

“the lies we tell our code” @misterbisson lies... · Node.js enterprise support Best Practices...
67
Security Management Networking Introspection Performance Utilization “the lies we tell our code” @misterbisson
Transcript of “the lies we tell our code” @misterbisson lies... · Node.js enterprise support Best Practices...

SecurityManagement Networking IntrospectionPerformance Utilization
“the lies we tell our code”@misterbisson


Powering modern applicationsYour favorite code
Container-native infrastructure
Your favorite platforms

SecurityManagement Networking IntrospectionPerformance Utilization
Public Cloud Triton Elastic Container Service. We run our customer’s mission critical applications on container native infrastructure
Private Cloud Triton Elastic Container Infrastructure is an on-premise, container run-time environment used by some of the world’s most recognizable brands
SecurityManagement Networking IntrospectionPerformance Utilization
Public Cloud Triton Elastic Container Service. We run our customer’s mission critical applications on container native infrastructure
Private DataCenter Triton Elastic Container Infrastructure is an on-premise, container run-time environment used by some of the world’s most recognizable brands
it’s open source!fork me, pull me: https://github.com/joyent/sdc

Node.js enterprise support
Best Practices
PerformanceAnalysis
Core FileAnalysis
Debugging Support
Critical IncidentSupport
⚠
As the corporate steward of Node.js and one of the largest-scale production users, Joyent is uniquely equipped to deliver the highest level of enterprise support for this dynamic runtime.

The best place to run Docker
Portability From laptop to any public or private cloud
Great for DevOps Tools for management, deployment & scale
Productivity Faster code, test and deploy

The best place to run containers. Making Ops simple and scalable.
SecurityManagement Networking IntrospectionPerformance Utilization

breath for a moment

lyingto our codeis a practical
choice

withoutmoralconsequence

withoutallconsequence
…but not

most importantly

most importantlynever
lie toyourself
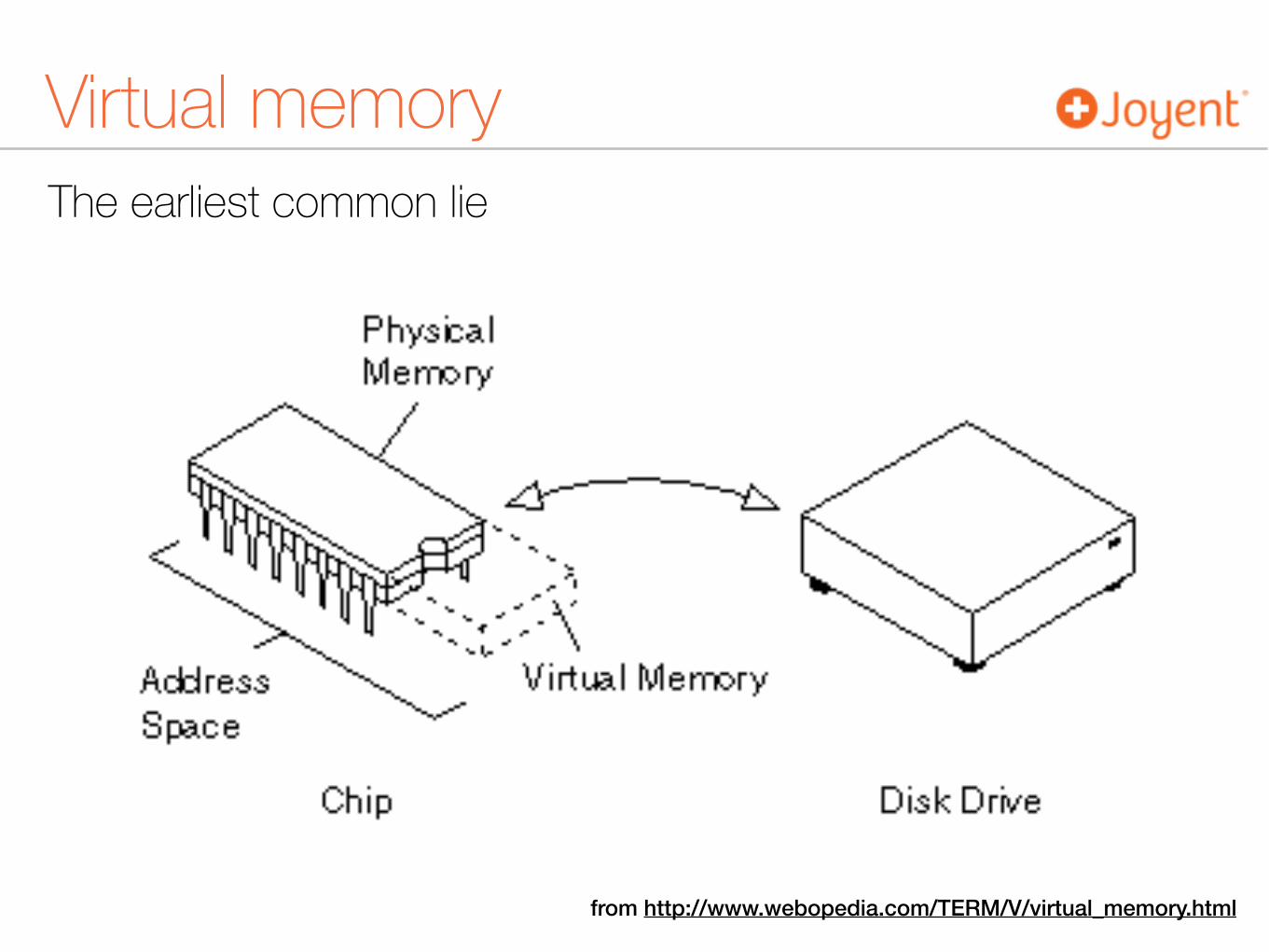
The earliest common lie
Virtual memory
from http://www.webopedia.com/TERM/V/virtual_memory.html

