
Politecnico di Milano · 2007-10-24 · Politecnico di Milano Facolt a di Ingegneria...
79
Politecnico di Milano Facolt` a di Ingegneria dell’Informazione Corso di Laurea in Ingegneria Informatica Dipartimento di Elettronica e Informazione Flusso per la Generazione Automatica di Controllori per la Riconfigurazione Dinamica Relatore: Prof. Donatella Sciuto Correlatore: Marco Domenico Santambrogio Tesi di Laurea di: Paolo Roberto GRASSI matr. 669971 Andrea CUOCCIO matr. 669004 Anno Accademico 2006-2007
-
Upload
nguyentram -
Category
Documents
-
view
213 -
download
0
Transcript of Politecnico di Milano · 2007-10-24 · Politecnico di Milano Facolt a di Ingegneria...

Politecnico di Milano
Facolta di Ingegneria dell’Informazione
Corso di Laurea in Ingegneria Informatica
Dipartimento di Elettronica e Informazione
Flusso per la Generazione Automatica di
Controllori per la Riconfigurazione Dinamica
Relatore: Prof. Donatella Sciuto
Correlatore: Marco Domenico Santambrogio
Tesi di Laurea di:
Paolo Roberto GRASSI matr. 669971
Andrea CUOCCIO matr. 669004
Anno Accademico 2006-2007


Per Marco:
”Se non vale la pena fare una ricerca,
non vale neanche la pena farla bene”
Prima legge di Gordon
Per Vincenzo:
”Non replicare mai un esperimento riuscito”
Legge di Fett


Ringraziamenti
I primi ringraziamenti vanno a Marco Santambrogio e Vincenzo Rana, per
averci seguito con incredibile pazienza e dedizione. Grazie veramente, niente
di tutto cio sarebbe stato possibile senza di voi: il vostro entusiasmo ha man-
tenuto vivo il nostro.
Grazie a tutti i ragazzi di DRESD e tutti coloro che lavorano nel MicroLab.
E stato un onore e un piacere lavorare con tutti voi. Ci avete fatto crescere
professionalmente e umanamente. La nostra speranza e di poter collaborare
assieme nei prossimi anni.
Infine, grazie a tutti coloro che ci hanno permesso di arrivare a questo primo
traguardo universitario.
Andrea
Alla mia famiglia che mi ha continuamente sostenuto e incoraggiato fino a
questo momento.
Agli amici compagni di corso con i quali si e passati attraverso questi tre duri
anni.
Agli amici al di fuori dell’universita indispensabile fonte di svago.
Alla promessa fatta sette anni fa, mantenuta fino a questo momento e alla
quale non verro mai a meno.
Paolo
Ringrazio Dio per avermi donato una famiglia che mi ha sostenuto e dato la
possibilita di studiare. Grazie ad Andrea, fedele e operoso compagno in tutto il
percorso in DRESD. Spero, in futuro, di poter ancora lavorare con lui in questo
magnifico gruppo. Un grazie di cuore a Sara per essere riuscita a strapparmi
un sorriso tutte quelle volte che avrei voluto piangere, per avermi fatto capire
quanto sia importante amare ed essere amati. Grazie a tutti i coloro che ho
conosciuto al Politecnico. Senza di loro non sarebbe stato tutto cosı bello. Un
v

vi
ultimo ringraziamento va a Biasi, Luca e Valerio, fedeli compagni delle mie ore
fuori dal Politecnico.
Milano, Settembre 2007

Indice
1 Riconfigurabilita 3
1.1 Field Programmable Gate Array . . . . . . . . . . . . . . . . . . 4
1.2 Caratteristiche di Riconfigurazione . . . . . . . . . . . . . . . . 6
1.2.1 Riconfigurabilita Totale o Parziale . . . . . . . . . . . . . 7
1.2.2 Distinzione in base alla granularita del processo . . . . . 9
1.2.3 Distinzione in base allo stato del dispositivo durante il
processo di riconfigurazione . . . . . . . . . . . . . . . . 10
1.2.4 Distinzione in base alla locazione del dispositivo che
effettua la riconfigurazione . . . . . . . . . . . . . . . . . 11
1.3 Porta ICAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.1 Descrizione componente . . . . . . . . . . . . . . . . . . 12
1.3.2 Implementazione . . . . . . . . . . . . . . . . . . . . . . 13
1.3.3 Utilizzo . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.4 Bitstream . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5 IBM CoreConnect . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.6 Software utilizzati . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.6.1 ISE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.6.2 EDK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2 Stato dell’Arte 21
2.1 OPB HWICAP . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.1.1 Interfaccia, struttura e funzionamento . . . . . . . . . . . 22
2.1.2 Pro e contro . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2 ICAP DRESD . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.1 Interfaccia, struttura e funzionamento . . . . . . . . . . . 24
2.2.2 Pro e Contro . . . . . . . . . . . . . . . . . . . . . . . . 25
vii

viii INDICE
2.3 PLBICAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3.1 Interfaccia, struttura e funzionamento . . . . . . . . . . . 26
2.3.2 Pro e Contro . . . . . . . . . . . . . . . . . . . . . . . . 26
3 DRC 29
3.1 Problematiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Il controller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.1 Struttura interna . . . . . . . . . . . . . . . . . . . . . . 31
3.2.2 Funzionamento . . . . . . . . . . . . . . . . . . . . . . . 32
3.2.3 Implementazione Hardware . . . . . . . . . . . . . . . . 33
3.3 Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 DRCgen 41
4.1 Analisi dei requisiti e modellizzazione . . . . . . . . . . . . . . . 41
4.1.1 Grandezze descrittive del DRC . . . . . . . . . . . . . . 41
4.1.2 Relazioni descrittive del DRC . . . . . . . . . . . . . . . 44
4.2 Flusso operativo di DRCgen . . . . . . . . . . . . . . . . . . . . 49
4.2.1 Ricerca della soluzione ottimale . . . . . . . . . . . . . . 49
4.2.2 Funzionamento . . . . . . . . . . . . . . . . . . . . . . . 51
4.2.3 Generazione dell’output . . . . . . . . . . . . . . . . . . 56
4.2.4 Utilizzo dei files di output in EDK . . . . . . . . . . . . 56
5 Risultati Sperimentali 59
5.1 Validazione del modello . . . . . . . . . . . . . . . . . . . . . . . 59
5.2 Test DRCgen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.2.1 Specifica del Solo Vincolo sul Throughput . . . . . . . . 62
5.2.2 Specifica del Solo Vincolo di Area . . . . . . . . . . . . . 62
5.2.3 Specifica di Entrambi i Vincoli . . . . . . . . . . . . . . . 64
5.3 Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6 Conclusioni e Sviluppi Futuri 67
6.1 Sviluppi Futuri . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Bibliografia 71

Sommario
Questo lavoro di tesi si colloca all’interno del progetto DRESD (Dynamic Re-
configurability in Embedded System Design) presso il Laboratorio di Microar-
chitetture del Politecnico di Milano.
Con Sistema Embedded [14] (sistema incapsulato) si identificano genericamente
dei sistemi elettronici a microprocessore progettati appositamente per una
determinata applicazione, spesso con una piattaforma hardware ad hoc in-
tegrata nel sistema che controlla e in grado di gestirne tutte o parte delle
funzionalita. Tra le tante applicazioni e implementazioni che rigurdano i sis-
temi embedded, DRESD si colloca nello scenario dei sistemi riconfigurabili su
Field-Programmable Gate Array (FPGA). Questi sistemi hanno la capacita di
modificare nel tempo sia la propria struttura che la propria funzionalita.
Nelle FPGA della famiglia Xilinx [8], la riconfigurabilita e garantita dalla
presenza dell’ICAP (Internal Configuration Access Port) che, tramite un op-
portuno controller, riceve i file di configurazione (Bitstream) e riconfigura il
dispositivo.
Obiettivo generale di questo lavoro di tesi e la creazione di un flusso di
generazione automatica di controllori per la riconfigurazione dinamica.
Da uno studio dello stato dell’arte in materia di controllori di riconfigurabilita,
ci si e accorti che un riconfiguratore muta le sue prestazioni in funzione dello
scenario in cui e immerso. Da qui l’idea di creare un controllore di riconfig-
urabilita seguendo una strada differente. I controllori esistenti sono in grado
di garantire buone prestazioni in una grande vastita di scenari. Dato che lo
scenario e noto a priori, e nata l’idea di construire un riconfiguratore ad hoc,
in modo che esso garantisca ottime prestazioni spaziali e temporali.
Il raggiungimento di questo obiettivo e stato raggiunto a fronte dello sviluppo
del DRC (DRESD Reconfiguration Controller). Questo controllore e dotato di
1

2 INDICE
un buffer di dimensioni arbitrarie ed e interfacciabile su piu bus. Il DRC ha
permesso, quindi, di portare avanti uno studio formale sugli scenari di ricon-
figurabilita in cui esso potrebbe trovarsi. Dopo una accurata modellizzazione
del sistema che sta alla base del DRC, e stato sviluppato DRCgen, un software
in grado di configurare il DRC in base allo scenario in cui esso dovra essere
collocato.
Nel Capitolo 1 verra presentata una panoramica dei sistemi riconfigurabili
introducendo tutte le nozioni di base che serviranno alla comprensione dei
successivi concetti. Nel Capitolo 2 si analizzera lo stato dell’arte in mate-
ria di controllori di riconfigurabilita con un confronto dei pregi e dei difetti.
Finalmente nel Capitolo 3 si presentera la struttura e il funzionamento del
DRC mettendolo a confronto con i controllori esposti al capitolo precedente.
Nel Capitolo 4 si affrontera la modellizzazione del DRC e la sua diretta im-
plementazione: DRCgen. Il Capitolo 5 contiene i test condotti sul DRC e su
DRCgen. Conclusioni e sviluppi futuri sono collocati nel Capitolo 6.

Capitolo 1
Riconfigurabilita
Un dispositivo riconfigurabile ha come caratteristica principale la possibilia
di cambiare comportamento (riconfigurarsi) nel corso del suo utilizzo, senza
dover essere sostituito, in base alle esigenze dell’utente.
In sistemi di questo tipo, le funzioni che devono essere svolte dal dispositi-
vo possono essere divise in moduli, che verranno caricati quando si riterra
necessaria la funzione che implementano. Dispositivi che presentano questa
caratteristica sono ad esempio le Field Programmable Gate Array (FPGA), che
verranno utilizzate in questo lavoro e descritte nel corso del primo paragrafo.
Per poter configurare questi dispositivi ci si serve di un file binario chiamato
Bitstrem che verra creato dopo varie fasi di sintesi. La parte riconfigurabile
piu piccola dell’FPGA viene chiamata frame.
Quando si parla di riconfigurazione e necessario chiarire cosa si intende, infatti
non esiste un unico modo per riconfigurare il dispositivo, ne esistono diversi e
ognuno con delle caratteristiche ben precise, che possono dare indicazioni sulle
modalita e sui problemi legati a quel tipo di riconfigurazione.
Quando si crea un’architettura, uno dei problemi principali e quello di creare
l’infrastruttura di comunicazione. Ad oggi uno standard e rappresentato dal
CoreConnect del’IBM, che presenta una struttura composta da tre bus : Pro-
cessor Local Bus , On-chip Peripheral Bus e Device Control Register bus.
Solitamente le case produttrici delle FPGA mettono a disposizione del proget-
tista i software per poter utilizzare le caratteristiche di questi dispositivi.
Nel corso di questo capitolo verranno descritti gli argomenti appena esposti,
ritenuti importanti per la comprensione dei successivi capitoli.
3

4 CAPITOLO 1. RICONFIGURABILITA
1.1 Field Programmable Gate Array
Una Field Programmable Gate Array (FPGA) [12] e un dispositivo a semi-
conduttore che contiene logica e interconnessioni programmabili che possono
essere configurate in maniera tale da svolgere le operazioni logiche, da quelle
piu elementari come AND,OR,NOT,XOR, a funzioni piu complesse, come ad
esempio funzioni matematiche. Inoltre nella maggior parte delle FPGA questa
logica programmabile include anche elementi di memoria, che vanno dai sem-
plici flip-flops fino a banchi di memoria veri e propri.
I blocchi di logica programmabile (CLB) sono formati da una parte combina-
toria a 4 ingressi (Lookup table) e da una parte sequenziale formata da un
flip-flop. Un esempio di questa struttura e rappresentato in figura 1.1
I blocchi di logica programmabile hanno come ingresso 4 segnali e un segnale
Figura 1.1: schema di una CLB su FPGA della famiglia delle Virtex II
di clock.
Le interconnessioni vengono create tramite apposite strutture chiamate ”
switch matrix ”, che permettono di creare tutti i collegamenti possibili. Tali
collegamenti sono disabilitati inizialmente, poi verranno attivati secondo ne-
cessita.
Inoltre ci sono dei collegamenti che permettono di raggiungere gli Input-Output
Block (IOB), che sono l’interfaccia del dispositivo con il mondo esterno. In
figura 1.2 e rappresentata la struttura delle interconnessioni dei blocchi appe-
na descritti.

1.1. FIELD PROGRAMMABLE GATE ARRAY 5
Figura 1.2: struttura della FPGA
Per specificare il comportamento di questi dispositivi, generalmente il pro-
gettista ne fornisce una descrizione tramite un linguaggio di hardware descrip-
tion language (HDL). I linguaggi HDL piu conosciuti sono il VHDL e il Verilog.
Dopo aver creato un design, per poterlo effettivamente utilizzare, si deve pas-
sare attraverso una serie di passi che dalla descrizione in VHDL/Verilog portera
al bitstream.
Si parte da un processo di sintesi, che verifica la sintassi del codice e analizza la
gerarchia del design, assicurandosi di ottimizzarlo per il dispositivo su cui deve
essere implementato. Viene cosı creato un file .NGC che contiene la netlist1
del design.
Si passa poi ad una fase di translate, che unisce la netlist con eventuali vincoli
posti al design. I vincoli vengono specificati sottoforma di testo in un file
.UCF (User Constraint File) [7]. Tali vincoli possono essere spaziali,temporali
o di sintesi e andranno a determinare come il design verra implementato: ad
esempio un vincolo spaziale indica l’area entro la quale usare la logica per
1La netlist e una descrizione testuale dei collegamenti del circuito. Fondamentalmente
contiene una lista di connettori e una lista di istanze tale che, per ognuna di esse, si ha una
lista di segnali connessi ai suoi terminali.

