry from the key-value store. We willdefer the discussion on cache maintenance to the next section.
4.3. Function of co-space distance
SoLoMo systems recommend each user a set of real-time nearbystrangers as the potential friends. In the recommendation process,the physical distance and social distance are combined to form theco-space distance. However, finding an effective way to combinethe two distances is not trivial. Let dðui;ujÞ; gðui;ujÞ and eðui;ujÞdenote the co-space distance, social distance and physical distance(Euclidean distance) between two users ui and uj, respectively. Theco-space distance must satisfy the following properties.
Property 1. For three users, u0;u1 and u2, if gðu0;u1Þ ¼ gðu0;u2Þ andeðu0;u1Þ < eðu0;u2Þ, then dðu0;u1Þ < dðu0;u2Þ.
X. Zhou et al. / Expert Systems wit
Property 2. For three users, u0;u1 and u2, if gðu0;u1Þ < gðu0;u2Þ andeðu0;u1Þ ¼ eðu0;u2Þ, then dðu0;u1Þ < dðu0;u2Þ.
The above two properties indicate that the function of co-spacedistance is monotonic for each of its component. In this paper, weadopt the SVM scheme (Burges, 1998) to learn the co-space func-tion. The social distance and physical distance are used as two vari-ables in the function. The linear SVM function of co-space distanceis represented as:
f ðui;ujÞ ¼ b0gðui;ujÞ þ b1eðui;ujÞ þ b2
Parameter b0;b1 and b2 need to be learned from samples. In ourlearning process, we have the following constraint.
Theorem 2. Linear SVM function guarantees the monotonic proper-ties of the co-space function, if both b0 and b1 are larger than 0.
Proof. If both b0 and b1 are larger than 0, the function f ðui;ujÞ ismonotonic (e.g., the co-space distance increases when either thephysical distance or the social distance increases). Therefore, it sat-isfies the two properties of the co-space distance. h
In fact, more complex non-linear SVM functions with differentkernels can be applied as well, as long as the monotonic propertiesare maintained. We will investigate and compare the performancesof different SVM functions in future work. In this paper, we shalljust use the linear function to demonstrate our idea.
To facilitate the learning process, we adopt the crowdsourcingtechniques (Franklin, Kossmann, Kraska, Ramesh, & Xin, 2011;Liu et al., 2012). In particular, we randomly select m users andfor each user �u, its kNN results are retrieved based on the physicaldistance and the R-tree index. Let the kNN user set beU ¼ fu0; u1; . . . ;uk�1g. A crowdsourcing job is generated for �u andsubmitted to the Amazon Mechanical Turk for processing. In thejob, we ask the human workers to decide whether a user in U isa good recommendation for �u. Therefore, each job contains kquestions.
A typical question is illustrated in Fig. 6. To help the workersmake their decisions, we provide three relationships between theusers.
1. The physical distance computed by the users’ current locations.2. The social relationship between users, e.g., how many n-hop
(1 6 n 6 3) common friends in Facebook.3. The similarities between the two users’ profiles.
The questions and their answers are used as our training sampleset D. For user �u and his recommendation result ui, if the workerreturns ‘‘yes’’ for the question, it indicates that ui is a good recom-mendation result for �u and hence, the co-space distance between ui
and �u should be a small value v0. On the other hand, if the answeris negative, the co-space distance between the two users should beset to a large enough value v1 (v0 < v1). The goal of our trainingprocess is to generate a SVM model that returns a distancevx 6 v0 or vy P v1 for any good or bad recommendation respec-tively. v0 and v1 can be set to any value satisfying v0 < v1. By fol-lowing the standard SVM approach, we set v0 and v1 as �1 and 1 inour training process respectively. The sample set is formalized as:
D ¼ fðxi; yiÞ j xi 2 R2; yi 2 f�1;1gg
where xi is a 2-dimensional vector denoting the social distance andphysical distance between users and yi is the co-space distance. Letw ¼ ðb0; b1Þ. To maximize the margin between two classes, we needto minimize kwk. On the other hand, let �i denote the classificationerror, which is computed as:
yiðw� xi � b2Þ ¼ 1� �i
We need to minimizeP�i to improve the accuracy of the classifier.
By combining the two factors, our optimization goal is to find a lin-ear SVM function dðui;ujÞ, which minimizes
min12kwk2 þ C
X�i
� �ð3Þ
where C is a regularization term that can be estimated by cross-val-idation. We adopt the scheme in Cortes and Vapnik (1995) to solvethe SVM problem.
After the learning process, we get a linear co-space distancefunction, which is used to estimate the similarities between users.The learning process is invoked occasionally to catch the updates ofusers’ relationships. We will study the effectiveness of the co-spacefunction in our experiment.
5. kNN query processing
When a user �u checks into a SoLoMo system, we will return thetop-k nearest neighbors to �u based on the co-space distance. Thekey idea of query processing is illustrated in Algorithm 1. The main

Fig. 6. Crowdsourcing question.
6974 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
challenges are twofold. First, we need to guarantee the correctnessof the kNN results and terminate the processing as soon as possi-ble. We retrieve �u’s nearby users based on their geo-locations,but the ranking function of co-space distance is related to bothsocial and physical distances. This strategy prevents us from usingprevious kNN approaches, such as the index-based approach (Yu,Ooi, Tan, & Jagadish, 2001), directly. Second, the social distancemay be anti-correlated to the physical distance. For instance, twousers, who are physically close to each other, may have no socialsimilarity. In our implementation, the social distance index ismaintained by a key-value store and a cache is adopted to facilitatethe access. As the cache size is limited, with high probability, whenthe query processor retrieves the distance between two users, wemay get a cache miss and need to look up the key-value store,which is costly. Therefore, a good cache maintenance strategy isrequired. In this section, we discuss how to handle the two prob-lems in the SoLoMo query processing. To simplify the discussion,without explicit definition, the social distance and physical dis-tance refers to the distance to the query user �u.
5.1. Naive approach
To retrieve the kNN results progressively, we can adopt the TAalgorithm (Fagin et al., 2001). Given a user �u, we need to retrievetwo user lists, which are sorted in an ascending order based onthe users’ physical and social distances to �u, respectively. However,it is not practical to maintain such sorting lists, since a popularSoLoMo system may have millions of users and the geo-locationsof these users change frequently. Instead, for the physical distance,we can employ an R-tree based incremental kNN algorithm(Hjaltason & Samet, 1999), which can exploit the index and priorityqueue to search for the nearest neighbors continuously. For thesocial distance, it is too costly to generate a sorted list from theusers’ relationships maintained in the key-value store. It is moreefficient to access the social distances via the random access. Asa result, we have one SA (Sorted-Access) data source and one RA(Random-Access) data source.