Virtual memoryaccording to Poul-Henning KampTake Squid for instance, a 1975 program if I ever saw one: You tell it how much RAM it can use and how much disk it can use. It will then spend inordinate amounts of time keeping track of what HTTP objects are in RAM and which are on disk and it will move them forth and back depending on traffic patterns. Squid’s elaborate memory management…gets into fights with the kernel’s elaborate memory management, and like any civil war, that never gets anything done. from http://web.archive.org/web/20080323141758/http://varnish.projects.linpro.no/wiki/ArchitectNotes

Virtual memoryaccording to Poul-Henning KampVarnish knows it is not running on the bare metal but under an operating system that provides a virtual-memory-based abstract machine. For example, Varnish does not ignore the fact that memory is virtual; it actively exploits it. A 300-GB backing store, memory mapped on a machine with no more than 16 GB of RAM, is quite typical. The user paid for 64 bits of address space, and I am not afraid to use it. from http://queue.acm.org/detail.cfm?id=1814327

vm.swappiness = 0

The harmless lie
Hyperthreading
from http://www.intel.com/cd/channel/reseller/asmo-na/eng/products/36016.htm

HyperthreadingOne physical core appears as two processors to the operating system, which can use each core to schedule two processes at once. It takes advantage of superscalar architecture in which multiple instructions operate on separate data in parallel. Hyper-threading can be properly utilized only with an OS specifically optimized for it.
from http://en.wikipedia.org/wiki/Hyper-threading
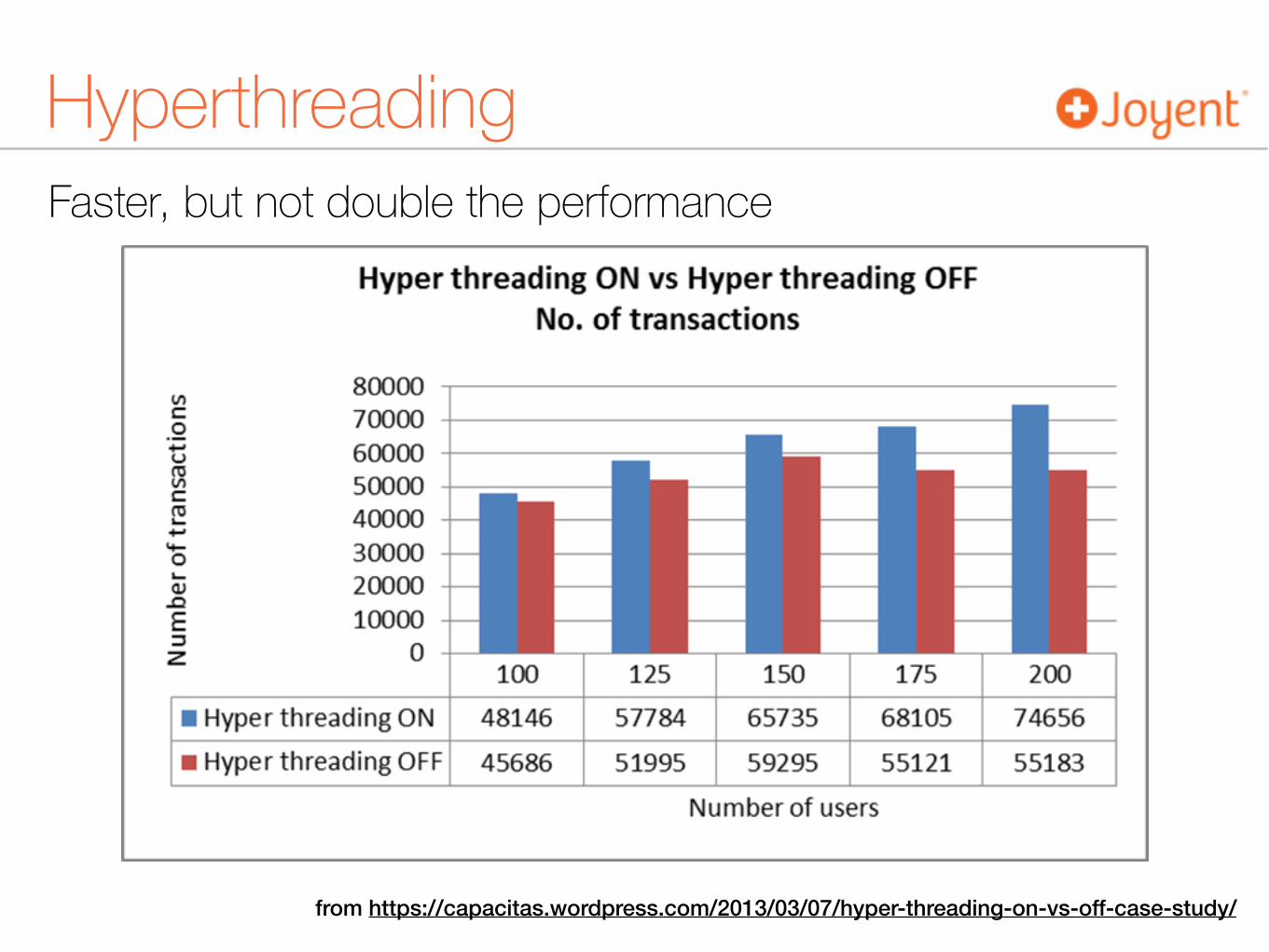
Faster, but not double the performance
Hyperthreading
from https://capacitas.wordpress.com/2013/03/07/hyper-threading-on-vs-off-case-study/

