
Performance in Spark 2.0, PDX Spark Meetup 8/18/16
57
Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Performance in Spark 2.0 …and onward to the next level Brad Carlile Sr. Director Strategic ApplicaIons Engineer SAE Oracle Systems Group August 18, 2016 Addi$onal info on system performance results: hNp://blogs.oracle.com/bestperf
-
Upload
pdxspark -
Category
Data & Analytics
-
view
307 -
download
1
Transcript of Performance in Spark 2.0, PDX Spark Meetup 8/18/16

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
PerformanceinSpark2.0…andonwardtothenextlevel
BradCarlileSr.DirectorStrategicApplicaIonsEngineerSAEOracleSystemsGroupAugust18,2016Addi$onalinfoonsystemperformanceresults:hNp://blogs.oracle.com/bestperf

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SafeHarborStatementThefollowingisintendedtooutlineourgeneralproductdirecIon.ItisintendedforinformaIonpurposesonly,andmaynotbeincorporatedintoanycontract.Itisnotacommitmenttodeliveranymaterial,code,orfuncIonality,andshouldnotberelieduponinmakingpurchasingdecisions.Thedevelopment,release,andImingofanyfeaturesorfuncIonalitydescribedforOracle’sproductsremainsatthesolediscreIonofOracle.
2

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
AboutmeSr.DirectorStrategicApplica0onsEngineering,OracleSystemsGroup• OracleHardwareSystemsPerformance&benchmarks:x86&SPARCproducts• 30yearsparallelprogramming,performanceopImizaIon&benchmarks:aNachedprocessors,Hypercube,MPPs,SMPs,NUMA…• FloaIngPointSystems,Cray,Sun,Oracle
• Skier• Traveler• BigWallClimber• IDriveanArtCar
3

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SparkisExciIng–ButYouAlreadyKnowThat!Spark’sWholeEcosystemtotallyappealstotheperformanceexpertinme!
• GreatEcosystemforAnalyIcs– SparkformsaconInuumwithothertechnologies(Kaaa,Solr,…)
• Sparkisfast&scalablebecauseofcleandesign– Spark’sin-memoryfocus
• SparkspeaksSQL&DataFrames– PerfectmarriageforDataScienIsts&HardwareAcceleraIon– Oracle’sSofwareinSiliconcanbeusedonApacheSpark
• LotsofOraclecustomersusingApacheSpark4

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ApacheSpark
5
Spark Core (Implemented in Scala & JVM, operates on RDDs)
Spark SQL
(SQL & DSL(Scala/Java/Python…)
Spark API: Scala, Python, R, Java
DataFrames / DataSets
Data Sources: Json, csv, Hadoop, Cassandra, Hive, Hbase, Postgres, MySQL, Elasticsearch,...
Spark Streaming
(Streaming Analytics micro-batches)
Spark MLlib
(Machine Learning & statistic routines)
GraphX
(Graph)

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ApacheSpark2.0.0GreatNewFeatures
• SparkSQL– SQL2003andUnifiedDataFrames/DatasetsAPI.– TungstenPhase2:WholeStageCodeGen
• SparkMllib&GraphX–LargeScaleMachineLearningonApacheSpark
• StructuredStreaming
6
Bestnewfeatures-Star0ngwithSparkSQL

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SQLisPowerfulFeatureofApacheSpark
• SQLisapowerfullanguageforthewiderangeofDataScienIsts– ExpressessetoperaIonsondataofanysize:sort,filter,manipulateetc
7

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SQLisPowerfulFeatureofApacheSpark
• SQLisapowerfullanguageforthewiderangeofDataScienIsts– ExpressessetoperaIonsondataofanysize:sort,filter,manipulateetc
• SQLconciselyexpressdatamanipulaIonatscaleinreadableway– ETL(Extract,Transform,andLoad)– FeatureselecIonforML– FeaturecreaIon/generaIonforML– ReportgeneraIon
8

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SQLisPowerfulFeatureofApacheSpark
• SQLisapowerfullanguageforthewiderangeofDataScienIsts– ExpressessetoperaIonsondataofanysize:sort,filter,manipulateetc
• SQLconciselyexpressdatamanipulaIonatscaleinreadableway– ETL(Extract,Transform,andLoad)– FeatureselecIonforML– FeaturecreaIon/generaIonforML– ReportgeneraIon
• Manywell-knowntechniquestoefficientlyopImizeSQL– ApacheSpark“CatalystopImizer”reorganizesqueryforfastestexecuIon– Extensible:youcancontributeyourownopImizaIons
9

