
The Semantic Web, RDF, Ontology & Library Systems Name: Mariaan Smit & Eleta Grimbeek Job Title:...
72
The Semantic Web, RDF, Ontology & Library Systems Name: Mariaan Smit & Eleta Grimbeek Job Title: Metadata Email: [email protected] , [email protected] Tel: 012 643 9500
-
Upload
randolf-johns -
Category
Documents
-
view
221 -
download
2
Transcript of The Semantic Web, RDF, Ontology & Library Systems Name: Mariaan Smit & Eleta Grimbeek Job Title:...

The Semantic Web,
RDF, Ontology &Library Systems
Name: Mariaan Smit & Eleta Grimbeek
Job Title: Metadata
Email: [email protected], [email protected]
Tel: 012 643 9500

Libraries are no longer the first place users search for information Users live in a highly interactive, networked world - turn to Web search
engines for their information needs. This new generation of users finds library OPACs, difficult to use, and unnecessarily limited by a single library's boundaries.
The Internet (especially “ “) changed the
way users get information. To get user attention, we must:• Join the larger world of information. Learn how information attracts users, and take advantage of their
interest.
What is happening?

Metadata based on catalog cards Library software that can’t sort search results better than
“random” or “alphabetic” Search interfaces, even Librarians don’t like (and we know the
data) Static HTML pages that don’t attract interest, or give guidance. Silos for
books, journal articles, images, e-books,
digitized books.
What We Must Leave Behind

How are we going to do it ?
To understand the Semantic Web, RDF, OWL etc.
we must create a pattern of information and form
a knowledge about it.
Symbolic Thinking Tools encourage us to…… form symbolic mental images of our world,
according to Csikszentmihalyi (1990):” ..playing with ideas is exhilarating.”
Technology & abstract conceptsTools

Explore tools and techniques for sharing bibliographic data.
Express library standards in machine-readable and machine-actionable formats, especially developed for use on the Web.
Responsibility of those wanting to build a Semantic Web: look beyond modern library limitations, and Explore functions
that have sustained the library as main custodian of information.
It’s Time to Explore“The Web is the new platform”

New Pieces in the Puzzle
Web 2.0 Semantic Web (Web 3.0) RDF SPARQL OWL SKOS XML ILS
SPARQL
RDF
OWL
WEB
XML

Semantic Web: - Web 3.0
RDF: Resource Description Framework (a W3C standard)
RDF Schema: Vocabulary description language of RDF
SPARQL: The query language of the Semantic Web
OWL: Web Ontology Language
SKOS: Simple Knowledge Organisation System (a W3C standard) An RDF application
ILS: Integrated Library Systems
New words for the pieces

Towards the Semantic Web

Where did it all start?
It all began in 1974 with TCP/IP – the language of communication between computer connections
In 1990 hyperlinks emerge – it interconnected documents and content
The semantic wave embraces the three stages of internet growth. The first stage was, Web 1.0, - connecting information and getting on net. Web 2.0 is about connecting people — putting the “I” in user interface, and
the “we” into a web of social participation. Web 3.0, is starting now. It is about representing meanings, and
connecting knowledge

Web 1.0 Read only web
Mostly flat information
Put content on the web
Netscape
Limited content
Limited creativity
Little engagement or Interactivity
Works but is clunky, not that efficient, technically limited

Web 2.0 Read-write web
Collaboration
Power of Networks
Greater interactivity
User generated content
Growth of social media / social networking/ sharing content
Online communities created / social capital
Smoother experience, looks better
Still lacks cohesion
Connects people


Semantic web
Joining up of information
Data portability
Meaning of data
Technological change
iGoogle
Browsers and search engines become more ‘intelligent’
Greater scope for exploration
Limitless potential, smart
Connects everything
Web 3.0