The lie that built the cloud
Hardware virtual machines
from http://virtualizationtutor.com/what-is-hosted-virtualization-and-dedicated-virtualization/

HVM: call translationSay a virtual machine guest OS makes the call to flush the TLB (translation look-aside buffer) which is a physical component of a physical CPU. If the guest OS was allowed to clear the entire TLB on a physical processor, that would have negative performance effects for all the other VMs that were also sharing that same physical TLB. [Instead, the hypervisor must translate that call] so that only the section of the TLB that is relevant to that virtual machine is flushed.
from http://serverfault.com/a/455554

The lie that made VMware huge
HVM: type 1 vs. type 2
from https://microkerneldude.wordpress.com/2009/03/23/virtualization-some-get-it-some-dont/

Lies upon lies
Paravirtualization
from http://www.cubrid.org/blog/dev-platform/x86-server-virtualization-technology/

HVM vs. clocksource…EC2 User: the kernel time will jump from 0 to thousands of seconds.
Kernel dev: for some reason it looks like the vcpu time info misses…without implementation details of the host code it is hard to say anything more.
AWS: Ubuntu…uses the underlying hardware as a timesource, rather than sources native to the instance, leading to timestamps that are out of sync with the local instance time.
from https://forums.aws.amazon.com/thread.jspa?messageID=560443

HVM vs. CPU oversubscriptionAn operating system requires synchronous progress on all its CPUs, and it might malfunction when it detects this requirement is not being met. For example, a watchdog timer might expect a response from its sibling vCPU within the specified time and would crash otherwise. When running these operating systems as a guest, ESXi must therefore maintain synchronous progress on the virtual CPUs. from http://www.vmware.com/files/pdf/techpaper/VMware-vSphere-CPU-Sched-Perf.pdf

HVMs vs. network I/OReality: interrupts are challenging in HVM with oversubscribed CPU. Consider these AWS network tuning recommendations: • Turn off tcp_slow_start_after_idle • Increased netdev_max_backlog from 1000 to 5000 • Maximize window size (rwnd, swnd, and cwnd) from http://www.slideshare.net/AmazonWebServices/your-linux-ami-optimization-and-performance-cpn302-aws-reinvent-2013

HVMs vs. memory oversubscription[P]age sharing, ballooning, and compression are opportunistic techniques. They do not guarantee memory reclamation from VMs. For example, a VM may not have sharable content, the balloon driver may not be installed, or its memory pages may not yield good compression. Reclamation by swapping is a guaranteed method for reclaiming memory from VMs. from https://labs.vmware.com/vmtj/memory-overcommitment-in-the-esx-server

HVM vs. performanceMost successful AWS cluster deployments use more EC2 instances than they would the same number of physical nodes to compensate for the performance variability caused by shared, virtualized resources. Plan to have more EC2 instance based nodes than physical server nodes when estimating cluster size with respect to node count. from http://docs.basho.com/riak/latest/ops/tuning/aws/

Because lying about software is easier than lying about hardware
OS-based virtualization
from http://www.slideshare.net/ydn/july-2014-hug-managing-hadoop-cluster-with-apache-ambari

