
Tachyon 2015 08 China
54
内内内内内内内内内 内内内内内内统 内内 , 内内内内内 Tachyon Nexus 2015/08/30 @ 南南
-
Upload
tachyon-nexus-inc -
Category
Technology
-
view
586 -
download
2
Transcript of Tachyon 2015 08 China

内存为中心的大数据分布式存储系统范斌 , 软件工程师
Tachyon Nexus2015/08/30 @ 南京

• Tachyon 项目的创始人及核心开发人员• A 轮融资: Andreessen Horowitz , 750 万美元• 致力于 Tachyon 开源项目
2
www.tachyonnexus.com

3

4

大纲• Tachyon 系统– 背景– 系统架构– 使用
• Tachyon 开源项目– 近况– 产品用例
• 路线图5

大纲• Tachyon 系统– 背景– 系统架构– 使用
• Tachyon 开源项目– 近况– 产品用例
• 路线图6

Tachyon
7
• 一种假想的超光速粒子
• 发音 : ['tækiːˌɒn]

Tachyon 从 UC Berkeley AMPLab 诞生
8
服务器集群管理 并发计算平台
可靠 , 分布式,以内存为中心的存储系统

9
我们为什么需要 Tachyon?
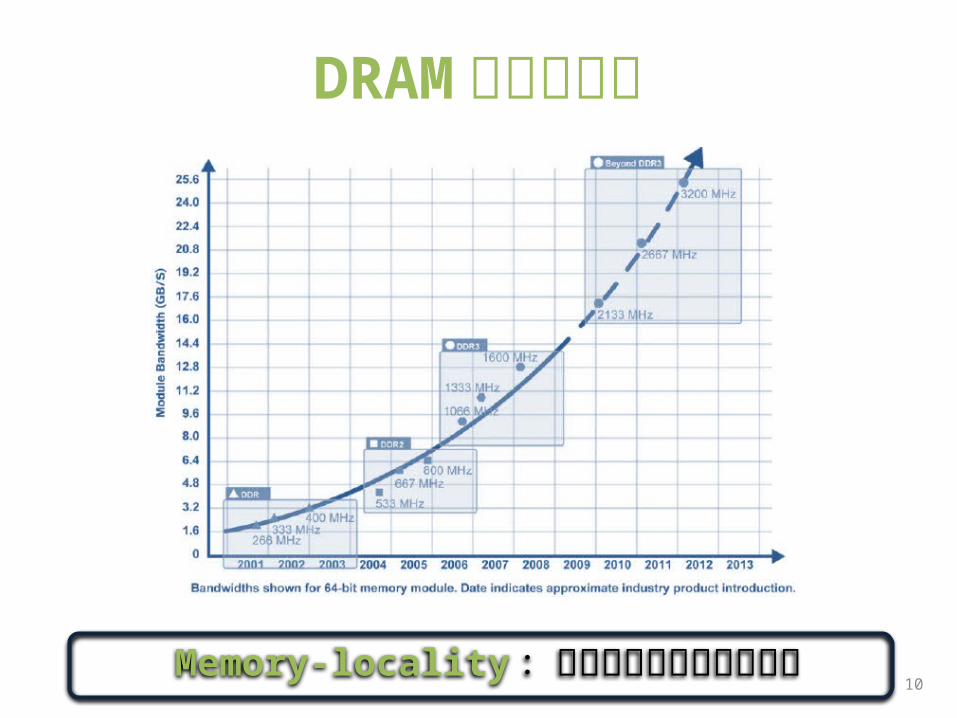
DRAM 正越来越快
10Memory-locality :达到交互级别响应的关键
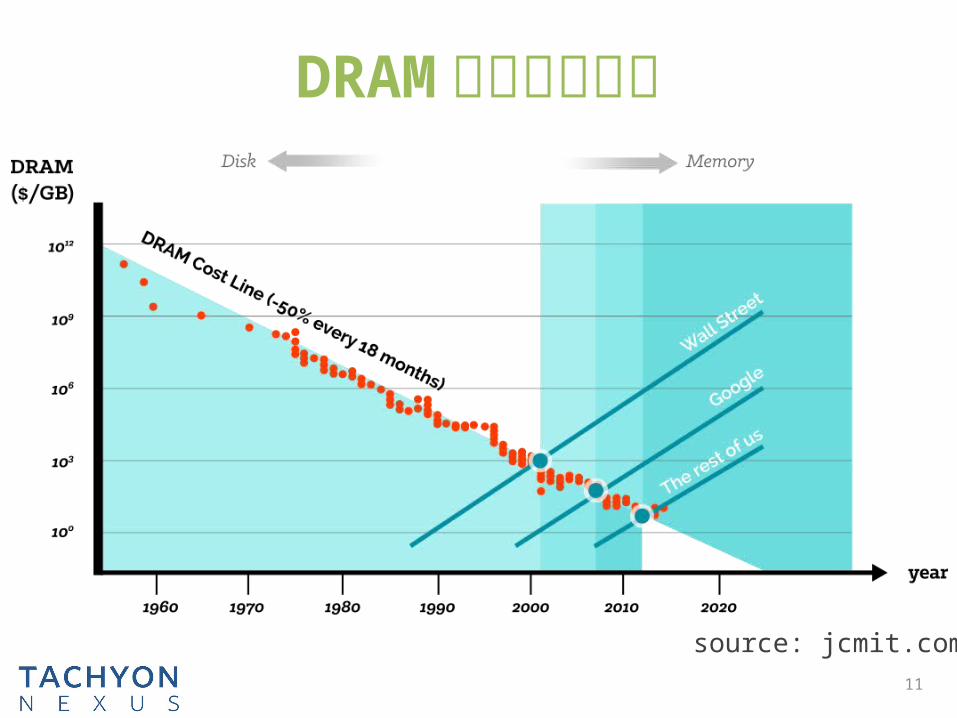
DRAM 正越来越便宜
source: jcmit.com11

涌现出的 In-Memory 平台
12

13
问题已经解决了么 ?