The Current Web The current Web (Web 2.0) :
Difficult for machine processing Needs only a single program to access it: a browser. Okay for humans set of Resources and Links identified by URL's (Uniform Resource Links)
• It's made with computers but for people. The sites you visit every day use natural language, images and page layout to present information in a way that's easy for you to understand. Even though they are central to creating and maintaining the Web, the computers themselves really can't make sense of all this information. They can't read, see relationships or make decisions like you can.
Exciting world – connects people, building networks

The Current Web


A Logical Extension to the Current Web Machines will be able to consume machine-readable information, better, enabling computers and people to work, learn and exchange knowledge effectively Extensible; Relational Resources and Links are identified by URI's (Uniform Resource Identifiers)
Web 3.0 is powered by semantic technologies.The Semantic Web proposes to help computers "read" and use the Web. The big idea is pretty simple -- metadata added to Web pages can make the existing World Wide Web machine readable. This won't bestow artificial intelligence or make computers self-aware, but it will give machines tools to find, exchange and, to a limited extent, interpret information.
It's an extension of, not a replacement for, the World Wide Web.
The Semantic Web

The term “semantic web” came into existence in 1998 when
Sir Tim Berners-Lee published the “Roadmap to the Semantic Web” on
the homepage of the World Wide Web Consortium (W3C).
The Semantic Web will enhance the existing human-readable Web with structured data that's easy for software to process
It will allow you to find, share, and combine information more easily.
Sir Tim Berners-Lee is the greatest technological pioneer Sir Tim Berners-Lee is the greatest technological pioneer Britain has produced over the last 30 years - and has been Britain has produced over the last 30 years - and has been rewarded with all kinds of honours, from his knighthood, to rewarded with all kinds of honours, from his knighthood, to the Millennium Technology Prize, to Time Magazine's list of the Millennium Technology Prize, to Time Magazine's list of the 100 most influential people of the 20th century.the 100 most influential people of the 20th century.
Overview of the Semantic Web

Meaning of word “Semantics” Semantics = “the meaning of” (meaning behind what you say) Syntax = “study of grammar” (how to say something)
The semantics of something = the meaning of something.
The Semantic Web = “a Web with a meaning”
Purpose Semantic Web = realizing the idea, having data on the Web defined and linked in a way used by machines not for display purposes, but for automation,
integration,
reuse of data across applications.

What is the Semantic Web? A seamless web of all the data in your life.
It is a collection of standard technologies to realize a Web of Data.
Statements are built with syntax rules. The syntax of a language defines the rules for building language statements. But how can syntax become semantic?
This is what the Semantic Web is all about. Describing things in a way that computer applications can
understand.
The Semantic Web is not about links between web pages. The Semantic Web describes relationships between things (like C is a
part of D and R is a member of S) and the properties of things (like size, weight, age)

Goals of the Semantic Web To create a universal medium for the exchange of data.
Data shared and processed by automated tools and by people.
Sir Tim Berners-Lee, inventor of the World Wide Web, said that these tools will let the Web -- currently similar to a giant book -- become a giant database.
To focus on machine consumption.
Enable vocabulary semantics to be defined by communities of expertise.
Ultimate goal - the design of enabling technologies to support machine facilitated global knowledge exchange.

Where is the Semantic Web? The Semantic Web is a web-technology that lives on top of the
existing web, by adding machine-readable information without modifying the existing Web.
The Semantic Web is an evolving extension of the World Wide Web in which the semantics of information and services on the web is defined, making it possible for the web to understand and satisfy the requests of people and machines to use the web content.
The Semantic Web will enhance the existing human-readable Web with structured data that is easy for software to process.
New web-technology emerging …..

Aspects of Miller’s “Library 2.0” / Web 2.0 (2006),
including a move toward a more semantic Web.(Web 3.0) emerging:
Blogs, social media, networking and technologies Tagging: semantic tagging, increasing via folksonomies and social
tagging projects (e.g., Flickr, Del.icio.us, Penn Tags, Facebook). Collaboration: Wikipedia Partnerships between academic and research libraries and
information industry leaders (Google, Yahoo! and Microsoft), Digital content and associated metadata are key commodities.