OS-based virtualizationSimple idea • The kernel is there to manage the relationship with hardware
and isolate processes from each other • We’ve depended on secure memory protection, process
isolation, privilege management in unix for a long time • Let’s leverage that and expand on it OS virt adds new requirements • Namespace lies (pid, uid, ipc, uts, net, mnt) • Polyinstantiation of resources • Virtualized network interfaces, etc Learn more about Linux, SmartOS

OS-based virtualization• Significantly reduced RAM requirements
• Makes microservices possible • Shorter I/O chains • Kernel visibility across all processes
• Co-scheduled I/O and CPU tasks • Elastic use of memory and CPU across all containers • Allowing explicit resizing of containers (raising RAM, CPU, I/O limits) • Allowing bursting of containers (unused CPU cycles can claimed by
whatever container wants them) • Allowing the kernel to use unused RAM as an FS cache across all
containers • Greater tolerance of CPU oversubscription • Significantly higher workload density

run code fasterwith less
hardware
bare metal containers

claim:save money
and reduce CO2 emissions

OS-based virtualization: LinuxLinux kernel support for namespaces is still very new. This note accompanying their introduction has proved prescient:
“[T]he changes wrought by this work are subtle and wide ranging. Thus, it may happen that user namespaces have some as-yet unknown security issues that remain to be found and fixed in the future.” from http://lwn.net/Articles/531114/

from https://twitter.com/swardley/status/587747997334765568

OS-based virtualization: SmartOS• Kernel and facilities built for zones from the start • Process encapsulation separates processes, their data and the namespace
• Processes cannot escape from zones. • Processes cannot observe other zones. • Processes cannot signal other zones. • Naming (such as user IDs or opening a port on an IP address) does not
conflict with other zones • Zone processes have a privilege limit and no process in a zone ever has as
much privilege as the global zone • Mature and tested: almost ten years in production at Joyent without incident • Coming up: filesystem and network virtualization contributions to container
security

Playing charades: two syllables, sounds like…
Syscall virtualization
• The internet • Native Linux binaries • Linux syscall translation • SmartOS Kernel