14
缺少存储层面的解决方案
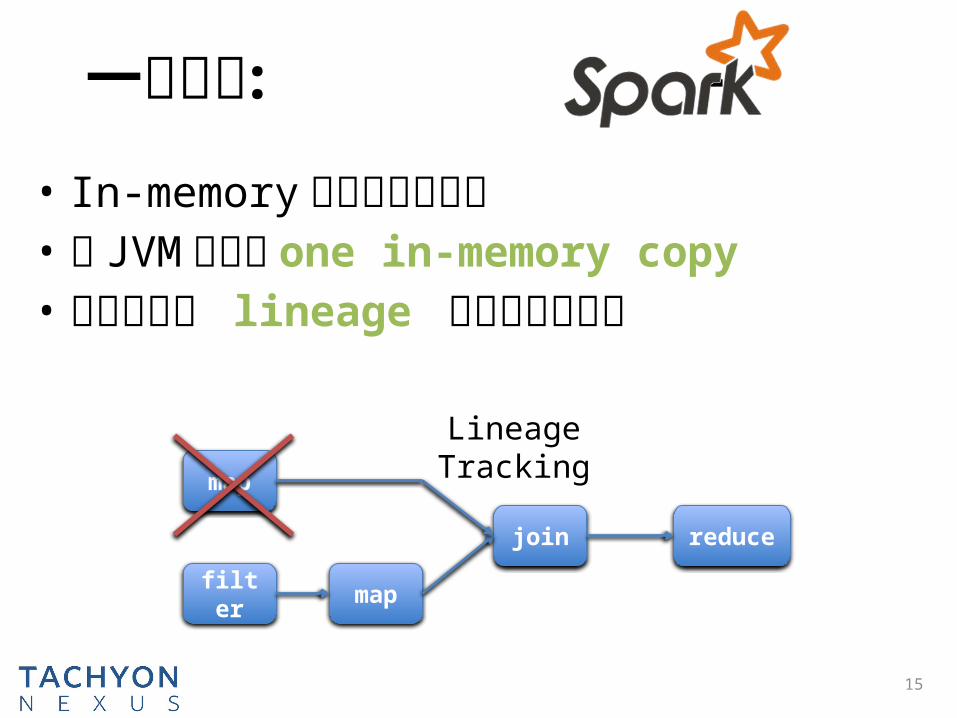
一个例子 : - • In-memory 大数据处理框架 • 在 JVM 中存储 one in-memory copy• 记录并使用 lineage 来重建遗失数据
map
filter map
join reduce
Lineage Tracking
15

