
Taking Spark Streaming to the Next Level with Datasets and DataFrames
40
Taking Spark Streaming to the next level with Datasets and DataFrames Tathagata “TD” Das @tathadas Strata San Jose 2016
-
Upload
databricks -
Category
Software
-
view
4.088 -
download
0
Transcript of Taking Spark Streaming to the Next Level with Datasets and DataFrames

Taking Spark Streaming to the next
level with Datasets and DataFrames
Tathagata “TD” Das@tathadas
Strata San Jose 2016

Streaming in Spark
Spark Streaming changed how people write streaming apps
2
SQL Streaming MLlib
Spark Core
GraphXFunctional, concise and expressive
Fault-tolerant state management
Unified stack with batch processing
More than 50% users consider most important part of Spark

Streaming apps are growing more complex
3

Streaming computations don’t run in isolation
Need to interact with batch data, interactive analysis, machine learning, etc.

Use case: IoT Device Monitoring
IoTDevices
ETL into long term storage- Prevent data loss- Prevent duplicatesStatus monitoring
- Handle late data- Process based on
event time
Interactively debug issues- consistency
event stream
Anomaly detection- Learn models offline- Use online + continuous
learning

1. Processing with event-time, dealing with late data- DStream API exposes batch time, hard to incorporate event-time
2. Interoperate streaming with batch AND interactive - RDD/DStream has similar API, but still requires translation- Hard to interoperate with DataFrames and Datasets
3. Reasoning about end-to-end guarantees- Requires carefully constructing sinks that handle failures correctly- Data consistency in the storage while being updated
Pain points with DStreams

Structured Streaming

The simplest way to perform streaming analyticsis not having to reason about streaming at all
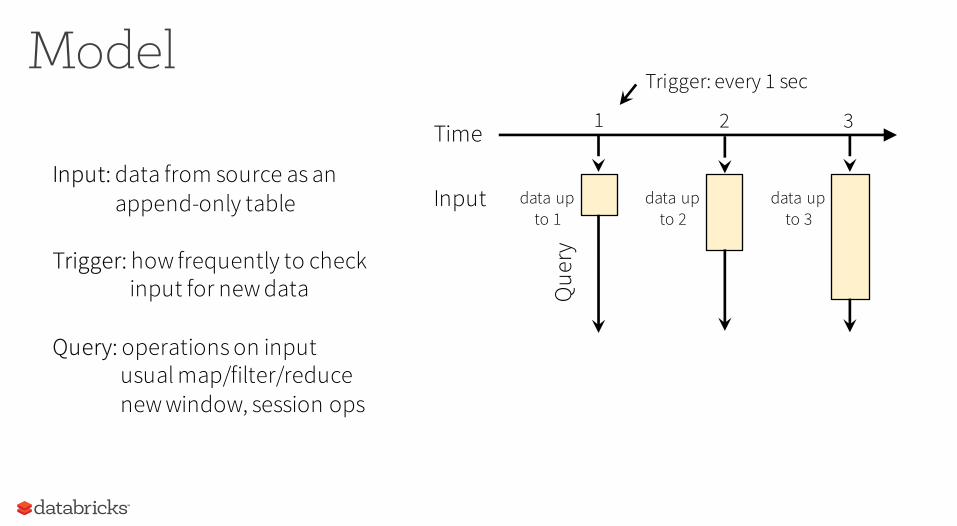
ModelTrigger: every 1 sec
1 2 3Time
data upto 1
Input data upto 2
data upto 3
Que
ry
Input: data from source as an append-only table
Trigger: how frequently to checkinput for new data
Query: operations on inputusual map/filter/reduce new window, session ops
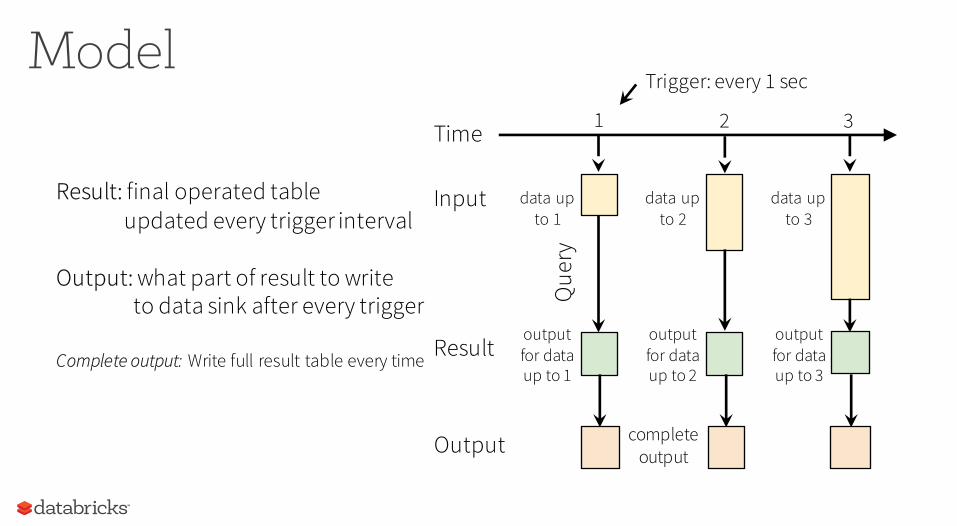
ModelTrigger: every 1 sec
1 2 3
output for data up to 1
Result
Que
ry
Time
data upto 1
Input data upto 2
output for data up to 2
data upto 3
output for data up to 3
Result: final operated tableupdated every trigger interval
Output: what part of result to write to data sink after every trigger
Complete output: Write full result table every time
Output complete output