PennTags PennTags is a social bookmarking tool for locating,
organizing, and sharing favorite online resources.
Members of the Penn Community can collect and maintain URLs, links to journal articles, and records in Franklin, the online catalog and VCat, the online video catalog. Once these resources are compiled, it can be organized by assigning tags (free-text keywords) and/or grouping them into projects, according to your specific preferences.
PennTags was developed by librarians at the University of Pennsylvania.

twitter Twitter is a service for friends, family, and co–workers
to communicate and stay connected through the exchange of quick, frequent answers to one simple question: What are you doing?
What are you doing?
Latest: I am working on a presentation for the RDA Lecture Series on the 22 July 2009 less than a minute ago from web

Flickr & Library of CongressFor the Common Good: The Library of Congress, Flickr Pilot Project Historical photographs were made public on a Library account on Flickr photosharing site. The response of the pilot was overwhelmingly positive.
Statistics shows the popularity & impact of the pilot: October 23, 2008 = 10.4 million views of the photos on Flickr. 67,176 tags added by 2,518 unique Flickr accounts.
The Flickr project increases awareness of the Library and its collections; sparks creative interaction with collections; provides LC staff with experience with social tagging and Web 2.0 project increased the reach of Library content & demonstrated the many kinds of creative interactions that are possible, accessing collections within their own Web communities.

The LibraryThing LibraryThing = social cataloging web application –
storing and sharing personal library catalogs and book lists.
March 2009 = 650,000 users, 37 million books cataloged.
Users : informally known as thingamabrarians, can catalog personal collections, keep reading lists, post book reviews, & chat to other users who have the same books.
Thingamabrarians can browse the entire database by searching titles, authors, or tags generated by users as they enter books into their libraries.
LibraryThing's social features define it as a Web 2.0 application.
Can be compared to bookmark manager Del.icio.us and the Collaborative music service Last.fm.

1996
2015 ?
2009
Web 3.0
Web was all about read-only content and static HTML websites. People preferred navigating the web through link directories of Yahoo!
User-generated content and the read-write web. People are consuming as well as contributing information through blogs or sites like Flickr, YouTube, Digg, etc.
This will be about semantic web (or the meaning of data), personalization (e.g. iGoogle), intelligent search and behavioral advertising among other things.

Libraries and the Semantic Web Libraries are defined by the following primary functions: collection development,
cataloging, reference, and circulation.
Primary library functions may also be valuable for developing the Semantic Web.
The Semantic Web, is quite similar to the library for the following reasons:
has developed, in part, as a response to an abundance of information. has mission statements grounded in service, information access
& knowledge discovery. has advanced as result of international and national standards. has grown due to a collaborative spirit.
The similarities is quite strong, further justifying the need for an inquiry on the applicability of library functions for developing the Semantic Web.

Librarians and the Semantic Web The majority of Semantic Web documentation presents technical
standards or hypothetical scenarios, is currently not possible, which makes it difficult for librarians to determine where their skills and knowledge can aid Semantic Web development.
The Semantic Web/library “gap,” it seems, could be reduced if librarians
could explore beyond their current domain and consider how their skills are needed.
Continued efforts may bridge the Semantic Web/library gap and lead to new opportunities for both communities.