The naive approach scans the SA source and uses the randomaccess to probe the RA source. Let mins be the minimal social dis-tance between �u and other users. Algorithm 6 illustrates the basicidea. In line 2, we apply the incremental kNN algorithm (Hjaltason& Samet, 1999) to get a sorted user list from R-tree. For eachreturned user, we use dp to denote his physical distance to �u. If cur-rent result size is less than k, we add in the new user into the
candidate set (line 6–7). Otherwise, we compute the co-space dis-tance of the user and compare with existing candidates (line 9–14).After each step, we update the threshold by using mins as the min-imal unseen social distance (line 15). If current kth user has a smal-ler distance than the threshold, the algorithm terminates andreturns.
Algorithm 6. NaivekNN (User �u)
1: Set result ¼ ;, double threshold = MAX2: UserIterator<User,double> S0=lookupIndex (�u)3: while S0.hasMoreUsers () do4: UserTuple t = S0.next ()5: User ui = t.getFirst (), double dp = t.getSecond ()6: if result.size< k then7: result.add (ui)8: else9: double ds = lookupKeyValueStore (�u;ui)
10: f ð�u;uiÞ ¼ b0ds þ b1dp þ b2
11: double dist = getMaxDist (result)12: if f ð�u;uiÞ < dist then13: result.add (ui)14: remove the user with maximal distance from
result15: threshold ¼ b0mins þ b1dp þ b2
16: if getMaxDist (result)< threshold then17: return result//stop and return
The threshold is an estimation for the lower bound of the co-space distance. As in the naive approach, we only update thethreshold based on the physical distances, the algorithm cannotprune the candidates with large social distances. Hence, the naiveapproach may scan a large portion of users before stopping. Toaddress this problem, we next propose a cache-based solution.
5.2. Cache-based approach
Retrieving the social distances from the key-value store incurshigh random I/O costs. To reduce the overhead, we can cache thenearest social friends in a memory buffer. In particular, when wecompute the social distances between �u and other users, we canmaintain a list of the N users with the smallest distances. Whenthe system is online, the query engine loads the nearest neighborsinto memory cache. In this way, we have two sorted lists and theconventional TA algorithm can be applied.
Figs. 7–9 illustrate the idea of cache-based approach. Supposethe co-space distance function is f ðui;ujÞ ¼ gðui;ujÞ þ eðui;ujÞ andwe want to return the top-3 results. Let the left table and righttable represent the user lists sorted by the physical distances andsocial distances respectively. The dotted-line in the right table rep-resents the data not in the cache. To speed up the retrieval, webuild a hash index for UID in the left table. In the first step, weget two users (U1 and U5) with co-space distances of 25 and 40.The physical distance of U1 is retrieved by the R-tree based incre-mental kNN algorithm, while its social distance is directly obtainedfrom the memory cache. Similarly, U5’s social distance is main-tained in the memory and we check its physical distance by look-ing up the hash index. The termination threshold is estimated as10 + 8 = 18. In step 2, the same process repeats and two new usersare probed. The threshold is updated to 27. As only one user has ahigher score (smaller distance) than the threshold, the query pro-cessing continues. In step 3, no new user is found and we havetwo possible results. Therefore, we need to scan the user lists fur-ther. However, we use up the memory cache for the social distancelist. After step 3, the query engine switches to the naive approach,

Fig. 7. kNN processing (step 1). Fig. 8. kNN processing (step 2).
Fig. 9. kNN processing (step 3).
Table 1Notations for cost modeling.
Notations
m0 Average I/O costs of R-tree based incremental algorithmm1 Average I/O costs of key-value storeNp Number of users probed in the R-tree indexNc Number of users in the memory cachen Total number of users in the SoLoMo systemfp PDF of social distancehs Data distribution function of social distancehe Data distribution function of physical distanceymax Largest social distance in memory cache
X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982 6975
except that instead of using mins for the lower bound of social dis-tance, we can use the value of the last user in the memory cache(e.g., 15 in step 3). In the next step, the threshold will be updatedto 43 and the query processing can stop, as more than three resultsare obtained.
The use of cache can effectively reduce the I/O costs by beingable to terminate the query processing early. Let m0 and m1 be theaverage I/O costs of retrieving a user tuple from the R-tree basedincremental algorithm and key-value store respectively. Weassume that looking up the hash index only incurs 1 I/O operation.Suppose the cache size is Nc and we probe Np users in the R-treeindex before stopping. The cost of answering �u’s top-k query canbe estimated as:
Cqueryð�uÞ ¼ ðm0 þ ð1� dÞm1ÞNp þ Nc ð4Þ
where d is the cache hit ratio, computed as the percentage of tuplesin the cache. As d is normally very small, we set it to 0 in the com-putation. When Nc ¼ 0, the above equation can be used to estimatethe processing cost of the naive approach.
To get a precise estimation for Np, we assume that the social dis-tance is independent of the physical distance. Let fp be the proba-bility density function of the social distance. Namely, fpðyiÞdenotes the probability of a social distance equal to yi. Let hs andhe be the sorted data distribution functions of the social distanceand physical distance respectively. Suppose user ui has the mthsmallest social distance and nth smallest physical distance. Hissocial and physical distances can be estimated as hsðmÞ and heðnÞ.In our implementation, all the density and distribution functionsare simulated by histograms. The details have been discussed bymany previous studies and are omitted in this paper (Poosala,1997). Table 1 lists the parameters used in our analysis.