问题一
16
数据共享可能成为瓶颈 :Slow writes to disk
Spark Job1 Spark Job2
block 1
HDFS / Amazon S3
block 1
block 1
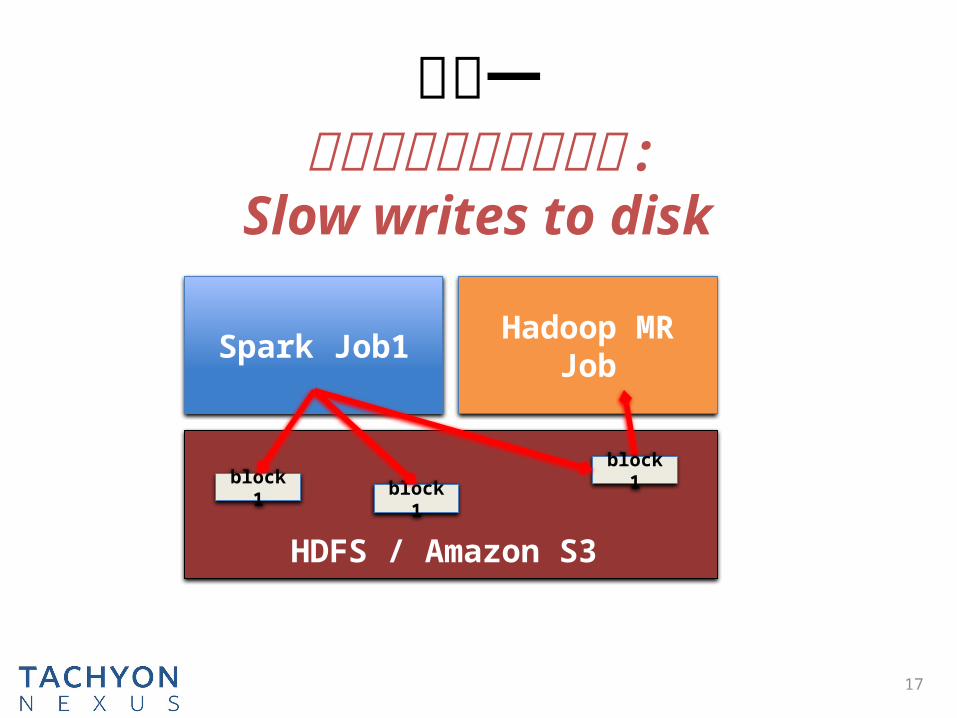
问题一
17
数据共享可能成为瓶颈 :Slow writes to disk
Spark Job1 Hadoop MR Job
block 1
HDFS / Amazon S3
block 1
block 1
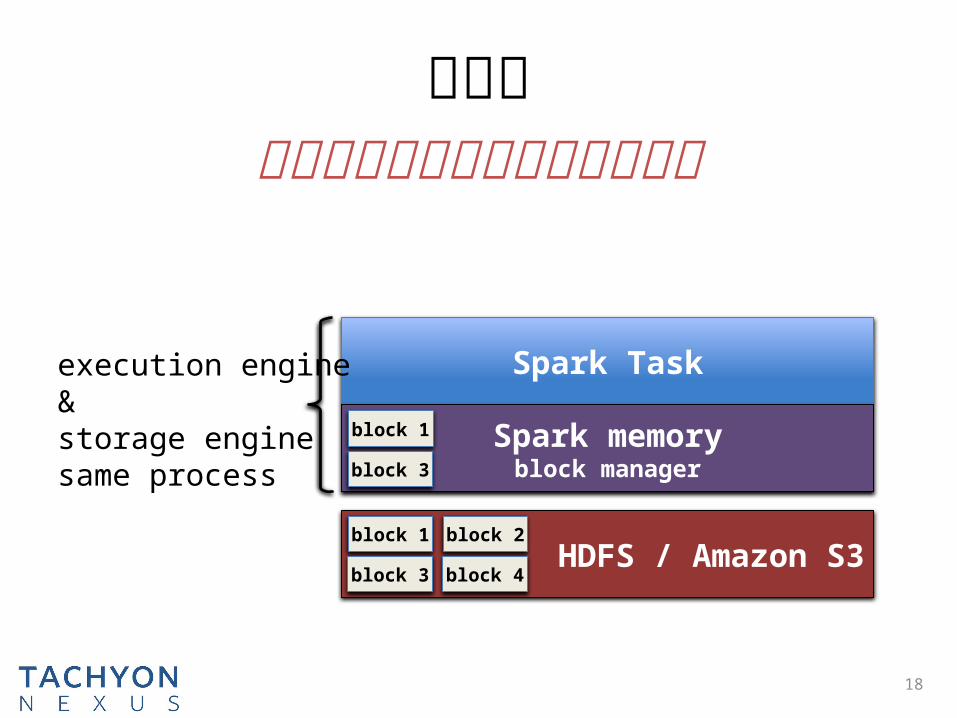
问题二
18
Spark Task
Spark memoryblock manager
block 1
block 3
HDFS / Amazon S3block 1
block 3
block 2
block 4
execution engine &
storage enginesame process
进程崩溃会导致缓存的数据丢失
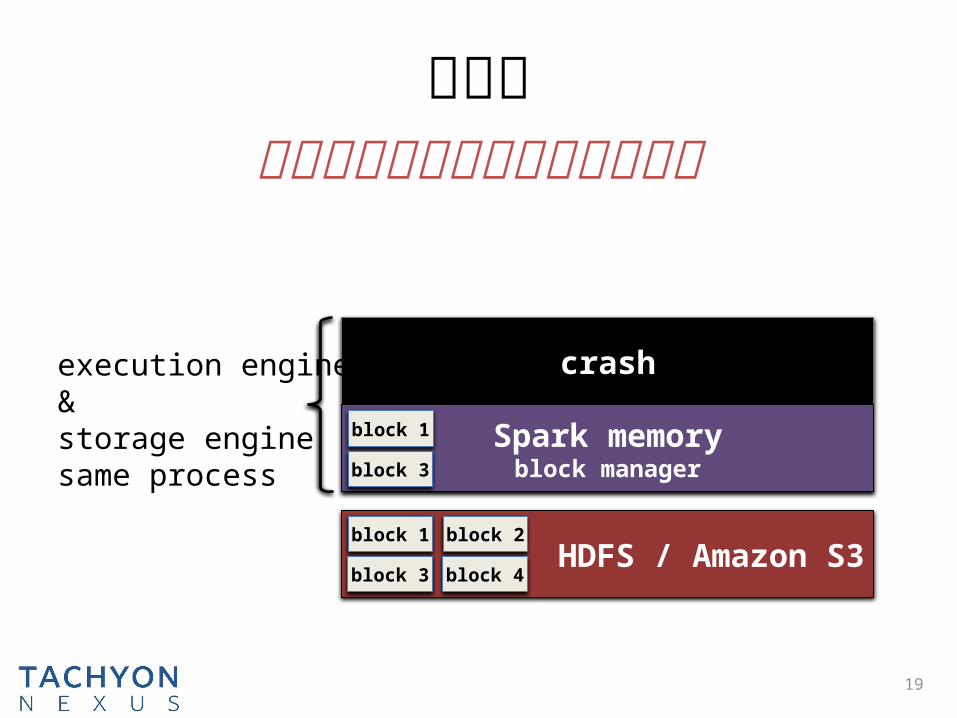
19
crash
Spark memoryblock manager
block 1
block 3
HDFS / Amazon S3block 1
block 3
block 2
block 4
execution engine &
storage enginesame process
问题二进程崩溃会导致缓存的数据丢失
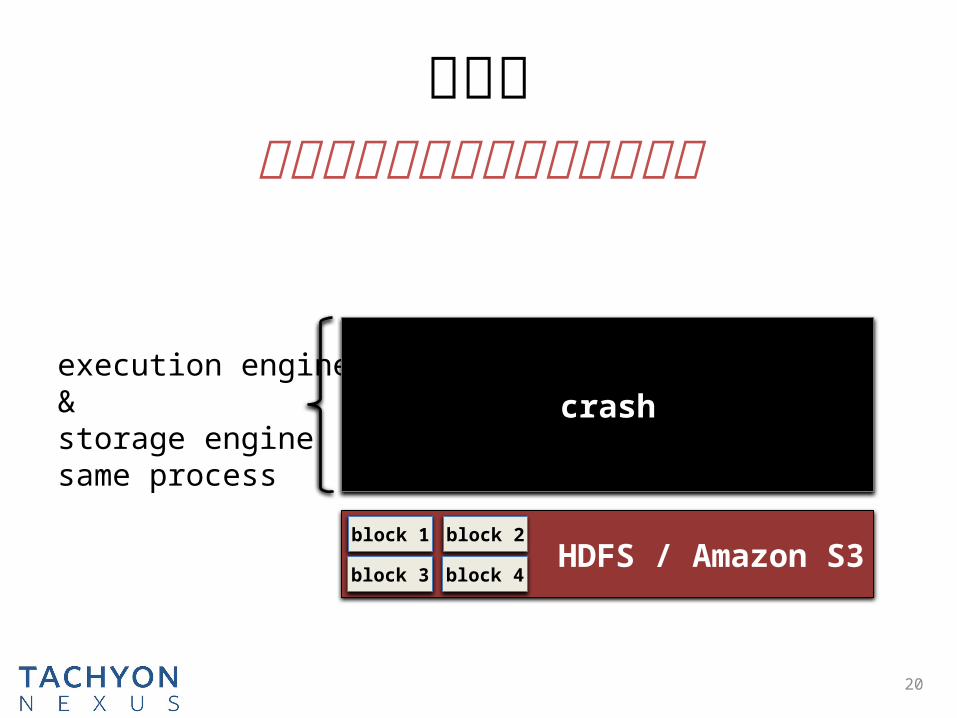
HDFS / Amazon S3
20
block 1
block 3
block 2
block 4
execution engine &
storage enginesame process
crash
问题二进程崩溃会导致缓存的数据丢失
HDFS / Amazon S3
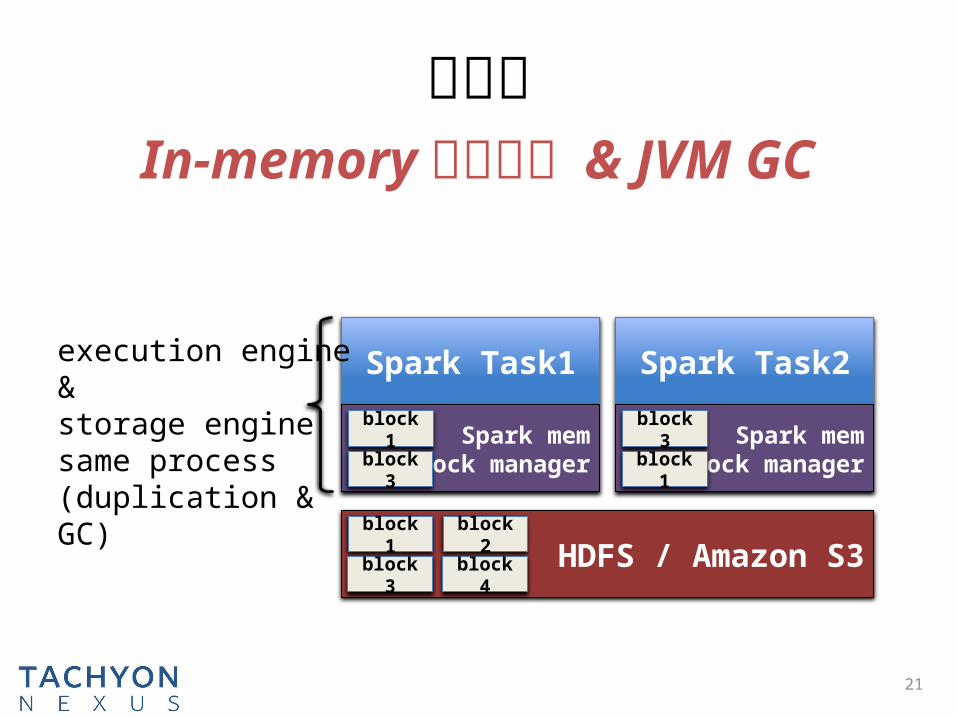
问题三
21
In-memory 数据重复 & JVM GC
Spark Task1
Spark memblock manager
block 1
block 3
Spark Task2
Spark memblock manager
block 3
block 1
block 1
block 3
block 2
block 4
execution engine &
storage enginesame process(duplication & GC)