Syscall virtualization• Branded zones provide a set of interposition points in the
kernel that are only applied to processes executing in a branded zone. • These points are found in such paths as the syscall path,
the process loading path, and the thread creation path. • At each of these points, a brand can choose to
supplement or replace the standard behavior. from http://docs.oracle.com/cd/E19044-01/sol.containers/817-1592/gepea/index.html
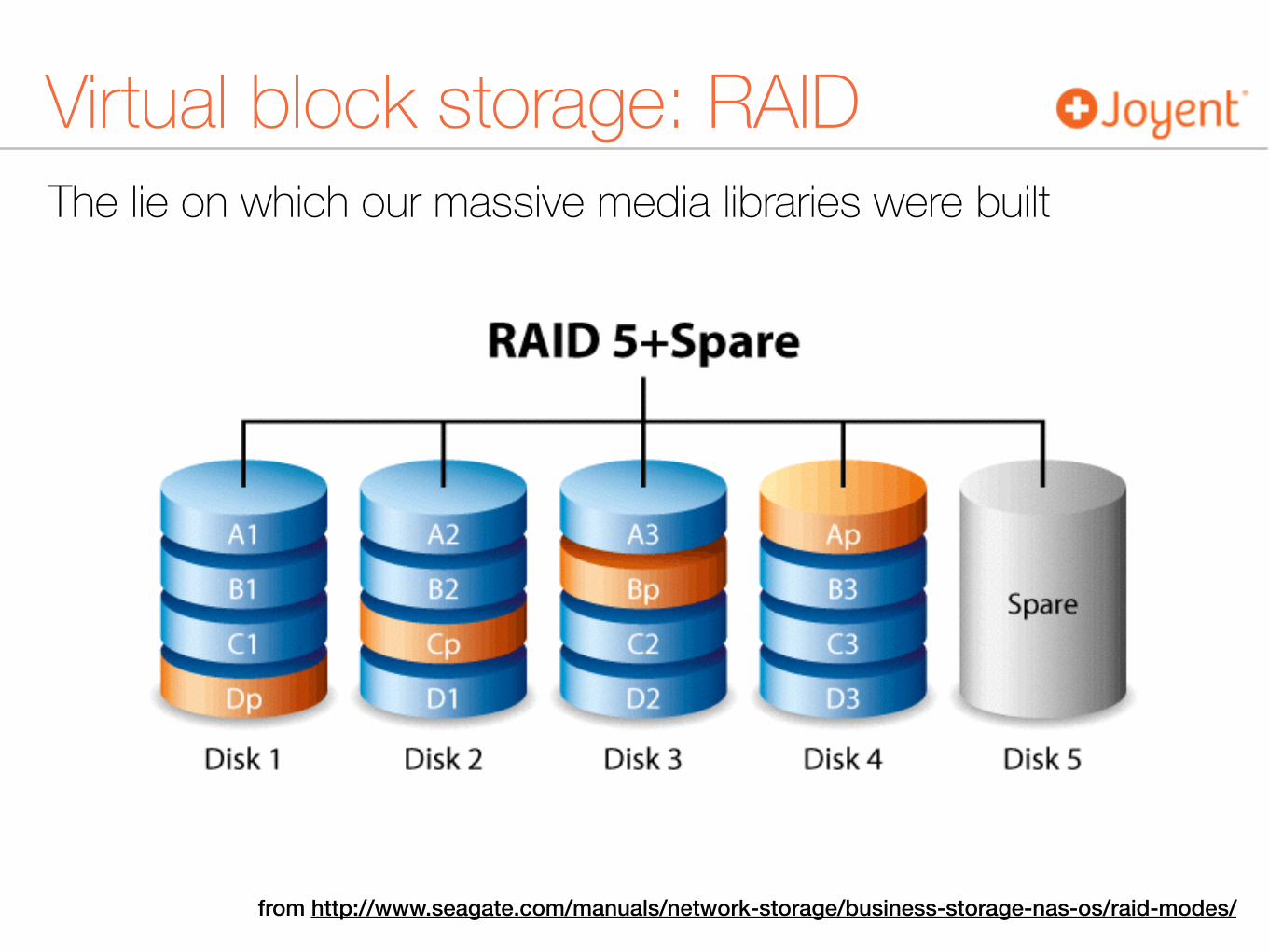
The lie on which our massive media libraries were built
Virtual block storage: RAID
from http://www.seagate.com/manuals/network-storage/business-storage-nas-os/raid-modes/
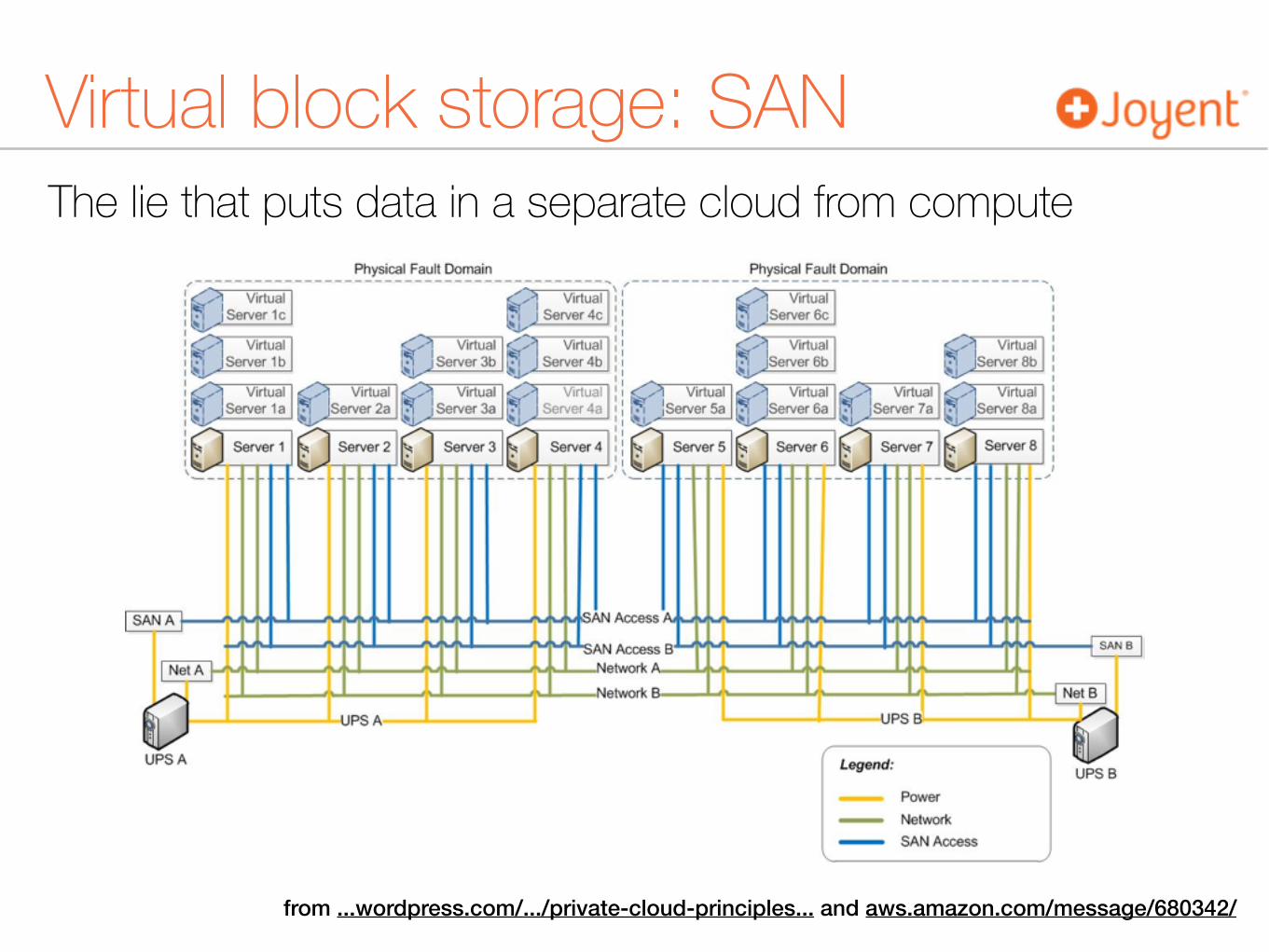
The lie that puts data in a separate cloud from compute
Virtual block storage: SAN
from ...wordpress.com/.../private-cloud-principles... and aws.amazon.com/message/680342/