Based on the distribution functions, the largest social distancein the memory cache is
ymax ¼ hsðNcÞ ð5Þ
Suppose the last probed user uj in R-tree index has a physical dis-tance x0, the threshold is
threshold ¼ b0ymax þ b1x0 þ b2 ð6Þ
Let ui be a user with physical distance xi and xi < x0. The R-treebased algorithm must return ui before uj. ui is a potential top-kresult, only if
b0yi þ b1xi þ b2 < threshold ð7Þ
where yi denotes the social distance of ui. The above equation canbe transformed into
yi <b0ymax þ b1x0 � b1xi
b0ð8Þ
The probability of yi < C can be computed asR C
0 fpðyiÞdyi. Theexpected number of valid top-k results is
Nexpect ¼Z x0
0
Z b0ymaxþb1x0�b1xib0
0fpðyiÞdyidxi ð9Þ
Nexpect should be larger than k to guarantee that enough results arefound. On the other hand, based on the data distribution function,we have
x0 ¼ heðNpÞ ð10Þ
Therefore, the function of Np is:
k ¼Z heðNpÞ
0
Z b0hs ðNc Þþb1he ðNp Þ�b1xib0
0fpðyiÞdyidxi ð11Þ
The above equation indicates that Np is correlated to Nc . Given anNc , we can adopt the binary search to find the corresponding Np.To reduce the online computation cost, we pre-compute some pairsof (Nc;Np) and maintain them in a table. When both Nc and Np areknown, the query cost can be estimated by Eq. (4).
Theorem 3. For user �u, a larger cache size results in less number ofusers being probed in the R-tree index. That is, a larger Nc leads to asmaller Np.

Fig. 10. Effect of cache.
6976 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
Proof. By definition, both he and hs are monotonically increasingfunctions. We have hsðNc þ 1Þ ¼ hsðNcÞ þ �, where � > 0. In Eq.(11), we replace Nc with Nc þ 1.
k ¼Z heðNpÞ
0
Z b0hs ðNc Þþb0�þb1he ðNpÞ�b1xib0
0fpðyiÞdyidxi
¼Z heðNpÞ
0
Z b0hs ðNc Þþb1he ðNpÞ�b1xib0
0fpðyiÞdyidxi
þZ heðNpÞ
0
Z b0hs ðNc Þþb0�þb1he ðNpÞ�b1xib0
b0hs ðNc Þþb1he ðNpÞ�b1xib0
fpðyiÞdyidxi
For the same k;Np needs to be smaller to satisfy the above equation.Therefore, a larger Nc leads to a smaller Np. h
The effect of cache on query performance is illustrated inFig. 10. The black line and dotted line represent the terminationthresholds without and with cache, respectively. The red dotsdenote users and their co-space distances. When the cache isemployed, we get a precise lower bound for the unseen co-space distance. Therefore, we can terminate the query process-ing much earlier.
As it is difficult to denote the relationship between Np and Nc
explicitly, direct optimization of Eq. (4) (minimize the query cost)is not possible. However, in our implementation, we found that thefirst term ðm0 þ ð1� dÞm1ÞNp dominates the processing cost. There-fore, the simplest way to minimizing the query cost is to provide alarge buffer for each user to cache his/her social distances. Butwhen the system needs to process concurrent queries with limitedmemory, we cannot keep a large enough cache for all users and thesimple strategy cannot work. Therefore, an adaptive cache mainte-nance strategy is required.
5.3. Cache maintenance
Given limited memory, we need to design an effective cachemaintenance strategy. Let xi denote the query frequency of userui (average number of queries issued by ui per second). The totalquery processing cost is evaluated as:
Ctotal ¼Xn
i
xiCqueryðuiÞ ð12Þ
When we fix Nc , we can estimate Np by Eq. (11) and hence computethe average query cost CqueryðuiÞ. For each specific user ui, we pre-compute a set of ðCqueryðuiÞ;NcÞ for different Nc . In this way, the opti-mal caching strategy is formalized as
Definition 6 (Optimal caching strategy). For each user ui, wedefine his candidate set as Si={(cost0;Nc0), (cost1;Nc1),. . .,(costm;Ncm)}. costj is the estimated query processing cost whenthe cache maintains Ncj social distances for the user. In particular,Nc0 ¼ 0 and cost0 denotes the cost of naive approach for ui. Givenlimited memory size M and n users, the caching strategy needs toselect exact one tuple from each Si. Let idxi be the index of theselection. We need to guarantee that
Pni Si½idxi�½1� 6 M andPn
i xiSi½idxi�½0� is minimized among all possible selections.Finding optimal caching strategy is an NP-complete problem, as
shown in the following theorem.
Theorem 4. Cache optimization problem can be reduced to the setpacking problem.
Proof. Suppose we only compute one Nc for each user. If wechoose to maintain a cache for user ui, we will buffer ui:Nc socialdistances. The cache optimization problem is transformed intohow to select a subset of users for caching to minimize the querycost. This is the conventional set packing problem, which isNP-complete. h
Algorithm 7. CacheMaintenace (Cache C, Query Q)
1: User u = Q.user2: if not C.contains (u) then3: ArrayList L = sortByBenefit (u.candidateSet)4: for i = 0 to L.size do5: Pair< double; int > p = L.get (i)6: double benefit = p.first, int Nc=p.second7: if C.size+ Nc 6 M then8: load Nc social distances of u into cache9: break
10: else11: Replacement R = getSwap (C; p;userset)12: if R:benefit < benefit then13: C.discard (R.all ())14: load Nc social distances of u into cache15: break
In SoLoMo systems, we need to support millions of online users.Therefore, using brute force to find the exact solution is not prac-tical. Instead, a light-weight heuristic approach is applied. Specifi-cally, we define the benefit of a caching strategy of user ui as thecost saving compared to the naive approach:
Bx ¼ xicost0 � costx
Ncx
We rewrite the candidate set of user ui into S0i={(B1;Nc1), . . .,(Bm;Ncm)}. The heuristic algorithm adopts the greedy strategy tomaintain the cache. The cache entry follows the format ofðuid;Nc;DsÞ, where uid is the user ID, Nc is the size of cached dataand Ds is the list of cached social distances.
Algorithm 7 outlines the idea. If the query is issued by an exist-ing user in the cache, we will bypass the adjustment process.Otherwise, we retrieve and sort the user’s candidate set by the ben-efits (line 3). Starting from the strategy with highest benefit, wetest whether the available memory can support the strategy. If

X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982 6977
the memory is large enough, we load the corresponding social dis-tances into memory and terminate the cache maintenance process(line 7–9). Otherwise, we search the cache to find the replacementR (line 11). The replacement consists of one or multiple existingcache entries. That is, R={ðuid0;Nc0;Ds0Þ, . . ., ðuidk;Nck;DskÞ}. Thereplacement contains the entries with least benefits in the cacheand cache:size�
Pkj¼0Ncj þ Nc 6 M. If the total benefit of the entries
in the replacement is smaller than the new entry (line 12), weinsert the new entry and delete the old ones.