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SparkSQL&DataFrames:PerfectforDataScienIstsAmazingworkwhichalsoefficientlyputsDataInMemoryforfastaccess
• SQLeasiestwaytowritecodetofilter,merge,scan,…– scala>dfr=sparkSession.sql("SELECTfirstName,age,gender
FROMcustWHEREage>20ORDERBYageDESC").show()
• DataFramescolumnarandtyped//schema:firstName:String,lastName:String,gender:String,age:Int
– DataFramesbeNerforanalyIcsthangenericRDDs
10
RDD:row-based,originalApacheSparkdatastructureJay,Lock,M,81Rosa,Ruiz,F,14Clair,Bride,F,23
DataFrame:columnarJay Lock M 81Rosa Ruiz F 14Clair Bride F 23

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Columns:whatisinthem?Whynotjustrow-store?
• Eachcustomerdatapoint,event,etc.hasmanykindsofpossibledata
• SparkSchema’sdefinesthecolumnsandtheirtypes,canhavehugenumbers10’sto100’s(verywidecolumns)
11
Differentcharacteris0csofadatapointarestoredindifferentcolumns
Name Addr St City Zip Age Id’edGender Edu Sal Marital Loyalty
planCustYear
BuyFreq
FavDevices
Commode …
Duma 6nw7 Or PDX 97223 25 F MA 60k M Lev2b 5.7 .2 iPh txt
valloSchema=StructType(StructField("lo_orderkey",IntegerType,true)::StructField("lo_linenumber",IntegerType,true)::StructField("lo_custkey",IntegerType,true)::StructField("lo_partkey",IntegerType,true)::StructField("lo_suppkey",IntegerType,true)::StructField("lo_orderdate",StringType,true)::StructField("lo_orderpriority",StringType,true)::StructField("lo_shippriority",StringType,true)::StructField("lo_quanIty",IntegerType,true)::StructField("lo_extprice",IntegerType,true)::StructField("lo_ordtotalprice",IntegerType,true)::
StructField("lo_discount",IntegerType,true)::StructField("lo_revenue",IntegerType,true)::StructField("lo_supplycost",IntegerType,true)::StructField("lo_tax",IntegerType,true)::StructField("lo_commitdate",IntegerType,true)::StructField("lo_shipmode",StringType,true)::StructField("lo_ordermode",StringType,true)::StructField("lo_webIme",FloatType,true)::StructField("lo_shopcarvme",FloatType,true)::
...StructField("lo_loyaltyPercnt",FloatType,true)::Nil)
Ananalysismayonlyneedtoexploreasmallsubsetofthesecolumns.
Muchfasterifonlyaccess
theneededcolumn,alsomanyserverbenefits!

