
Representative basedclustering
17
Representative Based Clustering Algorithm: Part 1, K-Means Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected]. December 18, 2016 Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected]. Representative Based Clustering Algorithm: Part 1, K-Means December 18, 2016 1 / 15
-
Upload
ananda-swarup -
Category
Education
-
view
69 -
download
0
Transcript of Representative basedclustering

Representative Based Clustering Algorithm: Part 1,K-Means
Ananda Swarup Das, Technical Staff Member,IBM India Research Labs, New Delhi, [email protected].
December 18, 2016
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 1 / 15

Standing on the Shoulders of the Giants.
Please note that, I use the excellent book titled ”Python MachineLearning” [3] for most of the programming examples in thispresentation.
The Theoretical text is covered from multiple sources like [1], [2] and[4].
Thanks to all the authors for such great books.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 2 / 15

Definition of Clustering
A Formal Definition: Clustering can be defined as partitioning agiven data set D = {xi}ni=1 where each xi ∈ Rd into k sub-partitionsdenoted by C = {C1, . . . ,Ck} such that that D ∩Cj 6= ∅ , for 1 ≤ j ≤ kand ∪nj=1Cj = D. The k is an user-defined/chosen parameter.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 3 / 15

Is the definition okay ?
The definition is incomplete in the sense that it misses the definitionof quality of each sub-partition.
Going simply by the previous definition, the points can be groupedarbitrarily into k sub-groups. (Will that help ?)
Did we miss something ? (Well, Yes,. . ., We did not speak about howwe represent each cluster . . .)
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 4 / 15

The Representative Based Clustering
For each cluster, we try to find a representative point thatsummarizes the cluster.
Ideally, it is the mean of the cluster.
K-Means algorithm is an example of the representative basedclustering.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 5 / 15

K Means Clustering: Definition and the Objective Function
Given the task of clustering, the first important factor is to find anappropriate scoring function to ensure the quality of the clustering.
The K-means clustering greedily finds the k-number of meansµ1 . . . µk for the clusters c1, . . . , ck .
The sum of squared error for each cluster Ci is given asSSE (ci ) =
∑xj∈ci ||xj − µi ||
2.
The sum of squared error for the clustering scheme C is define asSSE (C ) =
∑ki=1
∑xj∈ci ||xj − µi ||
2.
The objective is therefore to find the clustering scheme C ′ such thatC ′ = arg min C{SSE (C )} .
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 6 / 15

K Means Clustering: Algorithmic Steps and HardAssignment
As stated in [4],
1 At the first step t = 0, randomly initialize k centroids denoted byµt1 . . . µ
tk .
2 repeat
Increment the iteration index t by 1.Let Cj = ∅ for all j = 1 . . . k .for each xj in the data set D, do,
Find j? = arg mini{||xj − µt−1i ||2}
Cj? = Cj? ∪ {xj}.3 Update Centroids for each cluster as µti = 1
|Ci |∑
xj∈Cixj .
4 Stop if∑k
i=1 ||µti − µt−1i ||2 ≤ ε where ε is a user-defined parameter.
Notice that in each iteration of k means, a point in D is greedily assignedto at most one cluster. This is called hard assignment.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 7 / 15

K Means Clustering: Algorithmic Steps and HardAssignment
As stated in [4],
1 At the first step t = 0, randomly initialize k centroids denoted byµt1 . . . µ
tk .
2 repeat
Increment the iteration index t by 1.Let Cj = ∅ for all j = 1 . . . k .for each xj in the data set D, do,
Find j? = arg mini{||xj − µt−1i ||2}
Cj? = Cj? ∪ {xj}.3 Update Centroids for each cluster as µti = 1
|Ci |∑
xj∈Cixj .
4 Stop if∑k
i=1 ||µti − µt−1i ||2 ≤ ε where ε is a user-defined parameter.
Notice that in each iteration of k means, a point in D is greedily assignedto at most one cluster. This is called hard assignment.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 7 / 15