5.4. Parallel processing
The query processing techniques proposed in previous sectionscan be easily extended to run on a cluster of computers. The sim-plest strategy is to run an individual query engine on each nodeand share the R-tree index among them. Each query engine canprocess the queries independently and concurrently. One draw-back of this strategy is failing to fully exploit the power of parallelprocessing. Therefore, in this paper, we adopt a MapReduceapproach, which is more scalable and efficient.
Fig. 11 illustrates the processing logic. In our case, we useMapReduce online (Condie et al., 2010), which enables the MapRe-duce framework to handle streaming jobs. The query processingalgorithm runs as a non-stopped MapReduce job. There are twotypes of mappers. One reads the social index from the key-valuestore and distributes them into different reducers. Each reducer willstore the social index for a specific user in its local storage. The sec-ond type of mappers continuously accept the query stream and for-ward the query to the reducer with the corresponding social index.The reducer then works as a query engine to process the query. If itneeds to retrieve the physical distance, it will connect the masternode to get the R-tree index. To reduce the communication costs,all internal R-tree nodes are cached in the reducer and synchro-nized with the master node in a lazy mode. In this way, we caneffectively reduce the I/O cost of query processing, as the reduceronly needs to search its local storage for the social distance.
15 Renren and Weibo are the most popular Facebook-like and Twitter-like socialnetwork sites in China respectively. The connections to other sites (e.g., Facebook andTwitter) can be easily extended.
6. Experimental study
In this section, we evaluate the performance of our proposedapproach using a real dataset crawled from the Gowalla website.In this dataset, there are 456,700 users in our dataset and318,812 users have uploaded their geo-locations via the ‘‘spot’’interface. The geo-location table has 2,942,643 spot records. Inother words, a user can check in more than once. The correspond-ing records are linked together to form his/her traveling trajectory,which is used to simulate the user’s behaviors. For each user, wecompute a query frequency using the number of his/her spotrecords. In each experiment, we randomly select 10 K users andgenerate 20 K queries based on the query distribution. Namely,popular users will issue more queries and each query correspondsto one spot record with a different geo-location. The first 10 K que-ries are used to warm up the cache and we measure the perfor-mance for the rest 10 K queries. The average I/O cost andprocessing time are used as our metrics. When processing thequery, we first update the user’s geo-location in R-tree and thenperform our top-k algorithm for the co-space distance.
The experiment was conducted on a cluster with 16 nodes. Eachnode is equipped with an Intel X3430 2.4 GHz processor, 8 GB ofmemory, 500 GB of disk capacity and gigabit ethernet. On top ofthe cluster, we deploy the Hadoop and HBase as our MapReduceengine and key-value store respectively. Before the experiment,the user vectors are computed via MapReduce jobs and the resultsare stored in HBase as the social index. Without explicitly specified,the top-k algorithm is running on the master node of the cluster.
The R-tree index is maintained in the master node as well. Therange and default settings of the experiment are shown in Table 2.The parallel processing nodes scale from 1 to 16, and no parallelprocessing is adopted by default.
6.1. Importance of co-space distance
To verify the performance of the proposed approach, weimplement an android application of the SoLoMo system. In theapplication, the users are required to provide their Renren(http://www.renren.com/) or Weibo (http://www.weibo.com/)accounts15. We have a back-end cluster, receiving the requests fromthe mobile application. When user joins our system, he needs togrant the Android application to access his personal informationon social network and expose his current location to others. Protect-ing the privacy of users in LBS (Location-Based Service) has been wellstudied (Ozer, Conley, O’Connell, Gubins, & Ginsburg, 2010; Liu,2007). The topic is very challenging by itself and beyond the scopeof this paper. Therefore, we adopt the following basic approach.Firstly, before turning on the recommendation feature, all privacyissues are notified and the user needs to authorize our system forfurther processing. Secondly, when the user turns off the recommen-dation feature, our system will immediately stop recommending theuser to others and disclosing his/her location information. Once theuser grants the SoLoMo system the privilege to access his/her socialaccounts, the back-end cluster will retrieve his/her social informa-tion, including friends and profiles. To reduce the cost, we only keepthe friendship where both users are the registered users in ourSoLoMo system. In this way, we maintain a social graph in our data-base. The social distances of users are computed periodically and forthe new user, before the next iteration of computation, its social dis-tances to his/her friends are set to 1, while the distances to otherusers are set to þ1. The geo-locations of users are collected viathe mobile phones’ GPS. When a user checks in, we perform thekNN processing to retrieve the top similar users based on the co-space distance as the recommendation, which are sent back to themobile application. Fig. 12 shows the interface of the application.We provide two views, the map view and the list view.
The map view shows the user’s current location and all thenearby recommended friends. The list view provides the detailsof the recommendations. In particular, we list the physical distanceand social distance for each recommendation. As the social dis-tance is obscure, we show the number of common 1-hop friendsand shared interests (extracted from the profiles of users). Theapplication is installed by the undergraduates of Zhejiang Univer-sity with more than 1000 registered users.
We also conduct a survey for the users of our android applica-tion. About 130 users submit their survey forms. We show the firstthree questions in Table 3. Most application users agree that merg-ing the spatial distances with the social distances can help improvethe users’ experience in SoLoMo systems. Many of them mentionedthat the major problems of current friend recommendations inSoLoMo system is lack of effective way to turn the strangers intoa stable relationship, while co-space distance can help them estab-lish the relationship more easily.
6.2. SVM learning with crowdsourcing
To merge the social distance and physical distance, we adoptthe SVM learning approach. Specifically, to get enough trainingsamples, we randomly select a set of users and their possiblefriends to generate the crowdsourcing jobs, which are submitted

Fig. 11. MapReduce processing.
Table 2Experiment settings.
