
Procedures voor het Single Machine Maximum Lateness...
89
Procedures voor het Single Machine Maximum Lateness probleem Family batching Jeroen Neckebrouck Koen Schellinck Promotor: prof. dr. Mario Vanhoucke Begeleider: Veronique Sels Masterproef ingediend tot het bekomen van de graad van Master in de Bedrijfseconomie: Bedrijfseconomie Vakgroep Beleidsinformatica en Operationeel Beheer Voorzitter: prof. dr. Mario Vanhoucke Faculteit Economie Academiejaar 2009-2010
Transcript of Procedures voor het Single Machine Maximum Lateness...

Procedures voor het Single Machine MaximumLateness probleemFamily batching
Jeroen Neckebrouck
Koen Schellinck
Promotor: prof. dr. Mario VanhouckeBegeleider: Veronique Sels
Masterproef ingediend tot het bekomen van de graad vanMaster in de Bedrijfseconomie: Bedrijfseconomie
Vakgroep Beleidsinformatica en Operationeel BeheerVoorzitter: prof. dr. Mario VanhouckeFaculteit EconomieAcademiejaar 2009-2010


Procedures voor het Single Machine MaximumLateness probleemFamily batching
Jeroen Neckebrouck
Koen Schellinck
Promotor: prof. dr. Mario VanhouckeBegeleider: Veronique Sels
Masterproef ingediend tot het bekomen van de graad vanMaster in de Bedrijfseconomie: Bedrijfseconomie
Vakgroep Beleidsinformatica en Operationeel BeheerVoorzitter: prof. dr. Mario VanhouckeFaculteit EconomieAcademiejaar 2009-2010

Voorwoord
Toen wij vorig jaar afstudeerden als Master in de Ingenieurswetenschappen, Jeroenin de richting bouwkunde en Koen in de richting bedrijfskunde, waren we uiteraardtevreden met ons behaalde diploma, maar hadden we beiden het gevoel alsof er nogeen blinde vlek was in ons studieverloop. Het was namelijk zo dat we al verschillendeingenieursaspecten van de bedrijfswereld hadden leren kennen, maar nooit echt inaanraking waren gekomen met de economische kant ervan. Het leek ons dan ookinteressant om nog een masteropleiding te volgen in de bedrijfseconomie, waar wein contact kwamen met studiegebieden zoals marketing, accountancy, economie enbedrijfsfinanciering. We kregen naderhand inzicht in de economische implicaties vanverschillende beslissingen, genomen op bedrijfsniveau.
Toen ons gevraagd werd om een thesisonderwerp te kiezen, gingen wij dadelijk opzoek naar een gemeenschappelijk interessepunt; een zoektocht die niet lang duurde.Het was namelijk zo dat Jeroen naast zijn afstudeerrichting bouwkunde begonnen wasaan de Master in de Bedrijfskundige Systeemtechnieken en Operationeel Onderzoek,net de richting waarin Koen al afgestudeerd was. Het toeval wou dan ook nog eensdat we beiden een thesisonderwerp gekozen hadden dat sterk in verband stond metoperationeel onderzoek, en dat deze specifieke vakgroep ook aanwezig was binnende faculteit Economie en Bedrijfskunde.
We gingen dan ook aankloppen bij het hoofd van de vakgroep Beleidsinformatica enOperationeel beheer, prof. Dr. Mario Vanhoucke. We werden zeer enthousiast on-thaald en maakten meteen kennis met enkele interessante onderwerpen betreffendeoperationeel onderzoek waar op dat ogenblik uitgebreid onderzoek naar werd gedaan.Een onderwerp daarvan genoot meteen onze voorkeur: het Single Machine Schedul-ing (SMS) probleem. Er was namelijk op dat moment onderzoek naar de combinatievan verschillende gevalstudies die van toepassing waren op dit probleem, op basis vande centrale heuristiek van de Genetische Algoritmen. Dit onderzoek werd uitgevoerdonder leiding van wetenschappelijk medewerkster en doctoraatsstudente Veronique

ii
Sels.
Samen met haar en professor Vanhoucke kwamen we dan tot het uiteindelijke besluitdat wij onze thesis zouden uitvoeren omtrent specifieke uitbreidingen van haar on-derzoek en hopelijk zo ons steentje zouden kunnen bijdragen.
Gent, mei 2010Koen Schellinck
Jeroen Neckebrouck

Toelating tot bruikleen
De auteur geeft de toelating deze masterproef voor consultatie beschikbaar te stellenen delen van de masterproef te kopieren voor persoonlijk gebruik.Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzondermet betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalenvan resultaten uit deze scriptie.
The author gives the permission to use this thesis for consultation and to copyparts of it for personal use. Every other use is subject to the copyright laws, morespecifically the source must be extensively specified when using results from thisthesis.
Gent, mei 2010Koen Schellinck
Jeroen Neckebrouck

Inhoudstafel
Voorwoord i
Toelating tot bruikleen iii
Inleiding vi
1 Het Single Machine Scheduling Probleem 11.1 Wiskundige omschrijving . . . . . . . . . . . . . . . . . . . . . . . 21.2 Performantiematen . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Modelformulering . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Literatuurstudie van het SMS probleem 62.1 Het 1|Lmax probleem . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 Het 1 |prec|Lmax probleem . . . . . . . . . . . . . . . . . . . . . 72.3 Het 1 |rj |Lmax probleem . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 Het Schrage-algoritme . . . . . . . . . . . . . . . . . . . . 82.3.2 Andere studies rond het 1 |rj |Lmax probleem . . . . . . . . 9
2.4 Het 1 |sij |Lmax en het 1 |rij , sij |Lmax probleem . . . . . . . . . . 102.4.1 Het 1 |sij |Lmax probleem . . . . . . . . . . . . . . . . . . 102.4.2 Het 1 |rij , sij |Lmax probleem . . . . . . . . . . . . . . . . 13
2.5 Onze keuze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.6 Heuristische oplossingsmethoden . . . . . . . . . . . . . . . . . . . 142.7 Genetische algoritmen in SMS . . . . . . . . . . . . . . . . . . . . 142.8 Conclusie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Datageneratie 173.1 Inleiding en doelstelling . . . . . . . . . . . . . . . . . . . . . . . 173.2 Inzichten uit de literatuurstudie . . . . . . . . . . . . . . . . . . . . 18
3.2.1 Aantal taken, n . . . . . . . . . . . . . . . . . . . . . . . . 193.2.2 Procestijden, pi . . . . . . . . . . . . . . . . . . . . . . . . 193.2.3 Aantal families, F . . . . . . . . . . . . . . . . . . . . . . 19

INHOUDSTAFEL v
3.2.4 Due Dates, di . . . . . . . . . . . . . . . . . . . . . . . . . 193.2.5 Releasetijden . . . . . . . . . . . . . . . . . . . . . . . . . 203.2.6 Verdeling aantal jobs per familie . . . . . . . . . . . . . . . 203.2.7 Set-uptijden . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Eigen datageneratie: methode . . . . . . . . . . . . . . . . . . . . . 223.3.1 Aantal taken . . . . . . . . . . . . . . . . . . . . . . . . . 223.3.2 Procestijden, releasetijden en due dates . . . . . . . . . . . 223.3.3 Aantal families en verdeling aantal jobs per familie, een in-
telligente aanpak . . . . . . . . . . . . . . . . . . . . . . . 223.4 Conclusie: gebruikte dataset . . . . . . . . . . . . . . . . . . . . . 24
4 Modelontwikkeling en -oplossing met behulp van Genetische Algoritmen 274.1 Inleiding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.2 Genetische algoritmen . . . . . . . . . . . . . . . . . . . . . . . . 274.3 Algemene oplossingsmethode . . . . . . . . . . . . . . . . . . . . 29
4.3.1 Voorstelling van de oplossingen . . . . . . . . . . . . . . . 294.3.2 Opbouw van de oplossingsmethode . . . . . . . . . . . . . 304.3.3 Local search-algoritme . . . . . . . . . . . . . . . . . . . . 334.3.4 Intelligent move operator . . . . . . . . . . . . . . . . . . . 344.3.5 Invoegen nieuwe oplossingen . . . . . . . . . . . . . . . . 38
4.4 Matlab R©- programma . . . . . . . . . . . . . . . . . . . . . . . . 384.5 Conclusie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5 Evaluatie van het programma 415.1 Inleiding en doelstelling . . . . . . . . . . . . . . . . . . . . . . . 415.2 Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.3 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.4 Praktische besluittrekkingen uit de testruns . . . . . . . . . . . . . 46
5.4.1 Invloed van de familiespreiding . . . . . . . . . . . . . . . 485.4.2 Invloed van de set-uptijden . . . . . . . . . . . . . . . . . . 505.4.3 Invloed van releasetijden en due dates . . . . . . . . . . . . 50
5.5 Conclusie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6 Conclusie 53.1 Appendix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64

Inleiding
Door de jaren heen heeft het onderzoek op het gebied van Single Machine Scheduling(SMS) een belangrijke rol ingenomen in de bedrijfswereld. Dit mag niet verbazen.Het SMS-probleem, waarin een enkele machine wordt beschouwd, ligt immers aande basis van talrijke, vaak complexe softwarepakketten die worden gebruikt voorhet aansturen van gehele productiefaciliteiten. Deze masterproef wordt in hoofdzaakvooruitgestuwd door de drang naar het vinden van een optimale toewijzingspolitieken de daarbij horende constante drijfveer voor kostenbesparing.
In het eerste hoofdstuk wordt verder ingegaan op het begrip optimale toewijzingspoli-tiek en wordt het concept ’Single Machine Scheduling’ uit de doeken gedaan. Ditlaatste concept vinden we terug in vele productiebedrijven en heeft telkens betrekkingop het inplannen van verschillende jobs op een enkele machine, waar dan telkensverschillende voorwaarden en specificaties aan verbonden zijn. We zullen dit kortverduidelijken en beknopt bespreken, zodat in het verdere verloop van deze thesisgeen onduidelijkheden omtrent dit onderwerp de kop zullen kunnen opsteken.
In het daarop volgende hoofdstuk zullen we het resultaat naar voren schuiven vande literatuurstudie die door ons werd verricht. Om inzicht te krijgen in de materiedienden we namelijk eerst vertrouwd te raken met de terminologie, de bestaandemodellen en de toepassingsgebieden ervan die tot op de dag van vandaag gebruiktworden. Zo zult u kennis maken met het Single Machine Scheduling probleem metof zonder releasetijden, batching en jobfamilies. Verschillende modellen die in deloop der jaren ontwikkeld zijn, zullen worden gepresenteerd. Na een evaluatie vande verschillende modellen, wordt het meest veelbelovende weerhouden. Er wordtaandacht besteed aan de voordelen, maar eveneens aan de limiteringen van het doorons gekozen model.
Vanaf het derde hoodstuk komt onze persoonlijke inbreng in de masterproef aan bod.In dit hoofdstuk zal dieper worden ingegaan op het probleem van de datageneratie.

vii
Dit is een belangrijke fase. Opdat ons model bruikbaar zou zijn voor een grote ver-scheidenheid aan praktijkgevallen, dient immers een grote variatie aan data te wordengecreeerd en ontworpen. Specifiek kan het nut van een dergelijke variatie in tweezaken worden gevonden. Enerzijds is deze variatie interessant voor ons aangezienzij ons in staat stelt te evalueren hoe ons model reageert op verschillende instances.Anderzijds laat de verscheidenheid ons ook toe om aan het einde van onze mas-terproef algemeen toepasbare conclusies te trekken die nuttig kunnen zijn voor debedrijfswereld.
In het vierde hoofdstuk komt het door ons ontworpen model aan bod. We zullenproberen om bestaande modellen zo uit te breiden of aan te passen met zelf bedachtevernieuwingen, dat ze specifieke gevallen uit de industrie efficienter, i.e. sneller ofeffectiever aanpakken. We bespreken onze werkwijze en de daartoe speciaal ontwor-pen programma’s die ons zullen toelaten ons model te testen in praktijk.
Uiteraard moeten we de gegenereerde data dan ook gebruiken in ons model. Dit isdan ook het onderwerp van het vijfde hoofdstuk, waarin we een optimalisatiecycluszullen proberen ontwikkelen, waarbij we de minimalisatie van de maximum lateness,een veelgebruikt optimalisatiecriterium, tot doel stellen. Zo zal het mogelijk zijnvia testresultaten een gepaste validering uit te voeren van het voorgestelde model enverschillende gevalstudies uit te voeren, om na te gaan welke methode en welke datade beste resultaten opleveren. Relevante besluiten die nuttig kunnen zijn in diversepraktische situaties zullen worden getrokken.
We sluiten deze thesis af met een conclusie, waarin we zowel een evaluatie makenvan de gebruikte methoden en modellen, maar waarin we ook ruimte creeren voorverdere toepassingen en uitbreidingen van de gevonden oplossing.


ix

1Het Single Machine Scheduling Probleem
Het Single Machine Scheduling Probleem is een probleem waarmee bedrijven, vooraldeze die in de productie actief zijn, al sinds jaar en dag kampen. In zijn eenvoudigstevorm kunnen we het Single Machine Scheduling (SMS) Probleem omschrijven alshet proces van het toewijzen van verschillende groepen van taken aan een enkelemachine of resource. Het grote probleem daarvan wordt namelijk duidelijk als werekening houden met het feit dat deze machine een kritieke rol kan vervullen binnende productielijn.
Als deze machine bijgevolg een bottleneck zou zijn, zien we meteen in dat het opti-maal toewijzen van taken aan deze machine van cruciaal belang zal zijn wat betreftzijn impact op de andere machines binnen dezelfde productielijn. Wanneer we danook nog eens de bedenking maken dat het SMS probleem een klein onderdeel kanzijn in een veel grotere planningsomgeving, merken we dat het efficient oplossenervan onontbeerlijk is.
Het resultaat dat tevoorschijn zou moeten komen na het oplossen van het SMS pro-bleem, is het meest optimale toewijzingsschema voor de uit te voeren taken. Ditschema wordt voorgesteld door middel van een zogenaamde Gantt-chart, die er bij-voorbeeld zo kan uitzien

1.1. WISKUNDIGE OMSCHRIJVING 2
Figure 1.1: Gantt-chart
1.1 Wiskundige omschrijving
Een meer symbolische omschrijving kunnen we geven als volgt: stel dat er in totaalN verschillende taken zijn die verwerkt moeten worden op dezelfde machine. Ditmoet gebeuren onder een aantal voorwaarden:
i. de machine moet continu beschikbaar zijn.
ii. er kan maximum een taak per keer op de machine verwerkt worden.
iii. er mag geen pre-emption plaatsvinden; dit is het tijdelijk onderbreken van eentaak die verwerkt wordt, met het oog op het later afwerken van die taak, om eenbevoorrechte taak ten opzichte van de anderen uit te voeren.
Elke taak heeft een bepaalde releasetijd rj ; dit is het moment waarop de taak beschik-baar wordt voor verwerking. Daarnaast is er voor elke taak uiteraard ook een spec-ifieke verwerkingstijd pj en een tijdstip waarop de taak verwacht wordt om klaar tezijn, namelijk zijn due date dj .
Daarnaast kunnen we ook nog een andere parameter definieren, namelijk de comple-tion time Cj , die aangeeft wanneer een taak precies klaar is met verwerking. Deze

1.2. PERFORMANTIEMATEN 3
variabele is voor elke taak afhankelijk van de releasetijd en de verwerkingstijd, beideonafhankelijke variabelen. Wiskundig definieren we dit als volgt [1] :
C(1) = r1 + p1
C(j) = max(rj , Cj−1 + pj) ∀j = 2, . . . , N
1.2 Performantiematen
Nu we het probleem gedefinieerd hebben, moeten we ook een maatstaf gaan bepalenom bestaande productieschema’s van de machine te analyseren. In de praktijk zijner vier gangbare performance measures die we kunnen berekenen om na te gaan hoegoed een huidig schema is. Dit zijn, achtereenvolgens :
i. Tardiness : dit is het verschil tussen de completion time van een taak en zijn duedate, waarbij negatieve verschillen gelijk gesteld worden aan nul.
ii. Earliness : dit is net het omgekeerde van de tardiness, waarbij we dus bepalenhoeveel een taak te vroeg klaar is, ofwel het verschil tussen zijn due date en zijncompletion time.
iii. Lateness : dit is net hetzelfde begrip als de zonet besproken tardiness, met datverschil dat hier wel negatieve waarden toegestaan worden en dat er dus zoietszal bestaan als een negatieve lateness.
iv. Flowtime : dit is het verschil tussen de completion time en de releasetijd van eentaak en is dus een maatstaf voor hoelang een taak in het systeem verblijft.
Terwijl in de literatuur op alle vier deze performance measures onderzoek is verrichten ze telkens uitgebreid geanalyseerd zijn, moeten we op dit moment kiezen metwelke maatstaf we verder zullen werken. De meest gebruikte maatstaf in de praktijk,waarvoor we dan ook zullen kiezen, is de lateness. Het blijkt ook dat het mini-maliseren van de maximum lateness vaak leidt tot schema’s die tevens goed scorenwanneer zij worden beoordeeld op basis van tardiness en cycle time.
We zullen meer bepaald proberen om een toewijzingsschema te ontwikkelen datprobeert om de maximale lateness - dit slaat op de taak met de grootste lateness -te minimaliseren.

1.3. MODELFORMULERING 4
1.3 Modelformulering
Nu we weten wat we precies willen bekomen, kunnen we ons probleem vertalen ineen wiskundig model met behulp van de reeds gedefinieerde parameters. We baserenons hiervoor op het werk van Keha et al. (2009) [2]. Daartoe introduceren we vol-gende variabelen :
• xij , die gelijk wordt aan 1 als job j volgt op job i en gelijk wordt aan nul in hetandere geval.
• M , een zeer groot getal
• ri, pi, di en Ci zoals hierboven al besproken
• Lmax, de maximum lateness
Het wiskundige model luidt dan als volgtmin Lmax
onder de voorwaarden
1. Lmax ≥ Ci − di ∀i ∈ N
2. Ci ≥ pi + ri ∀i ∈ N
3. Cj − Ci −M · xij ≥ pj −M ∀i, j ∈ N, i < j
4. Ci − Cj + M · xij ≥ pi ∀i, j ∈ N, i < j
5. Ci ≥ 0 ∀i ∈ N
6. xij ∈ {0, 1} ∀i, j ∈ N, i < j
Enige verduidelijking hierbij: De doelfunctie streeft ernaar die oplossing te vindenwaarvan de maximum lateness zo laag mogelijk ligt. Dit wordt ook geıllustreerddoor de eerste voorwaarde, die stelt dat de maximum lateness minimaal de latenessvan elke taak apart moet zijn. De tweede voorwaarde drukt eenvoudigweg de definitievan de completion time uit en verzekert zich ervan dat die groter is of gelijk aan desom van de proces- en de releasetijd.
De derde en vierde voorwaarde zijn disjunctieve voorwaarden, aangezien die tweegevallen, xij = 0 (j komt niet na i) en xij = 1 (j komt wel na i), behelzen. In heteerste geval zal voorwaarde (3) steeds voldaan zijn en zal voorwaarde (4) stellen dattaak i zeker later verwerkt zal zijn dan taak j plus de procestijd van taak i. In hettweede geval geldt het omgekeerde analoog.

1.3. MODELFORMULERING 5
Voorwaarde (5) verzekert de niet-negativiteit van de completion times. In de laatstevoorwaarde duiden we aan dat beslissingsvariable xij een binaire variabele is dieenkel de waarden 0 en 1 kan aannemen.
In het volgende hoofdstuk gaan we dieper in op de verschillende varianten die opdit probleem bestaan en de uiteenlopende aanpakken die al gebruikt zijn om eenoplossing te vinden voor die verschillende SMS problemen.

