
Recoomendation systems Intro
63
Recommendation Systems From scratch to a working spark implementation
-
Upload
oren-razon -
Category
Data & Analytics
-
view
401 -
download
0
Transcript of Recoomendation systems Intro

Recommendation SystemsFrom scratch to a working spark
implementation

Recommendation SystemDictionary definition
Set of tools which help in finding products, information, or services in a specific domain when the user has not enough knowledge or
when there are just too many items
It’s a subclass of Information Retrieval that differ in the fact that it’s active and personal
It’s not the technique, it’s an application.It’s the WHAT not the HOW

Few ExamplesIt’s not only Amazon! It’s everywhere!

Take a few seconds to spot all the recommendations in the coming screen



The RecipeNo one solution to fit them all

Problem DefinitionThe basic elements
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4

Problem DefinitionThe basic elements
MetadataMight be given, or inferred
(images, text, statistics)
ProportionsItem set is usually much
smaller than User set
IncomingNew users & items
appear on a certain rate
LifetimeItems might have a
lifetime
HierarchyUsers and\or Items could be
aggregated together

Problem DefinitionThe recommendation question
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4
Given User u in a given Context c, and given an existing action history,what Item set out of all Items should be suggested to the user?
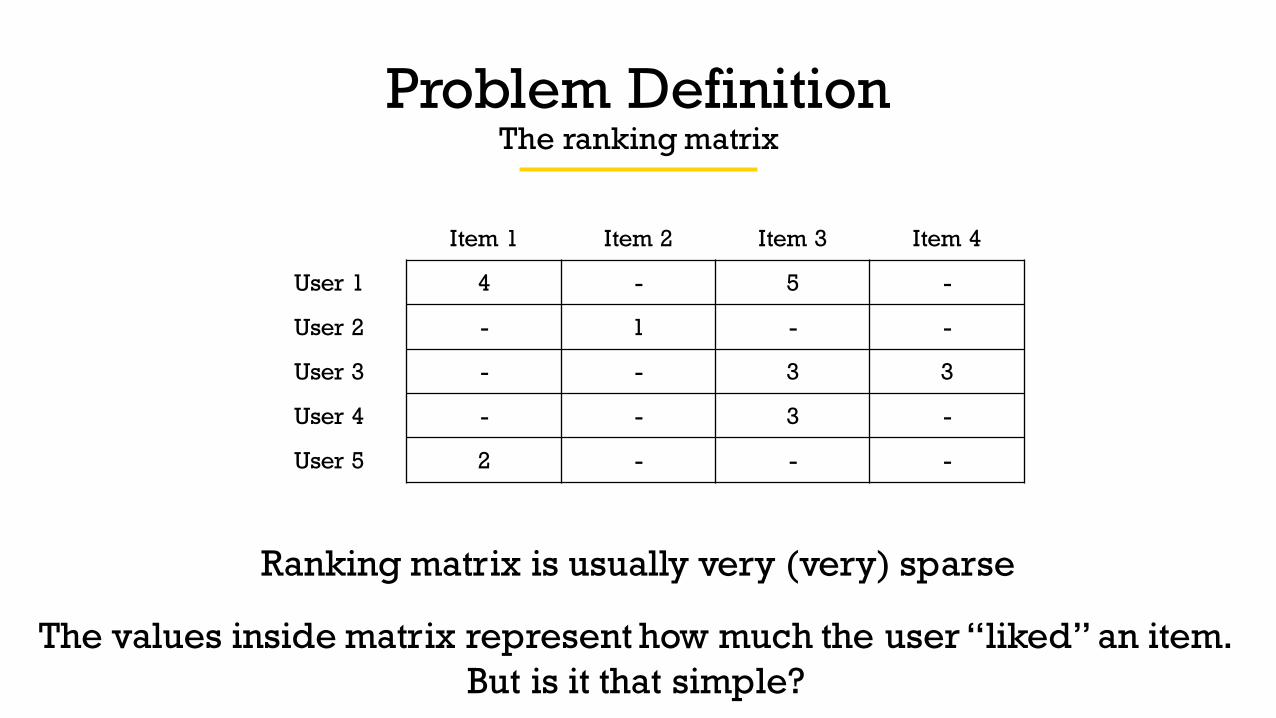
Problem DefinitionThe ranking matrix
Item 1 Item 2 Item 3 Item 4
User 1 4 - 5 -
User 2 - 1 - -
User 3 - - 3 3
User 4 - - 3 -
User 5 2 - - -
Ranking matrix is usually very (very) sparse
The values inside matrix represent how much the user “liked” an item.But is it that simple?

