
Reproducibility with the 99 cents Linked Data archive
44
Reproducibility with the 99 cents Linked Data archive Miel Vander Sande
-
Upload
miel-vander-sande -
Category
Technology
-
view
131 -
download
0
Transcript of Reproducibility with the 99 cents Linked Data archive

Reproducibility with the 99 cents Linked Data archiveMiel Vander Sande


Reproducibility.

Pragmatic archiving with HDT
Sustainable querying with Triple Pattern Fragments
Uniform access to history with Memento
Reproducibility with the 99 cents Linked Data archive
Time travelling through DBpedia
Reproducibility on the Web

Pragmatic archiving with HDT
Sustainable querying with Triple Pattern Fragments
Uniform access to history with Memento
Reproducibility with the 99 cents Linked Data archive
Time travelling through DBpedia
Reproducibility on the Web
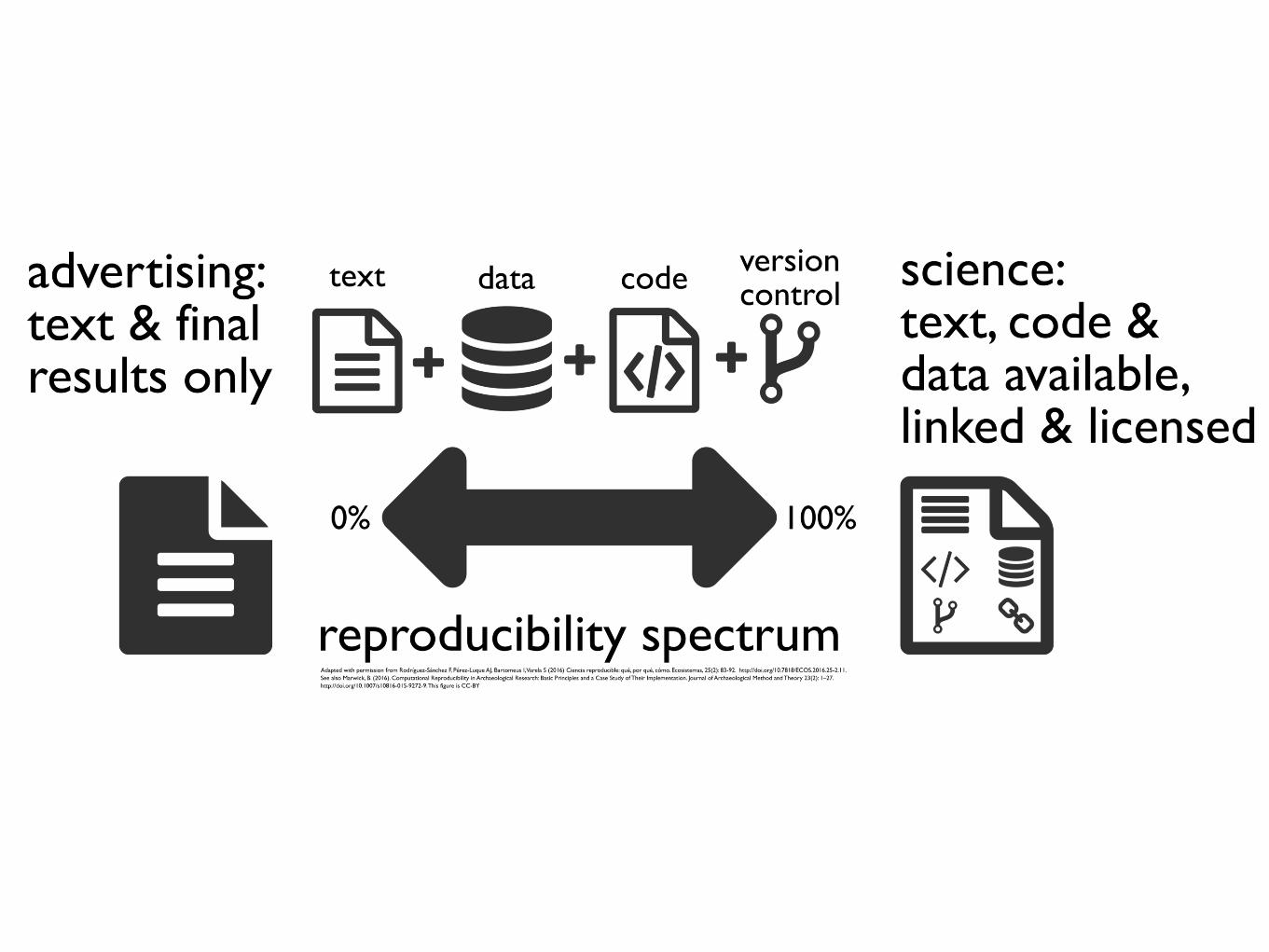

Reproducing experiments to sustain validity.