Technologies/Structure of the
Copyright: http://www.w3.org/2007/10/sw-logos.html

The Semantic Web is a layered structure.
Consists of:
A global naming scheme (URIs)
(XML) that forms the basis, being the transport syntax. (RDF) provides the information representation framework.
A standard means of describing the properties of that data (RDF Schema).
On top of this layer, a standard means of describing relationships between
data items, schemas and ontologies provide the logical apparatus necessary for the expression of vocabularies, enabling intelligent processing of information.
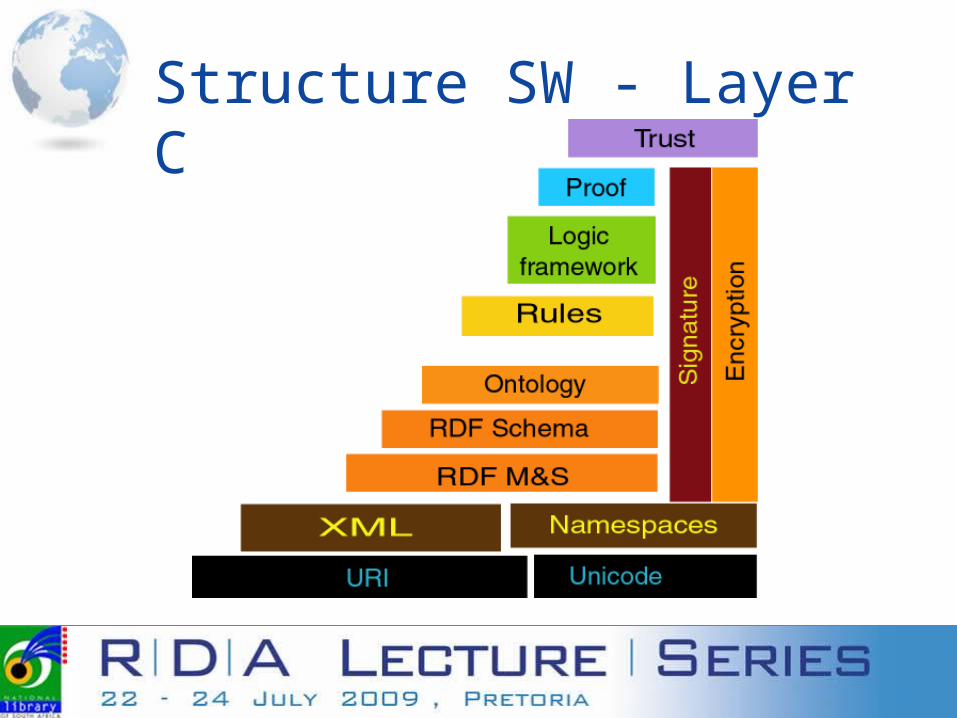
Structure SW - Layer Cake

URI & XML
… the first layer of the semantic web

URI: Global Naming scheme
Web naming/addressing technology: URIs. Uniform Resource Identifiers (URIs, aka URLs) are short strings
that identify resources in the web: URIs (uniform resource identifiers) look like URLs, but they may
not represent an actual web page.
http://www.sabinet.org/contact#Sabinet

EXtensible Markup Language
Is most likely how library systems will evolve after MARC.
• XML is a markup language much like HTML
• XML was designed to carry data, not to display data
• XML tags are not predefined. You must define your own tags
• XML is designed to be self-descriptive
• XML is a W3C Recommendation
It is invisible to the people who read the document but visible to computers
XML

RDF
is the first layer of the semantic web standards
38
“is only for machines”

RDF = Resource Description Framework.
The datamodel of the Semantic Web
Is designed to be read and understood by computers.
Is written in XML
In order to make meaningful statements in RDF, the thing you’re talking about has to be identified in some unique way. – by URIs
What is RDF?

