
時系列グラフクラスタリングによるトレンド分析 · DEIM Forum 2015 E6-6 時系列グラフクラスタリングによるトレンド分析 岸田 吉弘 y塩川浩昭yy

TS002

Stata 12 コマンド解説書
【経済系機能編】多変量時系列分析
Stataには時系列データを分析するためのコマンドが多数用意されています。本解説書では多変量時系列分析
に関係するものを中心に、その機能と用法を記述しました。
• 多変量時系列分析の概要• VAR(ベクトル自己回帰)モデル
• VEC(ベクトル誤差修正)モデル
• イノベーション会計
目 次
コマンド whitepaperタイトル ページ mwp番号
− 多変量時系列分析 4 mwp-084
var VARモデルのフィット 14 mwp-004
varbasic VARモデルのフィット 26 mwp-005
svar 構造 VARモデルのフィット 33 mwp-007
vec intro VEC関連コマンドの概要 51 mwp-008
vec VECモデルのフィット 80 mwp-063
VAR系推定後機能
vargranger Granger因果性の検定 93 mwp-062
varlmar 残差自己相関の検定 101 mwp-059
varnorm 擾乱の正規性検定 107 mwp-060
varsoc ラグ次数選択 113 mwp-057
varstable 安定性のチェック 118 mwp-058
varwle ラグ項の有意性検定 124 mwp-061
VEC系推定後機能
veclmar 残差自己相関の検定 131 mwp-066
vecnorm 擾乱の正規性検定 135 mwp-067
vecrank 共和分ランクの推定 139 mwp-064
vecstable 安定性のチェック 144 mwp-065

目 次
コマンド whitepaperタイトル ページ mwp番号
irf IRF系コマンドの用法 149 mwp-006
fcast compute 動的予測 160 mwp-068
fcast graph 動的予測のプロット 166 mwp-069
本解説書は StataCorp社の許諾のもとに作成したものです。
c⃝ 2011 Math工房
一部 c⃝ 2011 StataCorp LP
Math工房 web: www.math-koubou.jp
email: [email protected]

Stata12 whitepapers
mwp-084
多変量時系列分析
Stataには多変量時系列データを分析するための機能として var, vec等のコマンドが用意されています。そ
れぞれの機能/用法については別に whitepaperを用意していますが(mwp-004 , mwp-063 , 等)、前提となる
基本的事項については別途整理しておいた方が良いと考え、本 whitepaper を作成しました。なお、arima,
arch等の単変量時系列分析機能に関する同様のイントロについては mwp-083 をご参照ください。
1. VARモデル
2. イノベーション会計
3. 構造型 VAR
4. VECモデル
補足1
1. VARモデル
(1) 多変量時系列
単変量の場合には {yt} という 1 つの変数に関する時系列を分析の対象としましたが、多変量の場合には
yt = (y1t, y2t, . . . , ynt)′ で表されるベクトルが考察対象となり、その確率過程は
{yt} = {. . . ,y−1,y0,y1, . . .} (1)
として定義されます。このような {yt}に対する定常性(より厳密には弱定常性または共分散定常性)は次のように定義されます。
(i) 平均 E(yt)を µとしたとき、ベクトル µがすべての tに対して一定である。
(ii) 分散共分散行列 V (yt) = E[(yt − µ)(yt − µ)′]がすべての tに対して一定である。
(iii) 自己共分散行列 Cov(yt,yt−s) = E[(yt −µ)(yt−s −µ)′]が tには依存せず、時点の差である s(s > 0)
のみに依存する。
c⃝ Copyright Math工房; 一部 c⃝ Copyright StataCorp LP (used with permission)
4

Stata12 whitepapers
(2) VARモデル
ベクトル自己回帰モデル (VAR: vector autoregression model) は単変量の AR(p)モデルの延長として、一般
的に次のように表現されます。
yt = A0 +p∑
i=1
Aiyt−i + ut (2)
ここにA0 は定数項を表す n× 1の列ベクトル、Ai(i = 1, 2, . . . , p)は係数を表す n× nの行列、ut は擾乱を
表す n × 1の列ベクトルです。なお、ut に対しては次の性質を仮定します。
E(ut) = 0 (3a)
V (ut) = E(utu′t) = Σ (3b)
E(utut−s) = 0, for s > 0 (3c)
この中で Σは対角行列とは限らない点に注意してください。すなわち同時点の誤差項間における相関の存在
が許容されているわけです。モデル式 (2)の場合には過去 p期の値に依存した形になっているため、VAR(p)
モデルと表記されます。
定常性の条件: VAR(p)モデル (2)の定常性の条件は∣∣∣∣∣In −(
p∑i=1
Aizi
)∣∣∣∣∣ = 0 (4)
の根の絶対値がすべて 1より大きいことである。ただし | |は行列式を意味する。
(3) VARモデルの推定
(2)式に示されるような VARモデルの各方程式は誤差項の相関を通じて関係しています。このようなモデル
は見かけ上無関係な回帰 (SUR: seemingly unrelated regression) モデルと呼ばれます。一般的に SURモデ
ルに対して有効な推定を行うためには、誤差項の相関を考慮する必要があるため、すべての回帰式を同時に推
定しなくてはなりません。しかし VARモデルの場合にはすべての回帰式が同一の説明変数を持つという特殊
性が備わっています。この条件のもとでは、各方程式に対し個別に OLSを適用することによって得られる係
数の推定値が最良線形不偏推定量 (BLUE: best linear unbiased estimator) となることが知られています。
VARモデルの推定には通常 varコマンドが使用されます*1。仕様の詳細や用例については [TS] var (mwp-
004 ) をご参照ください。なお、varコマンドの実行に際してはラグ次数 pを指定する必要があります。そこ
でどのような値を選択したら良いかが問題となるわけですが、Stataには次数選択を支援する preestimation
機能が varsocコマンドとして用意されています。[TS] varsoc (mwp-057 ) をご参照ください。
*1 後述するインパルス応答解析等の機能まで包含し、VAR の機能をより使いやすくしたコマンド varbasic も用意されています。[TS] varbasic (mwp-005 ) をご参照ください。
5

