![Led Zeppelin - Led Zeppelin II [Songbook]](https://static.fdocuments.net/doc/165x107/547a8890b37959892b8b4a0b/led-zeppelin-led-zeppelin-ii-songbook.jpg)
Apache Spark+Zeppelinでアドホックなネットワーク解析
17
Apache Spark+Zeppelin で でででででででででででででで Tetsuhiro Sato
-
Upload
npsg -
Category
Technology
-
view
938 -
download
0
Transcript of Apache Spark+Zeppelinでアドホックなネットワーク解析

Apache Spark+Zeppelin でアドホックなネットワーク解
析Tetsuhiro Sato

2
自己紹介
佐藤 哲大( tetz ) 某ネットワークベンダで、 SDN (っぽい)仕
事をしてます ネットワークプログラマビリティ勉強会の企画、
運営をしてますhttp://network-programmability.connpass.com/

3
全体像
Netflowコレクタ(自作)
Apache Spark と Apache Zeppelin でデータアナリストちっくにアドホックにネットワークトラフィックを解析するっていう、ゆるふわネタ

4
既成可視化ツールとの違い
さまざまな観点からアドホックに可視化できる期間集約(インターフェース、ユーザ、サーバ、アプ
リケーション)上記集約の組み合わせグラフ形式(棒、エリア、円、離散)
とはいえ、ネットワークトラフィックの見たい観点なんて、そんな多様ではないかも。。。

5
自作 Netflow コレクタ
flow record FLOW-RECORD match ipv4 protocol match ipv4 source address match ipv4 destination address match transport source-port match transport destination-port match application name collect counter bytes collect counter packets collect timestamp absolute first collect timestamp absolute last
テンプレートフローセットからデータフローセットを動的に解析し、適切なフィールド名になる
https://github.com/tetsusat/fnfc
ルータの設定
6
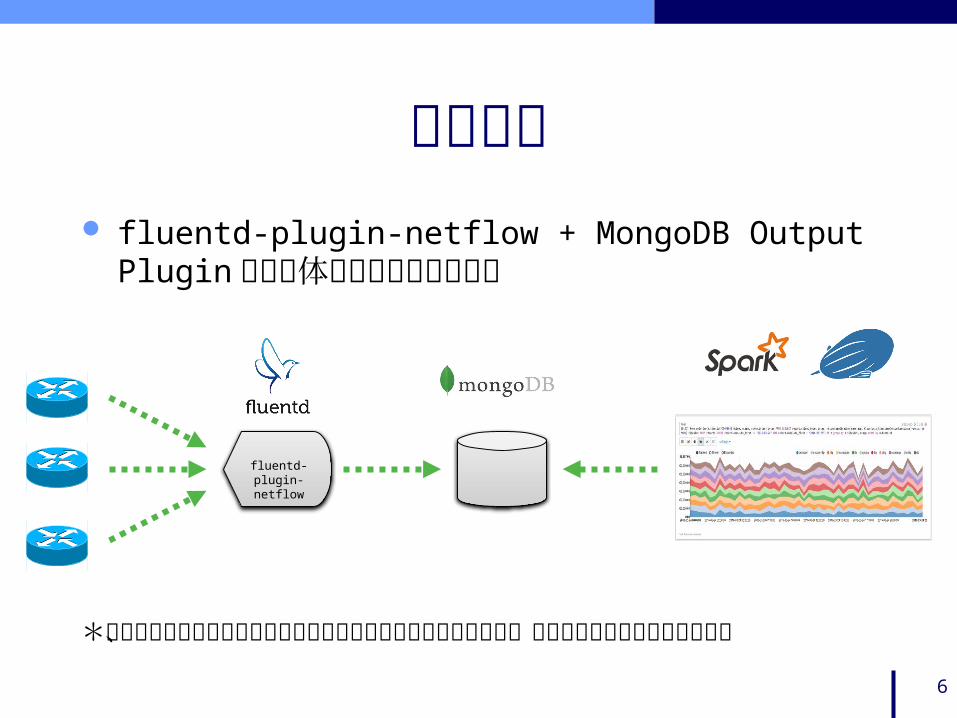
ちなみに fluentd-plugin-netflow + MongoDB Output
Plugin でも大体同じことができます
fluentd-plugin-netflow
*作成されるレコードの構成およびフィールド名が若干違うので、適宜読み替える必要があります

7
Stratio Spark-MongoDB MongoDB 上のコレクションに対して Spark SQL
の処理を可能にするライブラリ
https://github.com/Stratio/Spark-MongoDB

• MongoDB の netflow データベースの records コレクションを Spark DataFrame へ読み込み
Apache Spark + Apache Zeppelin 1/6