2Literatuurstudie van het SMS probleem
In dit hoofdstuk zullen we op zoek gaan naar de verschillende studies die in de litera-tuur bestaan omtrent ons onderwerp. Na dit overzicht moeten we dan beslissen metwelk model we verder zullen werken, meer bepaald wat de basis zal zijn voor onzeeigen inbreng in een verdere uitwerking van een oplossing voor het probleem.
2.1 Het 1|Lmax probleem
Wanneer we enkel en alleen het probleem beschouwen waarin geen rekening wordtgehouden met releasetijden, spreken we van het 1|Lmax probleem. De voorgaandenotatie zullen we in de gehele literatuurstudie gebruiken. Deze notatie, ontworpen omde verschillende schedulingproblemen te classificeren, is afkomstig van Lawler [3].Voor het 1|Lmax probleem hebben we dan te maken met een reeks taken die allebeschikbaar worden voor verwerking op tijdstip nul. Elke taak heeft nog steeds zijnprocestijd en zijn due date als parameters, en de opdracht luidt een schema te zoekendie de maximale lateness minimaliseert. Dit probleem werd voor het eerst in 1955opgelost door Jackson, die zijn oplossing de ”Earliest Due Date”-regel noemde [4].Het probleem kan namelijk steeds optimaal opgelost worden door de verschillendetaken te ordenen volgens hun due dates, te beginnen met de taak die het vroegstaf moet zijn. Laat ons het voorbeeld uit tabel 2.1 beschouwen ter verduidelijk-ing. Passen we op deze gegevens de EDD-regel toe, dan krijgen we het schemavoorgesteld in figuur 2.1.

2.2. HET 1 |PREC|LMAX PROBLEEM 7
Taak Pj Dj
tijdseenheden tijdseenheden1 5 112 6 13 10 404 9 315 3 29
Table 2.1: Data horende bij het voorbeeld ter verduidelijking van de earliest due dateregel. Elke taak wordt gekenmerkt door een eigen taaknummer, benodigde procestijd pj
en due date dj
Figure 2.1: Voorbeeld ter verduidelijking van de earliest due date regel: schema
Indien het probleem anders geformuleerd zijn met het objectief om de gemiddeldeflowtijd te minimaliseren, zouden we een ander veelgebruikt algoritme kunnen toepassen,namelijk dat van de ”Shortest Processing Time”. Hierbij wordt telkens de taak metde kortste procestijd eerst ingepland, om uiteindelijk een productieschema te krijgenmet een minimale gemiddelde flowtijd.
2.2 Het 1 |prec|Lmax probleem
Wanneer aan het vorige probleem nu bepaalde voorrangsregels worden opgelegd,zien we in dat het oplossen ervan al iets moeilijker wordt. Toch beschreef Lawler in1973 een algoritme dat het oplossen ervan mogelijk maakt binnen polynomiale tijd.
We werken verder met ons vorig voorbeeld, maar stellen we nu dat taak 2 enkel kanuitgevoerd worden na taak 1 en taak 4 enkel na taak 3, dan krijgen we een anderschema, weergegeven in Figuur 2.2.

2.3. HET 1 |RJ |LMAX PROBLEEM 8
Figure 2.2: Voorbeeld ter verduidelijking van het principe van de voorrangsregels:schema
2.3 Het 1 |rj|Lmax probleem
Vervolgens belanden we bij de situatie waar we rekening zullen moeten houden met(willekeurige) releasetijden. We zien al gauw in dat dit het probleem heel wat com-plexer maakt. Oplossingen zullen niet zomaar binnen polynomiale tijd gevondenkunnen worden, tenzij in een paar speciale gevallen. Zo zien we dat dit onder meermogelijk is voor problemen waar alle procestijden hetzelfde zijn: het 1 |rj , pj = p|Lmax
probleem. Een andere mogelijkheid is het toelaten van pre-emption zoals hierbovenreeds uitgelegd [5].
In de andere gevallen zeggen we dan dat het probleem ”NP-hard” wordt in sterkezin (non-deterministisch polynomiale tijd moeilijk) [6]. Een baanbrekende oplossingvoor het gewone probleem kwam er echter in 1971 door Schrage [7].
2.3.1 Het Schrage-algoritme
De basisidee van het Schrage-algoritme bestaat erin om de verschillende taken teordenen zoals Jackson, maar mits uitbreidingen die rekening houden met de aan-wezigheid van releasetijden. We noemen dit dan ook de ”Uitgebreide Earliest DueDate” - regel. Een duidelijke wiskundige formulering van deze regel kwam er doorMcMahon en Florian in 1975 :
Schrage: Als S de verzameling is van alle reeds ingeplande taken en S’ de verza-meling van alle nog niet geplande taken, en stel het volledig aantal taken = N, door-loop dan volgend algoritme:
1. Stap 1: S = ∅ en de tijd t = min(rj) , ∀j ∈ N
2. Stap 2: Bekijk op tijdstip t alle beschikbare taken j ∈ S′ waarbij de releasetijdkleiner is dan of gelijk aan t, en plan die taak in, die de kleinste due date heeft.

2.3. HET 1 |RJ |LMAX PROBLEEM 9
3. Stap 3: S = S ∪ j , Cj = t + pj (completion time van taak j) en t =max(Cj , min(rk)),∀k ∈ S′. Kijk tenslotte of |S| = 0. Is dit zo, dan is hetalgoritme compleet; ga anders terug naar stap 2.
Het Schrage-algoritme resulteert in een schema dat bestaat uit alle taken, ingeplandvolgens een reeks van blokken, waarbij 1 blok bestaat uit een serie opeenvolgendetaken. Tussen de blokken is het mogelijk dat er idle time optreedt; dit is tijd waaropde machine stilstaat en ze dus niet productief is.
In dit schema kunnen we ook de kritieke taak definieren. Dit is namelijk de taakdie de grootste lateness, Lmax , met zich meebrengt. Het zal dus deze taak zijn dieverantwoordelijk is voor de uiteindelijke beoordeling van het schema in het zoekennaar eventuele verbeteringen ervan. Optimaliteit bij Schrage wordt bereikt wanneerde due date van de kritieke taak de grootste is van alle taken die in hetzelfde blok vande kritieke taak ingepland zijn.
Wanneer we er ons voorbeeld weer bijhalen, aangevuld met releasetijden, krijgen we:
Taak Pj Dj Rj
tijdseenheden tijdseenheden tijdseenheden1 5 11 72 6 1 163 10 40 104 9 31 195 3 29 6
Table 2.2: Data horende bij het voorbeeld ter verduidelijking van de earliest due dateregel bij taken met releasetijd rj . Elke taak wordt gekenmerkt door een eigentaaknummer, een benodigde procestijd pj , een duedate dj en een tijdstip waarop detaak vrij komt rj
Het schema, opgesteld volgens het Schrage-algoritme, wordt dan (Figuur 2.3):
2.3.2 Andere studies rond het 1 |rj|Lmax probleem
Branch-and-bound algoritmen
Een van de meest efficiente algoritmen die de techniek van branching en boundingtoepast, is te vinden in het werk van Carlier uit 1982 [8]. Het is vooral toepasbaar op

2.4. HET 1 |SIJ |LMAX EN HET 1 |RIJ , SIJ |LMAX PROBLEEM 10
Figure 2.3: Voorbeeld ter verduidelijking van de earliest due date regel bij taken metreleasetijd: schema
grote datasets. Dit algoritme werd door de jaren heen verder bestudeerd, uitgediept enverbeterd door verschillende onderzoekers. Aanpassingen werden gemaakt omtrenttaakafhankelijkheden, voorrangsregels tussen taken. Terwijl de meest eenvoudigesituaties relatief makkelijk en binnen afzienbare tijd exact werden opgelost, werdvoor de meer moeilijke situaties de techniek van de branch-and-bound algoritmentoegepast.
De meest vernoemenswaardige papers omtrent dit onderwerp zijn Baker and Su(1974) [9], Bratley et al. (1974) [10] McMahon and Florian et al. (1986) [11],Lageweg er al. (1976) [12], Larson er al. (1985) [13], Grabowski er al. (1986) [14] ,Nowicki and Zdrzalka (1986) [15],Balas et al. (1995) [16], Chang and Su (2001) [17]en Pan and Shi (2006) [18].
Benaderingsalgoritmen
Hier vernoemen we het werk van Kise et al. (1979) [19], Potts (1980) [20], Hall andShmoys (1992) [21] en Nowicki and Smutnicki (1994) [22]. Allen zochten ze naarverschillende benaderingsalgoritmen, gebaseerd op de heuristiek van Schrage. Deworst-case resultaten werden onderzocht.
Andere oplossingsmethoden zijn de heuristische methoden. We bespreken eerst echternog kort het probleem met set-uptijden en gaan daarna over tot die oplossingswijzen.
2.4 Het 1 |sij|Lmax en het 1 |rij, sij|Lmax probleem
2.4.1 Het 1 |sij|Lmax probleem
Wanneer we nu beredeneren dat het niet in acht nemen van set-uptijden kan leidentot zeer grote hoeveelheden tijd die gespendeerd worden aan change-overs, zien wedat dit kan resulteren in een significant verlies aan capaciteit. Daarom is het ook

2.4. HET 1 |SIJ |LMAX EN HET 1 |RIJ , SIJ |LMAX PROBLEEM 11
belangrijk dat we het probleem van het minimaliseren van Lmax in de aanwezigheidvan set-uptijden beschouwen. We definieren voor het verdere verloop van dit werkook een taakfamilie als alle gelijksoortige taken die eenzelfde set-uptijd vereisen.
Als we veronderstellen dat de set-uptijden volgordeafhankelijk zijn, stelt sij de tijdvoor die nodig is voor een set-up wanneer taak j onmiddellijk achter taak i ingeplandstaat. Ook dit probleem is, net als het probleem hiervoor, NP-hard. Monma andPotts (1989) stellen een dynamisch programmeeralgoritme voor als oplossingswijzeen bewijzen daarnaast ook dat er een optimaal schema bestaat waar alle taken binneneen taakfamilie gepland worden volgens de ”Earliest Due Date”-regel (EDD-regel)[23]. Deze eigenschap impliceert ook dat een optimaal schema zal bestaan uit eenbepaald aantal ”batches”, elk bestaande uit een aantal taken van dezelfde familie dievolgens de EDD-regel geordend zijn. Het probleem van het vinden van een optimaalschema kan dus herleid worden naar 2 deelproblemen. Enerzijds het bepalen van hetaantal geschikte batches voor een familie en anderzijds het vinden van de optimalevolgorde voor de taken van deze familie. We halen nogmaals ons voorbeeld aanen duiden nu aan bij welke familie elke taak hoort, en wat de volgordeafhankelijkeset-uptijden zijn voor elke familie:
Taak Pj Dj Ftijdseenheden tijdseenheden tijdseenheden
1 5 11 12 6 1 23 10 40 34 9 31 25 3 29 1
Table 2.3: Voorbeeld - Taakdata: Elke taak wordt gekenmerkt door een eigentaaknummer, een benodigde procestijd pj , een due date dj en een familie F waar zijtoe behoren
Dan krijgen we volgend schema, wanneer we bijvoorbeeld de regel toepassen van deEDD en elke familie batchen:
We kunnen ook andere voorbeelden indenken, waarbij niet elke familie een batch is,maar taken van dezelfde familie op verschillende plaatsen in het schema voorkomen.Uiteraard zijn dan meerdere set-ups nodig.
Potts toonde aan dat de complexiteit van het probleem sterk vermindert wanneer hetaantal families beperkt blijft tot twee [24]. Uzsoy et al. gebruikten in 1991 om een

2.4. HET 1 |SIJ |LMAX EN HET 1 |RIJ , SIJ |LMAX PROBLEEM 12
Familie 1 2 31 2 4 62 1 2 33 3 5 7Set-up t=0 2 1 3
Table 2.4: Voorbeeld - Set-uptijden: Wanneer twee taken van een verschillende familiena elkaar worden gepland, dan is er een set-uptijd vereist
Figure 2.4: Voorbeeld schema: familie en set-uptijden
branch-and-bound algoritme het 1 |prec, sij |Lmax probleem op te lossen, waarbijdus nog extra voorrangsregels in het spel komen [25]. Hariri and Potts (1997) komendan weer met een samengestelde heuristiek waarbij alle taken van een familie in eenenkele batch gepland worden [26]. Ze gebruiken dan een dubbele-batch heuristiekwaarbij ze een familie in twee splitsen zodat ten hoogste twee geordende batches vanelke familie ontstaan.
Een groot aantal onderzoeken werd ook gevoerd naar de ”Group Technology” (GT)veronderstelling, waarbij alle taken van dezelfde familie in dezelfde batch geplaatstworden. Potts and Wassenhove (1992) bekijken een aantal algoritmen van dezesoort [27]. Naar analogie met de dubbele-batch heuristiek kan dit GT-principe ookuitgebreid worden naar scenario’s die batches splitsen. Webster and Baker (1995)definieerden de EDD-regel voor batches als een heuristiek waarbij, gegeven een reeksbatches die elk binnenin georden zijn volgens EDD, de minimale Lmax bereikt wordtdoor alle batches in niet-afnemende volgorde van hun due dates te plaatsen [28].Baker (1998) tenslotte stelde een ”gap” heuristiek voor, waarbij de familiebatchgecreeerd door de GT-techniek, gesplitst wordt, maar waarbij ook taken toegevoegdworden aan het schema.
Uzsoy and Velasquez (2008) definieren daarnaast nog eens een familie due date eneen familie lateness, waardoor ze de EDD-regel kunnen doortrekken naar de batches[29]. Daarbuiten verwijzen we nog naar een aantal andere interessante studies die

2.5. ONZE KEUZE 13
naar dit onderwerp gevoerd zijn, onder meer door Allahverdi, Gupta and Aldowaisan(1999) en naar het classificatieschema opgesteld door Potts and Kovalyov (2000)[30, 31].
Tot slot wensen we de moeilijkheid van dit probleem te benadrukken. In het spe-ciale geval waarin alle taken dezelfde due date hebben, is het 1|sij |Lmax probleemvolledig equivalent aan 1|sij |Cmax waarbij Ci de makespan voorstelt. Dit probleemis volledig equivalent aan het Travelling Salesman Problem (TSP) (Baker, 1974) datNP-hard is in sterke zin [9].
2.4.2 Het 1 |rij, sij|Lmax probleem
Wanneer we nu de twee gegevens die het probleem zoveel complexer maken, namelijkhet invoeren van releasetijden en het invoeren van set-uptijden combineren, sprekenwe van het 1 |rij , sij |Lmax probleem. Nodeloos om te zeggen dat dit probleem min-stens dubbel zo complex wordt als elk geval apart. Gezien het onderliggend probleemzonder set-uptijden reeds NP-hard is in de sterke zin, is het zeer onwaarschijnlijk dater een procedure bestaat die het probleem oplost binnen polynomiale-tijd.
Enkele auteurs deden al onderzoek naar dit probleem, waarbij we verwijzen naar vol-gende papers: Allahverdi et al. (1999) met een overzicht van verschillende oploss-ingsmethoden, Ovacik and Uzsoy (1994) met een rolling horizon algoritme, de be-naderingsmethode van Zdrzalka (1995), de branch-and bound procedure van Schuttenet al. (1996) en het Tabu search algoritme van Shin et al. (2002) [30, 32–35].
2.5 Onze keuze
Nu beslissen we naar welk probleem wij onderzoek gaan doen. Onze keuze vieluiteindelijk op het laatste probleem, namelijk het 1 |rij , sij |Lmax probleem, omdat:
• wij daaromtrent het minste informatie terugvonden in de literatuur en het pro-bleem verder onderzoek waard is,
• het uiteindelijk een uitdaging is om dit moeilijke probleem aan te pakken en
• omdat wij dan verder kunnen werken op een paper van Sels en Vanhoucke(2009), die een oplossingsmethode voor het 1 |rij |Lmax probleem gebruiktwaarmee wij bekend zijn en die we nog niet teruggevonden hebben in de lite-ratuur in verband met het 1 |rij , sij |Lmax probleem [36].

2.6. HEURISTISCHE OPLOSSINGSMETHODEN 14
2.6 Heuristische oplossingsmethoden
Aangezien we in het verdere verloop van deze thesis voort zullen werken met dezesoort oplossingsmethoden, zoals reeds gezegd verder bouwend op het werk van Selsand Vanhoucke (2009), houden wij er toch aan al eens te verklaren wat deze methodenzijn. We gaan tevens na in de literatuur of er al werk verricht is dat steunt op onzegekozen heuristische methode.
Wanneer het beschouwde probleem zoals hierboven vermeld zo groot wordt dat wete kampen krijgen met zeer talrijke datasets, blijken enkel heuristische methodenrelevant te zijn en kunnen we door exacte methodes geen oplossingen meer verkrij-gen. Een heuristiek is namelijk een methode die systematisch te werk gaat om zo totoplossingen te komen. Er kan zelfs een zogenaamde metaheuristiek gebruikt wor-den. Dit is een heuristische methode die verder gaat dan de gewone heuristieken engebruikt wordt wanneer er geen praktische aanwending van een algoritme mogelijkis.
Er bestaan verschillende metaheuristische oplossingsmethodes, waaronder bijvoor-beeld:
• Genetische algoritmen
• Tabu Search
• Simulated Annealing
• A*
• Neurale netwerken
• Ant-colony optimalisatie
• . . .
2.7 Genetische algoritmen in SMS
Sinds ongeveer de helft van de jaren negentig zijn wetenschappers op het idee gekomenom genetische algoritmen te gebruiken voor het oplossen van allerhande SMS prob-lemen. Zo onderzochten Rubin and Ragatz (1995), Tan et al. (2000) en Armentanoand Mazzini (2000) het SMS probleem met due dates en volgordeafhankelijke set-uptijden [37–39]. Daarbij ontwikkelden ze een Genetisch Algoritme (GA) om detotale tardiness te minimaliseren.