Stata12 whitepapers
2. イノベーション会計
VARや VECモデルがフィットされた段階で、そのモデルがショックに対してどう反応するかを調べる動学的
分析手法はイノベーション会計 (innovation accounting) と呼ばれます。インパルス応答関数 (IRF: impulse
response function) や予測誤差分散分解 (FEVD: forecast-error variance decomposition) による分析手法が
その代表的なものです。
評価版では割愛しています。
3. 構造型 VAR
評価版では割愛しています。
4. VECモデル
(1) 共和分とは
xt と yt が 1次の和分過程 I(1)であるときに、それらの線形結合 β1xt + β2yt が定常過程 I(0)となる関係が成
立するのであれば、xt と yt とは共和分の関係にある (cointegrated) と言います。またベクトル β = (β1, β2)′
を共和分ベクトル (cointegrating vector) と呼びます。
ベクトル誤差修正モデル (VECM: vector error correction model) は経済変数間に何らかの長期的均衡が存
在する場合の分析手法として用いられます。
(2) 誤差修正メカニズム
まず、次のような n変量の VAR(p)モデルについて考えます。
yt = A0 +p∑
i=1
Aiyt−i + ut (22)
ただし {yt}を構成するすべての変数 y1t, y2t, . . . , ynt は I(1)過程に従う非定常系列である点に注意してくだ
さい。このモデルを扱う上では第 1階差を取ることがポイントとなります。詳細は補足1を参照いただくとし
て、(22)式は次のように変形できます。
∆yt = A0 + Πyt−1 +p−1∑i=1
Γi∆yt−i + ut (23)
ただしΠ =∑p
i=1 Ai − In, Γi = −∑pj=i+1 Aj です。この (23)式で重要な点は、左辺、及び右辺のΠyt−1
という項以外は定常であるという点です。このことからΠyt−1 も定常でなくてはならないという帰結が導か
れます。そのためには次のいずれかの条件が成立する必要があります。
Case 1: Π = 0、すなわち∑p
i=1 Ai = In となること。
たまたまこのような条件が満たされるのであれば、(23)式は VARのモデル式となるため、{∆yt}についてVARをフィットさせれば良いことになります。この場合、{yt}は共和分の関係にはありません。
6

Stata12 whitepapers
Case 2: Πyt−1 というベクトルの各成分が定常であること。
これは変数 y1t, y2t, . . . , ynt 間の線形結合(1つとは限らない)が定常であること、すなわち共和分関係の存
在を意味するものです。この場合、Πは αβ′ のように表現できることが知られています。すなわち (23)式は
∆yt = A0 + αβ′yt−1 +p−1∑i=1
Γi∆yt−i + ut (24)
のようになります。ただし α,βは共に n× rの行列であり、rはΠのランクを意味します。β′ は r組の共和
分ベクトルを表し、β′yt−1 によって r個の線形結合式、すなわち誤差修正項 (error correction term) が規定
されることになります。一方、αは調整係数ベクトル (adjustment coefficient vector) と呼ばれます。
(24)式は VECMの基本式です。変数間に共和分の関係が存在する場合にモデルが (24)式のような形で表現
できることをグランジャーの表現定理 (Granger’s representation theorem) と言います。
(3) 共和分ランクの検定
評価版では割愛しています。
(4) VECモデルの推定
評価版では割愛しています。
補足1 – VECモデル式の誘導
評価版では割愛しています。
¥
7

Stata12 whitepapers
mwp-004
var - ベクトル自己回帰モデル
Stata にはベクトル自己回帰 (VAR: vector autoregressive) モデルに関連したコマンドが一式用意されてい
ます。本 whitepaperではその中核となる varコマンドについて、その機能概要と用例を紹介します。なお、
VARとしての機能は制限されますが、簡便な操作で IRFや FEVDをも含む形で分析が行える varbasicと
いうコマンドが別に用意されています。これについては mwp-005 をご参照ください。
1. VARモデル
2. varの用例
2.1 基本的な VARモデル
2.2 外生変数を含むモデル
2.3 制約を含むモデル
3. var関連推定後機能
1. VARモデル
VARの一般的なモデル式については [TS] var intro p543 に記載されています。ベクトル式なのでわかり
にくいかも知れないので、3変量 VAR(2)モデルのケースについて成分表示のモデル式を記しておきます。た
だし外生変数 xt を含まないモデルについて考えるものとします。y1t
y2t
y3t
=
v1
v2
v3
+
a(1)11 a
(1)12 a
(1)13
a(1)21 a
(1)22 a
(1)23
a(1)31 a
(1)32 a
(1)33
y1,t−1
y2,t−1
y3,t−1
+
a(2)11 a
(2)12 a
(2)13
a(2)21 a
(2)22 a
(2)23
a(2)31 a
(2)32 a
(2)33
y1,t−2
y2,t−2
y3,t−2
+
u1t
u2t
u3t
(M1)
u1t
u2t
u3t
∼ W.N.(Σ)
ここで [TS] var intro の一般式とは
A1 =
a(1)11 a
(1)12 a
(1)13
a(1)21 a
(1)22 a
(1)23
a(1)31 a
(1)32 a
(1)33
A2 =
a(2)11 a
(2)12 a
(2)13
a(2)21 a
(2)22 a
(2)23
a(2)31 a
(2)32 a
(2)33
という対応付けを行っています。
c⃝ Copyright Math工房; 一部 c⃝ Copyright StataCorp LP (used with permission)
8