• MongoDB から読み込んだデータフレーム( org.apache.spark.sql.DataFrame )のスキーマ
Apache Spark + Apache Zeppelin 2/6

• アプリケーション毎のバイト数
Apache Spark + Apache Zeppelin 3/6
%sqlSELECT record.application_name, sum(record.client_bytes) bytes FROM records GROUP BY record.application_name

• アプリケーション毎のバイト数( WHERE 句をパラメータ化)
Apache Spark + Apache Zeppelin 4/6
%sqlSELECT record.application_name, sum(record.client_bytes) bytes FROM records WHERE record.ipv4_src_addr="${src}" AND record.ipv4_dst_addr="${dst}" GROUP BY record.application_name
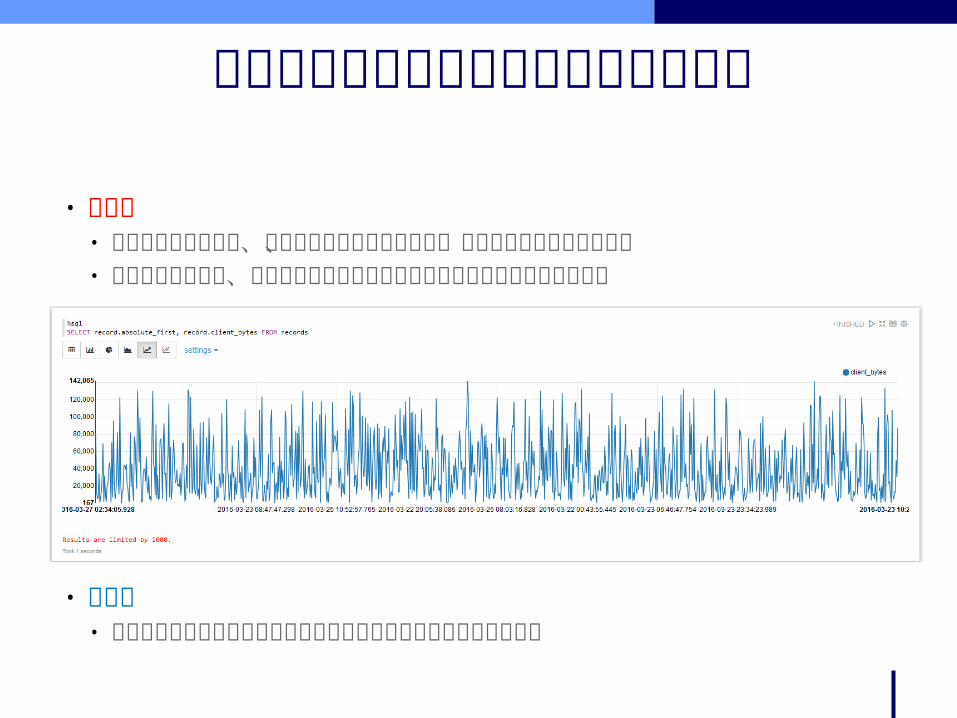
• 問題点• 通信のタイミングは、セッション毎に様々なので、そのままでは集約で
きない• 集約されない結果、グラフ描画ライブラリの処理しきれないほどのレ
コード
時系列データをグラフ化する際の課題
• 解決策• セッションのタイミングを特定間隔のタイムスロットに割り当てる

