
Toward automated methods of bilingual annotation -...
43
Toward automated methods of bilingual annotation Preparing your Corpus for Archival Storage LSA 2016 Workshop Barbara E. Bullock & Almeida Jacqueline Toribio
Transcript of Toward automated methods of bilingual annotation -...

Toward automated methods of bilingual annotation
Preparing your Corpus for Archival StorageLSA 2016 Workshop
Barbara E. Bullock &Almeida Jacqueline Toribio

Overview
2

Introduction
● The Bilingual Annotation Tasks (BATs) Force
○ Produces language identification models to annotate multilingual texts for overt mixing (or
qualitative transfer, à la Mougeon et al. 2012) √
○ Attempting to extend usage-based probabilistic frameworks to microvariation in contact
varieties to allow us to annotate for covert mixing (or quantitative transfer, à la Szmrecsanyi et
al. to appear )
● Significance
○ The methods and tools to annotate bilingual/contact texts using automatic methods lack the first
crucial step for the enterprise, accurate language identification
○ Success would allow us to move to larger data sets 3

Motivation
4
● Any text may show characteristics of contact, e.g., the spread of anglicisms worldwide (Zenner et al. 2012, 2012, Chesley 2010, Chesley & Baayen 2010)
○ Mixing is gradient/probabilistic—some varieties/speakers show more or less of it
● Language is metadata
○ Users of archival data need to know what languages are represented and how much of each

5

Spanish in Texas Corpus● http://spanishintexas.org/
(Bullock & Toribio 2013)○ Transcribed, annotated video archive
○ Research tab■ Methodology for collection
■ Full corpus, downloadable in
multiple formats■ Metadata
○ Education tab■ Searchable video clips■ Activities
**Play with it and let us know what you think**
6

Why a big data approach ?
● To examine variation (geo-linguistic, sociolinguistic, typological), we need data—lots of it—and the tools for effectively annotating it, particularly when overtly mixed forms are present
● We need lots of data because contact phenomena, though salient, are often pretty sparse in a corpus
○ e.g., 2.5 million word Ottawa-Hull Corpus analyzed in seminal Poplack et al. (1988) comprised
0.83% borrowings from English into French
7

Computational challenges of mixed language data● Monolingual texts
○ Open-source tools available for only a few languages
■ Stanford Log-linear Part-Of-Speech Tagger
■ Treetagger
■ C&C parser
● Multilingual texts ○ Require two or more systems
○ Overlap between two languages → homographs (often high-frequency)
8
No, there isn’t a sale. No sale a bailar
She opens the elevator door y sale.

Attempts to study multilingual corpora● LIDES/LIPPS Group (Barnett et al. 2000)
● BilingBank http://www.talkbank.org/
● Contacts de Langues: Analyses Plurifactorielles (CLAPOTY) ○ Isabelle Léglise (CNRS SEDYL/CELIA) - http://clapoty.vjf.cnrs.fr/index.html
● Bangor Autoglosser (Donnelly & Deuchar 2011)
● HLVC [Variation and Change in Toronto’s Heritage Languages] (Nagy & Łyskawa 2016)
9

Studying multilingual data: Traditionally
● Manual annotation for language
● Assumption of a base/matrix language
● Discrete categorization of different contact features○ established borrowings (vs. single word code-switch and nonce borrowing)
■ mon chum
○ syntactic or semantic calques (vs. dialectal extensions of existing patterns in a language)
■ take a coffee < have coffee
■ registrarse ‘to register (for a class)
○ the language of proper names (Named Entity)
■ Robert
10

Why automate?● Consistency of annotation● Eliminate obstacles of cost and time● Eliminate errors/biases introduced by manual coding● Increase accountability through replicability● Process other people’s data to create open resources √● Accelerate production of findings● Encourage collaboration
11

Bilingual Annotation Tasks (BATs) Force/|\ (°v°)/|\
12

Goals for today● Demonstrate that it is possible to automatically identify the languages in a data
set without the need for manual tagging
● Demonstrate what we can learn about language use from the ability to language tag a corpus:○ Apply quick metrics to calculate the degree to which a text is structurally mixed so that it can be
compared with other texts
○ Model language use per speaker and location
13

14
A first step: written corpus
● Killer Crónicas: Bilingual Memories
○ ~49,000 words
○ colloquial language
○ dialectal forms
○ highly bilingual
○ extensive mixing

Annotation tags for manual Gold Standard
15
Language Tag Example
English years, spontaneous
Non-standard English anygüey, whaat
Spanish brindar, apoyo
Non-standard Spanish cashe, ehcritora
Mixed category closeto, speechecito, taipeando
Named Entities Sophia, Los Angeles, UCLA, The Beatles
Other languages carte blanche, boitjie, sine qua non
Punctuation . ! , ? –