6 CAPITOLO 1. RICONFIGURABILITA
implementare.
La fase di translate produce un file .NGD (Native Generic Database) che
descrive la logica ridotta a primitive del dispositivo, che serve come input al
processo di mapping. Tale processo ”mappera” la logica definita nel .NGD in
elementi della FPGA, come CLB e IOB. L’output prodotto e un file .NCD
(Native Circuit Description) che fisicamente rappresenta il design mappato sui
componenti dell’FPGA.
Si giunge poi al place & route che istanzia i componenti e instrada le con-
nessioni.Si viene cosı a creare un opportuno NCD che viene utilizzato per la
generazione dei bitstream, che verranno utilizzati per (ri)configurare il dispo-
sitivo.
Infine, sulle FPGA e possibile utilizzare uno o piu processori che permettono
l’esecuzione di programmi scritti in un normale codice ad alto livello come
l’ANSI-C.
Si possono distinguere due diversi tipi di processori:
• hard-processor : sono processori gia presenti fisicamente nel dispositivo,
integrati nel silicio, come il POWER-PC405 nella famiglia di VIRTEX
II Pro della Xilinx [5].
• soft-processor : sono processori che vengono sintetizzati come un nor-
male core e vanno ad utilizzare la logica programmabile presente sul
dispositivo. Un esempio di questo tipo di core e il MicroBlaze [4].
1.2 Caratteristiche di Riconfigurazione
Esistono diversi tipi di riconfigurazione, distinti tra loro da diverse caratteris-
tiche, ognuna della quali porta vantaggi e svantaggi con se. Tali caratteristiche
possono essere divise in base alla globalita o meno della superficie interessata
dalla riconfigurazione, alla granularita della riconfigurazione, se questo avviene
a run-time oppure off-line, e in base alla presenza o meno sul dispositivo del
componente che effettua la riconfigurazione.
La prima caratteristica suddivide la riconfigurazione in totale o parziale, la
seconda in Module-based e Difference-based, la terza in statica o dinamica e
l’ultima in interna ed esterna.

1.2. CARATTERISTICHE DI RICONFIGURAZIONE 7
1.2.1 Riconfigurabilita Totale o Parziale
In base alla totalita o meno della parte interessata dalla riconfigurazione,
si puo distinguere tra riconfigurazione totale, che prevede la riscrittura del
circuito dell’intero dispositivo, o riconfigurazione parziale, che prevede la
riscrittura di singole parti del dispositivo.
Riconfigurabilita Totale: questo e il caso piu semplice di riconfigura-
zione, dato che l’operazione prevede il solo caricamento di un intero bitstream
per aggiornare il dispositivo. Tuttavia in questa operazione si hanno due
inconvenienti non trascurabili: ad ogni riconfigurazione, anche di una piccola
parte, si deve per forza riconfigurare tutto il dispositivo e, durante il processo
di riconfigurazione, si ha una interruzione del servizio.
Riconfigurabilita Parziale: un passo avanti si ha con la riconfigurazione
parziale, che permette di riconfigurare aree del dispositivo dove necessario.
Questo approccio e particolarmente potente, poiche potendo cambiare anche
solo una funzione, si riduce il tempo di riconfigurazione che e legato alla
lunghezza del bitstream.
Per contro la riconfigurazione parziale fa sorgere un nuovo problema, che
si presenta in fase di sintesi dei moduli riconfigurabili e nella creazione dei
bitstream: dato che si ha la possibilita di cambiare i moduli di calcolo in
modo dinamico, non si potra avere la certezza della posizione finale dei moduli
di calcolo duraznte l’utilizzo del dispositivo riconfigurabile. Inoltre bisogna
stare attenti a non riconfigurare parti del dispositivo che sono in uso in quel
momento.
Alcune FPGA della Xilinx permettono solo la riconfigurazione dei moduli
per colonne, come le Virtex II e Virtex II-Pro (altri venditori producono dis-
positivi configurabili per righe), ovvero di aree rettangolari di altezza pari a
quella del dispositivo. Vale a dire che per riconfigurare un modulo bisogna
riconfigurare l’intera colonna che lo contiene, andando ad influenzare tutta la
logica contenuta nel rettangolo. Per quanto riguarda la riconfigurazione per
colonne (o righe), si parla di approccio monodimensionale alla riconfigurabilita.
Infatti anche se e permesso dare vincoli di piazzamento in 2D dei moduli (sotto

8 CAPITOLO 1. RICONFIGURABILITA
opportuni vincoli), non e possibile fare lo stesso per la riconfigurazione. Men-
tre in altre FPGA come la Virtex-4 e la Virtex-5 sono permessi piazzamenti e
riconfigurazione sia in 1D che in 2D.
Vediamo un po’ piu in dettaglio cosa si intende: un vincolo di piazzamento
va ad identificare l’area entro la quale un modulo deve essere mappato. Se
quest’area ha la stessa altezza del dispositivo si parla di vincolo 1D, mentre se
non si e obbligati a raggiungere una tale altezza si puo parlare di vincolo 2D.
Nel caso in cui si ha anche un solo modulo con una altezza minore di quella
del dispositivo, si parla di vincolo 2D.
Parlando di riconfigurazione si e nel caso 1D se l’area piu piccola che puo es-
sere riconfigurata copre comunque in altezza il dispositivo, altrimenti si parla
di riconfigurazione 2D.
Nella Figura 1.3 si possono vedere diversi casi i diversi casi di piazzamento
e riconfigurazione 1D e 2D. In figura 1.3 (1) si ha il caso di piazzamento
e riconfigurazione entrambe 1D: i moduli in verde indicano una situazione
permessa, mentre quelli in rosso indicano una irregolarita nel piazzamento
e/o nella riconfigurabilita. Nel dettaglio in Figura 1.3 (1.a) si puo vedere un
piazzamento 1D permesso, mentre in Figura 1.3 (1.b) si ha un piazzamento
irregolare perche le due aree si sovrappongono. In Figura 1.3 (2) si ha il caso di
piazzamento 2D e riconfigurazione 1D, il quale mostra che in alcuni casi, anche
se si ha la liberta del paizzamento 2D, non e permesso riconfigurare un’area
con un’altezza minore di quella del dispositivo. La Figura 1.3 (2.a) mostra un
caso permesso, mentre la Figura 1.3 (2.b) ne mostra uno irregolare. Infatti
anche se le due aree espresse nei vincoli non si sovrappongono, lo fanno le aree
riconfigurabili il che non e permesso nella riconfigurazione 1D. Infine in Figura
1.3 (3) si possono vedere entrambe: riconfigurazione e piazzamento 2D. Ambo
i casi sono considerati validi.

1.2. CARATTERISTICHE DI RICONFIGURAZIONE 9
Figura 1.3: Vincoli 1D e 2D combinati con riconfigurazione 1D e 2D in
differenti scenari appplicativi
1.2.2 Distinzione in base alla granularita del processo
In base alla granularita del processo si puo distinguere l’approccio Module-
based, a grana meno fine in quanto agisce a livello di colonne, e l’approccio
Difference-based, a grana piu fine in quanto agisce a livello di singoli bit.
Approccio Module-based: questo approccio prevede la creazione
dei vari moduli, ognuno dei quali implementa una diversa funzionalita sul
dispositivo. Ciascuno di questi moduli ha la possibilita di essere aggiunto o
rimosso dal sistema individualmente. In questo caso si prevede che se si avvia
il processo di riconfigurazione si abbia l’aggiunta o la rimozione di uno o piu
moduli dal sistema. Allo stato attuale la gestione dei moduli avviene per
colonne (o per righe) e ogni modulo viene allocato in un gruppo di colonne
libere, scrivendo i dati di configurazione frame per frame. Va notato che la
porzione minima su cui e possibile effettuare delle modifiche a questo livello
non e il frame, ma l’intera colonna che e composta da un numero di frame
dipendenti dal tipo di scheda sulla quale si sta lavorando.
Approccio Difference-based: questo approccio puo avvenire a due di-
versi livelli: front-end oppure back-end
Nel primo caso si va a modificare il VHDL/Verilog oppure lo schematico, poi
si deve risintetizzare il progetto che va reimplementato su scheda. Nel secondo
caso le modifiche si fanno sul NCD, che contiene le informazioni del routing
e della logica utilizzati, tramite tool quali FPGA editor e BitGen, con i quali

10 CAPITOLO 1. RICONFIGURABILITA
e possibile la creazione di bitstream che andranno a modificare solo la parte
richiesta. Questa operazione e generalmente molto veloce, in quanto i bit-
stream differenza (vedi 1.4) sono in genere molto piu piccoli di quelli totali di
configurazione.
1.2.3 Distinzione in base allo stato del dispositivo du-
rante il processo di riconfigurazione
Questa caratteristica distingue riconfigurazione statica, ovvero a dispositivo
inattivo, e riconfigurazione dinamica, ovvero si permette alle parti non
interessate dal processo di riconfigurazione di continuare a computare.
Riconfigurazione statica: questo e un approccio molto semplice di
riconfigurazione, in quanto prevede l’aggiunta e la rimozione di moduli
solo quando il dispositivo e inattivo; qualora ci siano delle elaborazioni in
corso e il processo inizia, tali elaborazioni devono essere terminate perche la
riconfigurazione vada a buon fine.
Per contro presenta il grosso svantaggio che, per sostituire anche solo un
modulo, bisogna disattivare il dispositivo per un certo periodo di tempo prima
che riprenda a lavorare con la nuova configurazione. Inoltre non e possibile la
sostituzione di un modulo necessario a supportare una computazione in atto,
poiche si dovrebbe disattivare anche la parte richiedente del nuovo modulo.
Riconfigurazione dinamica: piu complessa e la riconfigurazione
dinamica, che permette la riconfigurazione senza la necessita di disattivare
l’intero dispositivo. Questo permette l’allocazione dei moduli che servono
alla computazione, nel momento in cui servono, garantendo piu flessibilita al
sistema.
Sicuramente presenta aspetti implementativi da non sottovalutare sin dalla
fase di sintesi, nella quale si dovranno creare un gran numero di bitstream,
per poi utilizzarli quando lo si terra necessario.
Nella gestione del processo di elaborazione si dovra tener conto dello stato
in cui si trova la scheda, poiche si sappia quali risorse sono effettivamente
presenti in un determinato momento. Inoltre si dovra garantire l’accesso a

1.2. CARATTERISTICHE DI RICONFIGURAZIONE 11
quei moduli non interessati dalla riconfigurazione.
1.2.4 Distinzione in base alla locazione del dispositivo
che effettua la riconfigurazione
Questa caratteristica indica la presenza o meno di quel componente, hardware
o software o una combinazione di entrambi i moduli, atto alla gestione del
processo di riconfigurazione all’interno dell’architettura.
In qualsiasi modo venga implementato, non si pongono restrizioni sul dove
verranno salvati i bitstreams. Solitamente vengono salvati all’esterno del
dispositivo riconfigurabile (ad esempio su delle RAM esterne), poiche la sua
memoria interna disponibile e piuttosto limitata.
Riconfigurazione esterna: il caso piu semplice e quello di avere il gestore
all’esterno del dispositivo, ruolo che puo essere svolto da un computer che ha
senz’altro capacita di calcolo maggiori. In questo caso l’architettura diventa
di fatto una periferica riconfigurabile, gestita da un calcolatore che permette
controlli sulla riconfigurazione anche molto complessi data la potenza di
calcolo maggiore.
Tuttavia questo approccio ha di negativo il fatto che ogni volta che si necessita
di una riconfigurazione si perde molto tempo nel trasferimento dei file di
riconfigurazione. Questo tempo, che comunque puo essere ridotto da strutture
di comunicazione migliori, e comunque una grave perdita per quei sistemi che
richiedono riconfigurazioni piuttosto ravvicinate, poiche bisognera attendere
ogni volta i dati dal sistema esterno.
Riconfigurazione interna: questo e un caso piu interessante da analizza-
re, data la presenza del gestore della riconfigurazione all’interno dell’architet-
tura. Esempi di questo dispositivo sono analizzati nel capitolo 2.
In questo caso si dovra predisporre un’area all’interno del dispositivo dove
collocare il sistema che si occupera del processo di riconfigurazione. Tale area
non dovra essere interessata da tale processo per non comprometterne la fun-
zionalita.
Percio si dovra suddividere il dispositivo in due tipi di aree distinte: una che

12 CAPITOLO 1. RICONFIGURABILITA
si occupera della riconfigurazione del dispositivo, quindi sara una parte fissa
(non interessata dalla riconfigurazione), e una composta da uno piu moduli
riconfigurabili.
Anche se la riconfigurazione interna e piu difficile da realizzare rispetto a
quella esterna ha comunque l’indubbio vantaggio di creare un dispositivo
riconfigurabile stand-alone, che non necessita di supporti esterni.
1.3 Porta ICAP
Nel corso di questo lavoro di tesi prenderemo in considerazione le FPGA
che supportano la riconfigurazione interna. Nella famiglia delle Virtex-II e
Virtex-II Pro e Virtex-4 esiste un componente che prende il nome di Internal
Configuration Access Port (ICAP) che permette di farlo. L’ICAP permette
l’accesso al registro di configurazione del dispositivo, nonche il trasferimento
dati con tale registro, tramite un protocollo che e un subset del protocollo
della SelectMap[3]. Anche l’interfaccia e semplificata rispetto alla SelectMap,
permettendo comunque le operazioni di lettura e scrittura. Tramite la porta
ICAP il richiedente delle riconfigurazione ha la possibilita di intervenire sul-
la configurazione della stessa ed eventualmente modificarla. In particolare, il
processore puo andare a leggere la configurazione dell’FPGA, lavorando su una
porzione minima di dati chiamata ”frame” . Allo stesso modo puo scrivere una
nuova configurazione trasferendo sempre un frame alla volta, oppure passando
un bitstream differenza vero e proprio.
1.3.1 Descrizione componente
Passiamo ora ad illustrare brevemente il significato delle varie porte dell’inter-
faccia:
• I/O: sono rispettivamente le porte di input e output. Il bit 0 e il bit piu
significativo. Vengono selezionate in base al segnale presente sulla porta
WRITE.
• WRITE: questa porta viene utilizzata per discriminare il tipo di opera-
zione in corso. Se e Low indica che e un’operazione di scrittura, percio