2.8. CONCLUSIE 15
Koh et al. (2005), Kashan et al. (2006) en Damodaran et al. (2006) onderzochtendaarentegen het single-batch-processing machine probleem met niet-identieke taak-groottes om de makespan te minimaliseren aan de hand van een hybride GA-methode[40–42]. Chou et al. (2006) breidden deze studie uit door het toevoegen van (willekeurige)releasetijden [43].
Een vergelijkende studie tussen verschillende local search heuristieken, waaronderhet GA, werd gemaakt door Crauwels et al. (1996), waarbij vooral de nadruk werdgelegd op het minimaliseren van het aantal taken die te laat werden opgeleverd[27]. De gemiddelde completion tijd van de taken minimaliseren met behulp van eenaangepast GA was het onderwerp van een studie van Liu and Tang (1999) [1]. Hayatand Wirth (1997) onderzochten dan weer de toepassing van GA voor een single-batch-processing machine met volgordeonafhankelijke set-uptijden met het oog ophet minimaliseren van de totale flowtijd [44].
Uiteindelijk komen we dan bij het onderzoek aangaande de door ons gekozen perfor-mantiemaat: de maximum lateness. Wang and Uzsoy (2002) ontwierpen een situatiewaarin dynamisch taken arriveerden op een batch-verwerkende machine [45]. Zijkenden echter prioriteitsgewichten toe aan de taken, waardoor de te minimaliserendoelfunctie anders uitvalt. Verder vernoemen we nog het werk van Kethley and Ali-dae (2002), die het totale gewogen werk dat te laat is, willen minimaliseren, Sevauxand Dauzre-Prs (2003), die lichtjes anders het gewogen aantal taken die te laat zijn,minimaliseren, Lin and Ying (2007), die verschillende metaheuristische methodenvergelijken in hun performantie tot het totale gewogen tardiness probleem met vol-gordeafhankelijke set-uptijden en Chang et al. (2006) en Hsieh et al. (2006) waar dedoelstelling het minimaliseren van de totale gewogen completion time is in de aan-wezigheid van releasetijden [43,46–49]. Allen maken ze gebruik van de techniek vande GA.
Om deze literatuurstudie af te ronden, vermelden we nog dat er ook GA-methodenbestaan die onderzoek doen naar het minimaliseren van andere doelfuncties, waar hettoestaan van idle time voordelig kan zijn voor de oplossing. Daartoe wordt meestalgebruik gemaakt van earliness- en tardiness-strafpunten.
2.8 Conclusie
Wat besluiten we nu uit deze literatuurstudie? We kennen nu de achtergrond en deverschillende bestaande varianten op het SMS probleem. We kiezen een specifiekprobleem uit en bouwen verder op de techniek van de GA om te proberen tot eengoede oplossingsmethode te komen. In het volgende hoofdstuk zullen we eerst dedoor ons gevolgde methode van datageneratie bespreken, terwijl we in hoofdstuk

2.8. CONCLUSIE 16
vier onze oplossing voor het probleem uit de doeken doen.

3Datageneratie
3.1 Inleiding en doelstelling
Bij het opbouwen van een planningsalgoritme is het genereren van adequate datazonder twijfel een cruciale stap. Dergelijke data zullen immers gebruikt wordendoorheen de hele ontwikkeling van het programma. Er zullen voldoende realistis-che instances moeten worden gecreeerd om het algoritme in een eerste fase te testen,vervolgens te optimaliseren en finaal te evalueren. Onder een instance verstaan weeen enkele taken-dataset, bestaande uit n aantal taken, tesamen met een bijhorendeset-uptijdendataset. Zoals reeds meermaals aangehaald zal in het ontworpen modelelke taak worden gekenmerkt door een eigen procestijd, releasetijden, due date en eenfamilienummer. Dit laatste element geeft voor elke individuele taak aan tot welke fa-milie zij behoort.
Het belang van de keuze van de instances indachtig is het spijtig vast te stellen dat inde literatuur geen standaard benchmark datasets terug te vinden zijn. Elke individueleauteur lijkt de voorkeur te geven aan het ontwerpen van een eigen datageneratiemeth-ode, eerder dan het overnemen van bestaande datasets. Evenwel, in contrast tot degrote verscheidenheid aan deze methodes staat de grote eenvormigheid ertussen. In-derdaad, de concepten waarop de verschillende datageneratiemethodes steunen, zijnvrijwel telkens analoog. Het doel is telkens om instances te creeren die representatiefzijn voor een gehele probleemklasse. Hall en Posner verwijzen naar deze eigenschapmet de term correspondence [50]. Het onachtzaam genereren van ”gemakkelijke”

3.2. INZICHTEN UIT DE LITERATUURSTUDIE 18
problemen dient immers te worden vermeden. Dergelijke eenvoudig oplosbare in-stances zullen immers niet in staat zijn om het algoritme met de verschillende sub-programma’s en vondsten ten gronde en in alle volledigheid te testen.
3.2 Inzichten uit de literatuurstudie
Uit de uitgevoerde literatuurstudie volgde al gauw het inzicht dat twee extremen degehele klasse van mogelijk genereerbare instances insluiten. Aan de ene zijde vindenwe die instances die gekenmerkt worden door set-uptijden die zeer groot zijn in ver-houding tot de procestijden en/of weinig strenge due dates. Onder taken met weinigstrenge due dates verstaan we taken waarvan de duedates zich voldoende ver, i.e.ruim later in de tijd, bevinden t.o.v. de releasetijden. Deze klasse zal worden geop-timaliseerd door de Group Theory sequentie, i.e. die sequentie waarbij alle takenvan dezelfde familie bij elkaar worden genomen. In deze klasse zal het totaal aan-tal set-ups zal gelijk zijn aan het totaal aantal verschillende families verminderd meteen. Aan de andere zijde vinden we die instances terug die geoptimaliseerd wordendoor de ”Earliest Due Date”-sequentie. Dit zijn typisch instances waarbij de taakset-uptijden zeer klein zijn in verhouding tot de taak-procestijden. Interessante in-stances, die het algoritme in haar volledigheid testen, zullen zich tussen deze tweeuitersten bevinden.
De parameters die bepalend zijn bij de datageneratie voor ons model zijn:
• het aantal taken per instance
• de releasetijden, procestijden en due dates van de taken
• het aantal verschillende families en het aantal taken per familie
• de verschillende set-uptijden
In de beperkte literatuur omtrent de modellen die het maximum lateness probleemmet batching behandelen, worden voor elk van deze parameters enigzins verschil-lende waarden en methodes teruggevonden. Omdat de meeste generatiemethodes uitbovengenoemde klasse quasi analoog blijken, vermelden we hieronder voornamelijkde parameterwaarden die gebruikt werden in de studies waar zowel set-uptijden alsreleasetijden aan bod komen, i.e. de 1|rij , sij |Lmax problemen. In deze laatsteklasse, merken we op dat Shin in 2002 de instances die gebruikt werden voor depublicatie van Ovacik in 1994 overneemt [32, 35]. Bovendien merken we op datin deze masterproef wordt aangenomen dat set-uptijden enkel voorkomen tussen 2taken van een andere familie. In de publicaties van Ovacik en Shin wordt voor elkecombinatie van 2 taken rekening gehouden met een bepaalde set-uptijd.

3.2. INZICHTEN UIT DE LITERATUURSTUDIE 19
3.2.1 Aantal taken, n
Eerst bekijken we de keuze van het aantal taken per instance. In 1994 onderzoekenOvacik en Uszoy instances met een aantal taken tussen 10 en 100 [32]. In 1996 werktSchutten met instances die 30 tot 50 taken bevatten [34]. Een jaar later, bij Hariri enPotts, alsook bij Baker (zonder releasetijden) vinden we een analoog interval meteen aantal taken gelijk aan 30, 40, 50 of 60 [26, 51]. Jin, die evenwel geen rekeninghoudt met relasetijden, maakt in 2008 gebruik van instances met 60 tot 100 taken.Jin vermeldt bovendien dat in echte bedrijfsproblemen vaak problemen voorkomenmet meer dan 100 taken [52].
3.2.2 Procestijden, pi
In elke door ons doorgenomen publicatie worden de procestijden pj voor elke taakrandom gekozen uit een discrete uniforme distributie. Zowel Hariri als Schuttenmaken gebruik van random integers uit het interval [1, 100] [26, 34]. Ovacik kiestzowel de proces- als de set-uptijden uit het interval [1,200] [32].
3.2.3 Aantal families, F
Schutten deelt voor elke instance de taken uniform in tussen een aantal families F,waarbij dit aantal gekozen wordt uit het interval [2, n/5]. Aangezien de instancestot 50 taken bevatten, betekent dit dat er maximaal 10 families van 5 taken zullenbestaan. Bij Hariri (geen releasetijden) wordt ook een uniforme verdeling toegepast.Het aantal families bedraagt er ten minste 2 en ten hoogste 10. Bij Ovacik, alsookbij Shin wordt geen gebruik gemaakt van families. In beide studies wordt voor elkkoppel taken, i en j, een set-uptijd gedefinieerd, sij .
3.2.4 Due Dates, di
De methodes die due dates genereren zijn typisch op te delen in 2 categorien.
Een eerste categorie publicaties genereert due dates die onafhankelijk zijn van deindividuele taak procestijden of of releasetijden. Het meest gebruikte voorbeeld is al-licht de techniek van Hariri die op basis van de som van alle procestijden, i.e.
∑j pj ,
de due dates uniform genereert in het interval U [a ·∑
j pj , b ·∑
j pj ]. De parametersa en b (a < b) leggen dan zowel de locatie als de breedte van het interval op waaruitde due dates worden gekozen. In de publicatie van Hariri in 1997 (alle releasetijden

3.2. INZICHTEN UIT DE LITERATUURSTUDIE 20
gelijk aan 0), worden a ∈ [0, 0.2, 0.4, 0.6, 0.8] en b ∈ [0.2, 0.4, 0.6, 0.8, 1] gekozen(a < b) [26].
Een tweede klasse kiest due dates die afhankelijk zijn van de releasetijden en deprocestijden van de individuele taken. Schutten kiest duedates uniform tussen [rj +pj , rj + pj + d · pavg] waarbij pavg de gemiddelde procestijd, i.e. 50, voorstelt end ∈ 2, 4, 6 [34]. Ook Ovacik kiest releasetijdafhankelijke due dates, met name di =ri + 2 · k · pi waarbij k ∈ [−1, 4] en k ∈ N.
Aangezien deze k-waarde ook negatief kan worden, betekent dit dat een taak reedsvoorbij haar due date kan zijn wanneer ze aan de machine toekomt. In een indus-triele omgeving kan deze situatie voorkomen wanneer een taak al vertraging heeftopgelopen in voorgaande stappen van het productieprocess.
Tot slot vermelden we nog het feit dat enkel de relatieve afstand tussen de release-tijden van belang is, veel meer dan de absolute waarde van de due dates. Het to-evoegen van een constante aan alle taak-due dates van een bepaalde instance heeftimmers geen relevante invloed op de ’fitness’ van de verschillende voortgebrachtesequenties. Enkel de maximum lateness zal toenemen met een waarde gelijk aan degekozen constante.
3.2.5 Releasetijden
Slechts een beperkt aantal gepubliceerde modellen incorporeren taak-releasetijden.Bij Schutten wordt een Poissonproces gesimuleerd met een gemiddelde interarrival-tijd, varierend tussen 57.29 en 68.39 [34]. Bij Ovacik vinden we dat de release-tijden uniform verdeeld zijn over een interval [0, R · n · (pavg + savg)]. Hierbij steltn · (pavg + savg) de average makespan voor, het aantal taken n vermenigvuldigd metde som van de gemiddelde procestijd, i.e. 100, en de gemiddelde set-uptijd, ook 100.Hoe groter R, hoe minder frequent de taken aankomen aan de machine. Voor degegenereerde instances was R ∈ [0.6, 0.8, 1, 1.2, 1.4] [32]. In figuur 3.1 wordt eenvergelijking gemaakt tussen de distributie van de releasetijden volgens een Poisson-proces enerzijds en volgens een uniforme distributie anderzijds. De grote variabiliteitin de releasetijden volgens de uniforme verdeling is opvallend.
3.2.6 Verdeling aantal jobs per familie
In het merendeel van de publicaties waarin taakfamilies aan bod komen, worden defamilie-indices van de taken uniform gekozen uit de range [1, F ] [26, 34]. Ook bijSchutten is dit het geval. Bij Ovacik en Uzsoy wordt zoals reeds aangehaald niet metfamilies gewerkt. Elke sequentie van 2 taken heeft een bijhorende set-uptijd sij dieuniform verdeeld is tussen [0, 200].

3.2. INZICHTEN UIT DE LITERATUURSTUDIE 21
Figure 3.1: Cumulatieve distributie van de interarrivaltimes - een vergelijking tussenverschillende datageneratiemethodes. In de grafiek is de poissondistributieweergegeven met gemiddelde waarde 50. Een dergelijke distributie wordt gebruikt doorSchutten [34]. Voor de distributies van Ovacik werd een herschaling doorgevoerd zodatde arrivaltimes uniform werden gekozen in het interval [0, R · n · 50]
3.2.7 Set-uptijden
De grootte van de set-uptijden, samen met de distributie van de due dates, bepaalt vol-gens Hariri in belangrijke mate de ’moeilijkheid’ van het probleem [26]. Bij Schutten(met releasetijden) alsook bij Hariri en Jin, worden 3 klassen set-uptijden gecreeerd.Voor elke klasse worden de setuptijden variabel gekozen uit uniforme distributies.Bij Schutten vinden we als intervallen Klasse A: [1, 12.5], Klasse B: [1, 25] en KlasseC: [1, 37.5] [34]. Alle set-uptijden zijn hier dus kleiner dan de gemiddelde proces-tijd, i.e. pavg = 50. Bij Hariri dan weer vinden we Klasse A: [1, 100], Klasse B:[1, 20] en Klasse C: [101, 200] [26]. Klasse A genereert set-uptijden die dezelfde dis-tributie hebben als de procestijden. In klasse B is elke set-uptijd klein in vergelijkingmet de gemiddelde procestijd terwijl in klasse C elke set-uptijd groter zal zijn danelke procestijd. Bij Jin ten slotte vinden we eveneens 3 klassen Klasse A: [11, 20],Klasse B: [51, 100] en Klasse C: [101, 200] [52]. Het is opmerkelijk vast te stellen datSchutten enkel relatief kleine set-uptijden gebruikt. Bovendien stellen we vast dat deset-uptijden vaak uit een ruim interval, bijvoorbeeld [1, 100] worden gekozen. Voorbepaalde reele industriele processen, bijvoorbeeld het vervangen van een treksteen instaaldraadproductie, lijkt het ons even goed mogelijk dat set-uptijden slechts gering

3.3. EIGEN DATAGENERATIE: METHODE 22
varieren. Daarenboven wordt in geen van de vermelde publicaties gevolg gegevenaan de opdeling in set-uptijden klasses. Zo worden de prestaties van de algoritmenniet in verband gebracht met de verschillende voorgestelde set-uptijden klassen enalgemene conclusies hieromtrent (al dan niet batchen) blijven ook uit.
3.3 Eigen datageneratie: methode
3.3.1 Aantal taken
De gelijkaardige modellen uit de literatuurstudie indachtig, kozen wij er voor onsmodel voor om te werken met instances bestaande uit 50 taken.
3.3.2 Procestijden, releasetijden en due dates
Voor de generatie van de taakrelevante tijden besloten wij als basis de procedure zoalsvoorgesteld door Sels en Vanhoucke te volgen [36]. Uit dit werk nemen we volgendemethodes over:
• het genereren van de procestijden als uniform verdeelde integers in het interval[0, 100]
• het genereren van releasetijden als uniform verdeelde integers in het interval[0, l ·
∑pj ], waarbij l de range aangeeft waarover de releasetijden zullen wor-
den verdeeld. Deze parameter l is aldus vergelijkbaar met de parameter Ruit het werk van Ovacik [32], hoewel daar ook rekening wordt gehouden metgemiddelde set-uptijden.
• het genereren van due dates volgens de eerste methode, i.e. due dates afhanke-lijk van de releasetijden en procestijden. Meer bepaald zullen we due datesuniform genereren uit het interval [rj +k ·pj , rj +k ·pj +q] waarbij de param-eter k de due date tightness en q de slack allowance voorstelt. De totale slack,i.e. de periode tussen de releasedate en de due date van een bepaalde taak, zalaldus toenemen voor stijgende k en q.
3.3.3 Aantal families en verdeling aantal jobs per familie, een intelli-gente aanpak
In ons model werd ervoor gekozen om te werken met families van 5 tot 20 taken.Meer bepaald zullen we werken met 4 verschillende waarden, Nf ∈ [5, 10, 15, 20].Dit zorgt ervoor dat het minimum aantal families 3 bedraagt terwijl het maximumaantal 10 (= 50/5) is. Deze aantallen zijn vergelijkbaar met de waarden uit de litera-tuurstudie.

3.3. EIGEN DATAGENERATIE: METHODE 23
Er werd niet gekozen om de familie-indices van de taken uniform te kiezen uit derange [1, F ] [26, 34]. Deze methode genereert immers steeds taken die onderlinguiterst random zijn met betrekking tot de keuze van de familie. Stel bijvoorbeelddat alle taken worden gerangschikt op basis van releasetijd, i.e. alle taken krijgeneen index waarbij de taak die het eerste vrijkomt index 1 krijgt en diegene die hetlaatste vrijkomt index 50. Volgens de vooropgestelde generatiemethode zal er indeze sequentie geen enkele correlatie zijn tussen de families van 2 op elkaar volgendetaken.
In werkelijke industriele omgevingen zullen ons inziens zowel aankomsten voorkomendie compleet familie-random zijn, als aankomsten waar een zekere familie-correlatiebestaat. Om tegemoet te komen aan deze bevinding, werd een intelligente proce-dure ontwikkeld die de familie-indices zal toekennen. Het algoritme bestaat uit eenselectiecyclus en is hieronder weergegeven.
• Initialisatie
– Creeer de verzameling van alle taken, S, |S| = 50
– Rangschik deze taken op releasetijd, de taak met de kleinste releasetijdeerst
– Kies het aantal taken per familie Nf ∈ [5, 10, 15, 20]
– Kies de familiespreidingsparameter T : T ∈ [1, 50/Nf ], T ∈ R– Initialiseer de familieindex, nFamily = 1
• Herhaal zolang |S| ≥ T ·Nf
i. j=1
ii. Herhaal zolang j < Nf
a. Bepaal een taakpositie k random uit de uniforme discrete distributie:k = U [1, T ·Nf − j + 1]
b. Ken aan de taak op positie k uit de lijst S de familie-index nFamilytoe
c. Verwijder taak uit lijst: S = S \ k
d. j = j + 1
iii. Verhoog de familie-index nFamily = nFamily + 1
• Indien |S| 6= 0, ken dan aan alle resterende taken uit de lijst de familie-indexnFamily toe

3.4. CONCLUSIE: GEBRUIKTE DATASET 24
In de initialisatiestap worden alle taken gerangschikt op releasetijd en wordt het aan-tal taken per familie en de familiespreidingsparameter T bepaald. Deze laatste pa-rameter duidt aan in welke mate de families gespreid zijn over de aankomende taken.Een waarde T = 1 zal ervoor zorgen dat alle taken van dezelfde familie vlak naelkaar toekomen. Een grotere waarde voor T, stel bijvoorbeeld T = 2 zorgt ervoordat de taken van dezelfde familie verder uit elkaar liggen. De verduidelijking hiervanvolgt samen met de beschrijving van de toewijzingscyclus van het algoritme.
Eens de familieindex nFamily geınitaliseerd is met waarde 1, start het algoritmemet het toewijzen van deze indices aan de taken. Als voorbeeld beschrijven we hettoekennen van de eerste familieindex. De taak die als eerste (j = 1) de familieindex1 zal krijgen wordt bepaald door een random en integere waarde k uit het interval[1, T · Nf − j + 1] te kiezen. Indien er 10 taken per familie zijn (Nf = 10), en defamiliespreidingsparameter T = 1.5 wordt gekozen dan wordt k voor de eerste taakgetrokken uit [1, 15]. De waarde k bepaalt aan welke taak binnen de lijst van takenzonder familie-index, i.e. S, de familieindex nFamily zal worden toegekend. Steldat k = 7 wordt getrokken, dan is dit de zevende taak uit de lijst.
Eens de index toegewezen, wordt de taak uit de lijst S verwijderd en zal de volgendeindex (j = j + 1) worden toegewezen. Dit zal zich herhalen zolang de teller jkleiner is dan het maximum aantal taken per familie Nf . Op dat ogenblik wordt defamilieindex met een eenheid verhoogd en zo naar de volgende familie gesprongen.De cyclus herhaalt zich en blijft telkens indices toekennen en taken uit de selectielijstS schrappen tot zolang het aantal resterende taken in de lijst kleiner is dan de hetproduct T · Nf . Alle taken die op dat ogenblik geen familie-index bevatten, krijgende laatste familie-indexwaarde toegewezen.
Een en ander wordt nog verduidelijkt in figuur 3.2.
3.4 Conclusie: gebruikte dataset
Na het uiteenzetten van de methode voor het genereren van de data, volgt in dezesectie de uiteindelijke keuze van de parameterwaarden. Binnen het gebied van ”in-teressante” instances (zie sectie 3.2) dient er een trade-off te gebeuren. Enerzijdsdienen de data zoveel mogelijk verschillende gevallen te beschrijven omwille vande volledigheid. Anderzijds brengt een grote variatie aan parameters al gauw eenenorme hoeveelheid data voort. Het mag duidelijk zijn dat een ontzaglijke hoeveel-heid data het nemen van duidelijke conclusies niet steeds in positieve zin beınvloedt.
De parameterkeuzes zijn weergegeven in tabel 3.1. Het totaal aantal instancesbedraagt 1152.
Ninstances = 2 · 2 · 3 · 4 · 6 · 4 = 1152

3.4. CONCLUSIE: GEBRUIKTE DATASET 25
Figure 3.2: Stap in het toewijzingsalgoritme van de verschillende familieindices. In hetvoorbeeld is het aantal taken per familie Nf = 10 en is de familiespreidingsparameterT = 1.5. De tien indices voor de eerste familie zijn reeds toegekend en op de figuurwordt de 2e index voor de tweede familie toegewezen aan de taak op de 7e positie in derij van beschikbare taken.
Parameters waarden aantalAantal taken, n 50 1Procestijden, pj U [0, 100] NAReleasetijden, rj l ∈ [1, 1.5] 2Due dates, dj k ∈ [0, 5] 2
q ∈ [n, 5 · n, 10 · n] 3Aantal taken per familie, Nf Nf ∈ [5, 10, 15, 20] 4Familiespreidingsparameter, T T ∈ [1, 1.2, 1.4, 1.6, 1.8, 2] 6Set-uptijden ST ∈ [20, 60, 100, 300] 4
Table 3.1: Parameters van de instances
Bemerk nog dat de parameter l die de range van releasetijden beschrijft 2 waarden kanaannemen. Zowel de waarde l = 1 als l = 1.5 leidt tot ”interessante” instances voorons algoritme. Hoewel in de publicatie van Sels en Vanhoucke ook parameterwaardenl voorkomen kleiner dan 1, zullen wij deze niet behandelen. Immers, releasetijden diezeer dicht bij elkaar liggen veroorzaken in onze datageneratiemethode ook due datesdie dicht bij elkaar liggen. Aangezien wij in tegenstelling tot Sels en Vanhouckerekening houden met set-uptijden, leiden kleine waarden voor l al gauw tot datasetsdie enorme Lmax waarden genereren [36].
Voor l = 1 zal het bereik van de releasetijden samenvallen met de range van som van

3.4. CONCLUSIE: GEBRUIKTE DATASET 26
de procestijden. Bij kleinere familiegroottes, grotere set-uptijden en een grote fam-iliespreidingsfactor zullen we in dit geval allicht al gauw enorme waarden bekomenvoor de maximum lateness.

