
Spark DataFrames for Data Munging
18
© 2016 Mesosphere, Inc. All Rights Reserved. SPARK DATAFRAMES FOR DATA MUNGING 1 Susan X. Huynh, Scala by the Bay, Nov. 2016
-
Upload
susan-xinh-huynh -
Category
Software
-
view
120 -
download
1
Transcript of Spark DataFrames for Data Munging

© 2016 Mesosphere, Inc. All Rights Reserved.
SPARK DATAFRAMES FOR DATA MUNGING
1
Susan X. Huynh, Scala by the Bay, Nov. 2016

© 2016 Mesosphere, Inc. All Rights Reserved.
OUTLINE
2
Motivation
Spark DataFrame API
Demo
Beyond Data Munging
© 2016 Mesosphere, Inc. All Rights Reserved.
MOTIVATION
3
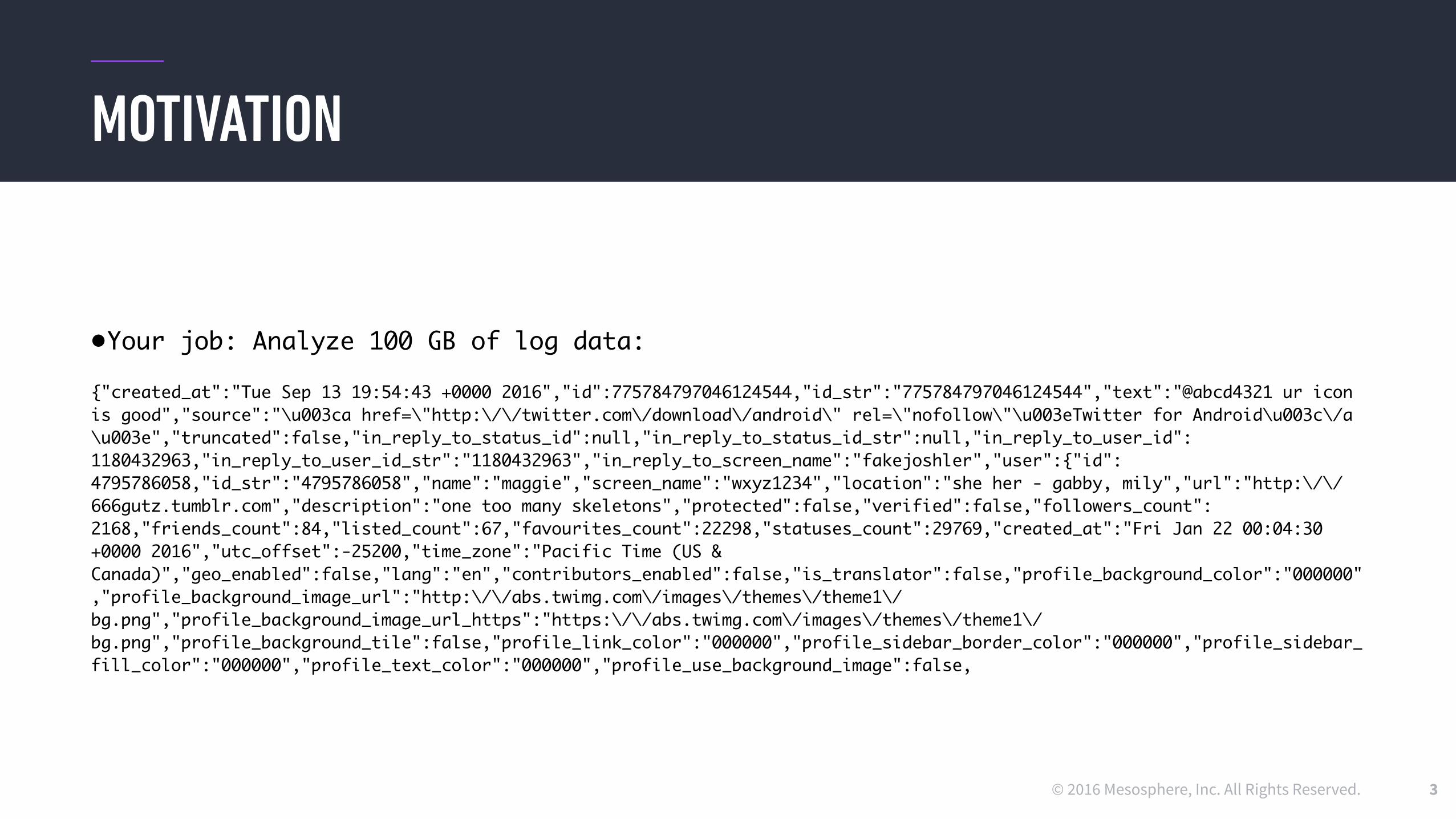
•Your job: Analyze 100 GB of log data:
{"created_at":"Tue Sep 13 19:54:43 +0000 2016","id":775784797046124544,"id_str":"775784797046124544","text":"@abcd4321 ur icon is good","source":"\u003ca href=\"http:\/\/twitter.com\/download\/android\" rel=\"nofollow\"\u003eTwitter for Android\u003c\/a\u003e","truncated":false,"in_reply_to_status_id":null,"in_reply_to_status_id_str":null,"in_reply_to_user_id":1180432963,"in_reply_to_user_id_str":"1180432963","in_reply_to_screen_name":"fakejoshler","user":{"id":4795786058,"id_str":"4795786058","name":"maggie","screen_name":"wxyz1234","location":"she her - gabby, mily","url":"http:\/\/666gutz.tumblr.com","description":"one too many skeletons","protected":false,"verified":false,"followers_count":2168,"friends_count":84,"listed_count":67,"favourites_count":22298,"statuses_count":29769,"created_at":"Fri Jan 22 00:04:30 +0000 2016","utc_offset":-25200,"time_zone":"Pacific Time (US & Canada)","geo_enabled":false,"lang":"en","contributors_enabled":false,"is_translator":false,"profile_background_color":"000000","profile_background_image_url":"http:\/\/abs.twimg.com\/images\/themes\/theme1\/bg.png","profile_background_image_url_https":"https:\/\/abs.twimg.com\/images\/themes\/theme1\/bg.png","profile_background_tile":false,"profile_link_color":"000000","profile_sidebar_border_color":"000000","profile_sidebar_fill_color":"000000","profile_text_color":"000000","profile_use_background_image":false,