1.3. PORTA ICAP 13
viene letto il dato presente sulla porta I . Se e High indica un’operazione
di lettura, percio il dato viene scritto sulla porta O.
• CE: chip enable, abilita le porte di lettura o scrittura. Se e Low abilita la
porta scelta in base al segnale presente su WRITE. Se e High disabilita
le porte di lettura e scrittura.
• BUSY: quando CE e Low, questa porta indica se l’ICAP puo accettare
un altro dato oppure no. Se Busy e Low indica che il prossimo dato
verra accettato sul fronte di salita del Clock quando entrambi CE e Write
saranno Low. Se e High allora l’ICAP rifiuta il dato attuale che dovra
essere ricaricato al prossimo fronte di salita del Clock. Comunque se si
usa il componente con una frequenza inferiore ai 50 MHz il Busy puo
essere ignorato, mentre e indispensabile al di sopra di 50 MHz.
• CCLK: e il clock entrante nel componente che si occupa della sincroniz-
zazione di tutte le operazioni di lettura e scrittura.
1.3.2 Implementazione
Virtex-II e Virtex-II Pro: in queste famiglie la porta ICAP e situata solo
nell’angolo in basso a destra dell’ FPGA.
Va sottolineato che qui le porte di input e di output funzionano solo ad 8-bit.
Tramite VHDL/Verilog e accessibile attraverso la primitiva ICAP VIRTEX2.
Virtex-4: a differenza delle due precedenti famiglie,qui si puo trovare la
porta ICAP sull’FPGA in due locazioni differenti, una in alto e una in basso.
L’implementazione ha due interfacce che condividono la stessa logica di
base. La sola differenza tra le due e la loro posizione sulla FPGA, e le
interconnessioni alle quali possono essere connesse. Da notare che le due
interfacce non devono mai essere attive allo stesso istante [6]. La presenza di
due accessi a tale porta, permette sia una maggiore flessibilita su dove poter
collocare il controller che si interfaccera con l’ICAP, sia la possibilita di poterli
utilizzare contemporaneamente in modo alternato.
Un’altra differenza e che le porte di input ed output sono a 32-bit.
Cio non esclude la possibilita di poter usare l’ICAP a 8-bit: infatti e presente

14 CAPITOLO 1. RICONFIGURABILITA
un opportuno parametro, che puo essere settato durante l’istanziazione, che
permette di specificare la grandezza del dato che si vorra mandare.
Infine, tramite VHDL/Verilog e accessibile attraverso la primitiva
ICAP VIRTEX4.
Figura 1.4: Interfaccie dell’ ICAP VIRTEX2 e ICAP VIRTEX4
1.3.3 Utilizzo
Va notato che per poter utilizzare questo componente, bisogna dotarlo di un
opportuno controller che sia in grado di interfacciarsi sul bus utilizzato per
poter dialogare con questa interfaccia. Oltre a funzioni di dialogo con il bus,
questo controller deve poter svolgere altre funzioni come la gestione del flusso
di dati, la lettura e scrittura di uno specifico frame.
Per poter ignorare il segnale di Busy esistono due alternative possibili:
• Free runnig Clock: si utilizza come clock per il componente quello
utilizzato per il bus. In questo caso il bus non deve avere una frequenza
maggiore di 50 MHz
• Controlled CCLK: si utilizza il clock del bus per controllare una
macchina a stati che genera, in maniera opportuna, il clock adatto per il
funzionamento dell’ICAP

1.4. BITSTREAM 15
Nota bene: sulle schede che usano dispositivi della famiglia delle Virtex 2
e Virtex 2Pro sono presenti dei pin che permettono di abilitare o disabilitare de-
terminati metodi di riconfigurazione. Per poter utilizzare il componente ICAP,
tali pin non devono trovarsi nella configurazione 101, che rende disponibile solo
le modalita JTAG o Boundary Scan , disabilitando l’ICAP.
Figura 1.5: Configurazione dei pin per utilizzo ICAP
1.4 Bitstream
Le FPGA possono essere utilizzate per creare dispositivi capaci di riconfigu-
rare tutta, o parte, della propria architettura al fine di modificare il proprio
comportamento a seconda delle esigenze dello sviluppatore. Una FPGA e in
grado di implementare al suo interno sia la riconfigurabilita di tipo statico
che quella di tipo dinamico. Come gia accennato, l’FPGA puo essere ricon-
figurata utilizzando il file binario generato dai software di sintesi. Tale file,
chiamato bitstream, e in grado di riconfigurare il dispositivo sia totalmente
che parzialmente, specificando la funzione di tutte le sue CLB e instradando
correttamente le linee di collegamento. Ad esempio supponiamo che esistano
due moduli che possono essere usati all’interno dell’architettura. Esisteran-
no percio un bitstream βA che configurera il dispositivo con il modulo A e
un bitstream βB che lo configurera con il modulo B. Pero l’utilizzo dei bit-
stream comporta la riconfigurazione dell’intero dispositivo, con conseguente

16 CAPITOLO 1. RICONFIGURABILITA
interruzione del servizio da parte del dispositivo durante il processo di riconfi-
gurazione. Questo e il caso della riconfigurazione statica. Per poter utilizzare
la riconfigurazione parziale si introduce il concetto di bitstream differenza: tale
file contiene solo le informazioni per passare da una configurazione all’altra del
dispositivo. L’utilizzo di questi bitstream comporta percio la modifica di solo
una parte del dispositivo, mentre l’altra puo continuare a lavorare. Inoltre
hanno il vantaggio di essere di dimensioni molto ridotte rispetto a quelli totali.
Tornando all’esempio precedente, esisteranno un bitstream βA−>B che perme-
ttera di passare dalla configurazione con il modulo A a quella con il modulo
B; esistera poi il bitstream βB−>A, che permettera il passaggio inverso.
Figura 1.6: Bitstream differenza e riconfiguarbilita parziale
Con due moduli ci saranno solo due bitstream differenza, ma con tre mo-
duli il numero cresce a sei, per poi passare a dodici con quattro moduli. Si
ha quindi il problema dell’elevato numero di bitstream differenza da conser-
vare in memoria. Anche con un numero di moduli piuttosto basso, e data la
scarsa disponibilita di memoria sulla FPGA, questo potrebbe diventare una
forte restrizione. Un altro approccio sarebbe quello di avere un bitstream che
istanzia il modulo in un’area vuota dell’FPGA (rappresentato da β−>A) e un
altro che rimuove il modulo dall’area in cui si trova (detto βA−>). In tal caso
ogniqualvolta si debba sostituire un modulo A con B, in una determinata area,
prima la si rende vuota con βA−> poi la si istanzia con B utilizzando β−>B.

1.5. IBM CORECONNECT 17
Figura 1.7: Bitstream differenza sbiancante
Questo procedimento prevede solo due bitstream differenza per ogni
modulo, il che si traduce in un notevole risparmio di spazio di memoria;
tuttavia si raddoppiano i tempi di riconfigurazione. Quindi in fase di
progettazione si dovra trovare un opportuno trade-off in base alle esigenze.
1.5 IBM CoreConnect
La tecnologia CoreConnect sviluppata da IBM e un sistema per la gestione
delle comunicazioni per applicazioni on-chip. A questa struttura vengono at-
tacati dei core, ovvero componenti che implementano unita a se stante di
logica2, provenienti da parti diverse per formare diverse architetture.
Come si puo vedere da figura 1.8, in questa tecnologia vengono implemen-
tati tre bus : Processor Local Bus (PLB),On-Chip Peripheral Bus (OPB) e
Device Control Register (DCR). Solitamente le periferiche piu veloci vengono
attaccate al PLB che presenta una maggiore velocita e minor latenza, mentre
all’OPB vengono attaccati i core piu lenti per ridurre il traffico sul PLB.
2Ad esempio un filtro, un DSP, un controllore della memoria, DMA . . .

18 CAPITOLO 1. RICONFIGURABILITA
Figura 1.8: Struttura della tecnologia CoreConnect dell’IBM
Processor Local Bus (PLB), e un bus sincrono caratterizzato da alte
prestazioni a cui solitamente si collega il processore dell’architettura (da qui il
Processor nel nome). Le sue implementazioni sono caratterizzate dalla possi-
bilita di avere il bus dei dati a 32, 64 o 128 bit, anche se il bus degli indirizzi
rimane sempre a 32 bit per tutte e tre le implementazioni. Oltre a prevedere le
normali operazioni di lettura e scrittura vi e anche la possibilita di effettuarle
in modalita burst, ovvero una volta ricevuta l’autorizzazione dall’arbitro, il
richiedente puo inviare o ricevere un pacchetto di dati ad ogni ciclo di clock.
On-Chip Peripheral Bus (OPB), bus sincrono piu lento e meno com-
plesso del precedente. Anch’esso ha la possibilita di essere usato a 32, 64 e 128
bit, permette le semplici operazioni di lettura e scrittura e in una modalita
burst semplificata rispetto a quella del PLB.
OPB-PLB bridge, e un bridge bidirezionale con un’unica limitazione
(prevista nello standard): il rapporto tra la frequenza di clock del PLB e quella
del OPB e una potenza (ovviamente intera) di due. Spesso nelle architetture
su FPGA si prende un esponente uguale a 0 in modo che i due bus risultino
isocroni e in questo caso si puo notare come, nonostante le prestazioni offerte
dai due bus siano comparabili in condizioni di lavoro medie, si voglia comunque
mantenerli separati per suddividere il traffico delle periferiche piu veloci da
quello delle piu lente.
OPB e PLB arbiter, entrambi i due arbitri hanno una struttura molto
simile, infatti li si puo vedere come due grossi multiplexer. Hanno in ingresso
tutti i segnali dei vari master e in uscita i segnali del bus verso i vari slave,

1.6. SOFTWARE UTILIZZATI 19
che vengono controllati da un master alla volta, dopo che essi hanno ricevuto
l’autorizzazione dall’arbitro.
Esiste una limitazione del numero di master che possono essere connessi all’ar-
bitro, dato che ogni master ha le sue linee dedicate per parlare con l’arbitro,
il che comporta linee dei dati indirizzi e controllo per ogni master, mentre non
si prevede una limitazione per quanto riguarda gli slave dato che condividono
lo stesso canale di comunicazione.
Device Control Register Bus (DCR), anch’esso e un bus sincrono con
10 bit per gli indirizzi e 32 per i dati. Permette il trasferimento dei dati
contenuti nei registri general purpose del processore alla logica slave connessa
al DCR, in questo modo si evita di salvare i registri di configurazione in
memoria, riducendo il carico sugli altri bus.
1.6 Software utilizzati
Nello corso di questo lavoro di tesi sono state usate le FPGA della Xilinx,
percio durante la fase implementativa sono stati utilizzati i software da loro
creati. In questo paragrafo verranno descritti brevemente.
1.6.1 ISE
ISE (Integrated Software Enviroment), e una suite di programmi che permet-
te lo sviluppo completo di un design partendo dallo schematico o dal codice
VHDL/Verilog. Programma centrale e senz’altro Project Navigator, attraverso
il quale e possibile gestire passo per passo il processo di implementazione con
la possibilita di richiamare tutti gli altri programmi della suite.
Principalmente e formato da:
• un editor che permette di lavorare con il codice, schematici o vincoli
fisici. Il piu utilizzato e l’editor di testo che permette la visualizzazione,
nonche la scrittura e modifica del codice VHDL/Verilog.
• una console nella quale si possono leggere tutte le informazioni relative
ai vari passi dell’implementazione, nonche eventuali messaggi di errore e
di warning

20 CAPITOLO 1. RICONFIGURABILITA
• un albero delle risorse nel quale e possibile vedere la struttura del com-
ponente sul quale si sta lavorando, nonche il dispositivo sul quale verra
implementato
• un menu delle funzioni dal quale e possibile accedere a tutte le funzioni di
ISE. Tramite esso si possono lanciare le varie fasi descritte nel paragrafo
1.1 e i relativi programmi che le svolgono.
E importante citare FPGA editor, utile per visualizzare il risultato del
processo di Place & Route in un disegno elettronico che mostra come verranno
effettivamente programmate e interconnesse le singole CLB e Switch Matrix.
Mette inoltre a disopsizione delle funzioni per la modifica del design anche se
le modifiche normalmente fatte sono molto piccole.
1.6.2 EDK
EDK(Embedded Development Kit), e un programma utilizzato per la gestione
degli IP-CORE, gia esistenti o creati e importati dall’utente, al fine di creare
un’architettura CoreConnect desiderata.
Per l’utilizzo delle sue funzioni si appoggia su ISE. Importanti da citare sono:
• Create/Import peripheral, tramite la quale e possibile gestire la creazione
di un nuovo IP-CORE oppure l’importazione di uno gia esistente, rifer-
endosi ad un progetto di ISE oppure ai file di codice e gli NGC che
formano il core.
• Application, tramite il quale e possibile aggiungere e gestire i sorgenti
software che gireranno sul processore (PowerPC o MicroBlaze). Il lin-
guaggio riconosciuto e l’ANSI-C. Una volta compilato, EDK provvedera
ad unirlo al bitstream che descrive l’architettura creata.
E importante citare anche SDK, un ambiente di sviluppo che si appoggia
ad Eclipse per la gestione delle librerie e i file .h usati nei programmi che poi
gireranno sulla FPGA. Tra queste e importante xparameters.h che contiene
tutti i parametri dei vari IP-CORE dell’architettura, tra cui anche lo spazio
degli indirizzi a loro riservato.