Tachyon
Reliable data sharing at memory-speed
within and across cluster frameworks/jobs
22

概述基本想法• 围绕 DRAM 为中心的存储架构• 在存储层实现 lineage• 管理 tiered storage
实践• 保持一份数据在 DRAM• 通过 Re-computation 保证容错
23
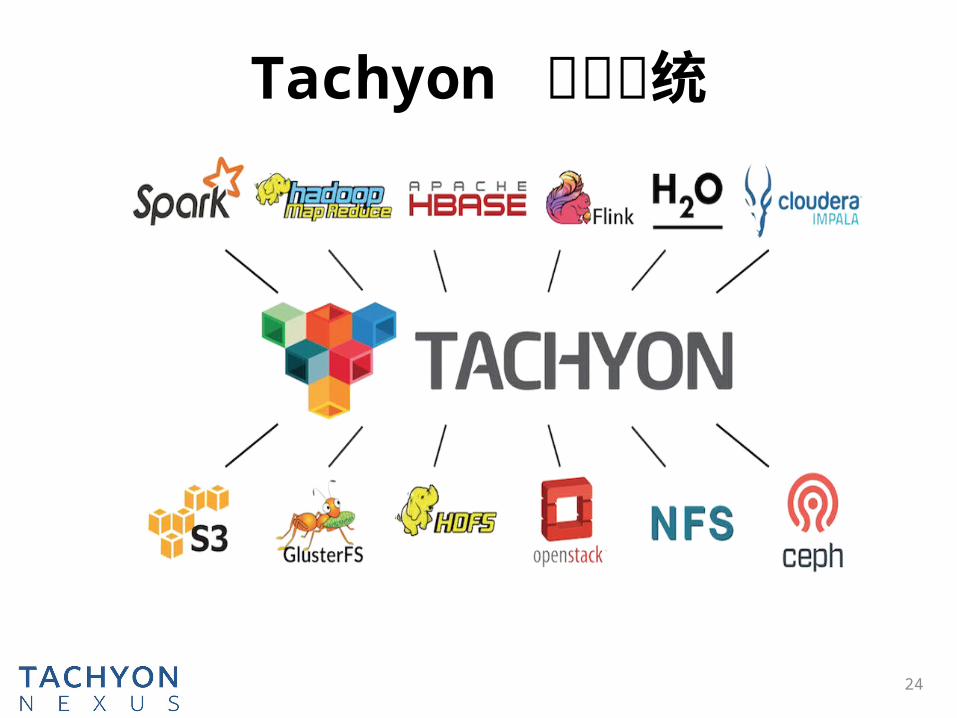
Tachyon 生态系统
24
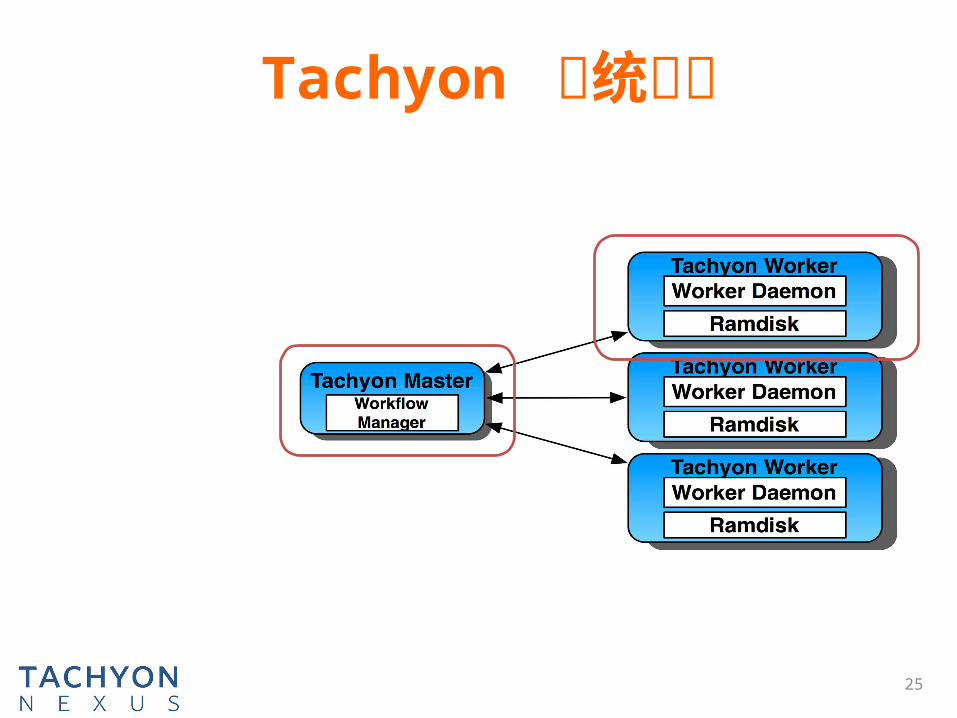
Tachyon 系统架构
25
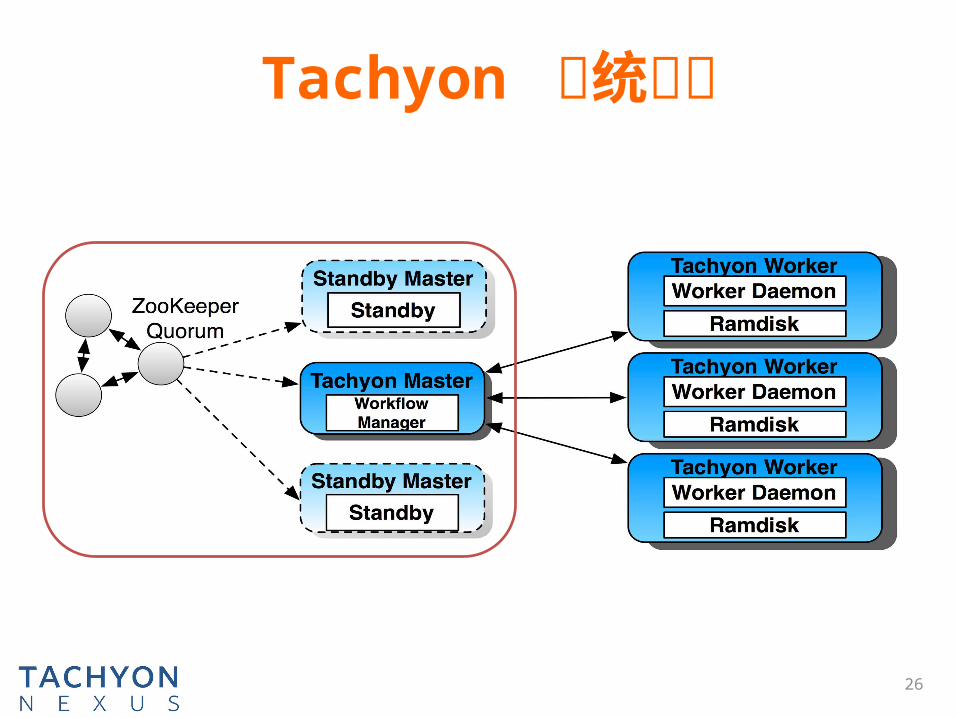
Tachyon 系统架构
26
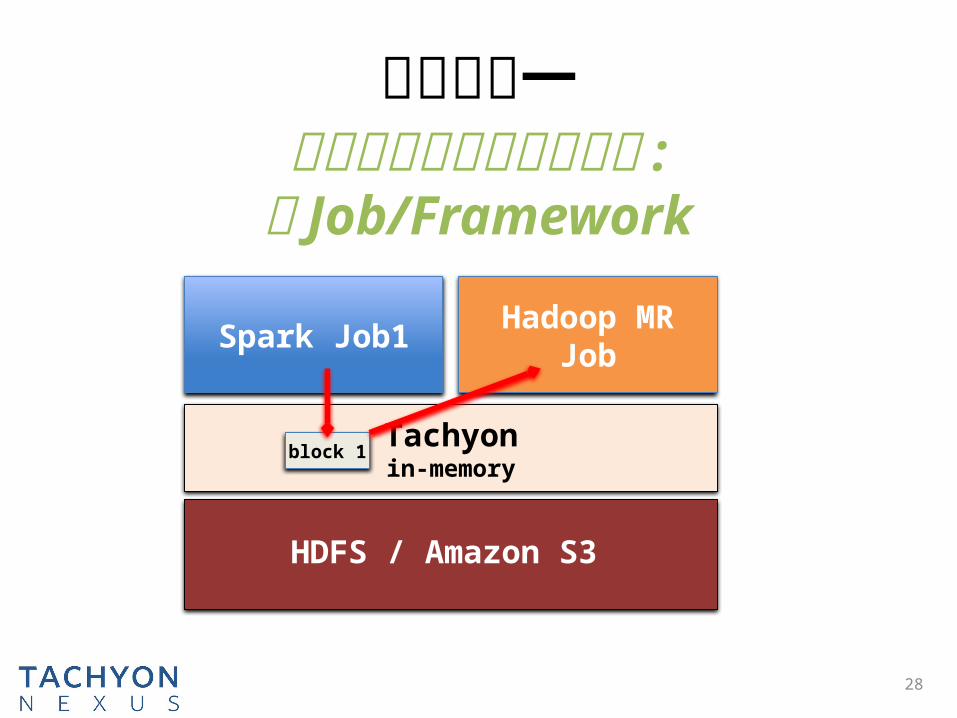
解决问题一
28
以内存读写速度共享数据 :跨 Job/Framework
Spark Job1
HDFS / Amazon S3