© 2016 Mesosphere, Inc. All Rights Reserved.
WHAT DO YOU MEAN BY “ANALYZE”?
4
AKA: data munging, ETL, data cleaning, acronym: PETS (or PEST? :)
Parse
Explore
Transform
Summarize
Data pipeline
Motivation
"source":"\u003ca href=\"http:\/\/twitter.com\/download\/android\" rel=\”nofollow\”…

© 2016 Mesosphere, Inc. All Rights Reserved.
BEST TOOL FOR THE JOB?
5
DataFrame
Pandas (Python)
R
Big data + SQL
Hive, Impala
DataFrame + Big data / SQL
Spark DataFrame
Motivation
https://flic.kr/p/fnCVbL

© 2016 Mesosphere, Inc. All Rights Reserved.
WHY SPARK?
6
Open source
Scalable
Fast ad-hoc queries
Motivation

© 2016 Mesosphere, Inc. All Rights Reserved.
WHY SPARK DATAFRAME?
7
Parse: Easy to read structured, semi-structured (JSON) formats
Explore: DataFrame
Transform / Summarize:
SQL queries + procedural processing
Utilities for math, string, date / time manipulation
Scala
Motivation

© 2016 Mesosphere, Inc. All Rights Reserved.
PARSE: READING JSON DATA
8
> spark res4: org.apache.spark.sql.SparkSession@3fc09112
> val df = spark.read.json(“/path/to/mydata.json”) df: org.apache.spark.sql.DataFrame = [contributors: string ... 33 more fields]
DataFrame: a table with rows and columns (fields)
Spark DataFrame API
"source":"\u003ca href=\"http:\/\/twitter.com\/download\/android\" rel=\”nofollow\”…

© 2016 Mesosphere, Inc. All Rights Reserved.
EXPLORE
9
> df.printSchema() // lists the columns in a DataFrameroot |-- contributors: string (nullable = true) |-- coordinates: struct (nullable = true) | |-- coordinates: array (nullable = true) | | |-- element: double (containsNull = true) | |-- type: string (nullable = true) |-- created_at: string (nullable = true) |-- delete: struct (nullable = true) | |-- status: struct (nullable = true) | | |-- id: long (nullable = true) |-- lang: string (nullable = true)…
Spark DataFrame API