Capitolo 2
Stato dell’Arte
Per poter utilizzare la porta ICAP, non la si puo collegare semplicemente al
bus del sistema, infatti si deve creare un componente opportuno che ha come
compito essenziale quello di permettere il dialogo tra i due. Principalmente
come struttura di collegamento tra i vari core dell’architettura viene usato il
CoreConnect dell’IBM (vedi paragrafo 1.5) che mette a disposizione i bus OPB
e PLB per l’interfacciamento.
Le interfaccie sul bus possono essere slave o master : solitamente le slave per-
mettono funzioni limitate al solo dialogo che e permesso nel momento in cui un
master le designa tramite il bus degli indirizzi; le interfacce master presentano
il vantaggio di poter richiedere i bus quando lo ritengono necessario, percio
olter ad essere piu complesse, mostrano anche funzioni migliori rispetto alle
slave.
Oltre alle interfacce, alcune volte si ritiene necessario l’utilizzo di una memoria
interna per poter gestire il flusso dei dati oppure anche un protocollo di comu-
nicazione che mette a disposizione funzioni piu complesse rispetto alle normali
funzioni di lettura e scrittura.
Nel corso di questo capitolo verranno presi in analisi tre core gia esistenti che
si interfacciano con il componente ICAP, spiegandone il funzionamento, pregi
e difetti di ognuno.
I core che prenderemo in considerazione saranno:
• OPB HWICAP reperibile nella libreria di EDK della Xilinx [11]
• ICAP DRESD sviluppato nel laboratorio di microarchitetture presso
il Politecnico di Milano dal gruppo D.R.E.S.D. . [9]
21

22 CAPITOLO 2. STATO DELL’ARTE
• PLBICAP sviluppato presso la Technische Univetsitat Munchen[2]
2.1 OPB HWICAP
In questo paragrafo verra preso in considerazione un componente gia esistente
nella libreria di EDK : l’OPB HWICAP; ne verranno analizzate l’interfaccia su
bus, struttura interna e funzionamento, terminando con conclusioni sui pregi e
difetti di questo dispositivo. Tramite il dispositivo e possibile effettuare sia la
configurazione, sia readback, cioe la possibilita di leggere lo stato del registro
di configurazione. Questo permette di verificare la correttezza della corrente
configurazione di ogni CLB e IOB, nonche il valore corrente nelle LUT RAM
e nelle BRAM.
2.1.1 Interfaccia, struttura e funzionamento
Interfaccia su bus: come si puo subito capire dal nome, l’HWICAP ha una
interfaccia slave sul bus OPB. Questa parte del dispositivo si occupa solamente
di tradurre i segnali che arrivano dal bus, in segnali interpretabili dalle parti
piu interne.
Figura 2.1: Interfaccia dell’OPB HWICAP

2.1. OPB HWICAP 23
Struttura interna: oltre all’interfaccia e alla porta ICAP, questo
dispositivo e anche composto da:
• un controllore che si occupa di decodificare i comandi che gli vengono
comunicati da bus, occupandosi della gestione del flusso di dati da e/o
verso la BRAM con il Bus
• una memoria costituita da una Block RAM (capacita 512 Byte),
che permette l’interfacciamento con i dati sia a 8 che a 32 byte
contemporaneamente
• un controller che si occupa della gestione dei dati da e/o verso l’ICAP
con la BRAM
Figura 2.2: OPB HWICAP
Funzionamento: il processo di riconfigurazione e portato a termine da
un meccanismo di lettura-modifica-scrittura. Per modificare il circuito del-
l’FPGA, la periferica determina quali frame di configurazione devono essere
modificati, poi legge il contenuto di ogni frame, uno alla volta da una BRAM.
Il contenuto di ogni frame e modificato prima di essere scritto dall’ICAP. Il
meccanismo di lettura-modifica-scrittura e effettuato un singolo frame alla vol-
ta. Per quanto riguarda il readback, i frame sono riletti dentro la BRAM e poi
estratti i bit che interessano.

24 CAPITOLO 2. STATO DELL’ARTE
2.1.2 Pro e contro
Una buona caratteristica di questo componente e la possibilita di trasferire
blocchi di 4 byte per volta dal bus, pero dato il funzionamento a singoli byte
della porta ICAP, si e riscontrata la necessita di inserire un dispositivo che
permettesse sia la lettura che la scrittura a 8 e 32 bit contemporaneamente.
Questo componente e stato implementato tramite un controllore di bram che
si occupa della gestione degli indirizzi.
L’utilizzo di bram come memoria fa in modo che solo la restante parte del
core venga implementata in slice, il che rende l’occupazione d’area per questo
componente trascurabile. Tuttavia la sua modalita di funzionamento lo rende
particolarmente lento e la mancanza di segnali di interrupt implica il fatto che
per tutto il tempo in cui e in funzione esso tiene occupato anche il bus che non
puo rendersi disponibile per altri scopi.
Infine la sua interfaccia e solo sul bus OPB, il che lo rende ancora piu lento in
una architettura che usa il PowerPc: infatti in una architettura di questo tipo,
i controller delle bram si trovano sul bus PLB, percio, per trasferire dei dati
verso l’HWICAP, si rende necessario attraversare anche un bridge PLB-OPB.
Inoltre la scarsa documentazione messa a disposizione della stessa Xilinx ne
rende difficile l’utilizzo.
2.2 ICAP DRESD
Questa versione del gestore della riconfigurabilita e stato sviluppato nel labo-
ratorio di microarchitetture del Politecnico di Milano, all’interno del gruppo
D.R.E.S.D. . Questo componente presenta enormi differenze rispetto all’HW-
ICAP e, nonostante sia piu semplificato rispetto a quello precedente, permette
sia la riconfigurazione sia il readback.
2.2.1 Interfaccia, struttura e funzionamento
Interfaccia: una prima differenza risiede nel fatto che presenta un’interfaccia
sul bus PLB anziche sull’OPB, seppur rimane un’interfaccia slave. Questa
parte del componente permette sempre di dialogare con il bus, anche se
questa volta risulta un po’, ma non molto, piu complesso. Va notato che
normalmente il bus PLB trasferisce 64 bit alla volta, per questo all’interno

2.2. ICAP DRESD 25
dell’interfaccia e predisposta una parte apposita per la selezione della word
d’interesse, scelta fatta in base al valore del segnale Byte enable del PLB.
Struttura interna: la struttura interna e molto semplice, dato che e
composta solamente dall’interfaccia IPIF e da una macchina a stati che serve
per il trasferimento dei dati da e verso l’ICAP. Questa macchina a stati non
prevede l’utilizzo del segnale di busy dell’ICAP, percio, come gia accennato,
si dovra o far funzionare il PLB a 50 MHz oppure si deve controllare il Clock
dell’ICAP, in modo tale da farlo andare al massimo a 50 MHz.
Funzionamento: l’utilizzo di questo componente e molto semplice: si
invia il bitstream in blocchi di 8 bit per volta (la posizione del byte deve essere
quella meno significativa), utilizzando la funzione XIo Out8(Address,Data)
della libreria xio messa a disposizione da SDK. Nel campo Address si deve
indicare il BASEADDRESS del componente che si puo o inserire di vol-
ta in volta nel programma, una volta assegnati gli indirizzi con EDK, op-
pure importando la libreria xparameters e richiamando il base address at-
traverso XPAR BASEADDR NOMEDELL’ISTANZA. Ad esempio se il com-
ponente si chiamasse ICAP CORE 0 (lo 0 indica il numero dell’istanza una
volta che verra usato in EDK) esistera in xparameters una costante di nome
XPAR BASEADDR ICAP CORE 0 che conterra il suo base address. Come
Data bisognera inserire il Byte da passare.
2.2.2 Pro e Contro
L’occupazione di questo componente e relativamente piccola rispetto all’HW-
ICAP, grazie alla sua semplicita, dovuta soprattutto al suo funzionamento a 8
bit che rende il componente libero di dialogare direttamente con l’ICAP senza
l’utilizzo di registri che permettano il passaggio da 32 bit a 8 bit. Inoltre, come
appena descritto, e anche molto piu facile da utilizzare rispetto al precedente.
Comunque questa semplicita viene pagata proprio dal suo funzionamento a
8 bit, che rallenta in modo considerevole la velocita di trasferimento verso
l’ICAP. Inoltre, ignorando il segnale di busy dell’ICAP, si rallenta ancor di piu
la velocita di trasferimento. Un’altra limitazione e determinata dalla sua sola
interfaccia sul bus PLB che ci riporta al problema analogo, ma sul versante

26 CAPITOLO 2. STATO DELL’ARTE
opposto, che ha l’HWICAP : in una architettura con MicroBlaze si dovra
passare per un Bridge per arrivare sul PLB e infine a questo componente.
2.3 PLBICAP
Nella creazione di questo componente e stato preso in considerazione lo spinoso
problema dell’accelerazione del processo di riconfigurazione.
Accelerazione raggiunta sia dalla presenza di un DMA nell’interfaccia del com-
ponente, sia soprattutto alla compressione dei bitstream legata allo sviluppo
di questo componente.
2.3.1 Interfaccia, struttura e funzionamento
Interfaccia: come appena accennato, questo controller ha un DMA (Direct
Memory Access) presente nella sua interfaccia che deve essere, ovviamente,
master sul bus PLB.
Struttura interna: oltre al gia citato DMA, l’interfaccia master, e un con-
troller per l’ICAP, e presente anche un registro di tipo FIFO, per la corretta
gestione del flusso di dati.
Funzionamento: data la presenza del DMA, il processore deve solo indi-
care l’indirizzo iniziale e finale dove andare a prendere il bitstream, che dovra
gia essere memorizzato in una parte accessibile dall’architettura. Una volta
che il processo di riconfigurazione ha inizio, il DMA continuera a fare dei
trasferimenti in modalita burst 1 sul bus.
2.3.2 Pro e Contro
L’indubbio vantaggio di questo componente e la presenza del DMA. Essa per-
mette al processore di poter lavorare senza doversi occupare del trasferimento
dati, aumentandone anche la velocita. Difatti in questo caso i dati vengono
presi direttamente dalla memoria, anziche passare prima dal processore,
inoltre la modalita burst permette di evitare la richiesta di utilizzo del bus
ogniqualvolta si richieda un trasferimento di dati. Da notare che i tempi di
1si indica con burst un trasferimento che non richiede piu di chiedere all’arbitro il
permesso per utilizzare il bus

2.3. PLBICAP 27
riconfigurabilita raggiunti da questo componente sono in maggior parte legati
alla compressione dei bitstream che ne riduce la grandezza in percentuale
maggiore rispetto ai bitstream differenza.
In tabella 2.1 sono riassunte le principali caratteristiche tecniche dei core
visti in questo capitolo:
Caratteristiche/Core OPB HWICAP ICAP DRESD PLBICAP
Interfaccia OPB slave a 32 bit PLB slave a 8 bit PLB master DMA(bus width n.d.)
Memoria SI NO SI
Dimensione memoria 512 byte / 1024 byte
Implementazione memoria 1 BRAM / 2 BRAM
Gestione handshaking icap SI NO SI
Frequenza funzionamento ICAP OPB CLK ≤ 50MHz PLB CLK
Tabella 2.1: Riassunto delle caratteristiche principali dei core di
riconfigurazione visti in questo capitolo


Capitolo 3
DRC
Nel capitolo precedente sono stati analizzati dei controllori dell’ICAP tuttora
esistenti, che tuttavia presentano lo svantaggio di non utilizzare la velocita
dell’ICAP al massimo delle sue capacita. Per tempo di riconfigurazione si
intende l’intervallo di tempo tra il passaggio del primo frame all’ICAP, fino
alla computazione dell’ultimo. Un problema molto spinoso nei sistemi riconfi-
gurabili e l’accelarazione del processo di configurazione. Questo e un aspetto
molto importante, in quanto permette di creare architetture piu complesse e
di aumentare l’affidabilita di quei sistemi che per vari motivi richiedono una
veloce risposta. Tutti i controller visti nel Capitolo 2 presentano la possibilita
di essere interfacciati solo su un determinato bus e utilizzano sempre la stessa
quantita di memoria, rendendoli poco adattabili alle varie architetture.
In questo capitolo verra analizzato il controller di riconfigurabilita creato nel
corso di questo lavoro di tesi.
29

30 CAPITOLO 3. DRC
3.1 Problematiche
Tutti i controller tuttora esistenti presentano varie caratteristiche che rallen-
tano il processo di riconfigurazione, talvolta queste caratteristiche negative
vengono controbilanciate dalle semplicita implementative di questi core. Si
e visto che l’HWICAP ha come inconveniente il suo protocollo di modifica
del registro di configurazione: infatti legge la configurazione esistente tramite
l’ICAP e la salva su una sua cache interna, il processore la modifica e la ri-
manda all’ICAP. L’inconveniente dell’ICAP DRESD e il suo lavorare a 8 bit
e vincolare il clock dell’ICAP a meta del clock del processore: questo aspetto
rallenta molto sia il throughput dell’ICAP, sia quello del bus che deve ogni
volta aspettare che l’ICAP abbia finito di lavorare. Del terzo core non si puo
dire molto date le scarse informazioni a disposizione. Tuttavia si puo notare
che oltre la presenza del DMA e all’utilizzo del segnale di busy dell’ICAP,
non si e fatto niente dal punto di vista hardware per velocizzare il processo di
riconfigurazione, aspetto preso in considerazione con la sola compressione del
bitstream.
Infine tutti controller esaminati finora hanno l’interfaccia su un unico bus,
quindi, per poter essere usati, si deve prevedere l’utilizzo di bridge da un bus
ad un altro, ove quella richiesta per il controller non sia presente nell’architet-
tura. Questo comporterebbe un grosso svantaggio in quanto il passaggio per il
bridge rallenterebbe il trasferimento dei dati sul bus, dunque anche il processo
di riconfigurazione, impedendo anche l’uso del bus ad altri core che necessitano
del bus.
Vari aspetti devono essere presi in considerazione nella creazione di un con-
troller che deve da un lato velocizzare il processo di riconfigurazione, dall’altro
non deve occupare un eccessivo numero di risorse.
L’unico modo per velocizzare il processo di riconfigurazione e tentere di utiliz-
zare il 100% del throughput dell’ICAP: questa e la massima velocita con cui
si potra riconfigurare.
Il secondo aspetto deve tenere in considerazione parametri come l’overhead sul
bus e l’occupazione di area sulla scheda. Un modo per aumentare il through-
put del bus puo essere quello di inviare pacchetti da 32 bit invece che da 8 bit,
tuttavia bisogna tenere conto che l’ICAP funziona a 8 bit: questo comporta
l’ulteriore problema di introdurre una coda che divida i 32 bit in quattro pac-