Problem DefinitionHow to describe the preference value?
Explicit vs. Implicit- Explicit is not always possible, when do, users are lazy - Explicit might be misleading

Problem DefinitionHow to describe the preference value?
Explicit vs. Implicit- Explicit is not always possible, when do, users are lazy - Explicit might be misleading

Problem DefinitionHow to describe the preference value?
Explicit vs. Implicit- Explicit is not always possible, when do, users are lazy - Explicit might be misleading
Item 1 Item 2 Item 3 Item 4
User 1 5 4 5 -
User 2 - 1 - -
User 3 3 - 3 3
User 4 - - 3 -
User 5 2 - - -
Item 1 Item 2 Item 3 Item 4
User 1 1 0 1 0
User 2 0 1 0 0
User 3 0 0 1 1
User 4 0 0 1 0
User 5 1 0 0 0
Binary vs. Scale- Non-binary contain more information- More information could be misleading- Non-binary scale is hard to define and usually biased by the user

Problem DefinitionHow to describe the preference value?
Explicit vs. Implicit- Explicit is not always possible, when do, users are lazy - Explicit might be misleading
Binary vs. Scale- Non-binary contain more information- More information could be misleading- Non-binary scale is hard to define and usually biased by the user

Problem DefinitionHow to describe the preference value?
Explicit vs. Implicit- Explicit is not always possible, when do, users are lazy - Explicit might be misleading
Binary vs. Scale- Non-binary contain more information- Non-binary scale is hard to define and usually biased by the user- More information could be misleading
Missing values- Usually a missing value is indication that the user is not familiar with the item- But it could be a negative indication- Not all suggestion were born equal

How to MeasureTell me where you want to go and I will tell you how
Define success measure in a way that is significant to you
And then
Aim to it

How to MeasureHow to describe the preference value
Item 1 Item 2 Item 3 Item 4
User 1 4 - 5 -
User 2 - 1 - -
User 3 - - 3 3
User 4 - - 3 -
User 5 2 - - -
Given a recommendation to user 3. How will we judge it?
PredictionHowaccuratecanitestimateUser3
preferencetoItem1&2?
RankingHowaccuratecanitestimateifItem1is
“better”thanItem2forUser3

How to MeasurePrediction vs. Ranking
Item # Actual System A System B
1 9 8.4 10
2 8.8 8.9 7.4
3 8.5 8.5 7.5
4 8 7 6
5 6.5 7.1 5
Which recommender system is better?

How to MeasurePrediction vs. Ranking
Item # Actual System A System B
1 9 8.4 10
2 8.8 8.9 7.4
3 8.5 8.5 7.5
4 8 7 6
5 6.5 7.1 5
Which recommender system is better?
RMSESystem A = 0.588System B = 1.430
nDCGSystem A = 0.990 System B = 0.996
How to MeasureNow let’s go to the soft side
10% Coffee & PastryArcaffe
10% Coffee & PastryAroma
10% Coffee & PastryIlan’s

How to MeasureGive me something different
10% Coffee & PastryArcaffe
10% Coffee & PastryAroma
10% Coffee & PastryIlan’s
Diversity

How to MeasureNow let’s go to the soft side
Diversity

How to MeasureNow let’s go to the soft side
Diversity Novelty

How to MeasureNow let’s go to the soft side
You must join the “See it to believe!” meetup group
Diversity Novelty

How to MeasureNow let’s go to the soft side
You must join the “See it to believe!” meetup group
Diversity Novelty

How to MeasureNow let’s go to the soft side
You should join the “See it to believe!” meetup group
Diversity TrustNovelty

How to MeasureNow let’s go to the soft side
Diversity TrustNovelty

How to MeasureNow let’s go to the soft side
Diversity TrustNovelty Utility

How to MeasureNow let’s go to the soft side
System A System BVs.
0123456789
Accuracy
Diversity
TrustNovelty
Utility
0123456789
Accuracy
Diversity
TrustNovelty
Utility

How to MeasureHow to conduct an experiment
The common offline Train\Test method
Item 1 Item 2 Item 3 Item 4
User 1 4 - 5 -
User 2 - 1 - -
User 3 - - 3 3
User 4 - - 3 -
User 5 2 - - -
User Item Preference
1 1 4
1 3 5
2 2 1
3 3 3
3 4 3
4 3 3
5 1 2
Train
Test
Item 1 Item 2 Item 3 Item 4
User 1 4 - 5 -
User 2 - 1 - -
User 3 - - 3 3