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
OLDcase class Customer (c_custkey: Int, c_name: String, c_address: String, c_city: String, c_phone: String, c_mktsegment: String)...object RCDBTestProgram { def main(args: Array[String]) { val sparkConf = newSparkConf() .setAppName("RCDB") val sc = new SparkContext(sparkConf) val sqlContext = new org.apache.spark.sql.SQLContext(sc)... val dataDir ="file:/Users/bc/datasets/R_SF1000/” val df1 = sc.textFile(dataDir+”customer.csv")
.map(_.split(";"))
.map(p => Customer(p(0).trim.toInt,p(1), .trim,p(2).trim,p(3) .trim,p(4).trim,p(5).trim,p(6).trim)) .toDF()
df1.registerTempTable(”customer”)
... query = "””SELECT COUNT(*) FROM customer""” val count = sqlContext.sql(query).take(1)
Newobject RCDBTestProgram { def main(args: Array[String]) { val sparkSession = SparkSession.builder .appName("RCDB”).getOrCreate()... val dataDir ="file:///Users/bc/datasets/R_SF1000/” val custSchema = StructType( StructField("c_custkey", IntegerType, true) :: StructField("c_name", StringType, true) :: StructField("c_address", StringType, true) :: StructField("c_city", StringType, true) :: StructField("c_phone", StringType, true) :: StructField("c_mktsegment", StringType, true) :: Nil) val df3 = sparkSession.read.option("sep", ";") .option("header","false").schema(custSchema) .csv(dataDir+"customer.csv").toDF().repartition(256) df3.createOrReplaceTempView("customer") df3.persist(StorageLevel.OFF_HEAP)
... query = "””SELECT COUNT(*) FROM customer""” val count = sparkSession.sql(query).take(1)... sparkSession.sql("SHOW TABLES").show() sparkSession.catalog.listTables.show()
12
ApacheSpark2.0.0NewSparkSessionreplacingtheSQLContext
https://databricks.com/blog/2016/08/15/how-to-use-sparksession-in-apache-spark-2-0.html
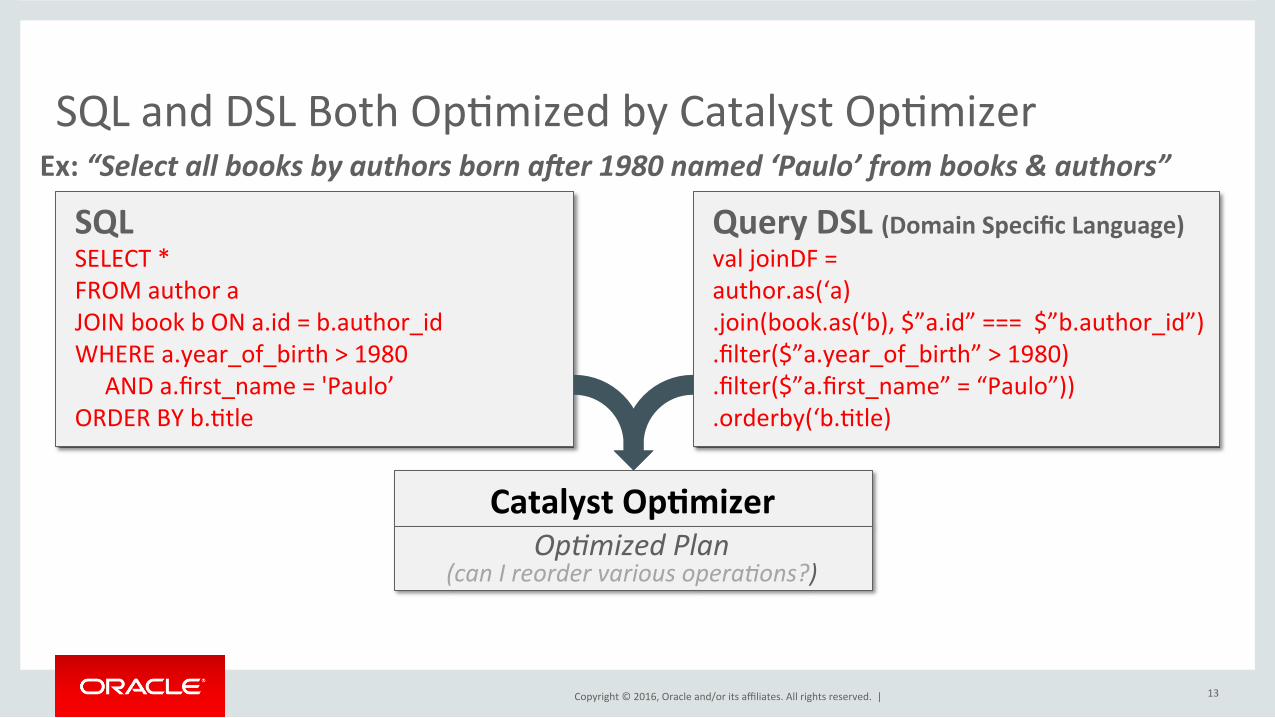
Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SQLandDSLBothOpImizedbyCatalystOpImizer
13
Ex:“SelectallbooksbyauthorsbornaEer1980named‘Paulo’frombooks&authors”SQLSELECT*FROMauthoraJOINbookbONa.id=b.author_idWHEREa.year_of_birth>1980ANDa.first_name='Paulo’ORDERBYb.Itle
QueryDSL(DomainSpecificLanguage)valjoinDF=author.as(‘a).join(book.as(‘b),$”a.id”===$”b.author_id”).filter($”a.year_of_birth”>1980).filter($”a.first_name”=“Paulo”)).orderby(‘b.Itle)
CatalystOp0mizerOp$mizedPlan
(canIreordervariousopera$ons?)

