
UNIFIED MEMORY ON PASCAL AND...
70
1 Nikolay Sakharnykh - May 10, 2017 UNIFIED MEMORY ON PASCAL AND VOLTA
Transcript of UNIFIED MEMORY ON PASCAL AND...

1
Nikolay Sakharnykh - May 10, 2017
UNIFIED MEMORY ON PASCAL AND VOLTA

2
HETEROGENEOUS ARCHITECTURES
GPU 0
MEM
CPU
SYS MEM
GPU 0
GPU 1
MEM
GPU 1
GPU 2
MEM
GPU 2

3
UNIFIED MEMORY FUNDAMENTALSSingle Pointer
CPU code GPU code
void *data;data = malloc(N);
cpu_func1(data, N);
cpu_func2(data, N);
cpu_func3(data, N);
free(data);
void *data;data = malloc(N);
cpu_func1(data, N);
gpu_func2<<<...>>>(data, N);cudaDeviceSynchronize();
cpu_func3(data, N);
free(data);

4
UNIFIED MEMORY FUNDAMENTALSSingle Pointer
Explicit Memory Management
Unified Memory
void *h_data, *d_data;h_data = malloc(N);cudaMalloc(&d_data, N);cpu_func1(h_data, N);cudaMemcpy(d_data, h_data, N, ...)gpu_func2<<<...>>>(data, N);
cudaMemcpy(h_data, d_data, N, ...)cpu_func3(h_data, N);
free(h_data);cudaFree(d_data);
void *data;data = malloc(N);
cpu_func1(data, N);
gpu_func2<<<...>>>(data, N);cudaDeviceSynchronize();
cpu_func3(data, N);
free(data);

5
UNIFIED MEMORY FUNDAMENTALSDeep Copy Nightmare
Explicit Memory Management
Unified Memory
char **data;data = (char**)malloc(N*sizeof(char*));for (int i = 0; i < N; i++)
data[i] = (char*)malloc(N);
char **d_data;char **h_data = (char**)malloc(N*sizeof(char*));for (int i = 0; i < N; i++) {
cudaMalloc(&h_data2[i], N);cudaMemcpy(h_data2[i], h_data[i], N, ...);
}cudaMalloc(&d_data, N*sizeof(char*));cudaMemcpy(d_data, h_data2, N*sizeof(char*), ...);
gpu_func<<<...>>>(data, N);
char **data;data = (char**)malloc(N*sizeof(char*));for (int i = 0; i < N; i++)
data[i] = (char*)malloc(N);
gpu_func<<<...>>>(data, N);
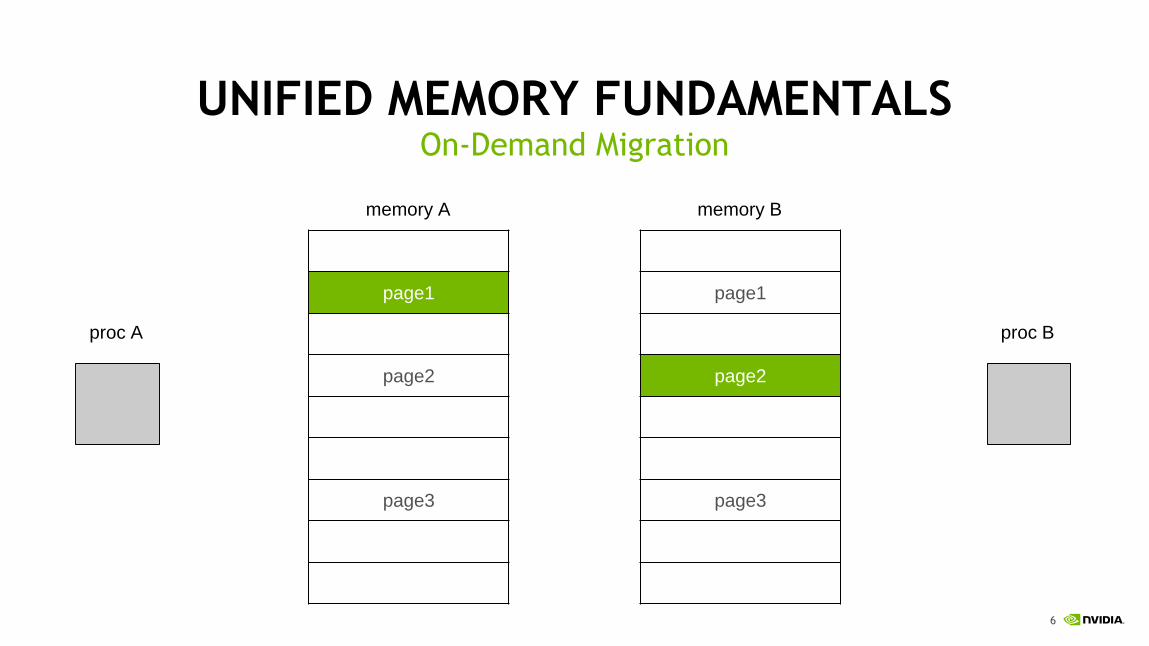
6
UNIFIED MEMORY FUNDAMENTALSOn-Demand Migration
page1
page2
page3
page1
page2
page3
proc A proc B
memory A memory B
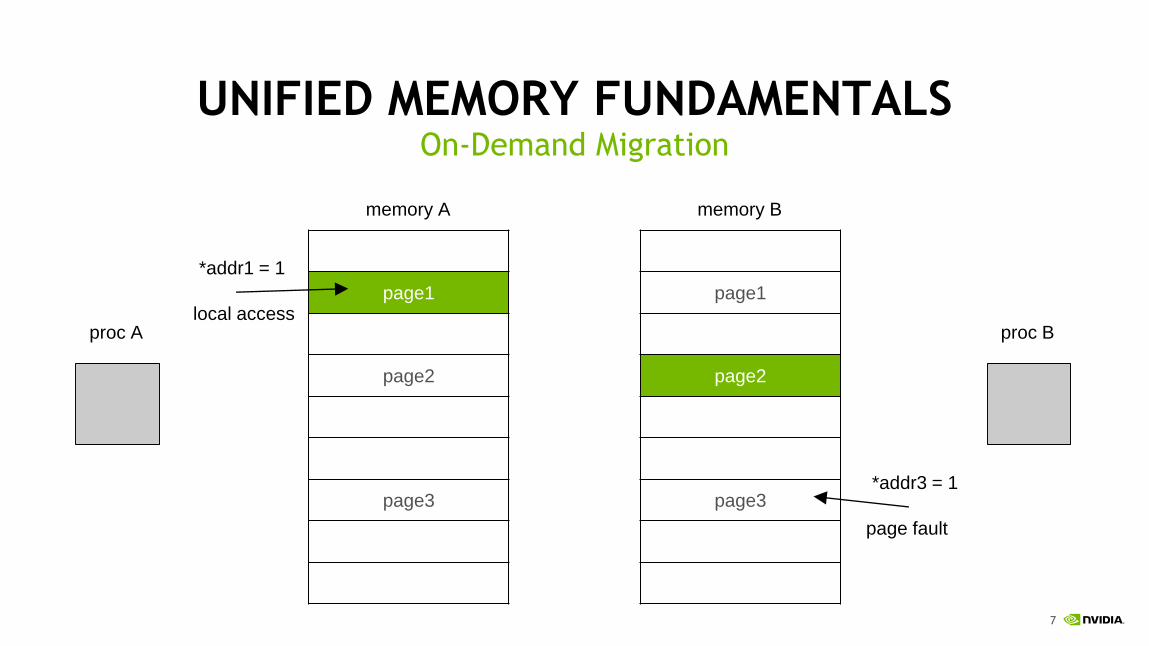
7
UNIFIED MEMORY FUNDAMENTALSOn-Demand Migration
page1
page2
page3
page1
page2
page3
*addr1 = 1
local access
*addr3 = 1
page fault
proc A proc B
memory A memory B
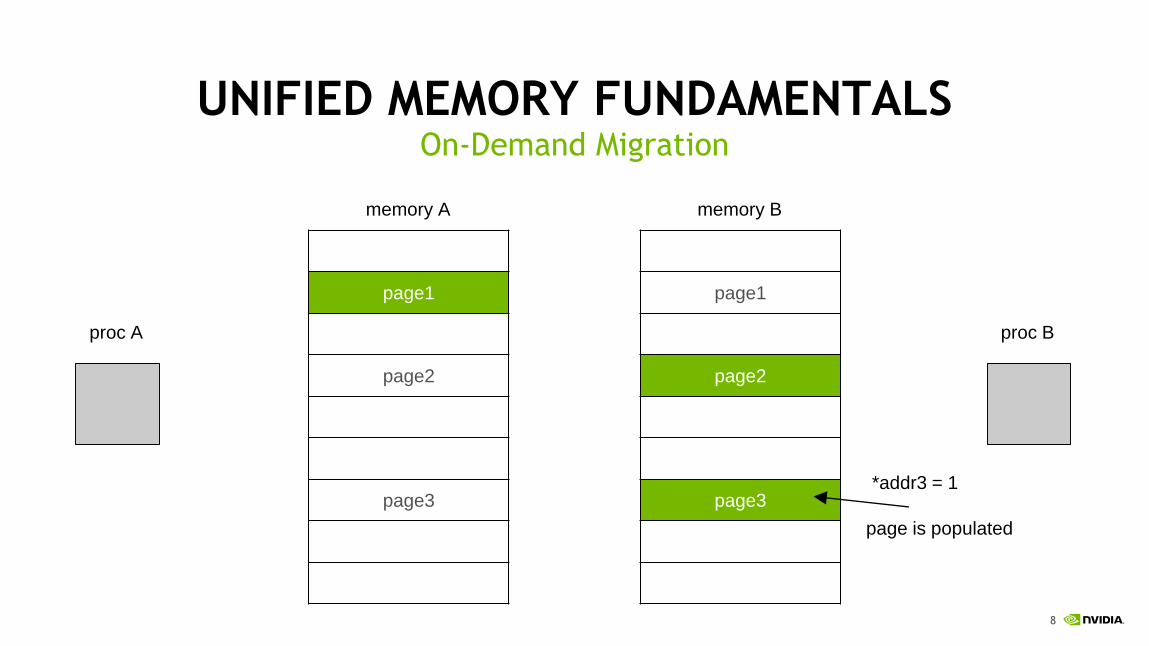
8
UNIFIED MEMORY FUNDAMENTALSOn-Demand Migration
page1
page2
page3
page1
page2
page3*addr3 = 1
page is populated
proc A proc B
memory A memory B
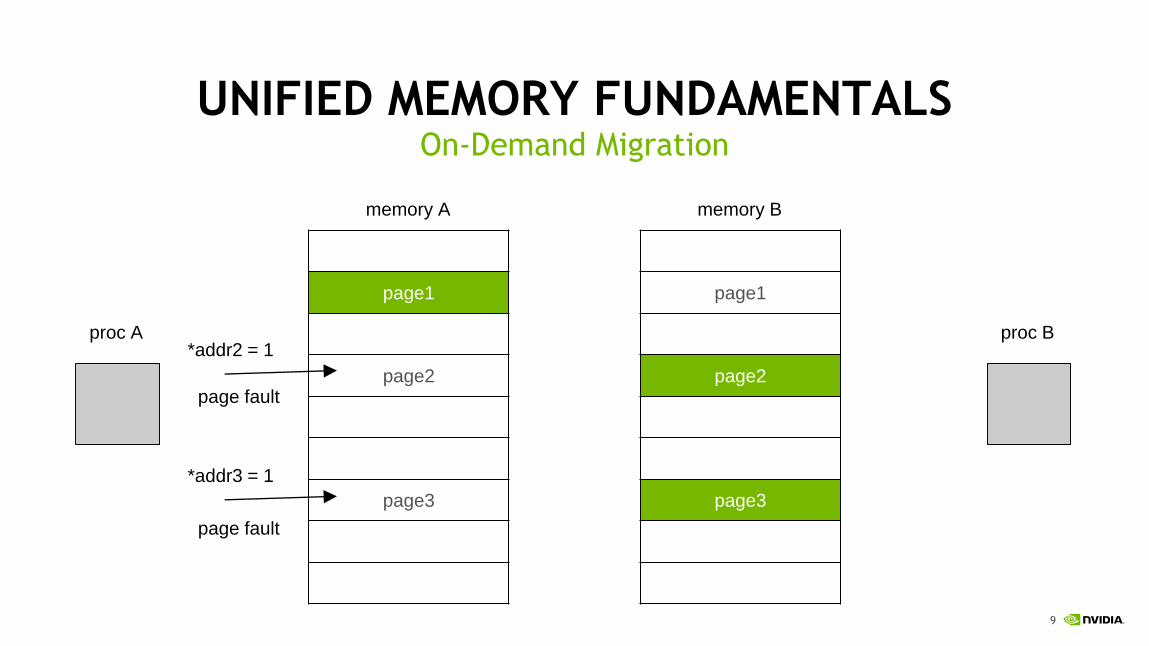
9
UNIFIED MEMORY FUNDAMENTALSOn-Demand Migration
page1
page2
page3
page1
page2
page3
*addr2 = 1
*addr3 = 1
page fault
page fault
proc A proc B
memory A memory B