RDFCompose of three basic elements Resources – the things being described Properties – the relationships between things Classes – the buckets used to group the things
Every piece of knowledge is broken down into things in the form of Triplets Subject - The thing that the metadata describes. Predicate - A property the statement describes.
[Predicates are always URIs] Object - The value of the metadata.
<Subject> <Predicate> <Object>
Something Has the Property Characteristic
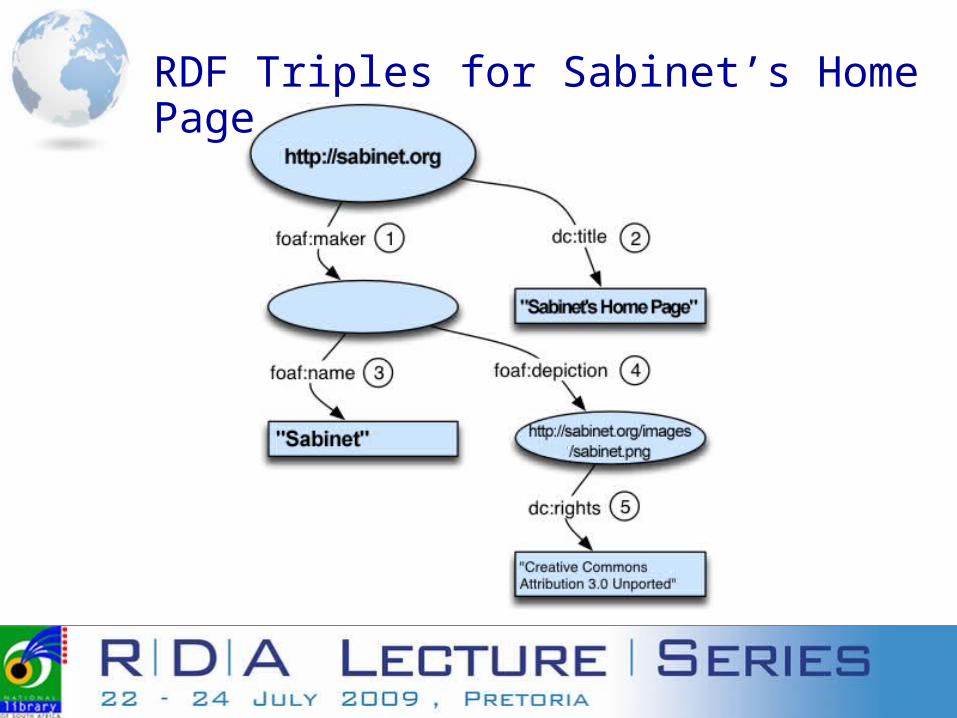
RDF Triples for Sabinet’s Home Page

Example of a RDF Document
<?xml version="1.0"?>
<rdf:RDFxmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:cd="http://www.recshop.fake/cd#">
<rdf:Descriptionrdf:about="http://www.recshop.fake/cd/Empire Burlesque"> <cd:artist>Bob Dylan</cd:artist> <cd:country>USA</cd:country> <cd:company>Columbia</cd:company> <cd:price>10.90</cd:price> <cd:year>1985</cd:year></rdf:Description>
<rdf:Descriptionrdf:about="http://www.recshop.fake/cd/Hide your heart"> <cd:artist>Bonnie Tyler</cd:artist> <cd:country>UK</cd:country> <cd:company>CBS Records</cd:company> <cd:price>9.90</cd:price> <cd:year>1988</cd:year></rdf:Description></rdf:RDF>

RDF Building Blocks
RDF permits you to have metadata about metadata
RDF - is about making machine-processable statements, using a machine-processable language –XML for representing RDF statements
A system of machine-processable identifiers for resources (subjects, predicates, objects):
Uniform Resource Identifier (URI)
It provides a framework to describe resources.
Each component of an RDF statement (triple) is a “resource”

RDF and the Semantic Web
XML and RDF are at the heart of the Semantic Web.
They give computers a structure in which to look for information and define
relationships between resources. Putting information into RDF files, makes it possible for computer
programs ("web spiders") to search, discover, pick up, collect, analyze and
process information from the web.
RDF language is a part of the W3C's “Semantic Web Vision” where : Web information has exact meaning.
Web information can be understood and processed by computers.
Computers can integrate information from the web.

RDF & SW cont….. It is not immediately obvious that the simple statement model of RDF
can be used to make the Semantic Web a reality.
The most fundamental benefit of RDF compared to other meta-data approaches is that using RDF, you can say anything about anything.
If information about music, cars, tickets, etc. were stored in RDF files, intelligent web agents could collect information from many different sources, combine information, and present it to users in a meaningful way.