Settings
Parameter Range and default valuek 5–15 (10)User number 10,000Cache size per 1 K users 0–48 M (20 M)Processing node 1–16 (1)Adaptive caching NoHDFS data chunk size 256 MB
6978 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
to the AMT for processing. The human workers’ answers are fed tothe SVM model as training samples. In our current implementa-tion, we adopt the linear model. There are 20 jobs submitted tothe AMT. Each job contains 50 samples and their questions. Eachjob is assigned to three workers and we apply the ‘‘majority vote’’approach (Liu et al., 2012) to address the conflictions. Fig. 13 dem-onstrates the learning process. The x-axis represents the social dis-tance between two users, while the y-axis is their physicaldistance. The circle points denote the positive answers from thehuman workers and the cross points are the negative ones. We
Fig. 12. Demonstration of
show the output (the dark line) of the SVM model in the Figure.Most samples can be correctly classified into the two categoriesby the line. For a new point, we use its vertical distance to the lineas its co-space distance. Let the vertical distance be v. If the newpoint belongs to the positive group, the co-space distance is setto �v . Otherwise, it equals to v. Finally, all co-space distances arenormalized to be larger than zero by adding a constant. Giventhe SVM formula, the above computation can be performed effi-ciently. In our future work, we will replace the linear SVM withother kernel-based SVM models to further improve the accuracy.
6.3. Performance of top-k processing
In this set of experiments, we compare the performances of dif-ferent top-k approaches. The naive approach denotes the simpleapplication of TA algorithm with no cached social index. The pro-gressive approach is our approach, which speeds up the query pro-cessing by the adaptive caching strategy. Figs. 14 and 15 show theresults of different k values. For a larger k, more users need to bechecked and more random I/O are incurred for the key-value store.However, note that for the mobile application, a small k (e.g., 10) is
android application.

Table 3Survey result.
Q1: In current social network (e.g., Facebook), is it necessary to include the spatial distance when recommending a new friend?
(a) Yes, it is very necessary. 23%(b) It would be a good feature. 60%(c) No, I do not need the feature. 17%Q2: In current SoLoMo system (e.g., Path), is it necessary to include the social distance when recommending a new friend?(a) Yes, it is very necessary. 50%(b) It would be a good feature. 43%(c) No, I do not need the feature. 7%Q3: Recommending problem in current SoLoMo system:(a) Lack common interest with the recommended strangers. 42%(b) Cannot set up a stable relationship with the strangers. 33%(c) Others. 25%
0
10
20
30
40
50
0 0.5 1 1.5 2
Spat
ial D
ista
nce
(km
)
Social Distance
Fig. 13. SVM with crowdsourcing.
600 800
1000 1200 1400 1600 1800 2000 2200
6 8 10 12 14
Aver
age
I/O C
ost
k value
Naive ApproachProgressive Approach
Fig. 14. I/O Cost of top-k query.
250 300 350 400 450 500 550 600 650
6 8 10 12 14
Aver
age
Tim
e C
ost (
ms)
k value
Naive ApproachProgressive Approach
Fig. 15. Processing time of top-k query.
0
1000
2000
3000
4000
5000
6000
1 2 3 4 5 6 7 8 9 10Av
erag
e I/O
Cos
t
Density-Sorted Workload
Naive ApproachProgressive Approach
Fig. 16. Performance of density-sorted workloads (I/O cost).
0 200 400 600 800
1000 1200 1400 1600 1800
1 2 3 4 5 6 7 8 9 10
Aver
age
Tim
e C
ost (
ms)
Density-Sorted Workload
Naive ApproachProgressive Approach
Fig. 17. Performance of density-sorted workloads (processing time).
X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982 6979
good enough, as the screen cannot display too many results. In thetest, the progressive approach performs better than the naive one.It can significantly reduce the number of retrieved social indexentries and the processing time. It can terminate the scan processmuch early.
In the experiment, we get an interesting observation: the queryperformance is correlated to the user density. With the samesearch range, the user will get more strangers in a higher densityarea. The system needs to check all those users before makingthe correct recommendation. Therefore, the processing cost is high.On the contrary, in the low density area, the system only needs toevaluate a few number of users, as other users with long physicaldistances are definitely not the top-k results (pruned by ourthreshold). To show the query performances in different settings,we cluster the 10 K users into 10 groups by their geo-locations
0
1000
2000
3000
4000
5000
6000
1 2 3 4 5 6 7 8 9 10
Aver
age
I/O C
ost
Randomized Workload
Naive ApproachProgressive Approach
Fig. 18. Performance of randomized workloads (I/O cost).
1100 1200 1300 1400 1500 1600 1700 1800 1900 2000
0 4 8 12 16 20 24
Aver
age
I/O C
ost
Cache Size (MB) per 1000 Users
Fixed Cache ApproachAdaptive Cache Approach
Fig. 20. Effect of adaptive caching (I/O cost).
350
400
450
500
550
600
650
0 4 8 12 16 20 24
Aver
age
Tim
e C
ost (
ms)
Cache Size (MB) per 1000 Users
Fixed Cache ApproachAdaptive Cache Approach
Fig. 21. Effect of cache size (processing time).
6980 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
and each group has 1 K users. In Figs. 16 and 17, we sort the groupsby the user density (workload 10 is the one with highest density)and process the queries for each group individually. The resultsshow that the progressive approach is more scalable for the densearea. Its performance gap to the naive approach becomes larger inthe high density area.
For comparison, in Figs. 18 and 19, we group users randomlyinto 10 sets and conduct the same set of experiments. The resultsare very different from the ones shown in Figs. 16 and 17. Weobserve that the user density plays a major role in the query pro-cessing. For the area such as shopping mall and working office,the query overhead is extremely high. Therefore, load balancingis required. We will study the effect of different load balancingstrategies in our future work.
6.4. Effect of caching strategy
In the progressive approach, to avoid the high random I/O costsincurred by the key-value store, we maintain a buffer for each userto cache the friends with least social distances. In this way, we cancompute a much tighter upper bound for the unseen users and thetop-k processing can terminate early than the naive approach. Infact, the strategy of cache maintenance affects the query perfor-mance significantly. By default, we maintain the same number ofindex entries for each user in the cache. In our case, each indexentry ðu1;u2; distÞ takes 24 bytes. Given 20 M memory for 1 K users,we roughly maintain 1 K entries for each user.