10
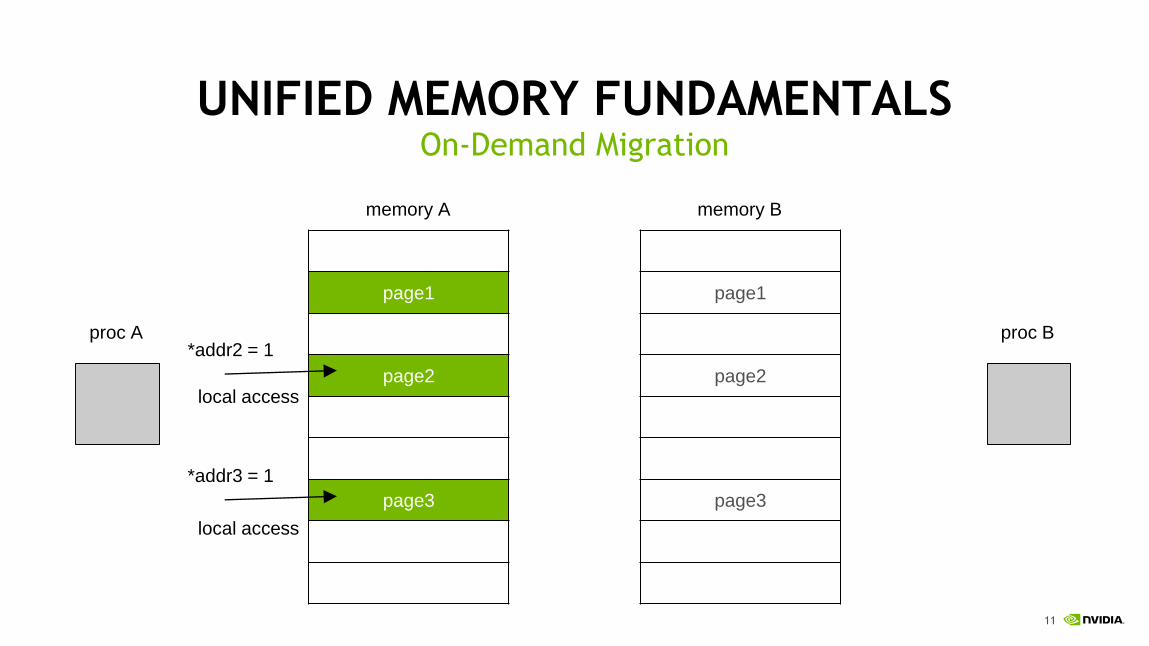
UNIFIED MEMORY FUNDAMENTALSOn-Demand Migration
page1
page2
page3
page1
page2
page3
*addr2 = 1
*addr3 = 1
page migration
page migrationpage fault
page fault
proc A proc B
memory A memory B
11
UNIFIED MEMORY FUNDAMENTALSOn-Demand Migration
page1
page2
page3
page1
page2
page3
proc A proc B*addr2 = 1
*addr3 = 1
local access
local access
memory A memory B

12
UNIFIED MEMORY FUNDAMENTALS
When it doesn’t matter how data moves to a processor
1) Quick and dirty algorithm prototyping
2) Iterative process with lots of data reuse, migration cost can be amortized
3) Simplify application debugging
When it’s difficult to isolate the working set
1) Irregular or dynamic data structures, unpredictable access
2) Data partitioning between multiple processors
When Is This Helpful?
13
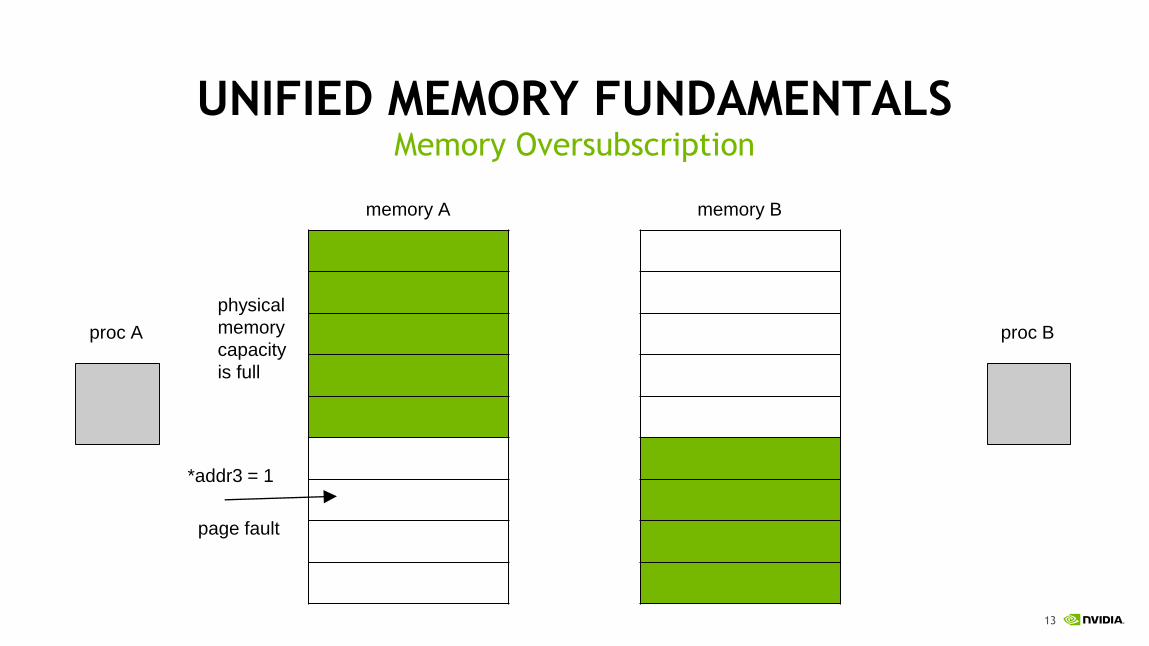
UNIFIED MEMORY FUNDAMENTALSMemory Oversubscription
proc A proc B
*addr3 = 1
page fault
physical
memory
capacity
is full
memory A memory B
14
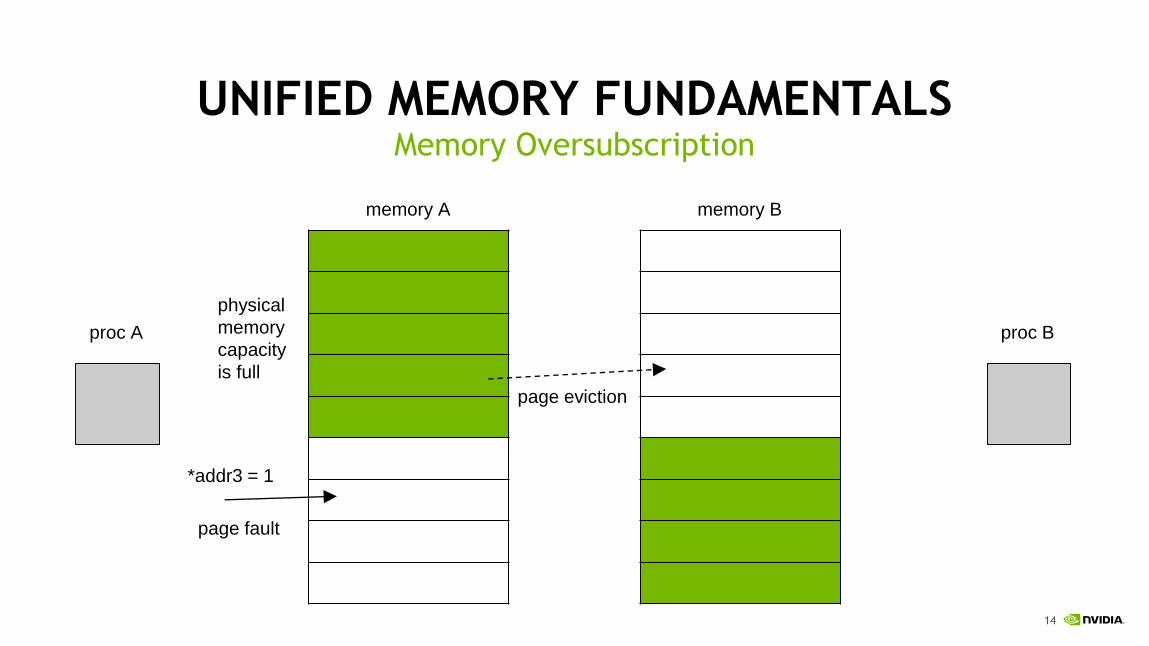
UNIFIED MEMORY FUNDAMENTALSMemory Oversubscription
proc A proc B
*addr3 = 1
page fault
page eviction
physical
memory
capacity
is full
memory A memory B
15
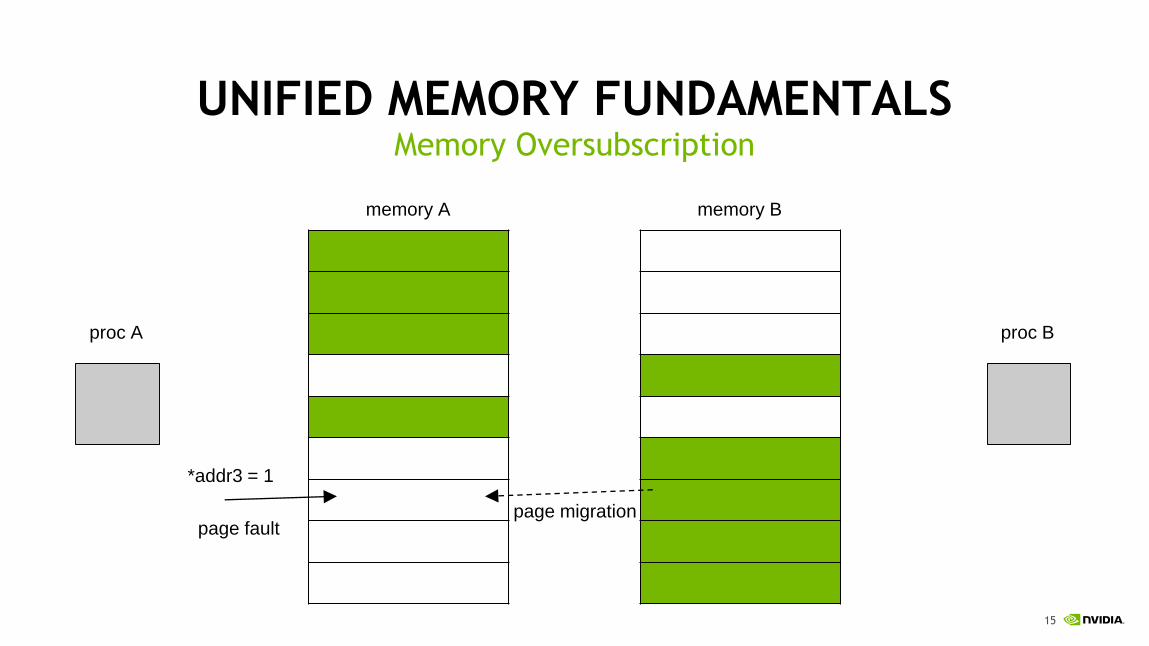
UNIFIED MEMORY FUNDAMENTALSMemory Oversubscription
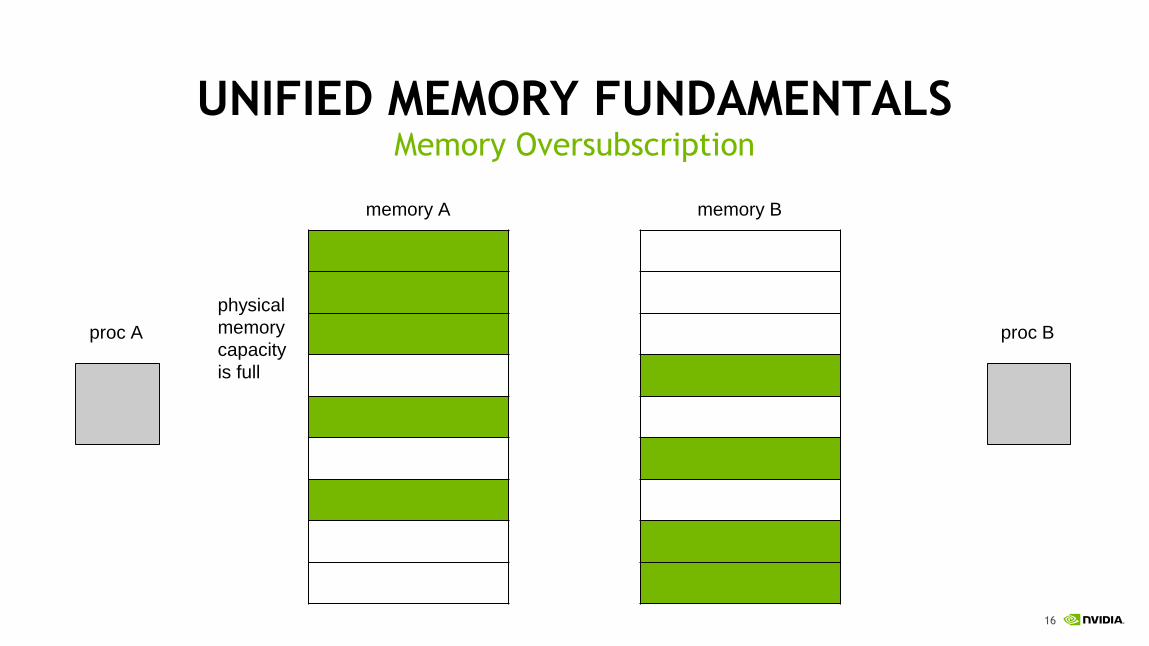
proc A proc B
*addr3 = 1
page faultpage migration
memory A memory B
16
UNIFIED MEMORY FUNDAMENTALSMemory Oversubscription
proc A proc B
physical
memory
capacity
is full
memory A memory B

