Procesadores Digitales de Señal (DSP)electro.fisica.unlp.edu.ar/arq/transparencias/ARQII_11... ·...
15
Arquitecturas GPU v. 2013
Transcript of Procesadores Digitales de Señal (DSP)electro.fisica.unlp.edu.ar/arq/transparencias/ARQII_11... ·...

Arquitecturas GPUv. 2013

Arquitecturas GPUStream Processing
Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO).
Data-centric model: adecuado para DSP o GPU (image, video and digital signal processing) pero no para procesamiento de propósitos generales con acceso a los datos aleatorio (randomized data access) como por ejemplo bases de datos.
El modelo es adecuado para aplicaciones que presentan las siguientes características:Cómputo intensivo, el número de operaciones aritméticas por I/O o referencia a memoria debe ser elevado. En muchas aplicaciones de procesamiento de señales actuales dicha razón está bien por encima de 50:1 y se incrementa con la complejidad del algoritmo.Parallelismo en los Datos, está presente si la misma función se aplica a todos los elementos de un stream y un cierto número de elementos puede ser procesado simultaneamente sin esperar los resultados de operaciones anteriores.Localidad en los Datos, es una forma específica de localidad temporal, común en procesamiento multimedia y de señales, donde los datos se producen una vez, son utilizados una o dos veces en la aplicación, y nunca más son utilizados.
DATAFLOW PROGRAMMING

Arquitecturas GPUGPU (Unidad de procesamiento gráfico)
Coprocesador con su propio repertorio de instrucciones y memoria propia (aunque no siempre).
Se accede como cualquier otro dispositivo de I/O (comandos o DMA).
Para el software es otro núcleo al cual se le envían datos y rutinas para procesar.
Marcas actuales:- Sony/Toshiba/IBM Cell Broadband Engine- NVIDIA family of GPUs. GeForce (games), Quadro (workstation) y Tesla (supercomputing).- ATI (AMD) family, Fusion APU accelerated processing unit (CPU+GPU)
DirectX (Microsoft propietario) vs. OpenGL (Open Graphics Library): API multilenguaje y multiplataforma para gráficos 2D y 3D (250+ funciones).

Arquitecturas GPUOrganización
http://www.pgroup.com/lit/articles/insider/v1n1a1.htm

Arquitecturas GPUPrestaciones
Tres aspectos clave:
Procesadores: 30 multiprocesadores, cada uno con 8 procesadores de hebras que ejecutan el mismo programa sincrónicamente (ejecutan la misma instrucción al mismo tiempo).
Memoria: hasta 4GB actualmente, bastante lenta como en CPU. Cache, pero principalmente ejecución por hebras.
Interconexión: gran ancho de banda.
DESACTUALIZADO

Arquitecturas GPUGP-GPULos chips gráficos empezaron como procesadores gráficos de funciones fijas, pero se hicieron cada vez más programables y potentes desde el punto de vista computacional, lo que permitió a NVIDIA introducir la primera GPU. Entre los años 1999 y 2000, científicos del sector informático y de otras disciplinas empezaron a utilizar las GPU para acelerar diversas aplicaciones científicas. Fue el nacimiento de un nuevo concepto denominado GP-GPU o GPU de propósito general.Aunque los usuarios conseguían un rendimiento sin igual (por encima de 100x con respecto a las GPU en algunos casos), el problema era que las GP-GPU requerían el uso de APIs de programación de gráficos como OpenGL al programar para las GPU. Eso limitaba el acceso a la enorme capacidad de las GPU en el campo científico.
NVIDIA CUDA (Compute Unified Device Architecture) SDK, incluye un compilador con extensiones para C. Aún implica reescritura y reestructuración del programa y el código no es ejecutable en x86.