Tachyonin-memoryblock 1
Hadoop MR Job
HDFS / Amazon S3block 1
block 3
block 2
block 4Tachyonin-memory
block 1
block 3 block 4
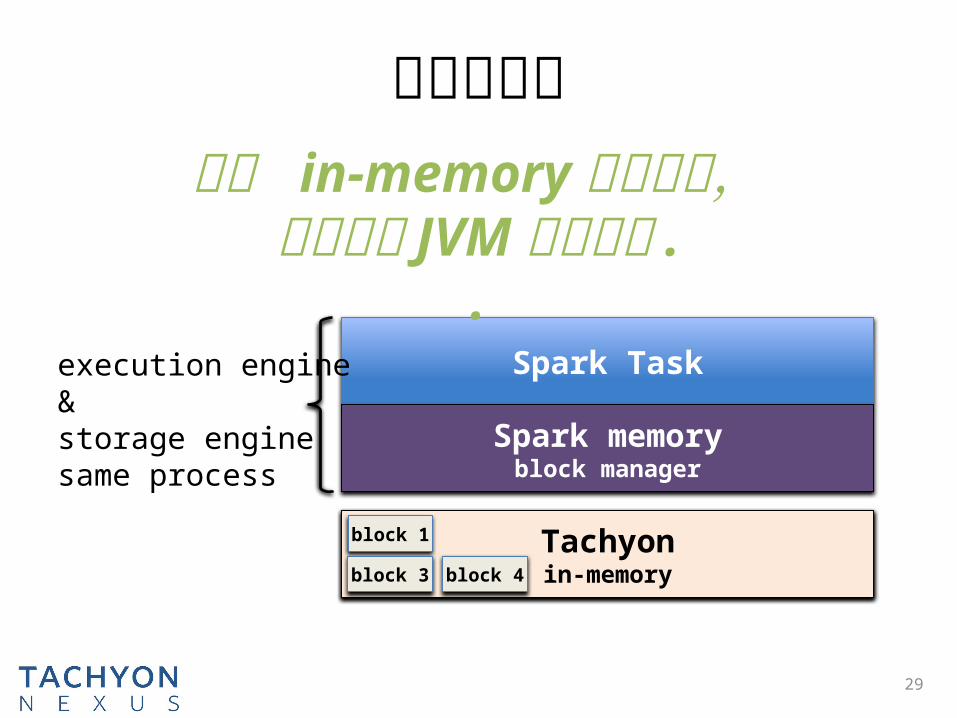
解决问题二
29
Spark Task
Spark memoryblock manager
execution engine &
storage enginesame process
保护 in-memory 数据安全,即使遭遇 JVM 进程崩溃 ..
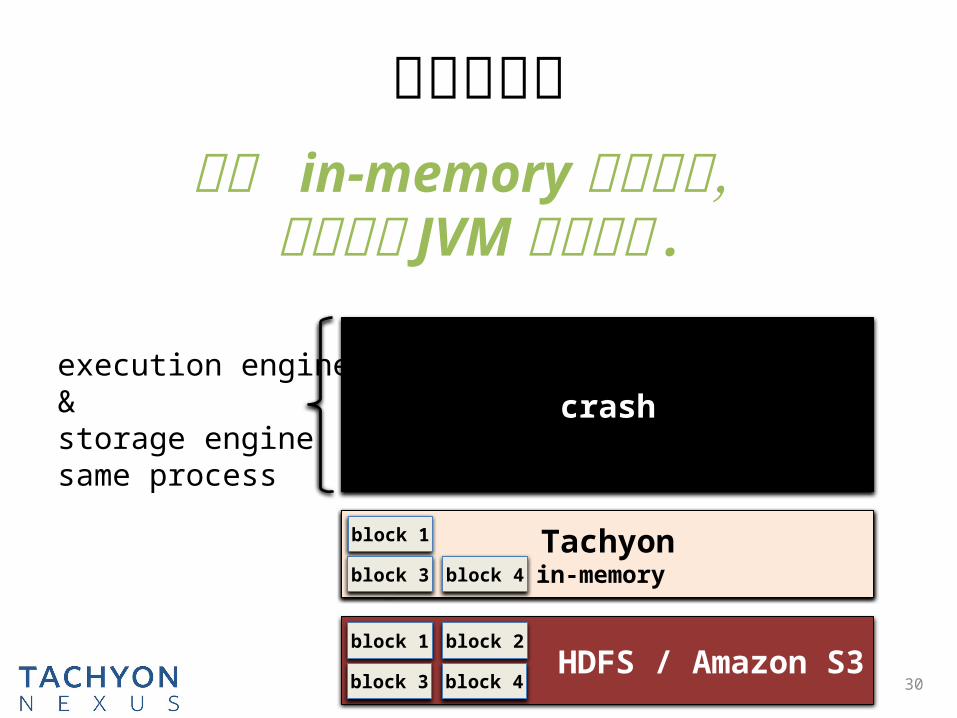
解决问题二
30
HDFSdisk
block 1
block 3
block 2
block 4
execution engine &
storage enginesame process
Tachyonin-memory
block 1