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ApacheSparkSQL:CatalystOpImizesSQL/DSLExecuIon
14
*HashAggregate(keys=[],funcIons=[count(1)])+-ExchangeSingleParIIon+-*HashAggregate(keys=[],funcIons=[parIal_count(1)])+-*Project+-*Filter((isnotnull(lo_quanIty#89)&&(lo_quanIty#89>=10))&&(lo_quanIty#89<=20))+-InMemoryTableScan[lo_quanIty#89],[isnotnull(lo_quanIty#89),(lo_quanIty#89>=10),(lo_quanIty#89<=20)]:+-InMemoryRelaIon[lo_orderkey#81,lo_linenumber#82,lo_custkey#83,lo_partkey#84,lo_suppkey#85,lo_orderdate#86,lo_orderpriority#87,lo_shippriority#88,lo_quanIty#89,lo_extendedprice#90,lo_ordtotalprice#91,lo_discount#92,lo_revenue#93,lo_supplycost#94,lo_tax#95,lo_commitdate#96,lo_shipmode#97],false,16384,StorageLevel(disk,memory,o�eap,1replicas)::+-ExchangeRoundRobinParIIoning(16)::+-*Scancsv[lo_orderkey#81,lo_linenumber#82,lo_custkey#83,lo_partkey#84,lo_suppkey#85,lo_orderdate#86,lo_orderpriority#87,lo_shippriority#88,lo_quan$ty#89,lo_extendedprice#90,lo_ordtotalprice#91,lo_discount#92,lo_revenue#93,lo_supplycost#94,lo_tax#95,lo_commitdate#96,lo_shipmode#97]Format:CSV,InputPaths:file:/Users/bradcarlile/datasets/RCDB_SF1/lineorder-new.csv,PushedFilters:[],ReadSchema:struct<lo_orderkey:int,lo_linenumber:int,lo_custkey:int,lo_partkey:int,lo_suppkey:int,lo_orderdat...
Qbet:SELECTcount(*)FROMlineorderWHERElo_quanItyBETWEEN10and20
CanlookatOpQmizedplanwithExplainplancreatedbyusing:sparkSession.sql(query).explain()
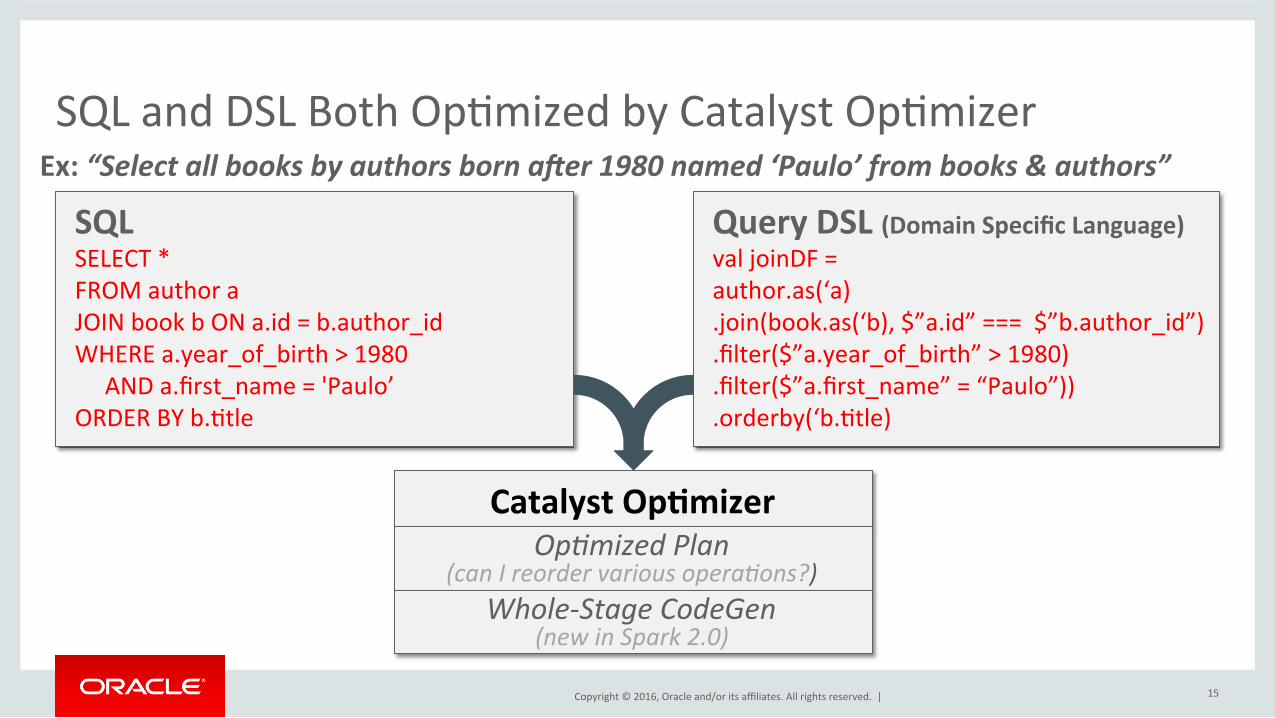
Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SQLandDSLBothOpImizedbyCatalystOpImizer
15
Ex:“SelectallbooksbyauthorsbornaEer1980named‘Paulo’frombooks&authors”SQLSELECT*FROMauthoraJOINbookbONa.id=b.author_idWHEREa.year_of_birth>1980ANDa.first_name='Paulo’ORDERBYb.Itle
QueryDSL(DomainSpecificLanguage)valjoinDF=author.as(‘a).join(book.as(‘b),$”a.id”===$”b.author_id”).filter($”a.year_of_birth”>1980).filter($”a.first_name”=“Paulo”)).orderby(‘b.Itle)
CatalystOp0mizerOp$mizedPlan
(canIreordervariousopera$ons?)Whole-StageCodeGen
(newinSpark2.0)

