
VSSML16 L4. Association Discovery and Latent Dirichlet Allocation
48
September 8-9, 2016
-
Upload
bigml-inc -
Category
Data & Analytics
-
view
153 -
download
3
Transcript of VSSML16 L4. Association Discovery and Latent Dirichlet Allocation

September 8-9, 2016

BigML, Inc 2
Association Discovery
Geoff Webb Professor of Information Technology Research
Monash University, Melbourne, Australia
Finding interesting correlations

BigML, Inc 3Unsupervised Learning
• Algorithm: “Magnum Opus” from Geoff Webb • Unsupervised Learning: Works with unlabelled
data, like clustering and anomaly detection. • Learning Task: Find “interesting” relations
between variables.
Association Discovery

BigML, Inc 4Unsupervised Learning
Unsupervised Learning
date customer account auth class zip amountMon Bob 3421 pin clothes 46140 135Tue Bob 3421 sign food 46140 401Tue Alice 2456 pin food 12222 234Wed Sally 6788 pin gas 26339 94Wed Bob 3421 pin tech 21350 2459Wed Bob 3421 pin gas 46140 83The Sally 6788 sign food 26339 51
date customer account auth class zip amountMon Bob 3421 pin clothes 46140 135Tue Bob 3421 sign food 46140 401Tue Alice 2456 pin food 12222 234Wed Sally 6788 pin gas 26339 94Wed Bob 3421 pin tech 21350 2459Wed Bob 3421 pin gas 46140 83The Sally 6788 sign food 26339 51
Clustering
Anomaly Detection
similar
unusual

BigML, Inc 5Unsupervised Learning
{class = gas} amount < 100
Association Rules
date customer account auth class zip amountMon Bob 3421 pin clothes 46140 135Tue Bob 3421 sign food 46140 401Tue Alice 2456 pin food 12222 234Wed Sally 6788 pin gas 26339 94Wed Bob 3421 pin tech 21350 2459Wed Bob 3421 pin gas 46140 83The Sally 6788 sign food 26339 51
{customer = Bob, account = 3421} zip = 46140
Rules:
Antecedent Consequent

BigML, Inc 6Unsupervised Learning
Use Cases
• Market Basket Analysis
• Web usage patterns
• Intrusion detection
• Fraud detection
• Bioinformatics
• Medical risk factors

BigML, Inc 7Unsupervised Learning
Magnum OpusWhat's wrong with frequent pattern mining?

BigML, Inc 8Unsupervised Learning
Magnum OpusWhat's wrong with frequent pattern mining?
• Feast or famine• often results in too few or too many patterns
• The vodka and caviar problem• some high value patterns are infrequent
• Cannot handle dense data• Minimum support may not be relevant• cannot be low enough to capture all valid rules• cannot be high enough to exclude all spurious rules

BigML, Inc 9Unsupervised Learning
Magnum OpusVery infrequent patterns can be significant
Data file: Brijs retail.itl, 88162 cases / 16470 items237 → 1 [Coverage=3032; Support=28; Lift=3.06; p=1.99E-007]237 & 4685 → 1 [Coverage=19; Support=9; Lift=157.00; p=5.03E-012]1159 → 1 [Coverage=197; Support=9; Lift=15.14; p=1.13E-008]4685 → 1 [Coverage=270; Support=9; Lift=11.05; p=1.68E-007]168 → 1 [Coverage=293; Support=9; Lift=10.18; p=3.33E-007]4382 → 1 [Coverage=72; Support=8; Lift=36.83; p=6.26E-011]168 & 4685 → 1 [Coverage=9; Support=7; Lift=257.78; p=6.66E-011]

BigML, Inc 10Unsupervised Learning
Magnum OpusVery high support patterns can be spurious
Data file: covtype.data 581012 cases / 125 valuesST15=0 → ST07=0 [Coverage=581009; Support=580904; Confidence=1.000]ST07=0 → ST15=0 [Coverage=580907; Support=580904; Confidence=1.000]ST15=0 → ST36=0 [Coverage=581009; Support=580890; Confidence=1.000]ST36=0 → ST15=0 [Coverage=580893; Support=580890; Confidence=1.000]ST15=0 → ST08=0 [Coverage=581009; Support=580830; Confidence=1.000]ST08=0 → ST15=0 [Coverage=580833; Support=580830; Confidence=1.000]… 197,183,686 such rules have highest support