block 3 block 4
crash
HDFS / Amazon S3block 1
block 3
block 2
block 4
保护 in-memory 数据安全,即使遭遇 JVM 进程崩溃 .
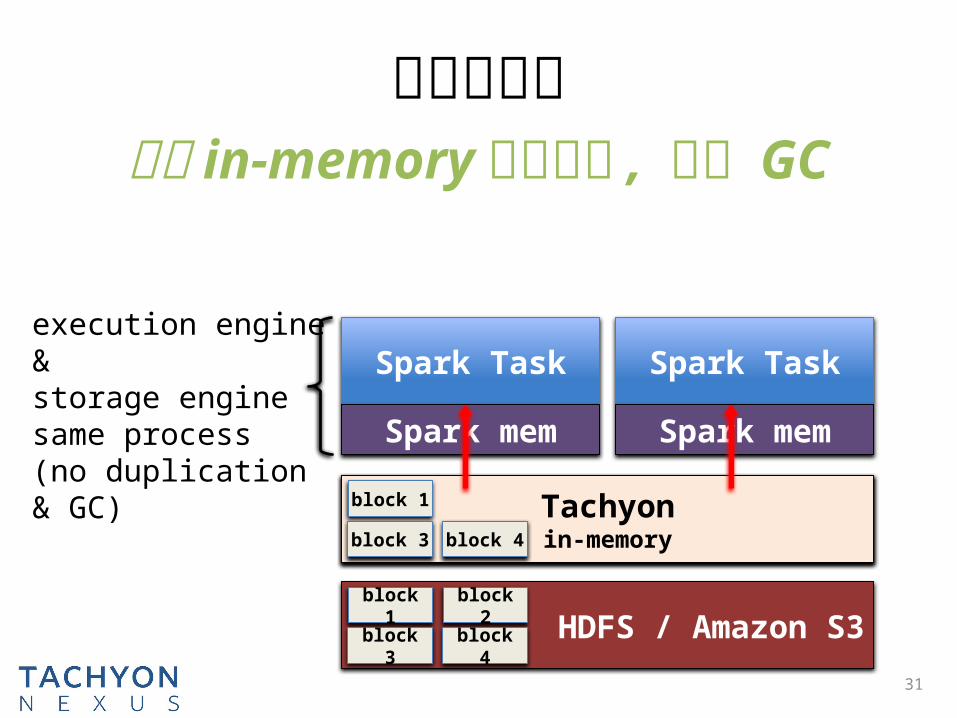
解决问题三
31
避免 in-memory 数据重复 , 减少 GC
Spark Task
Spark mem
Spark Task
Spark mem
HDFS / Amazon S3block
1block
3
block 2
block 4
execution engine &
storage enginesame process(no duplication & GC) HDFS
diskblock 1
block 3
block 2
block 4Tachyonin-memory
block 1
block 3 block 4
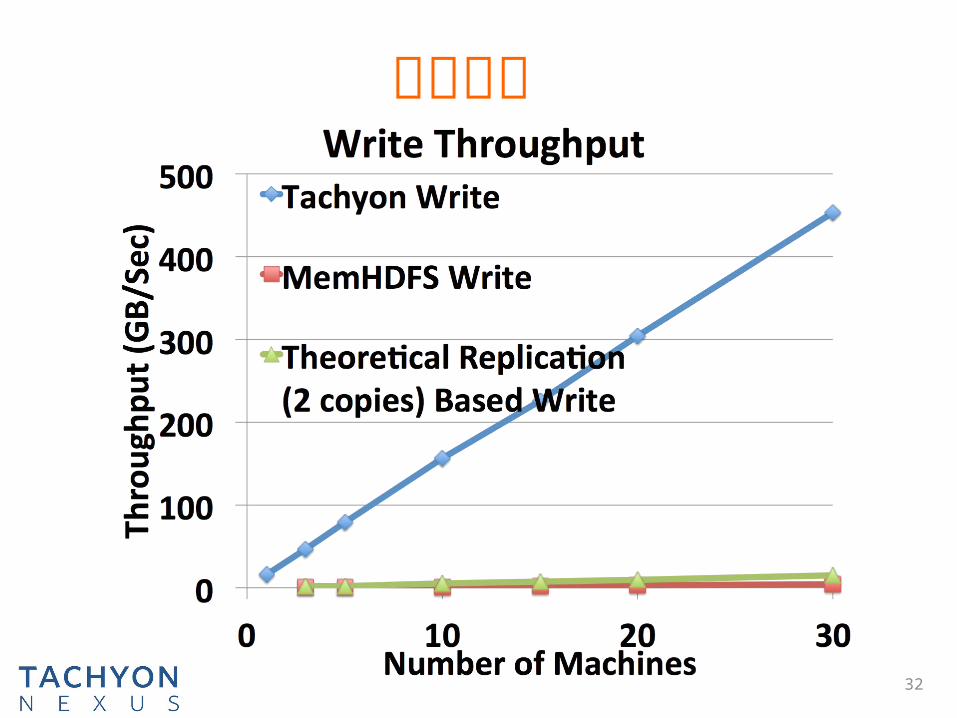
性能比较
32

