
VSSML16 LR1. Summary Day 1
38
Class summary
-
Upload
bigml-inc -
Category
Data & Analytics
-
view
221 -
download
0
Transcript of VSSML16 LR1. Summary Day 1

Class summary

BigML, Inc.2
Day 1 – Morning sessions
Class summary

BigML, Inc.3
A Gentle Introduction toMachine Learning
Charles Parker
● Experts who extract some rules to predict new results
● Programmers who tailor a computer program that predicts following the expert's rules.
● Non easily scalable to the entire organization
● Data (often easily to be found and more accurate than the expert)
● ML algorithms
(faster, more modular, measurable performance)
● Scalable to the entire organization
What is your company's strategy based on?
Expertdriven decisions Datadriven decisions

BigML, Inc.4
A Gentle Introduction toMachine Learning
When datadriven decisions are a good idea
● Experts are hard to find or expensive● Expert knowledge is difficult to be programmed into
production environments accurately/quickly enough● Experts cannot explain how they do it: character or speech
recognition● There's a performancecritical handmade system
● Experts are easily found and cheap● Expert knowledge is easily programmed into production
environments● The data is difficult or expensive to acquire
When datadriven decisions are a bad idea

BigML, Inc.5
A Gentle Introduction toMachine Learning
Steps to create a ML program from data
● Acquiring data
In tabular format: each row stores the information about the thing that has a property that you want to predict. Each column is a different attribute (field or feature).
● Defining the objective
The property that you are trying to predict● Using an ML algorithm
The algorithm builds a program (the model or classifier) whose inputs are the attributes of the new instance to be predicted and whose output is the predicted value for the target field (the objective).

BigML, Inc.6
A Gentle Introduction toMachine Learning
Modeling: creating a program with an ML algorithm
● The algorithm searches in a Hypothesis Space the set of variables that best fits your data
Examples of Hypothesis Spaces:● Logistic regression: Features coefficients + bias● Neural network: weights for the nodes in the network● Support vector machines: coefficients on each training point● Decision trees: combination of features ranges

BigML, Inc.7
A Gentle Introduction toMachine Learning
Decision tree construction
● What question splits better you data? try all possible splits and choose the one that achieves more purity
● When should we stop?
When the size of the subset is totally pure
When the size reaches a predetermined minimum
When the number of nodes or tree depth is too large
When you can’t get any statistically significant improvement
● Nodes that don’t meet the latter criteria can be removed after tree construction via pruning
The recursive algorithm analyzes the data to find

BigML, Inc.8
A Gentle Introduction toMachine Learning
Visualizing a decision tree
Root node(split at petal length=2.45)
Branches
Leaf(splitting stops)

BigML, Inc.9
A Gentle Introduction toMachine Learning
Decision tree outputs
● Prediction: Start from the root node. Use the inputs to answer the question associated to each node you reach. The answer will decide which branch will be used to descend the tree. If you reach a leaf node, the majority class in the leaf will be the prediction.
● Confidence: Degree of reliability of the prediction. Depends on the purity of the final node and the number of instances that it classifies.
● Field importance: Which field is more decisive in the model's classification. Depends on the number of times it is used as the best split and the error reduction it achieves.
Inputs: values of the features for a new instance

BigML, Inc.10
A Gentle Introduction toMachine Learning
Evaluating your models
● Testing your model with new data is the key to measure its performance. Never evaluate with training data!
● Simplest approach: split your data into a training dataset and a test dataset (8020% is costumary)
● Advanced approach: to avoid biased splits, do it repeatedly and average evaluations or kfold crossvalidate.
● Accuracy is not a good metric when classes are unbalanced. Use the confusion matrix instead or phi, F1score or balanced accuracy.
Which evaluation metric to choose?

BigML, Inc.11
● Confusion matrix can tell the number of correctly classified (TP, TN) or misclassified instances (FP, FN) but this does not tell you how misclassifications will impact your business.
● As a domain expert, you can assign a cost to each FP or FN (cost matrix). This cost/gain ratio is the significant performance measure for your models.
A Gentle Introduction toMachine Learning
Domain specific evaluation

BigML, Inc.12
● Ensembles are groups of different models built on samples of data.
● Randomness is introduced in the models. Each model is a good approximation for a different random sample of data.
● A single ML Algorithm may not adapt nicely to some datasets. Combining different models can.
● Combining models can reduce the over-fitting caused by anomalies, errors or outliers.
● The combination of several accurate models gets us closer to the real model.
Ensembles
Can a group of weaker models outperform a stronger single model?
Poul Petersen