A Question to Ponder
Can we do something so that instead of greedily assigning a point to onecluster at most, we assign the point to multiple clusters ?
Yes, we can, but we will defer the answer to that for sometime as we havesome maths to brush up. Part 2 series of this slide will answer the question.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 8 / 15

A Question to Ponder
Can we do something so that instead of greedily assigning a point to onecluster at most, we assign the point to multiple clusters ?
Yes, we can, but we will defer the answer to that for sometime as we havesome maths to brush up. Part 2 series of this slide will answer the question.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 8 / 15

Few Things to Learn
1 Clustering is an unsupervised technique.
You are not provided with any training data of any labeled data totrain a system.You are trying to find some group/pattern in the data.
2 How to decide an ideal value for the parameter k .
Use Elbow-MethodIf the dimension is not too high, one can also use Bayesian InformationCriterion (bic)
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 9 / 15

Visualizations
I am using make−blobs from sklearn-datasets following examples from [3] togenerate the 2-d sample data set with four centers. It is a synthetic data (fordemo purpose) and in practice, one will rarely get such well clustered data.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 10 / 15

Introducing k-Means from sklearn-cluster
This is as simple as follows:
1 from sklearn.cluster import KMeans
2 km = KMeans(n−clusters = 4, init=’random’, n−init = 10,max−iter = 800, tol = 1e − 04, random−state = 0)
The important terms:
n−cluster , denotes the number of clusters you want. This is actually yourvalue of k .
init=’random’ means k random points will be initially selected as thecentroid/means.
n−init denote the number of times the k-means algorithm will be run withdifferent centroid seeds.
max−iter = 800 denotes the maximum number of iterations the KMeansalgorithm will run. Default is 800.
tol = 1e − 04 Minimum tolerance to declare convergence. Remember,∑ki=1 ||µt
i − µt−1i ||2 ≤ ε. ε is the tol .
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 11 / 15

Deciding the Cluster Number of k
1 Remember the sum of squared error for the clustering scheme C isdefine as SSE (C ) =
∑ki=1
∑xj∈ci ||xj − µi ||
2. This parameter is alsoknown as cluster distortion or cluster inertia.
2 The Kmeans module of skelarn.cluster will give you that value askm.inertia−.
3 Run your Kmeans algorithm in a loop where at each iteration, youchoose a different value of k . Collect the cluster inertia for that valueof k .
4 Make a plot and find the elbow.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 12 / 15
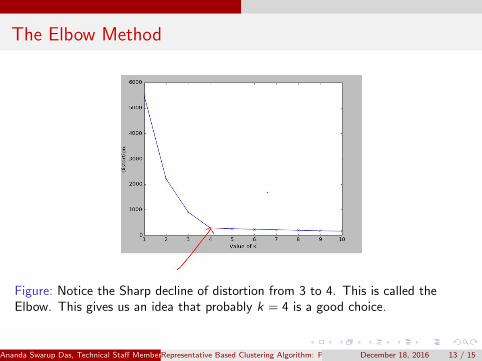
The Elbow Method
Figure: Notice the Sharp decline of distortion from 3 to 4. This is called theElbow. This gives us an idea that probably k = 4 is a good choice.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 13 / 15

In the Next Series
In the next part of this series (probably in a time of week), we willintroduce the Expectation Maximization Algorithm with elaboratedetails and explanations.
Till then Happy Data Science with Python.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 14 / 15

Citations
G. James, D. Witten, T. Hastie, and R. Tibshirani.
An Introduction to Statistical Learning: with Applications in R.
Springer Texts in Statistics. Springer New York, 2014.
C. D. Manning, P. Raghavan, and H. Schutze.
Introduction to information retrieval.
Cambridge University Press, 2008.
S. Raschka.
Python Machine Learning.
Packt Publishing, 2015.
M. J. Zaki and W. Meira.
Data Mining and Analysis: Fundamental Concepts and Algorithms.
Cambridge University Press, 2014.
Ananda Swarup Das, Technical Staff Member, IBM India Research Labs, New Delhi, [email protected] Based Clustering Algorithm: Part 1, K-MeansDecember 18, 2016 15 / 15


