4Modelontwikkeling m.b.v. Genetische
Algoritmen
4.1 Inleiding
In hoofdstuk 2 werd beslist welk type model in deze masterproef zou worden be-handeld, meer bepaald het 1|rij , sij |Lmax probleem. Bovendien werd de globalemethode gekozen waarmee het probleem zal worden aangepakt, i.e. de methodevan de genetische algoritmen. In hoofdstuk 3 werd vervolgens een gepaste maniervan datageneratie besproken. In dit hoofdstuk wordt het tijd om over te gaan tothet verduidelijken van ons nieuwe model, maar ook van de techniek van genetischealgoritmen, die we als oplossingsmethode zullen gebruiken.
Onze optimalisatiecyclus die we naar voren schuiven, is zoals eerder beslist gebaseerdop het werk van Sels en Vanhoucke (2009) [36]. De uitbreiding naar het algemeneregeval met productfamilies, set-uptijden en batches zal onze eigen inbreng zijn in ditwerk.
4.2 Genetische algoritmen
De techniek van de genetische algoritmen stamt oorspronkelijk af van de biologie.In de genetica wordt namelijk de relatie bestudeerd tussen ouders en kinderen. Zo

4.2. GENETISCHE ALGORITMEN 28
vindt men onderlinge relaties en bestudeert men de invloed van bepaalde uiterlijkeof fysieke kenmerken. Om de toepassing van genetische algoritmen in de optimal-isatieproblematiek te kunnen situeren, herinneren we aan de evolutietheorie, die steltdat de ”fitste” individuen het best overleven.
Bij genetische algoritmen wordt namelijk gewerkt met een zichzelf voortplantendepopulatie, die een bepaald aantal individuen bevat. In een initialisatiestap wordtzo een aantal individuen gegenereerd, waarbij elk individu op zich voldoet aan devooropgestelde voorwaarden. We zeggen dan dat het individu doenlijk (E.: feasible)is. Voor elk individu in die populaties wordt dan de ”fitheid” berekend aan de handvan een fitheidfunctie. Deze fitheid symboliseert hoe goed of hoe slecht het individuzich verhoudt tot andere individuen.
Tijdens een stap die selectie wordt genoemd, zal men dan de grootte van de populatieverminderen door de beste individuen, de zogeheten ouders, te selecteren. Daarnawil men dat de populatie weer aangroeit. De nieuwe populatie (of beter: generatie)ontstaat door middel van reproductie. Reproductie is een proces waarin nieuwe in-dividuen, de zogeheten kinderen, worden gecreeerd door de methodes mutatie enrecombinatie toe te passen op de geselecteerde ouders.
Bij een techniek van het type recombinatie worden telkens twee individuen, i.e. ou-ders, gecombineerd tot een nieuw individu. Een voorbeeld hiervan is de cross-overtechniek, die delen van het ene individu in het andere invult. Bij mutatie daarentegenwordt gewoon een individu geselecteerd, waarop verschillende mutatieoperatorenlosgelaten worden. Het hoofddoel van de mutatietechniek bestaat erin om bij te dra-gen tot de diversiteit of verscheidenheid binnen de populatie. Dankzij deze diversiteitwordt getracht het te snel convergeren naar een lokale, niet optimale oplossing tegente gaan. Via recombinatie worden aldus bepaalde eigenschappen van de individuengewijzigd, in de hoop om steeds betere ”fitheden” te bekomen in de opeenvolgendegeneraties. Elke gebruikte recombinatietechniek volgt voort uit deze doelstelling,met name om in elke volgende stap, i.e. de nieuwe populatie/generatie, betere en dusfittere individuen te produceren.
Naast recombinatie beschouwen we ook nog immigratie, waar in tegenstelling totde recombinatie geen kleine wijzigingen aan de bestaande populatie worden aange-bracht, maar geheel nieuwe oplossingen worden gecreeerd. Deze nieuwe oplossingenmoeten tevens bijdragen tot de diversiteit in de populatie.
Alvorens de nieuwe oplossingen (recombinatiekinderen en immigratiekinderen) inde populatie worden geıntroduceerd, wordt nog getracht elk individu op zich te ver-beteren via een zogeheten local search techniek. Een dergelijk algoritme zoektop iteratieve manier doorheen de oplossingsruimte, startend vanuit de individuele

4.3. ALGEMENE OPLOSSINGSMETHODE 29
oplossing die het individu aangeeft. Het local search algortime zal telkens de huidigeoplossing door een betere naburige oplossing in de naburige ruimte vervangen totdatgeen gunstigere oplossing meer kan worden gevonden of tot wanneer aan een bepaaldstopcriterium is voldaan. Een dergelijk local search stopcriterium kan bijvoorbeeldgebaseerd zijn op het beperken van het aantal zoekiteraties of op het limiteren van dezoektijd.
Het genetisch algoritme blijft de voorgaande optimalisatiecyclus (selectie, recombi-natie en immigratie) herhalen tot aan een zekere stopconditie is voldaan. Dergelijkestopconditie kan verscheidene vormen aannemen. Vaak wordt een maximale totalerekentijd of een maximaal aantal cycli bepaald. Ook is het mogelijk om het zoekente stoppen wanneer gedurende een bepaalde periode of aantal cycli geen verbeter-ing meer wordt gevonden. Eens het algoritme stopgezet, zal de fitste oplossing naarvoren worden geschoven als de meest optimale.
Het grote voordeel van metaheuristieken zoals genetische algoritmen is hun mo-gelijkheid om een enorme zoekruimte te kunnen verwerken. Het grootste nadeeldaarentegen is dat ze nooit zekerheid kunnen geven omtrent de optimaliteit van degevonden oplossing. Wel vormt die oplossing doorgaans een goede schatting voor deoptimale oplossing en is ze een ondergrens ervoor.
Om nu de gepaste methoden en parameters betreffende al deze verschillende stappente ontwikkelen en te programmeren, zullen we ons grotendeels baseren op het reedsgeleverde werk van Sels en Vanhoucke (2009) [36]. Laat ons nu even dieper ingaanop onze oplossingswijze.
4.3 Algemene oplossingsmethode
4.3.1 Voorstelling van de oplossingen
Een belangrijke stap in de opbouw van alle genetisch algoritmen, is de beslissing opwelke manier de oplossingen of individuen zullen worden voorgesteld. Een vaak ge-bruikte methode in SMS is permutatiecodering. Daarbij wordt elke ’chromosoom’ alseen permutatie van n taken, elk met een uniek taaknummer, voorgesteld. Aangezienelke taak een en slechts een keer voorkomt, ontstaan gegarandeerd unieke schema’s.Zo kan bijvoorbeeld een permutatie van 10 taken eruit zien als volgt:
[5, 2, 4, 9, 1, 10, 6, 7, 3, 8]
4.3. ALGEMENE OPLOSSINGSMETHODE 30
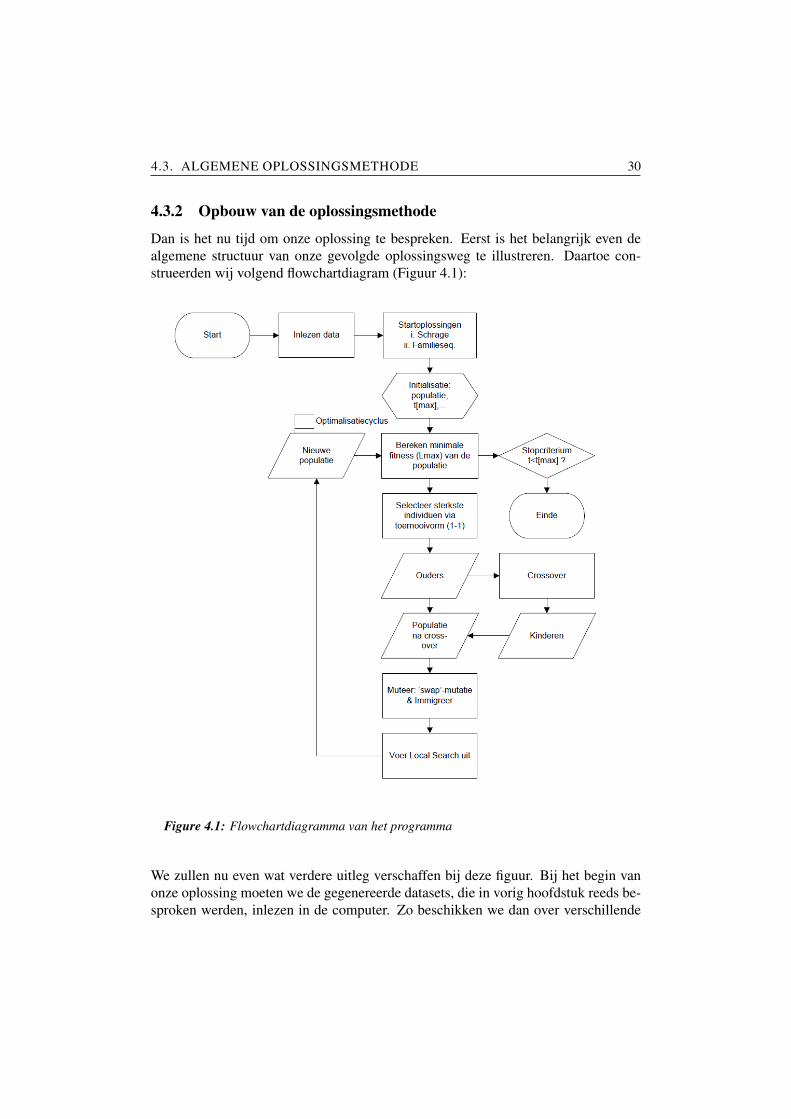
4.3.2 Opbouw van de oplossingsmethode
Dan is het nu tijd om onze oplossing te bespreken. Eerst is het belangrijk even dealgemene structuur van onze gevolgde oplossingsweg te illustreren. Daartoe con-strueerden wij volgend flowchartdiagram (Figuur 4.1):
Figure 4.1: Flowchartdiagramma van het programma
We zullen nu even wat verdere uitleg verschaffen bij deze figuur. Bij het begin vanonze oplossing moeten we de gegenereerde datasets, die in vorig hoofdstuk reeds be-sproken werden, inlezen in de computer. Zo beschikken we dan over verschillende

4.3. ALGEMENE OPLOSSINGSMETHODE 31
taken, elk gekarakteriseerd door een releasetijd, procestijd, due date en taakfamilie.Eenmaal dit gebeurd is, kunnen we overgaan tot onze veelbesproken optimalisatiecy-clus. Deze wordt namelijk voor elk probleem apart doorlopen gedurende een zekeretijd. Is deze tijd verlopen, dan wordt de cyclus stopgezet (het stopcriterium).
Als de cyclus wordt gestart, wordt allereerst een populatie gecreeerd in de initialisa-tiestap. Dit houdt in dat we grotendeels at random permutaties zullen maken van debeschikbare data, naast enkele weldoordachte startoplossingen. De grootte van dezepopulatie moeten we instellen op een bepaalde waarde, die we later door testrunskunnen optimaliseren. Op dit ogenblik baseren we ons voor alle instelparameters opde bevindingen van Sels en Vanhoucke (2009), in dit geval wordt dat dan een vijfdevan het totaal aantal individuen.
In ons algoritme worden 2 startoplossingen voor de populatie zelf aangebracht endus niet random gegenereerd. Deze twee startoplossing beschrijven twee uiterstenvan de zoekruimte. De eerste is de oplossing die bekomen wordt door het Schrage-algoritme toe te passen. Voor deze oplossing wordt aldus abstractie gemaakt van deset-uptijden. Deze methode zal allicht een goede, fitte startoplossing geven in diegevallen waar de set-uptijden vrij klein zijn relatief ten opzichte van de procestijden.De tweede startoplossing, die in de initiele populatie wordt meegegeven, is diegenedie het aantal set-ups minimaliseert. De sequentie die dit realiseert is diegene die alletaken van dezelfde familie groepeert. Binnen dezelfde familie werd er voor gekozenom in deze tweede startoplossing de taken te rangschikken volgens releasetijd. Dezestartoplossing zal een goeie, fitte, startoplossing zijn in die gevallen waar de set-uptijden zeer groot zijn relatief ten opzichte van de procestijden.
Door de doelfunctie te berekenen, kennen we de startwaarden voor de fitnesses. Dezekunnen we later gebruiken om de totale verbeteringen te onderzoeken. De volgendestap in onze cyclus is dan de selectiestap. Ook hier halen we de gebruikte methodeuit de vermelde paper. Daar zien we namelijk dat na testen de toernooimanier voorselectie de beste blijkt te zijn. Deze methode neemt at random twee individuen uit depopulatie, vergelijkt hun fitnesswaarden twee aan twee, en houdt enkel diegene metde beste fitness over voor de volgende stap, cross-over.
Wanneer we de cross-over toepassen, zullen we twee willekeurig gekozen ouders ge-bruiken uit de reeds geselecteerde populatie. Deze zullen een nieuwe permutatievoortbrengen, een kind, dat per definitie minstens even goed als zijn ouders zoumoeten zijn. Hiertoe gebruiken we opnieuw de best gevonden methode van de basis-paper. Dit is de positiegebaseerde cross-over. Dit hele proces kan gebeuren met eenzekere kans, de cross-overkans. Het proces zelf werkt als volgt: selecteer at randomeen aantal taken uit de eerste ouder en voeg deze op identiek dezelfde plaatsen in hetkind in. Zoek dan de plaatsen van de overgebleven taken in de tweede ouder en plaats

4.3. ALGEMENE OPLOSSINGSMETHODE 32
deze taken in die volgorde in het kind. Een voorbeeld is weergegeven in (Figuur 4.2):
Figure 4.2: Illustratie van het cross-overmechanisme
In dit voorbeeld worden taken 1, 4, 5 en 6 gekozen van de eerste ouder, terwijl taken2, 3 en 7 in dezelfde volgorde van voorkomen in ouder 2 ingevoegd worden in hetkind op de nog lege plaatsen.
De bekomen kinderen worden nu bij de geselecteerde ouders gevoegd om opnieuween volledige populatie te hebben.
In een volgende stap worden deze dan gemuteerd, eveneens met een zekere kans:of de mutatiekans. Dit is opnieuw een parameter. De meest gunstige methode dieSels en Vanhoucke gebruiken hiervoor, is de zogeten swap mutatie [36]. Hierbijworden eenvoudigweg twee verschillende taken at random uit de permutatie gekozenen vervolgens verwisseld van plaats.
Daarna kan opnieuw met een zekere kans, de immigratiekans, een totaal nieuw in-dividu worden gecreeerd. Het inbrengen van dergelijk nieuw individu heeft tot doelvoldoende diversiteit in de populatie te brengen. Een dergelijke diversiteit is nodigom twee redenen. Enerzijds dient het algoritme een zo breed mogelijke oploss-ingsruimte te doorzoeken. Anderzijds mag het algoritme zich niet vastlopen in eenlokaal minimum. Hoeweel het toevoegen van volledig nieuwe individuen een belang-rijke bijdrage heeft in het creeren van voldoende diversiteit, zal de immigratiekanszeer klein worden gekozen. Ook bij Sels en Vanhoucke, waar setup-tijden niet inrekening worden gebracht, ligt de instelwaarde voor deze parameter zeer laag [36].

4.3. ALGEMENE OPLOSSINGSMETHODE 33
4.3.3 Local search-algoritme
In een laatste stap van de optimalisatiecyclus wordt het local search algoritme uit-gevoerd. Gezien het grote belang van dit algoritme in de zoektocht naar quasi-optimale oplossingen, wordt een aparte subsectie voorzien. Het algoritme dat ge-bruikt zal worden, is opgebouwd uit 5 verschillende zoek-verbeter-procedures dieworden toegepast op elk individu van de populatie. De vijf procedures die gebruiktworden, zijn
i. Randomized pairwise swap: deze algemeen gekende subprocedure zoekt naarverbeteringen of hogere fitnesses (lagere maximum lateness) door 2 taken uit hetindivivu/taaksequentie at random van plaats te wisselen
ii. Adjacant pairwise swap: deze algemeen gekende subprocedure zoekt naar eenlagere maximum lateness door 2 naburige taken van plaats te wisselen
iii. Family swap is analoog aan de randomized pairwise swap maar wisselt enkeltaken die tot dezelfde familie behoren
iv. Family move neemt een taak van een bepaalde familie uit de sequentie en voegtdeze in na een random gekozen taak van dezelfde familie
v. Intelligent move operator is een zelf ontworpen procedure die zoekt naar verbe-teringen door taken een per een op een doordachte manier te verplaatsen; eenmeer gedetailleerde uitleg volgt hieronder
Het mag duidelijk zijn dat bepaalde procedures aanzienlijk intelligenter of complexerzijn dan andere. Zo zijn de Randomized pairwise swap alsook de Adjacant pairwiseswap weinig complexe zoekprocedures. Ze worden toegepast in SMS modellen zon-der batching. Het door ons bestudeerde model is omwille van de set-uptijden aanzien-lijk complexer dan deze basismodellen. De kracht van deze random verwisselopera-toren neemt daardoor aanzienlijk af. Een toevoeging van andere zoekprocedures lijktzeer wenselijk.
De Family swap alsook de Family move operator komen tegemoet aan het feit dathet beschouwde model rekening houdt met batches en set-uptijden. Beide operatorenhebben geen invloed op het aantal noch op de duur van de set-ups die in de sequentieoptreden. We verwachten dat voor problemen met grote set-uptijden en een kleinefamiliespreidingsparameter R (zie 3.3.3) deze operatoren behoorlijk krachtig zullenzijn.