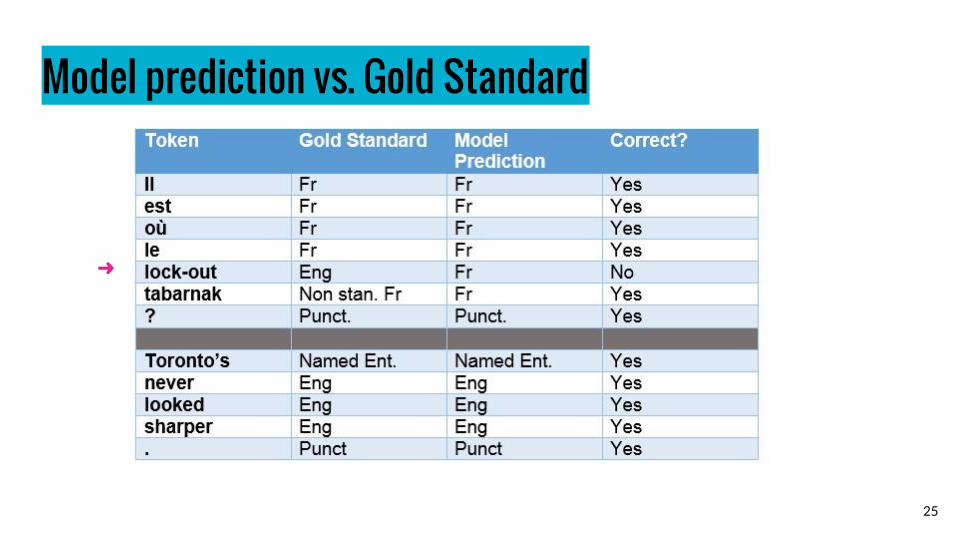
Model prediction vs. Gold Standard
16

A second step: oral corpus
● Bon Cop Bad Cop
○ 13,502 tokens
○ colloquial language
○ dialectal forms
○ extensive mixing
○ highly bilingual
17

Corpus creation 1. Monolingual subtitles: open subtitle.com (English), subsmax. com (French)
18

Corpus creation2. Manually combined the two subtitles to create a transcript
19

Annotation tags for manual Gold Standard
20
Language Tag Example
English years, country
Non-standard English Hopportunity
French frère, ville
Non-standard French mononcle, tabarnak
Named Entities Montréal, Toronto, David
Punctuation . ! , ? –
Number 2001, VII

Example of the Gold Standard
21

Building a language identification model● Numbers and Punctuation
○ Rule-based
● Named Entity
○ Stanford Named Entity Recognizer
● English and French ○ Character Ngram
○ HMM
22

Character N-gram Model● What’s the probability that a given word is English? French?● Model a language using training data (La Presse corpus, CALLHOME corpus)● Identify language of an unknown word based on how often it occurs in training
data● Example:
23

Hidden Markov Model (HMM)● What’s the probability that this word is English, considering that the previous
word was English?● Code-switching is less frequent (therefore less probable) than not switching.
-Me occurs in both English and French training data → ambiguous -Because previous word was English, me is more likely to be English
24
Model prediction vs. Gold Standard
25
➜

Evaluation of our model for Bon Cop Bad Cop
26
Tag Accuracy Precision Recall
English 98.3% 98.3% 96.6%
French 97.5% 97.4% 98.6%
Named Entity 69.4% 78.7% 85.5%
Over-all 97.0%

Characters’ Usage of French Across Cities
27Montréal Toronto

Predicting mixing by character and location
28
● Relative to Martin WArd …○ Others: not a significant predictor
○ David Bouchard: 15 times more likely to use French
○ Tattoo Killer: 1.6 times more likely to use English
● Relative to Toronto○ In Montréal: 8 times more likely to use French

Bilingual metric
29
● The M-metric is developed by the LIPPS Group (2000)
where,
k=total number of languages/categories
pj=total number of words in the given language over total words in the corpus
● The metric allows us to determine how bilingual a text is: the closer the value is
to 1, the more ‘bilingual’ the text

M-metric
30
Killer Crónicas Overall 0.997
Bon Cop Bad Cop Overall 0.71
Toronto 0.41
Montreal 0.60
David Bouchard 0.50
Martin Ward 0.77
Tattoo Killer 0.84

Switch points, based on language identification only
31
Types of Switches Example
Eng to French He has had an unfortunate contretemps
French to English On peut aller demander à ses partners
Punct. only Hey, where you going?Chez nous.
Named Ent. and Punct. Bye, Patrick. Merci d'avoir appelé.

Switch Pattern
32
Over ⅔ of direct switches involved single word borrowings (eg. ses affaires cheap américaines)
Direct Switches
Indirect Switches
Indirect Switches

Discussion and Conclusions
33

What we’ve achieved● Presented a profile of language switching in a bilingual text, based only on
language identification ○ locale
○ speaker
● Demonstrated that it is possible to automatically identify language switches without manually coding all the data○ with a high degree of accuracy: 97%
● Calculated the degree to which segments of the corpus are mixed and how they are mixed○ M score of .71 for overall mixing, where 1 = perfectly mixed
34

What we’ve learned about who switches, where
● Context matters— a lot
■ In Toronto, only the Québécois cop (Bouchard) uses French; all others perform in English
■ In Montreal, the Torontonian cop (Ward) and Tattoo Killer perform bilingually
● Speaker matters— a lot
■ The most bilingual character appears to be Tattoo Killer
■ The least is the Québécois cop, Bouchard
35