ModelTrigger: every 1 sec
1 2 3
output for data up to 1
Result
Que
ry
Time
data upto 1
Input data upto 2
output for data up to 2
data upto 3
output for data up to 3
Output deltaoutput
Result: final operated tableupdated every trigger interval
Output: what part of result to write to data sink after every trigger
Complete output: Write full result table every timeDelta output: Write only the rows that changed
in result from previous batchAppend output: Write only new rows
*Not all output modes are feasible with all queries

Static, bounded table
Dataset, DataFrame
Streaming, unbounded table
Single API !

Batch ETL with DataFrame
input = ctxt.read.format("json").load("source-path")
result = input.select("device", "signal").where("signal > 15")
result.write.format("parquet").save("dest-path")
Read from Json file
Select some devices
Write to parquet file

Streaming ETL with DataFrame
input = ctxt.read.format("json").stream("source-path")
result = input.select("device", "signal").where("signal > 15")
result.write.format("parquet").outputMode("append").startStream("dest-path")
Read from Json file stream
Select some devices
Write to parquet file stream

Streaming ETL with DataFrame
input = ctxt.read.format("json").stream("source-path")
result = input.select("device", "signal").where("signal > 15")
result.write.format("parquet").outputMode("append").startStream("dest-path")
read…stream() creates a streaming DataFrame, does not start any of the computation
write…startStream() defines where & how to output the data and starts the processing
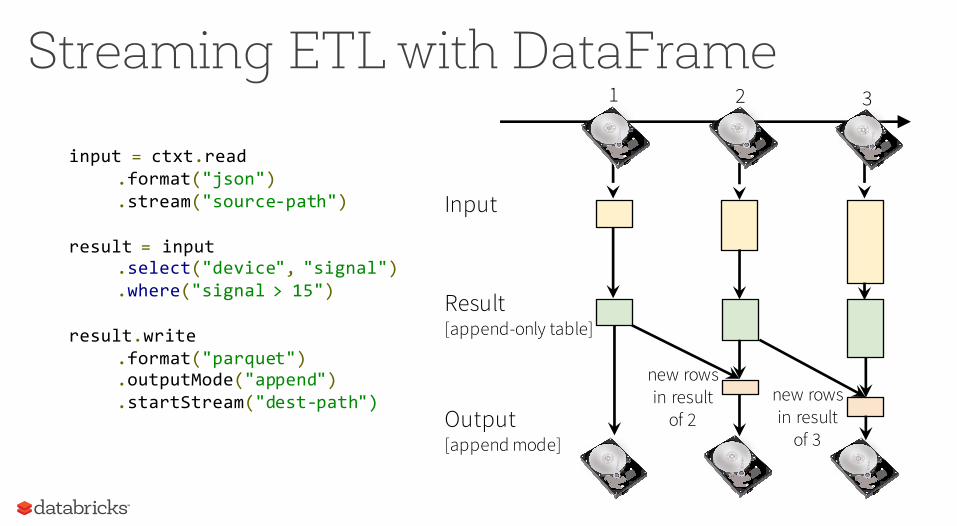
Streaming ETL with DataFrame
input = ctxt.read.format("json").stream("source-path")
result = input.select("device", "signal").where("signal > 15")
result.write.format("parquet").outputMode("append").startStream("dest-path")
1 2 3
Result[append-only table]
Input
Output[append mode]
new rows in result
of 2new rows in result
of 3

