
ReproducingKernelHilbertSpacesinMachine Learninggretton/coursefiles/Slides4A.pdf ·...
133
Course overview Motivating examples Basics of reproducing kernel Hilbert spaces Simple kernel algorithms Reproducing Kernel Hilbert Spaces in Machine Learning Arthur Gretton, Gatsby Unit, CSML, UCL October 25, 2017 Reproducing Kernel Hilbert Spaces in Machine Learning
Transcript of ReproducingKernelHilbertSpacesinMachine Learninggretton/coursefiles/Slides4A.pdf ·...

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Reproducing Kernel Hilbert Spaces in MachineLearning
Arthur Gretton, Gatsby Unit, CSML, UCL
October 25, 2017
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Course overview (kernels part)
1 Construction of RKHS,2 Simple linear algorithms in RKHS (e.g. PCA, ridge regression)3 Kernel methods for hypothesis testing (two-sample,
independence)4 Further applications of kenels (feature selection, clustering,
ICA)5 Support vector machines for classification, regression6 Theory of reproducing kernel Hilbert spaces (optional, not
assessed)
Lecture notes will be put online at:http://www.gatsby.ucl.ac.uk/∼gretton/rkhscourse.html
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Assessment and locations
The course has the following assessment components:Written Examination (2.5 hours, 50%)Coursework (50%)
To pass this course, you must pass both the exam and thecoursework
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Course times, locations
Lectures will be at the Ground Floor Lecture Theatre, SainsburyWellcome Centre (with a couple of exceptions late in the term)
Kernel lectures are Wednesday, 11:30 -13:00,Theory lectures are Friday 14:00 -15:30
(with a couple of exceptions!)There will be lectures during reading week, due to clash with NIPSconference.The tutor for the kernels part is Michael Arbel.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Why kernel methods (1): XOR example
−5 −4 −3 −2 −1 0 1 2 3 4 5−5
−4
−3
−2
−1
0
1
2
3
4
5
x1
x2
No linear classifier separates red from blueMap points to higher dimensional feature space:φ(x) =
[x1 x2 x1x2
]∈ R3
Reproducing Kernel Hilbert Spaces in Machine Learning
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
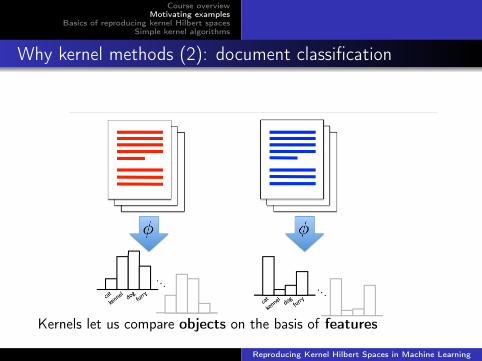
Why kernel methods (2): document classification
Kernels let us compare objects on the basis of features
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Why kernel methods(3): smoothing
−0.5 0 0.5 1 1.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
−0.5 0 0.5 1 1.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
−0.5 0 0.5 1 1.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
Kernel methods can control smoothness and avoidoverfitting/underfitting.
Reproducing Kernel Hilbert Spaces in Machine Learning

Basics of reproducing kernel Hilbert spaces

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Outline: reproducing kernel Hilbert space
We will describe in order:1 Hilbert space (very simple)2 Kernel (lots of examples: e.g. you can build kernels from
simpler kernels)3 Reproducing property
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Hilbert space
Definition (Inner product)
Let H be a vector space over R. A function 〈·, ·〉H : H×H → Ris an inner product on H if
1 Linear: 〈α1f1 + α2f2, g〉H = α1 〈f1, g〉H + α2 〈f2, g〉H2 Symmetric: 〈f , g〉H = 〈g , f 〉H3 〈f , f 〉H ≥ 0 and 〈f , f 〉H = 0 if and only if f = 0.
Norm induced by the inner product: ‖f ‖H :=√〈f , f 〉H
Definition (Hilbert space)
Inner product space containing Cauchy sequence limits.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Hilbert space
Definition (Inner product)
Let H be a vector space over R. A function 〈·, ·〉H : H×H → Ris an inner product on H if
1 Linear: 〈α1f1 + α2f2, g〉H = α1 〈f1, g〉H + α2 〈f2, g〉H2 Symmetric: 〈f , g〉H = 〈g , f 〉H3 〈f , f 〉H ≥ 0 and 〈f , f 〉H = 0 if and only if f = 0.
Norm induced by the inner product: ‖f ‖H :=√〈f , f 〉H
Definition (Hilbert space)
Inner product space containing Cauchy sequence limits.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Hilbert space
Definition (Inner product)
Let H be a vector space over R. A function 〈·, ·〉H : H×H → Ris an inner product on H if
1 Linear: 〈α1f1 + α2f2, g〉H = α1 〈f1, g〉H + α2 〈f2, g〉H2 Symmetric: 〈f , g〉H = 〈g , f 〉H3 〈f , f 〉H ≥ 0 and 〈f , f 〉H = 0 if and only if f = 0.
Norm induced by the inner product: ‖f ‖H :=√〈f , f 〉H
Definition (Hilbert space)
Inner product space containing Cauchy sequence limits.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Kernel
Definition
Let X be a non-empty set. A function k : X ×X → R is a kernelif there exists an R-Hilbert space and a feature map φ : X → Hsuch that ∀x , x ′ ∈ X ,
k(x , x ′) :=⟨φ(x), φ(x ′)
⟩H .
Almost no conditions on X (eg, X itself doesn’t need an innerproduct, eg. documents).A single kernel can correspond to several possible featuremaps. A trivial example for X := R:
φ1(x) = x and φ2(x) =
[x/√2
x/√2
]Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
New kernels from old: sums, transformations
Theorem (Sums of kernels are kernels)
Given α > 0 and k , k1 and k2 all kernels on X , then αk andk1 + k2 are kernels on X .
(Proof via positive definiteness: later!) A difference of kernels maynot be a kernel (why?)
Theorem (Mappings between spaces)
Let X and X be sets, and define a map A : X → X . Define thekernel k on X . Then the kernel k(A(x),A(x ′)) is a kernel on X .
Example: k(x , x ′) = x2 (x ′)2 .
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
New kernels from old: sums, transformations
Theorem (Sums of kernels are kernels)
Given α > 0 and k , k1 and k2 all kernels on X , then αk andk1 + k2 are kernels on X .
(Proof via positive definiteness: later!) A difference of kernels maynot be a kernel (why?)
Theorem (Mappings between spaces)
Let X and X be sets, and define a map A : X → X . Define thekernel k on X . Then the kernel k(A(x),A(x ′)) is a kernel on X .
Example: k(x , x ′) = x2 (x ′)2 .
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
New kernels from old: products
Theorem (Products of kernels are kernels)
Given k1 on X1 and k2 on X2, then k1 × k2 is a kernel on X1 ×X2.If X1 = X2 = X , then k := k1 × k2 is a kernel on X .