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Spark2.0:AbigperformanceIncreasewithTungstenPhase2SELECTcount(*)FROMlineorderWHERElo_quan0tyBETWEEN10and20
1. VolcanoIteratormodel:SQLplaninterpretaIon– Open;– Nextdataelement;– performpredicate;– Close– …Iterate
2. “CollegeFreshman”Javacode:TungstenWholeStagecodeGenpipelinedcode– for(lo_quan$tyinlineorder{– if(lo_quan$ty>10andlo_quan$ty<20)– {count+=1}– }
16

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SampleWhole-StageCodeGen
17
valcode-df=sparkSession.sql("explaincodegen"+query)code-df.show(false)
Subtree1/2Generatedcode:/*033*/privatevoidagg_doAggregateWithoutKey()throwsjava.io.IOExcepIon{/*034*///iniIalizeaggregaIonbuffer/*035*/agg_bufIsNull=false;/*036*/agg_bufValue=0L;/*037*//*038*/while(inputadapter_input.hasNext()){/*039*/InternalRowinputadapter_row=(InternalRow)inputadapter_input.next();/*040*/longinputadapter_value=inputadapter_row.getLong(0);/*041*//*042*///doaggregate/*043*///commonsub-expressions/*045*///evaluateaggregatefuncIon/*046*/booleanagg_isNull3=false;/*047*//*048*/longagg_value3=-1L;/*049*/agg_value3=agg_bufValue+inputadapter_value;/*050*///updateaggregaIonbuffer/*051*/agg_bufIsNull=false;/*052*/agg_bufValue=agg_value3;/*053*/if(shouldStop())return;/*054*/}/*056*/}/*058*/protectedvoidprocessNext()throwsjava.io.IOExcepIon{/*059*/while(!agg_initAgg){/*060*/agg_initAgg=true;/*061*/longagg_beforeAgg=System.nanoTime();/*062*/agg_doAggregateWithoutKey();/*063*/agg_aggTime.add((System.nanoTime()-agg_beforeAgg)/1000000);/*064*//*065*///outputtheresult/*067*/agg_numOutputRows.add(1);/*068*/agg_rowWriter.zeroOutNullBytes();/*069*//*070*/if(agg_bufIsNull){/*071*/agg_rowWriter.setNullAt(0);/*072*/}else{/*073*/agg_rowWriter.write(0,agg_bufValue);/*074*/}/*075*/append(agg_result);}}}
Subtree2/2Generatedcode:/*033*/privatevoidagg_doAggregateWithoutKey()throwsjava.io.IOExcepIon{/*034*///iniIalizeaggregaIonbuffer/*035*/agg_bufIsNull=false;/*036*/agg_bufValue=0L;/*037*//*038*/while(inputadapter_input.hasNext()){/*039*/InternalRowinputadapter_row=(InternalRow)inputadapter_input.next();/*040*///doaggregate/*041*///commonsub-expressions/*043*///evaluateaggregatefuncIon/*044*/booleanagg_isNull1=false;/*045*//*046*/longagg_value1=-1L;/*047*/agg_value1=agg_bufValue+1L;/*048*///updateaggregaIonbuffer/*049*/agg_bufIsNull=false;/*050*/agg_bufValue=agg_value1;/*051*/if(shouldStop())return;/*052*/}/*054*/}/*056*/protectedvoidprocessNext()throwsjava.io.IOExcepIon{/*057*/while(!agg_initAgg){/*058*/agg_initAgg=true;/*059*/longagg_beforeAgg=System.nanoTime();/*060*/agg_doAggregateWithoutKey();/*061*/agg_aggTime.add((System.nanoTime()-agg_beforeAgg)/1000000);/*062*//*063*///outputtheresult/*065*/agg_numOutputRows.add(1);/*066*/agg_rowWriter.zeroOutNullBytes();/*067*//*068*/if(agg_bufIsNull){/*069*/agg_rowWriter.setNullAt(0);/*070*/}else{/*071*/agg_rowWriter.write(0,agg_bufValue);/*072*/}/*073*/append(agg_result);}}}
query=“SELECTcount(*)FROMlineorderWHERElo_quan0tyBETWEEN10and20”