4.3. ALGEMENE OPLOSSINGSMETHODE 34
4.3.4 Intelligent move operator
De Intelligent move operator tenslotte volgde uit het bestuderen van de ’rolling hori-zon’ procedure die door Ovacik en Uzsoy (1994) werd gebruikt om het 1|rij , sij |Lmax
probleem aan te pakken [32]. Ook in 2008 steunden Uzsoy et al. op een ’rolling hori-zon’ procedure bij het behandelen van het 1|sk|Lmax probleem [29]. De ’rolling hori-zon’ procedure is een techniek die steeds sequenties van een beperkt aantal opeenvol-gende taken (de horizon) tracht te optimaliseren. De procedure start typisch aan hetbegin van de taaksequentie en tracht vervolgens de sequentie van de eerste n takente optimaliseren. Eens een optimale of verbeterde oplossing voor deze eerste n takenis gevonden, wordt een volgend subprobleem behandeld. De eerste taak wordt nubuiten beschouwing gelaten en de horizon, de sequentie van n taken die in het sub-probleem wordt beschouwd, start vanaf de tweede taak in de gehele sequentie. Wezeggen dat de horizon opschuift (E: rolling).
In ons probleem werd ervoor gekozen om voor de Intelligent move operator op zoekte gaan naar een variant op deze rolling horizon (RH) procedure met het doel eenbelangrijke toevoeging te creeren bij de 4 andere reeds besproken operatoren. Netzoals bij RH onderzochten we welke verbeteringen het verplaatsen van taken binneneen beperkte horizon kan voortbrengen.
Er werd steeds gezocht naar een lagere lateness voor een welbepaalde taak k door eenandere taak (stel j), oorspronkelijk gepland op een positie voor taak k in te voegenvlak na deze taak k (zie figuur 4.3).
Figure 4.3: Illustratie van de Intelligent move operator, taak j wordt ingevoegd na taakk. In het gunstige geval vervroegen de tijdstippen waarop de taken j + 1 tot kaanvatten.
De verschillende methodes ter bepaling van taken j en k worden besproken na eenalgemene uitleg omtrent de werking van de procedure.
In de ’Rolling horizon’ procedures uit de literatuur wordt voor de horizon typisch eenvast aantal taken aangenomen. Onze voorgestelde operator daarentegen beschouwt

4.3. ALGEMENE OPLOSSINGSMETHODE 35
een alternatieve aanpak met een variabele horizon. We zullen op zoek gaan naar dietaakverplaastingen die een verlaging (of het gelijk blijven) van de lateness van taak kvoortbrengen zonder de maximale lateness van de sequentie te verhogen. Specifiekonderzoeken we als voorwaarden dat
• de lateness van taak k afneemt (of gelijk blijft)
• en de lateness van taak j niet groter wordt dan de huidige maximale lateness
Eerste voorwaarde De eerste voorwaarde stelt dat de lateness van taak k moetafnemen. Dit is enkel mogelijk wanneer alle taken in de sequentie [j + 1, k] naarvoor kunnen worden geschoven. Dit is pas mogelijk onder 2 condities. Enerzijdsdient de minimale wachttijd, i.e. de tijd tussen de releasetijd en het starttijdstip vaneen bepaalde taak, van al deze taken [j + 1, k] groter te zijn dan nul. Inderdaad,wanneer een van deze taken reeds aanvangt op zijn releasetijd dan kan deze nietworden vervroegd. Deze verhindert het vervroegen van alle andere eropvolgendetaken. We noteren als eerste voorwaarde
min(st − rt : t ∈ [j + 1, k]) > 0
waarbij we t gebruiken als algemene notatie voor een bepaalde taak en st, respec-tievelijk rt, het starttijdstip en de releasetijd voorstellen van die bepaalde taak t.Anderzijds mag de starttijd van taak j + 1 niet vergroot worden in het voorgesteldeschema. In dat geval zal taak k nooit kunnen worden vervroegd. Een latere starttijdvoor taak j + 1 kan voorkomen uit een set-uptijd tussen de familie van taak j − 1en de familie van taak j + 1; we noteren setupFj−1,Fj+1 . We noteren symbolisch datde voorgestelde starttijd s’ van taak j + 1 kleiner of gelijk moet zijn dan de huidigestarttijd s van taak j + 1
s′j+1 = max(sj−1 + pj−1 + setupFj−1,Fj+1 , rj+1) ≤ sj+1
Beide voorwaarden in acht nemend, is de maximale tijdsduur waarmee taak k alduskan worden vervroegd
∆k,max = min(min(st − rt : t ∈ [j + 1, k]), sj+1 − s′j+1)
Tweede voorwaarde De tweede voorwaarde stelt dat de lateness van taak j nietgroter mag worden dan de huidige maximale lateness. Aangezien taak j wordt ge-pland na taak k, zal zij in het voorgestelde schema ten vroegste starten zijn op hettijdstip s′j = sk −∆k,max + pk + setupFk,Fj . Hierdoor wordt de voorwaarde
s′j + pj − dj < Lmax

4.3. ALGEMENE OPLOSSINGSMETHODE 36
De voorwaarden, die noodzakelijk zijn om een verlaging van de lateness van eenbepaalde taak k te veroorzaken, zijn op dit moment besproken. Rest ons nog debeslissing te nemen op welke manier de taken j en k zullen worden geselecteerd.Zowel voor de keuze van de taak j die zal worden verplaatst als voor de taak waarnazij zal trachten te worden ingevoegd, i.e. taak k, wordt een lus doorlopen. Drie ver-schillende mogelijkheden om dit te bewerkstelligen worden onderzocht en vergeleken.In alle gevallen wordt de zoekoperator afgebroken zodra een verlaging van de max-imum lateness, Lmax is gevonden of zodra alle lussen werden voltooid. De driemethodes om beide lussen te doorlopen, zijn:
i. Zowel de lus voor de taak die zal verplaatst worden, taak j, als de lus voor deinvoegtaak k, zijn oplopende lussen, waarbij lus k zich binnen lus j bevindt. Demogelijke voorgestelde schema’s zijn dus achtereenvolgens [j = 1, k = 2],[j =1, k = 3],[j = 1, k = 4],...[j = 2, k = 3],[j = 2, k = 4],..
ii. Zowel de lus voor de taak die zal verplaatst worden, taak j, als de lus voorde invoegtaak k zijn aflopende lussen, waarbij lus k zich binnen lus j bevindt.De mogelijke voorgestelde schema’s zijn dus achtereenvolgens [j = 50, k =49],[j = 50, k = 48],[j = 50, k = 47],...[j = 49, k = 48],[j = 49, k = 47],..
iii. Lus j start bij de taak die in het huidig schema de kleinste lateness heeft. Lus kstart bij de taak die in het huidig schema de grootste lateness heeft. Taak j wordtinitieel vastgehouden terwijl k alle taken (volgens aflopende lateness doorloopt).Indien in deze eerste lus geen verbetering wordt gevonden, dan wordt taak jvervangen door de taak met de op een na kleinste lateness en wordt lus k opnieuwdoorlopen.
De drie methodes worden in combinatie met de andere operatoren losgelaten opeen steekproef van ’moeilijke’ instances. De parameterwaarden voor de instances uitde steekproef zijn weergegeven in tabel 4.1.
Voor elk van de drie varianten worden 2 runs uitgevoerd, namelijk een kortere runmet 10 seconden rekentijd per instance en een langere run met 20 seconden reken-tijd per instance. Voor elk van de drie varianten word vervolgens voor elk van beideruns een score berekend op basis van de berekende fitnesswaarden Lmax. Voor beideruns wordt voor elk van de 3 varianten voor elke instance de relatieve afwijking t.o.v.de beste gevonden fitnesswaarde berekend. De gemiddelde afwijking over alle in-stances levert dan de scorewaarde. Hoe lager deze scorewaarde (in %), hoe kleinerde afwijking ten opzichte van de best gevonden waarde, dus hoe beter de methode.
Stel met m de beschouwde methode voor (m ∈ [1, 2, 3]) en met I de verzameling van

4.3. ALGEMENE OPLOSSINGSMETHODE 37
Parameters waardenAantal taken, n 50Procestijden, pj U [0, 100]Releasetijden, rj l = 1Due dates, dj k = 5
q = 5 · nAantal taken per familie, Nf Nf ∈ [5, 10, 15, 20]Familiespreidingsparameter, T T ∈ [1, 1.2, 1.4, 1.6, 1.8, 2]Set-uptijden ST = 60
Table 4.1: Steekproef voor het onderzoek naar de 3 varianten van de voorgesteldeintelligent move operator: onderzochte klasse
alle instances in de steekproef, dan krijgen we als score voor een bepaalde methode:
Scorem =1|I|
∑i∈I
(Lmax,m,i
min(Lmax,1,i, Lmax,2,i, Lmax,3,i))
Kijkend naar de kolom ’20s rekentijd’ uit tabel 4.2, blijkt dat het steekproefonder-zoek de methode met de oplopende lussen naar voor schuift als de aangewezen me-thode. Opmerkelijk is dat op basis van de korte run (10 seconden rekentijd) zowelde methode met de aflopende lussen als deze op basis van de latenesses betere re-sultaten geven. We zijn evenwel geınteresseerd in die methode die uiteindelijk debeste oplossing zal geven en niet diegene die binnen een rekentijd van 10 secondende beste oplossing geeft. Daarom wordt voor de methode van de oplopende lussengekozen.
Methode Score10s rekentijd 20s rekentijd[%] [%]
Oplopende lussen 11.54 4.27Aflopende lussen 7.49 8.01Latenesses 10.56 6.77
Table 4.2: Resultaten van het steekproefonderzoek met betrekking tot de 3 variantenvan de intelligent move operator

4.4. MATLAB R©- PROGRAMMA 38
4.3.5 Invoegen nieuwe oplossingen
Wanneer we nu al deze verbeterde individuen samenvoegen tot de vernieuwde popu-latie, moeten we nog naar een voorwaarde kijken. Het is namelijk zo dat we slechtseen bepaald (klein) percentage van identieke oplossingen willen laten voorkomen inde populatie. Daartoe moeten we nog controleren of er onder een zeker duplicatie-percentage gebleven wordt bij het invoegen. Is dit niet zo, dan behouden we hetvorige individu. Nu kunnen we, nadat we hun nieuwe fitnesses berekend hebben,nagaan of de vooropgestelde looptijd verstreken is. Is dit niet zo, dan keren we terugnaar de selectiestap en doorlopen de cyclus een volgende keer.
Op dit moment zou de door ons gevolgde werkwijze in theorie duidelijk moeten zijn.Rest ons enkel nog dit in de praktijk om te zetten. We besloten om deze methodiekte gaan programmeren in het programma Matlab R©, versie 2010b. Dit omdat hetprogramma bekend staat om zijn vele toolboxen, waaronder ook een toolbox voorgenetische algoritmen. In deze toolbox konden we dan ook ideeen opdoen voor onzeeigen programmacode.
Als bijlage kan u de programmacode terugvinden. In volgend onderdeel zullen wetrachten de structuur en werkwijze van het programma te verduidelijken.
4.4 Matlab R©- programma
Opnieuw stellen we eerst een flowchart voor waarin de structuur van het door onsontworpen programma duidelijk wordt. Deze is weergegeven in figuur 4.4.
Het programma dat in het commandovenster opgeroepen wordt, is het programmaTestRun.m. Hierin wordt beslist welke datasets ingelezen worden vanuit de werkruimte.De gegevens ervan worden meegegeven in het Hoofdprogramma.m. Daarin wor-den voor elk probleem apart alle gegevens meegegeven in het programma Optimal-isatiecyclus.m, waarin zoals de titel het al zegt, voor een bepaalde tijd de optimal-isatiecyclus doorlopen wordt, de waarden voor de fitnesses bijgehouden worden endus verbeteringsstappen bekeken kunnen worden.
In ons grootste programma, niet toevallig Optimalisatiecyclus.m, vinden we volgendeprogramma’s terug: naast de at random generator voor de startpopulatie hebben weook het programma Schrage.m, dat uiteraard met de beschikbare taken de Schrage-oplossing als een van de initiele oplossingen genereert. Vervolgens starten we deeigenlijke cyclus, waarin we eerst de huidige fitnesses berekenen, door middel vanhet programma berekenfitness.m.

4.4. MATLAB R©- PROGRAMMA 39
Figure 4.4: Flowchart van het matlab R©programma
Daarna volgen de ondertussen al gekende stappen elkaar op in de programma’s dievolgende evidente titels hebben meegekregen: selecteer.m, brengvoort.m, muteer.m,immigreer.m. Het local search-algoritme (localsearch.m) ontvangt voor elk individuof voor elke taaksequentie uit de populatie de eindtijden van de individuele takenvia het programma berekeneindtijden.m. Tot slot volgen de programma-elementenberekenduplicatiepercentage.m en insert.m. Zij stellen de verschillende stappen voorin het GA, die kunnen voorkomen met hun respectievelijke kansen.
Als laatste controleren we of het stopcriterium, namelijk het aantal vooropgesteldeseconden dat het programma mag lopen, voldaan is en we houden de fitnesses bij inde daarvoor voorziene matrices.

4.5. CONCLUSIE 40
4.5 Conclusie
Nu de werking van de verschillende Matlab R©- subprogramma’s duidelijk is, kan erovergegaan worden tot het testen van het totale programma. We kunnen daarbij ooknagaan wat de invloed is van de verschillende parameters en zo een optimale werkingvan het programma voorstellen. Dit alles is het onderwerp van het volgende en laatstehoofdstuk.

5Evaluatie van het programma
5.1 Inleiding en doelstelling
In dit laatste hoofdstuk wordt het programma getest met behulp van de instancesuit de datageneratie (zie hoofdstuk 3). We onderzoeken de causale verbanden vande parameters op de werking van het programma. Hierbij beschouwen we zowelde werking van het programma als geheel maar ook van de individuele onderdelenvan het programma. Tot slot komen we tot enkele inzichten die toelaten om op deproductievloer betere beslissingen te nemen over het al dan niet batchen van bepaaldetaken.
5.2 Methode
Zoals vermeld in de inleiding worden de 1152 instances uit de datageneratie gebruiktom het programma met behulp van testruns te evalueren. Bij een industriele experi-mentele opzet zijn 3 essentiele karakteristieken van belang. Dit zijn
• replicatie: om nauwkeurigere schattingen te bekomen van de effecten.
• randomisatie: om de effecten van ongekende storingsfactoren uit te middelen.
• blocking: om gekende variabiliteit, waarvan we de invloed niet wensen tebeoordelen uit te sluiten.

5.3. RESULTATEN 42
Voor onze testruns kwamen we tegemoet aan de eisen van replicatie en randomisatiedoor elke instance driemaal door het algoritme te laten oplossen. Dergelijke replicatieis nuttig, aangezien zowel in de procedures van het genetische algoritme als in delocal search-procedure random effecten optreden. De maximale rekentijd werd opbasis van enkele testruns ingesteld op 60 seconden.
Tmax = 60s
Met betrekking tot blocking wensen we op te merken dat onze doordacht gekozendataset ons in staat stelde om voor elke parameter apart de invloed in te schatten.
Om de werking van de individuele operatoren in de local search procedure te be-studeren, werden improvementmatrices gecreeerd. In deze matrices werd voor alleinstances elke gevonden verbetering (verlaging van de maximale fitness) opgeslagensamen met het tijdstip waarop die welbepaalde verbetering werd gevonden. Omdatde verbeteringen werden gekoppeld aan de respectievelijke operatoren (randomizedswap, adjacent pairwise swap, etc.), werd een analyse van de werking van elk vandeze onderdelen mogelijk. Ook verbeteringen die een rechtstreeks gevolg waren vande cross-over of mutatie procedure werden opgeslagen.
5.3 Resultaten
In tabel 5.1 worden voor de gehele dataset de gemiddelde fitnesses en het gemiddeldaantal set-ups weergegeven voor verschillende instelparameters.
We kunnen volgende conclusies maken:
• Zowel de parameter k als q die verband houden met de due dates, hebben eenzeer beperkte invloed op het aantal set-ups.
• De grootte van de set-uptijden heeft logischerwijze een belangrijke invloedop de grootte van de gemiddelde fitness en uiteraard zullen er minder set-upsgebeuren wanneer de tijd die ervoor nodig is, zeer groot wordt.
• Zoals verwacht, neemt het gemiddeld aantal set-ups af bij een toenemend aan-tal taken per familie, F .
• Ook tussen de familiespreidingsfactor T en het gemiddeld aantal set-ups bestaateen positieve correlatie.
In tabel 5.2 worden voor de gehele dataset de verbeteringen van de verschillendeoperatoren samengevat.
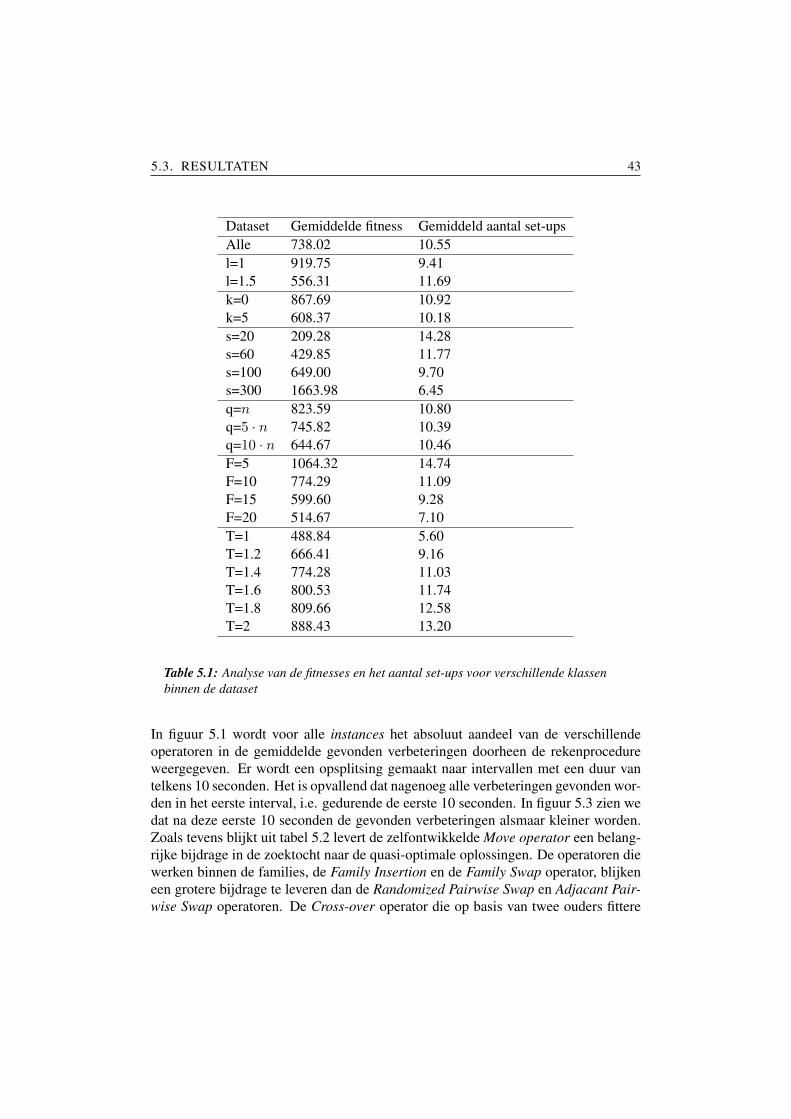
5.3. RESULTATEN 43
Dataset Gemiddelde fitness Gemiddeld aantal set-upsAlle 738.02 10.55l=1 919.75 9.41l=1.5 556.31 11.69k=0 867.69 10.92k=5 608.37 10.18s=20 209.28 14.28s=60 429.85 11.77s=100 649.00 9.70s=300 1663.98 6.45q=n 823.59 10.80q=5 · n 745.82 10.39q=10 · n 644.67 10.46F=5 1064.32 14.74F=10 774.29 11.09F=15 599.60 9.28F=20 514.67 7.10T=1 488.84 5.60T=1.2 666.41 9.16T=1.4 774.28 11.03T=1.6 800.53 11.74T=1.8 809.66 12.58T=2 888.43 13.20
Table 5.1: Analyse van de fitnesses en het aantal set-ups voor verschillende klassenbinnen de dataset
In figuur 5.1 wordt voor alle instances het absoluut aandeel van de verschillendeoperatoren in de gemiddelde gevonden verbeteringen doorheen de rekenprocedureweergegeven. Er wordt een opsplitsing gemaakt naar intervallen met een duur vantelkens 10 seconden. Het is opvallend dat nagenoeg alle verbeteringen gevonden wor-den in het eerste interval, i.e. gedurende de eerste 10 seconden. In figuur 5.3 zien wedat na deze eerste 10 seconden de gevonden verbeteringen alsmaar kleiner worden.Zoals tevens blijkt uit tabel 5.2 levert de zelfontwikkelde Move operator een belang-rijke bijdrage in de zoektocht naar de quasi-optimale oplossingen. De operatoren diewerken binnen de families, de Family Insertion en de Family Swap operator, blijkeneen grotere bijdrage te leveren dan de Randomized Pairwise Swap en Adjacant Pair-wise Swap operatoren. De Cross-over operator die op basis van twee ouders fittere