Proof: Main idea only!k1 is a kernel between shapes,
φ1(x) =
[I�I4
]φ1(�) =
[10
], k1(�,4) = 0.
k2 is a kernel between colors,
φ2(x) =
[I•I•
]φ2(•) =
[01
]k2(•, •) = 1.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
New kernels from old: products
“Natural” feature space for colored shapes:
Φ(x) =
[I� I4I� I4
]=
[I•I•
] [I� I4
]= φ2(x)φ>1 (x)
Kernel is:
k(x , x ′) =∑
i∈{•,•}
∑j∈{�,4}
Φij(x)Φij(x′) = tr
φ1(x)φ>2 (x)φ2(x ′)︸ ︷︷ ︸k2(x ,x ′)
φ>1 (x ′)
= tr
φ>1 (x ′)φ1(x)︸ ︷︷ ︸k1(x ,x ′)
k2(x , x ′) = k1(x , x ′)k2(x , x ′)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
New kernels from old: products
“Natural” feature space for colored shapes:
Φ(x) =
[I� I4I� I4
]=
[I•I•
] [I� I4
]= φ2(x)φ>1 (x)
Kernel is:
k(x , x ′) =∑
i∈{•,•}
∑j∈{�,4}
Φij(x)Φij(x′) = tr
φ1(x)φ>2 (x)φ2(x ′)︸ ︷︷ ︸k2(x ,x ′)
φ>1 (x ′)
= tr
φ>1 (x ′)φ1(x)︸ ︷︷ ︸k1(x ,x ′)
k2(x , x ′) = k1(x , x ′)k2(x , x ′)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Sums and products =⇒ polynomials
Theorem (Polynomial kernels)
Let x , x ′ ∈ Rd for d ≥ 1, and let m ≥ 1 be an integer and c ≥ 0 bea positive real. Then
k(x , x ′) :=(⟨x , x ′
⟩+ c)m
is a valid kernel.
To prove: expand into a sum (with non-negative scalars) of kernels〈x , x ′〉 raised to integer powers. These individual terms are validkernels by the product rule.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Infinite sequences
The kernels we’ve seen so far are dot products between finitelymany features. E.g.
k(x , y) =[sin(x) x3 log x
]> [ sin(y) y3 log y]
where φ(x) =[sin(x) x3 log x
]Can a kernel be a dot product between infinitely many features?
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Infinite sequences
DefinitionThe space `2 (square summable sequences) comprises allsequences (ai )i≥1 for which
∞∑i=1
a2i <∞.
TheoremGiven sequence of functions (φi (x))i≥1 in `2 where φi : X → R isthe ith coordinate of φ(x). A well-defined kernel k on X is
k(x , x ′) :=∞∑i=1
φi (x)φi (x′). (1)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Infinite sequences
DefinitionThe space `2 (square summable sequences) comprises allsequences (ai )i≥1 for which
∞∑i=1
a2i <∞.
TheoremGiven sequence of functions (φi (x))i≥1 in `2 where φi : X → R isthe ith coordinate of φ(x). A well-defined kernel k on X is
k(x , x ′) :=∞∑i=1
φi (x)φi (x′). (1)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Infinite sequences (proof)
Proof: We just need to check that inner product remains finite.Norm ‖a‖`2 associated with inner product (1)
‖a‖`2 :=
√√√√ ∞∑i=1
a2i ,
where a represents sequence with terms ai . Via Cauchy-Schwarz,∣∣∣∣∣∞∑i=1
φi (x)φi (x′)
∣∣∣∣∣ ≤ ‖φi (x)‖`2∥∥φi (x ′)∥∥`2 ,
so the sequence defining the inner product converges for allx , x ′ ∈ X
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Taylor series kernels
Definition (Taylor series kernel)
For r ∈ (0,∞], with an ≥ 0 for all n ≥ 0
f (z) =∞∑n=0
anzn |z | < r , z ∈ R,
Define X to be the√r -ball in Rd , so ‖x‖ < √r ,
k(x , x ′) = f(⟨x , x ′
⟩)=∞∑n=0
an⟨x , x ′
⟩n.
Example (Exponential kernel)
k(x , x ′) := exp(⟨x , x ′
⟩).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Taylor series kernel (proof)
Proof: Non-negative weighted sums of kernels are kernels, andproducts of kernels are kernels, so the following is a kernel if itconverges:
k(x , x ′) =∞∑n=0
an(⟨x , x ′
⟩)nBy Cauchy-Schwarz, ∣∣⟨x , x ′⟩∣∣ ≤ ‖x‖‖x ′‖ < r ,
so the sum converges.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Exponentiated quadratic kernel
Example (Exponentiated quadratic kernel)
This kernel on Rd is defined as
k(x , x ′) := exp(−γ−2
∥∥x − x ′∥∥2) .
Proof: an exercise! Use product rule, mapping rule, exponentialkernel.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Positive definite functions
If we are given a function of two arguments, k(x , x ′), how can wedetermine if it is a valid kernel?
1 Find a feature map?1 Sometimes this is not obvious (eg if the feature vector is
infinite dimensional, like the exponentiated quadratic kernel inthe last slide)
2 The feature map is not unique.
2 A direct property of the function: positive definiteness.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Positive definite functions
Definition (Positive definite functions)
A symmetric function k : X × X → R is positive definite if∀n ≥ 1, ∀(a1, . . . an) ∈ Rn, ∀(x1, . . . , xn) ∈ X n,
n∑i=1
n∑j=1
aiajk(xi , xj) ≥ 0.
The function k(·, ·) is strictly positive definite if for mutuallydistinct xi , the equality holds only when all the ai are zero.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Kernels are positive definite
Theorem
Let H be a Hilbert space, X a non-empty set and φ : X → H.Then 〈φ(x), φ(y)〉H =: k(x , y) is positive definite.
Proof.
n∑i=1
n∑j=1
aiajk(xi , xj) =n∑
i=1
n∑j=1
〈aiφ(xi ), ajφ(xj)〉H
=
∥∥∥∥∥n∑
i=1
aiφ(xi )
∥∥∥∥∥2
H
≥ 0.
Reverse also holds: positive definite k(x , x ′) is inner product in Hbetween φ(x) and φ(x ′).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Sum of kernels is a kernel
Consider two kernels k1(x , x ′) and k2(x , x ′). Then
n∑i=1
n∑j=1
aiaj [k1(xi , xj) + k2(xi , xj)]
=n∑
i=1
n∑j=1
aiajk1(xi , xj) +n∑
i=1
n∑j=1
aiajk2(xi , xj)
≥ 0
Reproducing Kernel Hilbert Spaces in Machine Learning

The reproducing kernel Hilbert space
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
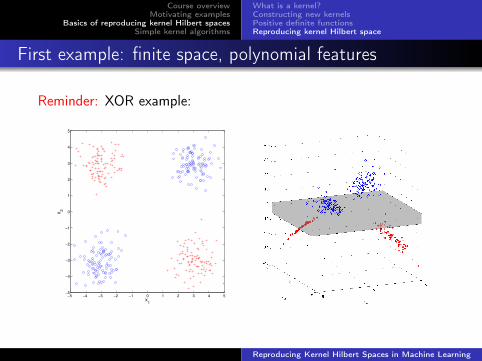
First example: finite space, polynomial features
Reminder: XOR example:
−5 −4 −3 −2 −1 0 1 2 3 4 5−5
−4
−3
−2
−1
0
1
2
3
4
5
x1
x2
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
First example: finite space, polynomial features
Reminder: Feature space from XOR motivating example:
φ : R2 → R3
x =
[x1x2
]7→ φ(x) =
x1x2x1x2
,with kernel
k(x , y) =
x1x2x1x2
> y1y2y1y2
(the standard inner product in R3 between features). Denote thisfeature space by H.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
First example: finite space, polynomial features
Define a linear function of the inputs x1, x2, and their product x1x2,
f (x) = f1x1 + f2x2 + f3x1x2.