Reproducing experiments to sustain validity.

Backwards-compatible Linked Open Data applications.
1.0
2.0

Publishing Linked Data Archives has a sustainability problem.
Many data publishing institutions are under-resourced.
Many of them care about data history.
Looking for “good-enough” solutionsCommonly resort to data dumps
Not able to afford public SPARQL infrastructure

Publishing Linked Data Archives has a sustainability problem.
Many clients asking complex queries is very expensive for a server to scale.
Access to data history makes this problem harder.
Unavailable servers prevent applications to unlock potential.

Pragmatic archiving with HDT
Sustainable querying with Triple Pattern Fragments
Uniform access to history with Memento
Reproducibility with the 99 cents Linked Data archive
Time travelling through DBpedia
Reproducibility on the Web

Single archive file (*.hdt)
Header-Dictionary-Triples (HDT) is a compact binary RDF representation.
Header
Dictionary Triples
Created by Fernández, Javier et.al

Features of HDT are desirable properties for digital archives.
High volumes
Direct access
Discovery and exchange
Represent massive data sets as a single file
Rapid search for ?subject ?predicate ?object
Included header with dataset metadata

HDT At0
HDT Bt0
HDT Ct0
HDT Zt0
HDT At-1
HDT Bt-1
HDT Ct-1
HDT Zt-x
HDT Zt-x
HDT Zt-x
HDT Zt-x
…
t0
Dataset B
Dataset Z
t-1 t-x
A matrix of HDT files can serve as pragmatic RDF archive.
Time-based index
…
Dataset A
Dataset C
…

14 DBpedia versions take 12.75% of the original N-triples size.
0
40
80
120
160
2.0
3.0
3.1
3.2
3.3
3.4
3.5
3.6
3.7
3.8
3.9
2014
2015
-04
2015
-10
Original size in NT (GB) HDT size (GB)

Space and time-to-publish significantly decreased for DBpedia.
Original HDT -based
Indexing Custom HDT-CPP
Indexing time ~ 24 hours per version ~ 4 hours per version
Storage MongoDB HDT binary files
Space 383 Gb 178 Gb
# Versions 10 versions: 2.0 through 3.9
14 versions: 2.0 through 2015-10
# Triples ~ 3 billion ~ 6 billion

Pragmatic archiving with HDT
Sustainable querying with Triple Pattern FragmentsUniform access to history with Memento
Reproducibility with the 99 cents Linked Data archive
Time travelling through DBpedia
Reproducibility on the Web

Linked Data Fragments: hunting trade-offs between client & server.
high server costlow server cost
datadump
SPARQLendpoint
interface offered by the server
high availability low availabilityhigh bandwidth low bandwidthout-of-date data live data
low client costhigh client cost
Linked Datapages

low server cost
datadump
SPARQLquery results
high availabilitylive data
Linked Datapages
triple patternfragments
A triple pattern fragments interfaceis low-cost and enables clients to query.

Expect less from Servers, so you can publish more.

A Triple Pattern Fragments interfaceacts as a gateway to an RDF source.
Client can only ask ?s ?p ?o patterns.
Decompose complex SPARQL querieson the client-side.
Low server cost, highly cacheable, but higher bandwidth and query time.



Usage of fragments.dbpedia.org is steadily increasing.
# Re
ques
ts
February 2015 September 2016
19.239.907
4.500.000

And still the API has 99.99% availability up to today.