Stata12 whitepapers
擾乱項 ut はホワイトノイズ (W.N.) ですが、その分散共分散行列が対角行列ではなく、一般的なΣと表記さ
れている点に注意してください。(M1)式の例で言えば
Σ =
σ11 σ12 σ13
σ21 σ22 σ23
σ31 σ32 σ33
ただし σ12 = σ21, σ13 = σ31, σ23 = σ32
となります。従って 3変量 VAR(2)モデルの場合、推定対象となるパラメータの数は a(1)ij が 9個、a
(2)ij が 9
個、σij が 6個で計 24個となります。
(M1)式の例に示されるような VARモデルの各方程式は誤差項の相関を通じて関係しています。このような
モデルは見かけ上無関係な回帰 (SUR: seemingly unrelated regression) モデルと呼ばれます。一般的に SUR
モデルに対して有効な推定を行うためには、誤差項の相関を考慮する必要があるため、すべての回帰式を同時
に推定しなくてはなりません。しかし VARモデルの場合にはすべての回帰式が同一の説明変数を持つという
特殊性が備わっています。この条件のもとでは、各方程式に対し個別に OLSを適用することによって得られ
る係数の推定値が最良線形不偏推定量 (BLUE: best linear unbiased estimator) となることが知られていま
す。さらに擾乱項 ut が多変量正規分布に従う場合には、各方程式を個別に OLSによって推定した係数値は
最尤推定量とも一致することになります。
2. varの用例
2.1 基本的な VARモデル
最初に基本的な VARモデルとして外生変数を含まないモデルについて考察します。使用する Exampleデー
タセットは lutkepohl2.dtaで、これに対し 3変量 VARモデルをフィットさせます。
. use http://www.stata-press.com/data/r12/lutkepohl2 *1
(Quarterly SA West German macro data, Bil DM, from Lutkepohl 1993 Table E.1)
(M1)式における y1, y2, y3 には次の 3つの時系列変数をそれぞれ対応させることにします。
変数名 内容 備考
dln inv ∆ ln(inv) inv: 投資
dln inc ∆ ln(inc) inc: 所得
dln consump ∆ ln(consump) consump: 消費
参考までに変数 invについて関係するデータを一部リストしておきます。
*1 メニュー操作:File ◃ Example Datasets ◃ Stata 12 manual datasets と操作、Time-Series Reference Manual [TS] の var
の項よりダウンロードする。
9

Stata12 whitepapers
. list qtr inv ln inv dln inv in 1/8, separator(4) *2
8. 1961q4 214 5.365976 .033257
7. 1961q3 207 5.332719 .0244513
6. 1961q2 202 5.308268 .0435905
5. 1961q1 211 5.351858 .0943627
4. 1960q4 192 5.257495 .0371394
3. 1960q3 185 5.220356 .03297
2. 1960q2 179 5.187386 .0055709
1. 1960q1 180 5.192957 .
qtr inv ln_inv dln_inv
データセット上には 1960q1から 1982q4までのデータが記録されていますが、ここでは 1978q4までの範囲
に限定する形でフィットを行います。
varコマンドを実行するに際してはラグ次数を指定する必要があるわけですが、本用例ではデフォルトの設定
を用いることにします。このためフィットされるモデルは VAR(2)ということになります。なお、推定実行前
に varsocコマンドを使用して適切なラグ次数を選択することもできますが、それについては [TS] varsoc
(mwp-057 ) をご参照ください。
• Statistics ◃ Multivariate time series ◃ Vector autoregression (VAR) と操作
• Modelタブ: Dependent variables: dln inv dln inc dln consump
Lags: Include lags 1 to: 2 (デフォルト)
図 1 varダイアログ – Modelタブ
*2 メニュー操作:Data ◃ Describe data ◃ List data
10

Stata12 whitepapers
• by/if/inタブ: If: qtr <= tq(1978q4)
図 2 varダイアログ – by/if/inタブ
dln_consump 7 .009445 0.2513 24.50031 0.0004
dln_inc 7 .011719 0.1142 9.410683 0.1518
dln_inv 7 .046148 0.1286 10.76961 0.0958
Equation Parms RMSE Rsq chi2 P>chi2
Det(Sigma_ml) = 1.23e11 SBIC = 15.37691
FPE = 2.18e11 HQIC = 15.77323
Log likelihood = 606.307 AIC = 16.03581
Sample: 1960q4 1978q4 No. of obs = 73
Vector autoregression
. var dln_inv dln_inc dln_consump if qtr <= tq(1978q4), lags(1/2)
11

Stata12 whitepapers
_cons .0129258 .0033523 3.86 0.000 .0063554 .0194962
L2. .0222264 .1294296 0.17 0.864 .2759039 .231451
L1. .2639695 .1292766 2.04 0.041 .517347 .010592
dln_consump
L2. .3549135 .1040292 3.41 0.001 .1510199 .558807
L1. .2248134 .1061884 2.12 0.034 .0166879 .4329389
dln_inc
L2. .0338806 .0243072 1.39 0.163 .0137607 .0815219
L1. .002423 .0244142 0.10 0.921 .050274 .045428
dln_inv
dln_consump
_cons .0157672 .0041596 3.79 0.000 .0076146 .0239198
L2. .0102 .1605968 0.06 0.949 .3249639 .3045639
L1. .2884992 .1604069 1.80 0.072 .0258926 .6028909
dln_consump
L2. .0191634 .1290799 0.15 0.882 .2338285 .2721552
L1. .1527311 .131759 1.16 0.246 .4109741 .1055118
dln_inc
L2. .0500302 .0301605 1.66 0.097 .0090833 .1091437
L1. .0439309 .0302933 1.45 0.147 .0154427 .1033046
dln_inv
dln_inc
_cons .0167221 .0163796 1.02 0.307 .0488257 .0153814
L2. .9344001 .6324034 1.48 0.140 .3050877 2.173888
L1. .9612288 .6316557 1.52 0.128 .2767936 2.199251
dln_consump
L2. .1146009 .508295 0.23 0.822 .881639 1.110841
L1. .1459851 .5188451 0.28 0.778 .8709326 1.162903
dln_inc
L2. .1605508 .118767 1.35 0.176 .39333 .0722283
L1. .3196318 .1192898 2.68 0.007 .5534355 .0858282
dln_inv
dln_inv
Coef. Std. Err. z P>|z| [95% Conf. Interval]
12