© 2016 Mesosphere, Inc. All Rights Reserved.
EXPLORE (CONT’D)
10
> df.filter(col(”coordinates”).isNotNull) // filters on rows, with given condition .select("coordinates", “created_at”) // filters on columns .show()
+------------------------------------------------+------------------------------+|coordinates |created_at |+------------------------------------------------+------------------------------+|[WrappedArray(104.86544034, 15.23611896),Point] |Thu Sep 15 02:00:00 +0000 2016||[WrappedArray(-43.301755, -22.990065),Point] |Thu Sep 15 02:00:03 +0000 2016||[WrappedArray(100.3833729, 6.13822131),Point] |Thu Sep 15 02:00:30 +0000 2016||[WrappedArray(-122.286, 47.5592),Point] |Thu Sep 15 02:00:38 +0000 2016||[WrappedArray(110.823004, -6.80342),Point] |Thu Sep 15 02:00:42 +0000 2016|
Other DataFrame ops: count(), describe(), create new columns, …
Spark DataFrame API

© 2016 Mesosphere, Inc. All Rights Reserved.
TRANSFORM/SUMMARIZE: SQL QUERIES + PROCEDURAL PROC.
11
> val langCount = df.select(“lang")
.where(col(”lang”).isNotNull)
.groupBy(“lang")
.count()
.orderBy(col(”count”).desc) +----+-----+
|lang|count|
+----+-----+
| en|61644|
| es|22937|
| pt|21610|
| ja|19160|
| und|10376|
Also: joins
> val result = langCount.map{row:Row => …} // or flatMap, filter, …
Spark DataFrame API
SQL
PROCEDURAL

© 2016 Mesosphere, Inc. All Rights Reserved.
MATH, STRING, DATE / TIME FUNCTIONS
12
> df.select(”created_at”)
.withColumn(“day_of_week”, col(”created_at”).substr(0, 3))
.show() +--------------------+-----------+
| created_at|day_of_week|
+--------------------+-----------+
| null| null|
|Thu Sep 15 01:59:...| Thu|
|Thu Sep 15 01:59:...| Thu|
|Thu Sep 15 01:59:...| Thu|
| null| null|
|Thu Sep 15 01:59:...| Thu|
Also: sin, cos, exp, log, pow, toDegrees, toRadians, ceil, floor, round, concat, format_string, lower, regexp_extract, split, trim, upper, current_timestamp, datediff, from_unixtime, …
Spark DataFrame API

© 2016 Mesosphere, Inc. All Rights Reserved.
DEMO
13
Spark 2.0
Zeppelin notebook 0.6.1
8 GB JSON-formatted public Tweet data

© 2016 Mesosphere, Inc. All Rights Reserved.
BEYOND DATA MUNGING
14
Machine learning
Data pipeline in production
Streaming data

© 2016 Mesosphere, Inc. All Rights Reserved.
BEYOND DATA MUNGING
15
Machine learning => DataFrame-based ML API
Data pipeline in production => Dataset API, with type safety
Streaming data => Structured Streaming API, based on DataFrame
Spark 2.0

© 2016 Mesosphere, Inc. All Rights Reserved.
RECAP
16
Spark DataFrames combine the “data frame” abstraction with Big Data and SQL
Spark DataFrames simplify data munging tasks (“PETS”):
Parse => structured and semi-structured formats (JSON)
Explore => DataFrame: printSchema, filter by row / column, show
Transform,
Summarize => SQL + procedural processing, math / string / date-time utility functions
All in Scala

© 2016 Mesosphere, Inc. All Rights Reserved.
REFERENCES
17
Spark SQL and DataFrames Guide: http://spark.apache.org/docs/latest/sql-programming-guide.html
Spark DataFrame API: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset
Overview of Spark DataFrames: http://xinhstechblog.blogspot.com/2016/05/overview-of-spark-dataframe-api.html
DataFrame Internals: https://amplab.cs.berkeley.edu/wp-content/uploads/2015/03/SparkSQLSigmod2015.pdf

© 2016 Mesosphere, Inc. All Rights Reserved.
THANK YOU!
18


