BigML, Inc 11Unsupervised Learning
Magnum Opus
• User selects measure of interest• System finds the top-k associations on that
measure within constraints • Must be statistically significant interaction between
antecedent and consequent• Every item in the antecedent must increase the
strength of association

BigML, Inc 12Unsupervised Learning
Association Metrics
Coverage
Percentage of instances which match antecedent “A”
Instances
AC

BigML, Inc 13Unsupervised Learning
Association Metrics
Support
Percentage of instances which match antecedent “A” and Consequent “C”
Instances
AC

BigML, Inc 14Unsupervised Learning
Association Metrics
Confidence
Percentage of instances in the antecedent which also contain the consequent.
Coverage
Support
Instances
AC

BigML, Inc 15Unsupervised Learning
Association Metrics
CInstances
A C
A
Instances
C
Instances
A
Instances
AC
0% 100%
Instances
AC
Confidence
A never implies C
A sometimes implies C
A always implies C

BigML, Inc 16Unsupervised Learning
Association Metrics
Lift
Ratio of observed support to support if A and C were statistically independent.
Support == Confidence p(A) * p(C) p(C)
Independent
AC
C
Observed
A

BigML, Inc 17Unsupervised Learning
Association Metrics
C
Observed
A
Observed
AC
< 1 > 1
Independent
A C
Lift = 1
Negative Correlation No Association Positive
Correlation
Independent
A C
Independent
A C
Observed
A C

BigML, Inc 18Unsupervised Learning
Association Metrics
Leverage
Difference of observed support and support if A and C were statistically independent.
Support - [ p(A) * p(C) ]
Independent
AC
C
Observed
A

BigML, Inc 19Unsupervised Learning
Association Metrics
C
Observed
A
Observed
AC
< 0 > 0
Independent
A C
Leverage = 0
NegativeCorrelation No Association Positive
Correlation
Independent
A C
Independent
A C
Observed
A C
-1…

BigML, Inc 20Unsupervised Learning
Use Cases
GOAL: Discover “interesting” rules about what store items
are typically purchased together.
• Dataset of 9,834 grocery cart transactions
• Each row is a list of all items in a cart at checkout

BigML, Inc 21Unsupervised Learning
Association Discovery Demo #1

BigML, Inc 22Unsupervised Learning
Use Cases
GOAL: Find general rules that indicate diabetes.
• Dataset of diagnostic measurements of 768 patients.
• Each patient labelled True/False for diabetes.

BigML, Inc 23Unsupervised Learning
Association Discovery Demo #2

BigML, Inc 24Unsupervised Learning
Medical RisksDecision Tree
If plasma glucose > 155 and bmi > 29.32 and diabetes pedigree > 0.32 and insulin <= 629 and age <= 44
then diabetes = TRUE
Association Rule
If plasma glucose > 146 then diabetes = TRUE

Latent Dirichlet Allocation
#VSSML16
September 2016
#VSSML16 Latent Dirichlet Allocation September 2016 1 / 24

Outline
1 Understanding the Limits of Simple Text Analysis
2 Aside: Generative Processes
3 Latent Dirichlet Allocation
4 A Couple of Instructive Examples
5 Applications
#VSSML16 Latent Dirichlet Allocation September 2016 2 / 24

Outline
1 Understanding the Limits of Simple Text Analysis
2 Aside: Generative Processes
3 Latent Dirichlet Allocation
4 A Couple of Instructive Examples
5 Applications
#VSSML16 Latent Dirichlet Allocation September 2016 3 / 24

Bag of Words Analysis
• Easiest way of analyzing a textfield is just to treat it as a “bagof words”
• Each word is a separatefeature (usually an occurrencecount)
• When modeling, the featuresare treated in isolation fromone another, essentially “oneat a time”
#VSSML16 Latent Dirichlet Allocation September 2016 4 / 24

Limitations
• Words are sometimesambiguous
• Both because of multipledefinitions and difference intone
• How do we usuallydisambiguate words? Context
#VSSML16 Latent Dirichlet Allocation September 2016 5 / 24