SPARQL- Query interface
46
?

SPARQL: Accessing the Metadata SPARQL – SPARQL Protocol And RDF Query Language
One of the long-term goals of the Semantic Web is to allow agents, software applications and web applications to access and use metadata. A key tool for doing this is simple protocol & RDF Query Language (SPARQL), which is still in development.
SPARQL's purpose = to extract information from RDF graphs. It can look for data and limit and sort the results.
One of the advantages of the RDF structure is that these queries can be very precise and get very accurate results.
Queries will become very important for distributed RDF data
SELECT ?isbn ?price ?currency # note: not ?x!WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x
p:currency ?currency.}

Ontology

Ontology Language
The first level above RDF required for the Semantic Web is an ontology language to describe the meaning of terminology used in Web documents.
49

Ontology- the O-Word Ontologies are as ancient as human language, but interestingly the very
nature of this branch of philosophy will be required in order for the Web to move from its current state to the promised Semantic Web.
For the web, ontology is about the exact description of web information and relationships between web information.
LIS and cataloguing professionals are familiar with ontology and form the core of their work. The traditional skills of librarianship - thesaurus construction, metadata design, and information organization - are deeply important in the creation of this next stage of Web development.
In general, ontologies aim to represent knowledge rather than describe content.
Additional features allow them to be processed by computers.

What is OWL? OWL is a language for processing web information.
OWL stands for Web Ontology Language Is built on top of RDF
Is not designed for being read by people
Is written in XML By using XML, OWL information can easily be exchanged between different
types of computers using different types of operating system and application languages.
OWL has three sublanguages OWL Lite OWL DL (includes OWL Lite) OWL Full (includes OWL DL)
OWL is a W3C standard

Goals of OWL The natural acronym for Web Ontology Language would be WOL instead of
OWL. Although the character Owl from Winnie the Pooh wrote his name WOL, the acronym OWL was proposed without reference to that character, as an easily pronounced acronym that would yield good logos, suggest wisdom, and honor.
GOALS:
Shared ontologies
Ontology interoperability
Inconsistency detection
Ease of use
XML syntax
Internationalization

Why OWL? OWL = part of the "Semantic Web Vision" - a future where:
Web information has explicit meaning Web information can be processed by computers Computers can integrate information from the web
OWL = Designed for Processing Information To be read by computer applications (instead of humans). To develop ontologies that are compatible with the World Wide Web.
OWL = Different from RDF To provide a common way to process the content of web information (instead of
displaying it). OWL and RDF are much of the same thing, but OWL is a stronger language with
greater machine interpretability than RDF. OWL comes with a larger vocabulary and stronger syntax than RDF.

SKOS Simple Knowledge Organisation Systems
Also based on RDF
Designed specifically to express information that’s more hierarchical – broader terms, narrower terms, preferred terms and other thesaurus-like relationships
Extendable into OWL, if needed
SKOS is built upon RDF and RDFS, and main objective to enable easy publication of controlled structured vocabularies for the Semantic Web.
SKOS = developed within the W3C framework.
Simpler than the more complex ontology language, OWL.

55
Security & Proof The SW requires security measures
to protect data and transactions.
Digital signatures, encryption,
proofs and trust.
Proofs and trust relate to the logic
of the SW and applications'
abilities to verify that data
is correct and consistent
through all the
web's layers.

Conclusion
To complete the puzzle..

People with appropriate skill sets for designing & building Semantic Web People with appropriate skill sets for designing & building Semantic Web solutions are not widely available.solutions are not widely available.
RDF was developed by people with an academic background in logic and artificial intelligence. For traditional developers it is not very easy to understand.
Will it ever be possible to link all these RDF files together and build a semantic web? No one knows, but someone will try.
Might be eBay, Microsoft, Google, or someone else. But someone will.
The SW will need help to become a reality. A search engine database will have to be built for all the items, and a
standard will have to be developed.
Will the SW become a reality?