Continuous Aggregations
Continuously compute average signal of each type of device
17
input.groupBy("device-type").avg("signal")
input.groupBy(window("event-time", "10min"),"device type")
.avg("age")
Continuously compute average signal of each type of device in last 10 minutes of event time
- Windowing is just a type of aggregation- Simple API for event time based windowing

Query Management
query = result.write.format("parquet").outputMode("append").startStream("dest-path")
query.stop()query.awaitTermination()query.exception()
query.sourceStatuses()query.sinkStatus()
18
query: a handle to the running streaming computation for managing it
- Stop it, wait for it to terminate- Get status- Get error, if terminated
Multiple queries can be active at the same time
Each query has unique name for keeping track

Logically:DataFrame operations on table(i.e. as easy to understand as batch)
Physically:Spark automatically runs the query in streaming fashion(i.e. incrementally and continuously)
DataFrame
Logical Plan
Continuous, incremental execution
Catalyst optimizer
Execution

Structured Streaming
High-level streaming API built on Spark SQL engineRuns the same computation as batch queries in Datasets/DataFramesEvent time, windowing, sessions, sources & sinksEnd-to-end exactly once semantics
Unifies streaming, interactive and batch queriesAggregate data in a stream, then serve using JDBCAdd, remove, change queries at runtimeBuild and apply ML models

Advantages over DStreams
1. Processing with event-time, dealing with late data
2. Exactly same API for batch, streaming, and interactive
3. End-to-end exactly-once guarantees from the system
4. Performance through SQL optimizations- Logical plan optimizations, Tungsten, Codegen, etc.- Faster state management for stateful stream processing
21

Underneath the Hood
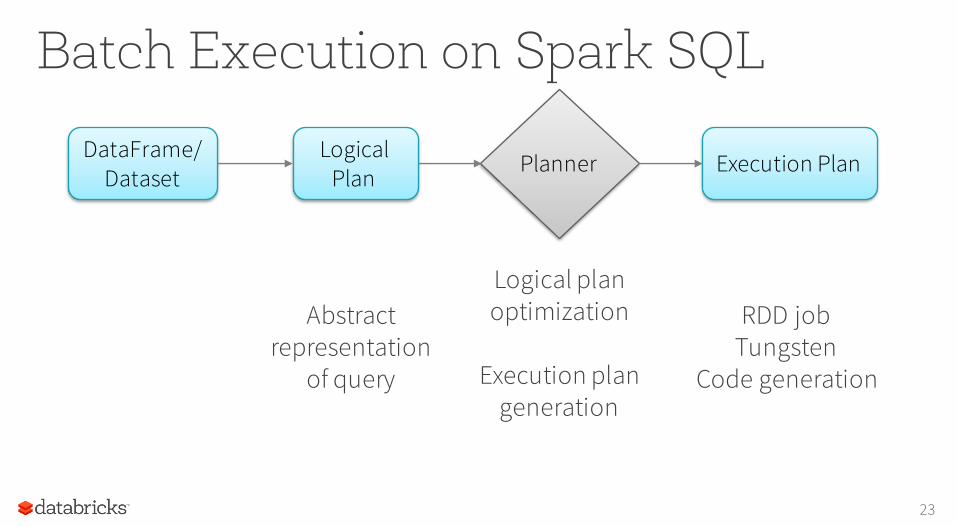
Batch Execution on Spark SQL
23
DataFrame/Dataset
Logical Plan
Execution PlanPlanner
Logical plan optimization
Execution plan generation
RDD jobTungsten
Code generation
Abstract representation
of query
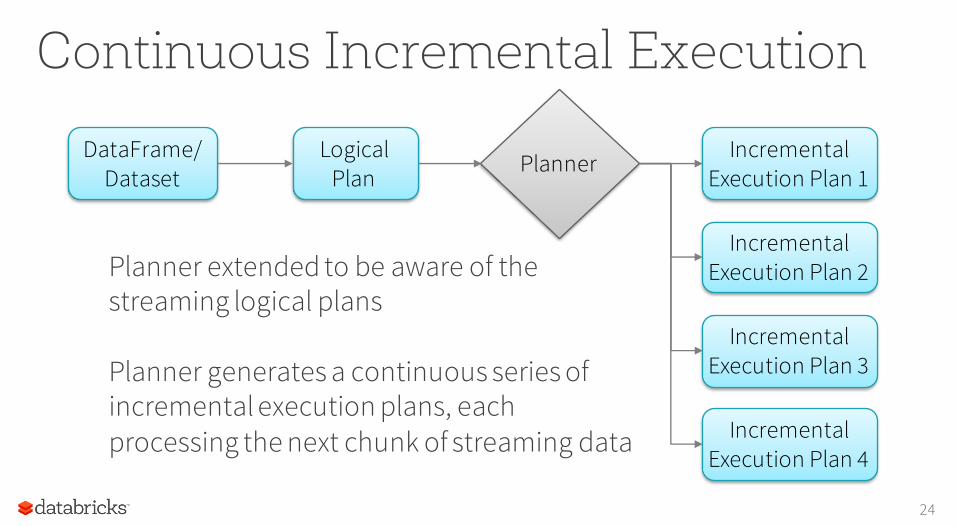
Continuous Incremental Execution
Planner extended to be aware of the streaming logical plans
Planner generates a continuous series of incremental execution plans, each processing the next chunk of streaming data
24
DataFrame/Dataset
Logical Plan
Incremental Execution Plan 1
Incremental Execution Plan 2
Incremental Execution Plan 3
Planner
Incremental Execution Plan 4