An Instructive Example
• One way of looking at the usefulness of a machine learningfeature is to think about how well it isolates unique and coherentsubsets of the data
• Suppose I have a collection of documents where some of themare about two different topics (via Ted Underwood’s Blog):
I Leadership (CEOs, organization, management)I Chemistry (Elements, compounds, reactions)
• If I do a keyword search for “lead” (or try to classify documentsbased on that word alone), I’ll get documents from either categoryand documents that are a mix of both
• Can we build a feature that better isolates which set of documentswe’re looking for?
#VSSML16 Latent Dirichlet Allocation September 2016 6 / 24

Outline
1 Understanding the Limits of Simple Text Analysis
2 Aside: Generative Processes
3 Latent Dirichlet Allocation
4 A Couple of Instructive Examples
5 Applications
#VSSML16 Latent Dirichlet Allocation September 2016 7 / 24

Generative Modeling
• Posit a parameterized structure that is responsible for generatingthe data
• Use the data to fit the parameters
• A notion of causality is important for these models
#VSSML16 Latent Dirichlet Allocation September 2016 8 / 24
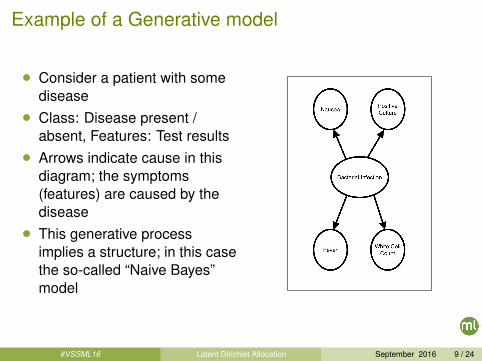
Example of a Generative model
• Consider a patient with somedisease
• Class: Disease present /absent, Features: Test results
• Arrows indicate cause in thisdiagram; the symptoms(features) are caused by thedisease
• This generative processimplies a structure; in this casethe so-called “Naive Bayes”model
#VSSML16 Latent Dirichlet Allocation September 2016 9 / 24

Generative vs. Discriminative
• This is an important distinction in machine learning generally
• Generative models try to model / assume a structure for theprocess generating the data
• More mathematically, generative classifiers explicitly model thejoint distribution p(x, y) of the data
• Discriminate models don’t care; they “solve the prediction problemdirectly”, and model only the conditional p(y|x) (Vapnik)
#VSSML16 Latent Dirichlet Allocation September 2016 10 / 24

Which is Better?
• No general answer to this question (not that we haven’t tried):Paper: On Discriminative vs. Generative Classifiers1
• Discriminative models tend to be faster to fit, quicker to predict,and in the case of non-parametrics are often guaranteed toconverge to the correct answer given enough data
• Generative models tend to be more probabilistically sound andable to do more than just classify
1http:
//ai.stanford.edu/~ang/papers/nips01-discriminativegenerative.pdf
#VSSML16 Latent Dirichlet Allocation September 2016 11 / 24

Outline
1 Understanding the Limits of Simple Text Analysis
2 Aside: Generative Processes
3 Latent Dirichlet Allocation
4 A Couple of Instructive Examples
5 Applications
#VSSML16 Latent Dirichlet Allocation September 2016 12 / 24

A New Way of Thinking About Documents
• Three entities: Documents,Terms, and Topics
• A term is a single lexical token(usually one or more words,but can be any arbitrary string)
• A document has many terms
• A topic is a distribution over
terms
#VSSML16 Latent Dirichlet Allocation September 2016 13 / 24

A Generative Model for Documents
• A document can be thought of as a distribution over topics, drawnfrom a distribution over possible distributions
• To create a document, repeatedly draw a topic at random from thedistribution, then draw a term from topic (which, remember, is adistribution over terms)
• The main thing we want to infer is the topic distribution
#VSSML16 Latent Dirichlet Allocation September 2016 14 / 24

Dirichlet Process Intuition: Rich Get Richer
• We use a Dirichlet process to model the relationship betweendocuments, topics, and terms
• We’re more likely to think a word came from a topic if we’vealready seen a bunch of words from that topic
• We’re more likely to think the topic was responsible for generatingthe document if we’ve already seen a bunch of words in thedocument from that topics.
• Here lies the disambiguation: If a word could have come from twodifferent topics, we use the rest of the words in the document todecide which meaning it has
• Note that there’s a little bit of self-fulfilling prophecy going on here(by design)
#VSSML16 Latent Dirichlet Allocation September 2016 15 / 24

Outline
1 Understanding the Limits of Simple Text Analysis
2 Aside: Generative Processes
3 Latent Dirichlet Allocation
4 A Couple of Instructive Examples
5 Applications
#VSSML16 Latent Dirichlet Allocation September 2016 16 / 24