Why Has It Not Already Been Done?Quite simply, it’s hard to do. (it's hard enough to explain!)
In the 1990’s, a movement towards marking up content with a metadata standard, Dublin Core – a set of 15 common types of information about on-line content intended to help search for material. DC was encoded into RDF, and linked to pages. The expectation was for search engines to look for this extended metadata. It didn’t happen.
What happen was a radically different approach – the Google approach,
- a great tool, using simple keyword extraction and Web linking activity to order links – BUT Metadata was ignored.
Google dominated the search engine scene, and outside specialist portals has, held back the development of more structured information searches.

What Else Will We See? Among other things, Web 2.0 turning the Web from a document-publishing
platform to an application platform. Has gone beyond the original vision.
The Web will retain the on-line world’s primary information resource.
It may take several years and a great deal of work before we realize the benefits of a network of semantic websites.
The Semantic Web will transform the existing human-readable Web with structured data that is easy for software to process.
Open Social Networking (Web 2.0) is a great application in the Web. But again it suffers from the ‘Social Silo Problem’ Users have often accounts in platforms like Facebook/Linked/MySpace. However, they are separated from each other in silos.
The challenge of the Semantic Web Community is now to interconnect the silos via RDF, OWL, HTTP, and SPARQL.

Library Systems

Library Systems at present Today libraries face unusual challenges as non-library entities invade into
traditional library territory.
Library users are more Web savvy than ever and have high expectations for information providers.
What do end users want? Improved search relevance More links to online full text (and make linking easy) More summaries/abstracts: Make summaries more prominent More details in the search results (e.g., cover art and summaries)
There need to be rapid advances in library automation, because a well-
functioning automation system is essential to the operation of the library

Should be capable of relating evaluative data, such as reviews and ratings, to bibliographic records.
Be enhanced to provide the capability to link to appropriate user-added data available via the Internet (e.g., Amazon.com, LibraryThing, Wikipedia).
And be developed so that it can accept user input and other non-library data without interfering with integrity of library-created data.
Investigate methods of categorizing creators of added data in order to enable informed use of user-contributed data without violating the privacy obligations of libraries.
Develop methods to guide user tagging through techniques that suggest entry vocabulary (e.g., term completion, tag clouds).
ILS Vendors should explore opportunities for developing mutually beneficial partnerships with commercial entities that would benefit from arrangements.
A New Look at Library Systems

Cataloging and RDA Written a century before the development of the Web, Charles Cutter’s (1904) objectives
for a library catalog is still applicable to library operations today:
Enable a person to find a book when the author, title, or subject is known; Show what the library has by author, subject, and literature genre; and Assist in the selection of a book by its edition and literary or topical
composition.
Today, digital resource cataloging (metadata creation) is being guided by principles and objectives documented in a variety of metadata schemes. RDA: Resource Description and Access is the new proposed standard for resource
description and access designed for the digital world, and may have the most impact on cataloging in the 21st century
It is important to recognize that RDA intends to provide cataloging guidance well beyond what is presented in communication and encoding standards (e.g., MARC and XML).
Moreover, RDA’s objectives are helping with the development of the Semantic Web.

Cataloging and Semantic Web Similarities between library cataloging and producing metadata for the
Semantic Web are obvious, both deal with representation.
Boundaries between the use of representation standards in the two environments (libraries and the Semantic Web) is artificial.
The representation activity takes place along a continuum, with simple bibliographic representation for search and retrieval on one end, and the implementation of formal ontologies and machine supported deductive reasoning on the other.
What are missing in the context of the SW are principles and objectives for using metadata schemes and an ontological system. -------?
Similar to the library’s community extensive MARC documentation, the SW
provides comprehensive documentation for working with enabling technologies, such as XML, RDF, and OWL but falls short, in providing documentation to guide the use of metadata standards and ontologies.