Streaming Source
A streaming data source where- Records can be uniquely identified by a offset- Arbitrary segment of the stream data can be read
based on an offset range- Files, Kafka, Kinesis supported
More restricted than DStream Receivers Can ensure end-to-end exactly-once guarantees
25
Logical Plan
Sources
Sink
Operations

Streaming Sink
Allows output to pushed to external storage
Each batch of output should be written to storage atomically and idempotently
Both needed to ensure end-to-end exactly-once guarantees, AND data consistency
26
Logical Plan
Sources
Sink
Operations

Incremental Execution
Every trigger interval
- Planner ask source for next chunk of input data
- Generates execution plan with the input
- Generate output data
- Hands to sink for pushing it out
27
Logical Plan
Sources
Sink
Ops
Incremental Execution Plan
Input
get new data as input
Outputpush output
generate outputPlanner
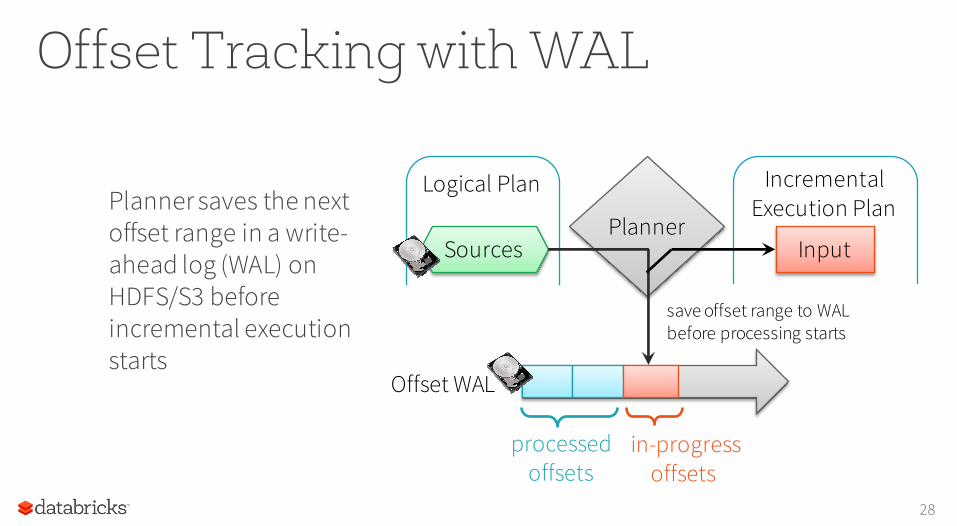
Offset Tracking with WAL
Planner saves the next offset range in a write-ahead log (WAL) on HDFS/S3 before incremental execution starts
28
Logical Plan
Sources
Incremental Execution Plan