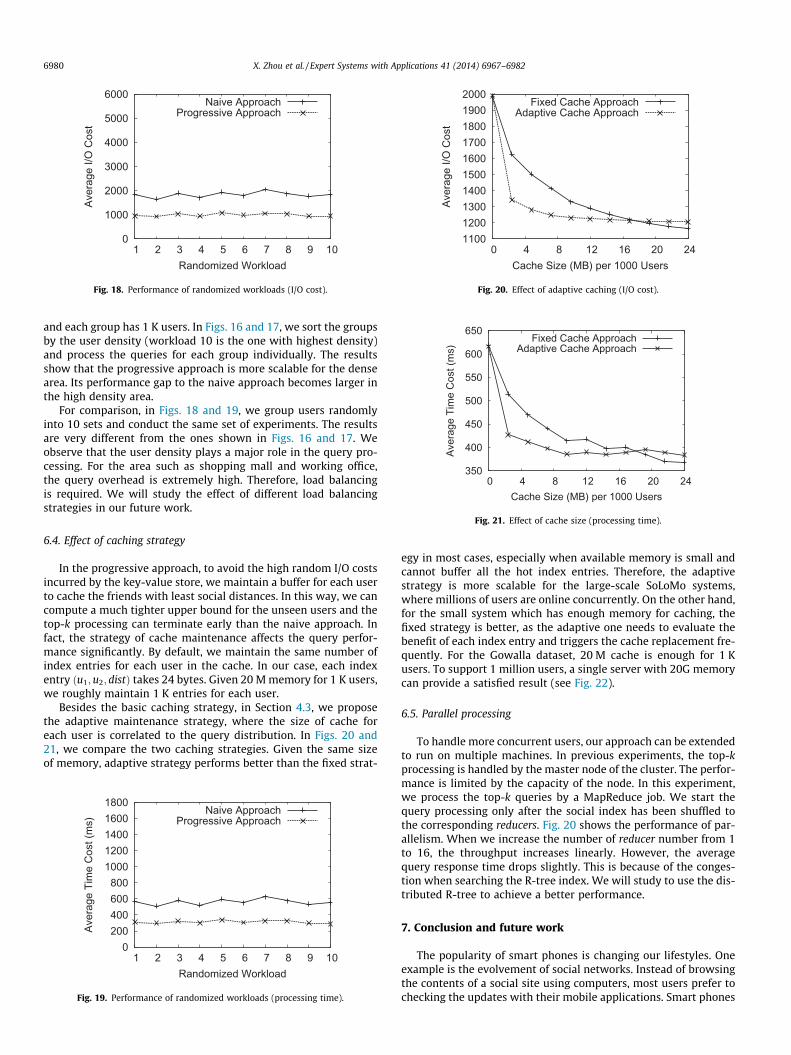
Besides the basic caching strategy, in Section 4.3, we proposethe adaptive maintenance strategy, where the size of cache foreach user is correlated to the query distribution. In Figs. 20 and21, we compare the two caching strategies. Given the same sizeof memory, adaptive strategy performs better than the fixed strat-
0 200 400 600 800
1000 1200 1400 1600 1800
1 2 3 4 5 6 7 8 9 10
Aver
age
Tim
e C
ost (
ms)
Randomized Workload
Naive ApproachProgressive Approach
Fig. 19. Performance of randomized workloads (processing time).
egy in most cases, especially when available memory is small andcannot buffer all the hot index entries. Therefore, the adaptivestrategy is more scalable for the large-scale SoLoMo systems,where millions of users are online concurrently. On the other hand,for the small system which has enough memory for caching, thefixed strategy is better, as the adaptive one needs to evaluate thebenefit of each index entry and triggers the cache replacement fre-quently. For the Gowalla dataset, 20 M cache is enough for 1 Kusers. To support 1 million users, a single server with 20G memorycan provide a satisfied result (see Fig. 22).
6.5. Parallel processing
To handle more concurrent users, our approach can be extendedto run on multiple machines. In previous experiments, the top-kprocessing is handled by the master node of the cluster. The perfor-mance is limited by the capacity of the node. In this experiment,we process the top-k queries by a MapReduce job. We start thequery processing only after the social index has been shuffled tothe corresponding reducers. Fig. 20 shows the performance of par-allelism. When we increase the number of reducer number from 1to 16, the throughput increases linearly. However, the averagequery response time drops slightly. This is because of the conges-tion when searching the R-tree index. We will study to use the dis-tributed R-tree to achieve a better performance.
7. Conclusion and future work
The popularity of smart phones is changing our lifestyles. Oneexample is the evolvement of social networks. Instead of browsingthe contents of a social site using computers, most users prefer tochecking the updates with their mobile applications. Smart phones

0
500
1000
1500
2000
2500
2 4 6 8 10 12 14 16
Thro
ughp
ut (q
uerie
s pe
r min
ute)
Reducer Count
Progressive Approach
(a) Throughput
0 50
100 150 200 250 300 350 400 450 500
2 4 6 8 10 12 14 16
Aver
age
Tim
e C
ost (
ms)
Reducer Count
Progressive Approach
(b) Response Time
Fig. 22. Effect of concurrent processing.
X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982 6981
allow us to connect to our friends anytime, anywhere, resultinginto a new type of social network system, SoLoMo (Social-Loca-tion-Mobile) system. The general idea of SoLoMo system is toenhance the users’ experience by combining their social relation-ships with realtime locations. The main function is to translatethe weak connections (location-based relationship) into strongconnections (social relationships). To fulfil the translation, currentSoLoMo systems adopt the location based friend recommendation.Namely, for each user, the system returns his/her k nearest neigh-bors as the recommendation. He/She can find potential friendswho share similar interests and establish a persistent friend con-nection. However, such strategy is proved ineffective. The reasonis twofold. First, the user lacks of enough information to decidewhether he/she can make a successful friend request with a recom-mended person. Second, people are unwilling to start a conversionwith strangers.
To address the problem, in this paper, we link the SoLoMo userswith their identities in the conventional social networks, such asFacebook and Twitter. The intuition is to increase the recommen-dation accuracy via the users’ social relationship. Therefore, anew similarity metric, co-space distance, is proposed, which com-bines the geo-distance and the social relationship between users.The main challenges of our new recommendation approach aresummarized as below: (1) how to define a proper co-space dis-tance function by merging the physical distance and social dis-tance; and (2) how to efficient compute the top-k recommendedresults based on the co-space distance.
We first train a SVM model to learn the co-space distance func-tion progressively. For each user, given a list of recommendedfriends, we can theoretically classify them into ‘‘good’’ recommen-dations and ‘‘bad’’ recommendations. Good recommendationsimply that the co-space distance between the user and the recom-mended friends should be small enough, while the bad recommen-dations refer to long co-space distances. We generate someclassification questions for a sample set of users and publish thequestions to the crowdsourcing platform, AMT (Amazon Mechani-cal Turk). Human workers will give us highly accurate classificationresults, which are then used to train our SVM model. For each clas-sification result, we theoretically analyze its impact on the SVMmodel and co-space distance function and adjust the model adap-tively. Finally, our SVM model outputs a linear function as our co-space distance function.