• 30 分毎に集約
タイムスロットへ割り当て
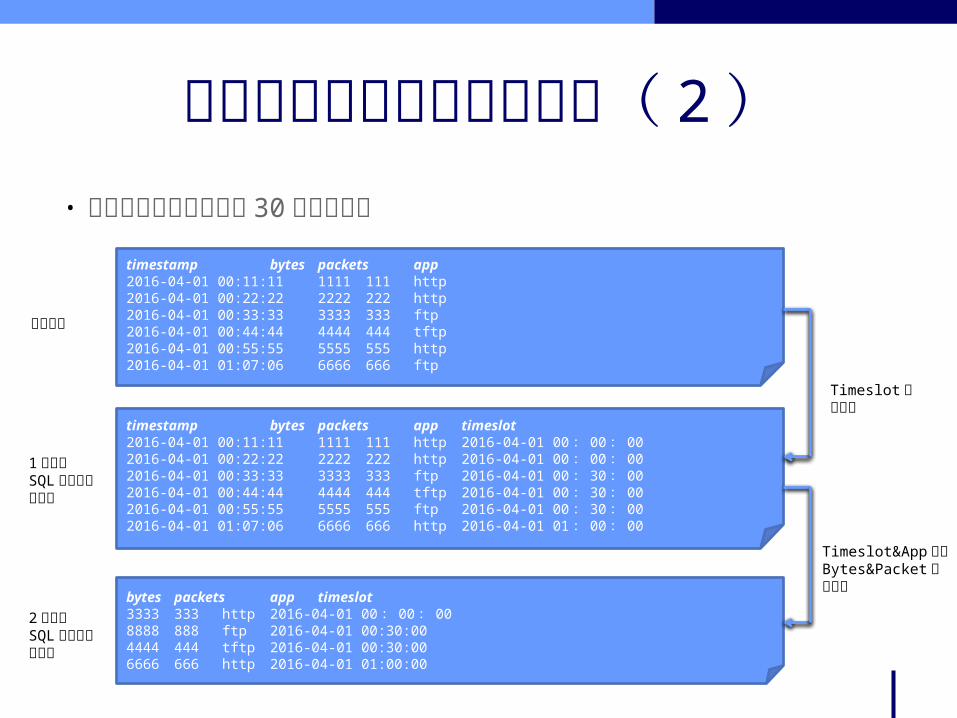
timestamp bytes packets2016-04-01 00:11:11 1111 1112016-04-01 00:22:22 2222 222 2016-04-01 00:33:33 3333 333 2016-04-01 00:44:44 4444 444 2016-04-01 00:55:55 5555 555 2016-04-01 01:07:06 6666 666
元データ
1 回目のSQL クエリーの結果
2 回目のSQL クエリーの結果
Timeslot 列の追加
Timeslot 列でBytes&Packet 列を集約
timestamp bytes packets timeslot2016-04-01 00:11:11 1111 111 2016-04-01 00 : 00 : 002016-04-01 00:22:22 2222 222 2016-04-01 00 : 00 : 002016-04-01 00:33:33 3333 333 2016-04-01 00 : 30 : 002016-04-01 00:44:44 4444 444 2016-04-01 00 : 30 : 002016-04-01 00:55:55 5555 555 2016-04-01 00 : 30 : 002016-04-01 01:07:06 6666 666 2016-04-01 01 : 00 : 00
bytes packets timeslot 3333 333 2016-04-01 00 : 00 : 0013332 1332 2016-04-01 00:30:00 6666 666 2016-04-01 01:00:00
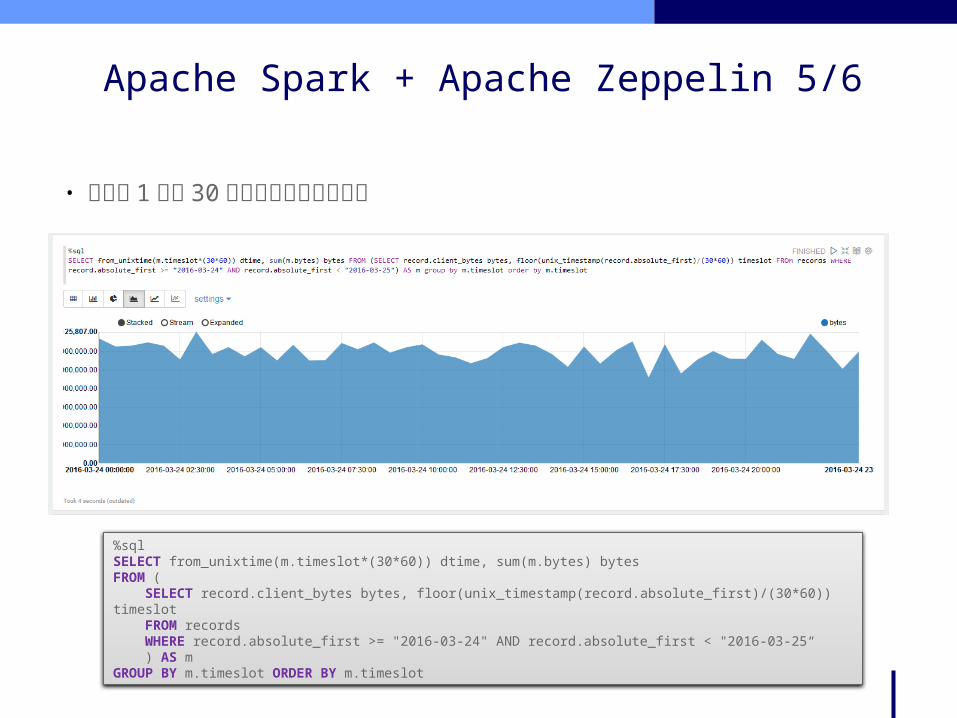
• 特定の 1 日で 30 分毎のバイト数を集計
Apache Spark + Apache Zeppelin 5/6
%sqlSELECT from_unixtime(m.timeslot*(30*60)) dtime, sum(m.bytes) bytes FROM ( SELECT record.client_bytes bytes, floor(unix_timestamp(record.absolute_first)/(30*60)) timeslot FROM records WHERE record.absolute_first >= "2016-03-24" AND record.absolute_first < "2016-03-25“ ) AS mGROUP BY m.timeslot ORDER BY m.timeslot
• アプリケーション毎に 30 分毎に集約
タイムスロットへ割り当て( 2 )