5.3. RESULTATEN 44
Dataset CrossO. Mut. RP.Swap AP.Swap Fam.Swap Fam.Ins. Move O.Alle 33.37 1.47 123.48 57.43 83.84 145.87 311.75l=1 34.23 1.73 116.04 53.83 91.39 149.91 303.16l=1.5 32.51 1.20 130.91 61.02 76.28 141.84 320.32k=0 35.75 1.27 123.18 57.29 84.85 148.92 332.63k=5 31.00 1.67 123.77 57.56 82.82 142.83 290.86s=20 8.78 0.37 46.76 21.75 36.59 54.02 114.76s=60 29.46 2.50 121.46 56.49 72.47 132.51 265.32s=100 42.81 2.15 169.16 78.68 106.84 185.25 369.49s=300 52.45 0.84 156.52 72.80 119.44 211.72 497.41q=n 29.64 1.69 130.15 60.53 93.23 147.02 328.57q=5 · n 36.78 1.69 116.48 54.17 78.79 132.96 315.92q=10 · n 33.70 0.94 123.79 57.57 79.48 157.64 290.74F=5 26.67 0.84 101.09 47.02 64.77 140.89 322.51F=10 30.75 0.90 135.80 63.16 96.26 157.98 316.75F=15 42.52 2.32 151.01 70.23 96.70 167.96 335.36F=20 41.07 2.80 140.10 65.16 101.31 147.07 367.18T=1 14.23 0.02 42.07 19.57 68.90 58.59 133.79T=1.2 36.80 0.93 80.99 37.67 56.91 115.12 235.09T=1.4 31.14 3.17 138.43 64.38 80.76 136.60 338.43T=1.6 36.60 1.22 162.99 75.81 89.38 177.96 375.92T=1.8 46.56 1.97 180.46 83.93 115.47 204.55 422.92T=2 41.70 3.02 187.27 87.10 124.74 223.64 485.84
Table 5.2: Analyse van de verschillende local search operatoren (Randomized PairwiseSwap, Adjacant Pairwise Swap, Family Swap, Family Insertion en Move Operator) ende rechtstreekse verbeteringen volgend uit Cross-over en Mutatie. Elke gevondenverbetering (effectieve verlaging van de minimale Lmax in de populatie) werdbewaard in afzonderlijke improvementmatrices
kinderen tracht te genereren, slaagt hier ook regelmatig in. Tot slot merken we opdat de Mutatie operator naast het creeren van diversiteit in de populatie quasi geenrechtreekse bijdrage heeft in de zoektocht naar de laagste maximum lateness.
Voor de duidelijkheid worden in figuur 5.2 de verbeteringen die optraden na de eerste10 seconden in close-up genomen, terwijl in figuur 5.4 de verbeteringen gedurendede eerste 5 seconden worden beschouwd. Opnieuw wordt het gemiddelde van dehele dataset genomen. De Move operator levert ook hier de belangrijkste bijdrage.

5.3. RESULTATEN 45
De invloeden van de andere operatoren lijken allen op een gelijkaardige manier af tenemen. Een gedetailleerder beeld volgt in figuur 5.5 waar de relatieve aandelen vande verschillende operatoren over de tijdsintervallen worden weergegeven. Hieruitbijkt dat de Move operator aan relatief belang wint. Het relatief belang van de andereoperatoren neemt zoals reeds vermoed op gelijke wijze af.
Figure 5.1: Alle Instances, absoluut aandeel van de verschillende operatoren in degemiddelde gevonden verbeteringen doorheen de rekenprocedure
In figuur 5.6, respectievelijk figuur 5.7 worden de resultaten afkomstig van instancesmet set-uptijden gelijk aan 20, respectievelijk 300, afgezonderd. Bij de instances metset-uptijden gelijk aan 20 wint de Move Operator uitdrukkelijk aan relatief belanggedurende de rekenprocedure. Bij de instances met set-uptijden gelijk aan 300 is diteffect minder nadrukkelijk aanwezig.
In figuur 5.8 worden voor verschillende familiegroottes de absoluut aandelen van deverschillende operatoren in de gemiddelde verbeteringen weergegeven. De invloedvan het aantal taken per familie op het relatief aandeel van de operatoren blijkt relatiefbeperkt. Wel stellen we vast dat een groter aantal taken per familie het totale bedragaan verbeteringen doet toenemen. Voor deze instances ligt de maximum lateness vanonze beide zelf aangebrachte startoplossingen verder van de optimale oplossing.

5.4. PRAKTISCHE BESLUITTREKKINGEN UIT DE TESTRUNS 46
Figure 5.2: Alle Instances, absoluut aandeel van de verschillende operatoren in degemiddelde gevonden verbeteringen doorheen de rekenprocedure, na de eerste 10seconden
5.4 Praktische besluittrekkingen uit de testruns
In het laatste deel van dit hoofdstuk zullen we trachten conclusies te trekken die inpraktische omstandigheden gebruikt kunnen worden. Daartoe bekijken we de resul-taten van verschillende instelwaarden voor de parameters uit tabel 5.2. We zullen inverschillende gevallen hun prestaties vergelijken aan de hand van een nieuwe perfor-mantiemaat, namelijk de ”batching scoringsmaat”.
Voor een bepaalde groep van instances definieren we deze maat als het percentageinstances waarvoor de optimale oplossing gegeven wordt door die oplossing met hetminimum aantal set-ups. Logischerwijze is dit de oplossing die alle taken van een-zelfde familie groepeert. Aangezien we het aantal set-ups van een gegeven oplossingenkel vergelijken met dit absolute minimum, is deze maat behoorlijk streng. Kleineafwijkingen, bijvoorbeeld oplossingen met 1 set-up meer, worden immers niet tot deoptimale groep gerekend terwijl ze er wel zeer dicht bij aanleunen. We moeten echterergens een lijn trekken; percentages groter dan 30% zullen bij onze berekening dusal sterk in het voordeel van batching spreken. Een hoog percentage zal steeds eensterke indicatie vormen voor batchen, ook al houdt dit niet systematisch in dat alletaken van dezelfde familie moeten worden gegroepeerd.

5.4. PRAKTISCHE BESLUITTREKKINGEN UIT DE TESTRUNS 47
Figure 5.3: Cumulatieve curve van het gemiddelde van alle verbeteringen. Dewaarden na 60 seconden rekentijd werden als 100% ingesteld.
Figure 5.4: Absoluut aandeel van de verschillende operatoren in de gemiddeldegevonden verbeteringen gedurende de eerste 5 seconden van de rekenprocedure
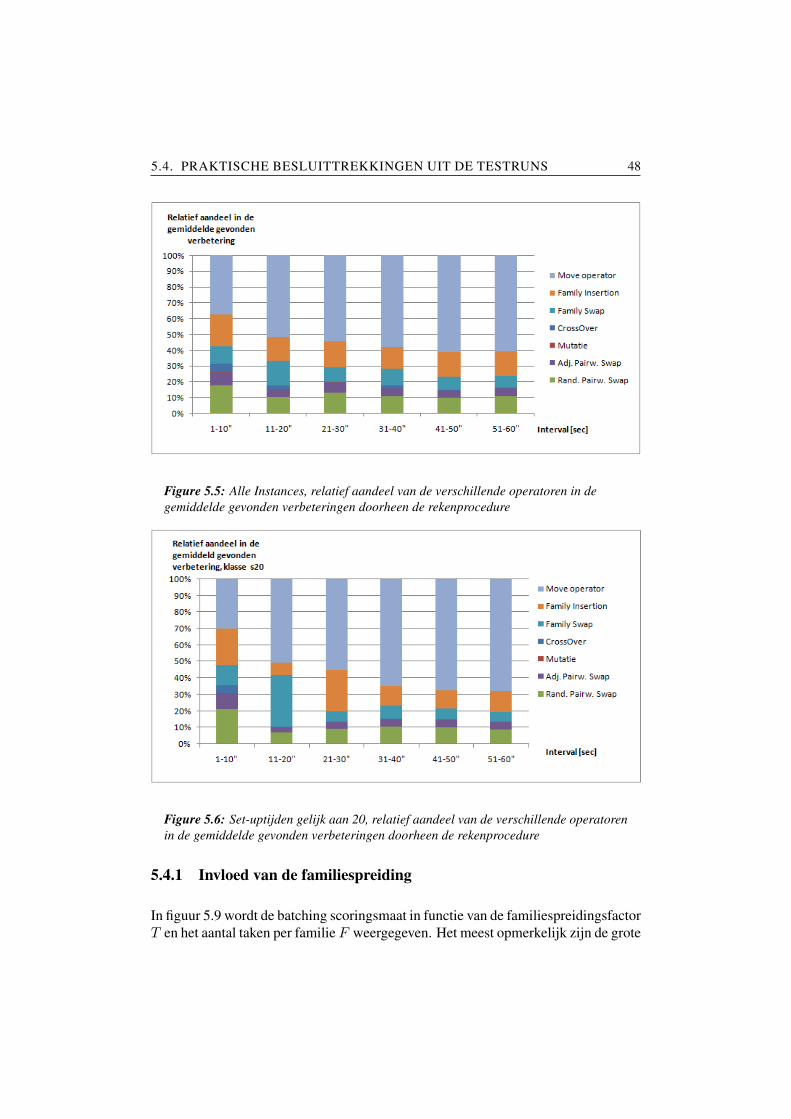
5.4. PRAKTISCHE BESLUITTREKKINGEN UIT DE TESTRUNS 48
Figure 5.5: Alle Instances, relatief aandeel van de verschillende operatoren in degemiddelde gevonden verbeteringen doorheen de rekenprocedure
Figure 5.6: Set-uptijden gelijk aan 20, relatief aandeel van de verschillende operatorenin de gemiddelde gevonden verbeteringen doorheen de rekenprocedure
5.4.1 Invloed van de familiespreiding
In figuur 5.9 wordt de batching scoringsmaat in functie van de familiespreidingsfactorT en het aantal taken per familie F weergegeven. Het meest opmerkelijk zijn de grote

5.4. PRAKTISCHE BESLUITTREKKINGEN UIT DE TESTRUNS 49
Figure 5.7: Set-uptijden gelijk aan 300, relatief aandeel van de verschillendeoperatoren in de gemiddelde gevonden verbeteringen doorheen de rekenprocedure
Figure 5.8: Verschillende familiegroottes, absoluut aandeel van de verschillendeoperatoren in de gemiddelde gevonden verbeteringen gedurende de eerste 10 secondenvan de rekenprocedure
percentages voor de waarde T = 1. Ook voor T = 1.2 blijkt het volledig batchenvan taken van dezelfde familie sterk aangewezen. Voor grotere spreidingen neemt deneiging tot batchen sterk af. Enkel voor kleine families (F = 5) blijft de drang totbatching bestaan.

5.4. PRAKTISCHE BESLUITTREKKINGEN UIT DE TESTRUNS 50
Figure 5.9: Batching scoringsmaat in functie van de familiespreidingsfactor T en hetaantal taken per familie F
5.4.2 Invloed van de set-uptijden
In figuur 5.10 wordt de batching scoringsmaat in functie van de grootte van de set-uptijden S en de familiegrootte F weergegeven. Voor set-uptijden kleiner dan of inde grootteorde van de procestijden blijft de drang tot groeperen van alle taken vandezelfde familie beperkt. Hoe groter de set-uptijden, hoe meer aangewezen batchingwordt. Opmerkelijk is de grote sprong, vooral voor kleinere families waarbij het dusduidelijk wordt dat batching cruciale verbeteringen met zich meebrengt.
5.4.3 Invloed van releasetijden en due dates
Laat ons eerst kijken naar de releasetijden aan de hand van de parameter l, een indi-catie voor de spreiding van de releasetijden. Zoals reeds in hoofdstuk 3 besproken,zal l = 1 de situatie illustreren waarbij releasetijden zeer dicht op elkaar volgenterwijl l = 1.5 aangeeft dat releasetijden verder uit elkaar liggen. In figuur 5.11wordt de batching scoringsmaat in functie van de grootte van de set-uptijden S en dereleasetijd-factor l weergegeven.
We krijgen hier een opmerkelijk resultaat. We zien namelijk dat in functie van degrootte van de set-uptijden de drang tot batching verspringt tussen beide gevallen.

5.4. PRAKTISCHE BESLUITTREKKINGEN UIT DE TESTRUNS 51
Figure 5.10: Batching scoringsmaat in functie van de grootte van de set-uptijden S ende familiegrootte F
Figure 5.11: Batching scoringsmaat in functie van de grootte van de set-uptijden S ende releasetijd-factor l
Voor kleine set-uptijden is de drang groter bij sterk gespreide releasetijden, terwijlbatching aan belang wint bij grotere set-uptijden voor nauw aansluitende release-tijden. We mogen ons echter niet blindstaren op dit fenomeen; het is namelijk zo dat

5.5. CONCLUSIE 52
de neiging tot batching in alle gevallen toeneemt met een groter wordende set-uptijd.
Wanneer we de invloed onderzoeken van de spreiding van de due dates, kunnen wereeds uit tabel 5.2 vermoeden dat deze bij onze datasets weinig invloed zal hebben opde scoringsmaat, zoals we merken aan de waarden van parameters k en q. Inderdaad,we kunnen dit beredeneren uit de manier waarop de due dates worden gegenereerd.Zij worden uniform getrokken uit het interval [rj + k · pj , rj + k · pj + q en zijnbijgevolg afhankelijk van de releasetijden. Een toename van de parameter k of q zorgtervoor dat globaal gezien alle due dates verlaten. We vermoeden dat deze verlatingvrij gelijkmatig gebeurt en dus slechts een beperkte invloed heeft op de maximumlateness.
5.5 Conclusie
In dit laatste hoofdstuk werd het programma getest met behulp van de instances uitde datageneratie (zie hoofdstuk 3). De causale verbanden van de verschillende para-meters op de werking van het programma werden onderzocht alsook hun invloed ophet advies om alle taken van dezelfde familie te batchen. De belangrijkste parametersbleken zoals verwacht de grootte van de set-uptijden s, het aantal taken per familieF en de familiespreidingsfactor T te zijn. Aan het eind van het hoofdstuk kwamenwe tot enkele inzichten die toelaten om op de productievloer betere beslissingen tenemen over het al dan niet batchen van bepaalde taken.

6Conclusie
In de loop van deze masterproef maakten we kennis met de verschillende begrip-pen en problemen aangaande een belangrijke hindernis binnen diverse takken van deproductiesector, met name het Single Machine Scheduling probleem. Dit kan eenbelangrijk punt zijn wanneer verschillende taken door dezelfde cruciale machine be-werkt of verwerkt moeten worden. Dit kunnen taken zijn van allerhande soorten, dieelk op verschillende momenten beschikbaar worden, elk een eigen proces- of ver-werkingstijd hebben en allen op een bepaald tijdstip afgewerkt moeten zijn. Doordie verscheidene taken op de meest optimale manier in te plannen op die speci-fieke machine, ontstaat een productieschema in de populaire voorstellingsvorm vaneen Gantt-chart. Die rangschikking kan gebeuren op basis van verschillende per-formantiematen; wij kozen er echter voor om de maximum lateness, Lmax, te gaanminimaliseren.
Na voldoende geıntroduceerd te zijn in de bestaande terminologie omtrent het pro-bleem, deden we onderzoek naar de verschillende modellen en verwoordingen diebestonden in het domein van het probleem. We beschouwden de evolutie van diemodellen van de meest eenvoudige, oorspronkelijke vorm tot de meest uitgebreide,die verschillende gevallen combineert. Een duidelijk en kort overzicht is te vinden intabel 6.1.
Aan de hand van deze modellen kregen we meer inzicht in de problematiek en kondenwe een keuze maken aangaande welk probleem we wilden aanpakken. We kozen er

54
Model Specificaties Oplossingsmogelijkheden1||Lmax Basis: Procestijden, Due dates Exact oplosbaar
bv. ”Earliest Due Date”-regel1|prec|Lmax Basis + voorrangsregels Exact oplosbaar1|rj |Lmax Basis + release tijden NP-hard
uitzonderlijk wel exact oplosbaarbv. Schrage-algoritme
1|sij |Lmax Basis + set-up tijden NP-hardEDD-regel binnen families
1|prec, sij |Lmax Basis + set-up tijden NP-hard+ voorrangsregels Branch-and-bound algoritmen
1|rj , sij |Lmax Basis + set-up tijden NP-hard+ release tijden Heuristieken en metaheuristieken
Table 6.1: Overzicht verschillende SMS-modellen met hun specificaties enoplossingsmogelijkheden
dan voor het 1|rj , sij |Lmax - probleem verder te onderzoeken, bouwend op een papervan Sels and Vanhoucke (2009) [36].
Na het ontwikkelen van een weldoordachte manier van datageneratie stelden weeen theoretisch model op dat ervoor moest zorgen dat er een oplossing gevondenwerd voor ons probleem. Het scheen echter onontbeerlijk te zijn dit model ookin de praktijk te gaan testen. Dit was dan ook de drijfveer om via het software-programma Matlab R©een gloednieuw programma te gaan ontwikkelen, dat gebaseerdis op genetische algoritmen en zo op iteratieve wijze een optimalisatiecyclus door-loopt. Een local search procedure werd opgezet gebruik makende van 5 verschillendeoperatoren:
• twee operatoren die op de globale taaksequentie naar verbeteringen zoeken(Random Pairwise Swap en Adjacant Pairwise Swap),
• twee operatoren die binnen de taakfamilies opereren (Family Swap en FamilyInsertion)
• en tot slotte een zelf ontwikkelde operator die de maximum lateness op eengerichte manier tracht te verlagen door individuele taken te verplaatsen , deMove Operator.
Op deze metaheuristische manier kwamen we in verscheidene gevallen tot een (sub)-optimale oplossing voor ons probleem.