Arquitecturas GPU
NVIDIA Fermi 16x32=51216 SM (streaming multiprocessor) de 32 cores CUDA.Los 32 cores ejecutan el mismo kernel sobre 32 threads diferentes.Los 16 SM pueden ejecutar diferentes kernels (multicore)

Arquitecturas GPUAPU (accelerated processing unit)CPU multinúcleo + GPU + Bus de interconexión + Controlador de memoria

Arquitecturas GPUHerramientas de programaciónActualmente:
– NVIDIA's CUDA– AMD's Brook+– OpenCL: Open standard language, portable entre diferentes GPU y otros
systemas paralelos (FPGA)
Requieren reestructurar el programa de aplicación en dos partes: la sección “host” y la sección “acelerador”, que debe ser expresada como funciones tipo kernel.
– HOST: manage device memory allocation, data movement, and kernel invocation. – KERNEL: optimizado para GPU (unrolling loops and orchestrating device memory
fetches and stores).
Si bien se ha avanzado mucho, tanto CUDA como OpenCL están lejos de ser una herramienta de utilización inmediata (curva de aprendizaje).

Arquitecturas GPU - ProgramaciónPlataforma NVIDIA-CUDALa plataforma de cálculo paralelo CUDA® proporciona extensiones de C y C++ que permiten implementar paralelismo en el procesamiento de tareas y procesos con diferentes niveles de granularidad. El programador puede expresar ese paralelismo mediante diferentes lenguajes de alto nivel como C, C++ y Fortran o mediante estándares abiertos como las directivas del modelo OpenACC.

Arquitecturas GPU - ProgramaciónOpenCLOpen Computing Language permite crear aplicaciones con paralelismo a nivel de datos y de tareas que pueden ejecutarse en diferentes plataformas (CPU, GPU, FPGA). El lenguaje está basado en C, eliminando cierta funcionalidad y extendiéndolo con operaciones que permiten la especificación de paralelismo.Apple creó la especificación original y fue desarrollada en conjunto con AMD, IBM, Intel y NVIDIA. Apple la propuso al Grupo Khronos para convertirla en un estándar abierto y libre de derechos.
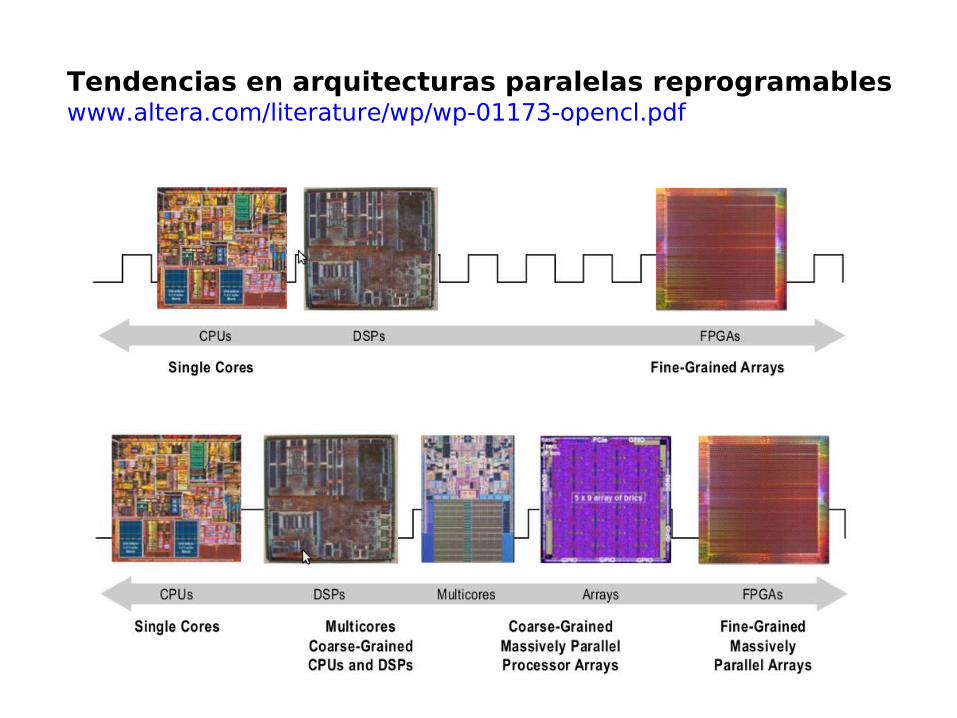
Tendencias en arquitecturas paralelas reprogramableswww.altera.com/literature/wp/wp-01173-opencl.pdf

TendenciasOpenCL en FPGA...

TendenciasOpenCL en FPGA

TendenciasAMD Bulldozer microarchitecture
Ver procesadores FX