Pragmatic archiving with HDT
Sustainable querying with Triple Pattern Fragments
Uniform access to history with Memento
Reproducibility with the 99 cents Linked Data archive
Time travelling through DBpedia
Reproducibility on the Web
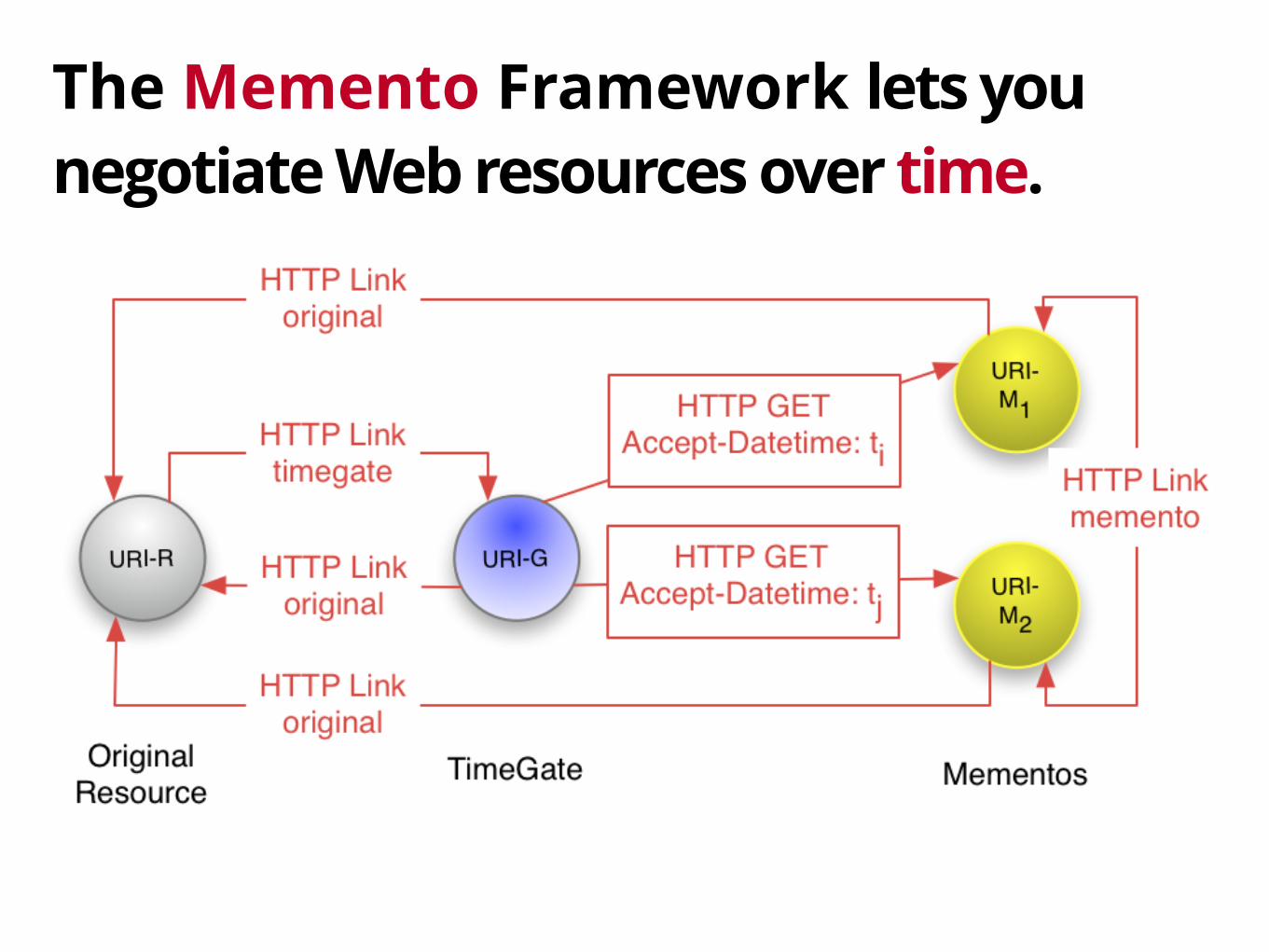
The Memento Framework lets you negotiate Web resources over time.

Any client can transparently navigate to a prior version.