55
In het laatste hoofdstuk werd ons programma getest op basis van de gegenereerdedata. De invloed van de verschillende parameters werd onderzocht en enkele prak-tische besluiten werden meegegeven. Het ontworpen algoritme bleek in staat omaanzienlijke verbeteringen te vinden ten opzichte van twee uiterste startoplossingen,enerzijds de ”EDD”-sequentie en anderzijds de sequentie die de taken volgens fa-milie samenneemt. Elke operator die in de local searchprocedure werd geımple-menteerd bleek efficient te werken; de zelfontworpen Move Operator in het bijzon-der. Een batchingscoringsmaat werd geıntroduceerd. Deze coefficient geeft voorverschillende waarden van de instelparameters de mate aan waarin alle taken vandezelfde familie worden gebatcht. De invloed van de meest bepalende parameters (degrootte van de set-uptijden, de familiespreiding, het aantal taken per familie etc.) opdeze batchingscoringsmaat tenslotte werd weergegeven in overzichtelijke grafieken(figuren 5.9,5.10 en 5.11). Bedrijfsbeslissingen kunnen getoetst worden aan dezebekomen besluiten om efficientere en economischere processen op te zetten.
Wil iemand bijvoorbeeld gebruik maken van andere technieken zoals Simulated An-nealing, Ant Colony Optimalization of andere (meta)heuristische methoden, dan kun-nen die bekomen resultaten getoetst worden aan onze uitkomsten.
Als afsluiter van deze masterproef kunnen we enkel de hoop koesteren dat u, delezer, iets gehad heeft aan de naar onze mening interessante materie die we naar voorhebben gebracht. Daarnaast kunnen we enkel wensen dat u iets wijzer geworden bentvan onze nieuwe aanpak omtrent het gestelde probleem en zo gemotiveerd geraaktbent om meer te ontdekken binnen deze leerstof, net zoals wij waren aan het beginvan dit avontuur. . .
”An economist is an expert who will know tomorrow why the things hepredicted yesterday didn’t happen today”
-Laurence J. Peter-

List of Figures
1.1 Gantt-chart . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.1 Voorbeeld ter verduidelijking van de earliest due date regel: schema 72.2 Voorbeeld ter verduidelijking van het principe van de voorrangsregels:
schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3 Voorbeeld ter verduidelijking van de earliest due date regel bij taken
met releasetijd: schema . . . . . . . . . . . . . . . . . . . . . . . . 102.4 Voorbeeld schema: familie en set-uptijden . . . . . . . . . . . . . . 12
3.1 Cumulatieve distributie van de interarrivaltimes - een vergelijkingtussen verschillende datageneratiemethodes. In de grafiek is de pois-sondistributie weergegeven met gemiddelde waarde 50. Een dergeli-jke distributie wordt gebruikt door Schutten [34]. Voor de distributiesvan Ovacik werd een herschaling doorgevoerd zodat de arrivaltimesuniform werden gekozen in het interval [0, R · n · 50] . . . . . . . . 21
3.2 Stap in het toewijzingsalgoritme van de verschillende familieindices.In het voorbeeld is het aantal taken per familie Nf = 10 en is defamiliespreidingsparameter T = 1.5. De tien indices voor de eerstefamilie zijn reeds toegekend en op de figuur wordt de 2e index voorde tweede familie toegewezen aan de taak op de 7e positie in de rijvan beschikbare taken. . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1 Flowchartdiagramma van het programma . . . . . . . . . . . . . . 304.2 Illustratie van het cross-overmechanisme . . . . . . . . . . . . . . . 324.3 Illustratie van de Intelligent move operator, taak j wordt ingevoegd
na taak k. In het gunstige geval vervroegen de tijdstippen waarop detaken j + 1 tot k aanvatten. . . . . . . . . . . . . . . . . . . . . . . 34
4.4 Flowchart van het matlab R©programma . . . . . . . . . . . . . . . 39
5.1 Alle Instances, absoluut aandeel van de verschillende operatoren inde gemiddelde gevonden verbeteringen doorheen de rekenprocedure 45

LIST OF FIGURES 57
5.2 Alle Instances, absoluut aandeel van de verschillende operatoren inde gemiddelde gevonden verbeteringen doorheen de rekenprocedure,na de eerste 10 seconden . . . . . . . . . . . . . . . . . . . . . . . 46
5.3 Cumulatieve curve van het gemiddelde van alle verbeteringen. Dewaarden na 60 seconden rekentijd werden als 100% ingesteld. . . . 47
5.4 Absoluut aandeel van de verschillende operatoren in de gemiddeldegevonden verbeteringen gedurende de eerste 5 seconden van de reken-procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.5 Alle Instances, relatief aandeel van de verschillende operatoren in degemiddelde gevonden verbeteringen doorheen de rekenprocedure . . 48
5.6 Set-uptijden gelijk aan 20, relatief aandeel van de verschillende oper-atoren in de gemiddelde gevonden verbeteringen doorheen de reken-procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.7 Set-uptijden gelijk aan 300, relatief aandeel van de verschillendeoperatoren in de gemiddelde gevonden verbeteringen doorheen derekenprocedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.8 Verschillende familiegroottes, absoluut aandeel van de verschillendeoperatoren in de gemiddelde gevonden verbeteringen gedurende deeerste 10 seconden van de rekenprocedure . . . . . . . . . . . . . . 49
5.9 Batching scoringsmaat in functie van de familiespreidingsfactor T enhet aantal taken per familie F . . . . . . . . . . . . . . . . . . . . . 50
5.10 Batching scoringsmaat in functie van de grootte van de set-uptijdenS en de familiegrootte F . . . . . . . . . . . . . . . . . . . . . . . 51
5.11 Batching scoringsmaat in functie van de grootte van de set-uptijdenS en de releasetijd-factor l . . . . . . . . . . . . . . . . . . . . . . 51

List of Tables
2.1 Data horende bij het voorbeeld ter verduidelijking van de earliest duedate regel. Elke taak wordt gekenmerkt door een eigen taaknummer,benodigde procestijd pj en due date dj . . . . . . . . . . . . . . . . 7
2.2 Data horende bij het voorbeeld ter verduidelijking van de earliest duedate regel bij taken met releasetijd rj . Elke taak wordt gekenmerktdoor een eigen taaknummer, een benodigde procestijd pj , een due-date dj en een tijdstip waarop de taak vrij komt rj . . . . . . . . . . 9
2.3 Voorbeeld - Taakdata: Elke taak wordt gekenmerkt door een eigentaaknummer, een benodigde procestijd pj , een due date dj en eenfamilie F waar zij toe behoren . . . . . . . . . . . . . . . . . . . . 11
2.4 Voorbeeld - Set-uptijden: Wanneer twee taken van een verschillendefamilie na elkaar worden gepland, dan is er een set-uptijd vereist . . 12
3.1 Parameters van de instances . . . . . . . . . . . . . . . . . . . . . 25
4.1 Steekproef voor het onderzoek naar de 3 varianten van de voorgesteldeintelligent move operator: onderzochte klasse . . . . . . . . . . . . 37
4.2 Resultaten van het steekproefonderzoek met betrekking tot de 3 vari-anten van de intelligent move operator . . . . . . . . . . . . . . . . 37
5.1 Analyse van de fitnesses en het aantal set-ups voor verschillendeklassen binnen de dataset . . . . . . . . . . . . . . . . . . . . . . . 43
5.2 Analyse van de verschillende local search operatoren (RandomizedPairwise Swap, Adjacant Pairwise Swap, Family Swap, Family Inser-tion en Move Operator) en de rechtstreekse verbeteringen volgend uitCross-over en Mutatie. Elke gevonden verbetering (effectieve verlag-ing van de minimale Lmax in de populatie) werd bewaard in afzon-derlijke improvementmatrices . . . . . . . . . . . . . . . . . . . 44
6.1 Overzicht verschillende SMS-modellen met hun specificaties en oploss-ingsmogelijkheden . . . . . . . . . . . . . . . . . . . . . . . . . . 54

References
[1] J.Y. Liu and L.X. Tang. A modified genetic algorithm for single machinescheduling. Computers and industrial engineering, 37:43–46, 1999.
[2] Khowala K. Keha, A.B. and J.W. Fowler. Mixed integer programming formula-tions for single machine scheduling problems. Computers and Industrial engi-neering, 56:357–367, 2009.
[3] E.L. Lawler, J.K. Lenstra, A.H.G. Rinnooy Kan, and D.B. Shmoys. Sequenc-ing and Scheduling: Algorithms and Complexity. Logistics of production andinventory, 9, 1993.
[4] J.R. Jackson. Scheduling a production line to minimize maximum tardiness.Management Science Research Project, UCLA, Los Angeles, Research Report43, 1955.
[5] M. Leung, J.Y.T.and Pinedo. A note on scheduling parallel machines subject tobreakdown and repair. Naval research logistics, 51:60–71, 2004.
[6] M.R. Garey and D.S. Johnson. Computers and Intractability: A Guide to theTheory of NP Completeness. San Franciso: W.H. Freeman, 1979.
[7] L. Schrage. Obtaining optimal solutions to resource constrained networkscheduling problems. 1971.
[8] J. Carlier. The One-Machine sequencing problem. European journal of opera-tional research, 11:42–47, 1982.
[9] K.R. Baker and Z.S. Su. Sequencing with due dates and early start times tominimize maximum tardiness. Naval Research Logistics Quarterly, 21:171–176,1974.
[10] M. Bratley, P.and Florian and P. Robillard. Scheduling with earliest start anddue date constraints on multiple machines. Naval reasearch logistics, 22:165–173, 1975.

REFERENCES 60
[11] G. McMahon and M. Florian. Scheduling with ready times and due dates to min-imize maximum lateness. European Journal of operational research, 120:228–249, 2000.
[12] J.K. Lageweg, B.J.and Lenstra and A.H.G. Rinnooykan. Minimizing maximumlateness on one machine: algorithms and applications. Combinatorial opti-mization, 1979:371–425, 1976.
[13] M.I. Larson, R.E.and Dessouky and R.E. Devor. A forward-backward proce-dure for the single-machine problem to minimize maximum lateness. IIE Trans-actions, 17:252–260, 1985.
[14] J. Grabowski, E. Nowicki, and S. Zdrzalka. A block approach for single-machine scheduling with release dates and due dates. European Journal ofoperational research, 26:278–285, 1986.
[15] E. Nowicki and S. Zdrzalka. A note on minimizing maximum lateness in aone-machine sequencing problem with release dates. European Journal of op-erational research, 23:266–267, 1986.
[16] E. Balas, J.K. Lenstra, and A. Vazacopoulos. The one-machine problem with de-layed precedence constraints and its use in job-shop scheduling. ManagementScience, 41:94–109, 1995.
[17] P.C. Chang and L.H. Su. Scheduling n jobs on one machine to minimize themaximum lateness with a minimum number of tardy jobs. Computers and in-dustrial engineering, 40:349–360, 2001.
[18] Y.P. Pan and L.Y. Shi. Branch-and-bound algorithms for solving hard instancesof the one-machine sequencing problem. European Journal of operational re-search, 168:1030–1039, 2006.
[19] H. Kise, T. Ibaraki, and H. Mine. Performance analysis of 6 approximation al-gorithms for the one-machine maximum lateness scheduling problem with readytimes. Journal of the operations research society of Japan, 22:205–224, 1979.
[20] C.N. Potts. Analysis of a heuristic for one machine sequencing with releasedates and delivery times. Operations research, 28:1436–1441, 1980.
[21] L.A. Hall and D.B. Shmoys. Jackson rule for single-machine scheduling - mak-ing a good heuristic better. Mathematics of Operations research, 17:22–35,1992.
[22] E. Nowicki and C. Smutnicki. An approximation algorithm for a single-machinescheduling problem with release times and delivery times. Discrete appliedmathematics, 48:69–79, 1994.

REFERENCES 61
[23] C.L. Monma and C.N. Potts. On the complexity of scheduling with batch setuptimes. Operations Research, 37:798–804, 1989.
[24] C.N. Potts. Scheduling 2 job classes on a single machine. European Journal ofoperational research, 18:411–415, 1991.
[25] R. Uzsoy, L.A. Martinvega, and C.Y. Lee. Production scheduling algorithmsfor a semiconductor test facility. IEE Transactions on semiconductor manufac-turing, 4:270–280, 1991.
[26] A.M.A. Hariri and C.N. Potts. Single machine scheduling with batch set-uptimes to minimize maximum lateness. Annals of Operations Research, 70:75–92, 1997.
[27] Potts C.N. Crauwels, H.A.J. and L.N. VanWassenhove. Local search heuristicsfor single-machine scheduling with batching to minimize the number of latejobs. European Journal of operational research, 90:200–213, 1996.
[28] S. Webster and K.R. Baker. Scheduling groups of jobs on a single machine.Operations research, 43:692–703, 1995.
[29] R. Uzsoy and J.D. Velsquez. Heuristics for minimizing maximum lateness on asingle machine with family-dependent set-up times. Computer and operationsresearch, 35:2018–2033, 2006.
[30] A. Allahverdi, J.N.D. Gupta, and T. Aldowaisan. A review of scheduling re-search involving setup considerations. Omega, 27:219–239, 1999.
[31] C.N. Potts and M.Y. Kovalyov. Scheduling with batching: A review. EuropeanJournal of operational research, 120:228–249, 2000.
[32] M. Ovacik and R. Uzsoy. Rolling horizon heuristics for a single-machine dy-namic scheduling problem with sequence-dependent setup times. InternationalJournal of production research, 32:1243–1263, 1994.
[33] S. Zdrzalka. Analysis of approximation algorithms for single-machine schedul-ing with delivery times and sequence independent batch setup times. EuropeanJournal of operational research, 80:371–380, 1995.
[34] J.M.J. Schutten, S.L. Van de Velde, and W.H.M. Zijm. Single-Machine Schedul-ing with release dates, due dates and family setup times. Management Science,42:1165–1174, 1996.
[35] H.J. Shin, C.O. Kim, and S.S. Kim. A tabu search algorithm for single ma-chine scheduling with release times, due dates, and sequence-dependent set-up

REFERENCES 62
times. International Journal of advanced manufacturing technology, 19:859–866, 2002.
[36] V. Sels and M. Vanhoucke. A genetic algorithm for the single machine maximumlateness problem. 2009.
[37] P.A. Rubin and G.L. Ragatz. Scheduling in a sequence dependent setup envi-ronment with genetic search. Computers and operations research, 22:85–99,1995.
[38] K.C. Tan, R. Narasimhan, and P.A. Rubin. A comparison of four methods forminimizing total tardiness on a single processor with sequence dependent setuptimes. Omega, 28:313–326, 2000.
[39] V.A. Armentano and R. Mazzini. A genetic algorithm for scheduling on a singlemachine with set-up times and due dates. Production planning and control,11:713–720, 2000.
[40] S.G. Koh, P.H. Koo, and D.C. Kim. Scheduling a single batch processing ma-chine with arbitrary job sizes and incompatible job families. International Jour-nal of production economics, 98:81–96, 2005.
[41] A.H. Kashan, B. Karimi, and F. Jolai. Effective hybrid genetic algorithm forminimizing makespan on a single-batch-processing machine with non-identicaljob sizes. International journal of production research, 44:2337–2360, 2006.
[42] Manjeshwar P.K. Damodaran, P. and K. Srihari. Minimizing makespan on abatch-processing machine with non-identical job sizes using genetic algorithms.International Journal of production economics, 103:882–891, 2006.
[43] F.D. Chou, P.C. Chang, and H.M. Wang. A hybrid genetic algorithm to minimizemakespan for the single batch machine dynamic scheduling problem. Interna-tional Journal of advanced manufacturing technology, 31:350–359, 2006.
[44] N. Hayat and A. Wirth. Genetic algorithms and machine scheduling with classsetups. International Journal of Computer and Engineering Management, 5:10–23, 1997.
[45] C.S. Wang and R. Uzsoy. A genetic algorithm to minimize maximum latenesson a batch processing machine. Computers and operations research, 29:1621–1640, 2002.
[46] R.B. Kethley and B. Alidaee. Single machine scheduling to minimize totalweighted late work: a comparison of scheduling rules and search algorithms.Computers and industrial engineering, 43:509–528, 2002.

REFERENCES 63
[47] M. Sevaux and S. Dauzere-Peres. Genetic algorithms to minimize the weightednumber of late jobs on a single machine. European Journal of operational re-search, 151:296–306, 2003.
[48] S.W. Lin and K.C. Ying. Solving single-machine total weighted tardiness pro-blems with sequence-dependent setup times by meta-heuristics. InternationalJournal of advanced manufacturing technology, 34:1183–1190, 2007.
[49] J.C. Hsieh, P.C. Chang, and S.H. Chen. Genetic local search algorithms forsingle machine scheduling problems with release time. Knowledge Enterprise:Intelligent Strategies in Product Design, Manufacturing, and Management Eu-ropean Journal of operational research, 207:875–880, 2006.
[50] N.G. Hall and M.E. Posner. Generating experimental data for scheduling pro-blems. manuscript, Ohio State University, 1996.
[51] K.R. Baker. Heuristic procedures for scheduling job families with setups anddue dates. Naval Research Logistics, 46:978–991, 1999.
[52] F. Jin, S. Song, and C. Wu. A simulated annealing algorithm for single machinescheduling problems with family setups. Computers and Operations Research,36:2133–2138, 2009.

.1. APPENDIX 64
.1 Appendix
1. Testrun.m
2. Optimalisatiecyclus.m
3. Hoofdprogramma.m
4. Schrage.m
5. FamilyRank.m
6. Berekenfitness.m
7. Berekenduplicatiepercentage.m
8. Selecteer.m
9. Brengvoort.m
10. Muteer.m
11. Immigreer.m
12. Berekeneindtijden.m
13. Localsearch.m
14. Insert.m

1.Testrun.m
2. Optimalisatiecyclus.m
3. Hoofdprogramma.m
4. Schrage.m
5. FamilyRank.m
6. Berekenfitness.m
7. Berekenduplicatiepercentage.m
8. Selecteer.m
9. Brengvoort.m
10. Muteer.m
11. Immigreer.m
12. Berekeneindtijden.m
13. Localsearch.m
14. Insert.m
1. Testrun.m TestDataFitnesses=[]; TestDataNsetups=[]; CalcTimePerInstance=20; tGlobalStart=tic; TimeNeeded=1*CalcTimePerInstance*size(AllDataMatrices_n50l1k5q5_famsf,3)*1; %Test instances with setuptimes 20,60,100 and 300 for SetupTimeValue=[60] TimeNow=toc(tGlobalStart); disp(['Time elapsed: ',num2str(TimeNow),' from ',num2str(TimeNeeded)]); [fitnesses,~,allnsetups,improvementmatrices_n50l1k5q5_famsf_60] = Optimalisatiecyclus(AllDataMatrices_n50l1k5q5_famsf,AllSetupTimes_n50l1k5q5_famsf,SetupTimeValue,CalcTimePerInstance,tGlobalStart,TimeNeeded); TestDataFitnesses=[TestDataFitnesses fitnesses] TestDataNsetups=[TestDataNsetups allnsetups] end
2. Optimalisatiecyclus.m
function [fitnesses,instances,allnsetups,improvementmatrices] = Optimalisatiecyclus(DataMatrix,SetupTimes,SetupTimeValue,CalcTimePerInstance,tGlobalStart,TimeNeeded) fitnesses=[]; allnsetups=[]; instances=[]; improvementmatrices=[]; for k=1:size(SetupTimes,3) SetupTimes(:,:,k)=SetupTimeValue*(SetupTimes(:,:,k)~=0); end tStart=tic; for i=1:size(DataMatrix,3) pos=i; Data = DataMatrix(:,:,pos); Setup = SetupTimes(:,:,pos); [~,fit,~,nsetups,improvementmatrix] =Hoofdprogramma(Data,Setup,CalcTimePerInstance);

fitnesses = [fitnesses; fit]; allnsetups=[allnsetups; nsetups]; improvementmatrices(1:size(improvementmatrix,1),1:size(improvementmatrix,2),i)=improvementmatrix; TimeNow=toc(tGlobalStart); disp(['Time elapsed: ',num2str(TimeNow),' from ',num2str(TimeNeeded)]); end fitnesses; end
3. Hoofdprogramma.m
function [besteoplossing,fit,lb,nsetups,improvementmatrix] = Hoofdprogramma(datamatrix,setups,CalcTimePerInstance) global initpop toernooigrootte crossoverkans mutatiekans immigratiekans duplicatiepercentage; nsetups=0; toernooigrootte = 2; crossoverkans = 0.6; mutatiekans = 0.2; immigratiekans = 0.1; duplicatiepercentage = 0.05; %Maximale rekentijd 60 seconden maxT=CalcTimePerInstance; Schrageopl=Schrage(datamatrix); FamilyRankopl=FamilyRank(datamatrix); % schragefit = berekenfitness(Schrageopl,datamatrix,setups); populatiegrootte = size(datamatrix,1)/5; populatie = []; fit=[]; i=1; dubbel=0; %Start klok, genereer een random populatie tStart=tic; while(i<populatiegrootte-1) aantaltaken = size(datamatrix,1); nieuwetaak = []; toetevoegentaken = [1:aantaltaken]; for j=1:aantaltaken plaats = ceil(rand*length(toetevoegentaken)); nieuwetaak(j)=toetevoegentaken(plaats); toetevoegentaken(plaats) = []; end populatie = [populatie; nieuwetaak]; [fitness,nsetups] = berekenfitness(populatie,datamatrix,setups); dubbel = berekenduplicatiepercentage(fitness); if(dubbel>duplicatiepercentage) populatie(i,:)=[]; i=i-1; else dubbel =0; end i=i+1; end % In de initiele populatie is de eerste oplossing diegene die alle taken