使用 Tachyon 容易么 ?
33

Spark/MapReduce/Shark without Tachyon
• Sparkscala> val file = sc.textFile(“hdfs://ip:port/path”)
• Hadoop MapReduce$ hadoop jar hadoop-examples-1.0.4.jar wordcount hdfs://localhost:19998/input hdfs://localhost:19998/output
• SharkCREATE TABLE orders_cached AS SELECT * FROM orders;
34

Spark/MapReduce/Sharkwith Tachyon
• Sparkscala> val file = sc.textFile(“tachyon://ip:port/path”)
• Hadoop MapReduce$ hadoop jar hadoop-examples-1.0.4.jar wordcount tachyon://localhost:19998/input tachyon://localhost:19998/output
• SharkCREATE TABLE orders_tachyon AS SELECT * FROM orders;
35

大纲• Tachyon 系统– 背景– 系统架构– 使用
• Tachyon 开源项目– 近况– 产品用例
• 路线图36
开源项目概述• 2012 年夏天于 UC Berkeley AMPLab 开始• Apache License 2.0, Version 0.7 (2015 年 7月 )
• 在超过 50 家公司部署 (2014 年 7 月数据 )
• 有超过 30 家公司参与贡献代码37
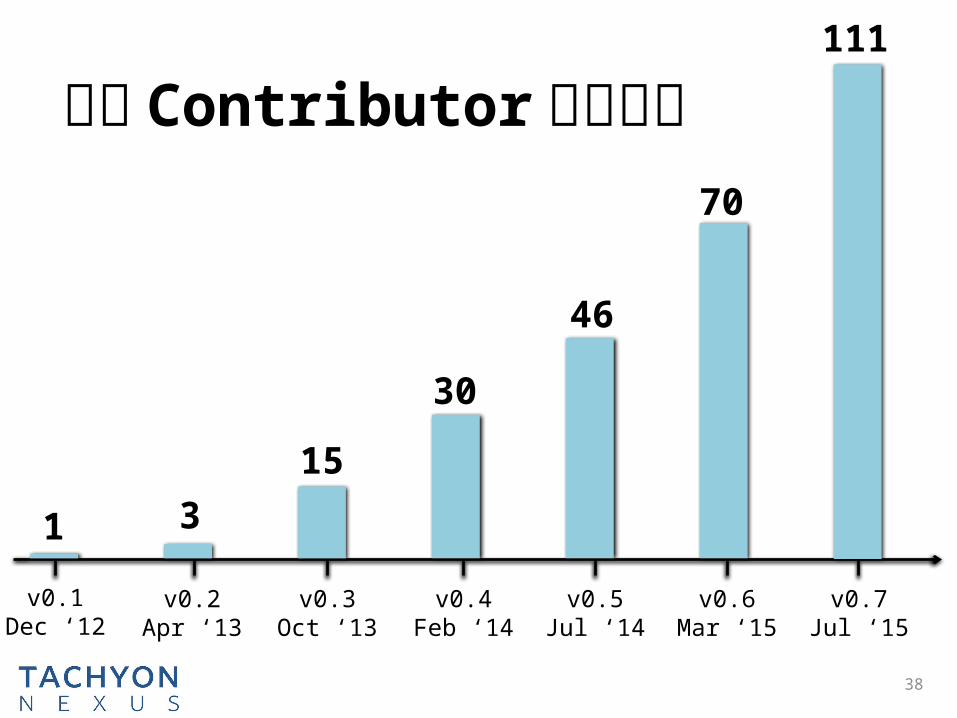
38
项目 Contributor 飞速增长
v0.4Feb ‘14
v0.3Oct ‘13
v0.2Apr ‘13
v0.1Dec ‘12
v0.6Mar ‘15
v0.5Jul ‘14
v0.7Jul ‘15
1 315
30
46
70
111
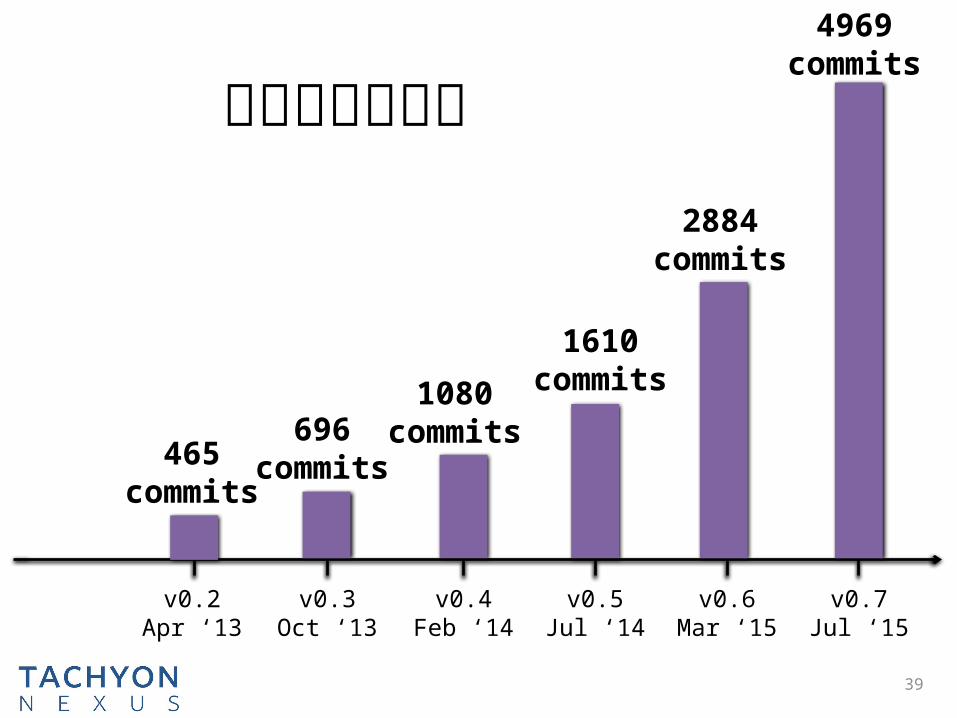
39
代码量飞速增长
v0.4Feb ‘14
v0.3Oct ‘13
v0.2Apr ‘13
v0.6Mar ‘15
v0.5Jul ‘14
v0.7Jul ‘15
465commits
696commits
1080commits
1610commits
2884commits
4969commits