Impact on ILS Biggest impact that RDA is likely to have – is secondary and that is on
online catalogues. Users will probably not notice much difference, although some
details might change
ILS = Improved integration of metadata content rules and guidance with cataloguing modules.
RDA be published as an online product offering direct access to individual rules, glossary terms and other specific content as well as structured navigation across and within its component parts.
ILS vendors are kept informed of RDA for them to develop their cataloguing workflows and context-sensitive help services – to utilize the functionality of the RDA product

Library Systems and RDA
OCLC's is currently doing experimental work, using OCLC's FRBR clustering algorithms (building on Fiction Finder), to extract this kind of data along with classification and other elements and present it to users at higher level displays.
Millennium - Are keeping an eye on RDA, “But so far there has been nothing that is, as we say, machine-actionable, so being ready has mostly involved monitoring the progress of the Joint Steering Committee.”
SirsiDynix - is closely monitoring the progress of RDA,
“And participating in RDA discussions where possible. Once the standard has been fully developed and these principal libraries have provided implementations recommendations, we will be in a better position to change our code and parameters, if required, and to provide recommendations to our customers.”

Aleph - The British Library is also participating in the development of RDA The BL is currently developing plans to evaluate and test RDA in the second
half of 2009, with a view to implementation during 2010.
“The realisation of benefits from RDA implementation will be constrained by existing system architectures. Our data must be sufficient to support these developments, in terms of record content, relationships between records, and links between the metadata and the actual content. The ever-increasing dependence on records from elsewhere introduces challenges for data interchange, especially as new standards such as RDA and new ways of expressing data (e.g. in XML formats) are implemented.”
Sirsi - Web 2.0, faceted, pattern-recognition searching
There are interesting times ahead!
Library Systems and RDA

Be Prepared

Group Learning, self-directed learning, Lists - discussing new ideas, watch blogs, for discussion and updates
[email protected], [email protected] onarchos.com [email protected], [email protected]
Web tutorials: http://www.w3schools.com/
Blogs: Lorcan Dempsey (http://orweblog.oclc.org/); Karen Coyle (http://kcoyle.blogspot.com/) The FRBR Blog (http://www.frbr.org/) ; Catalogablog (http://catalogablog.blogspot.com/) Cataloging Futures (http://www.catalogingfutures.com/), Metadata
(http://managemetadata.org/blog/)
RDF Online Validator W3C's RDF Validation Service is useful when learning RDF. Here you can experiment
with RDF files. The online RDF Validator parses your RDF document, checks your syntax, and generates tabular and graphical views of your RDF document.
Learning Strategies

Get familiar with the terminology.
Ask questions, talk with colleagues, participate in discussions.
Attend Conference presentations, Seminars, workshops.
Explore websites, tutorials and other resources.
Keep an open mind.
Be prepared for change. ……
most importantly don’t press the …. Button.
What next?

Bibliography http://www.w3.org/2002/Talks/www2002-w3ct-swintro-em/slide4-0.html http://www.amk.ca/talks/2003-03/ http://www.w3schools.com/semweb/default.asp http://www.digital-web.com/ http://metadata.cetis.ac.uk/ http://www.w3schools.com/rdf/rdf_owl.asp
Online Catalogs: What Users and Librarians Want -An OCLC Report 2009
213 Chapter 11, Knitting the Semantic Web/Cataloging & Classification Quarterly 43(3-4) Pre-print
214 Chapter 11, Knitting the Semantic Web/Cataloging & Classification Quarterly 43(3-4) Pre-print
Cutter, Charles A., W. P. Cutter, Worthington Chauncey Ford, Philip Lee Phillips, and Oscar George Theodore Sonneck, Rules for a dictionary catalog (Washington: Government Printing Offi ce, 1904).

Thank you!
Mariaan & Eleta


