BigML, Inc.13
● Bootstrap aggregating (bagging) models are built on random samples (with replacement) of n instances.
● Random decision forest in addition to the random samples of bagging, the models are built by choosing randomly the candidate features at each split (random candidates).
● Plurality majority wins● Confidence weighted each vote is weigthed by confidence
and majority wins● Probability weighted each tree votes according to the
distribution at its prediction node● K-Threshold a class is predicted only if enough models vote
for it● Confidence Threshold votes for a class are only computed
if their confidence is over the threshold
Ensembles
Types of ensembles
Types of combinations

BigML, Inc.14
● How many trees?● How many nodes?● Missing splits?● Random Candidates?
● SMACdown: automatic optimization of ensembles by exploring the configuration space.
Ensembles
Configuration parameters
Too many parameters? Automate!

BigML, Inc.15
● Regressions are typically used to relate two numeric variables
● But using the proper function we can relate discrete variables too
Logistic Regression
How comes we use a regression to classify?Logistic Regression is a classification ML Algorithm
Poul Petersen

BigML, Inc.16
● We should use feature engineering to transform raw features in linearly related predictors, if needed.
● The ML algorithm searches for the coefficients to solve the problem
by transforming it into a linear regression problem
In general, the algorithm will find a coefficient per feature plus a bias coefficient and a missing coefficient
Logistic Regression
Assumption: The output is linearly related to the predictors.

BigML, Inc.17
• Bias: Allows an intercept term. Important if P(x=0) != 0
• Regularization
L1: prefers zeroing individual coefficientsL2: prefers pushing all coefficients towards
zero
• EPS: The minimum error between steps to stop.
• Auto-scaling: Ensures that all features contribute equally. Recommended unless there is a specific need to not auto-scale.
Logistic Regression
Configuration parameters

BigML, Inc.18
• Multi-class LR: Each class has its own LR computed as a binary problem (one-vs-the-rest). A set of coefficients is computed for each class.
• Non-numeric predictors: As LR works for numeric predictors, the algorithm needs to do some encoding of the non-numeric features to be able to use them. These are the field-encodings. – Categorical: one-shot, dummy encoding, contrast
encoding– Text and Items: frequencies of terms● Curvilinear LR: adding quadratic features as new
features
Logistic Regression
Extending the domain for the algorithm

BigML, Inc.19
Logistic Regression
Logistic Regressions versus Decision Trees
● Expects a "smooth" linear relationship with predictors
● LR is concerned with probability of a discrete outcome.
● Lots of parameters to get wrong: regularization, scaling, codings
● Slightly less prone to over-fitting
● Because fits a shape, might work better when less data available.
● Adapts well to ragged non-linear relationships
● No concern:
classification, regression, multi-class all fine.
● Virtually parameter free● Slightly more prone to
over-fitting● Prefers surfaces parallel
to parameter axes, but given enough data will discover any shape.

BigML, Inc.20
Day 1 – Evening sessions

BigML, Inc.21
● Clustering is a ML technique designed to find and group of similar instances in your data (group by).
● It's unsupervised learning, as opposed to supervised learning algorithms, like decision trees, where training data has been labeled and the model learns to predict that label. Clusters are built on raw data.
● Goal: finding k clusters in which similar data can be grouped together. Data in each cluster is similar self similar and dissimilar to the rest.
Clusters
Clusters: looking for similarityPoul Petersen

BigML, Inc.22
● Customer segmentation: grouping users to act on each group differently
● Item discovery: grouping items to find similar alternatives
● Similarity: Grouping products or cases to act on each group differently
● Recommender: grouping products to recommend similar ones
● Active learning: grouping partially labeled data as alternative to labeling each instance
Clustering can help us to identify new features shared by the data in the groups
Clusters
Use cases

BigML, Inc.23
● K-means: The number of expected groups is given by the user. The algorithm starts using random data points as centers.
– K++: the first center is chosen randomly from instances and each subsequent center is chosen from the remaining instances with probability proportional to its squared distance from the point's closest existing cluster center
Clusters
Types of clustering algorithm
The algorithm computes distances based on each instance features. Each instance is assigned to the nearest center or centroid. Centroids are recalculated as the center of all the data points in each cluster and process is repeated till the groups converge.
● G-means: The number of groups is also determined by the algorithm. Starting from k=2, each group is split if the data distribution in it is not Gaussian-like.