Planner
processedoffsets
Offset WAL
in-progressoffsets
save offset range to WAL before processing starts
Input
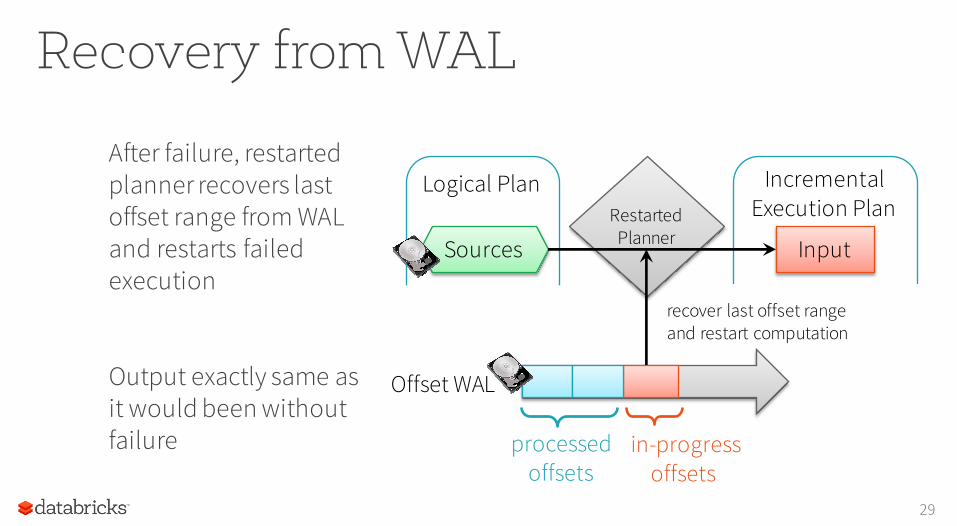
Recovery from WAL
29
Logical Plan
Sources
Incremental Execution PlanRestarted
Planner
processedoffsets
in-progressoffsets
Offset WAL
recover last offset range and restart computation
After failure, restarted planner recovers last offset range from WAL and restarts failed execution
Output exactly same as it would been without failure
Input

30
Streaming source +
Streaming sink +
Offset tracking=
End-to-end exactly-once guarantees

Stateful Stream Processing
Streaming aggregations require maintaining intermediate "state" data across batches
31
compute aggregates 3
Dog
Cat 2Dog 1
Cat 3Dog 1Cow 1
state data
compute aggregates 2
Cat, Cow
compute aggregates 1
Cat, Dog, Cat
aggregates
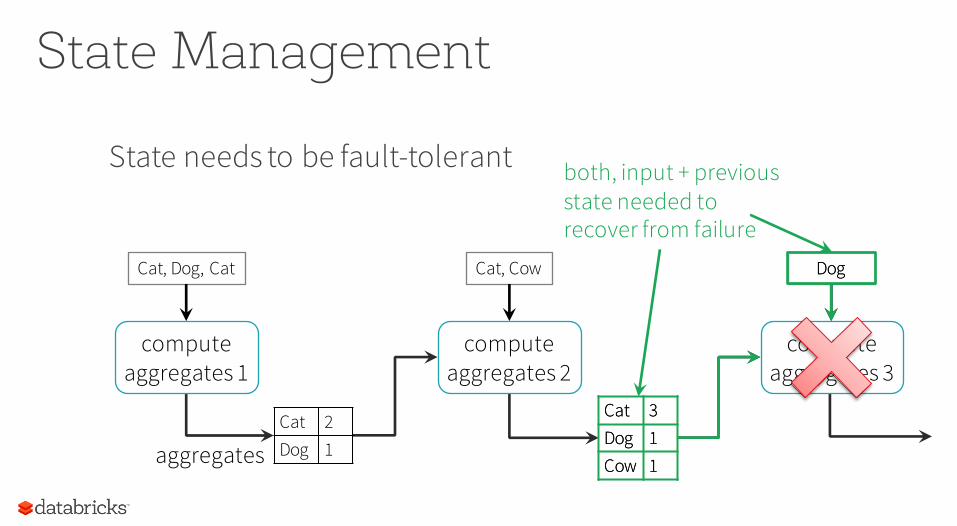
State Management
State needs to be fault-tolerant
Cat, Dog, Cat Cat, Cow Dog
Cat 2Dog 1
Cat 3Dog 1Cow 1aggregates
both, input + previous state needed to recover from failure
Cat 3Dog 1Cow 1
Dog
compute aggregates 1
compute aggregates 2
compute aggregates 3