f in a space of functions mapping from X = R2 to R. Equivalentrepresentation for f ,
f (·) =[f1 f2 f3
]>.
f (·) refers to the function as an object (here as a vector in R3)f (x) ∈ R is function evaluated at a point (a real number).
f (x) = f (·)>φ(x) = 〈f (·), φ(x)〉HEvaluation of f at x is an inner product in feature space (herestandard inner product in R3)H is a space of functions mapping R2 to R.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
First example: finite space, polynomial features
Define a linear function of the inputs x1, x2, and their product x1x2,
f (x) = f1x1 + f2x2 + f3x1x2.
f in a space of functions mapping from X = R2 to R. Equivalentrepresentation for f ,
f (·) =[f1 f2 f3
]>.
f (·) refers to the function as an object (here as a vector in R3)f (x) ∈ R is function evaluated at a point (a real number).
f (x) = f (·)>φ(x) = 〈f (·), φ(x)〉HEvaluation of f at x is an inner product in feature space (herestandard inner product in R3)H is a space of functions mapping R2 to R.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
What if we have infinitely many features?
Exponentiated quadratic kernel,
k(x , y) = exp(−‖x − y‖2
2σ2
)=∞∑i=1
φi (x)φi (y)
f (x) =∞∑i=1
fiφi (x)∞∑i=1
f 2i <∞.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
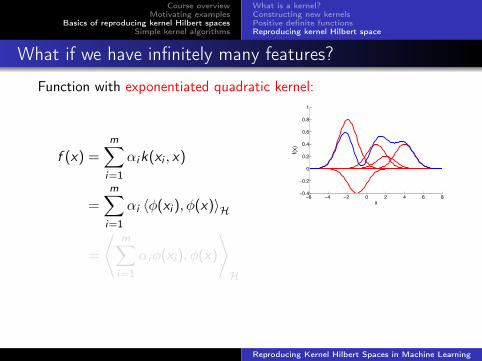
What if we have infinitely many features?
Function with exponentiated quadratic kernel:
f (x) =m∑i=1
αik(xi , x)
=m∑i=1
αi 〈φ(xi ), φ(x)〉H
=
⟨m∑i=1
αiφ(xi ), φ(x)
⟩H
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
Reproducing Kernel Hilbert Spaces in Machine Learning
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
What if we have infinitely many features?
Function with exponentiated quadratic kernel:
f (x) =m∑i=1
αik(xi , x)
=m∑i=1
αi 〈φ(xi ), φ(x)〉H
=
⟨m∑i=1
αiφ(xi ), φ(x)
⟩H
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
What if we have infinitely many features?
Function with exponentiated quadratic kernel:
f (x) =m∑i=1
αik(xi , x)
=m∑i=1
αi 〈φ(xi ), φ(x)〉H
=
⟨m∑i=1
αiφ(xi ), φ(x)
⟩H
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
What if we have infinitely many features?
Function with exponentiated quadratic kernel:
f (x) =m∑i=1
αik(xi , x)
=m∑i=1
αi 〈φ(xi ), φ(x)〉H
=
⟨m∑i=1
αiφ(xi ), φ(x)
⟩H
=∞∑`=1
f`φ`(x)
= 〈f (·), φ(x)〉H
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
f` :=∑m
i=1 αiφ`(xi )
Possible to write func-tions of infinitely manyfeatures!
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
What if we have infinitely many features?
Function with exponentiated quadratic kernel:
f (x) =m∑i=1
αik(xi , x)
=m∑i=1
αi 〈φ(xi ), φ(x)〉H
=
⟨m∑i=1
αiφ(xi ), φ(x)
⟩H
=∞∑`=1
f`φ`(x)
= 〈f (·), φ(x)〉H
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
f` :=∑m
i=1 αiφ`(xi )
Possible to write func-tions of infinitely manyfeatures!
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
The feature map is also a function
On previous page,
f (x) :=m∑i=1
αik(xi , x) = 〈f (·), φ(x)〉H where f (·) =m∑i=1
αiφ(xi ).
What if m = 1 and α1 = 1?Then
f (x) = k(x1, x) =
⟨k(x1, ·)︸ ︷︷ ︸
=f (·)=φ(x1)
, φ(x)
⟩H
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
The feature map is also a function
On previous page,
f (x) :=m∑i=1
αik(xi , x) = 〈f (·), φ(x)〉H where f (·) =m∑i=1
αiφ(xi ).
What if m = 1 and α1 = 1?Then
f (x) = k(x1, x) =
⟨k(x1, ·)︸ ︷︷ ︸
=f (·)=φ(x1)
, φ(x)
⟩H
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
The feature map is also a function
On previous page,
f (x) :=m∑i=1
αik(xi , x) = 〈f (·), φ(x)〉H where f (·) =m∑i=1
αiφ`(xi ).
What if m = 1 and α1 = 1?Then
f (x) = k(x1, x) =
⟨k(x1, ·)︸ ︷︷ ︸
=f (·)=φ(x1)
, φ(x)
⟩H
= 〈k(x , ·), φ(x1)〉H....so the feature map is a (very simple) function!We can write without ambiguity
k(x , y) = 〈k (·, x) , k (·, y)〉H.Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
The feature map is also a function
On previous page,
f (x) :=m∑i=1
αik(xi , x) = 〈f (·), φ(x)〉H where f (·) =m∑i=1
αiφ`(xi ).
What if m = 1 and α1 = 1?Then
f (x) = k(x1, x) =
⟨k(x1, ·)︸ ︷︷ ︸
=f (·)=φ(x1)
, φ(x)
⟩H
= 〈k(x , ·), φ(x1)〉H....so the feature map is a (very simple) function!We can write without ambiguity
k(x , y) = 〈k (·, x) , k (·, y)〉H.Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
The reproducing property
This example illustrates the two defining features of an RKHS:The reproducing property:∀x ∈ X , ∀f (·) ∈ H, 〈f (·), k(·, x)〉H = f (x). . .or use shorter notation 〈f , φ(x)〉H.In particular, for any x , y ∈ X ,
k(x , y) = 〈k (·, x) , k (·, y)〉H.
Note: the feature map of every point is in the feature space:∀x ∈ X , k(·, x) = φ(x) ∈ H,
Reproducing Kernel Hilbert Spaces in Machine Learning
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
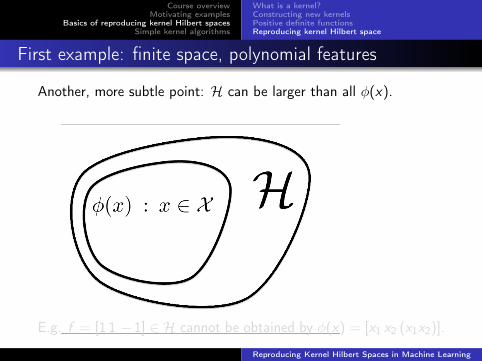
First example: finite space, polynomial features
Another, more subtle point: H can be larger than all φ(x).
E.g. f = [1 1 − 1] ∈ H cannot be obtained by φ(x) = [x1 x2 (x1x2)].
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
First example: finite space, polynomial features
Another, more subtle point: H can be larger than all φ(x).
E.g. f = [1 1 − 1] ∈ H cannot be obtained by φ(x) = [x1 x2 (x1x2)].