Stata12 whitepapers
モデル式 (M1)との対応で言えば次のようなパラメータ値が推定されたことになります。a(1)11 a
(1)12 a
(1)13
a(1)21 a
(1)22 a
(1)23
a(1)31 a
(1)32 a
(1)33
=
−0.320 0.146 0.9610.044 −0.153 0.288−0.002 0.225 −0.264
a(2)11 a
(2)12 a
(2)13
a(2)21 a
(2)22 a
(2)23
a(2)31 a
(2)32 a
(2)33
=
−0.161 0.115 0.9340.050 0.019 −0.0100.034 0.355 −0.022
v1
v2
v3
=
−0.0170.0160.013
なお、これらの点推定値以外にそれぞれに対する p値についても注意を払う必要があります。例えば dln inv
に関する方程式について言えば有意なのは a(1)11 のみであり、残る a
(2)11 , a
(1)12 , a
(2)12 , a
(1)13 , a
(2)13 , v1 については 0で
ある可能性を否定できないからです。制約を課した状態での VARのフィットについてはセクション 2.3を参
照してください。
一方、Σの推定値については e(Sigma)という形でアクセスすることが可能です。
. matrix list e(Sigma) *3
dln_consump .00011142 .00005557 .00008065
dln_inc .00006475 .00012417
dln_inv .00192542
dln_inv dln_inc dln_consump
symmetric e(Sigma)[3,3]
. matrix list e(Sigma)
2.2 外生変数を含むモデル
評価版では割愛しています。
2.3 制約を含むモデル
評価版では割愛しています。
*3 推定コマンドからの出力内容は ereturn listとコマンド入力することによって確認できます。
13

Stata12 whitepapers
3. var関連推定後機能
varコマンドに関連した postestimation機能には次のようなものがあります。
# 区分 機能 コマンド
1 診断 ラグ次数選択 varsoc
残差自己相関 varlmar
安定性 varstable
擾乱の正規性 varnorm
Granger因果性 vargranger
lag-exclusion varwle
2 予測 1ステップ予測 predict
動的予測 fcast compute/graph
3 IRF分析 IRF/DM/FEVD irf
¥
14

Stata12 whitepapers
mwp-008
vec intro - ベクトル誤差修正モデルの概要
Stataにはベクトル誤差修正モデル (VECM: vector error-correction models) に関連したコマンドが一式用
意されています。本 whitepaperではそれら VECM関連機能に関する全般的な解説と用例の紹介を行います。
個々のコマンドに関する機能概要と用例についてはそれぞれ別個の whitepaperをご参照ください。
1. Granger表現定理
2. トレンドの扱い
3. VECMの用例
3.1 ラグ次数の選択
3.2 共和分ランクの推定
3.3 VECMのフィット
3.4 Johansenの基準化
3.5 推定後機能
3.6 インパルス応答解析
3.7 VECMによる予測
補足1
1. Granger表現定理
VECMの概念を規定する前にいくつかの用語の定義をしておきます。
弱定常性(共分散定常性): 時系列 yt において、任意の tと k に対して
E(yt) = µ
Cov(yt, yt−k) = E[(yt − µ)(yt−k − µ)] = γk
が成立する場合、過程は弱定常 (weak stationary)、または共分散定常 (covariance stationary) である
と言われる。
単位根過程: 原系列 yt は非定常過程であるが、その差分を取った系列 ∆yt = yt − yt−1 が定常過程である
とき、過程は単位根過程 (unit root process) と言われ、yt ∼ I(1)と表記される。
和分過程: d − 1階以下の差分を取った系列は非定常過程であるが、d階差分を取った系列が定常過程とな
るとき、その過程は d次和分過程 (integrated process) と呼ばれ、I(d)過程と表記される。なお、I(0)
過程は定常過程と定義される。
c⃝ Copyright Math工房; 一部 c⃝ Copyright StataCorp LP (used with permission)
15

Stata12 whitepapers
共和分: yt は I(1)過程であるとする。c′yt ∼ I(0)となるような cが存在するとき、yt には共和分 (co-
integration) の関係がある、または yt は共和分している (cointegrated) と言う。このとき cは共和分
ベクトル(cointegrating vector) と呼ばれる。
それでは本題の Granger表現定理 (Granger representation theorem) に入ります。
Granger表現定理: [TS] vec intro p626 の (7)で定義される K 変量 VAR(p)過程が共和分関係を有す
る I(1)過程であるとしたとき、yt は [TS] vec intro p626 の (8)で示されるような VECM形式で
表現できる。
今、yt に r 個の共和分関係があるとするとΠ(K × K 行列)は αβ′(共に K × r 行列)のように分解され
ます。β′ は共和分ベクトルを、β′yt ∼ I(0)は r 個の共和分関係を表すことになります。また αは補正パラ
メータ (adjustment parameters) と呼ばれます。
2. トレンドの扱い
vecは線形のトレンドを含むモデルにも対応しています。実際、vecコマンドの Modelダイアログ上ではト
レンドを規定する項が 5種類用意されています。
図 1 vecダイアログ - Modelタブ
16