BigML, Inc.24
How distance between two instances is defined?
For clustering to work we need a distance function that must be computable for all the features in your data. Scaled euclidean distance is used for numeric features. What about the rest of field types?
Categorical: Features contribute to the distance if categories for both points are not the same
Text and Items: Words are parsed and its frequencies are stored in a vector format. Cosine distance (1 – cosine similarity) is computed.
Missing values: Distance to a missing value cannot be defined. Either you ignore the instances with missing values or you previously assign a common value (mean, median, zero, etc.)
Clusters
Extending clustering to different data types

BigML, Inc.25
● Anomaly detectors use ML algorithms designed to single out instances in your data which do not follow the general pattern (rank by).
● As clustering, they fall into the unsupervised learning category, so no labeling is required. Anomaly detectors are built on raw data.
● Goal: Assigning to each data instance an anomaly score, ranging from 0 to 1, where 0 means very similar to the rest of instances and 1 means very dissimilar (anomalous).
Anomaly Detection
Anomaly detection: looking for the unusualPoul Petersen

BigML, Inc.26
● Unusual instance discovery● Intrusion Detection: users whose behaviour does not
comply to the general pattern may indicate an intrusion● Fraud: Cluster per profile and look for anomalous
transactions at different levels (card, user, user groups)● Identify Incorrect Data● Remove Outliers● Model Competence / Input Data Drift: Models
performance can be downgraded because new data has evolved to be statistically different. Check the prediction's anomaly score.
Anomaly Detection
Use cases

BigML, Inc.27
Anomaly Detection
Statistical anomaly indicators
● Univariateapproach: Given a single variable, and assuming normal distribution (Gaussian). Compute the standard deviation and choose a multiple of it as threshold to define what's anomalous.
● Benford's law: In reallife numeric sets the small digits occur disproportionately often as leading significant digits.

BigML, Inc.28
Anomaly Detection
Isolation forests● Train several random
decision trees that overfit data till each instance is completely isolated
● Use the medium depth of these trees as threshold to compute the anomaly score, a number from 0 to 1 where 0 is similar and 1 is dissimilar
● New instances are run through the trees and assigned an anomaly score according to the average depth they reach

BigML, Inc.29
● Association Discovery is an unsupervised technique, like clustering and anomaly detection.
● Uses the “Magnum Opus” algorithm by Geoff Webb
Association Discovery
Geoff Webb and Poul Petersen
Looking for “interesting” relations between variables
date customer account auth class zip amount
Mon Bob 3421 pin clothes 46140 135
Tue Bob 3421 sign food 46140 401
Tue Alice 2456 pin food 12222 234
Wed Sally 6788 pin gas 26339 94
Wed Bob 3421 pin tech 21350 2459
Wed Bob 3421 pin gas 46140 83
Tue Sally 6788 sign food 26339 51
{class = gas} amount < 100
{customer = Bob, account = 3421} zip = 46140
Antecedent Consequent

BigML, Inc.30
Association Discovery
Use Cases
Market Basket Analysis
Web usage patterns
Intrusion detection
Fraud detection
Bioinformatics
Medical risk factors

BigML, Inc.31
Association Discovery
Problems with frequent pattern mining
● Often results in too few or too many patterns● Some high value patterns are infrequent● Cannot handle dense data● Cannot prune search space using constraints on relationship between antecedent and consequent eg confidence
● Minimum support may not be relevant● Cannot be low enough to capture all valid rules cannot be high enough to exclude all spurious rules