3.2. IL CONTROLLER 31
chetti da 8 bit da passare all’ICAP.
L’introduzione di questo meccanismo puo portare a pensare che il throughput
del bus si maggiore di quello con cui puo lavorare l’ICAP: questo non e del tutto
vero. Infatti si deve tenere conto che i dati vengono inviati dal processore che
deve prima reperirli dalle memorie oppure dalla porta seriale, invece l’ICAP
puo accedere direttamente ai dati che saranno gia presenti nella coda. Percio,
anche se si e aumentata sensibilmente la velocita di riconfigurazione, si ha
ancora una grande percentuale di throughput dell’ICAP inutilizzato.
Si puo quindi pensare di trasferire una parte del bitstream in una apposi-
ta memoria interna al controllore, memoria che comunque sara minore della
grandezza del bitsream, e poi far partire il processo di riconfigurazione una
volta che la memoria sia stata riempita per una certa percentuale. Si viene a
creare cosı una sorta di ”vantaggio” a favore del bus, che permette ad entrambi
di lavorare al massimo del loro potenziale.
Detto questo bisogna tener conto che la grandezza della memoria non dovra
occupare una percentuale rilevante della FPGA, altrimenti non varrebbe la
pena l’utilizzo di un tale controller.Per quanto riguarda la versatilita sul bus,
basta creare delle interfaccie intercambiabili in modo tale da poter avere la
massima liberta possibile nella creazione dell’architettura.
3.2 Il controller
Nel corso di questo paragrafo verra esposto nel dettaglio il controller DRC:
si procedera alla descrizione della struttura interna e del funzionamento del
componente, concludendo con la spiegazione delle sue implementazioni.
3.2.1 Struttura interna
Il DRC e composto da tre parti principali:
• l’interfaccia IPIF che puo essere sia su bus PLB che su bus OPB;
• il controller vero e proprio che comprende :
– una buffer a 32 bit di grandezza variabile

32 CAPITOLO 3. DRC
– una coda a 8 bit per l’invio dei dati all’ICAP
– registri di controllo
– due macchine a stati: una per la lettura e una per la scrittura su
buffer
• e l’ICAP vero e proprio.
Figura 3.1: Struttura interna DRC
3.2.2 Funzionamento
Prima di passare a descrivere l’implementazione nel dettaglio, verra prima
analizzato il funzionamento genereale del DRC.
Come gia accennato, la velocita con cui l’ICAP processera i dati sara mag-
giore della velocita con cui il bus riuscira a passarglieli, quindi si e prevista
una memoria tampone che verra precaricata prima di iniziare il processo di
riconfigurazione. Comunque non verra riempita totalmente, si arriva fino ad
una percentuale della memoria (denominata l), in modo tale da permettere
al bus di continuare con l’invio del bitstream mentre l’ICAP ha iniziato a
lavorare.
In tal modo si ottiene che per un certo lasso di tempo, sia bus che ICAP
lavorano al massimo possibile, garantento un aumento nella velocita di ricon-
figurazione. Una volta che l’ICAP ha ”raggiunto” il bus, smette di lavorare
in attesa di altre ”l” word. Quando la soglia verra superata ancora, l’ICAP
riprendera a lavorare.

3.2. IL CONTROLLER 33
Tuttavia va notato che non sempre accade che l’invio dell’ultimo pacchetto si
ha mentre l’ICAP e in funzione. Si ha quindi la possibilita di trovarsi in una
situazione tale per cui l’ICAP abbia raggiunto il bus, e che stia aspettando
altre ”l” word, mentre la rimantente parte del bitstream sia minore di l: ci
si troverebbe quindi ad aspettare indefinitamente l’arrivo di un numero di
pacchetti che permettano il superamento della soglia.
Si e quindi previsto un flag che indichi la presenza dell’ultimo pacchetto in
memoria e che, quando viene attivato, fara partire il processo di riconfigu-
razione anche se nel buffer ci saranno meno di l pacchetti. Un bitstream,
tuttavia, non e sempre multiplo di quattro byte: si ha quindi un problema
nella gestione dell’ultimo pacchetto che puo avere una lunghezza variabile tra
uno e tre byte.
Per evitare di passare all’ICAP piu byte di quelli contenuti nel bitsream, com-
promettendo il processo di riconfigurazione, si e pensato di inviare l’ultimo
pacchetto specificando nell’indirizzo che e l’ultimo, indicando anche quanti
sono i byte effettivi che deve leggere.
Questo e l’unico caso in cui si utilizza il bus degli indirizzi per indicare qual-
cosa di diverso dal solo BASEADDRESS: l’onere dell’indirizzamento del buffer
e lasciato a dei registri ad auto incremento che indicheranno gli indirizzi da
cui leggere e scrivere, e previsto anche un registro addizionale per indicizzare
i singoli byte all’interno di una word (dipende dall’implementazione, guardare
paragrafo successivo). Nel controller e inoltre presente un una coda che ha il
compito, data una word, di passare all’ICAP i singoli byte. Va infine detto che
il buffer a 32 bit ha la possibilita di poter variare la sua grandezza in modo
tale da permettere di adattarlo all’architettura sulla quale prestera servizio.
3.2.3 Implementazione Hardware
Esistono diverse implementazoni del DRC, ognuna delle quali presenta
modalita di funzionamento leggermente diverse dalle altre, anche se manten-
gono lo stesso comportamento generale. Tutti i file che lo compongono sono
stati scritti in VHDL.
Sono due le principali caratteristiche che differenzaino le varie implementazioni
di questo controller :
• il tipo di interfaccia sul bus :

34 CAPITOLO 3. DRC
– PLB
– OPB
• dove viene allocato il buffer interno al controllore :
– in Slice
– in BRAM
La possibilita di cambiare l’interfaccia permette al DRC di connettersi a
qualsiasi bus si voglia; tuttora vengono usati principalmente i bus PLB e OPB
del CoreConnect dell’IBM, ma nulla vieta di poter creare un’altra interfaccia
su un altro bus che possa essere aggiunta alle altre purche mantenga lo stesso
protocollo con il controller. Anche se su bus diversi, le due interfaccie presen-
tano le stesse funzionalita, infatti entrambe hanno un’interfaccia slave sul bus
e il loro unici compiti sono quelli di ricevere i pacchetti dal bus e/o l’invio di
pacchetti e ackwnoledge dal controller. Va notato che come occupazione di
area sul dispositivo, l’interfaccia PLB sara sempre maggiore di quella su OPB,
dato il maggior numero di segnali e un protocollo un po’ piu complesso da
gestire.
Tuttavia la differenza sostanziale esistente tra le varie implementazioni e nella
scelta del tipo di memoria usata per il buffer : si puo scegliere se utilizzare
le Slice come memorie oppure utilizzare direttamente le BRAM. Entrambe
hanno lo stesso funzionamento anche se i sistemi per la gestione degli indirizzi
e nell’implementazione della coda che effettua la conversione da 32 a 8 bit sono
leggermente diversi.
L’interfaccia del controller e la stessa per entrambe le implementazioni:
• Input
– Data : std logic vector (0 to 31);
– Address : std logic vector(0 to 31);
– reset : std logic;
– Enable : std logic;
– Clk : std logic;
– RNW : std logic;

3.2. IL CONTROLLER 35
• Output
– read data : std logic vector(0 to 31);
– buffer ack : std logic
Ora si passera a descrivere in dettaglio i due file VHDL che descrivono il
comportamento dei due controller:
slice : il buffer viene implementato tramite un array di larghezza 32
bit e di profondita pari ad un generico chiamato BUFFER SIZE. La coda
viene realizzata nello stesso modo, ma ha una larghezza da 8 bit e una
profondita di 4, ovvero e una coda di 4 byte. Gli indirizzi vengono gestiti da
tre registri:
• NAW che indica il prossimo indirizzo dove scrivere
• CAR32 che indica la posizione corrente di dove andare a leggere la word
nel buffer
• CAR8 che indica quale byte inviare all’icap della coda
A parte l’ultimo che e di tipo integer in un range da 0 a 4, i primi due sono
di tipo integer di lunghezza compresa tra 0 e BUFFER SIZE, in modo tale da
occupare solo le risorse strettamente necessarie.
La gestione dell’ultimo pacchetto e affidato a tre registri :
• last byte che indica la presenza dell’ultimo pacchetto nel buffer
• last address che indica la posizione dell’ultimo pacchetto nel buffer
• LAST che indica il numero di byte da leggere dall’ultima word
Infine il registro rec permission indica se procedere o meno alla fase di
riconfigurazione.
Il buffer ha un comportamento di tipo FIFO che viene realizzato tramite
un’apposita gestione dei registri di indirizzamento: innanzitutto sono registri
che vengono autoincrementati ogni volta che c’e una operazione di lettura
e scrittura e, una volta terminato lo spazio di indirizzamento, ripartono

36 CAPITOLO 3. DRC
dal primo indirizzo in modo tale da ottenere un indirizzamento ciclico. Nel
controller sono presenti due macchine a stati, che hanno il compito di gestire in
modo distinto le operazioni di lettura e di scrittura. Entrambe hanno la stessa
struttura di base, che poi si differenziera nella operazione di memoria svolta
determinando un differente incremento di registro. Questa differenziazione dei
processi di lettura e di scrittura e quello che permette al controller l’accesso
della memoria sia in letura che in scrittura contemporaneamente. All’inizio le
macchine si troveranno in uno stato di RESET, che ha il compito particolare
di azzerare i registri di indirizzamento e di inizializzare gli altri. Si passera poi
in un altro stato dove si attendera la richiesta di scrittura di un pacchetto da
bus oppure la richiesta di lettura di un byte dall’ICAP.Nello stato successivo si
esegue l’operazione richiesta e l’invio dell’ackwnoledge del suo completamento,
per poi passare direttamente ad uno stato in cui si aggiornano i contatori
e infine si arriva ad uno stato nel quale si attende che la richiesta venga
terminata. Poi si ritorna nello stato di attesa della richiesta. In figura 3.2
viene rappresentato schematicamente lo schema della macchina a stati.
Figura 3.2: Gestione delle operazioni di lettura e scrittura

3.2. IL CONTROLLER 37
Infine la gestione del flusso dei dati verso l’ICAP puo essere schematizzata nel
modo segnuente:
1. pacchetti da 32 bit arrivano dal bus e vengono salvati nel buffer, nella
locazione indicata da NAW
2. quando si raggiunge la condizione di start, rec permission viene imposta-
to a 1 e ha inizio il processo di riconfigurazione
3. se il processo di riconfigurazione e attivo viene prelevata la word indicata
da CAR32 e viene messa nella coda a 8 bit
4. se il processo di riconfigurazione e attivo il byte indicato da CAR8 viene
passato all’ICAP
5. quando CAR8 ha passato tutti e 4 i byte contenuti nella coda, ritorna a
segnare la posizione zero e si incrementa CAR32 di uno
In figura 3.3 si puo vedere la struttura del buffer implementato in slice.
Figura 3.3: Flusso dati verso l’ICAP

38 CAPITOLO 3. DRC
bram : in questo caso sia il buffer a 32 bit che quello a 8 bit sono imple-
mentati nelle BRAM, ognuna delle quali puo contenere fino a 512 Byte. In
quasto caso si ha il vantaggio di poter creare delle interfaccie alla memoria
tramite le quali si ha la possibilita di accedervi sia a 32 bit che a 8 bit con due
porte differenti, ovvero queste interfaccie prevedono una gestione di uno stesso
spazio di memoria con accessi sia a 32 bit che a 8 bit. In questo caso sia il
buffer da 32 che la coda da 8 sono la stessa entita, quindi in lettura non si avra
piu il problema di estrarre i singoli byte dalle word, dato che in questo caso
vi si puo accedere direttamente. Anche in questa implementazione si hanno
le due macchine a stati per la gestione della lettura e della scrittura, e si ha
lo stesso modo di segnalazione dell’ultimo pacchetto. Differenza sostanziale
si ha nella gestione del flusso dei dati verso l’ICAP, infatti esisteranno solo
due registri degli indirizzi, uno per scrivere a 32 bit e l’altro per leggere a 8
bit.Questo permette nella gestione dell’ultimo pacchetto di specificare diretta-
mente la posizione dell’ultimo byte, in quanto si puo direttamente calcolare il
suo indirizzo, che verra segnato come ultimo byte da leggere.
In questa implementazione non c’e un buffer size che indica indica la grandezza
della memoria, infatti usando un certo numero di BRAM, non avrebbe alcun
senso sfruttarle solo in parte. Infatti in questo caso si avranno dei generics
relativi alla grandezza dei bus degli indirizzi e quanto sono grandi NAW e
CAR8, che saranno multipli di 512. Da notare che in questo caso CAR8 sara
sempre 4 volte NAW e gli indirizzi della parte a 8 bit avranno sempre 2 bit in
piu rispetto alla parte a 32.
3.3. CONCLUSIONI 39
3.3 Conclusioni
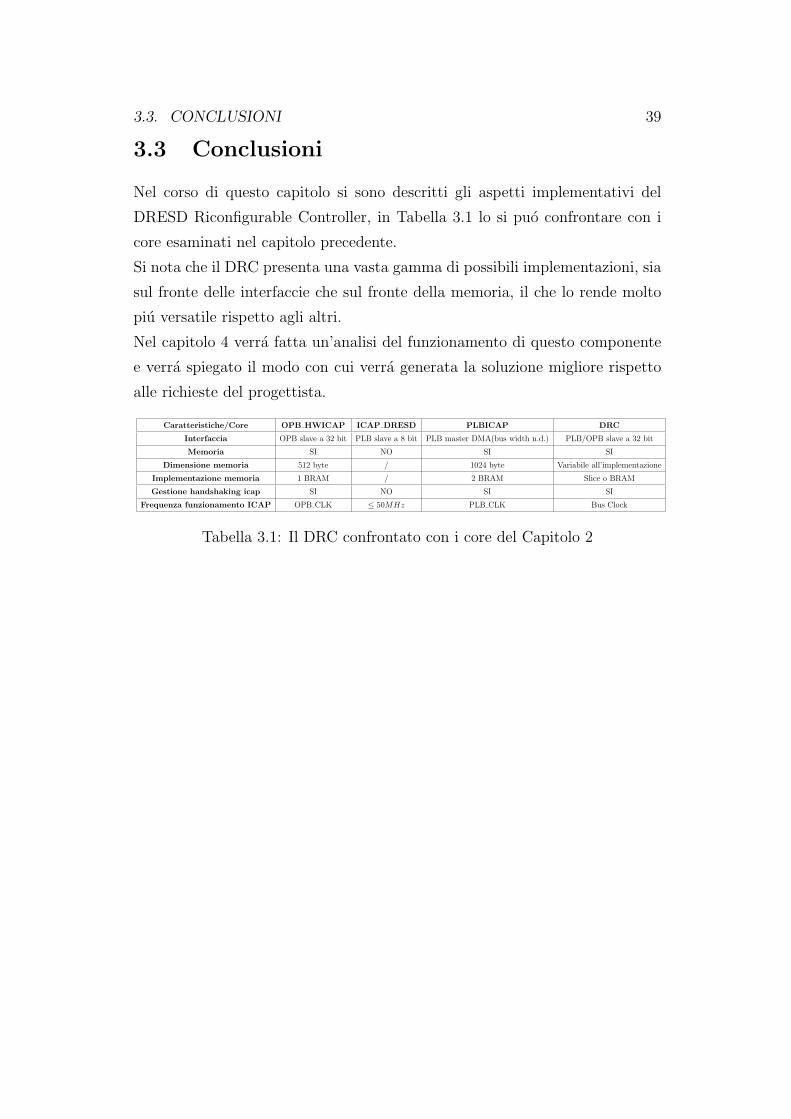
Nel corso di questo capitolo si sono descritti gli aspetti implementativi del
DRESD Riconfigurable Controller, in Tabella 3.1 lo si puo confrontare con i
core esaminati nel capitolo precedente.
Si nota che il DRC presenta una vasta gamma di possibili implementazioni, sia
sul fronte delle interfaccie che sul fronte della memoria, il che lo rende molto
piu versatile rispetto agli altri.
Nel capitolo 4 verra fatta un’analisi del funzionamento di questo componente
e verra spiegato il modo con cui verra generata la soluzione migliore rispetto
alle richieste del progettista.
Caratteristiche/Core OPB HWICAP ICAP DRESD PLBICAP DRC
Interfaccia OPB slave a 32 bit PLB slave a 8 bit PLB master DMA(bus width n.d.) PLB/OPB slave a 32 bit
Memoria SI NO SI SI
Dimensione memoria 512 byte / 1024 byte Variabile all’implementazione
Implementazione memoria 1 BRAM / 2 BRAM Slice o BRAM
Gestione handshaking icap SI NO SI SI
Frequenza funzionamento ICAP OPB CLK ≤ 50MHz PLB CLK Bus Clock
Tabella 3.1: Il DRC confrontato con i core del Capitolo 2