17
UNIFIED MEMORY FUNDAMENTALS
When you have large dataset and not enough physical memory
Moving pieces by hand is error-prone and requires tuning for memory size
Better to run slowly than get fail with out-of-memory error
You can actually get high performance with Unified Memory!
Memory Oversubscription Benefits
18
UNIFIED MEMORY FUNDAMENTALSSystem-Wide Atomics with Exclusive Access
page1
page2
page3
page1
page2
page3
memory A memory B
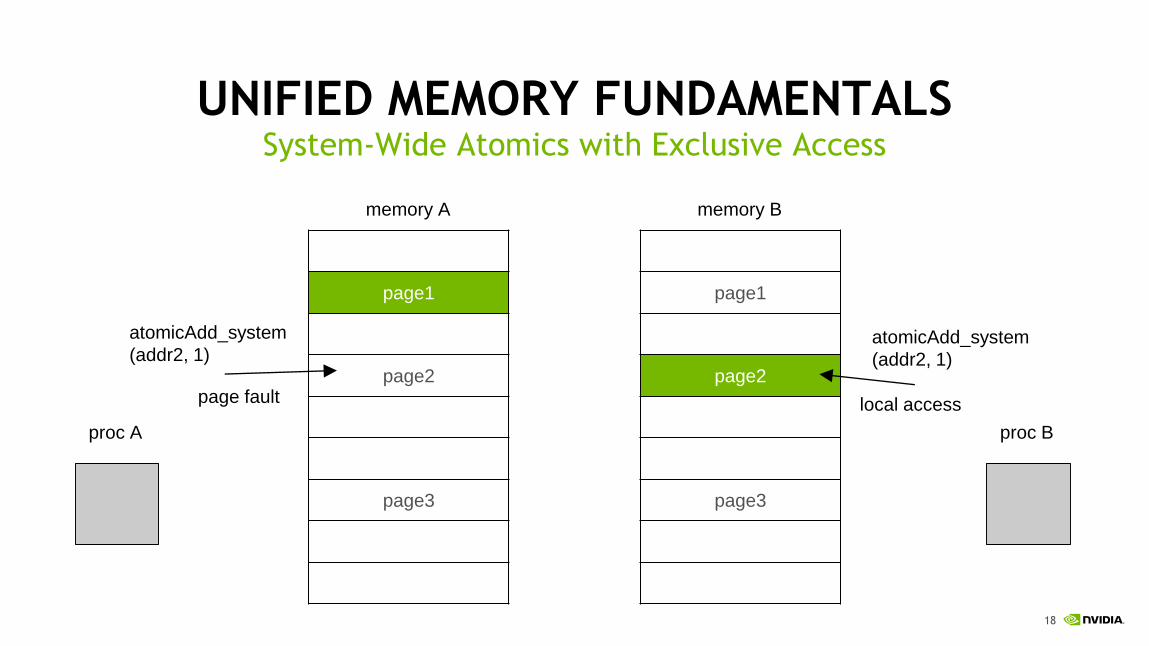
proc A proc B
atomicAdd_system
(addr2, 1)
page fault local access
atomicAdd_system
(addr2, 1)
19
UNIFIED MEMORY FUNDAMENTALSSystem-Wide Atomics with Exclusive Access
page1
page2
page3
page1
page2
page3
memory A memory B
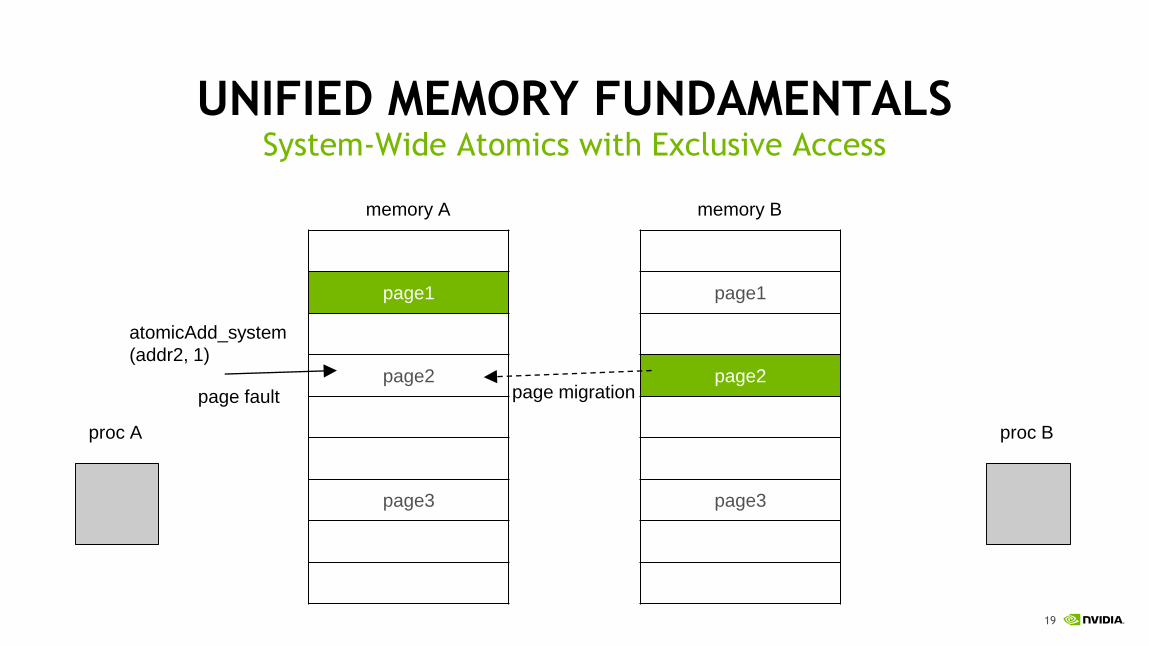
atomicAdd_system
(addr2, 1)
page fault page migration
proc A proc B
20
UNIFIED MEMORY FUNDAMENTALSSystem-Wide Atomics with Exclusive Access
page1
page2
page3
page1
page2
page3
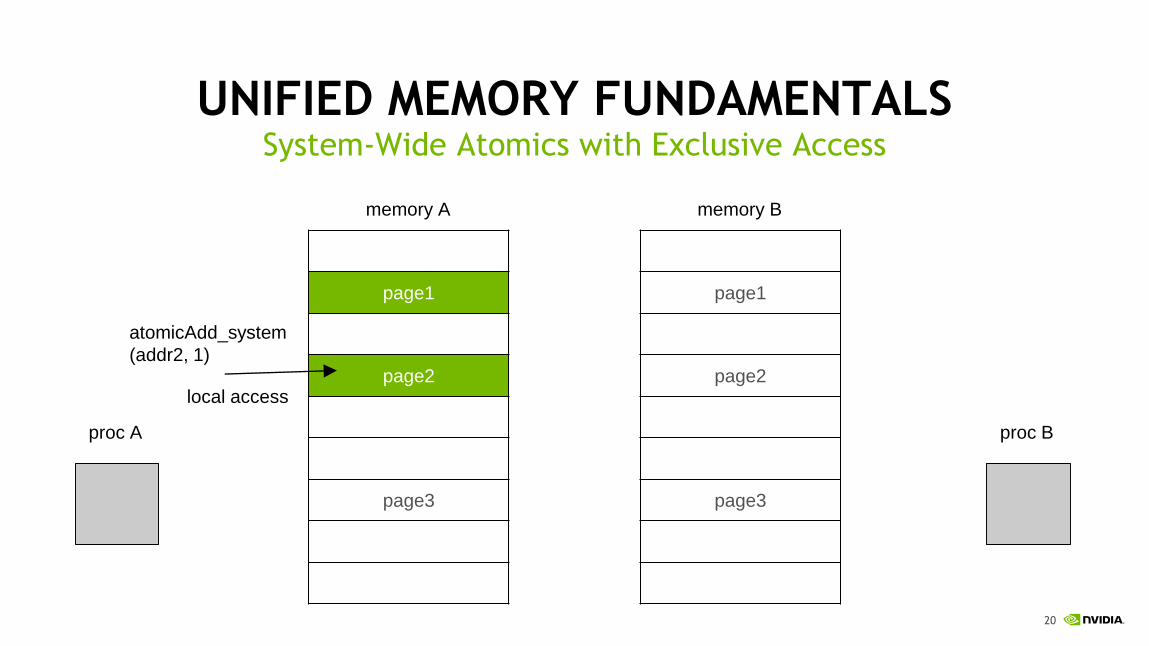
memory A memory B
local access
proc A proc B
atomicAdd_system
(addr2, 1)
21
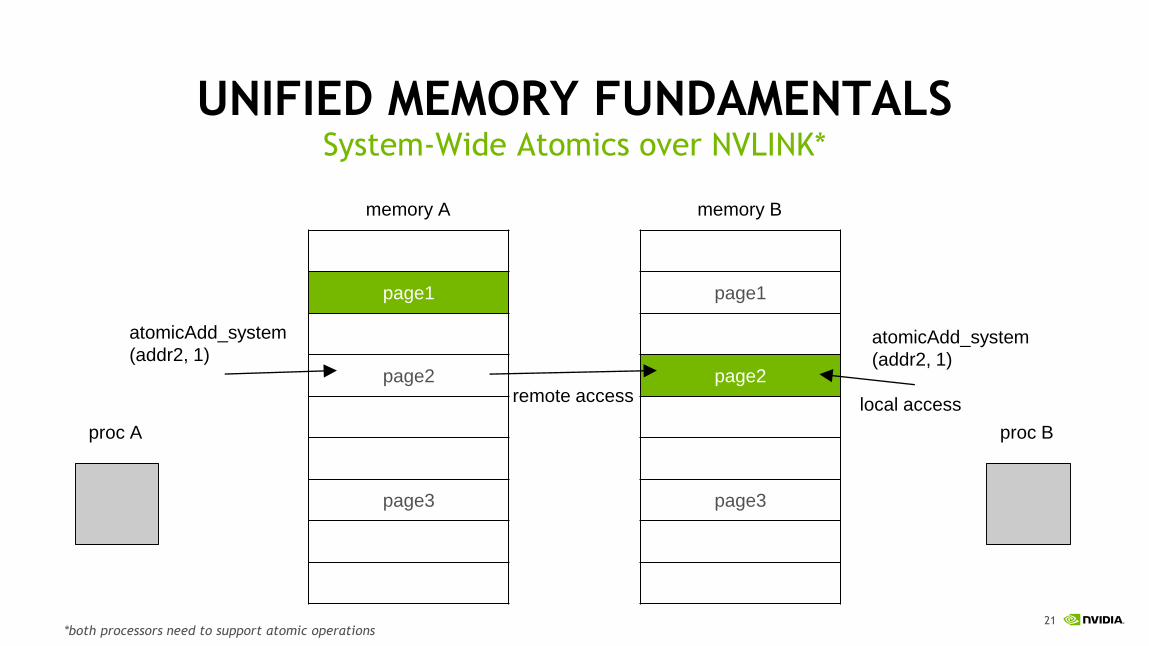
UNIFIED MEMORY FUNDAMENTALSSystem-Wide Atomics over NVLINK*
page1
page2
page3
page1
page2
page3
memory A memory B
remote access local access
proc A proc B
atomicAdd_system
(addr2, 1)
atomicAdd_system
(addr2, 1)
*both processors need to support atomic operations

22
UNIFIED MEMORY FUNDAMENTALS
GPUs are very good at handling atomics from thousands of threads
Makes sense to utilize atomics between GPUs or between CPU and GPU
We will see this in action on a realistic example later on
System-Wide Atomics

23
AGENDA
Unified Memory Fundamentals
Under the Hood Details
Performance Analysis and Optimizations
Applications Deep Dive

24
UNIFIED MEMORY ALLOCATOR
CUDA C: cudaMallocManaged is your most reliable way to opt in today
CUDA Fortran: managed attribute (per allocation)
OpenACC: -ta=managed compiler option (all dynamic allocations)
malloc support is coming on Pascal+ architectures (Linux only)
Note: you can write your own malloc hook to use cudaMallocManaged
Available Options