Usenet Movie Reviews
Library of over 26,000 movie reviews
A solid noir melodrama from Vincent Sherman, who takes a standardstory and dresses it up with moving characterizations and beautifullyexpressionistic B&W; photography from cinematographer James Wong Howe.The director took a songwriter Paul Webster's short magazine storycalled "The Man Who Died Twice" and improved the story by rounding outthe characters to give them both strong and weak points, so that theywould not be one-note characters as was the case in the originalstory. The film was made by Warner Brothers, who needed a film fortheir contract star Ann Sheridan and asked Sherman to change the storyaround so that her part as Nora Prentiss, a nightclub singer, isexpanded
#VSSML16 Latent Dirichlet Allocation September 2016 17 / 24

Supreme Court Cases
Library of about 7500 Supreme Court Cases
NO. 136. ARGUED DECEMBER 6, 1966. - DECIDED JANUARY 9, 1967. - 258 F.SUPP. 819, REVERSED.
FOLLOWING THIS COURT'S DECISIONS IN SWANN V. ADAMS, INVALIDATING THEAPPORTIONMENT OF THE FLORIDA LEGISLATURE (378 U.S. 553) AND THESUBSEQUENT REAPPORTIONMENT WHICH THE DISTRICT COURT HAD FOUNDUNCONSTITUTIONAL BUT APPROVED ON AN INTERIM BASIS (383 U.S. 210), THEFLORIDA LEGISLATURE ADOPTED STILL ANOTHER LEGISLATIVE REAPPORTIONMENTPLAN, WHICH APPELLANTS, RESIDENTS AND VOTERS OF DADE COUNTY, FLORIDA,ATTACKED AS FAILING TO MEET THE STANDARDS OF VOTER EQUALITY SET FORTH
#VSSML16 Latent Dirichlet Allocation September 2016 18 / 24

Outline
1 Understanding the Limits of Simple Text Analysis
2 Aside: Generative Processes
3 Latent Dirichlet Allocation
4 A Couple of Instructive Examples
5 Applications
#VSSML16 Latent Dirichlet Allocation September 2016 19 / 24
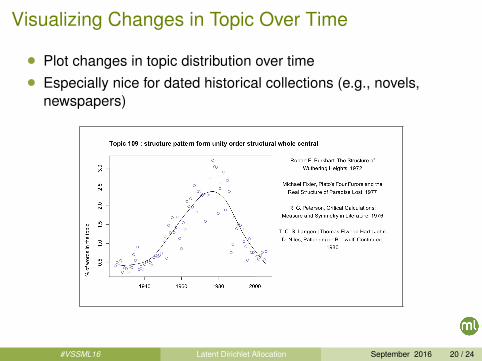
Visualizing Changes in Topic Over Time
• Plot changes in topic distribution over time
• Especially nice for dated historical collections (e.g., novels,newspapers)
#VSSML16 Latent Dirichlet Allocation September 2016 20 / 24

Search Without Keywords
• Keyword search is great, if youknow the keywords
• Good for finding search terms
• Great for, e.g., legal discovery
• Nice for finding “outliers”
• Surprise topics (From therecycle bin)
#VSSML16 Latent Dirichlet Allocation September 2016 21 / 24

Feature Spaces for Classification
• Just classify the documents in “topic space” rather than “bagspace”
• The topics that come out of LDA have some nice benefits asfeatures
I Can reduce a feature space of thousands to a few dozen (faster tofit)
I Nicely interpretableI Automatically tailored to the documents you’ve provided
• Foreshadowing Alert: When using LDA in this way, we’re doing aform of feature engineering which we’ll hear more about tomorrow.
#VSSML16 Latent Dirichlet Allocation September 2016 22 / 24

Some Caveats
• You need to choose the number of topics beforehand
• Takes forever, both to fit and to do inference
• Takes a lot of text to make it meaningful
• Tends to focus on “meaningless minutiae”
• While it sometimes makes a nice classification space, it’s a rarecase that provides dramatic improvement over bag-of-words
• I find it nice just for exploration
#VSSML16 Latent Dirichlet Allocation September 2016 23 / 24

Thus Ends The Lesson
Questions?
#VSSML16 Latent Dirichlet Allocation September 2016 24 / 24


