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
TheBasicAnalyIcsFlowAlotof0mespentinDataMunging• Datacancomefrommanysources
– Databases,NoSQL,csv,feeds…
• Weneedtoprepareit– DataMungingofallsorts!
• Analyzethedata– Findthe“rightway”toanalyzeit
• ML,Graph,SQL…
18
Databases
DataMunging
RESULTS
Analy0cs
NoSQL,Search.…
StreamingKafa,Storm…

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ConInuousAnalyIcsCycleResultsOfenEnrichTransacIonsAnaly0csismorethanonepipelinestream
• ConInuousiteraIonsaroundthedataanalyIcswheel– Save,catalog,andre-useallthings:data,SQL,code,andanalyIcs
• In-memoryadvantagesateachstage– SPARC’sDAX&leadingbandwidthiskey
• Manysourcesofdata– Internalproprietary,publicdata,externalstreaming,archives
19
StreamingKafa,Storm,…
EnhanceTransacQons
Reports
DatabasesNoSQL
ETL(SQL)
ETL(SQL)
In-Memory
ML&Graph(FP)
ResultDelivery(SQL)
FeatureExtract,Generate&Transform
(SQL)
AllmodernApps(Uber,Neolix,Amazon,FB…)enhancingtransac$onswithReal-$meanaly$cs
AdHoc

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SQLsqlContext.udf.register("newTitle",Itles.getOrElse((_:String),"Other"))sqlContext.udf.register("toString",(_:Int).toString) valavgAge=dataDFRaw.select("Age”).agg(avg("Age")).first().getDouble(0)valavgFare=dataDFRaw.select("Fare”).agg(avg("Fare")).first().getDouble(0)query=s"””SELECTPassengerId,toString(Survived)ASSurvivedString,Pclass,Name,newTitle(regexp_extract(Name,".*,(.*?)\\..*",1))ASTitle,Sex,NVL(Age,$avgAge)ASAge,IF(SibSp+Parch>3,1,0)ASWithFamily,NVL(Fare,$avgFare)ASFare,NVL(Embarked,'S')ASEmbarkedFROMdataDFRaw"""
…SamewithScaladefpreprocess(data:DataFrame,sqlContext:SQLContext,train:Boolean):DataFrame={vardataTrain=datavalavgAge=dataTrain.select(mean("Age")).first()(0).asInstanceOf[Double]println("avgAge="+avgAge)valavgFare=dataTrain.select(mean("Fare")).first()(0).asInstanceOf[Double]valwithFamily=sqlContext.udf.register("withFamily",(sib:Int,par:Int)=>{if(sib+par>3)1.0else0.0})valfillAge=sqlContext.udf.register("fillAge",(age:Double,Itle:String)=>{varnewage=0.0dif((age==avgAge)&&(Itle.equals("Master.")||Itle.equals("Miss.")))newage=14.1elsenewage=agenewage})valaddChild=sqlContext.udf.register("addChild",(sex:String,age:Double)=>{if(age<15)if(sex=="male")"mChild”else"fChild”elsesex})valtoDouble=sqlContext.udf.register("toDouble",((n:Int)=>{n.toDouble}))dataTrain=dataTrain.withColumn("Title",findTitle(dataTrain("Name")))dataTrain=dataTrain.na.fill(avgAge,Seq("Age"))
dataTrain=dataTrain.withColumn("fixAge",fillAge(dataTrain("Age"),dataTrain("Title")))dataTrain=dataTrain.withColumn("Pclass",toDouble(dataTrain("Pclass")))dataTrain=dataTrain.na.fill(avgFare,Seq("Fare"))dataTrain=dataTrain .withColumn("withFamily",withFamily(dataTrain("SibSp"),dataTrain("Parch")))dataTrain.withColumn("sexMod",addChild(dataTrain("Sex"),dataTrain("Age")))}
20
SelecIngFeatures&GeneraIngFeaturesKaggleTitanicChallenge:SQL&Scala