Stata12 whitepapers
定数項と線形トレンドを含んだモデルの場合、[TS] vec intro p626 の (8)式は p627 の (9)式のような
形になります。これをさらに変形したものが (11)式ですが、そこに含まれるパラメータ µ, ρ, γ, τ に対する制
約のかけ方によって 5種類のトレンドが規定されることになります。詳しくは [TS] vec intro のセクション
“Trends in the Johansen VECM framework” p627 をご参照ください。
3. VECMの用例
本セクションにおいては Exampleデータセット txhprice.dtaを用いて VEC関連コマンドの用法を説明し
ます。
. use http://www.stata-press.com/data/r12/txhprice *1
このデータセット中にはテキサス州 4都市 — Austin, Dallas, Houston, San Antonio — における住宅価格
対数値の推移が月単位に記録されています。
168. 2003m12 12.25200158 12.17303279 12.10625231 11.85296277
167. 2003m11 12.19551713 12.15898104 12.06968002 11.84438516
166. 2003m10 12.19955143 12.14046689 12.05117168 11.78524006
165. 2003m9 12.14579171 12.16837078 12.04590389 11.80931948
4. 1990m4 11.11393932 11.62625415 11.442503 11.39863632
3. 1990m3 11.36442546 11.60550465 11.39188714 11.29849385
2. 1990m2 11.39639165 11.62803827 11.41861479 11.22257316
1. 1990m1 11.40422605 11.6324847 11.38849539 11.19134184
t austin dallas houston sa
これらの変数をグラフ化すると次のようになります。価格はすべて対数値です。
*1 メニュー操作:File ◃ Example Datasets ◃ Stata 12 manual datasets と操作、Time-Series Reference Manual [TS] の vec
intro の項よりダウンロードする。
17
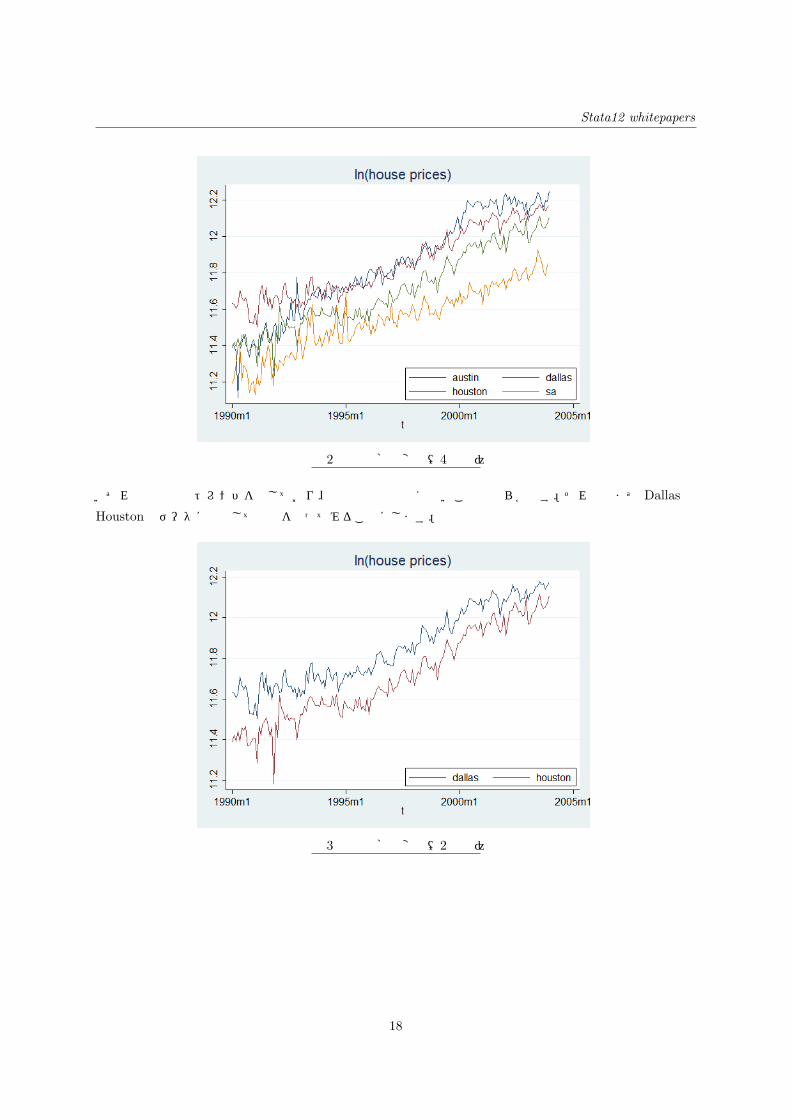
Stata12 whitepapers
図 2 住宅価格の変動(4都市)
いずれの時系列もトレンドを示しており、定常過程とは言えないことは明らかです。それではまず Dallasと
Houstonのデータに着目して分析を行ってみることにします。
図 3 住宅価格の変動(2都市)
18

Stata12 whitepapers
3.1 ラグ次数の選択
varコマンドにしろ vecコマンドにしろ、モデルフィットを行う際にはモデルに含めるべきラグ次数を明示
する必要があります。varsocコマンドを使用すると推定(モデルフィット)を行う前に適切なラグ次数を確
認することができます。なお、[TS] vec intro p626 の (7)式と (8)式に示されているように、VECMの
次数は VARの次数 pよりも 1つ低くなりますが、この違いを意識する必要はありません。vecコマンドに次
数を指示する場合にもベースとなる VARの次数 pを指定する形となっているからです。
それでは時系列 dallas, houstonを対象にして varsocを実行してみます。
• Statistics ◃ Multivariate time series ◃ VEC diagnostics and tests ◃ Lag-order selection statistics
(preestimation) と操作
• Mainタブ: Dependent variables: dallas houston
Options: Maximum lag order: 4 (デフォルト)
図 4 varsocダイアログ- Mainタブ
19

Stata12 whitepapers
Exogenous: _cons
Endogenous: dallas houston
4 596.364 5.8532 4 0.210 3.0e06 7.05322 6.9151 6.71299
3 593.437 4.918 4 0.296 2.9e06 7.06631 6.95888 6.80168
2 590.978 26.991* 4 0.000 2.9e06* 7.0851* 7.00837* 6.89608*
1 577.483 555.92 4 0.000 3.2e06 6.9693 6.92326 6.85589
0 299.525 .000091 3.62835 3.61301 3.59055
lag LL LR df p FPE AIC HQIC SBIC
Sample: 1990m5 2003m12 Number of obs = 164
Selectionorder criteria
. varsoc dallas houston
尤度比 (LR: likelihood ratio) 検定等、種々の手法による評価結果が LRや FPEと表示された列に表示されて
いるわけですが、モデルに含めるに際して適切と判断されるラグ次数には“*”の印が付されています。従って
この 2変量モデルの場合にはラグ次数として 2が適当であると判断されるわけです。
一方、4都市すべてを対象にした場合には次のような結果となるため、4変量モデルではラグ次数 3が適切と
判断されます。
. varsoc dallas houston austin sa
Exogenous: _cons
Endogenous: dallas houston austin sa
4 1185.84 20.339 16 0.205 1.4e11 13.6322 13.1105 12.3469
3 1175.68 40.378* 16 0.001 1.3e11* 13.7034* 13.3043 12.7205
2 1155.49 52.314 16 0.000 1.4e11 13.6523 13.376* 12.9718
1 1129.33 784.96 16 0.000 1.6e11 13.5284 13.3749 13.1504*
0 736.851 1.5e09 8.93721 8.90651 8.8616
lag LL LR df p FPE AIC HQIC SBIC
Sample: 1990m5 2003m12 Number of obs = 164
Selectionorder criteria
. varsoc dallas houston austin sa
20