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Second (infinite) example: fourier series
Function on the interval [−π, π] with periodic boundary. Fourierseries:
f (x) =∞∑
`=−∞f` exp(ı`x) =
∞∑l=−∞
f` (cos(`x) + ı sin(`x)) .
using the orthonormal basis on [−π, π],
12π
∫ π
−πexp(ı`x)exp(ımx)dx =
{1 ` = m,
0 ` 6= m.
Example: “top hat” function,
f (x) =
{1 |x | < T ,
0 T ≤ |x | < π.
f` :=sin(`T )
`πf (x) =
∞∑`=0
2f` cos(`x).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Second (infinite) example: fourier series
Function on the interval [−π, π] with periodic boundary. Fourierseries:
f (x) =∞∑
`=−∞f` exp(ı`x) =
∞∑l=−∞
f` (cos(`x) + ı sin(`x)) .
using the orthonormal basis on [−π, π],
12π
∫ π
−πexp(ı`x)exp(ımx)dx =
{1 ` = m,
0 ` 6= m.
Example: “top hat” function,
f (x) =
{1 |x | < T ,
0 T ≤ |x | < π.
f` :=sin(`T )
`πf (x) =
∞∑`=0
2f` cos(`x).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 100
0.1
0.2
0.3
0.4
0.5
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 100
0.1
0.2
0.3
0.4
0.5
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 10−0.2
0
0.2
0.4
0.6
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 10−0.2
0
0.2
0.4
0.6
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 10−0.2
0
0.2
0.4
0.6
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 10−0.2
0
0.2
0.4
0.6
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for top hat function
−4 −2 0 2 4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x
)
Top hat
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 10−0.2
0
0.2
0.4
0.6
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for kernel function
Kernel takes a single argument,
k(x , y) = k(x − y),
Define the Fourier series representation of k
k(x) =∞∑
`=−∞k` exp (ı`x) ,
k and its Fourier transform are real and symmetric. For example,
k(x) =12πϑ
(x
2π,ıσ2
2π
), k` =
12π
exp(−σ2`2
2
).
ϑ is the Jacobi theta function, close to exponentiated quadratic when σ2 sufficientlynarrower than [−π, π].
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for “Gaussian spectrum” kernel
−4 −2 0 2 4−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
x
k(x
)
Jacobi Theta
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 100
0.05
0.1
0.15
0.2
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for “Gaussian spectrum” kernel
−4 −2 0 2 4−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
x
k(x
)
Jacobi Theta
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 100
0.05
0.1
0.15
0.2
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for “Gaussian spectrum” kernel
−4 −2 0 2 4−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
x
k(x
)
Jacobi Theta
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 100
0.05
0.1
0.15
0.2
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Fourier series for “Gaussian spectrum” kernel
−4 −2 0 2 4−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
x
k(x
)
Jacobi Theta
−4 −2 0 2 4−1
−0.5
0
0.5
1
t
cos(ℓ×
x)
Basis function
−10 −5 0 5 100
0.05
0.1
0.15
0.2
ℓ
fℓ
Fourier series coefficients
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
RKHS via fourier series
Recall standard dot product in L2:
〈f , g〉L2 =
⟨ ∞∑`=−∞
f` exp(ı`x),∞∑
m=−∞gm exp(ımx)
⟩L2
=∞∑
`=−∞
∞∑m=−∞
f`g ` 〈exp(ı`x), exp(−ımx)〉L2
=∞∑
`=−∞f`g `.
Define the dot product in H to have a roughness penalty,
〈f , g〉H =∞∑
`=−∞
f`g `
k`.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
RKHS via fourier series
Recall standard dot product in L2:
〈f , g〉L2 =
⟨ ∞∑`=−∞
f` exp(ı`x),∞∑
m=−∞gm exp(ımx)
⟩L2
=∞∑
`=−∞
∞∑m=−∞
f`g ` 〈exp(ı`x), exp(−ımx)〉L2
=∞∑
`=−∞f`g `.
Define the dot product in H to have a roughness penalty,
〈f , g〉H =∞∑
`=−∞
f`g `
k`.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Roughness penalty explained
The squared norm of a function f in H enforces smoothness:
‖f ‖2H = 〈f , f 〉H =∞∑
l=−∞
f`f`
k`=
∞∑l=−∞
∣∣∣f`∣∣∣2k`
.
If k` decays fast, then so must f` if we want ‖f ‖2H <∞.Recall f (x) =
∑∞`=−∞ f` (cos(`x) + ı sin(`x)) .
Question: is the top hat function in the “Gaussian spectrum”RKHS?Warning: need stronger conditions on kernel than L2 convergence: Mercer’s theorem
(later).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Roughness penalty explained
The squared norm of a function f in H enforces smoothness:
‖f ‖2H = 〈f , f 〉H =∞∑
l=−∞
f`f`
k`=
∞∑l=−∞
∣∣∣f`∣∣∣2k`
.
If k` decays fast, then so must f` if we want ‖f ‖2H <∞.Recall f (x) =
∑∞`=−∞ f` (cos(`x) + ı sin(`x)) .
Question: is the top hat function in the “Gaussian spectrum”RKHS?Warning: need stronger conditions on kernel than L2 convergence: Mercer’s theorem
(later).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Roughness penalty explained
The squared norm of a function f in H enforces smoothness:
‖f ‖2H = 〈f , f 〉H =∞∑
l=−∞
f`f`
k`=
∞∑l=−∞
∣∣∣f`∣∣∣2k`
.
If k` decays fast, then so must f` if we want ‖f ‖2H <∞.Recall f (x) =
∑∞`=−∞ f` (cos(`x) + ı sin(`x)) .
Question: is the top hat function in the “Gaussian spectrum”RKHS?Warning: need stronger conditions on kernel than L2 convergence: Mercer’s theorem
(later).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Feature map and reproducing property
Reproducing property: define a function
g(x) := k(x − z) =∞∑
`=−∞exp (ı`x) k` exp (−ı`z)︸ ︷︷ ︸
g`
Then for a function f (·) ∈ H,
〈f (·), k(·, z)〉H = 〈f (·), g(·)〉H
=∞∑
`=−∞
f`
(k` exp(−ı`z)
)k`
=∞∑
`=−∞f` exp(ı`z) = f (z).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Feature map and reproducing property
Reproducing property for the kernel:Recall kernel definition:
k(x − y) =∞∑
`=−∞k` exp (ı`(x − y)) =
∞∑`=−∞
k` exp (ı`x) exp (−ı`y)
Define two functions
f (x) := k(x − y) =∞∑
`=−∞k` exp (ı`(x − y))
=∞∑
`=−∞exp (ı`x) k` exp (−ı`y)︸ ︷︷ ︸
f`
g(x) := k(x − z) =∞∑
`=−∞exp (ı`x) k` exp (−ı`z)︸ ︷︷ ︸
g`Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Feature map and reproducing property
Check the reproducing property:
〈k(·, y), k(·, z)〉H = 〈f (·), g(·)〉H
=∞∑
`=−∞
f`g `
k`
=∞∑
`=−∞
(k` exp(−ı`y)
)(k` exp(−ı`z)
)k`
=∞∑
`=−∞k` exp(ı`(z − y)) = k(z − y).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to original RKHS definition
Original form of a function in the RKHS was (detail: sum now from −∞ to ∞,
complex conjugate)
f (x) =∞∑
`=−∞f`φ`(x) = 〈f (·), φ(x)〉H .