SAN vs. app performanceRiak's primary bottleneck will be disk and network I/O. [S]tandard EBS will incur too much latency and iowait. Riak's I/O pattern tends to operate on small blobs from many places on the disk, whereas EBS is best at bulk reads and writes. from http://docs.basho.com/riak/latest/ops/tuning/aws/

SAN vs. disaster[Some common solutions] force non-obvious single points of failure. [They are] a nice transition away from traditional storage, but at the end of the day it is just a different implementation of the same thing. SAN and Software Defined Storage are all single points of failure when used for virtual machine storage. from https://ops.faithlife.com/?p=6

The lie that makes everything faster…including data loss
Async writes
from https://logging.apache.org/log4j/2.x/manual/async.html

Async writes vs. NFSContext: RHEL host w/512GB RAM and NFS mounted Oracle DB. Testing showed good DB performance, but inspection of `free` revealed 400GB of RAM used for fs write cache. Further testing showed brief network interruptions resulted in irrecoverable data loss due to partitioning of client from server. Use `forcedirectio` as an NFS mount option if your OS supports it. Applications can open files using `O_DIRECT` flag. The `sync` mount option will lower dirty ratio thresholds to trigger faster writebacks, but won’t necessarily force synchronous writes. Tested Summer 2013, YMMV. See also https://access.redhat.com/solutions/1171283 and http://unix.stackexchange.com/questions/87908/how-do-you-empty-the-buffers-and-cache-on-a-linux-system

More lies about where your data is
Filesystem virtualization: links
from http://www.cs.ucla.edu/classes/spring13/cs111/scribe/11c/ see also Busybox’s use of links, http://www.busybox.net/FAQ.html#getting_started

The lie on which Docker containers are built
Filesystem virtualization: copy-on-write
from https://docs.docker.com/terms/layer/

Filesystem virtualization: AUFS★Works on top of other filesystems ★ File-based copy-on-write ★ Each layer is just a directory in the host filesystem; no user
namespace mapping is applied ★Original underlying filesystem for Docker containers ★ Read/write performance degrades with number of layers ★Write performance degrades with filesize ★ In practice, dotCloud avoided these performance problems by
adding secondary volumes to containers to store data separately from container layers
See also http://jpetazzo.github.io/assets/2015-03-03-not-so-deep-dive-into-docker-storage-drivers.html and https://github.com/docker-library/mysql/blob/master/5.6/Dockerfile#L35
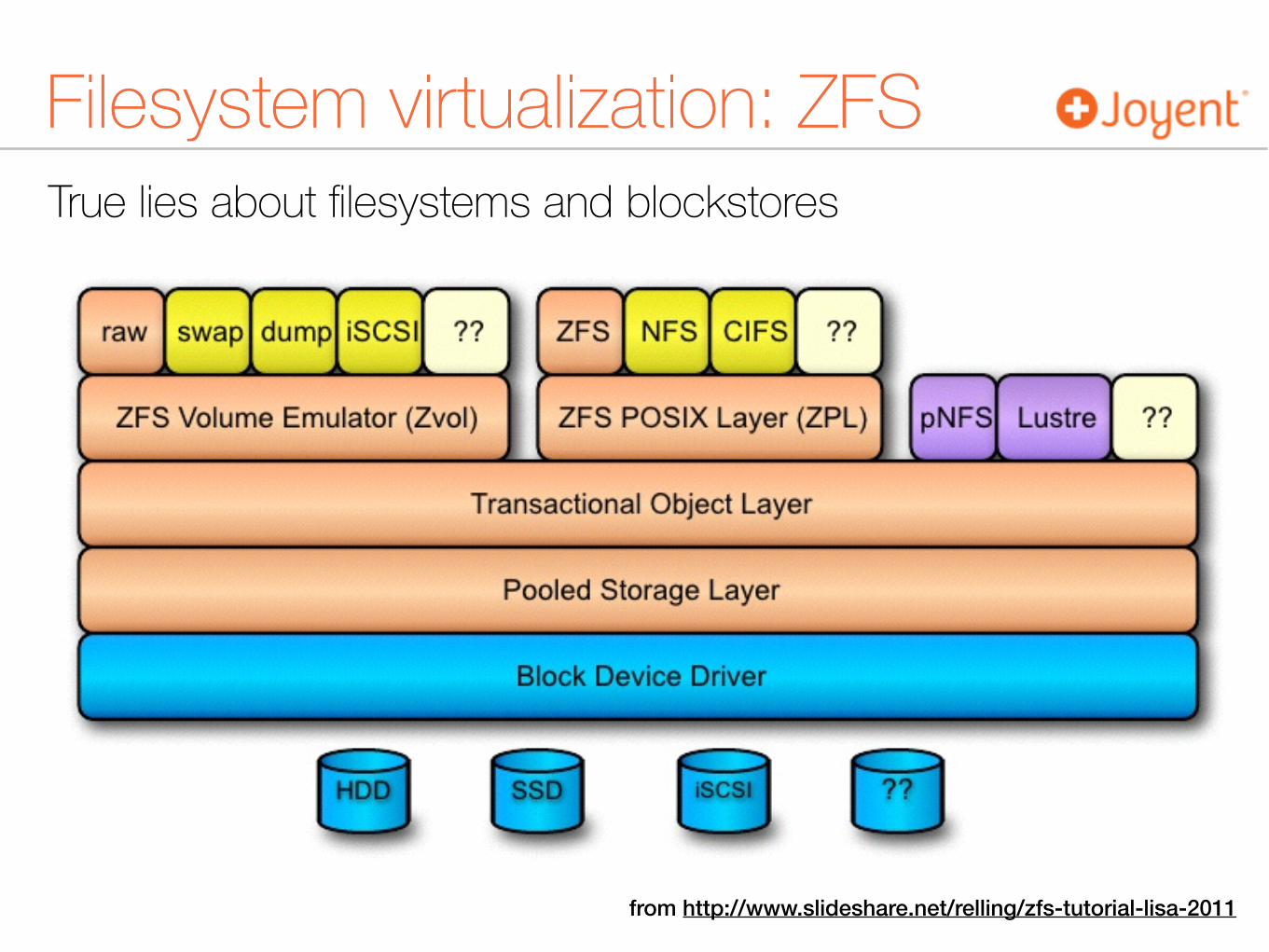
True lies about filesystems and blockstores
Filesystem virtualization: ZFS
from http://www.slideshare.net/relling/zfs-tutorial-lisa-2011