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ETL(Extract,Transpose,Load)&FeatureCreaIon
query="””SELECTx,year(x)ASYear,month(x)ASMonth,dayofmonth(x)ASDoM,dayofyear(x)ASDoY,date_format(x,"EEEE")ASlongDoW,date_format(x,"EE")ASshortDoW,date_format(x,"u")ASDoW,IF(date_format(x,"u")<6,0,1)ASweekendFlag,IF(date_format(x,"u")<6,datediff(next_day(x,"Sat"),x),0)ASdaystoWeekend,floor(months_between(current_date(),x)/12)AScurAge,IF(dayofyear(CONCAT(year(x),"-12-31"))>365,1,0)ASleapYearFlag,IF(month(x)=12ANDdayofmonth(x)>25,months_between(CONCAT(year(x)+1,"-12-25"),x),months_between(CONCAT(year(x),"-12-25"),x))ASmonthstoXmas,IF(month(x)=12ANDdayofmonth(x)>25,datediff(CONCAT(year(x)+1,"-12-25"),x),datediff(CONCAT(year(x),"-12-25"),x))ASdaystoXmas,IF((datediff(CONCAT(year(x),"-12-25"),x)<=14)AND(datediff(CONCAT(year(x),"-12-25"),x)>=0),1,0)ASx14dayBefore,quarter(add_months(x,-2))ASSeason,quarter(x)ASQtrFROMinputDate""".trim()
21
CanyouSQLtocreatenewfeaturesfromdata,examplegenera0ng0mefeatures

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ApacheSpark2.0.0GreatNewFeatures
• SparkSQL– SQL2003andUnifiedDataFrames/DatasetsAPI.– TungstenPhase2:WholeStageCodeGen
• SparkMLlib&GraphX–LargeScaleMachineLearningonApacheSpark– DataFrameAPIisprimaryAPIforMLlib(RDDmodeinmaintenance)– MLpersistencecancreatemodel,thensaveandredeploy
• hNps://databricks.com/blog/2016/05/31\• StructuredStreaming
– IntegraIonofDataFrames/Datasets&Streaming– PowerofSQL
22
Bestnewfeatures-MLlib&StructuredStreaming

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ML-MachineLearning• AutomaQcallysifingthroughlargeamountsofdata
– tofindpreviouslyhiddenpaNerns,– todiscovervaluablenewinsightsandmakepredicIons
• Examples:• Idmostimportantfactors(ApributeImportance)• Predictcustomerbehaviors(Classifica$on)• PredictoresImateavalue(Regression)• SegmentapopulaIon(Clustering)• Findfraudulentor“rareevents”(AnomalyDetec$on)
• Determineco-occurringitemsina“baskets”(Associa$ons)• Findprofilesoftargetedpeopleoritems(DecisionTrees)
23
A1A2A3A4A5

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
MachineLearning(ML):Scoring/PredicIonversusTraining/LearningCharacterisIcsPredic0on/Scoringoperatesonhugeamountsofdatawithlowcomputeintensity
MLPredic0on
MLTrain
%ofac0vity MostData *periodic
Computa0on O(n) O(n^3)Matrix-matrix
Data O(n) O(n^2)
ComputeIntensity(Compute/Data) Lowconstant O(n)
MemoryBandwidthRequirement
3xto6xpercore
Upto1.3xpercore
24
TrainingSet
PredicIon/Scoring/Spark’sTransform
Results
Cantrain/fitononeserverthenmovemodeltopredic$onserver(ex:StubHub)
Model Training/Learning/Spark’sFit
DatatoEvaluate
*periodicallyupdatestomodels:quarterly,monthly,weekly,nightly

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SavingtheMLmodelinApacheSpark
• Train/FitaRandomForestClassifierinPython,saveit
• CanloaditbackinPython• CanLoadintoaScalatoPredict/Transform
25
Modelcanbemovedbetweenlanguages:
trainingData=sqlContext.read...#data:features,labelrf=RandomForestClassifier(numTrees=20)model=rf.fit(trainingData)model.save("myModelPath”)
//LoadthemodelinScalavalsameModel=RandomForestClassificaIonModel.load("myModelPath")valpredicIons=sameModel.transform(mybigdata)
sameModel=RandomForestClassificaIonModel.load("myModelPath")MLlibalsoallowsuserstosave/loaden$reMLpipelines
Training
Predict
hNps://databricks.com/blog/2016/05/31/apache-spark-2-0-preview-machine-learning-model-persistence.html

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
HowcanwemakeSpark2.x.xevenFaster?ItcanbemadeaLOTFASTER:8xto20x!“Youcanonlycomputeasfastasyoucanmovedata”–BradCarlile
26