25
HETEROGEENOUS MEMORY MANAGER
Heterogeneous Memory Manager: a set of Linux kernel patches
Allows GPUs to access all system memory (malloc, stack, file system)
Page migration will be triggered the same way as for cudaMallocManaged
Ongoing testing and reviews, planning next phase of optimizations
More details on HMM today at 4:00 in Room 211B by John Hubbard
Work In Progress
26
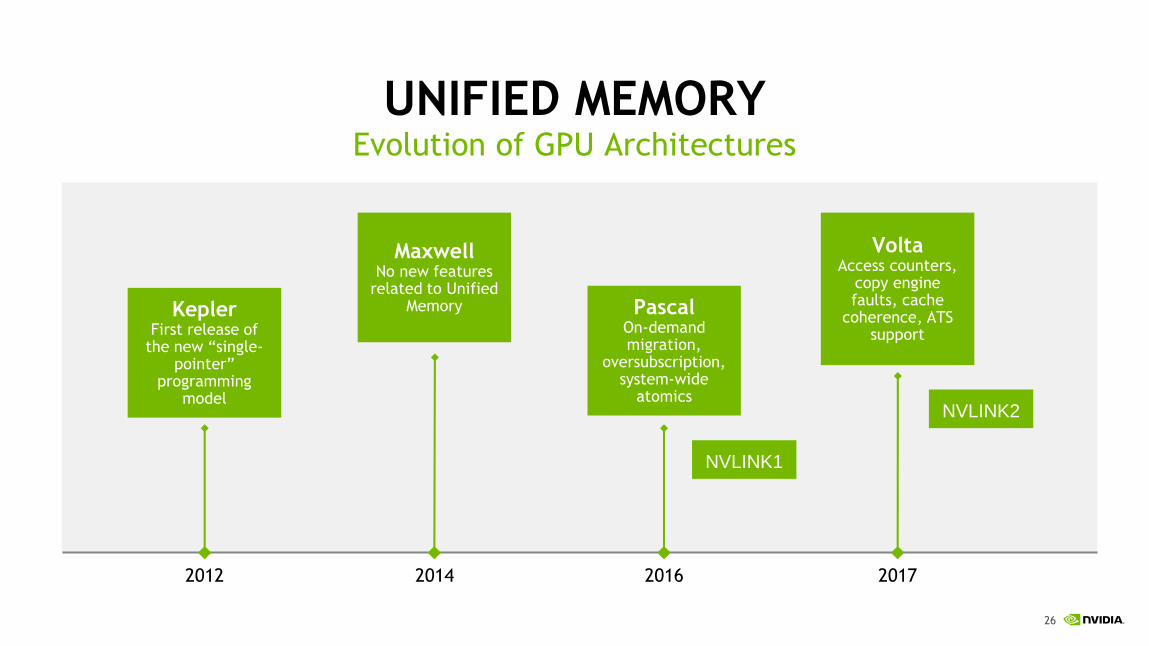
UNIFIED MEMORYEvolution of GPU Architectures
2012 2014 2016 2017
KeplerFirst release of
the new “single-pointer”
programming model
MaxwellNo new features
related to Unified Memory Pascal
On-demand migration,
oversubscription, system-wide
atomics
VoltaAccess counters,
copy engine faults, cache
coherence, ATS support
NVLINK1
NVLINK2
27
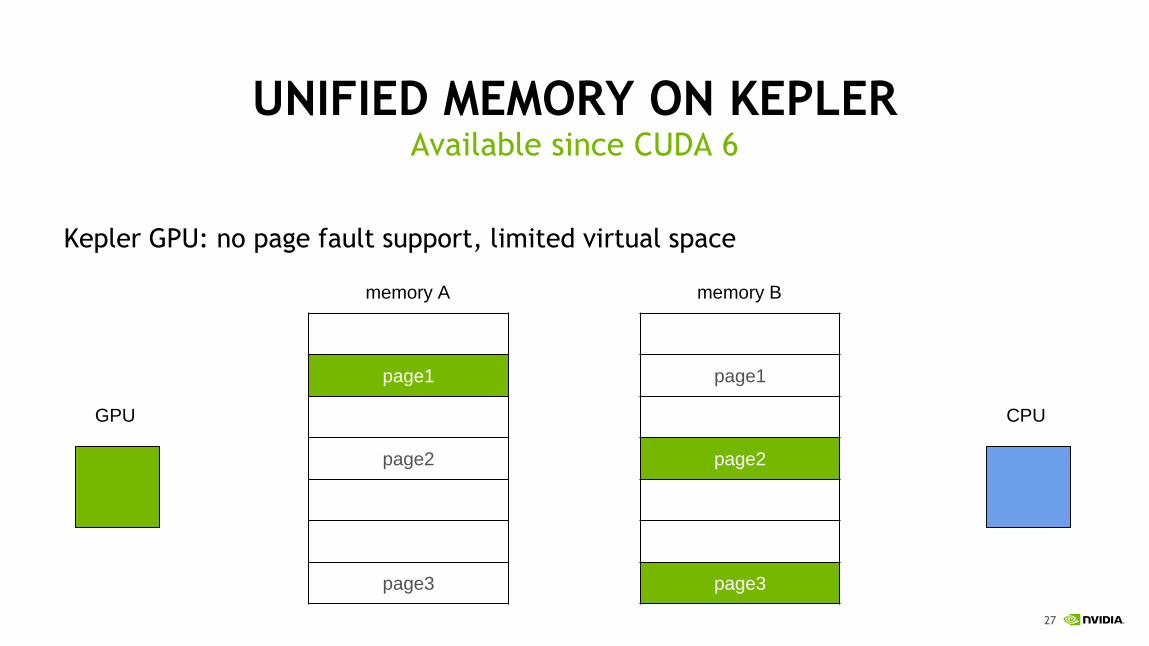
UNIFIED MEMORY ON KEPLER
Kepler GPU: no page fault support, limited virtual space
Available since CUDA 6
page1
page2
page3
page1
page2
page3
memory A memory B
GPU CPU
28
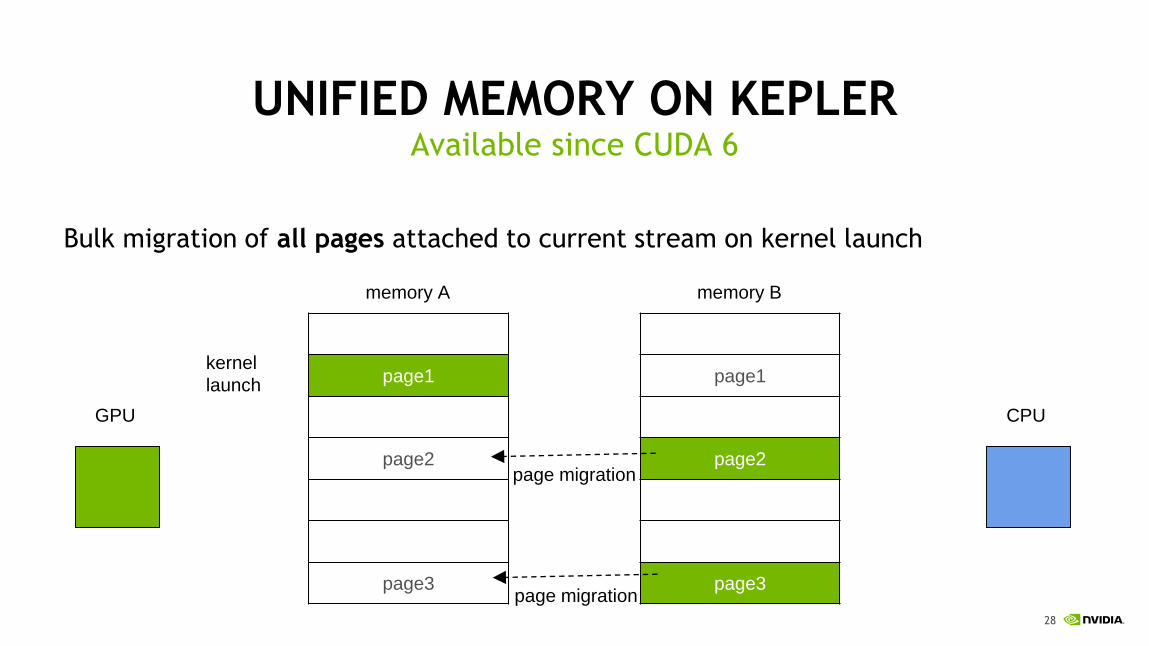
UNIFIED MEMORY ON KEPLER
Bulk migration of all pages attached to current stream on kernel launch
Available since CUDA 6
page1
page2
page3
page1
page2
page3
memory A memory B
kernel
launch
page migration
page migration
GPU CPU
29
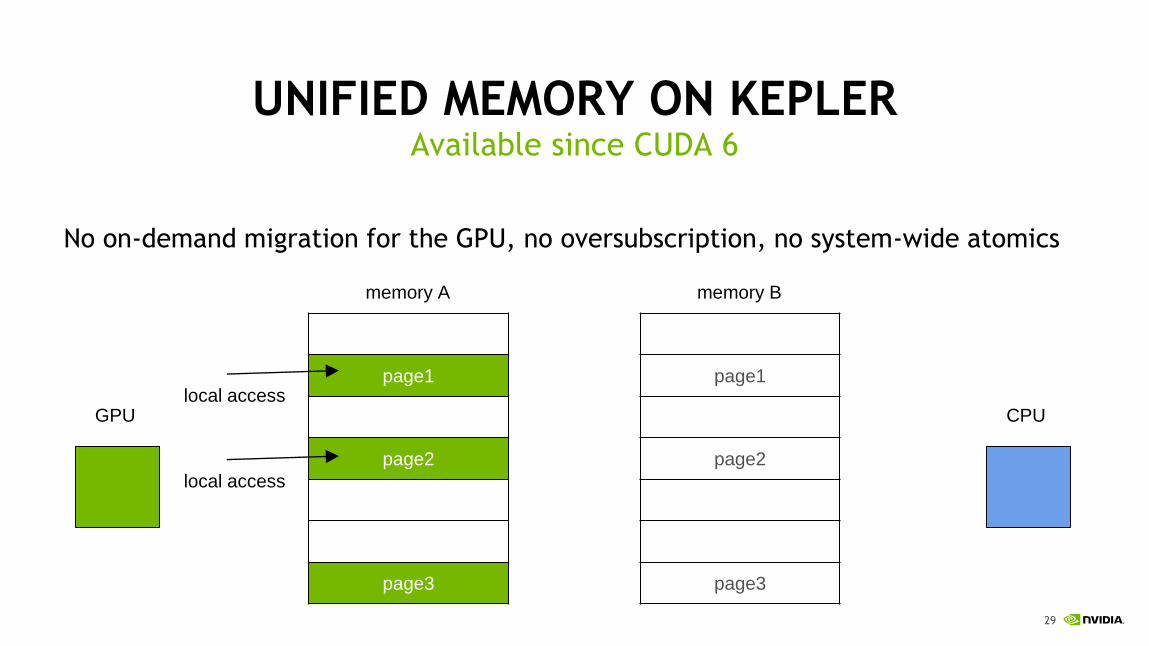
UNIFIED MEMORY ON KEPLER
No on-demand migration for the GPU, no oversubscription, no system-wide atomics
Available since CUDA 6
page1
page2
page3
page1
page2
page3
memory A memory B
local accessGPU CPU
local access

30
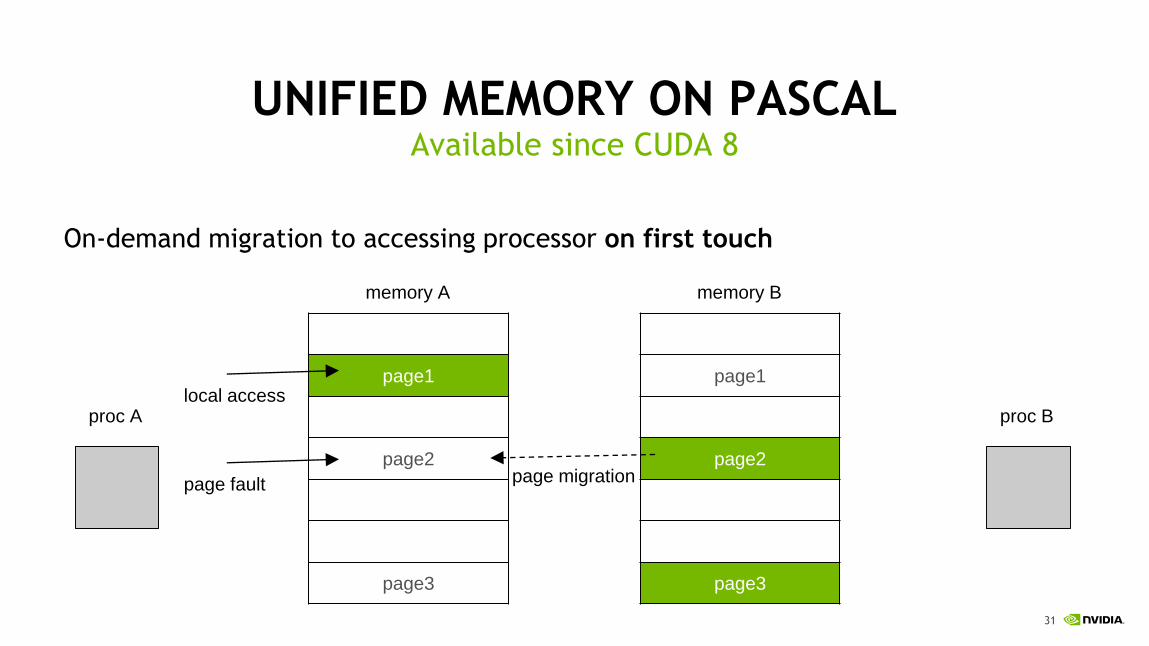
UNIFIED MEMORY ON PASCAL
Pascal GPU: page fault support, extended virtual address space (48-bit)
Available since CUDA 8
page1
page2
page3
page1
page2
page3
memory A memory B
proc A proc B
31
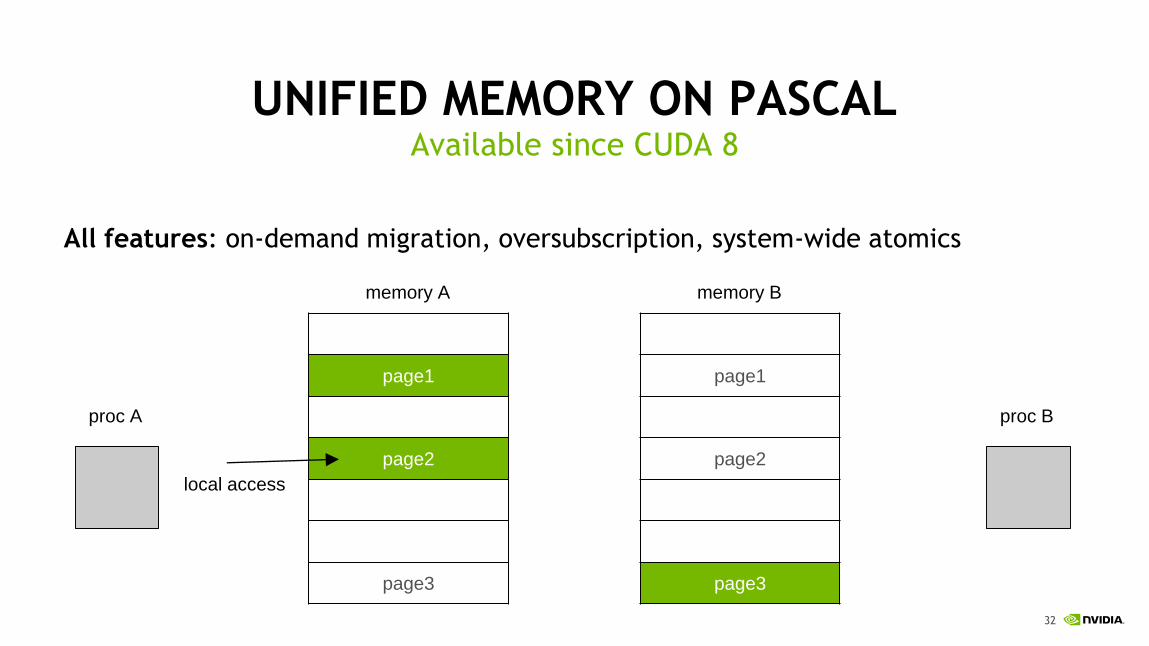
UNIFIED MEMORY ON PASCAL
On-demand migration to accessing processor on first touch
Available since CUDA 8
page1
page2
page3
page1
page2
page3
memory A memory B
local accessproc A proc B
page fault page migration
32
UNIFIED MEMORY ON PASCAL
All features: on-demand migration, oversubscription, system-wide atomics
Available since CUDA 8
page1
page2
page3
page1
page2
page3
memory A memory B
proc A proc B
local access