Old State Management with DStreams
DStreams (i.e. updateStateByKey, mapWithState) represented state data as RDDs
Leveraged RDD lineage for fault-tolerance and RDD checkpointing to prevent unbounded
RDD checkpointing saves all state data to HDFS/S3Inefficient when update rates are low
No "incremental" checkpointing
33

New State Management: State Store
State Store API: any versioned key value store that
- Allows a set of key-value updates to be transactionally committed with a version number (i.e. incremental checkpointing)
- Allows a specific version of the key-value data to be retrieved
34
Incremental Execution 1
state store, v1
Incremental Execution 2
Incremental Execution 3
state store, v2
Spark cluster
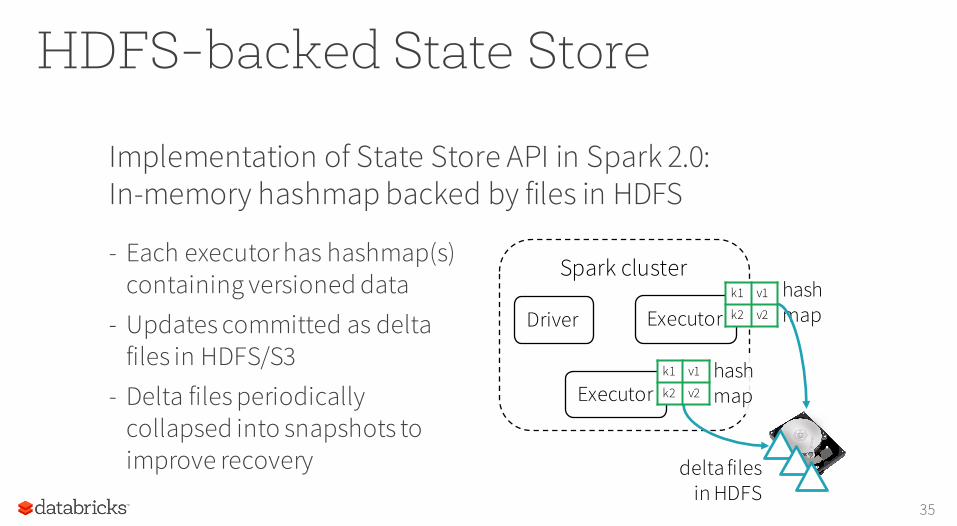
HDFS-backed State Store
Implementation of State Store API in Spark 2.0:In-memory hashmap backed by files in HDFS
35
Driver Executor
Executor
hashmap
hashmap
- Each executor has hashmap(s) containing versioned data
- Updates committed as delta files in HDFS/S3
- Delta files periodically collapsed into snapshots to improve recovery delta files
in HDFS
k1 v1
k2 v2
k1 v1
k2 v2

Fault recovery of HDFS State Store
State Store version also stored in the WAL
36
On fault recovery,- Recover input data from
source using last offsets- Recover state data using
last store versionIncremental
Execution
In progress WAL
sources
store filesrecovered state
recovered input

37
Fast, fault-tolerant, exactly-once stateful stream processing
without having to reason about streaming

Plan
Spark 2.0
Basic infrastructure and API- Event time, windows, aggregations
Files as sources and sinks- Kafka as source, SQL as sink (?)

Plan
Spark 2.1+
More support for late dataDynamic scalingSource and sinks public API
- Extends DataSource API
More sources and sinksML integrations
Spark XXX
"True streaming" engine- API already agnostic to
micro-batch

40
Simple and fast real-time analytics• Develop Productively• Execute Efficiently• Update Automatically
Questions?
Learn MoreToday, 1:50-2:30 AMA
Follow me @tathadas


