Filesystem virtualization: ZFS★ Native block-based copy on write ★ No performance hit for CoW
★ Default thin provisioned filesystems backed by hybrid pools of real devices ★ Low provisioning cost
★ Native snapshots map to Docker layers ★ Native checksum validation used to detect device errors before
the device reports them ★ Convenient, fast, and reliable by default ★ Native support for write-through SSD and big read caches to
further improve performance

More lies for better performance
Filesystem virtualization: ZFS hybrid pools
from http://na-abb.marketo.com/rs/nexenta/images/tech_brief_nexenta_performance.pdf and http://agnosticcomputing.com/2014/05/01/labworks-14-7-the-last-word-in-zfs-labworks/

from https://twitter.com/swardley/status/587747997334765568

from https://twitter.com/swardley/status/587747997334765568

The lie that completes the cloud
Network virtualization
from https://blogs.oracle.com/sunay/entry/crossbow_virtualized_switching_and_performance (Wayback Machine)

Network virtualization: WeaveA weave router captures Ethernet packets from its bridge-connected interface in promiscuous mode, using ‘pcap’. This typically excludes traffic between local containers, and between the host and local containers, all of which is routed straight over the bridge by the kernel. Captured packets are forwarded over UDP to weave router peers running on other hosts. On receipt of such a packet, a router injects the packet on its bridge interface using ‘pcap’ and/or forwards the packet to peers. from http://weaveworks.github.io/weave/how-it-works.html
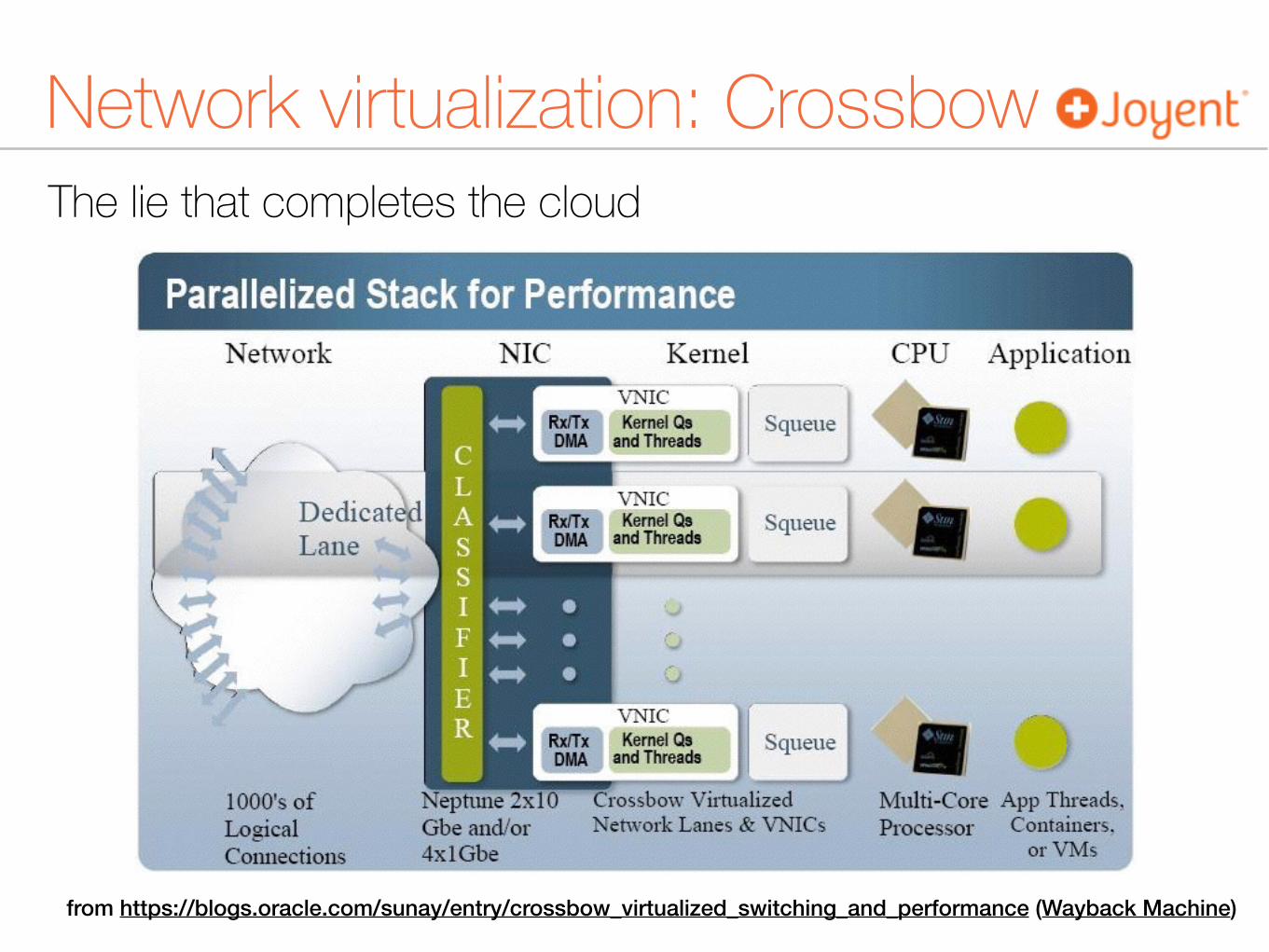
The lie that completes the cloud
Network virtualization: Crossbow
from https://blogs.oracle.com/sunay/entry/crossbow_virtualized_switching_and_performance (Wayback Machine)

Network virtualization: Triton SDN• Extends Crossbow to add user-defined networks. • Every user gets a private layer 2 network with a unique IP. • All my containers have working interconnectivity, regardless of
what physical hardware they’re on • …but your containers can’t see my containers. • When requested, containers also get a unique, publicly
routable IP.

An exquisite collection of lies
Docker
from https://blog.docker.com/2014/12/announcing-docker-machine-swarm-and-compose...

Docker: Swarm• Aggregates any number of Docker Remote API endpoints and
presents them as a single endpoint • Automatically distributes container workload among available
APIs • Works in combination with Docker Compose to deploy and
scale applications composed of multiple containers • Offers a direct path from building and testing on our
laptops to deploying across a number of hosts • Downside: you pay for VMs, not containers

Docker: Triton• Exposes the entire data center as a single Docker
Remote API endpoint • Automatically distributes container workload among available
APIs • Works in combination with Docker Compose to deploy and
scale applications composed of multiple containers (awaiting DOCKER-335 or compose/1317)
• Offers a direct path from building and testing on our laptops to deploying across a number of hosts
• You pay for containers, not VMs

breath for a moment

Lie about all the things• Containerize for better performance and workload density
• Don't run containers in VMs, that's sad • Watch out for security issues
• ...including at the filesystem level • Virtualize the network too,
• give every container its own NICs and IPs • Don't stop lying at the edge of the compute node

Missy Elliot’s philosophy• Is it worth it? • Let me work it • I put my thing down, flip it, and reverse it • Get that cash • Ain't no shame • Do your thing • Just make sure you’re ahead of the game

SecurityManagement Networking IntrospectionPerformance Utilization
Thank you

Remember Joyent for…• Proven container security
Run containers securely on bare metal in multi-tenant environments
• Bare metal container performance Eliminate the hardware hypervisor tax
• Simplified container networking Each container has its own IP(s) in a user-defined network (SDN)
• Simplified host management Eliminates Docker host proliferation
• Hybrid: your data center or ours Private cloud, public cloud, hybrid cloud, and open source


