What else we’ve learned about who switches● The anglophone speakers accommodate more to the francophone than vice
versa.○ Given the politics of language in Quebec with regard to French language maintenance, and the
fact that the director and producer of the film are Québécois, this might not be surprising.
36

What we’ve learned about how they switch
● Most switching coincides with punctuation, indicating○ a change in speaker turn
○ or a switch at a phrasal boundary
● Within a phrase○ nearly balanced French↔English
37

Where we are going now
1. Apply procedure to Spanish in Texas Corpus
2. Lemma and POS tagging of bilingual data to further investigate the direct, overt switches
3. Developing HMM models for covert (quantitative mixing)a. requires more computational power but do-able using NLP techniques for native language
identification (Jarvis & Creswell 2012 on transfer in SLA)
4. Creating a web interface so others can upload their training data to language tag their own multilingual corpora
38

ConclusionsThis work shows how NLP tools can be fruitfully recruited to shed light on contemporary mixed language use
http://tinyurl.com/pxn2l4q
39

Recommendations● Code for language (even if working with ‘monolingual’ text)● Code conservatively (e.g., no distinction between nonce borrowing and CS)● Share your data and annotations
40

Thanks● To our BATs Force
○ Kelsey Ball ○ Gualberto Guzman ○ Rozen Neupane○ Kris Novak ○ Jacqueline Larsen Serigos
● To ...○ Susana Chávez Silverman○ Dan Garrett ○ Thamar Solorio ○ Ramesh Yerraballi
● And to ...○ Malcah & Chris!
41
Barbara: [email protected]: [email protected]

Bibliography● Abney, S. P. (1992). Parsing by chunks. Springer. ● Barnett, R et al. (2000). The LIDES coding manual: A document for preparing and analyzing language interaction data
Version 1.1: International Journal of Bilingualism 4(2): 131-271.● Chesley, P. (2010). Lexical borrowings in French: Anglicisms as a separate phenomenon. Journal of French Language
Studies, 20(03), 231–251.● Chesley, P., & Baayen, R. H. (2010). Predicting new words from newer words: Lexical borrowings in French. Linguistics,
48(6), 1343–1374.● Donnelly, K & Deuchar, M. (2011). Using constraint grammar in the Bangor Autoglosser to disambiguate multilingual
spoken text. Constraint Grammar Applications: Proceedings of the NODALIDA 2011 Workshop, Rigva, Latvia 2011: 17-25.
● Jarvis, S., & Crossley, S. A. (2012). Approaching Language Transfer Through Text Classification: Explorations in the Detection based Approach (Vol. 64). Multilingual Matters.
● Onysko, A. (2007). Anglicisms in German: Borrowing, lexical productivity, and written codeswitching (Vol. 23). Walter de Gruyter.
● Poplack, S., & Sankoff, D. (1984). Borrowing: the synchrony of integration. Linguistics, 22(1), 99–136.● Poplack, S., Sankoff, D., & Miller, C. (1988). The social correlates and linguistic processes of lexical borrowing and
assimilation. Linguistics, 26(1), 47–104.
42

Bibliography● Schmid, H. (1994). Probabilistic part-of-speech tagging using decision trees. In Proceedings of the international conference
on new methods in language processing (Vol. 12, pp. 44–49). Manchester, UK. ● Schmid, H. (1995). Improvements in part-of-speech tagging with an application to German. In In Proceedings of the ACL
SIGDAT-Workshop. ● Solorio, T., & Liu, Y. (2008a). Learning to predict code-switching points. In Proceedings of the Conference on Empirical
Methods in Natural Language Processing (pp. 973–981). Association for Computational Linguistics. ● Solorio, T., & Liu, Y. (2008b). Part-of-speech tagging for English-Spanish code-switched text. In Proceedings of the
Conference on Empirical Methods in Natural Language Processing (pp. 1051–1060). Association for Computational Linguistics.
● Szmrecsany, B. Grafmiller, J., Heller, B., & Röthlisberger, M. (To appear). Around the world in three alternations: modeling syntactic variation in varieties of English. English World-Wide 37(2).
● Treffers-Daller, J. (2010). Borrowing. Retrieved from http://eprints.uwe.ac.uk/11789/● van Hout, R., & Muysken, P. (1994). Modeling lexical borrowability. Language Variation and Change, 6(01), 39–62.● Varra, R. M. (2013). The social correlates of lexical borrowing in Spanish in New York City. City University of New York.● Zenner, E., Speelman, D., & Geeraerts, D. (2011). A concept-based approach to measuring the success of loanwords. In
QITL-4-Proceedings of Quantitative Investigations in Theoretical Linguistics 4 (QITL-4). Humboldt-Universität zu Berlin. ● Zenner, E., Speelman, D., & Geeraerts, D. (2012). Cognitive Sociolinguistics meets loanword research: Measuring
variation in the success of anglicisms in Dutch. Cognitive Linguistics, 23(4), 749–792.
43


