After we generate a good co-space distance function, we designa new top-k algorithm to compute the top-k results based on theco-space distance. As users are moving around and setting upnew friendships, co-space distance is a dynamic distance. We need
to compute the distance between two users during query time. Toreduce the possible high overhead of I/Os, we adopt a cache-awareapproach. We theoretically analyze the effect of cache hit ratio andthe data distribution. We prove that generating the optimal cach-ing strategy is NP-hard. Hence, a heuristic approach is applied tominimize the I/O cost. Moreover, to further improve the perfor-mance, we also extend our approach to MapReduce frameworkand exploit the parallelism to speed up the query processing.
Experiments on the real dataset from Gowalla show the goodperformance of our top-k processing. We also build an androidapplication to evaluate the quality of our recommendation results.The participants give us very positive feedbacks for the co-spacebased recommendation results, verifying the effectiveness of com-bining the social and physical distance.
Although the android application shows a promising result forthe recommendation system using co-space distance, there are stillmany open questions that need to be addressed in our future work.
First, in this paper, the training result of SVM model is a linearfunction. It simplifies the computation of co-space distance, but itmay not correctly measure the real distance between users. Toprovide more accurate recommendation results, more complexco-space distance function, such as Gaussian function, should beexamined. The best solution is to employ FFT (Fast FourierTransform) to generate a set of functions to simulate the co-spacedistance. Besides, the co-space function should be aware of datadistribution. E.g., for a dense area with many users, the effect ofphysical distance should be reduced to emphasize the importanceof social part. We can maintain different co-space functions forareas with different densities.
Second, we use the number of shared friends to estimate thesocial distance between users. In fact, there are many differentsocial distances being proposed. We can estimate the social dis-tances by the number of hops between two users, or the numberof replies between them. We need to examine the effect of differ-ent social distances on our recommendation results.
Third, in current implementation, we use existing index struc-tures, such as R-tree and G-tree (Zhong et al., 2013), to speed upour top-k processing. However, existing indexes are not tailoredfor processing queries using co-space distance. To achieve a betterperformance, our next goal is to design a specific index for theco-space distance. The index should support two dimensions,the geo-dimension and the social-dimension. It integrates withthe co-space function naturally. So to retrieve the top-k results ofa query point, we just issue a range query around the query andexpand it if necessary. The new index can significantly reducethe processing overhead.

6982 X. Zhou et al. / Expert Systems with Applications 41 (2014) 6967–6982
Fourth, in this paper, we propose using MapReduce to facilitatethe query processing. MapReduce is not efficient for handling thereal-time query. In our ongoing version, we re-implement our rec-ommendation system on top of apache S4.16 Each node of S4 main-tains a partition of social distance index. When a query is streaminginto the system, we disseminate it to the node that can compute thesocial distance for the query. In this way, we reduce the cost of queryprocessing by an order of magnitude. In a real SoLoMo system, wehave millions of users and this is a truly big data application. A care-fully designed parallel processing model is required. Although S4shows a better performance than MapReduce. we still have manyoptimization and tuning work to do. We will report our findings inour future work.
Finally, it is interesting to see that our android application isbecoming popular among students. The application generates ahuge log for us to analyze. The log records when users check inand how their friendships are established. The log also recordsthe interactions between users. By mining the log data, we hopeto detect the effect of our co-space function and the quality ofour recommendation result. We want to discover the behavior pat-terns of users and use it to guide us in our design of recommenda-tion system.
Acknowledgement
This research has been supported by The National Key Technol-ogy R&D Program of the Ministry of Science and Technology ofChina (Grant No. 2013BAG06B01) and the National Science Foun-dation of China (NSFC Grant 61202047).
References
Akbarinia, R., Pacitti, E., & Valduriez, P. (2007). Processing top-k queries indistributed hash tables. In Euro-Par (pp. 489–502).
Balke, W. -T., Nejdl, W., Siberski, W., & Thaden, U. (2005). Progressive distributedtop-k retrieval in peer-to-peer networks. In ICDE.
Bao, J., Zheng, Y., & Mokbel, M .F. (2012). Location-based and preference-awarerecommendation using sparse geo-social networking data. In Proceedings of the20th international conference on advances in geographic information systems(SIGSPATIAL), 2012.
Bast, H., Majumdar, D., Schenkel, R., Theobald, M., & Weikum, G. (2006). Io-top-k:index-access optimized top-k query processing. In VLDB (pp. 475–486).
Burges, C. J. C. (1998). A tutorial on support vector machines for pattern recognition.Data Mining and Knowledge Discovery, 2, 121–167.
Chang, Y.-J., Liu, H.-H., Chou, L.-D., Chen, Y.-W.,& Shin, H.-Y. (2006). A generalarchitecture of mobile social network services. In 7th International conference onmobile data management (MDM).
Chen, L., Zeng, W., & Yuan, Q. (2013). A unified framework for recommending itemsgroups and friends in social media environment via mutual resource fusion.Expert Systems with Applications, 40(8), 2889–2903.
Cao, L., & Krumm, J. (2009). From GPS traces to a routable road map. In Proceedingsof the 17th ACM SIGSPATIAL international conference on advances in geographicinformation systems.
Cao, P. & Wang, Z. (2004). Efficient top-k query calculation in distributed networks.In PODC.
Chang, K. C. -C. & Hwang, S. -w. (2002). Minimal probing: Supporting expensivepredicates for top-k queries. In SIGMOD (pp. 346–357).
Chang, C.-C., & Lin, C.-J. (2011). LIBSVM: A library for support vector machines. ACMTransactions on Intelligent Systems and Technology, 2(3), 1–27.
Condie, T., Conway, N., Alvaro, P., Hellerstein, J.M., Elmeleegy, K., & Sears, R. (2010).Mapreduce online. In NSDI (pp. 313–328).
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3),273–297.
Das, G., Gunopulos, D., Koudas, N. & Tsirogiannis. D. (2006). Answering top-kqueries using views. In VLDB (pp. 451–462).
Dean, J., & Ghemawat, S. (2010). Mapreduce: A flexible data processing tool.Communication of the ACM, 53(1), 72–77.