33
UNIFIED MEMORY ON VOLTA
Volta GPU: uses fault on first touch for migration, same as Pascal
Default model
GPU CPU
page1
page2
page3
page1
page2
page3
local access
page fault page migration
GPU memory CPU memory

34
UNIFIED MEMORY ON VOLTA
If memory is mapped to the GPU, migration can be triggered by access counters
New Feature: Access Counters
page1
page2
page3
page1
page2
page3
GPU CPU
remote access
remote access
local access
GPU memory CPU memory

35
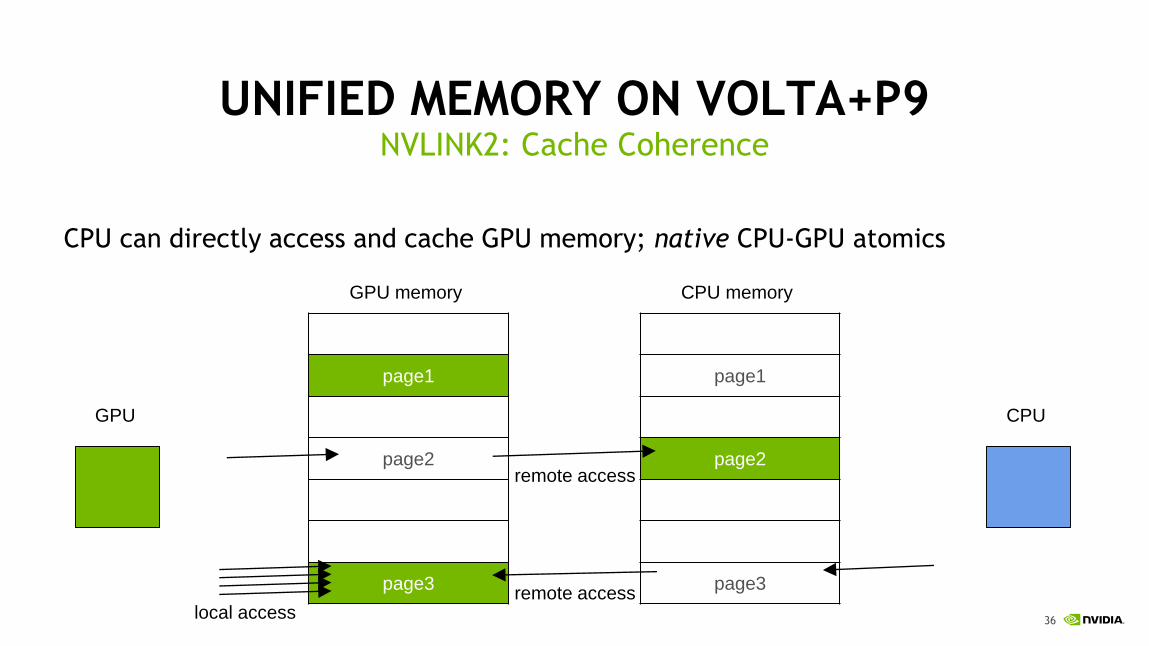
UNIFIED MEMORY ON VOLTA
With access counters migration only hot pages will be moved to the GPU
New Feature: Access Counters
page1
page2
page3
page1
page2
page3
GPU CPU
page migrationlocal access
GPU memory CPU memory
36
UNIFIED MEMORY ON VOLTA+P9
CPU can directly access and cache GPU memory; native CPU-GPU atomics
NVLINK2: Cache Coherence
page1
page2
page3
page1
page2
page3
GPU memory CPU memory
GPU CPU
local access
remote access
remote access

37
DRIVER HEURISTICS
The Unified Memory driver is doing intelligent things under the hood:
Prefetching: migrate pages proactively to reduce number of faults
Thrashing mitigation: heuristics to avoid frequent migration of shared pages
Eviction: what pages to evict when we need to make the room for new ones
You can’t control them but you can override most of these with hints
Things You Didn’t Know Exist
38
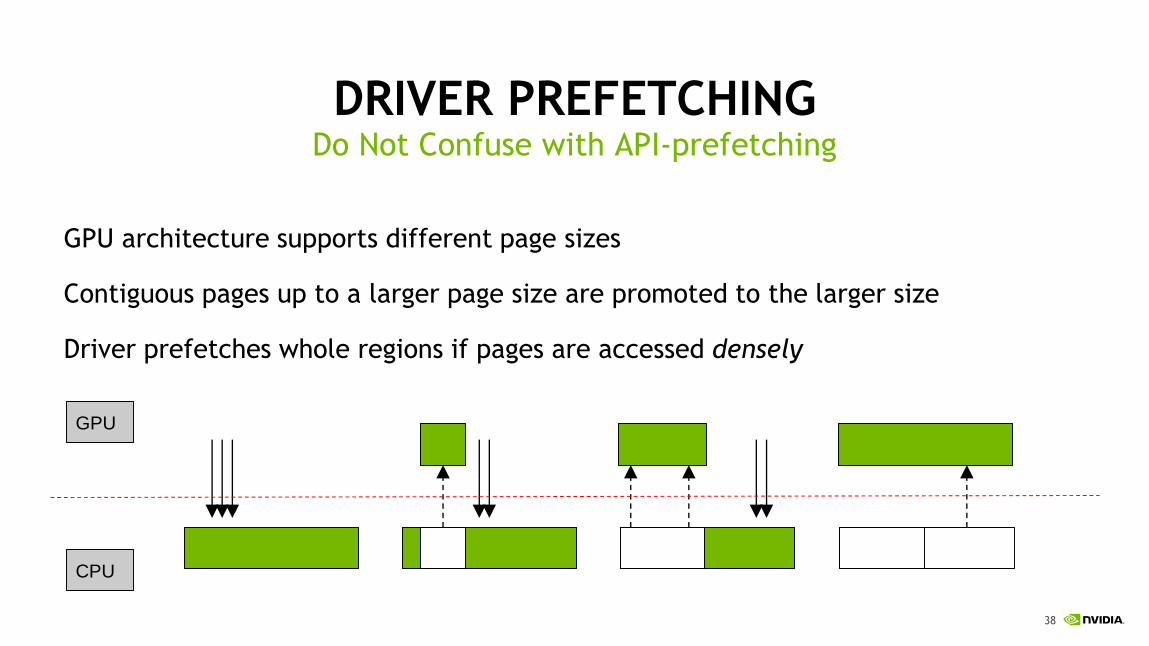
DRIVER PREFETCHING
GPU architecture supports different page sizes
Contiguous pages up to a larger page size are promoted to the larger size
Driver prefetches whole regions if pages are accessed densely
Do Not Confuse with API-prefetching
GPU
CPU
39
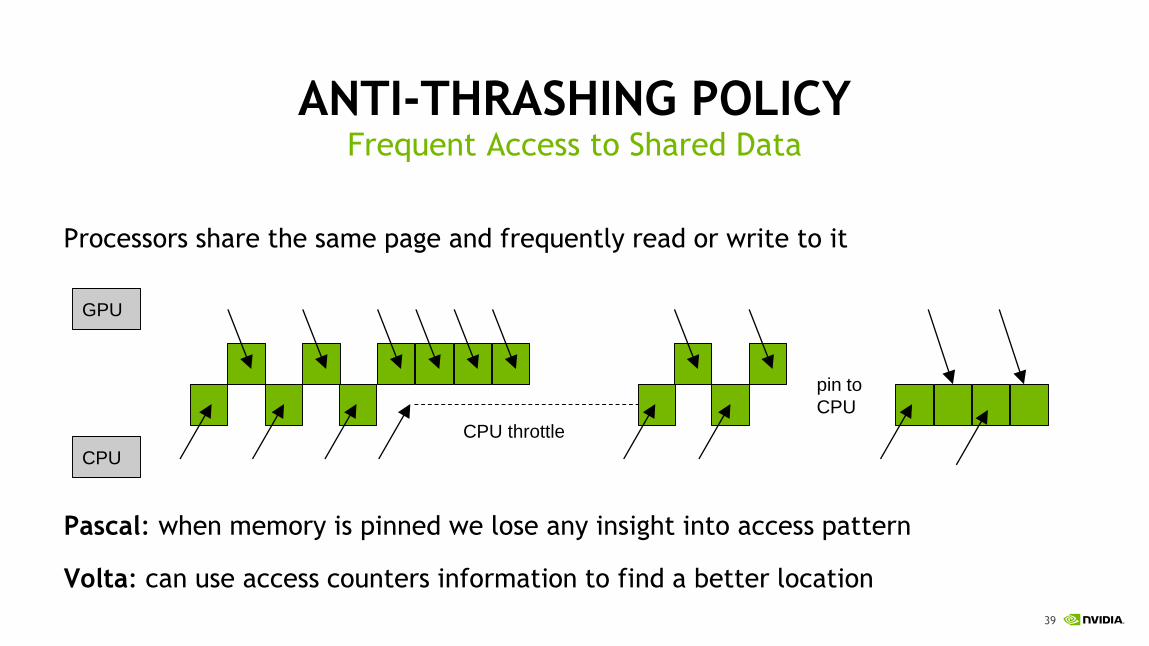
Processors share the same page and frequently read or write to it
Pascal: when memory is pinned we lose any insight into access pattern
Volta: can use access counters information to find a better location
ANTI-THRASHING POLICYFrequent Access to Shared Data
GPU
CPU
CPU throttle
pin to
CPU

40
Driver keeps a single list of physical chunks of GPU memory
Chunks from the front of the list are evicted first (LRU)
A chunk is considered “in use” when it is fully-populated or migrated
EVICTION ALGORITHMWhat Pages Are Moving Out of the GPU
eviction
allocation
migration to the GPU

41
AGENDA
Unified Memory Fundamentals
Under the Hood Details
Performance Analysis and Optimizations
Applications Deep Dive
42
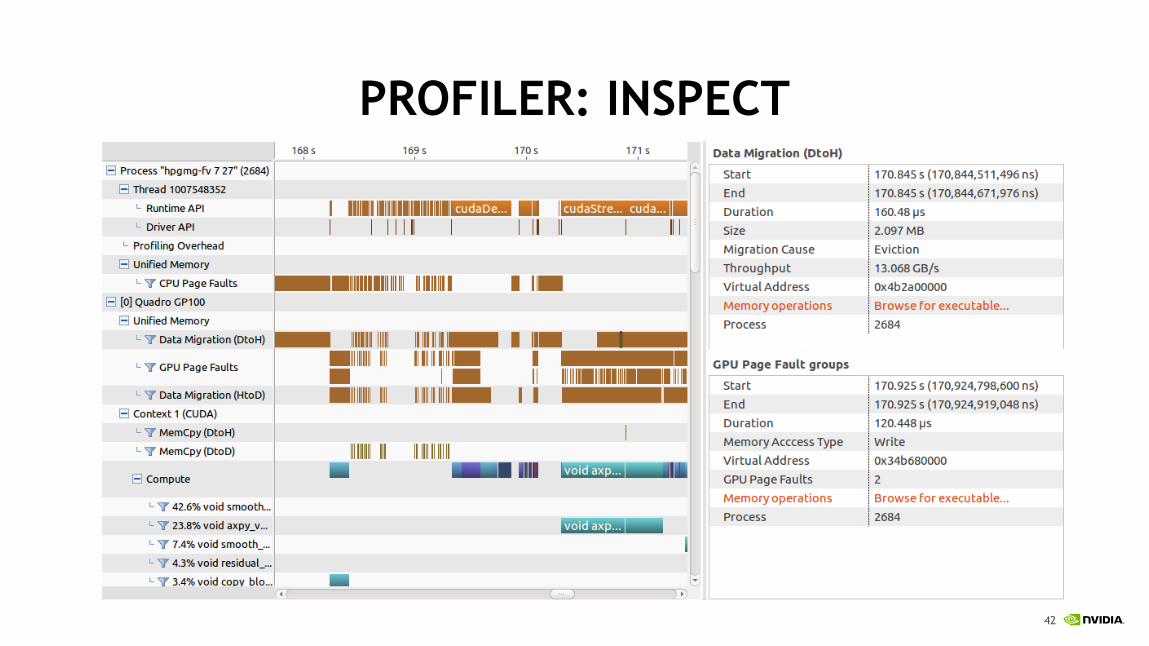
PROFILER: INSPECT
43
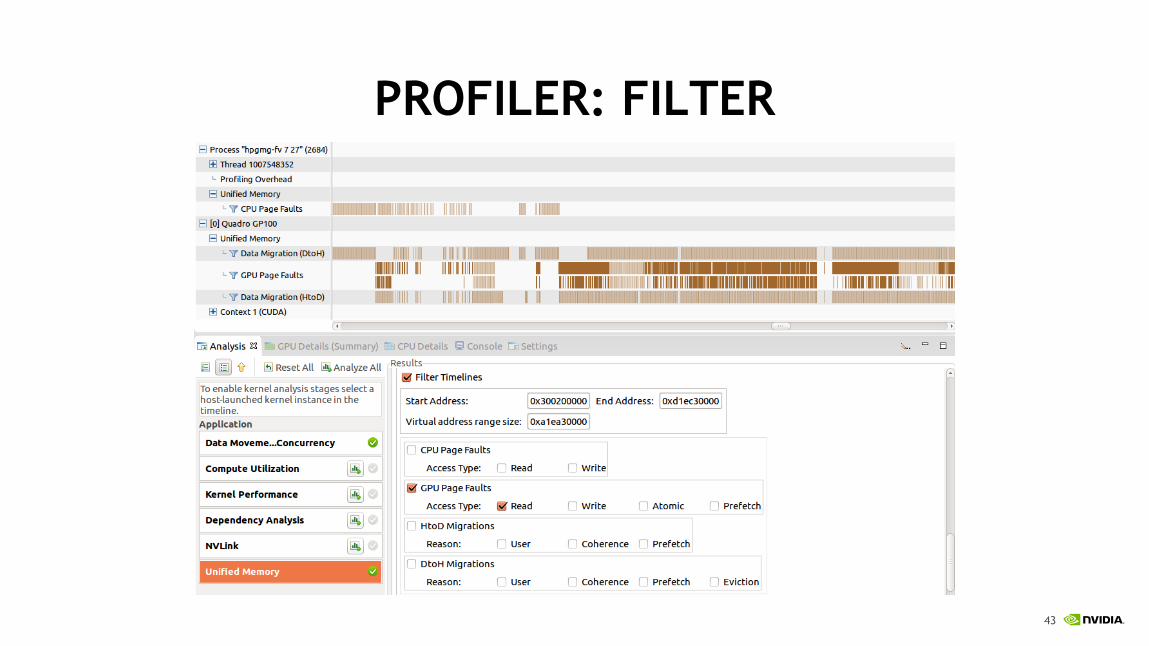
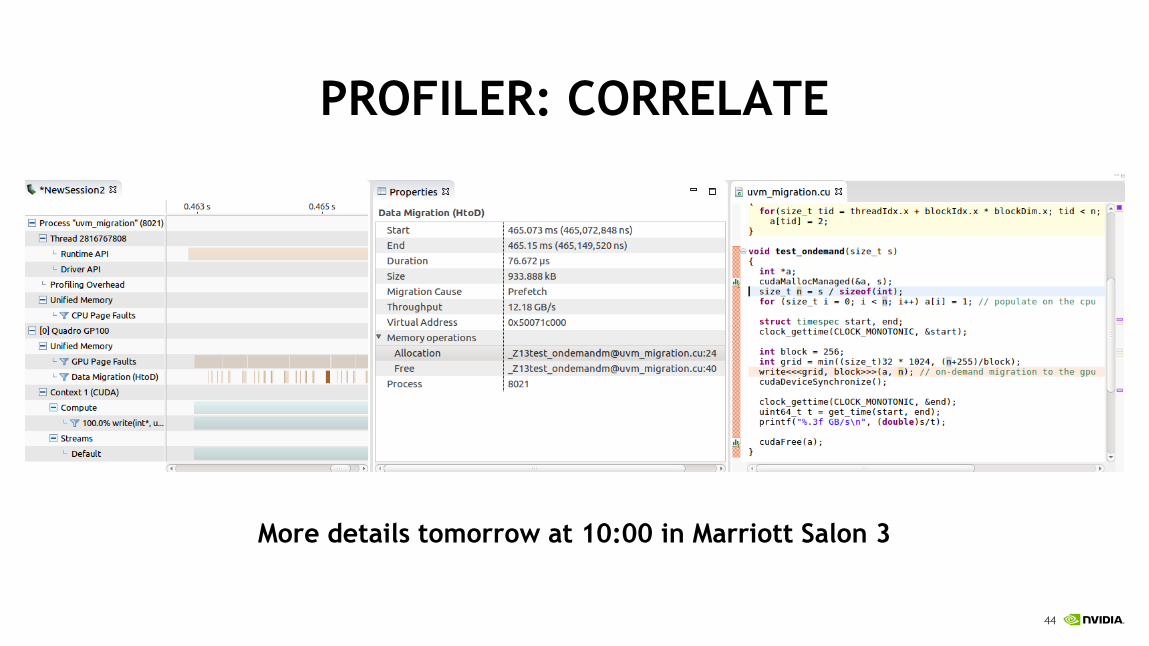
PROFILER: FILTER
44
PROFILER: CORRELATE
More details tomorrow at 10:00 in Marriott Salon 3

