
Procesadores Digitales de Señal...
17
Arquitecturas GPU v. 2015 http://en.wikipedia.org/wiki/Graphics_processing_unit http://en.wikipedia.org/wiki/Stream_processing http://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html https://www.khronos.org/opencl/ http://www.altera.com/literature/wp/wp-01173-opencl.pdf
Transcript of Procesadores Digitales de Señal...

Arquitecturas GPUv. 2015
http://en.wikipedia.org/wiki/Graphics_processing_unithttp://en.wikipedia.org/wiki/Stream_processing
http://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units
http://www.nvidia.com/object/what-is-gpu-computing.htmlhttps://www.khronos.org/opencl/
http://www.altera.com/literature/wp/wp-01173-opencl.pdf

Arquitecturas GPUGPU (Unidad de procesamiento gráfico)
Retorno al concepto de COPROCESADOR: * Uno o varios procesadores con su propio repertorio de instrucciones (o el mismo) y memoria propia (aunque no siempre) conectado como un dispositivo de hardware adicionales en el sistema.* Se accede como cualquier otro dispositivo de I/O (comandos o DMA) a través de los buses del sistema. Ej. PCI-Express, AGP.* Para el software es otro núcleo al cual se le envían datos y rutinas para procesar.
Marcas clásicas, en dispositivos independientes:- NVIDIA GeForce (juegos), Quadro (profesionales)- AMD ATI.
Ahora vienen incoporados en la CPU: APU- AMD Phenom-II y Fusion- Intel Ivy-bridge
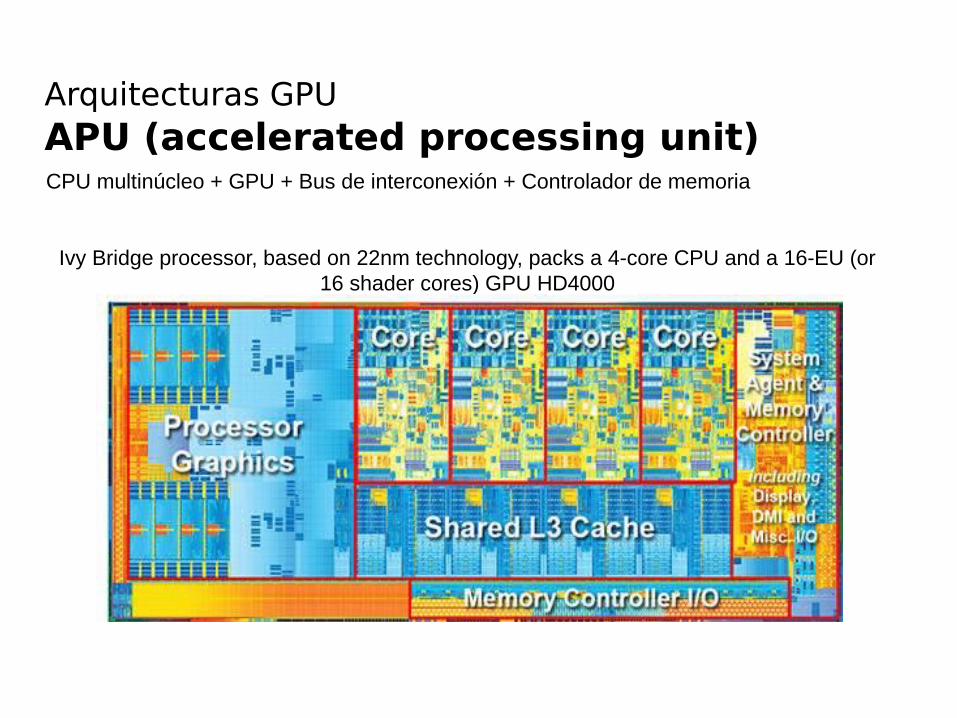
Arquitecturas GPUAPU (accelerated processing unit)CPU multinúcleo + GPU + Bus de interconexión + Controlador de memoria
Ivy Bridge processor, based on 22nm technology, packs a 4-core CPU and a 16-EU (or 16 shader cores) GPU HD4000

Arquitecturas GPUOrganización sistema con GPU
http://www.pgroup.com/lit/articles/insider/v1n1a1.htm

Arquitecturas GPUGP-GPU* Entre los años 1999 y 2000, investigadores del sector informático y de otras disciplinas empezaron a utilizar las GPU para acelerar diversas aplicaciones de cálculo.
* Este tipo de aplicación recibe el nombre de “General Purpose GPU” (GP-GPU) o GPU de propósito general.
Sin embargo inicialmente no existían interfaces de programación especialmente dedicadas a este tipo de aplicación, dificultando el desarrollo
* 2007 CUDA (Compute Unified Device Architecture) SDK, incluye un compilador con extensiones para C. Aún implica reescritura y reestructuración del programa y el código no es ejecutable en x86.* 2009 OpenCL (Open Computing Language) Plataforma un poco más genérica que CUDA. Para programa algoritmos paralelos en CPU, GPU, DSP, FPGA. Impulsado por Apple, Intel, Qualcomm, AMD, Nvidia, Altera, Samsung, Vivante, Imagination Technologies and ARM.* 2013 OpenACC (Open ACCelerators) Extensiones para código C, C++ y Fortran que permiten al programador especificarle al compilador como ejecutar el programa en paralelo. Cray, CAPS, Nvidia, PGI.