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑
l=−∞
f`g`
k`〈f (·), k(·, z)〉H =
∞∑`=−∞
f`
(k` exp(−ı`z)
)k`
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to original RKHS definition
Original form of a function in the RKHS was (detail: sum now from −∞ to ∞,
complex conjugate)
f (x) =∞∑
`=−∞f`φ`(x) = 〈f (·), φ(x)〉H .
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑
l=−∞
f`g`
k`〈f (·), k(·, z)〉H =
∞∑`=−∞
f`
(k` exp(−ı`z)
)(√
k`
)2
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to original RKHS definition
Original form of a function in the RKHS was (detail: sum now from −∞ to ∞,
complex conjugate)
f (x) =∞∑
`=−∞f`φ`(x) = 〈f (·), φ(x)〉H .
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑
l=−∞
f`g`
k`〈f (·), k(·, z)〉H =
∞∑`=−∞
f`
(k` exp(−ı`z)
)(√
k`
)2By inspection
f` = f`/
√k` φ`(x) =
√k` exp(−ı`x).
Reproducing Kernel Hilbert Spaces in Machine Learning
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
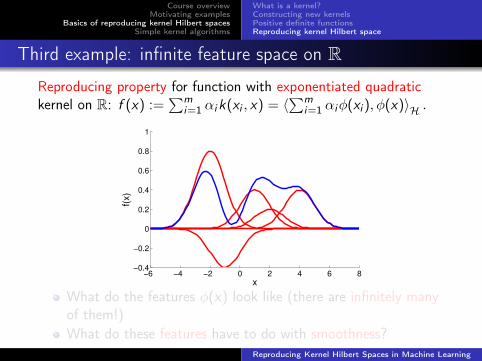
Third example: infinite feature space on RReproducing property for function with exponentiated quadratickernel on R: f (x) :=
∑mi=1 αik(xi , x) = 〈∑m
i=1 αiφ(xi ), φ(x)〉H .
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
What do the features φ(x) look like (there are infinitely manyof them!)What do these features have to do with smoothness?
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Third example: infinite feature space on RReproducing property for function with exponentiated quadratickernel on R: f (x) :=
∑mi=1 αik(xi , x) = 〈∑m
i=1 αiφ(xi ), φ(x)〉H .
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
What do the features φ(x) look like (there are infinitely manyof them!)What do these features have to do with smoothness?
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Third example: infinite feature space on R
Define a probability measure on X := R. We’ll use the Gaussiandensity,
dµ(x) =1√2π
exp(−x2
)dx
Define the eigenexpansion of k(x , x ′) wrt this measure:
λiei (x) =
∫k(x , x ′)ei (x
′)dµ(x ′),
∫L2(µ)
ei (x)ej(x)dµ(x) =
{1 i = j
0 i 6= j .
We can write
k(x , x ′) =∞∑`=1
λ`e`(x)e`(x′),
which converges in L2(µ).Warning: again, need stronger conditions on kernel than L2 convergence.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Third example: infinite feature space on R
Define a probability measure on X := R. We’ll use the Gaussiandensity,
dµ(x) =1√2π
exp(−x2
)dx
Define the eigenexpansion of k(x , x ′) wrt this measure:
λiei (x) =
∫k(x , x ′)ei (x
′)dµ(x ′),
∫L2(µ)
ei (x)ej(x)dµ(x) =
{1 i = j
0 i 6= j .
We can write
k(x , x ′) =∞∑`=1
λ`e`(x)e`(x′),
which converges in L2(µ).Warning: again, need stronger conditions on kernel than L2 convergence.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Third example: infinite feature space on RExponentiated quadratic kernel, k(x , y) = exp
(−‖x−y‖22σ2
), and
Gaussian µ, yield
λk ∝ bk b < 1ek(x) ∝ exp(−(c − a)x2)Hk(x
√2c),
a, b, c are functions of σ, and Hk is kth order Hermite polynomial.
e1(x)
e2(x)
e3(x)
k(x , x ′) =∞∑i=1
λiei (x)ei (x′)
Result from Rasmussen andWilliams (2006, Section 4.3)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Third example: infinite feature space
Reminder: for two functions f , g in L2(µ),
f (x) =∞∑`=1
f`e`(x) g(x) =∞∑`=1
g`e`(x),
dot product is
〈f , g〉L2(µ) =
⟨ ∞∑`=1
f`e`(x),∞∑`=1
g`e`(x)
⟩L2(µ)
=∞∑`=1
f`g`.
Define the dot product in H to have a roughness penalty,
〈f , g〉H =∞∑`=1
f`g`λ`
‖f ‖2H =∞∑`=1
f 2`λ`.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Third example: infinite feature space
Reminder: for two functions f , g in L2(µ),
f (x) =∞∑`=1
f`e`(x) g(x) =∞∑`=1
g`e`(x),
dot product is
〈f , g〉L2(µ) =
⟨ ∞∑`=1
f`e`(x),∞∑`=1
g`e`(x)
⟩L2(µ)
=∞∑`=1
f`g`.
Define the dot product in H to have a roughness penalty,
〈f , g〉H =∞∑`=1
f`g`λ`
‖f ‖2H =∞∑`=1
f 2`λ`.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to the original RKHS definition
Original form of a function in the RKHS was
f (x) =∞∑`=1
f`φ`(x) = 〈f (·), φ(x)〉H
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to the original RKHS definition
Original form of a function in the RKHS was
f (x) =∞∑`=1
f`φ`(x) = 〈f (·), φ(x)〉H
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑l=1
f`g`λ`
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to the original RKHS definition
Original form of a function in the RKHS was
f (x) =∞∑`=1
f`φ`(x) = 〈f (·), φ(x)〉H
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑l=1
f`g`λ`
g(z) = k(x , z) =∞∑`=1
λ`e`(z)︸ ︷︷ ︸g`
e`(x)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to the original RKHS definition
Original form of a function in the RKHS was
f (x) =∞∑`=1
f`φ`(x) = 〈f (·), φ(x)〉H
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑l=1
f`g`λ`
〈f (·), k(·, z)〉H =∞∑`=1
f`
g`︷ ︸︸ ︷(λ`e`(z))
λ`
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to the original RKHS definition
Original form of a function in the RKHS was
f (x) =∞∑`=1
f`φ`(x) = 〈f (·), φ(x)〉H
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑l=1
f`g`λ`
〈f (·), k(·, z)〉H =∞∑
`=−∞
f` (λ`e`(z))(√λ`)2
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Link back to the original RKHS definition
Original form of a function in the RKHS was
f (x) =∞∑`=1
f`φ`(x) = 〈f (·), φ(x)〉H
We’ve defined the RKHS dot product as
〈f , g〉H =∞∑l=1
f`g`λ`
〈f (·), k(·, z)〉H =∞∑
`=−∞
f` (λ`e`(z))(√λ`)2
By inspection
f` = f`/√λ` φ`(x) =
√λ`e`(x).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Writing RKHS functions without explicit features
Example RKHS function from earlier:
f (x) :=m∑i=1
αik(xi , x) =m∑i=1
αi
∞∑j=1
λjej(xi )ej(x)
=∞∑j=1
fj
[√λjej(x)
]︸ ︷︷ ︸
φj (x)
where fj =∑m
i=1 αi
√λjej(xi ).