Dong, Z. -B., Song, G. -J., Xie, K. -Q. & Wang, J. -Y. (2009). An experimental study oflarge-scale mobile social network. In Proceedings of the 18th internationalconference on world wide web (WWW ’09) (pp. 1175–1176).
Fagin, R. (1999). Combining fuzzy information from multiple systems. Computer andSystem Sciences, 58(1).
16 http://incubator.apache.org/s4/.
Fagin, R., Lotem, J., & Naor, M. (2003). Optimal aggregation algorithms formiddleware. Computer and System Sciences, 66(4).
Fagin, R., Lotem, A. & Naor, M. (2001). Optimal aggregation algorithms formiddleware. 2001. In Proceedings of the twentieth ACM SIGMOD-SIGACT-SIGARTsymposium on principles of database systems (pp. 102–113).
Franklin, M. J., Kossmann, D., Kraska, T., Ramesh, S., & Xin, R. (2011). Crowddb:answering queries with crowdsourcing. In SIGMOD conference (pp. 61–72).
Getoor, L., & Diehl, C. P. (2005). Link mining: A survey. SIGKDD Explorer Newsletter,7(2), 3–12.
Hjaltason, G. R., & Samet, H. (1999). Distance browsing in spatial databases. ACMTransaction on Database System, 24(2), 265–318.
Ilyas, I. F., Beskales, G., & Soliman, M. A. (2008). A survey of top-k query processingtechniques in relational database systems. ACM Computing Survey, 40(4),11:1–11:58.
Kim, J. K., Kim, H. K., & Cho, Y. H. (2008). A user-oriented contents recommendationsystem in peer-to-peer architecture. Expert Systems with Applications, 34(1),300–312.
Kim, H.-N., Saddik, A. E., & Jung, J.-G. (2012). Leveraging personal photos to inferringfriendships in social network services. Expert Systems with Applications, 39(8),6955–6966.
Liu, F., & Lee, H. J. (2010). Use of social network information to enhancecollaborative filtering performance. Expert Systems with Applications, 37(7),4772–4778.
Liu, X., Lu, M., Ooi, B.C., Shen, Y., Wu, S., & Zhang, M. (2012). Cdas: A crowdsourcingdata analytics system. In PVLDB.
Liu, L. (2007). From data privacy to location privacy: Models and algorithms. InVLDB Endowment (pp. 1429–1430).
Lo, S. & Lin, C. (2006). WMR–A graph-based algorithm for friend recommendation.In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence(pp. 121–128).
Michel, S., Triantafillou, P. & Weikum, G. (2005). Klee: A framework for distributedtop-k query algorithms. In VLDB.
Melinger, D., Bonna, K., Sharon, M., SantRam, M. (2004). Socialight: A mobile socialnetworking system. In Poster proceedings of the 6th international confer- ence onubiquitous computing (Ubicomp).
Moricz, M., Dosbayev, Y., & Berlyant, M. (2010). PYMK: Friend recommendation atmyspace. In SIGMOD (pp. 999–1002).
Machuca, E., & Mandow, L. (2012). Multiobjective heuristic search in road maps.Expert Systems with Applications, 39(7), 6435–6445.
O’Madadhain, J., Hutchins, J., & Smyth, P. (2005). Prediction and ranking algorithmsfor event-based network data. SIGKDD Explorations, 7(2), 23–30.
Ozer, N., Conley, C., O’Connell, D. H., Gubins, T. R., & Ginsburg, E. (2010). Location-based services: Time for a privacy check-in. In ACLU of Northern California.
Park, K. (2014). Location-based grid-index for spatial query processing. ExpertSystems with Applications, 41(4), 1294–1300.
Pietilainen, A. -K., Oliver, E., LeBrun, J., Varghese, G., & Diot, C. (2009). MobiClique:Middleware for mobile social networking. In Proceedings of the 2nd ACMworkshop on online social networks (WOSN) (pp. 49–54).
Poosala, V. (1997). Histogram-based estimation techniques in database systems (Ph.D.thesis). Madison, WI, USA. UMI Order No. GAX97-16074.
Popescul, A., & Ungar, L. H. (2003). Statistical relational learning for link prediction.In IJCAI workshop on learning statistical models from relational data.
Rattigan, M., & Jensen, D. (2005). The case for anomalous link discovery. SIGKDDExplorations, 7(2).
Romdhane, L. B., Chaabani, Y., & Zardi, H. (2013). A robust ant colony optimization-based algorithm for community mining in large scale oriented social graphs.Expert Systems with Applications, 40(14), 5709–5718.
Sivic, J. (2009). Efficent visual search of videos cast as text retrieval. IEEETransactions on Pattern Analysis and Machine Intelligence, 31(4), 591–605.
Tsai, F. S., Han, W., Xu, J., & Chua, H. C. (2009). Design and development of a mobilepeer-to-peer social networking application. Expert Systems with Applications,11077–11087.
Wu, Z., Jiang, S., & Huang, Q. (2009). Friend recommendation according toappearances on photos. In ACM Multimedia (pp. 987–988).
Ye, M., Yin, P., & Lee, W. -C. (2010). Location recommendation for location-basedsocial networks. In Proceedings of the 18th SIGSPATIAL international conference onadvances in geographic information systems (GIS), 2010.
Yu, C., Ooi, B. C., Tan, K. -L., & Jagadish, H. V. (2001). Indexing the distance: Anefficient method to kNN processing. In VLDB (pp. 421–430).
Zhang, J., Izmailov, R., Reininger, D., Ott, M. & Nec (1999). U.S.A. Web cachingframework: Analytical models and beyond. In Proceedings of the IEEE workshopon internet applications.
Zheng, Y., Chen, Y., Xie, X., & Ma, W. -Y. (2009). Geolife2.0: A location-based socialnetworking service. In International conference on mobile data management (pp.357–358).
Zheng, Y., Zhang, L., Ma, Z., Xie, X. & Ma, W. -Y. (2011). Recommending friends andlocations based on individual location history. In ACM Trans. Web (Vol. 5, No. 1).
Zhong, R., Li, G., Tan, K. -L. & Zhou, L. (2013). G-tree: An efficient index for kNNsearch on road networks. In Proceedings of the 22nd ACM international conferenceon Conference on information & knowledge management.


