The “Magic”Different modeling approaches
Collaborative-Filtering Content-Based Knowledge-Based
Uses only history preferences to imply
on unknown preferences
Try to find patterns between preferences
and different properties
Ingestion of domain specific knowledge

The “Magic”Collaborative Filtering “similarity” methods
Find similar entities using their previous preferences
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4
User based Item based

The “Magic”Collaborative Filtering matrix factorization methods
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4
Concept 1 Concept 2

The “Magic”Collaborative Filtering matrix factorization methods
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4
Concept 1 Concept 2
U*K

The “Magic”Collaborative Filtering matrix factorization methods
Item 1 Item 2 Item 3
User 1 User 2 User 3 User 4
Concept 1 Concept 2
K*I

The “Magic”Collaborative Filtering matrix factorization methods

The “Magic”Collaborative Filtering matrix factorization methods
2 3
1 4
2 2
2 5
3 4
2 5 1
2 4 2
U*K K*I U*I
2 - -
- 4 -
2 - 5
- 5 -
3 - 1

The “Magic”Collaborative Filtering matrix factorization methods
2 3
1 4
2 2
2 5
3 4
2 5 1
2 4 2
U*K K*I U*I
2 - -
10 4 -
2 - 7
- 5 -
3 - 1
Prediction of User 2 preference for Item 1

The “Magic”Collaborative Filtering matrix factorization methods

UserId Feature 1 Feature 2 Feature 3
…
…
ItemId Feature 1 Feature 2 Feature 3 Context 1 Context 2 Context 3 Preference
The “Magic”Content based methods
Similar to any standard supervised learning process

The “Magic”Methods comparison
Simplicity Novelty Cold start
Accuracy Grey sheep

The “Magic”Hybrid is usually the best

The “Magic”Hybrid is usually the best
Mix Average
Flow Rules

Architecture Considerations
Real time
Heavy lifting
Adaptivity
Collect context
Running ML processes
Respond to the user
Adapting to real time behavior
Collect additional sources and maintain user integrity

Serving layer
Architecture considerationsLambda architecture
New data
Batch layer
Speed layer
Analytical storage
Operative storage
QueueStream
processing
Stream processing
App

Architecture considerationsMicro-service architecture

2 - -
- 4 -
2 - 5
- 5 -
3 - 1
Relevant TechnologiesGraph databases vs. General purpose

SparkIntro
Originally developed in
2009 at UC Berkley AMP
Lab
Open sourced in 2010
As of 2014, Spark is a top-level
Apache project
Top open-source community in
2015

SparkIntro

SparkIntro

SparkMLlib

SparkALS in MLlib vs.Mahout

MLlib ALSAlternating-Least-Squares
- -
- -
- -
- -
- -
- - -
- - -
U*K K*I U*I
2 - -
10 4 -
2 - 7
- 5 -
3 - 1

MLlib ALSAlternating-Least-Squares
- -
- -
- -
- -
- -
- - -
- - -
U*K K*I U*I
2 - -
10 4 -
2 - 7
- 5 -
3 - 1
Fix one matrix solve the second

MLlib ALSAlternating-Least-Squares
5 1
2 3
2 4
2 1
3 4
- - -
- - -
U*K K*I U*I
2 - -
10 4 -
2 - 7
- 5 -
3 - 1
Fix one matrix solve the second

MLlib ALSAlternating-Least-Squares
5 1
2 3
2 4
2 1
3 4
- - -
- - -
U*K K*I U*I
2 - -
10 4 -
2 - 7
- 5 -
3 - 1
Fix one matrix solve the second

MLlib ALSAlternating-Least-Squares
5 1
2 3
2 4
2 1
3 4
2 3 1
1 1 2
U*K K*I U*I
2 - -
10 4 -
2 - 7
- 5 -
3 - 1
Fix one matrix solve the second

Demo

TakeawayNo one solution to fit them all

Additional MaterialsYour starting point

www.myyellowroad.com
Advanced Analytics
Big Data Architecture
Turnkey Analytics Projects
Big Data Analytics Methodology
From Business Need, With Big Data Analytics, To Business Success

Problem definition
Data modeling
How to measure
The “magic”Tech challenges
Architecture considerations
Relevant technologies Implementation Evaluation


