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
NOTE that thisenforces
smoothing:λj decay as ej
become rougher,fj decay since∑
j f2j <∞.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Explicit feature space as element of `2Does this work? Is f (x) <∞ despite the infinite feature space?Finiteness of f (x) = 〈f , φ(x)〉H obtained by Cauchy-Schwarz,
|〈f , φ(x)〉H| =
∣∣∣∣∣∞∑i=1
fi√λiei (x)
∣∣∣∣∣ ≤( ∞∑
i=1
f 2i
)1/2( ∞∑i=1
λie2i (x)
)1/2
= ‖f ‖`2√k(x , x).
and by triangle inequality,
‖f ‖`2 =
∥∥∥∥∥m∑i=1
αiφ(xi )
∥∥∥∥∥≤
m∑i=1
|αi | ‖φ(xi )‖ <∞.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Explicit feature space as element of `2Does this work? Is f (x) <∞ despite the infinite feature space?Finiteness of f (x) = 〈f , φ(x)〉H obtained by Cauchy-Schwarz,
|〈f , φ(x)〉H| =
∣∣∣∣∣∞∑i=1
fi√λiei (x)
∣∣∣∣∣ ≤( ∞∑
i=1
f 2i
)1/2( ∞∑i=1
λie2i (x)
)1/2
= ‖f ‖`2√k(x , x).
and by triangle inequality,
‖f ‖`2 =
∥∥∥∥∥m∑i=1
αiφ(xi )
∥∥∥∥∥≤
m∑i=1
|αi | ‖φ(xi )‖ <∞.
Reproducing Kernel Hilbert Spaces in Machine Learning

Some reproducing kernel Hilbert space theory

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Reproducing kernel Hilbert space (1)
DefinitionH a Hilbert space of R-valued functions on non-empty set X . Afunction k : X × X → R is a reproducing kernel of H, and H is areproducing kernel Hilbert space, if
∀x ∈ X , k(·, x) ∈ H,∀x ∈ X , ∀f ∈ H, 〈f (·), k(·, x)〉H = f (x) (the reproducingproperty).
In particular, for any x , y ∈ X ,
k(x , y) = 〈k (·, x) , k (·, y)〉H. (2)
Original definition: kernel an inner product between feature maps.Then φ(x) = k(·, x) a valid feature map.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Reproducing kernel Hilbert space (2)
Another RKHS definition:Define δx to be the operator of evaluation at x , i.e.
δx f = f (x) ∀f ∈ H, x ∈ X .
Definition (Reproducing kernel Hilbert space)
H is an RKHS if the evaluation operator δx is bounded: ∀x ∈ Xthere exists λx ≥ 0 such that for all f ∈ H,
|f (x)| = |δx f | ≤ λx‖f ‖H
=⇒ two functions identical in RHKS norm agree at every point:
|f (x)− g(x)| = |δx (f − g)| ≤ λx‖f − g‖H ∀f , g ∈ H.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
RKHS definitions equivalent
Theorem (Reproducing kernel equivalent to bounded δx )
H is a reproducing kernel Hilbert space (i.e., its evaluationoperators δx are bounded linear operators), if and only if H has areproducing kernel.
Proof: If H has a reproducing kernel =⇒ δx bounded
|δx [f ]| = |f (x)|= |〈f , k(·, x)〉H|≤ ‖k(·, x)‖H ‖f ‖H= 〈k(·, x), k(·, x)〉1/2H ‖f ‖H= k(x , x)1/2 ‖f ‖H
Cauchy-Schwarz in 3rd line . Consequently, δx : F → R boundedwith λx = k(x , x)1/2 (other direction: Riesz theorem).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Moore-Aronsajn
Theorem (Moore-Aronszajn)
Every positive definite kernel k uniquely associated with RKHS H.
Recall feature map is not unique (as we saw earlier): only kernel is.Example RKHS function, exponentiated quadratic kernel:f (·) :=
∑mi=1 αik(xi , ·).
−6 −4 −2 0 2 4 6 8−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
What is a kernel?Constructing new kernelsPositive definite functionsReproducing kernel Hilbert space
Correspondence
Reproducing Kernel Hilbert Spaces in Machine Learning

Simple Kernel Algorithms

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Distance between means (1)
Sample (xi )mi=1 from p and (yi )
mi=1 from q. What is the distance
between their means in feature space?
∥∥∥∥∥∥ 1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj)
∥∥∥∥∥∥2
H
=
⟨1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj),1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj)
⟩H
=1m2
⟨m∑i=1
φ(xi ),m∑i=1
φ(xi )
⟩+ . . .
=1m2
m∑i=1
m∑j=1
k(xi , xj) +1n2
n∑i=1
n∑j=1
k(yi , yj)−2mn
m∑i=1
m∑j=1
k(xi , yj).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Distance between means (1)
Sample (xi )mi=1 from p and (yi )
mi=1 from q. What is the distance
between their means in feature space?
∥∥∥∥∥∥ 1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj)
∥∥∥∥∥∥2
H
=
⟨1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj),1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj)
⟩H
=1m2
⟨m∑i=1
φ(xi ),m∑i=1
φ(xi )
⟩+ . . .
=1m2
m∑i=1
m∑j=1
k(xi , xj) +1n2
n∑i=1
n∑j=1
k(yi , yj)−2mn
m∑i=1
m∑j=1
k(xi , yj).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Distance between means (2)
Sample (xi )mi=1 from p and (yi )
mi=1 from q. What is the distance
between their means in feature space?∥∥∥∥∥∥ 1m
m∑i=1
φ(xi )−1n
n∑j=1
φ(yj)
∥∥∥∥∥∥2
H
When φ(x) = x , distinguish means. When φ(x) = [x x2],distinguish means and variances.There are kernels that can distinguish any two distributions
Reproducing Kernel Hilbert Spaces in Machine Learning
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
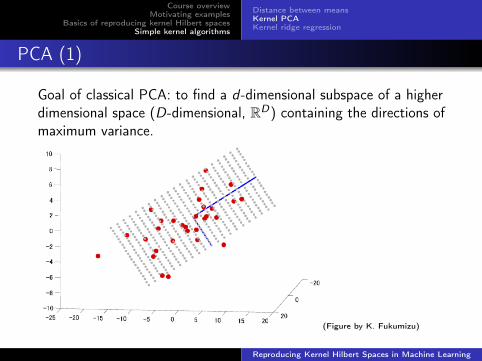
PCA (1)
Goal of classical PCA: to find a d-dimensional subspace of a higherdimensional space (D-dimensional, RD) containing the directions ofmaximum variance.
(Figure by K. Fukumizu)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Applicationof kPCA: image denoising
What is the purpose of kernel PCA?We consider the problem of denoising hand-written digits.We are given a noisy digit x∗.
Pdφ(x∗) = Pf1φ(x∗) + . . . + Pfdφ(x∗)
is the projection of φ(x∗) onto one of the first d eigenvectors{f`}d`=1 from kernel PCA (these are orthogonal).Define the nearest point y∗ ∈ X to this feature space projection as
y∗ = arg miny∈X‖φ(y)− Pdφ(x∗)‖2H .
In many cases,not possible to reduce the squared error to zero, as no single y∗
corresponds to exact solution.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Applicationof kPCA: image denoising
What is the purpose of kernel PCA?We consider the problem of denoising hand-written digits.We are given a noisy digit x∗.
Pdφ(x∗) = Pf1φ(x∗) + . . . + Pfdφ(x∗)
is the projection of φ(x∗) onto one of the first d eigenvectors{f`}d`=1 from kernel PCA (these are orthogonal).Define the nearest point y∗ ∈ X to this feature space projection as
y∗ = arg miny∈X‖φ(y)− Pdφ(x∗)‖2H .