Stata12 whitepapers
3.2 共和分ランクの推定
VECMのフィットを行う場合には vecダイアログ(図 1参照)からもわかるように、共和分ランク(共和分
関係にある方程式の数)の指定も必要となります。vecrankを使うとその推定を行うことができます。
• Statistics ◃ Multivariate time series ◃ Cointegrating rank of a VECM と操作
• Modelタブ: Dependent variables: dallas houston
図 5 vecrankダイアログ - Modelタブ
2 10 599.67706 0.00107
1 9 599.58781 0.24498 0.1785* 3.76
0 6 576.26444 . 46.8252 15.41
rank parms LL eigenvalue statistic value
maximum trace critical
5%
Sample: 1990m3 2003m12 Lags = 2
Trend: constant Number of obs = 166
Johansen tests for cointegration
. vecrank dallas houston, trend(constant)
共和分ランクの推定にはいくつかの手法が選択できますが、デフォルトでは Johansenのトレース統計量に基
づく手法が用いられ、その結果は“*”印によって表示されます。ここで対象とした 2変量モデルの場合、ラン
クは 1、すなわち共和分方程式が 1つ存在するものと判断されます。
一方、4変量モデルに vecrankを適用した場合にはランク 2という結果が得られます。
21

Stata12 whitepapers
. vecrank austin dallas houston sa, lag(3)
4 52 1158.5868 0.00203
3 51 1158.4191 0.05624 0.3354 3.76
2 48 1153.6435 0.17524 9.8865* 15.41
1 43 1137.7484 0.30456 41.6768 29.68
0 36 1107.7833 . 101.6070 47.21
rank parms LL eigenvalue statistic value
maximum trace critical
5%
Sample: 1990m4 2003m12 Lags = 3
Trend: constant Number of obs = 165
Johansen tests for cointegration
. vecrank austin dallas houston sa, lag(3)
3.3 VECMのフィット
セクション 3.1、セクション 3.2の結果に基づき、1つの共和分方程式の存在を前提にラグ次数 1/2の VECモ
デルをフィットさせることにします。なお、yt = (dallas, houston)′ としたとき、フィット対象のモデル式
は成分表示で書くと次のようになります。(∆y1t
∆y2t
)=
(v1
v2
)+
(α1
α2
) (β1 β2
)(y1,t−1
y2,t−1
)+
(γ11 γ12
γ21 γ22
)(∆y1,t−1
∆y2,t−1
)+
(ε1t
ε2t
)(M1)
• Statistics ◃ Multivariate time series ◃ Vector error-correction model (VECM) と操作
• Modelタブ: Dependent variables: dallas houston
Number of cointegrating equations (rank): 1 (デフォルト)
Maximum lag to be included in underlying VAR model: 2 (デフォルト)
Trend specification: constant (デフォルト)*2
*2 トレンドの設定については補足1を参照。
22

Stata12 whitepapers
図 6 vecダイアログ - Modelタブ
D_houston 4 .045348 0.3737 96.66399 0.0000
D_dallas 4 .038546 0.1692 32.98959 0.0000
Equation Parms RMSE Rsq chi2 P>chi2
Det(Sigma_ml) = 2.50e06 SBIC = 6.946794
Log likelihood = 599.5878 HQIC = 7.04703
AIC = 7.115516
Sample: 1990m3 2003m12 No. of obs = 166
Vector errorcorrection model
. vec dallas houston, trend(constant)
23

Stata12 whitepapers
_cons 1.688897 . . . . .
houston .8675936 .0214231 40.50 0.000 .9095821 .825605
dallas 1 . . . . .
_ce1
beta Coef. Std. Err. z P>|z| [95% Conf. Interval]
Johansen normalization restriction imposed
Identification: beta is exactly identified
_ce1 1 1640.088 0.0000
Equation Parms chi2 P>chi2
Cointegrating equations
_cons .0033928 .0035695 0.95 0.342 .0036034 .010389
LD. .3328437 .07657 4.35 0.000 .4829181 .1827693
houston
LD. .0619653 .1034547 0.60 0.549 .2647327 .1408022
dallas
L1. .5027143 .1068838 4.70 0.000 .2932258 .7122028
_ce1
D_houston
_cons .0056128 .0030341 1.85 0.064 .0003339 .0115595
LD. .0998368 .0650838 1.53 0.125 .2273988 .0277251
houston
LD. .1647304 .0879356 1.87 0.061 .337081 .0076202
dallas
L1. .3038799 .0908504 3.34 0.001 .4819434 .1258165
_ce1
D_dallas
Coef. Std. Err. z P>|z| [95% Conf. Interval]
24

Stata12 whitepapers
vecからの出力結果中にある ceという表示は共和分方程式を意味する cointegrating equations の略です。そ
の実体をなす β の推定値は最後のテーブル中に表示されています。すなわちこの 2変量 VECM(1)モデルの
共和分ベクトルは (β̂1
β̂2
)=
(1
−0.868
)であり
y1t − 0.868 · y2t − 1.689 (M2)
が定常時系列 I(0)となることが示唆されているわけです。
一方、調整係数 (adjustment coefficients) αを含む他のパラメータについては方程式別にメインのテーブル
中に表示されています。抽出すると次のようになります。(α̂1
α̂2
)=
(−0.3040.503
) (v̂1
v̂2
)=
(0.00560.0034
) (γ̂11 γ̂12
γ̂21 γ̂22
)=
(−0.165 −0.0998−0.062 −0.333
)(M2)式で規定される共和分方程式の値がほぼ一定と言えるかどうかは VECMを評価する上での 1つのポイ
ントとなります。詳しい手順はセクション 3.5 に記すとして、ここではグラフだけを掲載しておきます。な
お、y 軸のスケールは図 3に合せてあります。
. predict ce, ce equation( ce1)
. twoway (line ce t), yscale(range(-0.5 0.5)) yline(0) ylabel(-0.4(0.2)0.4)
25

Stata12 whitepapers
3.4 Johansenの基準化
評価版では割愛しています。
3.5 推定後機能
(1) predict
いかなる推定の場合でもモデルの妥当性の検証は大切ですが、特に VECMの場合には共和分関係が適正に維
持されているかどうかをチェックすることは必須のステップと言えます。predictコマンドを使用すると共
和分方程式の予測値を算出することができます。
• Statistics ◃ Postestimation ◃ Predictions, residuals, etc. と操作
• Mainタブ: New variable name: ce1
Produce: Prediction of cointegrating equation: XEquation to predict: ce1
図 8 predictダイアログ - Mainタブ
. predict ce1, ce equation(_ce1)
同様の操作を方程式 ce2に対しても繰り返します。
. predict ce2, ce equation( ce2)
. predict ce2, ce equation(_ce2)
26