45
USER HINTS
If you know your application well you can optimize with hints
These are also useful to override some of the driver heuristics
cudaMemPrefetchAsync(ptr, size, processor, stream)
Similar to move_pages() in Linux
cudaMemAdvise(ptr, size, advice, processor)
Similar to madvise() in Linux
Why, When, and How to Use Them

46
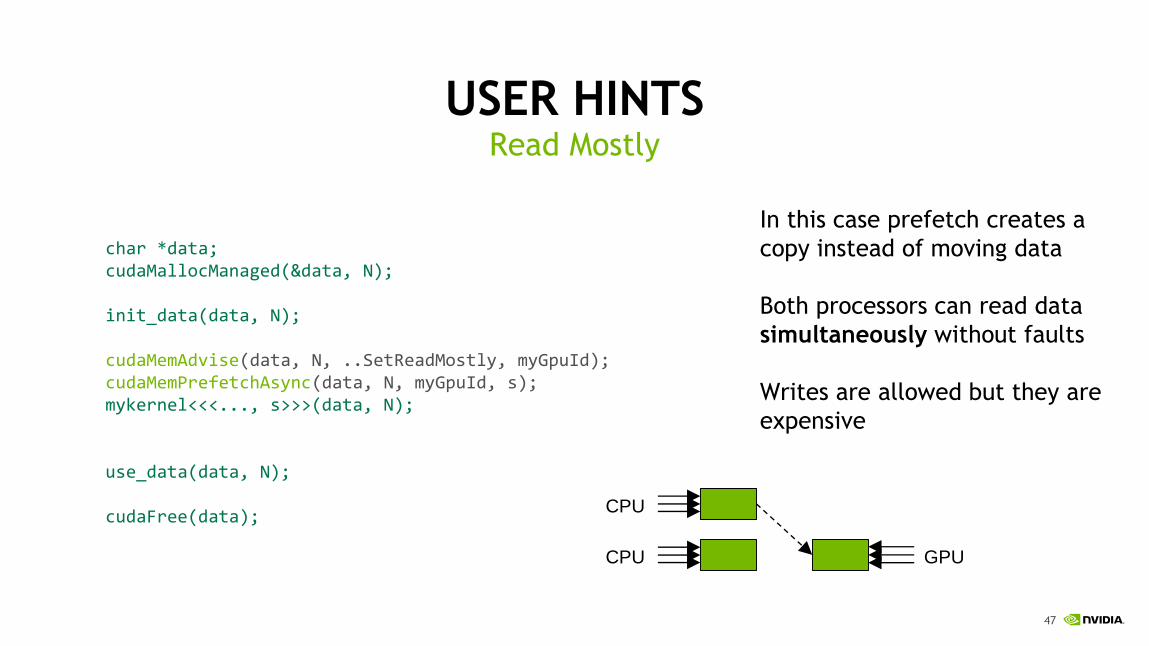
USER HINTSPrefetching
char *data;cudaMallocManaged(&data, N);
init_data(data, N);
cudaMemPrefetchAsync(data, N, myGpuId, s);mykernel<<<..., s>>>(data, N);cudaMemPrefetchAsync(data, N, cudaCpuDeviceId, s);cudaStreamSynchronize(s);
use_data(data, N);
cudaFree(data);
Page faults can be expensive
and they stall SM execution
Avoid faults by prefetching data
to the accessing processor
GPU
CPU
CPU
47
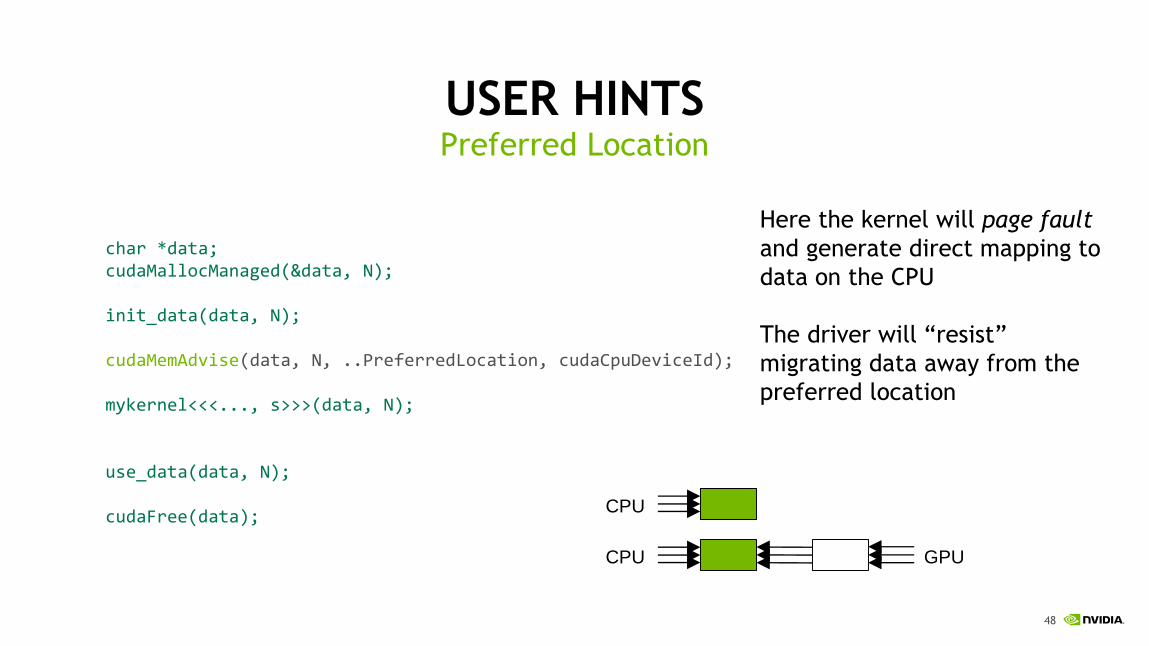
USER HINTSRead Mostly
char *data;cudaMallocManaged(&data, N);
init_data(data, N);
cudaMemAdvise(data, N, ..SetReadMostly, myGpuId);cudaMemPrefetchAsync(data, N, myGpuId, s);mykernel<<<..., s>>>(data, N);
use_data(data, N);
cudaFree(data);
In this case prefetch creates a
copy instead of moving data
Both processors can read data
simultaneously without faults
Writes are allowed but they are
expensive
GPU
CPU
CPU
48
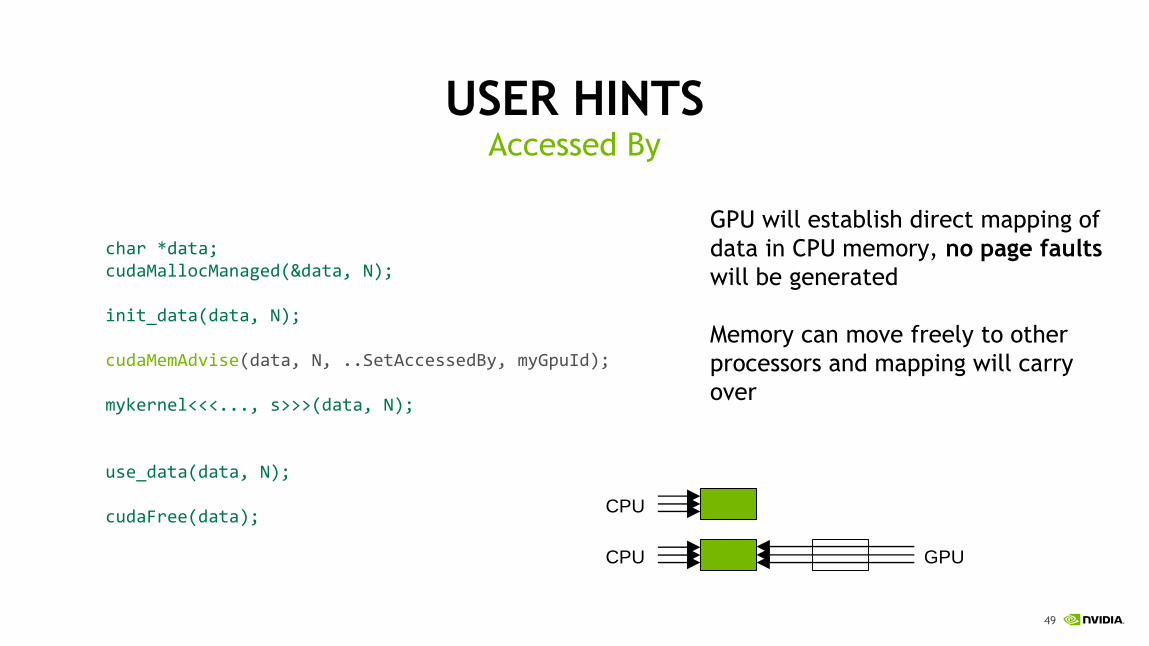
USER HINTSPreferred Location
char *data;cudaMallocManaged(&data, N);
init_data(data, N);
cudaMemAdvise(data, N, ..PreferredLocation, cudaCpuDeviceId);
mykernel<<<..., s>>>(data, N);
use_data(data, N);
cudaFree(data);
Here the kernel will page fault
and generate direct mapping to
data on the CPU
The driver will “resist”
migrating data away from the
preferred location
GPU
CPU
CPU
49
USER HINTSAccessed By
char *data;cudaMallocManaged(&data, N);
init_data(data, N);
cudaMemAdvise(data, N, ..SetAccessedBy, myGpuId);
mykernel<<<..., s>>>(data, N);
use_data(data, N);
cudaFree(data);
GPU will establish direct mapping of
data in CPU memory, no page faults
will be generated
Memory can move freely to other
processors and mapping will carry
over
GPU
CPU
CPU
50
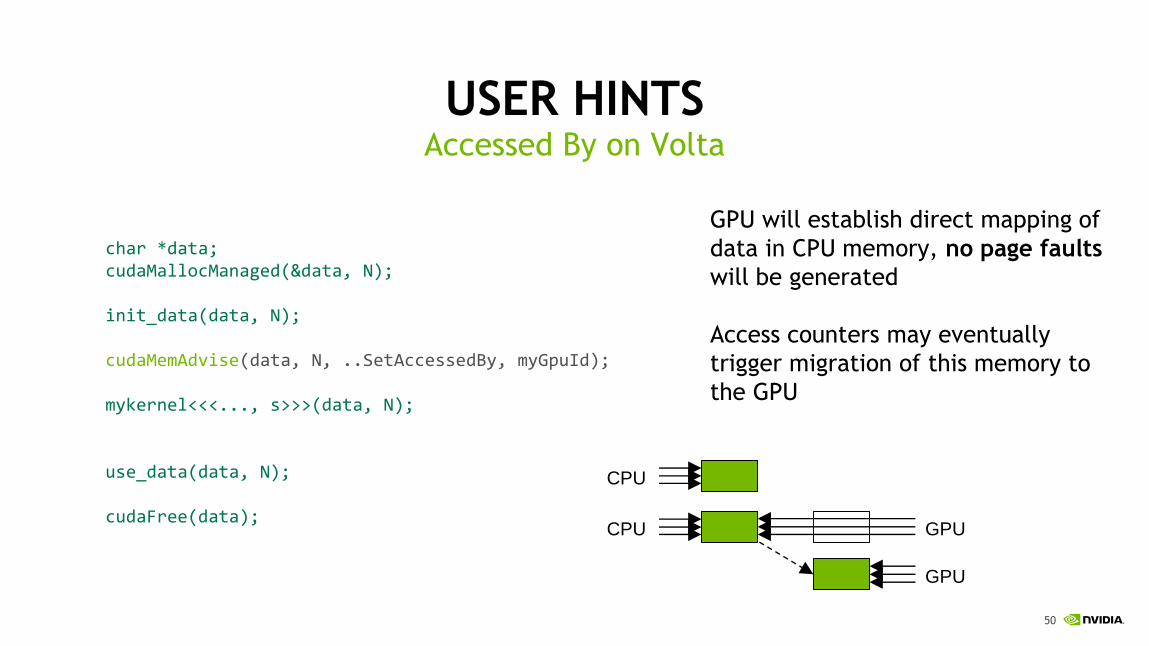
USER HINTSAccessed By on Volta
char *data;cudaMallocManaged(&data, N);
init_data(data, N);
cudaMemAdvise(data, N, ..SetAccessedBy, myGpuId);
mykernel<<<..., s>>>(data, N);
use_data(data, N);
cudaFree(data);
GPU will establish direct mapping of
data in CPU memory, no page faults
will be generated
Access counters may eventually
trigger migration of this memory to
the GPU
GPU
CPU
CPU
GPU
51
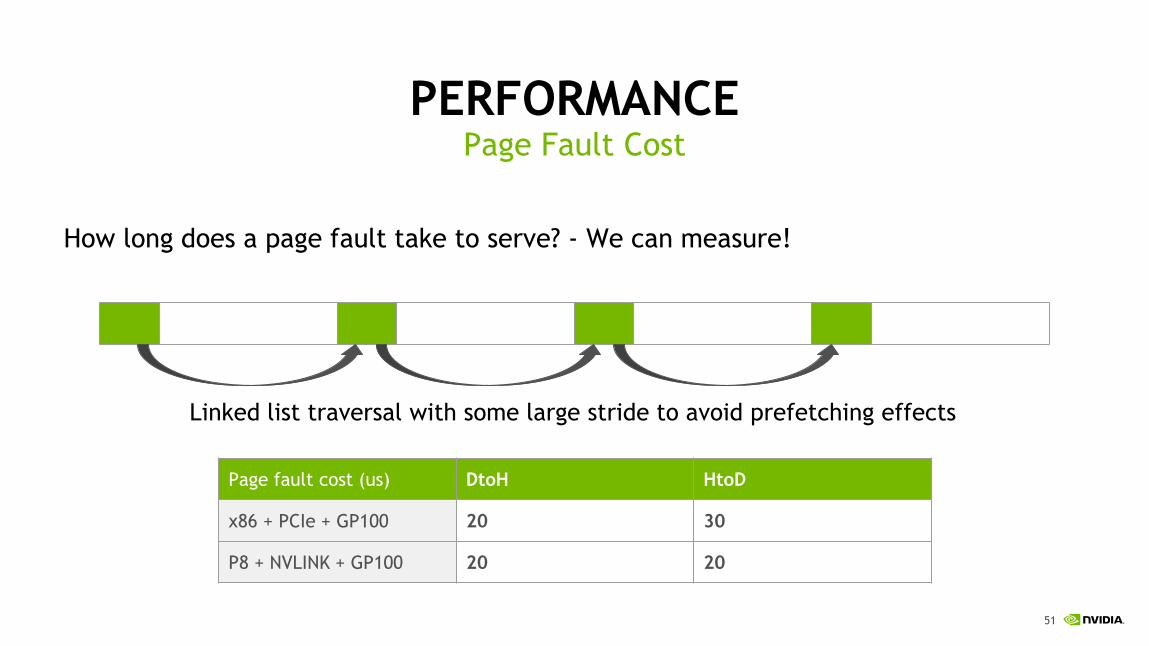
PERFORMANCE
How long does a page fault take to serve? - We can measure!
Page Fault Cost
Linked list traversal with some large stride to avoid prefetching effects
Page fault cost (us) DtoH HtoD
x86 + PCIe + GP100 20 30
P8 + NVLINK + GP100 20 20