感谢我们的 Contributors!
40

南京大学 PASA 大数据实验室• 顾荣博士– Tachyon 开源不到 4 个月便加入社区– Tachyon 项目核心开发者 , Meetup 组织者
• 5+ contributor
• 200+ commits
• Performance Benchmark, Tiered Storage41

• 合作 2 年以上• 10+ contributor
• 500+ commits
• Tiered Storage, System Stability, Security
42

见诸报道的 Tachyon
43

Under Filesystem: 丰富的选择(Big Data, Cloud, HPC, Enterprise)
44

• Framework: SparkSQL• Tachyon Storage: MEM + HDD• Under Storage: Baidu’s File System• 部署规模 : 100+ 节点• 管理存储容量 : 1PB+ • 提升性能 : 30x
More Details: www.meetup.com/Tachyon
用例一 : Baidu
45

用例二 : SAAS 公司• Framework: Impala
• Tachyon Storage: MEM + SSD
• Under Storage: S3
• 提升性能 : 15x
46

用例三 : 石油公司• Framework: Spark
• Tachyon Storage: MEM
• Under Storage: GlusterFS
• 分析传统存储系统中的数据47

用例四 : SAAS 公司• Framework: Spark
• Tachyon Storage: SSD
• Under Storage: S3
• Elastic Tachyon deployment
48

大纲• Tachyon 系统– 背景– 系统架构– 使用
• Tachyon 开源项目– 近况– 产品用例
• 路线图49

新功能• Lineage in Storage (alpha)• Tiered Storage (beta)
50

新功能• Lineage in Storage (alpha)• Tiered Storage (beta)• Data Serving• Support for New Hardware• …• Your New Feature!
51

52
Tachyon 的目标 ?
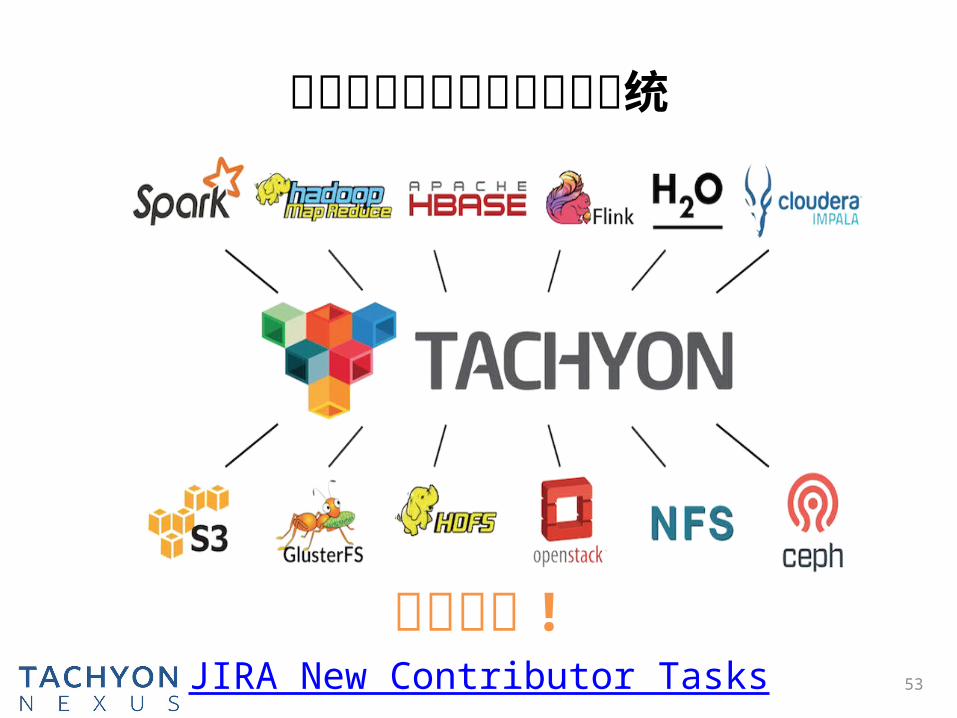
更方便更有效的使用其他系统
欢迎合作 !53JIRA New Contributor Tasks

• Website: http://tachyon-project.org
• Github: https://github.com/amplab/tachyon
• Meetup: http://www.meetup.com/Tachyon
• New Contributor Tasks: http://goo.gl/zmt2PS
• News Letter Subscription: http://goo.gl/mwB2sX
• Email: [email protected]

55


