Capitolo 4
DRCgen
DRCgen e uno strumento software che ha il compito di trovare la migliore con-
figurazione del DRC, adattandone le caratteristiche allo scenario in cui dovra
essere collocato, e garantendo, ad esempio, i vincoli su throughput e l’area
imposti dall’utente. DRCgen basa la sua efficacia su un modello formale del
DRC, che consiste in una modellizzazione dei parametri che ne caratterizzano
il funzionamento. La modellizzazione garantisce una stretta affidabilita dei
risultati al mondo con cui il DRC dovra relazionarsi.
4.1 Analisi dei requisiti e modellizzazione
DRCgen e un software sviluppato in linguaggio C che ha la capacita di generare
il miglior DRC possibile nei confronti dello scenario di riconfigurazione in cui
esso dovra essere utilizzato. Prima di sviluppare DRCgen, e stato necessario
modellizzare il DRC in modo da comprendere come le sue grandezze descrittive
siano fra loro relazionate. Una corretta modellizzazione del sistema e con-
dizione necessaria al raggiungimento della aderenza dei risultati del software
al mondo reale.
4.1.1 Grandezze descrittive del DRC
Un sistema dinamico[13] e un sistema che evolve nel tempo, indicando con
questo termine che sia l’ingresso che l’uscita si sviluppano nel tempo. In gen-
erale l’uscita all’istante t di un sistema dinamico non dipende solo dall’ingresso
del sistema allo stesso istante, ma da una grandezza, detta stato, che rappre-
41

42 CAPITOLO 4. DRCGEN
senta la storia passata degli ingressi del sistema.
Il DRC e, a tutti gli effetti, un sistema dinamico in quanto e dotato di un
ingresso, di un uscita e di uno stato. L’ingresso e rappresentato dalle linee
che dal bus arrivano al DRC, l’uscita dalle linee che dal DRC vanno verso
l’ICAP, mentre lo stato e rappresentato dal buffer. Visto che i dati sul bus, nel
buffer e verso l’ICAP variano nel tempo, si puo considerare il DRC un sistema
dinamico.
Fatte queste considerazioni, non resta altro che identificare quali grandezze
governano il sistema e come sono correlate tra loro.
Il DRC e caratterizzato da due principali parametri:
• TDRC = Throughput di riconfigurabilita [MBytessec
]
• A = Area occupata [slices]
Molte applicazioni richiedono dei thruoughput di riconfigurabilita alti con il
minor consumo di area possibile, quindi si puo subito affermare che un otti-
mo DRC e quello che riesce a massimizzare il throughput di riconfigurabilita,
minimizzandone l’area occupata. Ovviamente le tendenze sono opposte, cioe
al crescere del throughput di riconfigurabilita, l’area occupata tende a crescere
e viceversa, ma comunque e possibile trovare la soluzione che ottimizza il rap-
porto tra il throughput che si vuole ottenere e l’area che si vuole occupare.
Prima di addentrarsi nelle relazioni che governano questo meccanismo, e
opportuno e necessario introdurre altri parametri:
• Tbus = throughput del bus [MBytessec
]
• Ticap = throughput della porta ICAP [MBytessec
]
Questi due parametri descrivono l’ingresso e l’uscita del sistema. Il primo
parametro dipende fortemente dallo scenario in cui si trova il DRC, come il tipo
di bus scelto e il numero di periferiche collegate, mentre il secondo identifica il
throughput della porta ICAP, che e noto a priori e non dipende dallo scenario.
Prima di continuare nella analisi formale, e necessario considerare che vale la
seguente relazione:
Tbus < Ticap (4.1)

4.1. ANALISI DEI REQUISITI E MODELLIZZAZIONE 43
Modellizzazione del buffer: Il buffer ha il compito di salvare i dati in arrivo
da bus prima di passarli all’ICAP. Raggiunta una soglia di attivazione l’ICAP
si attiva e inizia a processare i dati mentre il bus continua a caricarli. L’ICAP
interrompera il lavoro solo se raggiunge la cella in cui deve scrivere il bus. Se
il buffer e sufficientemente grande da non interrompere mai il funzionamento
dell’ICAP il vantaggio ottenuto sara tale da invertire la Relazione 4.1.
Una volta invertita la 4.1, non sara piu necessario aumentare la dimensione
del buffer in quanto il throughput di riconfigurabilita non migliorerebbe. Pos-
siamo quindi anticipare che la grandezza del buffer non deve superare quella
grandezza capace di invertire la 4.1.
In definitiva il buffer e modellizzabile come in Figura 4.1:
Figura 4.1: Buffer del DRC
Esso e dotato di un ingresso che trasferisce dati con un throughput di Tbus e
una uscita che estrae dati dal buffer ad una velocita di Ticap. A questi due
parametri, che sono gli stessi visti in precedenza, e possibile aggiungere:
• L = dimensione del buffer in byte
• l = livello di attivazione dell’icap, cioe il livello dal quale inizia il
trasferimento dei dati, quindi la riconfigurazione.
• α = lL
= indice del margine di occupazione dei dati nel buffer

44 CAPITOLO 4. DRCGEN
Una corretta modellizzazione di questi parametri garantisce prestazioni
elevate al DRC. α indica di quanto margine e dotato il buffer. In linea del
tutto teorica, si potrebbe impostare α a 1, in quanto Tbus < Ticap ma, dato
che questa relazione non si puo considerare valida in ogni singolo istante, si
munisce il buffer di una area tampone per evitarne il piu possibile un completo
riempimento. Risultati sperimentali mostrano che un valore di α compreso
tra 0,8 e 0,9 e una buona scelta.
Occupazione di Area: Un sistema embedded e caratterizzato dall’avere
poche risorse di area e memoria, pertanto e importante tenere conto dell’oc-
cupazione di area del DRC nelle diverse configurazioni che lo caratterizzano.
Ricordando che esso e caratterizzato da una componente fissa (la logica di
controllo del bus e dell’ICAP) e da una variabile (la logica di controllo del
buffer), definiamo:
• Af = area occupata dalla parte fissa in slices
• Av = area occupata dalla parte variabile per Byte del buffer in slicesbyte
Dopo aver introdotto tutti i parametri, possiamo passare alla stesura delle
prime relazioni.
4.1.2 Relazioni descrittive del DRC
Occupazione di area: come gia accennato nel paragrafo precedente, il DRC
e composto da una parte fissa ed una variabile. La prima rappresenta la logica
di controllo del bus ed e indipendente dal tipo e dalla dimensione del buffer,
mentre la seconda rappresenta la logica del buffer, che e strettamente legata
al tipo e dimensione del buffer scelto.

4.1. ANALISI DEI REQUISITI E MODELLIZZAZIONE 45
Per comprendere come e legata l’occupazione di area alla dimensione del
buffer sono state eseguite le seguenti prove (effettuate usando il DRC con buffer
in slice e interfaccia OPB):
Dimensione Buffer (Bytes) Occupazione di Area (slices)
4 79
8 119
16 161
32 275
64 525
128 981
Tabella 4.1: Occupazione Area Soluzione Buffer in Slices con interfaccia su
OPB
Interpolando i valori di Tabella 4.1, si e capito che la parte variabile del DRC
ha un andamento lineare, quindi e corretto descrivere l’occupazione di area
come segue:
A = Af + Av ∗ L (4.2)
Dove Af e l’occupazione della parte fissa in slices, Av e l’occupazione della
parte variabile in slices per byte e L e la grandezza (in byte) del buffer.
I valori di Af e Av sono legati al tipo di bus e buffer scelti. In particolare,
una scelta di un buffer piuttosto che di un altro, influisce sulla occupazione
della parte fissa, mentre la scelta del tipo di buffer (slices o BRAM) determina
l’occupazione della parte variabile.
Throughput: con la presenza del buffer, il throughput di trasferimento
dei dati verso l’ICAP migliora rispetto alla soluzione priva di buffer. Questo
miglioramento e determinato sia dalla grandezza del buffer, che dalla grandezza
del bitstream (che identificheremo con B). Tenendo presente la Relazione 4.1,
e immediato ricavare:
TDRC =B
B − lTbus (4.3)
Esiste, quindi, un fattore che indica di quanto e accelerato il throghput di ri-
configurabilita rispetto al throghput del bus. La funzione e monotona crescente
per l < B con un asintoto in l = B, in quanto B − l < B. Tali considerazioni
fanno capire che Tbus < TDRC e che TDRC cresce al crescere di l. Cio dimostra

46 CAPITOLO 4. DRCGEN
che il miglioramento delle prestazioni e determinato dalla presenza del buffer,
senza il quale non sarebbe possibile aumentare il throughput di riconfigura-
bilita.
La Relazione 4.3 e espressa graficamente in Figura 4.2. I valori scelti per
la costruzione di questo grafico (giustificati da prove sperimentali [1]) sono
Tbus = 50MBytessec
e B = 20KBytes .
Figura 4.2: Throughput in funzione della dimensione del buffer
La Relazione 4.3, illustrata in Figura 4.2, non e del tutto esatta, in quanto
in essa non compare Ticap. Questo e ragionevole perche Tbus < Ticap, ma puo
creare non poche inaderenze alla realta. La Relazione 4.3 suppone che Ticap
sia grande a piacere, il che e inesatto. Ad esempio: si supponga di possedere
un buffer che sia delle dimensioni del bitstream. Una volta partita la riconfi-
gurazione, il processore passera al DRC il bitstream, il quale sara interamente
caricato nel buffer prima che l’ICAP parta con la riconfigurazione. Secondo la
Relazione 4.3 si ha che TDRC = ∞, quindi il processo di riconfigurazione del
dispositivo risulta immediato, quando, in realta, sappiamo essere pari al tempo
che l’ICAP impiega a leggere il bitstream dal buffer, ottenendo TDRC = Ticap.
Cio e interessante e ci obbliga a ridefinire la Relazione 4.3 nel modo seguente:
TDRC =
{BB−lTbus, se l < B(1− Tbus
Ticap)
Ticap, altrimenti(4.4)

4.1. ANALISI DEI REQUISITI E MODELLIZZAZIONE 47
Figura 4.3: Throughput del DRC
La Relazione 4.4 e espressa graficamente nella Figura 4.3. Il valore di l,
che causa una saturazione del throughput di riconfigurabilita, e pari a l =
B(1 − Tbus
Ticap). Non conviene avere dimensioni del buffer maggiori del punto
di saturazione, in quanto non si avrebbe un miglioramento del throughput di
riconfigurabilita.
Una volta vista la Relazione 4.4, e importante osservare come la dimensione del
bitstream influisce sul throughput. Proviamo ad esaminare come si comporta
il throughput di riconfigurabilita al crescere della dimensione del bitstream con
un limite:
TDRC = limB→∞
B
B − lTbus = Tbus (4.5)
Come si puo vedere nell’Equazione 4.5, il throughput di riconfigurabilita
peggiora all’aumentare della dimensione del bitstream. Dato che la di-
mensione del bitstream dipende da quanto e grande l’area che si vuole
riconfigurare, si deduce che maggiore e l’area da riconfigurare, a pari DRC,
peggiore sara il throughput di riconfigurabilita. Si faccia attenzione al fatto
che non si sta parlando di peggioramenti sui tempi di riconfigurabilita (che
necessariamente peggiorano all’aumentare della dimensione del bitstream),
ma di peggioramenti del throughput di riconfigurabilita.
Fatte queste premesse, vediamo graficamente quanto detto nella Figura 4.4
Le curve che saturano prima, sono quelle curve che hanno bitstream di
dimensioni piu ridotte. Da sinistra verso destra si e imposto B pari a: 15
KBytes, 16 KBytes, 18 KBytes, 20 KBytes, 23 KBytes e 25 KBytes. Questi

48 CAPITOLO 4. DRCGEN
Figura 4.4: Throughput del DRC al variare della dimensione del Bitstream
valori sono stati scelti in quanto rappresentano dimensioni di bitstream
differenza piuttosto reali.
Prima di arrivare ai primi confronti, e necessario disporre di relazioni dirette
tra area e throughput. Queste relazioni saranno utili anche per studiare quale
configurazione si adatta meglio ai vincoli imposti dall’utente. Unendo le
equazioni del paragrafo precedente si ottiene:
Dimensione del buffer in funzione dell’area occupata:
l =A− AfAv
α (4.6)
Dimensione del buffer in funzione del throughput:
l = B(1− TbusTDRC
) (4.7)
Throughput del DRC in funzione dell’area occupata:
TDRC =Tbus
1− αB
(A−Af
Av)
(4.8)
Area occupata in funzione del throughput:
A =B
αAv(1−
TbusTDRC
) + Af (4.9)
La modellizzazione del DRC e terminata. Ora si hanno tutti gli strumenti che
permettono di identificare la migliore configurazione del DRC in funzione dello
scenario in cui esso si trova.