Stata12 whitepapers
生成された予測値 ce1, ce2の値をプロットすると次のようになります。
. twoway (line ce1 t), yscale(range(-0.5 0.5)) yline(0) ylabel(-0.4(0.2)0.4)
> title(" ce1") *3
. twoway (line ce2 t), yscale(range(-0.5 0.5)) yline(0) ylabel(-0.4(0.2)0.4)
> title(" ce2")
方程式 ce1における 2000年以降の負のトレンドは少々気になるところかも知れません。
*3 メニュー操作: Graphics ◃ Twoway graph (scatter, line, etc.)
27

Stata12 whitepapers
(2) vecstable
評価版では割愛しています。
(3) veclmar
評価版では割愛しています。
(4) vecnorm
評価版では割愛しています。
3.6 インパルス応答解析
評価版では割愛しています。
3.7 VECMによる予測
評価版では割愛しています。
補足1 – トレンドの設定
評価版では割愛しています。
¥
28

Stata12 whitepapers
mwp-006
irf - IRF系コマンドの用法
irf系のコマンドは var, svar, vecによる推定実施後に行われるインパルス応答関数や予測誤差分散分解を
用いた解析を支援するための機能を提供します。irf関連のコマンドには 10種類ほどありますが、ここでは
基本となる次の 3つについてその用法を紹介します。
◦ irf set – IRF分析用のファイルを作成しアクティブにする
◦ irf create – IRF分析データを生成しアクティブファイル中に格納する
◦ irf graph – 分析結果をグラフ化する
なお、本 whitepaperでは VARモデルをフィットさせた後の用例について解説します。VECモデルフィット
後の用例については [TS] vecintro (mwp-008 ) をご参照ください。
1. IRF分析
2. Cholesky ordering
3. DM分析
4. FEVD分析
1. IRF分析
インパルス応答関数 (IRF: impulse response function) とは、1 つの内生変数におけるショック(イノベー
ション)が他の内生変数、及び自分自身にどのような影響を及ぼすかを調べる手法です。今、外生変数を含ま
ない VAR(p)モデルについて考えることにすると、そのモデル式は [TS] irf create p180 の (1)式のよう
に表現されます。この場合、やっかいなのは分散共分散行列 Σが対角行列ではないという点にあります。こ
のため特定の内生変数に対してのみショックを加え、他の内生変数は一定に保つといった操作がこのままでは
行えません。通常 IRF分析には直交化 IRF (orthogonalized IRF) が用いられますが、その背景にあるのはコ
レスキー分解 (Cholesky decomposition) を介して Σを対角化しようという考え方です。詳しいプロセスに
ついては [TS] irf create p180-181 をご参照ください。
c⃝ Copyright Math工房; 一部 c⃝ Copyright StataCorp LP (used with permission)
29