52
GB/s
GB/s
0
5
10
15
20
25
128KB 1MB 8MB 64MB 512MB 4GB
CPU memory
on-demand single on-demand multi
explicit single explicit multi
1
10
100
1000
128KB 1MB 8MB 64MB 512MB 4GB
GPU memory
on-demand prefetch explicit
PERFORMANCEPage Allocation Throughput
cudaMallocManaged/cudaMalloc + cudaMemset cudaMallocManaged/mmap + fill on the CPU
cudaMalloc is using
preallocated memory
for large sizes
53
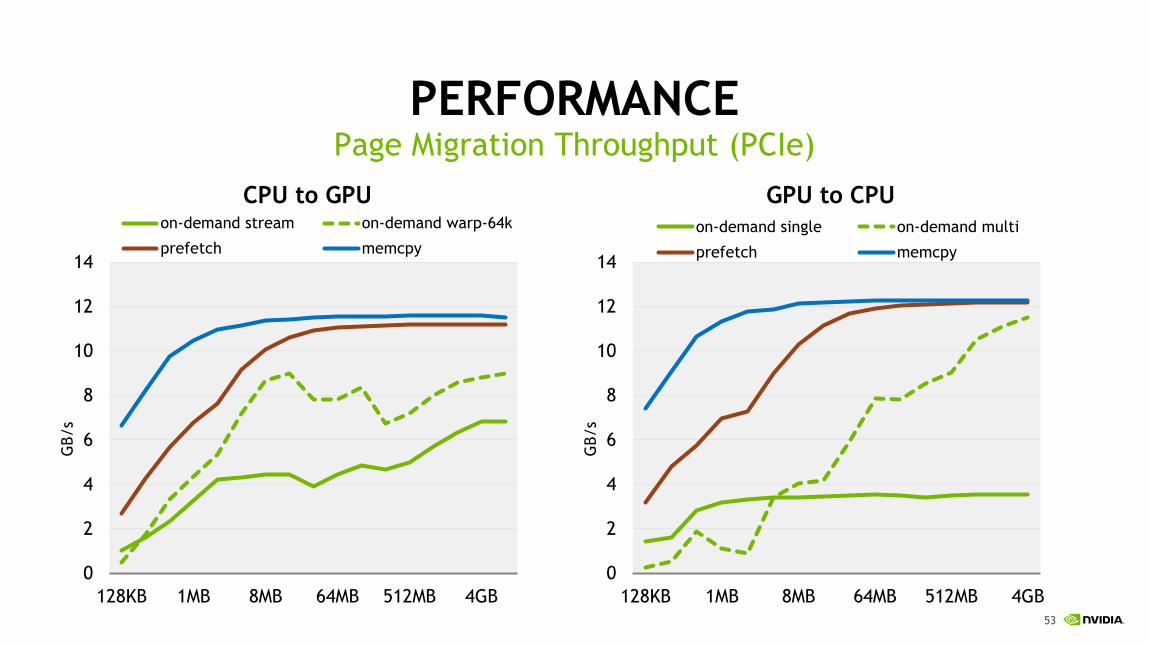
PERFORMANCEPage Migration Throughput (PCIe)
0
2
4
6
8
10
12
14
128KB 1MB 8MB 64MB 512MB 4GB
CPU to GPUon-demand stream on-demand warp-64k
prefetch memcpy
GB/s
0
2
4
6
8
10
12
14
128KB 1MB 8MB 64MB 512MB 4GB
GPU to CPU
on-demand single on-demand multi
prefetch memcpy
GB/s

54
PERFORMANCEPage Migration Throughput (2x NVLINK)
0
5
10
15
20
25
30
128KB 1MB 8MB 64MB 512MB
CPU to GPUon-demand stream on-demand warp-64k
prefetch memcpy
GB/s
0
5
10
15
20
25
128KB 1MB 8MB 64MB 512MB
GPU to CPU
on-demand single on-demand multi
prefetch memcpy
GB/s

55
PERFORMANCE
cudaMallocManaged alignment: 512B on Pascal/Volta, 4KB on Kepler/Maxwell
Too many small allocations will use up many pages
cudaMallocManaged memory is moved at system page granularity
For small allocations more data could be moved than necessary
Solution: use cached allocator or memory pools
Page Granularity Overhead

56
AGENDA
Unified Memory Fundamentals
Under the Hood Details
Performance Analysis and Optimizations
Applications Deep Dive

57
HPC: HPGMG
High-Performance Geometric Multigrid
Proxy AMR and Low Mach Combustion codes
Used in Top500 benchmarking
High memory usage requirements
http://crd.lbl.gov/departments/computer-science/PAR/research/hpgmg/
Combustion Simulation
58
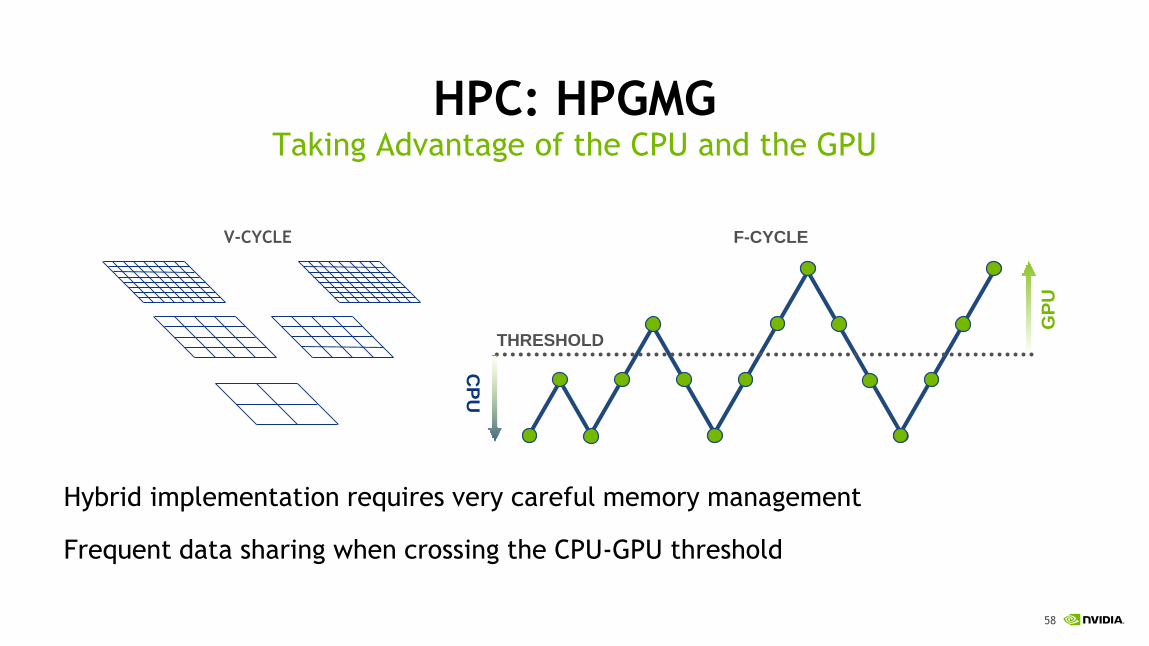
HPC: HPGMG
Hybrid implementation requires very careful memory management
Frequent data sharing when crossing the CPU-GPU threshold
Taking Advantage of the CPU and the GPU
V-CYCLE
GP
U
CP
U
THRESHOLD
F-CYCLE

59
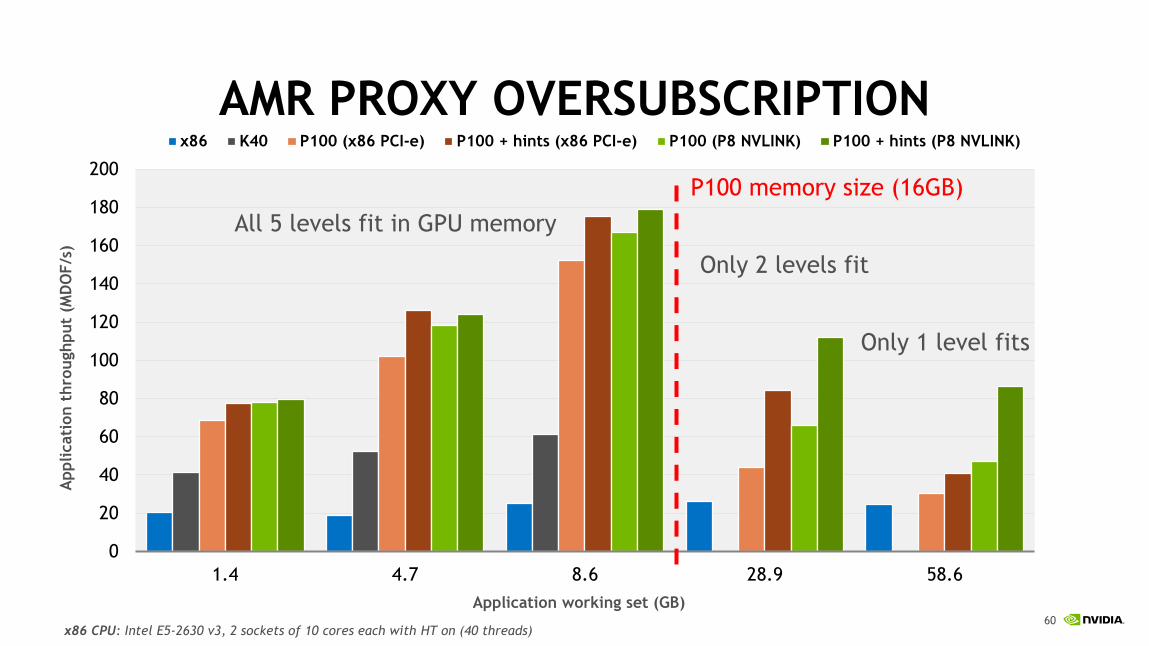
HPGMG: AMR PROXYData Locality and Reuse of AMR Levels
Optimization: prefetch the
next AMR level while
running computations on
the current level
We can use a separate
non-blocking CUDA stream
to overlap with the default
stream
https://devblogs.nvidia.com/parallelforall/beyond-gpu-memory-limits-unified-memory-pascal/
60
AMR PROXY OVERSUBSCRIPTION
0
20
40
60
80
100
120
140
160
180
200
1.4 4.7 8.6 28.9 58.6
x86 K40 P100 (x86 PCI-e) P100 + hints (x86 PCI-e) P100 (P8 NVLINK) P100 + hints (P8 NVLINK)
Applicati
on t
hro
ughput
(MD
OF/s
)
Application working set (GB)
P100 memory size (16GB)
x86 CPU: Intel E5-2630 v3, 2 sockets of 10 cores each with HT on (40 threads)
All 5 levels fit in GPU memory
Only 2 levels fit
Only 1 level fits