In many cases,not possible to reduce the squared error to zero, as no single y∗
corresponds to exact solution.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Applicationof kPCA: image denoising
What is the purpose of kernel PCA?We consider the problem of denoising hand-written digits.We are given a noisy digit x∗.
Pdφ(x∗) = Pf1φ(x∗) + . . . + Pfdφ(x∗)
is the projection of φ(x∗) onto one of the first d eigenvectors{f`}d`=1 from kernel PCA (these are orthogonal).Define the nearest point y∗ ∈ X to this feature space projection as
y∗ = arg miny∈X‖φ(y)− Pdφ(x∗)‖2H .
In many cases,not possible to reduce the squared error to zero, as no single y∗
corresponds to exact solution.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Applicationof kPCA: image denoising
Projection onto PCA subspace for denoising. kPCA: data may notbe Gaussian distributed, but can lie in a submanifold in input space.
(Figure: K.Fukumizu)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
What is PCA? (reminder)
First principal component (max. variance)
u1 = arg max‖u‖≤1
1n
n∑i=1
u>
xi −1n
n∑j=1
xj
2
= arg max‖u‖≤1
u>Cu
where
C =1n
n∑i=1
xi −1n
n∑j=1
xj
xi −1n
n∑j=1
xj
> =1nXHX>,
X =[x1 . . . xn
], H = I − n−11n×n, 1n×n a matrix of ones.
Definition (Principal components)
The pairs (λi , ui ) are the eigensystem of nλiui = Cui .Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
PCA in feature space
Kernel version, first principal component:
f1 = arg max‖f ‖H≤1
1n
n∑i=1
⟨f , φ(xi )−1n
n∑j=1
φ(xj)
⟩H
2
= arg max‖f ‖H≤1
var(f ).
We can write
f =n∑
i=1
αi
φ(xi )−1n
n∑j=1
φ(xj)
=n∑
i=1
αi φ(xi ),
since any component orthogonal to the span ofφ(xi ) := φ(xi )− 1
n
∑ni=1 φ(xi ) vanishes.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
PCA in feature space
Kernel version, first principal component:
f1 = arg max‖f ‖H≤1
1n
n∑i=1
⟨f , φ(xi )−1n
n∑j=1
φ(xj)
⟩H
2
= arg max‖f ‖H≤1
var(f ).
We can write
f =n∑
i=1
αi
φ(xi )−1n
n∑j=1
φ(xj)
=n∑
i=1
αi φ(xi ),
since any component orthogonal to the span ofφ(xi ) := φ(xi )− 1
n
∑ni=1 φ(xi ) vanishes.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
How to solve kernel PCA
We can also define an infinite dimensional analog of the covariance:
C =1n
n∑i=1
φ(xi )−1n
n∑j=1
φ(xj)
⊗φ(xi )−
1n
n∑j=1
φ(xj)
,
=1n
n∑i=1
φ(xi )⊗ φ(xi )
where we use the definition
(a⊗ b)c := 〈b, c〉H a (3)
this is analogous to the case of finite dimensional vectors,(ab>)c = (b>c)a.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
How to solve kernel PCA (1)
Eigenfunctions of kernel covariance:
f`λ` = Cf`
=
(1n
n∑i=1
φ(xi )⊗ φ(xi )
)f`
=1n
n∑i=1
φ(xi )
⟨φ(xi ),
n∑j=1
α`j φ(xj)
⟩H
=1n
n∑i=1
φ(xi )
n∑j=1
α`j k(xi , xj)
k(xi , xj) is the (i , j)th entry of the matrix K := HKH (exercise!).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
How to solve kernel PCA (1)
Eigenfunctions of kernel covariance:
f`λ` = Cf`
=
(1n
n∑i=1
φ(xi )⊗ φ(xi )
)f`
=1n
n∑i=1
φ(xi )
⟨φ(xi ),
n∑j=1
α`j φ(xj)
⟩H
=1n
n∑i=1
φ(xi )
n∑j=1
α`j k(xi , xj)
k(xi , xj) is the (i , j)th entry of the matrix K := HKH (exercise!).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
How to solve kernel PCA (2)
We can now project both sides of
f`λ` = Cf`
onto all of the φ(xq):⟨φ(xq),LHS
⟩H
= λ`
⟨φ(xq), f`
⟩H
= λ`
n∑i=1
α`i k(xq, xi ) ∀q ∈ {1 . . . n}
⟨φ(xq),RHS
⟩H
=⟨φ(xq),Cf`
⟩H
=1n
n∑i=1
k(xq, xi )
n∑j=1
α`j k(xi , xj)
∀q ∈ {1 . . . n}
Writing this as a matrix equation,
nλ`Kα` = K 2α` nλ`α` = Kα`.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
How to solve kernel PCA (2)
We can now project both sides of
f`λ` = Cf`
onto all of the φ(xq):⟨φ(xq),LHS
⟩H
= λ`
⟨φ(xq), f`
⟩H
= λ`
n∑i=1
α`i k(xq, xi ) ∀q ∈ {1 . . . n}
⟨φ(xq),RHS
⟩H
=⟨φ(xq),Cf`
⟩H
=1n
n∑i=1
k(xq, xi )
n∑j=1
α`j k(xi , xj)
∀q ∈ {1 . . . n}
Writing this as a matrix equation,
nλ`Kα` = K 2α` nλ`α` = Kα`.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Eigenfunctions f have unit norm in feature space?
‖f ‖2H
=
⟨n∑
i=1
αi φ(xi ),n∑
i=1
αi φ(xi )
⟩H
=n∑
i=1
n∑j=1
αiαi
⟨φ(xi ), φ(xj)
⟩H
=n∑
i=1
n∑j=1
αiαi k(xi , xj)
= α>Kα = nλα>α = nλ‖α‖2.
Thus α← α/√nλ (assumed: original eigenvector solution has ‖α‖ = 1)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Projection onto kernel PC
How do you project a new point x∗ onto the principal component f ?Assuming ‖f ‖H = 1, the projection is
Pf φ(x∗) = 〈φ(x∗), f 〉H f
=n∑
i=1
αi
n∑j=1
αj
⟨φ(x∗), φ(xi )
⟩H
φ(xi )
=n∑
i=1
αi
n∑j=1
αj
(k(x∗, xj)−
1n
n∑`=1
k(x∗, x`)
) φ(xi ).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Kernel ridge regression
−0.5 0 0.5 1 1.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
−0.5 0 0.5 1 1.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
−0.5 0 0.5 1 1.5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
Very simple to implement, works well when no outliers.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression: case of RD
We are given n training points in RD :
X =[x1 . . . xn
]∈ RD×n y :=
[y1 . . . yn
]>Define some λ > 0. Our goal is:
a∗ = arg mina∈RD
(n∑
i=1
(yi − x>i a)2 + λ‖a‖2)
= arg mina∈RD
(∥∥∥y − X>a∥∥∥2 + λ‖a‖2
),
The second term λ‖a‖2 is chosen to avoid problems in highdimensional spaces (see below).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression: solution (1)
Expanding out the above term, we get∥∥∥y − X>a∥∥∥2 + λ‖a‖2 = y>y − 2y>Xa + a>XX>a + λa>a
= y>y − 2y>X>a + a>(XX> + λI
)a = (∗)
Define b =(XX> + λI
)1/2a
Square root defined since matrix positive definiteXX> may not be invertible eg when D > n, adding λI meanswe can write a =
(XX> + λI
)−1/2b).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression: solution (2)
Complete the square:
(∗) =y>y − 2y>X>(XX> + λI
)−1/2b + b>b
=y>y +
∥∥∥∥(XX> + λI)−1/2
Xy − b
∥∥∥∥2 − ∥∥∥∥y>X> (XX> + λI)−1/2∥∥∥∥2
This is minimized when
b∗ =(XX> + λI
)−1/2Xy or
a∗ =(XX> + λI
)−1Xy ,
which is the classic regularized least squares solution.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression solution as sum of training points (1)
We may rewrite this expression in a way that is moreinformative,a∗ =
∑ni=1 α
∗i xi .