Stata12 whitepapers
(1) VARのフィット
IRF分析に先立ちまず VARのフィットを行います。使用するのは Exampleデータセット lutkepohl2.dta
です。
. use http://www.stata-press.com/data/r12/lutkepohl2 *1
(Quarterly SA West German macro data, Bil DM, from Lutkepohl 1993 Table E.1)
データセット中の変数 dln inv, dln inc, dln consump を対象に 3 変量 VAR(2) モデルをフィットさせま
す。データセットの内容については mwp-004 をご参照ください。
. var dln inv dln inc dln consump if qtr<=tq(1978q4), lags(1/2) dfk*2
_cons .0167221 .0172264 0.97 0.332 .0504852 .0170409
L2. .9344001 .6650949 1.40 0.160 .369162 2.237962
L1. .9612288 .6643086 1.45 0.148 .3407922 2.26325
dln_consump
L2. .1146009 .5345709 0.21 0.830 .9331388 1.162341
L1. .1459851 .5456664 0.27 0.789 .9235013 1.215472
dln_inc
L2. .1605508 .1249066 1.29 0.199 .4053633 .0842616
L1. .3196318 .1254564 2.55 0.011 .5655218 .0737419
dln_inv
dln_inv
Coef. Std. Err. z P>|z| [95% Conf. Interval]
dln_consump 7 .009445 0.2513 22.15096 0.0011
dln_inc 7 .011719 0.1142 8.508289 0.2032
dln_inv 7 .046148 0.1286 9.736909 0.1362
Equation Parms RMSE Rsq chi2 P>chi2
Det(Sigma_ml) = 1.23e11 SBIC = 15.37691
FPE = 2.18e11 HQIC = 15.77323
Log likelihood = 606.307 AIC = 16.03581
Sample: 1960q4 1978q4 No. of obs = 73
Vector autoregression
. var dln_inv dln_inc dln_consump if qtr<=tq(1978q4), lags(1/2) dfk
*1 メニュー操作:File ◃ Example Datasets ◃ Stata 12 manual datasets と操作、Time-Series Reference Manual [TS] の irf の項よりダウンロードする。
*2 メニュー操作: Statistics ◃ Multivariate time series ◃ Vector autoregression (VAR)
30
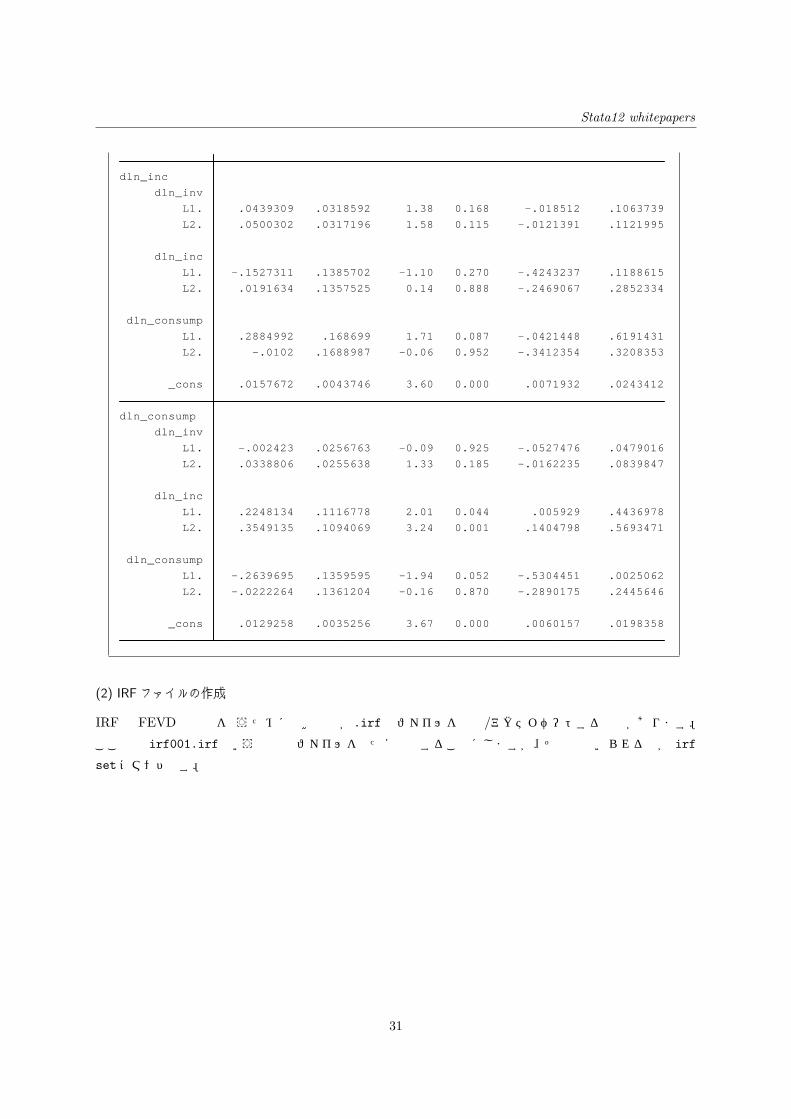
Stata12 whitepapers
_cons .0129258 .0035256 3.67 0.000 .0060157 .0198358
L2. .0222264 .1361204 0.16 0.870 .2890175 .2445646
L1. .2639695 .1359595 1.94 0.052 .5304451 .0025062
dln_consump
L2. .3549135 .1094069 3.24 0.001 .1404798 .5693471
L1. .2248134 .1116778 2.01 0.044 .005929 .4436978
dln_inc
L2. .0338806 .0255638 1.33 0.185 .0162235 .0839847
L1. .002423 .0256763 0.09 0.925 .0527476 .0479016
dln_inv
dln_consump
_cons .0157672 .0043746 3.60 0.000 .0071932 .0243412
L2. .0102 .1688987 0.06 0.952 .3412354 .3208353
L1. .2884992 .168699 1.71 0.087 .0421448 .6191431
dln_consump
L2. .0191634 .1357525 0.14 0.888 .2469067 .2852334
L1. .1527311 .1385702 1.10 0.270 .4243237 .1188615
dln_inc
L2. .0500302 .0317196 1.58 0.115 .0121391 .1121995
L1. .0439309 .0318592 1.38 0.168 .018512 .1063739
dln_inv
dln_inc
(2) IRFファイルの作成
IRFや FEVDの分析を行うためには拡張子が.irfのファイルを作成/アクティベートする必要があります。
ここでは irf001.irf という名称のファイルを新たに作成することにしますが、その際用いられるのが irf
setコマンドです。
31

Stata12 whitepapers
• Statistics ◃ Multivariate time series ◃ Manage IRF results and files ◃ Set active IRF file と操作
• irf setダイアログ: Set active IRF file: irf001
Replace any existing file with an empty file: X
図 1 irf setダイアログ
(file irf001.irf now active)
(file irf001.irf created)
. irf set "irf001", replace
この操作の場合、irf001.irfというファイルが存在していなければそれが新たに生成され、アクティブな状
態にセットされます。既に存在していた場合、それは空の状態にリセットされた上でアクティブとなります。
なお、ここでの操作のようにパス名を明示しなかった場合には、Stataインストール時に指定した作業用ディ
レクトリが仮定されます。
(3) IRFデータの生成
IRF 分析や FEVD 分析を行うためには最初にまず、irf create コマンドを用いて基盤となる分析データ
を生成しておく必要があります。ここではデータの名称を order1 とする形でコマンドを実行します(なぜ
“order1”という名前にするかはセクション 2で明らかになります)。
• Statistics ◃ Multivariate time series ◃ IRF and FEVD analysis ◃ Obtain IRFs, dynamic-multiplier
functions, and FEVDs と操作
• Mainタブ: Create IRF and store as name: order1
Forecast horizon: 8 (デフォルト)
32

Stata12 whitepapers
図 2 irf createダイアログ - Mainタブ
(file irf001.irf updated)
. irf create order1
計算された結果は irf001.irfファイル中に order1という名前で格納されました。
(4) 直交化 IRFグラフの作成
order1に出力された情報に基づき OIRFのグラフを作成してみます。今の場合、モデルが 3変量 VARモデ
ルなので、インパルスを発生させる側の変数と応答を追跡する側の変数との組合せは 3 × 3 = 9通り存在する
ことになります。デフォルトではこれら 9個のグラフが生成されるわけですが、ここでは入力側を dln inc、
応答側を dln consumpと明示する形でグラフ作成を行ってみます。
• Statistics ◃ Multivariate time series ◃ IRF and FEVD analysis ◃ Graphs by impulse or response と操作
• Mainタブ: Statistics to graph: Orthogonalized impulse-response functions (oirf)
IRF result sets: order1
Impulse variables: dln inc
Response variables: dln consump
33

Stata12 whitepapers
図 3 irf graphダイアログ - Mainタブ
. irf graph oirf, irf(order1) impulse(dln_inc) response(dln_consump)
タイトルにはデータ名、インパルス変数、応答変数の並びが示されています。
34

Stata12 whitepapers
2. Cholesky ordering
評価版では割愛しています。
3. DM分析
評価版では割愛しています。
4. FEVD分析
評価版では割愛しています。
¥
35





![[DSC 2016] 系列活動:李祈均 / 人類行為大數據分析](https://static.fdocuments.net/doc/165x107/58f9a900760da3da068b69e2/dsc-2016--58f9e923328b5.jpg)