61
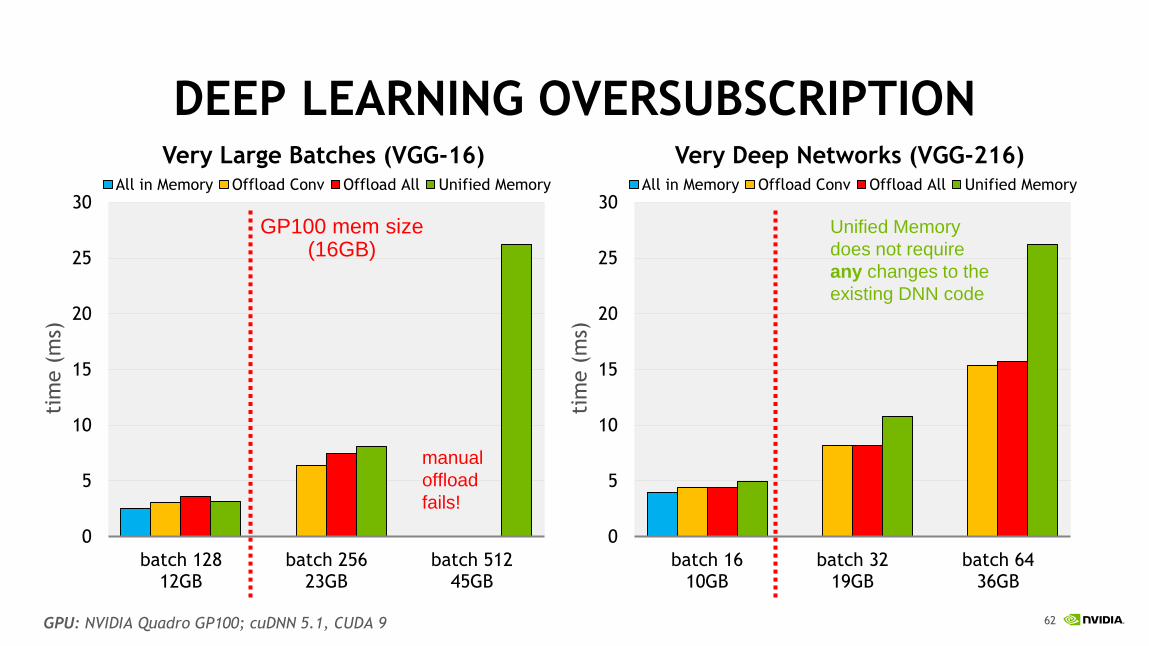
vDNN: Virtualized DNN for Scalable, Memory-Efficient Neural Network Design
Original version implemented custom heuristics to prefetch and offload data
Unified Memory can automatically migrate memory as needed!
DEEP LEARNING
62
DEEP LEARNING OVERSUBSCRIPTION
GPU: NVIDIA Quadro GP100; cuDNN 5.1, CUDA 9
0
5
10
15
20
25
30
batch 12812GB
batch 25623GB
batch 51245GB
Very Large Batches (VGG-16)All in Memory Offload Conv Offload All Unified Memory
tim
e (
ms)
0
5
10
15
20
25
30
batch 1610GB
batch 3219GB
batch 6436GB
Very Deep Networks (VGG-216)All in Memory Offload Conv Offload All Unified Memory
tim
e (
ms)
GP100 mem size(16GB)
manual
offload
fails!
Unified Memory
does not require
any changes to the
existing DNN code
63
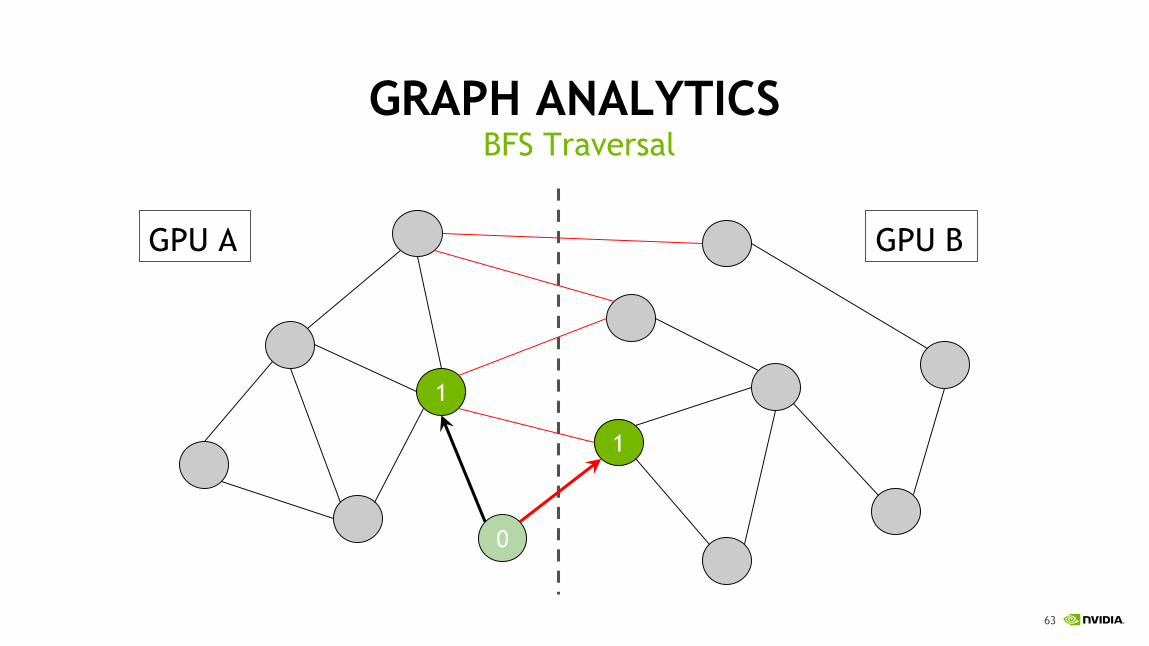
GRAPH ANALYTICSBFS Traversal
1
0
1
GPU A GPU B
64
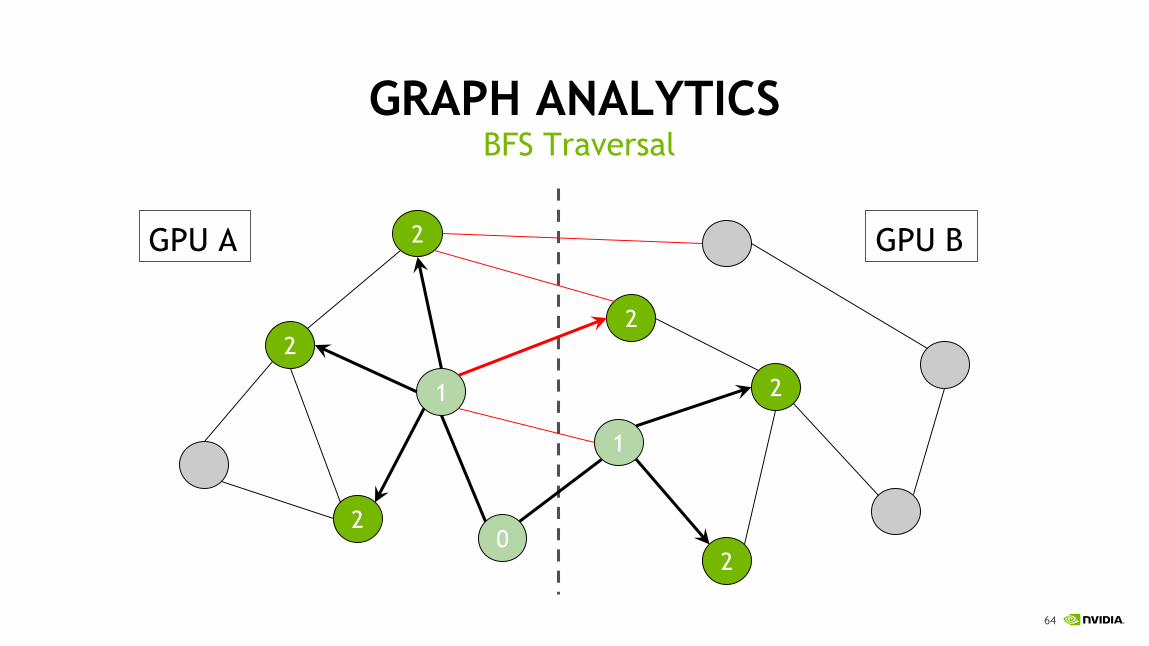
GRAPH ANALYTICSBFS Traversal
2
2
1
2
0
2
1
2
2
GPU A GPU B

65
GRAPH ANALYTICSBFS Traversal
3
2
2
1
2
0
2
1
2
2
3
3
GPU A GPU B

66
GRAPH ANALYTICSShared vs Duplicated Visibility Vector
GPU A GPU B
shared visibility bitmap
current frontier
duplicated visibility bitmap
67
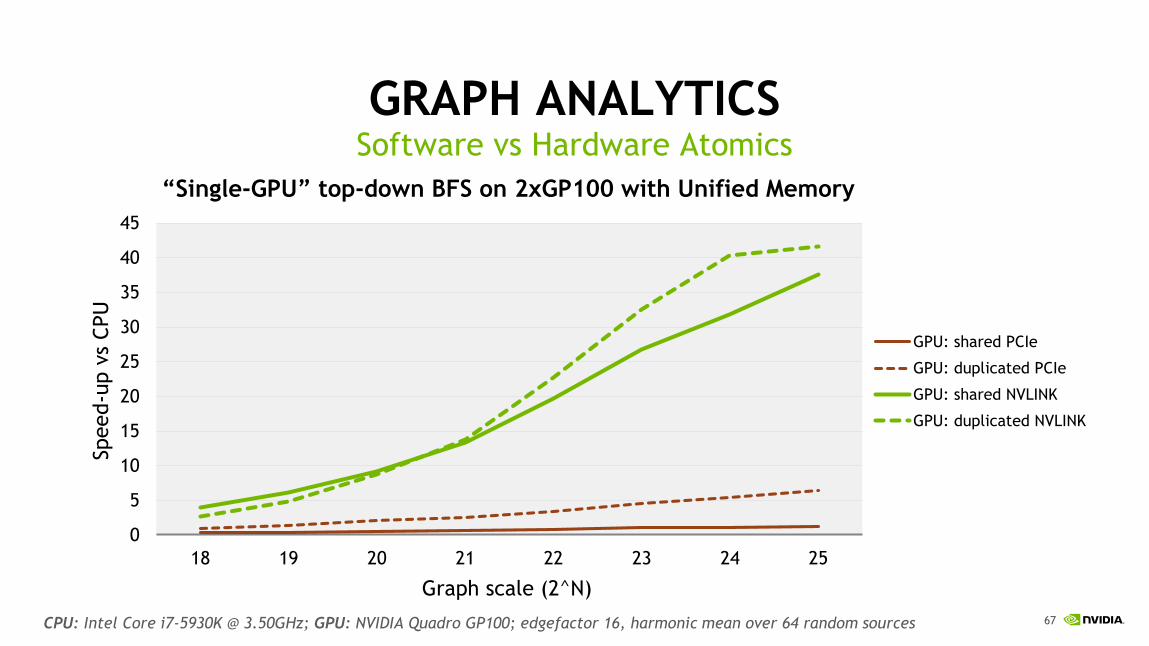
GRAPH ANALYTICSSoftware vs Hardware Atomics
CPU: Intel Core i7-5930K @ 3.50GHz; GPU: NVIDIA Quadro GP100; edgefactor 16, harmonic mean over 64 random sources
Speed-u
p v
s CPU
0
5
10
15
20
25
30
35
40
45
18 19 20 21 22 23 24 25
“Single-GPU” top-down BFS on 2xGP100 with Unified Memory
GPU: shared PCIe
GPU: duplicated PCIe
GPU: shared NVLINK
GPU: duplicated NVLINK
Graph scale (2^N)

68
AGENDA
Unified Memory Fundamentals
Under the Hood Details
Performance Analysis and Optimizations
Applications Deep Dive

69
CONCLUSIONS AND OUTLOOK
Consider using Unified Memory for any new application development
Get your code running on the GPU much sooner!
Enjoy clean code and *virtually* no memory limits
Increase productivity, explore and prototype new algorithms
Use the explicit data management only where you need it

70


