timestamp bytes packets app2016-04-01 00:11:11 1111 111 http2016-04-01 00:22:22 2222 222 http2016-04-01 00:33:33 3333 333 ftp2016-04-01 00:44:44 4444 444 tftp2016-04-01 00:55:55 5555 555 http2016-04-01 01:07:06 6666 666 ftptimestamp bytes packets app timeslot2016-04-01 00:11:11 1111 111 http 2016-04-01 00 : 00 :002016-04-01 00:22:22 2222 222 http 2016-04-01 00 : 00 :002016-04-01 00:33:33 3333 333 ftp 2016-04-01 00 : 30 :002016-04-01 00:44:44 4444 444 tftp 2016-04-01 00 : 30 :002016-04-01 00:55:55 5555 555 ftp 2016-04-01 00 : 30 :002016-04-01 01:07:06 6666 666 http 2016-04-01 01 : 00 :00bytes packets app timeslot3333 333 http 2016-04-01 00 : 00 : 008888 888 ftp 2016-04-01 00:30:004444 444 tftp 2016-04-01 00:30:006666 666 http 2016-04-01 01:00:00
元データ
1 回目のSQL クエリーの結果
2 回目のSQL クエリーの結果
Timeslot 列の追加
Timeslot&App 列でBytes&Packet 列を集約
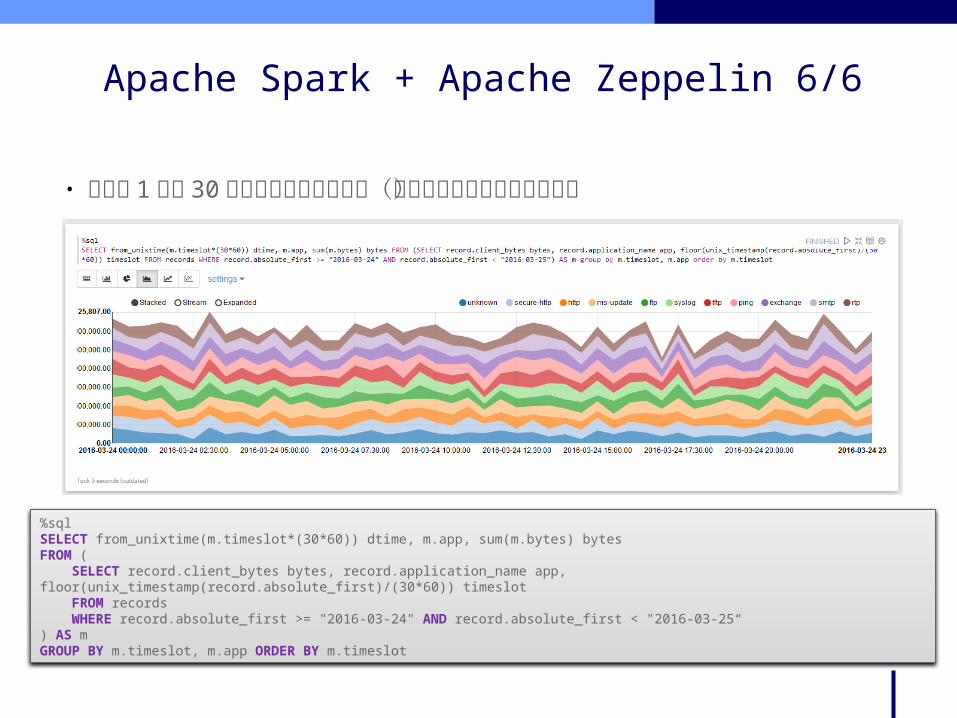
• 特定の 1 日で 30 分毎のバイト数を集計(アプリケーション毎の集約)
Apache Spark + Apache Zeppelin 6/6
%sqlSELECT from_unixtime(m.timeslot*(30*60)) dtime, m.app, sum(m.bytes) bytes FROM ( SELECT record.client_bytes bytes, record.application_name app, floor(unix_timestamp(record.absolute_first)/(30*60)) timeslot FROM records WHERE record.absolute_first >= "2016-03-24" AND record.absolute_first < "2016-03-25“) AS m GROUP BY m.timeslot, m.app ORDER BY m.timeslot

17
おわり
ご清聴、ありがとうございました m(_ _)m


