% van dezelfde familie bij elkaar houdt, de tweede is de Schrage oplossing initpop = [FamilyRankopl; Schrageopl ; populatie]; initpop1=initpop; a=1; optimaal=false; bounds=[Inf Inf Inf Inf]; fitnessvalue=[];improvementmuvalue=[];improvementcovalue=[];improvementavalue=[];improvementbvalue=[];improvementcvalue=[];improvementdvalue=[];improvementlsvalue=[]; fitnesstime=[];improvementmutime=[];improvementcotime=[];improvementatime=[];improvementbtime=[];improvementctime=[];improvementdtime=[];improvementlstime=[]; stop=0; [fitness,nsetups] = berekenfitness(initpop1,datamatrix,setups); while(optimaal == false && stop==0) [fitnessvoorcrossover,~] = berekenfitness(initpop1,datamatrix,setups); geselecteerdepop = selecteer(initpop1,fitness,toernooigrootte); kinderen = brengvoort(geselecteerdepop,initpop1,crossoverkans); totalenieuwepopulatie = [geselecteerdepop;kinderen]; [fitnessnacrossover,~] = berekenfitness(totalenieuwepopulatie,datamatrix,setups); improvementco=min(fitnessvoorcrossover)-min(fitnessnacrossover); if improvementco>0 improvementcovalue=[improvementcovalue improvementco]; improvementcotime=[improvementcotime toc(tStart)]; end gemuteerdepopulatie = muteer(totalenieuwepopulatie,mutatiekans); [fitnessnamutatie,~] = berekenfitness(gemuteerdepopulatie,datamatrix,setups); improvementmu=min(fitnessnacrossover)-min(fitnessnamutatie); if improvementmu>0 improvementmuvalue=[improvementmuvalue improvementmu]; improvementmutime=[improvementmutime toc(tStart)]; end popnaimmigratie = immigreer(gemuteerdepopulatie,immigratiekans); eindtijden = berekeneindtijden(popnaimmigratie,datamatrix,setups); [oplossingen,improvementa,improvementb,improvementc,improvementd,improvementls] = localsearch(popnaimmigratie,datamatrix,setups,eindtijden); nieuwepop = insert(oplossingen,initpop1,datamatrix,duplicatiepercentage,setups); initpop1=nieuwepop; [fitness,nsetups] = berekenfitness(initpop1,datamatrix,setups); fit1 = min(fitness); timenow=toc(tStart); fitnessvalue=[fitnessvalue fit1]; fitnesstime=[fitnesstime timenow]; if improvementa~=0 improvementavalue=[improvementavalue improvementa]; improvementatime=[improvementatime timenow]; end if improvementb~=0 improvementbvalue=[improvementbvalue improvementb]; improvementbtime=[improvementbtime timenow];

end if improvementc~=0 improvementcvalue=[improvementcvalue improvementc]; improvementctime=[improvementctime timenow]; end if improvementd~=0 improvementdvalue=[improvementdvalue improvementd]; improvementdtime=[improvementdtime timenow]; end if improvementls~=0 improvementlsvalue=[improvementlsvalue improvementls]; improvementlstime=[improvementlstime timenow]; end [optimaal,lb,bnds] = checkifopt(initpop1,datamatrix,fit1,bounds,setups); bounds = bnds; a=a+1; %Stop process as soon as time exceeds maximum calculating time if(toc(tStart)>maxT) stop=1; toc(tStart); end end besteindex = find(fitness == fit1); besteoplossing = initpop1(besteindex(1),:); toc(tStart) fit = [fit fit1] ncolumnsimprovementmatrix=max([length(improvementcovalue),length(improvementmuvalue),length(improvementavalue),length(improvementbvalue),length(improvementcvalue),length(improvementdvalue),length(improvementlsvalue)]); improvementmatrix=zeros(10,ncolumnsimprovementmatrix); improvementmatrix(1,1:length(improvementcovalue))=improvementcovalue; improvementmatrix(2,1:length(improvementcovalue))=improvementcotime; improvementmatrix(3,1:length(improvementmuvalue))=improvementmuvalue; improvementmatrix(4,1:length(improvementmuvalue))=improvementmutime; improvementmatrix(5,1:length(improvementavalue))=improvementavalue; improvementmatrix(6,1:length(improvementavalue))=improvementatime; improvementmatrix(7,1:length(improvementbvalue))=improvementbvalue; improvementmatrix(8,1:length(improvementbvalue))=improvementbtime; improvementmatrix(9,1:length(improvementcvalue))=improvementcvalue; improvementmatrix(10,1:length(improvementcvalue))=improvementctime; improvementmatrix(11,1:length(improvementdvalue))=improvementdvalue; improvementmatrix(12,1:length(improvementdvalue))=improvementdtime; improvementmatrix(13,1:length(improvementlsvalue))=improvementlsvalue; improvementmatrix(14,1:length(improvementlsvalue))=improvementlstime; end
4. Schrage.m function [Sequence] = Schrage(M) currenttime=0; Schrage=[]; number=(1:size(M,1))';

M=[M number]; while size(M,1)>=1 %If release date of next task is after finishing of last scheduled %task: update [releasedatenext,position]=min(M(:,2)); currenttime=max(releasedatenext,currenttime); CurrentDueDate=Inf; for i=1:size(M,1) if (M(i,2)<=currenttime) if (M(i,3)<CurrentDueDate) nexttask=i; CurrentDueDate=M(i,3); end end end Schrage=[Schrage;M(nexttask,1) M(nexttask,2) M(nexttask,3) M(nexttask,4) M(nexttask,5)]; currenttime=currenttime+M(nexttask,1); M(nexttask,:)=[]; end Schrage; Sequence=Schrage(:,5)'; end
5. FamilyRank.m function [Sequence] = FamilyRank(M) M=[M (1:size(M,1))']; M=sortrows(M,[4 3]); Sequence=M(:,5)';
6. Berekenfitness.m
function [fitnessmatrix,nsetups] = berekenfitness(pop,data,setups) fitnessmatrix = []; nsetups=zeros(size(pop,1),1); for i=1:size(pop,1) tijd = 0; latenesses = []; maximum=0; for j=1:size(pop,2) lateness = 0; taak = pop(i,j); if(j == 1) familie = data(taak,4); setuptijd = setups(size(setups,1),familie); tijdstip = setuptijd; else taakervoor = pop(i,j-1); familie1 = data(taakervoor,4); familie2 = data(taak,4); if(familie1 ~= familie2) nsetups(i,1)=nsetups(i,1)+1; setuptijd = setups(familie1,familie2); tijdstip = tijd+setuptijd; else tijdstip = tijd;

end end tijd = max(tijdstip,data(taak,2)); tijd = tijd + data(taak,1); lateness = data(taak,3)-tijd; latenesses = [latenesses; -lateness]; end maximum = max(latenesses); fitnessmatrix = [fitnessmatrix ; maximum]; end nsetups=min(nsetups); end
7. Berekenduplicatiepercentage.m
function perct = berekenduplicatiepercentage(fitness) teller = 0; algeweest = zeros(size(fitness,1)+1,1); for i=1:size(fitness,1) for j=1:(size(fitness,1)-i) if((fitness(i) == fitness(i+j)) && algeweest(i) ~= fitness(i)) teller = teller + 1; end end algeweest(i+1) = fitness(i); end perct = teller/size(fitness,1); end
8. Selecteer.m
function [selectie] = selecteer(pop,fit,grootte) selectie = []; aantalind = size(pop,1); %We verdelen de populatie at random in toernooien toernooien = []; fitkopie = fit; for i=1:(aantalind/grootte) for j=1:grootte randomgetal = ceil(length(fitkopie)*rand); toernooien(i,j)=fitkopie(randomgetal); fitkopie(randomgetal) = []; end end %We selecteren in elk toernooi het sterkste individu for i=1:(aantalind/grootte) sterkste = min(toernooien(i,:)); index = find(fit == sterkste); selectie = [selectie; pop(index,:)]; end end
9. Brengvoort.m
function [kinderen] = brengvoort(geselecteerdepop,beginpop,kans) aantalkinderen = size(beginpop,1) - size(geselecteerdepop,1); kinderen = [];

for i=1:aantalkinderen randomkans = rand; if(randomkans<=kans) kind = zeros(size(geselecteerdepop,2),1)'; %We kiezen twee ouders at random randomnummer1 = ceil(size(geselecteerdepop,1)*rand); randomnummer2 = ceil(size(geselecteerdepop,1)*rand); while(randomnummer2 == randomnummer1) randomnummer2 = ceil(size(geselecteerdepop,1)*rand); end ouder1 = geselecteerdepop(randomnummer1,:); ouder2 = geselecteerdepop(randomnummer2,:); %Nu bepalen we hoeveel taken we uit de eerste ouder nemen aantaltaken = ceil(length(ouder1)*rand); %Vervolgens bepalen we at random welke taken dit zijn takenvanouder1=[]; a=1; while(a<=aantaltaken) randomindex = ceil(length(ouder1)*rand); while(ouder1(randomindex) == 0) randomindex = ceil(length(ouder1)*rand); end taak = ouder1(randomindex); takenvanouder1 = [takenvanouder1;taak randomindex]; ouder1(randomindex) = 0; a= a+1; end %We wijzen die toe aan het kind for m=1:size(takenvanouder1,1) kind(takenvanouder1(m,2))=takenvanouder1(m,1); end %Dan zeggen we dat de overgebleven taken uit ouder 2 moeten komen takenvanouder2 = []; for j=1:length(ouder1) if(ouder1(j) ~= 0) takenvanouder2 = [takenvanouder2; ouder1(j)]; end end %We bepalen de index van de taken in ouder2 die daaruit moeten komen indici = []; for n=1:size(takenvanouder2,1) indici = [indici ; find(ouder2 == takenvanouder2(n))]; end correctevolgorde = sort(indici); for l=1:size(correctevolgorde,1) index = correctevolgorde(l,1); correctevolgorde(l,2) = ouder2(index); end %Nu voegen we die taken in het kind in in de correcte volgorde for k=1:length(kind) if(kind(k) == 0) kind(k) = correctevolgorde(1,2); correctevolgorde(1,:) = []; end end

%We bewaren het kind kinderen = [kinderen; kind]; end end end
10. Muteer.m
function [gemuteerdepop] = muteer(pop,kans) for i=1:size(pop,1) randomgetal=rand; if(randomgetal<=kans) %We bepalen at random de twee swapplaatsen lengte = length(pop(i,:)); plaats1 = ceil(lengte*rand); plaats2 = ceil(lengte*rand); while(plaats1 == plaats2) plaats2 = ceil(lengte*rand); end %We verwisselen beide taken tijdelijk = pop(i,plaats1); pop(i,plaats1)=pop(i,plaats2); pop(i,plaats2)=tijdelijk; end end gemuteerdepop=pop; end
11. Immigreer.m
function nieuwepop = immigreer(pop,kans) randomgetal = rand; if(randomgetal <= kans) aantaltaken = length(pop(1,:)); nieuwetaak = []; toetevoegentaken = [1:aantaltaken]; for i=1:aantaltaken plaats = ceil(rand*length(toetevoegentaken)); nieuwetaak(i)=toetevoegentaken(plaats); toetevoegentaken(plaats) = []; end nieuwepop = [pop ; nieuwetaak]; else nieuwepop = pop; end end
12. Berekeneindtijden.m
function eindtijden = berekeneindtijden(pop,data,setups) fitnessmatrix = []; eindtijden = 0*pop'; for i=1:size(pop,1) tijd = 0; latenesses = []; maximum=0; for j=1:size(pop,2)

lateness = 0; taak = pop(i,j); if(j == 1) familie = data(taak,4); setuptijd = setups(size(setups,1),familie); tijdstip = setuptijd; else taakervoor = pop(i,j-1); familie1 = data(taakervoor,4); familie2 = data(taak,4); if(familie1 ~= familie2) setuptijd = setups(familie1,familie2); tijdstip = tijd+setuptijd; else tijdstip = tijd; end end tijd = max(tijdstip,data(taak,2)); tijd = tijd + data(taak,1); lateness = data(taak,3)-tijd; eindtijden(taak,i)=tijd; latenesses = [latenesses; -lateness]; end maximum = max(latenesses); fitnessmatrix = [fitnessmatrix ; maximum]; end end
13. Localsearch.m
function [nieuwepop,improvementa,improvementb,improvementc,improvementd,improvementls] = localsearch(pop,data,setups,eindtijden) nieuwepop = []; improvementa=0; improvementb=0; improvementc=0; improvementd=0; improvementls=0; fitnessmatrix=berekenfitness(pop,data,setups); [currentminfitness,~]=min(fitnessmatrix); for i=1:size(pop,1) taak = pop(i,:); fitness=fitnessmatrix(i,1); %Swap between same families... nieuwefitness = Inf; c=0; cmax=800; while nieuwefitness>fitness && c<=cmax place1 = ceil(length(taak)*rand); samefamily=find(data(:,4)==data(place1,4)); randomtask2 = samefamily(ceil(length(samefamily)*rand),1); place2=find(taak==randomtask2); newtask = taak; temporary = newtask(place1); newtask(place1)= newtask(place2); newtask(place2)= temporary;

[nieuwefitness,~] = berekenfitness(newtask,data,setups); if(nieuwefitness < fitness) if nieuwefitness<currentminfitness improvementc=improvementc+currentminfitness-nieuwefitness; currentminfitness=nieuwefitness; end taak = newtask; c=cmax; end c=c+1; end %Move a task of one family behind a task of the same family (randomly) nieuwefitness = Inf; d=0; dmax=800; while nieuwefitness>fitness && d<=dmax place1 = ceil(length(taak)*rand); samefamily=find(data(:,4)==data(place2,4)); randomtask2 = samefamily(ceil(length(samefamily)*rand),1); place2=find(taak==randomtask2); if place2<place1 temporary=place2; place2=place1; place1=temporary; end newtask=[taak(1:place1-1) taak(place1+1:place2) taak(place1) taak(place2+1:end)]; [nieuwefitness,~] = berekenfitness(newtask,data,setups); if(nieuwefitness < fitness) if nieuwefitness<currentminfitness improvementd=improvementd+currentminfitness-nieuwefitness; currentminfitness=nieuwefitness; end taak = newtask; d=dmax; end d=d+1; end fitness = nieuwefitness; nieuwefitness = Inf; %Randomized pairwise swap a=0; amax=800; while(nieuwefitness > fitness && a<=amax) lengte = length(taak); plaats1 = ceil(lengte*rand); plaats2 = ceil(lengte*rand); while(plaats1 == plaats2) plaats2 = ceil(lengte*rand); end nieuwetaak = taak; tijdelijk = nieuwetaak(plaats1); nieuwetaak(plaats1)= nieuwetaak(plaats2); nieuwetaak(plaats2)= tijdelijk; [nieuwefitness,~] = berekenfitness(nieuwetaak,data,setups); if(nieuwefitness < fitness) if nieuwefitness<currentminfitness

improvementa=improvementa+currentminfitness-nieuwefitness; currentminfitness=nieuwefitness; end taak = nieuwetaak; a=amax; end a = a+1; end fitness = nieuwefitness; nieuwefitness = Inf; %Adjacent pairwise swap b=0; bmax=200; while(nieuwefitness > fitness && b<=bmax) lengte = length(taak); plaats = ceil(lengte*rand); nieuwetaak = taak; if(plaats == 1) tijdelijk = nieuwetaak(plaats); nieuwetaak(plaats) = nieuwetaak(plaats+1); nieuwetaak(plaats+1) = tijdelijk; [nieuwefitness,~] = berekenfitness(nieuwetaak,data,setups); if(nieuwefitness < fitness) if nieuwefitness<currentminfitness improvementb=improvementb+currentminfitness-nieuwefitness; currentminfitness=nieuwefitness; end taak = nieuwetaak; b=bmax; end else tijdelijk = nieuwetaak(plaats); nieuwetaak(plaats) = nieuwetaak(plaats-1); nieuwetaak(plaats-1) = tijdelijk; [nieuwefitness,~] = berekenfitness(nieuwetaak,data,setups); if(nieuwefitness < fitness) if nieuwefitness<currentminfitness improvementb=improvementb+currentminfitness-nieuwefitness; currentminfitness=nieuwefitness; end taak = nieuwetaak; b=bmax; end end b = b+1; end fitness = nieuwefitness; nieuwefitness = Inf; %Move operator latenesses=[eindtijden(:,i)-data(:,3)]; wachttijden=[eindtijden(:,i)-data(:,1)-data(:,2)]; maxlateness=max(latenesses); j=1; while nieuwefitness>fitness && j<=size(taak,2)-1 k=j+1;

while nieuwefitness>fitness && k<=size(taak,2)-1 && eindtijden(taak(k),1)-data(taak(j),3)<maxlateness && min(wachttijden(taak(j+1:k)))~=0 minwachttijd=min(wachttijden(taak(j+1:k),1)); if j==1 earlieststartjplus1=max(setups(size(setups,1),data(taak(j+1),4)),data(taak(j+1),2)); maxdeltattaakjplus1=eindtijden(taak(j+1),i)-data(taak(j+1),1)-earlieststartjplus1; maxdeltattaakk=min(maxdeltattaakjplus1,minwachttijd); else earlieststartjplus1=max(eindtijden(taak(j-1),i)+setups(data(taak(j-1),4),data(taak(j+1),4)),data(taak(j+1),2)); maxdeltattaakjplus1=eindtijden(taak(j+1),i)-data(taak(j+1),1)-earlieststartjplus1; maxdeltattaakk=min(maxdeltattaakjplus1,minwachttijd); end eindtijdtaakj=max(eindtijden(taak(k),i)-maxdeltattaakk+setups(data(taak(k),4),data(taak(j),4))+data(taak(j),1),data(taak(j),2)+data(taak(j),1)); tijdelijkelateness=eindtijdtaakj-data(taak(j),3); if latenesses(taak(k))>tijdelijkelateness nieuwetaak=[taak(1:j-1) taak(j+1:k) taak(j) taak(k+1:end)]; [nieuwefitness,~] = berekenfitness(nieuwetaak,data,setups); if nieuwefitness <= fitness if nieuwefitness < fitness && nieuwefitness<currentminfitness improvementls=improvementls+currentminfitness-nieuwefitness; end taak = nieuwetaak; end end k=k+1; end j=j+1; end nieuwepop = [nieuwepop ; taak]; end
14. Insert.m
function nieuwepop = insert(oplossingen,initpop,data,duplpct,setups) nieuwepop = initpop; oplfit = berekenfitness(oplossingen,data,setups); for i=1:size(oplossingen,1) popfit = berekenfitness(nieuwepop,data,setups); besteopl = min(oplfit); besteindex = find(oplfit == besteopl); duplicatie=1; teller=1; while(duplicatie>duplpct && teller<=size(nieuwepop,1)) slechtstetaak = max(popfit); slechtsteindex = find(popfit == slechtstetaak);

if(besteopl <= slechtstetaak) tijdelijk = nieuwepop(slechtsteindex,:); nieuwepop(slechtsteindex(1),:) = oplossingen(besteindex(1),:); nieuwefit = berekenfitness(nieuwepop,data,setups); duplicatie = berekenduplicatiepercentage(nieuwefit); if(duplicatie > duplpct) nieuwepop(slechtsteindex,:) = tijdelijk; popfit(slechtsteindex)=0; else oplfit(besteindex) = Inf; popfit(slechtsteindex) = 0; duplicatie = 0; end end teller = teller+1; end end end


