Any client can transparently navigate to a prior version.
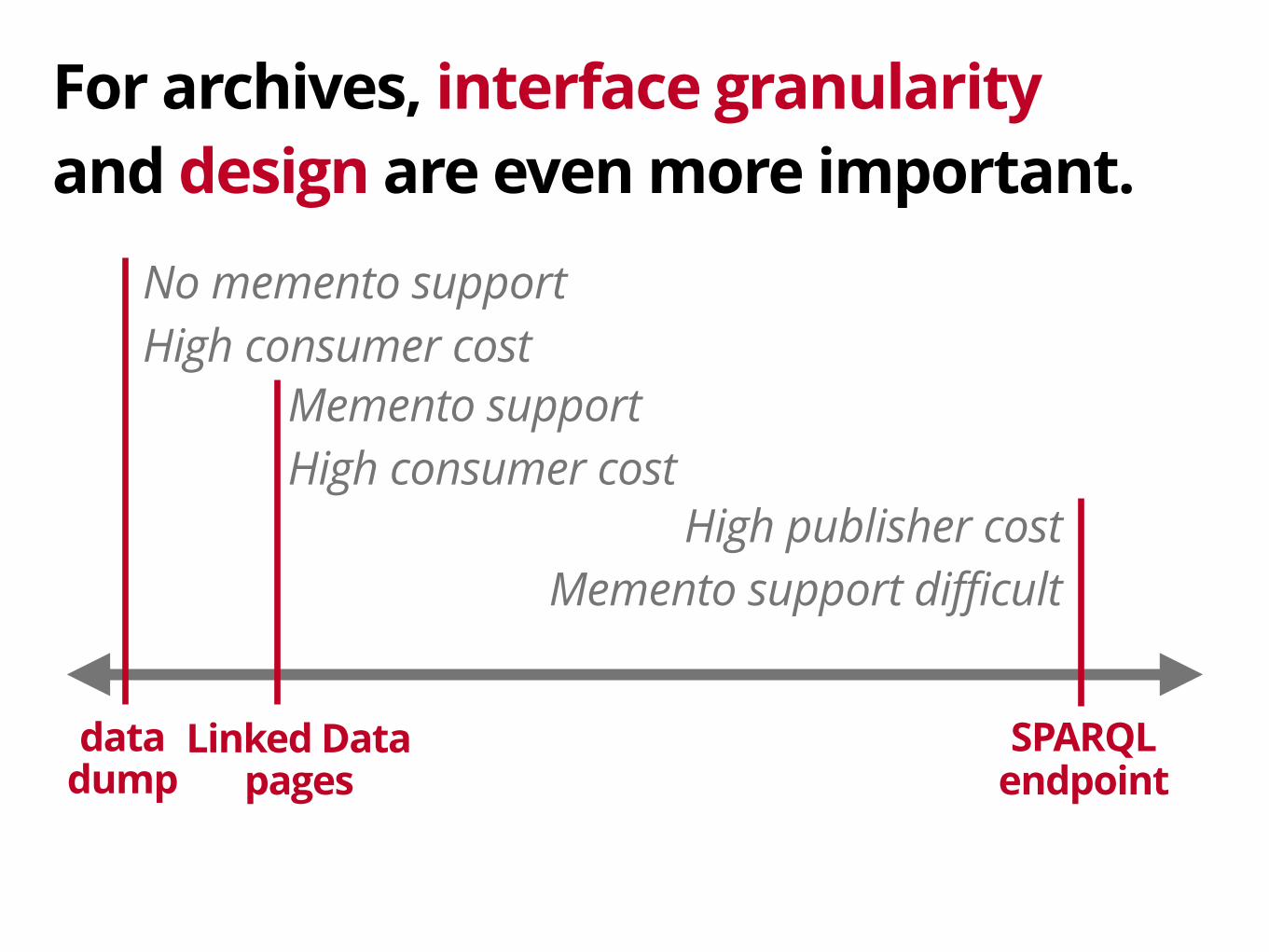
datadump
SPARQLendpoint
Linked Datapages
No memento supportHigh consumer cost
Memento supportHigh consumer cost
High publisher costMemento support difficult
For archives, interface granularity and design are even more important.

Directly compatible with Memento
datadump
SPARQLquery results
Useful for the consumer (queryable)Sustainable for publisher
Linked Datapages
triple patternfragments
The Triple Pattern Fragments trade-offalso pays off for archives.

Different HDT snapshots are exposed through an LDF server with Memento
http://fragments.dbpedia.org

DBpedia pages can be made available through a proxy.
http://dbpedia.org/resource/…

Preparing the TPF client is simply adding an HTTP header.
Query EngineSPARQL Processing
Hypermedia Layer Fragments interaction
HTTP Layer Resource access
Dataset B Dataset A
303 Location 200 Content-Location (CORS)
ClientServer
GET Accept-Datetime

A self-descriptive interface results in a single datetime negotiation.
Query EngineSPARQL Processing
Hypermedia Layer Fragments interaction
HTTP Layer Resource access
Dataset B Dataset A
ClientServer
GET 200

Pragmatic archiving with HDT
Sustainable querying with Triple Pattern Fragments
Uniform access to history with Memento
Reproducibility with the 99 cents Linked Data archive
Time travelling through DBpedia
Reproducibility on the Web

There is interesting information in the history of
Linked Data / DBpedia.
What could we learn if we could easily query it?

Querying history and the evolution of facts.
When did a researcher with name Frederik H. Kreuger and born in Amsterdam die?
Try it yourself: bit.ly/frederikkreuger
bit.ly/frederikkreuger-2013

What predicates were added in DBpedia between 2009 and 2014 to describe a person?
Analyze and profile changes in a data.
Try it yourself: bit.ly/personpredicates-2009 bit.ly/personpredicates-2014

What works by cubists were known by DBpedia and VIAF in 2009?
Resolve out-of-sync issues between federated sources.
Try it yourself: bit.ly/workscubists-2009
bit.ly/workscubists

Start hosting your own Linked Data archive (or play with the DBpedia one)!
github.com/LinkedDataFragmentsbit.ly/configuring-memento www.rdfhdt.org
linkeddatafragments.org mementoweb.org
Software
Documentation and specification
fragments.mementodepot.orgQuery the DBpedia archive on

Reproducibility with the 99 cents Linked Data archive@Miel_vdsHerbert Van de SompelHarihar Shankar Lyudmila BalakirevaRuben Verborgh


