BigML, Inc.32
● Very high support patterns can be spurious● Very infrequent patterns can be significant
So the user selects the measure of interest
System finds the top-k associations on that measure within constraints – Must be statistically significant interaction
between antecedent and consequent– Every item in the antecedent must increase
the strength of association
Association Discovery
It turns out that:
BigML, Inc.33
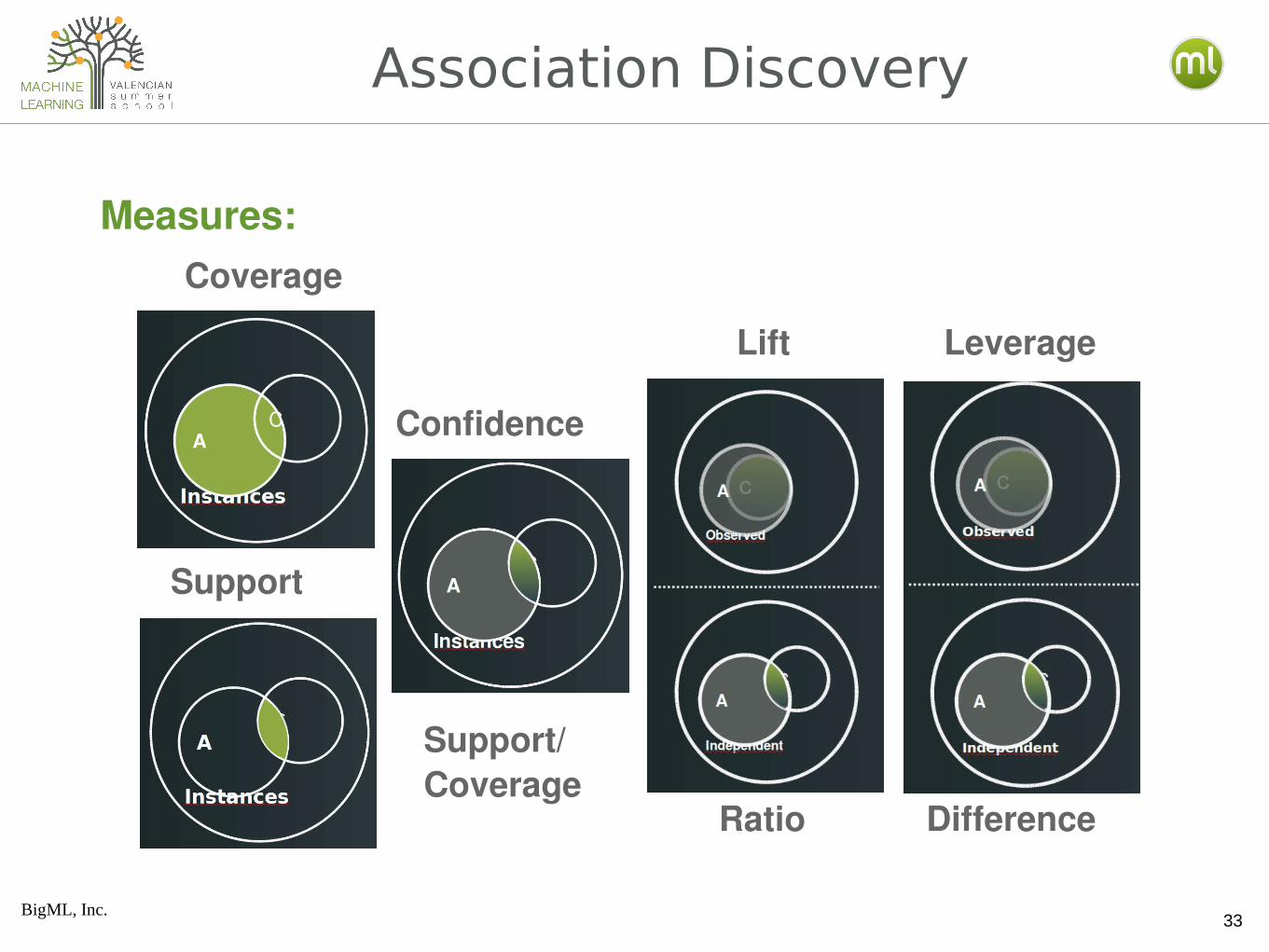
Association Discovery
Measures:Coverage
Support
Confidence
Lift Leverage
Support/Coverage
Ratio Difference
BigML, Inc.34
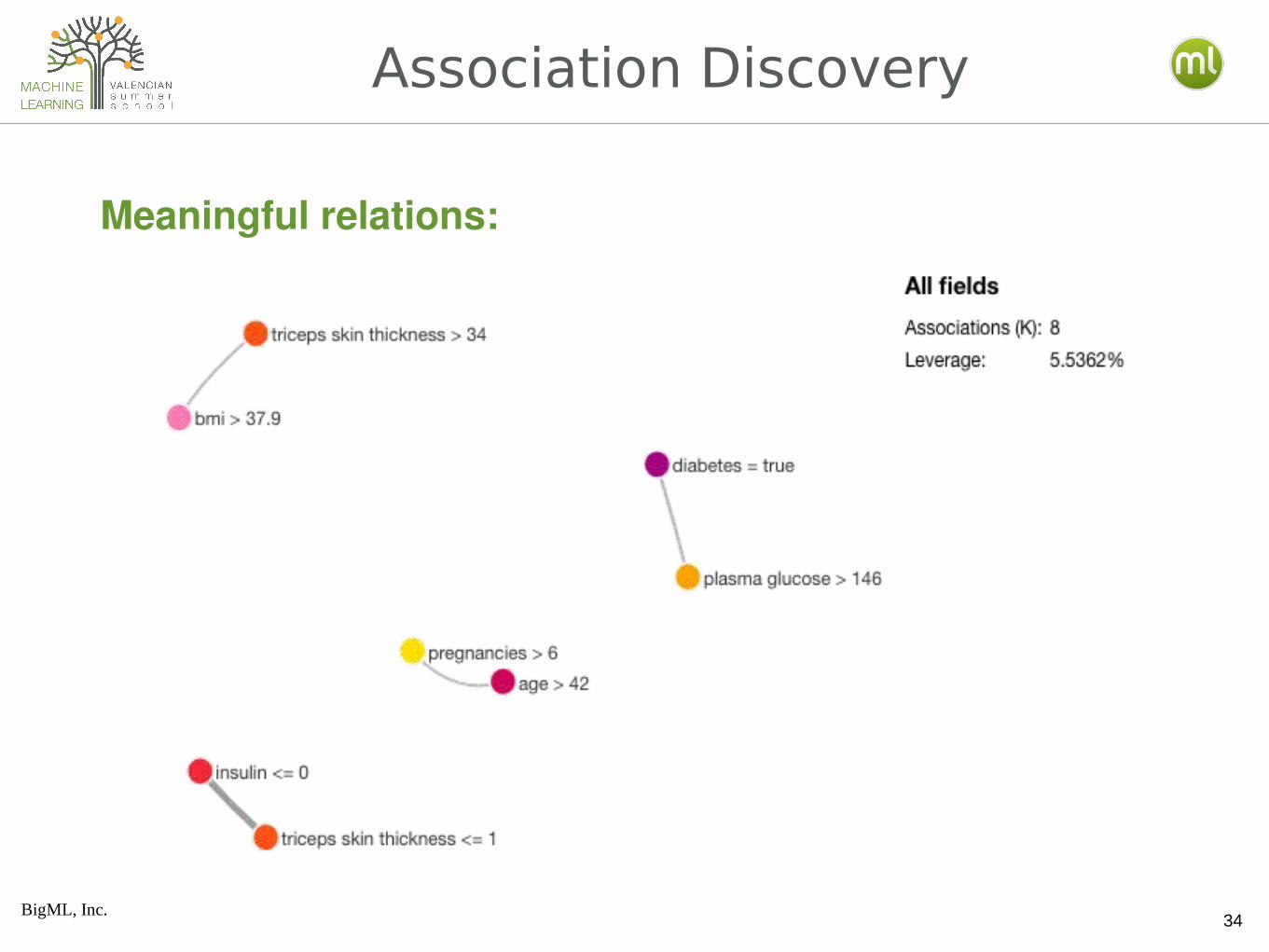
Association Discovery
Meaningful relations:

BigML, Inc.35
● Generative models try to fit the coefficients of a generic function to use it as data generating function. This conveys information about the structure of the model (looking for causality).
● Discriminative models, do not care about how the labeling is generated, they only find how to split the data into categories
● Generative models are more probabilistically sound and able to do more than just classify
● Discriminative models are faster to fit and quicker to predict
Latent Dirichlet Allocation
Generative vs discriminative modelsCharles Parker
Pros and Cons

BigML, Inc.36
A document can be analyzed from different levels● According to its terms (one or more words)● According to its topics (distributions of terms ~
semantics)
● Documents are generated by repeatedly drawing a topic and a term in that topic at random
● Goal: To infer the topic distribution
How? Dirichlet Process is used to model the term|topic, and topic|document distributions
Latent Dirichlet Allocation
Thinking of documents in terms of Topics
Generative Models for documents

BigML, Inc.37
● We're more likely to think a word came from a topic if we've already seen a bunch of other words from that topic
● We're more likely to think the topic was responsible for generating the document if we've already seen a bunch of words in the document from that topic.
● Visualizing topic changes in documents over time (specially for dated historical collections)
● Search by topics (without keywords)● Using topics as a new feature instead of the bag of
words approach in modeling
Latent Dirichlet Allocation
Dirichlet Process intuitions
Applications

BigML, Inc.38
● Topics can reduce the feature space● Are nicely interpretable● Automatically tailored to the document
● Need to choose the number of topics● Takes a lot of time to fit or do inference● Takes a lot of text to make it meaningful● Tends to focus on “meaningless minutiae”● While sometimes makes nice classifications, it's usually not a
dramatic improvement over bag-of-words● Nice for exploration
Latent Dirichlet Allocation
Nice properties about topics
Caveats


