4.2. FLUSSO OPERATIVO DI DRCGEN 49
4.2 Flusso operativo di DRCgen
Come gia accennato ad inizio capitolo, DRCgen utilizza il modello del DRC
al fine di individuare la configurazione che meglio si adatta ai vincoli posti
dall’utente, essi sono:
• Vincolo di Area: specifica quanto deve occupare l’intero DRC.
• Vincolo sul Throughput: specifica quanto deve essere il throughput
del DRC.
Questi vincoli possono anche essere espressi contemporaneamente, ma almeno
uno di essi deve essere specificato. In caso di mancanza di entrambi i vincoli, il
software restituisce un DRC di default. Oltre ai vincoli su throughput e area,
DRCgen tiene conto di altri parametri quali:
• Throughput Bus
• Throughput ICAP
• Dimensione Bitstream
• Tipo di Bus
• Famiglia FPGA
I primi tre parametri servono per individuare (assieme ai vincoli) la dimensione
del buffer e il tipo, il quarto definisce l’interfaccia su bus e l’ultimo serve al
software nella verifica dei risultati ottenuti. Questa verifica cerca di capire se la
soluzione trovata e o meno implementabile e, nel caso lo fosse, quanto occupa
su scheda.
4.2.1 Ricerca della soluzione ottimale
Lo studio del problema e differente nel caso in cui si stia specificando un solo
vincolo o entrambi. Questo perche con un solo vincolo, la soluzione ottimale
al problema e unica. Nello specifico, data l’area, si identifica immediatamente
il throughput e quindi la dimensione del buffer, oppure, dato il throughput,
si identifica univocamente l’area e quindi la dimensione del buffer. Questo e
garantito dal fatto che la relazione che lega il throughput e l’area e monotona.

50 CAPITOLO 4. DRCGEN
Essendo monotona, l’inversa, esiste ed e comunque monotona.
Nel caso di specifica contemporanea di entrambi i vincoli, la soluzione non
e sempre unica. Questo tipo di vincolo identifica un punto nel piano
Throughput/Area che puo trovarsi in 3 zone (Vedere Figura 4.5)
1. (a) Il punto si trova al di sopra della curva
2. (b) Il punto giace sulla curva
3. (c) Il punto si trova al di sotto della curva
Figura 4.5: Possibili vincoli
Se il punto giace sulla curva, le due soluzioni possibili (data la presenza di due
vincoli) coincidono, quindi la soluzione e univocamente determinata.
Negli altri due casi si identificano le due soluzioni come segue:
1. Calcolo il Throughput tenendo fisso il vincolo di Area
2. Calcolo l’Area tenendo fisso il vincolo sul Throughput
In questo modo si hanno due soluzioni che godono di proprieta differenti a
seconda che il punto del vincolo si trovi al di sopra o al di sotto della curva:
se il punto si trova sotto la curva, entrambe le soluzioni rispettano entrambi i
vincoli, mentre se il punto si trova al di sopra della curva, entrambe le soluzioni
non rispettano tutti e due i vincoli. Cio succede perche in un caso si sta

4.2. FLUSSO OPERATIVO DI DRCGEN 51
chiedendo al generatore un DRC con basso throughput con alta area, mentre
nell’altro un DRC con alto throughput con una bassa area.
Un altro problema si presenta quando si impongono dei vincoli su throughput
o area che escono dal range di valori di accettabilita. Se cio dovesse verificarsi,
prima di effettuare qualsiasi considerazione, il generatore impone i valori di
default secondo le seguenti regole:
• TDRC = Tbus se TDRC < Tbus
• TDRC = Ticap se TDRC > Ticap
• A = Af + Av se A < Af + Av
Queste regole sono continuamente tenute sott’occhio dal software in modo da
convergere verso la soluzione ottimale.
Dopo aver introdotto la metodologia di ricerca delle soluzioni ottimali di DRC-
gen, passiamo ad analizzare l’intero flusso operativo che esso segue per imple-
mentare la suddetta metodologia. Questo servira a comprendere fino in fondo
tutti i suoi comportamenti.
4.2.2 Funzionamento
DRCgen segue fedelmente la metodologia di ricerca delle soluzioni proposta
nel paragrafo precedente. Vista la grande diversita tra la specifica di un solo
vincolo e quella con piu vincoli, esso segue strade differenti che saranno esa-
minate separatamente.
Nello pseudocodice e nei grafici che seguiranno, e da applicare la seguente
legenda:
• T = Vincolo Throghput
• A = Vincolo Area
• Tbus = Throghput del bus
• Ticap = Throughput dell’ICAP
• Lslice = Dimensione buffer implementato in slice
• Lbram = Dimensione buffer implementato in bram

52 CAPITOLO 4. DRCGEN
• Aslice = Area occupata dal DRC implementato in slice
• Abram = Area occupata dal DRC implementato in bram
• Aminf = Area della parte fissa nella configurazione che occupa di meno
• Aminv = Area della parte variabile nella configurazione che occupa di
meno
• AFPGA = Area massima della FPGA scelta
• Tarea = Throughput calcolato mantenendo fisso il vincolo di area
• Athr = Area calcolata mantendo fisso il vincolo sul throughput
Ora che tutti i termini sono stati introdotti, e possibile esaminare lo
pseudocodice che descrive il funzionamento di DRCgen.

4.2. FLUSSO OPERATIVO DI DRCGEN 53
Specifica del solo vincolo sul Throughput: in input al programma si
ha il solo vincolo sul throughput. L’algoritmo procede come segue:
1: if T > Ticap then
2: T = Ticap
3: end if
4: if T < Tbus then
5: T = Tbus
6: end if
7: Calcolo Lslice da T
8: Calcolo Aslice da Lslice
9: Calcolo Lbram da T
10: Calcolo Abram da Lbram
11: if Aslice > Abram then
12: Scelgo la soluzione in bram
13: else
14: Scelgo la soluzione in slice
15: end if
16: Validazione dei risultati
17: Generazione del VHDL

54 CAPITOLO 4. DRCGEN
Specifica del solo vincolo sull’area: in input al programma si ha il solo
vincolo sull’area. L’algoritmo procede come segue:
1: if A < Aminf + Aminv then
2: A = Aminf + Aminv
3: end if
4: if A > AFPGA then
5: A = AFPGA
6: end if
7: Calcolo Lslice da A
8: Calcolo Lbram da A
9: if Lslice > Lbram then
10: Calcolo T da Lbram
11: if T > Ticap then
12: T = Ticap
13: Ricalcolo Lbram
14: end if
15: end if
16: Validazione dei risultati
17: Generazione del VHDL

4.2. FLUSSO OPERATIVO DI DRCGEN 55
Specifica del vincolo sull’area e del vincolo sul throughput: in
input al programma si ha sia il vincolo sull’area che quello sul throughput.
1: if T > Ticap then
2: T = Ticap
3: else if T < Tbus then
4: T = Tbus
5: end if
6: if A < Aminf + Aminv then
7: A = Aminf + Aminv
8: else if A > AFPGA then
9: A = AFPGA
10: end if
11: Calcolo Tarea da A
12: Calcolo Athr da T
13: if Tarea > Ticap then
14: TArea = Ticap
15: Ricalcolo A dato Tarea
16: end if
17: Proposta delle due soluzioni
18: if Scelta soluzione A Fissa
then
19: T = Tarea
20: else if Scelta soluzione T Fisso
then
21: A = Athr
22: end if
23: Validazione dei risultati
24: Generazione del VHDL

56 CAPITOLO 4. DRCGEN
4.2.3 Generazione dell’output
Dopo che il software ha identificato la soluzione migliore in base ai vincoli posti
dall’utente, nota l’interfaccia su bus e la famiglia di FPGA sulla quale si vuole
utilizzare, passa ad una fase di validazione finale dei risultati con generazione
dei files di output.
La validazione dei risultati consiste in un controllo di fattibilita della soluzione
su FPGA. Nel dettaglio controlla che l’area occupata dal DRC non sia superiore
all’area che l’FPGA scelta dispone, oppure, nel caso di buffer in BRAM, che
l’FPGA disponga di tutte le BRAM che il DRC richiede.
La validazione e l’ultima operazione che deve essere fatta in quanto solo a
flusso terminato si conosce la configurazione finale del DRC. Si noti che il
controllo sul vincolo di area e una tra le prime operazioni che DRCgen svolge,
quindi non e possibile immettere, come vincolo, un’area superiore a quella che
l’FPGA scelta dispone.
Se la validazione non fosse superata, il programma interrompe il flusso con un
errore che ne specifica la natura. Se, invece, la validazione viene passata con
successo, il programma genera in output:
• in base al bus: icap opb.vhd e pselect.vhd (se il bus e l’OPB) o solo
icap plb.vhd (se il bus e il PLB)
• icap buffer.vhd
• bram wrapper.vhd e bram wrapper.ngc nel caso in cui abbia un
buffer implementato in BRAM
Infine DRCgen, al termine della generazione di files di output, stampa a video
un resoconto finale dove l’utente puo controllare una serie di parametri quali:
tipo di buffer scelto dal generatore, prestazioni temporali, occupazioni di area,
ecc...
4.2.4 Utilizzo dei files di output in EDK
L’utilizzo dei files di output di DRCgen in una architettura che necessiti il
DRC e semplice. La scelta di creare i files sorgente e orientato ad un utilizzo
il piu vario possibile, tra i quali l’importazione in EDK.
L’importazione del DRC in un progetto EDK segue la stessa procedura di

4.2. FLUSSO OPERATIVO DI DRCGEN 57
qualsiasi importazione di periferica: una volta aperto EDK si apra ”Create or
Import Peripheral” che si trova sotto il menu ”Hardware” e procedere come
segue:
• in ”Peripheral Flow” selezionare ”Import Existing Peripheral”
• in ”Name and Version” inserire ”icap opb” se il bus e l’OPB e ”icap plb”
se il bus e il PLB
• in ”Source File Types” spuntare ”HDL source files” e ”Netlist Files” (se
il buffer e implementato in BRAM)
• in ”HDL Source Files” spuntare ”Browse to your HDL source and
dependent library files”
• in ”HDL Analysis Information” cliccare su ”Add Files” e selezionare tutti
i .vhd generati da DRCgen
• proseguire fino alla fine selezionando il bus corretto e, nel caso di buffer
in bram, aggiungere il file .ngc generato
Una volta che il DRC e stato importato in EDK, puo essere utilizzato alla pari
di tutte le periferiche di EDK.


Capitolo 5
Risultati Sperimentali
Dopo aver presentato nel dettaglio la struttura del DRC e del suo generatore,
e necessario controllare tutta la metodologia tramite una serie di simulazioni.
Obiettivo del capitolo e quello di estrarre dalla simulazione tutti i valori neces-
sari alla validazione del modello del DRC. Solo dopo tale validazione si potra
essere certi della correttezza formale del flusso la cui diretta implementazione,
DRCgen, dovra essere sottoposta ad una serie di test al fine di verificarne il
corretto funzionamento.
5.1 Validazione del modello
Come abbiamo visto nel Capitolo 4, Area e Throughput sono strettamente
collegati fra loro. Per mostrare che questa relazione non e solo teorica, prima
calcoleremo i coefficienti Af e Av che caratterizzano le due implementazioni,
poi calcoleremo i throughput teorici e infine verificheremo questi throughput
mediante una simulazione, andando a dimostrare tutte le relazioni enunciate
nel Capitolo 4. Questa prova verra effettuata su tutte e 4 le categorie di DRC.
Nella implementazione del buffer in slice sono stati scelti dei valori modesti, in
quanto tale implementazione richiede molta area.
La Tabella 5.1 e la Tabella 5.2 mostrano le occupazioni di area delle diverse
implentazioni del DRC. Come si e gia avuto modo di vedere nel Capitolo 4,
occupazione di area e dimensione del buffer sono legati da due parametri: Af
59