The solution is a linear combination of training points xi .Proof: Assume D > n (in feature space case D can be very large oreven infinite).Perform an SVD on X , i.e.
X = USV>,
where
U =[u1 . . . uD
]S =
[S 00 0
]V =
[V 0
].
Here U is D × D and U>U = UU> = ID (subscript denotes unitmatrix size), S is D × D, where S has n non-zero entries, and V isn × D, where V>V = V V> = In.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression solution as sum of training points (1)
We may rewrite this expression in a way that is moreinformative,a∗ =
∑ni=1 α
∗i xi .
The solution is a linear combination of training points xi .Proof: Assume D > n (in feature space case D can be very large oreven infinite).Perform an SVD on X , i.e.
X = USV>,
where
U =[u1 . . . uD
]S =
[S 00 0
]V =
[V 0
].
Here U is D × D and U>U = UU> = ID (subscript denotes unitmatrix size), S is D × D, where S has n non-zero entries, and V isn × D, where V>V = V V> = In.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression solution as sum of training points (2)
Proof (continued):
a∗ =(XX> + λID
)−1Xy
=(US2U> + λID
)−1USV>y
= U(S2 + λID
)−1U>USV>y
= U(S2 + λID
)−1SV>y
= US(S2 + λID
)−1V>y
= USV>V︸ ︷︷ ︸(a)
(S2 + λID
)−1V>y
=(b)
X (X>X + λIn)−1y (4)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Ridge regression solution as sum of training points (3)
Proof (continued):(a): both S and V>V are non-zero in same sized top-left block,and V>V is In in that block.(b): since
V(S2 + λID
)−1V>
=[V 0
] [ (S2 + λIn)−1
0
0 (λID−n)−1
] [V>
0
]=V
(S2 + λIn
)−1V>
=(X>X + λIn
)−1.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Kernel ridge regression
Use features of φ(xi ) in the place of xi :
a∗ = arg mina∈H
(n∑
i=1
(yi − 〈a, φ(xi )〉H)2 + λ‖a‖2H
).
E.g. for finite dimensional feature spaces,
φp(x) =
xx2
...x`
φs(x) =
sin xcos xsin 2x
...cos `x
a is a vector of length ` giving weight to each of these features soas to find the mapping between x and y . Feature vectors can alsohave infinite length (more soon).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Kernel ridge regression: proof
Use previous proof!
X =[φ(x1) . . . φ(xn)
].
All of the steps that led us to a∗ = X (X>X + λIn)−1y follow.
XX> =n∑
i=1
φ(xi )⊗ φ(xi )
(using tensor notation from kernel PCA), and
(X>X )ij = 〈φ(xi ), φ(xj)〉H = k(xi , xj).
Making these replacements, we get
a∗ = X (K + λIn)−1y
=n∑
i=1
α∗i φ(xi ) α∗ = (K + λIn)−1y .
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Kernel ridge regression: easier proof
We begin knowing a is a linear combination of feature spacemappings of points (representer theorem: later in course)
a =n∑
i=1
αiφ(xi ).
Thenn∑
i=1
(yi − 〈a, φ(xi )〉H)2 + λ‖a‖2H = ‖y − Kα‖2 + λα>Kα
= y>y − 2y>Kα + α>(K 2 + λK
)α
Differentiating wrt α and setting this to zero, we get
α∗ = (K + λIn)−1y .
Recall: ∂α>Uα∂α = (U + U>)α, ∂v>α
∂α = ∂α>v∂α = v
Reproducing Kernel Hilbert Spaces in Machine Learning
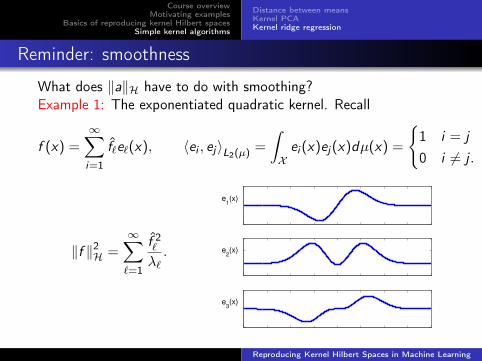
Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Reminder: smoothness
What does ‖a‖H have to do with smoothing?Example 1: The exponentiated quadratic kernel. Recall
f (x) =∞∑i=1
f`e`(x), 〈ei , ej〉L2(µ) =
∫Xei (x)ej(x)dµ(x) =
{1 i = j
0 i 6= j .
‖f ‖2H =∞∑`=1
f 2`λ`.
e1(x)
e2(x)
e3(x)
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Reminder: smoothness
What does ‖a‖H have to do with smoothing?Example 2: The Fourier series representation:
f (x) =∞∑
l=−∞fl exp(ılx),
and
〈f , g〉H =∞∑
l=−∞
fl gl
kl.
Thus,
‖f ‖2H = 〈f , f 〉H =∞∑
l=−∞
∣∣∣fl ∣∣∣2kl
.
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Parameter selection for KRR
Given the objective
a∗ = arg mina∈H
(n∑
i=1
(yi − 〈a, φ(xi )〉H)2 + λ‖a‖2H
).
How do we chooseThe regularization parameter λ?The kernel parameter: for exponentiated quadratic kernel, σ in
k(x , y) = exp(−‖x − y‖2
σ
).
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Choice of λ
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=0.1, σ=0.6
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Choice of λ
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=0.1, σ=0.6
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=10, σ=0.6
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
1.5
λ=1e−07, σ=0.6
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Choice of σ
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=0.1, σ=0.6
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Choice of σ
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=0.1, σ=0.6
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=0.1, σ=2
−0.5 0 0.5 1 1.5−1
−0.5
0
0.5
1
λ=0.1, σ=0.1
Reproducing Kernel Hilbert Spaces in Machine Learning

Course overviewMotivating examples
Basics of reproducing kernel Hilbert spacesSimple kernel algorithms
Distance between meansKernel PCAKernel ridge regression
Cross validation
Split n data into training set size ntr and test set sizente = n − ntr.Split training set into m equal chunks of size nval = ntr/m.Call these Xval,i ,Yval,i for i ∈ {1, . . . ,m}For each λ, σ pair
For each Xval,i ,Yval,i
Train ridge regression on remaining trainining set dataXtr \ Xval,i and Ytr \ Yval,i ,Evaluate its error on the validation data Xval,i ,Yval,i
Average the errors on the validation sets to get the averagevalidation error for λ, σ.
Choose λ∗, σ∗ with the lowest average validation errorMeasure the performance on the test set Xte,Yte.
Reproducing Kernel Hilbert Spaces in Machine Learning


