Arquitecturas GPUGP-GPU
* 2010 Primeras GPU exclusivamente para cálculo: NVIDIA Tesla (¿es GPU?)
* 2012 Intel sale a competir en el mercado del cómputo científico. Xeon Phi (¿es GPU?)

Arquitecturas GPUGP-GPU

Arquitecturas GPU
NVIDIA CUDA
* La resolución del problema se realiza mediante threads paralelos diminutos expresados en un kernel.
* El programador agrupa los threads en bloques y los encola para para su ejecución en la GPU.
* Ya en la GPU, el thread scheduler envía los bloques a los Streaming Multiprocessors que estén disponibles.
* Cada SM ejecuta simultáneamente múltiples bloques haciendo temporal multithreading.

Arquitecturas GPU
NVIDIA CUDA - SIMT * El hardware subdivide los bloques en grupos de 32 threads, llamados warps.
* Todos los threads de un mismo warp se ejecutan en lock-step: todos los que están activos simultáneamente realizan la misma instrucción.
* La metodología es similar a SIMD, ya que existe un único decodificador de instrucción para los 32 threads del warp, pero NO ES SIMD...
* Cada miembro del thread tiene su propio contador de programa. En las bifurcaciones, los miembros del warp pueden diverger. La característica vectorial es invisible al programador, que puede no tenerla en cuenta, el hardware se encarga de ocultarla.
* Pero si no la tiene en cuenta SE PAGA FUERTEMENTE EN PERFORMANCE.
* NVIDIA llama a esto SIMT (Single Instruction Multiple Thread).

Arquitecturas GPUNVIDIA CUDA – Temporal Multithreading
* Cada unidad de cálculo ejecuta las instrucciones en orden y sin predicción de saltos.
* Las latencias de las instrucciones pueden ser de decenas de ciclos de reloj, incluso centenas si hay accessos a memoria global.
* Para ocultar la latencia cada SM intercala la ejecución de diferentes warps en las unidades de procesamiento, siempre buscando warps cuyas dependencias estén satisfechas.
* Es responsabilidad del usuario que en todo momento hayan suficientes warps listos para ser ejecutados, o de lo contrario el SM tendrá que esperar y se pierde throughput.

Arquitecturas GPUNVIDIA CUDA - Performance
* Generar suficiente trabajo para esconder la latencia de las instrucciones.
* Evitar las bifurcaciones dentro de los warps.
* Limitar el uso de variables DOUBLE a donde sea estrictamente necesario.
* Respetar las limitaciones de la jerarquía de memoria: accesos alineados a memoria global, evitar las colisiones en memoria compartida, minimizar la cantidad de registros utilizados para no necesitar memoria local.
* ¡¡¡Dimensionar adecuadamente las unidades de trabajo!!! 440 puede parecer un número como cualquier otro para la cantidad de threads por bloque, pero ni es múltiplo de la cantidad de threads por warp (32), ni divide la cantidad de threads que aceptan típicamente las SM (256, 512, 768, etc.) por lo que las subutilizará.
* Tener en cuenta las características de la GPU que se utilizará: lo óptimo en una GeForce puede ser nefasto en una Tesla (diferentes capacidades de SMs, arquitecturas de memoria diferentes, diferentes cantidades de unidades de procesamiento).

Arquitecturas GPUNVIDIA CUDA – Ejemplo de kernel
Ejemplo de kernel CUDA. El siguiente kernel realiza todo el trabajo en GPU necesario para hacer la operación
A = α * X * XT + ADonde α es un escalar, X es un vector de largo n, y A es una matriz triangular superior de n2
elementos. En este programa n2 threads ejecutan sendas copias del código del kernel para realizar la operación matricial completa.

Arquitecturas GPU
AMD ATISimilares en su organización interna a NVIDIA
Se programan en OpenCL.

Arquitecturas GPU
Xeon PhiNo arrastran la herencia de GPU. En su lugar arrastran la herencia x86. Diseñados para cálculo científico.
* 60 cores “simples” basados en P5 (Pentium!).* Cada core es superescalar, con Hyper-Threading de cuatro vías. * Set de instrucciones x86, con extensiones x64 y SIMD de 512 bits de ancho.* Caches coherentes de todos los cores. * OpenMP, OpenCL. Más cercano a la programación de multicores que a la de GPUs.

Intel Xeon Phi Knight's Landing Processor (72 cores) Die Map

Arquitecturas GPU
GP-GPU - Prestaciones

- fin -


