60 CAPITOLO 5. RISULTATI SPERIMENTALI
Dimensione Buffer Occupazione di Area (OPB) Occupazione di Area (PLB)
(Bytes) (slices) (slices)
4 79 95
8 119 130
16 161 179
32 275 300
64 525 543
128 981 990
Tabella 5.1: Occupazione Area Buffer in Slice
Dimensione Buffer Occupazione di Area (OPB) Occupazione di Area (PLB)
(Bytes) (slices) (slices)
512 (1 BRAM) 106 120
1024 (2 BRAM) 116 131
2048 (4 BRAM) 120 141
4096 (8 BRAM) 129 144
8192 (16 BRAM) 154 169
Tabella 5.2: Occupazione Area Buffer in BRAM
e Av. E, quindi, possibile linearizzare i risultati ottenuti al fine di identificare
il preciso valore dei due parametri nelle quattro configurazioni:
• Buffer Slice, interfaccia OPB: Af = 44,33 , Av = 7,46
• Buffer Slice, interfaccia PLB: Af = 71,2 , Av = 7,4
• Buffer BRAM, interfaccia OPB: Af = 100 , Av = 0,01
• Buffer BRAM, interfaccia PLB: Af = 113 , Av = 0,011
L’identificazione di questi parametri, pero, non e sufficiente a validare il mod-
ello in quanto sono necessarie delle prove di validazione piu generali. Queste
prove devono mirare a dimostrare che il throughput di riconfigurabilita cal-
colato dal modello, corrisponde a quello del componente. Solo dopo questa
verifica sara possibile affermare che il modello del DRC e corretto.
Considerando che il DRC e un componente scritto in VHDL il cui compor-
tamento, fissata la dimensione del bitstream e del buffer, non e aleatorio, ha
senso condurre la prova con un simulatore. Cio garantisce dati precisi e non
affetti da rumore. Per questa simulazione si e scelto ModelSim 1, un software
1http://www.model.com

5.1. VALIDAZIONE DEL MODELLO 61
Figura 5.1: Screenshot di una simulazione in ModelSim
della Mentor Graphics che permette di simulare passo passo il comportamento
di qualsiasi core scritto in VHDL o Verilog.
La simulazione consiste in una analisi temporale di una riconfigurazione. Al
termine della simulazione verra confrontato il throughput di riconfigurabilita
con quello teorico al fine di validare le formule del Capitolo 4.
Per la prova si e imposto il throughput del bus a 50MBytessec
e il throughput del-
l’ICAP a 100MBytessec
, facendo variare la dimensione del bitstream e del buffer.
La Tabella 5.3 mostra i risultati di tale simulazione (visibile in Figura 5.1).
Tbus B L T simDRC T theorDRC
(MBytes/sec) (Bytes) (Bytes) (MBytes/sec) (MBytes/sec)
50 4000 400 55,7 55,62
50 4000 1000 66,76 66,70
50 8000 400 52,62 52,63
50 8000 2500 72,74 72,72
50 16000 400 51,29 51,28
50 16000 5000 72,74 72,72
50 16000 10000 100 100
Tabella 5.3: Risultati della simulazione condotta con ModelSim del DRC
I throughput ottenuti dalla simulazione ricalcano perfettamente quelli teorici.
Tale scenario afferma la correttezza del modello e delle metriche che sono state
definite.
Passiamo quindi alla verifica di funzionamento di DRCgen al fine di validarne
l’approccio.

62 CAPITOLO 5. RISULTATI SPERIMENTALI
5.2 Test DRCgen
Ora che la validazione del modello e stata conclusa, si sottoporra il software a
diverse prove sperimentali, al fine attraversare tutti i rami del flusso operativo.
Verranno effettuate 3 prove con il solo vincolo di throughput, 4 prove col
solo vincolo di area e, infine, 8 prove con entrambi i vincoli. Tutte le prove
sono state effettuate considerando Tbus = 50MBytessec
, Ticap = 100MBytessec
, B =
20KBytes, su bus OPB impostando come FPGA la Virtex-II Pro VP7.
5.2.1 Specifica del Solo Vincolo sul Throughput
Prova 1
Vincolo sul Throughput = 20MBytessec
:
./DRCgen.exe -throughput 20
Il software ha risposto correttamente imponendo il vincolo a 50MBytessec
,
restituendo cosı un DRC con buffer di 4 Bytes implementato in slices.
Prova 2
Vincolo sul Throughput = 120MBytessec
:
./DRCgen.exe -throughput 120
Il software ha dapprima imposto il vincolo al massimo possibile (100MBytessec
) e
successivamente calcolato il DRC che e risultato possedere un buffer formato
da 25 BRAM.
Prova 3
Vincolo sul Throughput = 60MBytessec
:
./DRCgen.exe -throughput 60
Il DRC trovato contiene 9 BRAM.
5.2.2 Specifica del Solo Vincolo di Area
Prova 1
Vincolo di Area = 30slices:
./DRCgen.exe -area 30

5.2. TEST DRCGEN 63
DRCgen ha risposto alzando il vincolo da 30slices a 51slices che e corretto in
quanto corrisponde al piu piccolo DRC generabile, cioe quello con 4 Bytes di
buffer implementato in slices e interfacciato su OPB.
Prova 2
Vincolo di Area = 10000slices:
./DRCgen.exe -area 10000
Il software non controlla se l’area richiesta e disponibile nella FPGA, ma resti-
tuisce il miglior DRC possibile, cioe il DRC che corrisponde al punto di sat-
urazione del throughput. Per raggiungere tale obiettivo, impone un vincolo
sul thoughput pari a quello dell’ICAP e ricalcola l’area. Nel caso specifico
la soluzione restituita e uguale alla Prova 2 dei test condotti sul vincolo di
throuhgput.
Prova 3
Vincolo di Area = 80slices:
./DRCgen.exe -area 80
Il valore e accettabile, cosı il software inizia a computare. L’area richiesta e
tale da non poter istanziare il DRC con buffer in BRAM, ma solo quello in
slices. Identificato il tipo di soluzione, il buffer e di 20 Bytes.
Prova 4
Vincolo di Area = 115slices:
./DRCgen.exe -area 115
La soluzione, in questo caso, prevede un buffer con 5 BRAM. Dato che,
come noto dal Capitolo 4, l’istanziazione di una nuova bram non ha costo
rilevante in termini di area, e sempre consigliabile inserire anche il vincolo
sul throughput al fine di evitare l’istanziazione di un numero spropositato di
BRAM.

64 CAPITOLO 5. RISULTATI SPERIMENTALI
5.2.3 Specifica di Entrambi i Vincoli
Prova 1
Vincolo di Area = 80slices, Vincolo sul Throughput = 70MBytessec
./DRCgen.exe -area 80 -throughput 70
Le due soluzioni proposte dal software sono:
• Area: 80 slices / Throughput: 50 MBytes/sec
• Area: 124 slices / Throughput: 70 MBytes/sec
Che sono due soluzioni corrette. Nessuna delle due soluzioni e in grado di
soddisfare ambo i vincoli.
Prova 2
Vincolo di Area = 130slices, Vincolo sul Throughput = 60MBytessec
./DRCgen.exe -area 200 -throughput 70
Le due soluzioni proposte dal software sono:
• Area: 130 slices / Throughput: 85 MBytes/sec
• Area: 119 slices / Throughput: 70 MBytes/sec
Entrambe corrette. Qui tutte e due le soluzioni soddisfano entrambi i vincoli.
Prova 3
Vincolo di Area = 125slices, Vincolo sul Throughput = 72MBytessec
./DRCgen.exe -area 200 -throughput 70
Le due soluzioni proposte dal software sono:
• Area: 125 slices / Throughput: 72 MBytes/sec
• Area: 125 slices / Throughput: 72 MBytes/sec
Che, coincidendo, danno la configurazione del DRC con buffer dotato di 14
BRAM.
La validazione di DRCgen e stata portata a compimento in quanto tutte le
prove hanno dato esiti positivi. E quindi possibile esaminare i risultati di
tutte le prove sperimentali cercando di analizzare il problema da un punto di
vista piu generale.

5.3. CONCLUSIONI 65
5.3 Conclusioni
Tutti i test condotti in questo capitolo hanno dato esito positivo. Si e quin-
di potuto dimostrare che il modello del DRC e corretto in tutti i suoi aspetti.
Inoltre i test sono stati utili a comprendere un altro fatto rilevante nella model-
lizzazione del DRC: l’assoluta indipendenza che esso ha dalla implementazione
su FPGA. La linearizzazione delle occupazioni di area prima e la simulazione
dopo sono un esempio di questo fatto. Nella simulazione la scelta dei valori
di Tbus e di Ticap, difatti, e irrilevante purche Tbus < Ticap. L’innovazione
introdotta da questo lavoro di tesi e, appunto, la completa indipendenza del
modello dal dispositivo su cui sara fisicamente implementato il riconfiguratore.
Inoltre e possibile applicare la modellizzazione del Capitolo 4 a riconfiguratori
diversi dal DRC purche sia presente un buffer e sia possibile identificare il
throughput del bus e quello dell’ICAP (o della porta di riconfigurazione del
dispositivo).


Capitolo 6
Conclusioni e Sviluppi Futuri
DRCgen, il software che e stato sviluppato, nasce da una esigenza precisa: la
necessita di adattare il riconfiguratore allo scenario da riconfigurare. In questo
modo il progettista potra generare, ogni volta che lo necessita, il controllore
con le caratteristiche che meglio si adattano al contesto in cui si trovera ad
operare.
Tutti i riconfiguratori analizzati nel Capitolo 2 hanno prestazioni medie molto
interessanti. Si puo dire che si adattano bene a moltissime applicazioni
pratiche, ma peccano in flessibilita.
Si supponga di avere un sistema riconfigurabile che si occupa di monitorare
una serie di temperature in un impianto industriale. Si capisce fin dal
principio che non e importante disporre di un riconfiguratore che goda di alte
prestazioni (dato che le temperature variano molto lentamente), ma piuttosto
di un riconfiguratore molto piccolo, in quanto molta logica della FPGA sara
utilizzata per il recupero dei dati. Allora che senso avrebbe utilizzare, ad
esempio, l’OPB HWICAP quando una BRAM intera non serve?
Oppure, si supponga di avere un sistema riconfigurabile che si occupa di fare
editing video. Questo sistema, invece, ha bisogno di avere un riconfiguratore
capace di garantire le piu alte prestazioni possibili (in termini di throghput) a
scapito di una occupazione di area maggiore.
Infine, si supponga di avere un sistema implementato su un’architettura con
Microblaze. In questa architettura non e presente il bus PLB. Per poter
utilizzare periferiche interfacciate su PLB, sara necessario mettere un bridge
tra il bus PLB e quello OPB. La presenza di questo bridge causa un crollo
67

68 CAPITOLO 6. CONCLUSIONI E SVILUPPI FUTURI
delle prestazioni (oltre ad una maggiore occupazione di area), che potrebbe
essere evitato avendo a disposizione un riconfiguratore su OPB.
L’innovazione introdotta da questo lavoro di tesi riguarda l’approccio,
del tutto nuovo, al problema della definizione e implementazione di un
riconfiguratore.
L’automazione assoluta del flusso di generazione permette di concentrare
tutte le attenzioni del lavoro su quello che l’utente desidera avere. Infatti
la riconfigurazione della FPGA non e lo scopo di un sistema embedded, ma
un meccanismo utilizzato per aumentare l’utilizzabilita di tali dispositivi.
Pertanto non deve essere l’applicazione a costruirsi attorno al riconfiguratore,
adattandosi ai suoi limiti, ma deve essere il riconfiguratore a configurarsi nei
vincoli richiesti dalla applicazione.
6.1 Sviluppi Futuri
Le attenzioni per il futuro sono da rivolgere in larga misura verso il DRC.
Esso, infatti, e ampiamente sviluppabile. Ogni sviluppo, pero, non deve essere
inteso come una miglioria rispetto alla soluzione precedente, ma come una va-
lida alternativa che, modellizzata corretamente, puo essere inserita nel flusso
come ulteriore soluzione. Pertanto una modifica del DRC causa una modifica
a DRCgen che dovra essere in grado di adattarsi alle tutte le innovazioni.
Uno tra i primi sviluppi del DRC e l’inserimento di un meccanismo di DMA.
Tale meccanismo deve, pero, rispettare a pieno la modularita del DRC, cioe
deve essere possibile eliminarlo qualora non fosse necessario. Il DMA e in gra-
do di incrementare il throughput in ingresso al DRC causando un decremento
delle memorie richieste (e quindi dell’area).
Un altro interessante sviluppo e legato all’interazione del DRC con il core di
BiRF [10]. BiRF e un componente capace di modificare i bitstream al fine di
riallocare un core in una posizione diversa da quella per cui e stato progettato.
Questa funzionalita e in grado di far risparmiare molto spazio di memoria,
altrimenti occupato da tutti i bitstream differenza.
L’idea e di includere BiRF nel DRC anteponendo tra i due una cache. Tale
cache conterra il bitstream che descrive il componente da riconfigurare. Se il

6.1. SVILUPPI FUTURI 69
componente necessita di una rilocazione, allora il bitstream sara prima mod-
ificato dal core di BiRF, salvato in cache e, succesivamente, passato al DRC.
Infine si possono utilizzare degli algoritmi di compressione in modo tale da ot-
tenere bitstream di dimensioni ancora piu ridotte di quelli parziali. Cosı si ha
la possibilita di ridurre la dimensione della memoria richiesta dal DRC oppure
usare la stessa quantita ed ottenere prestazioni migliori. Si noti che prima
di utilizzare questi bitstream, devono essere decompattati da un opportuno
decompressore prima del passaggio di questi all’ICAP.


Bibliografia
[1] Antonio Piazzi Alessio Montone. Yara: Un’architettura riconfigurabile
basata sull’approccio monodimensionale.
[2] Johannes Zeppenfeld Christopher Claus, Florian H. Muller and Walter
Stechele. A new framework to accelerate Virtex-II Pro dynamic partial self
reconfiguration.
[3] Xilinx XAPP138. Virtex FPGA Series Configuration and Readback.
[4] Xilinx Microblaze Processor Reference Guide.
[5] Xilinx PowerPC Processor Reference Guide.
[6] Xilinx UG071. Virtex-4 Configuration Guide.
[7] Xilinx User Constraint File Guide.
[8] Xilinx Site: http://www.xilinx.com.
[9] Stefano Bosisio Ivan Beretta. Integrazione del soft processor microblaze
nell’architettura riconfigurabile yara.
[10] M. Novati M.D. Santambrogio-D. Sciuto P. Spoletini S. Corbetta,
M. Morandi. Internal and external bitstream relocation for partial
dynamic reconfiguration.
[11] Xilinx OPB HWICAP Product Specification.
[12] Wikipedia. Fpga.
[13] Wikipedia. Sistema dinamico.
[14] Wikipedia. Sistema embedded.
71


