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Let’sExploreFirstPrinciplesThinkingWhatarethetruewaystogetatefficiency–AquickAnalogy
• WheretoLocateaFactory?Example:ElonMusk’sTeslaGigaFactory
27
TeslaGigaFactory ApacheSparkPerformance
Conven0onalWisdom 1) TaxIncenIves 1)Manycheapcores&Cloud
hpp://fortune.com/2015/12/11/nevada-energy-tech-hub/

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Let’sExploreFirstPrinciplesThinkingWhatarethetruewaystogetatefficiency–AquickAnalogy
• WheretoLocateaFactory?Example:ElonMusk’sTeslaGigaFactory
28
TeslaGigaFactory ApacheSparkPerformance
Conven0onalWisdom 1) TaxIncenIves 1)Manycheapcores&Cloud
FirstPrincipleThinkingCloselyLookateachcomponentWhatarealloftheissues
1) Nevada’sEnergycosts1) BestGeothermalnear2) Sun(2100kWh/kW-yr)3) Wind(~8-10ms/s)
2) Nevada’sRawMaterials1) OnlyLithiumMineinUS2) Lithiumsaltsnearby
3) FewhoursfromBIGMARKETS1) Taxincen$ves(don’thurt)
hpp://fortune.com/2015/12/11/nevada-energy-tech-hub/

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Let’sExploreFirstPrinciplesThinkingWhatarethetruewaystogetatefficiency–AquickAnalogy
• WheretoLocateaFactory?Example:ElonMusk’sTeslaGigaFactory
29
TeslaGigaFactory ApacheSparkPerformance
Conven0onalWisdom 1) TaxIncenIves 1)Manycheapcores&Cloud
FirstPrincipleThinkingCloselyLookateachcomponentWhatarealloftheissues
1) Nevada’sEnergycosts1) BestGeothermalnear2) Sun(2100kWh/kW-yr)3) Wind(~8-10ms/s)
2) Nevada’sRawMaterials1) OnlyLithiumMineinUS2) Lithiumsaltsnearby
3) FewhoursfromBIGMARKETS1) Taxincen$ves(don’thurt)
1) UseallofDeliveredBandwidth
2) JVMperformanceop0miza0ons
3) Innova0onsforscanningopera0ons
hpp://fortune.com/2015/12/11/nevada-energy-tech-hub/

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Whole-stageCodeGenPerformance
• Let’sevaluaIonperformanceonFullTableScanof600Mrows– TimetoScan=0.16secImpressive:104.7MillionRows/secpercore
30
2-chipx86E5v3(Haswell),total36cores,72threads/VCPU

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Whole-stageCodeGenPerformance
• Let’sevaluaIonperformanceonFullTableScanof600Mrows– TimetoScan=0.16secImpressive:104.7MillionRows/secpercore
• Goingbackto1stprinciples:Scanningisaboutdatamovement– Whatisthesystembandwidthofthisin-memoryScan? 15GB/s(Spark2.0.0)– Whatisthesystemmemorybandwidthofthesystem? 114GB/s(StreamTriad)– 7.6xmorebandwidthavailable!
• OtherQueries:“SELECTcount(*)FROMlineorderWHERElo_quanItyBETWEEN10and20”
– 19xmorebandwidthavailable!(onlydelivering6GB/sonthesystem)
31
2-chipx86E5v3(Haswell),total36cores,72threads/VCPU

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
AferSpark2.0:BigLeapinPerformancePossibleSelectcount(*)fromstore_saleswheress_item_sk>100andss_item_sk<1000
1. VolcanoIteratormodel:planinterpretaIon– Open;Nextdataelement;performpredicate;Close
2. “CollegeFreshman”Javacode:Whole-StageCodeGenpipelinedcode– for(ss_item_skinstore_sales){if(ss_item_sk>100andss_item_sk<1000){count+=1}}
3. Tunedlibrary:TrueVectorizaIonhighlytunedcodeoperatesonwholecolumn– vectorRangeFilter(n,VECTOR_OP_GT,1000,VECTOR_OP_LT,1000,store_sales,result,result_cnt)
4. HardwareAccelera0onfurtheracceleratesscanning– vectorRangeFilter(n,VECTOR_OP_GT,1000,VECTOR_OP_LT,1000,store_sales,result,result_cnt)
• x86AVX2(GraphicsInstrucIon)–Canachieve70GB/sperchip• Oracle’sSPARCM7/S7processors–evenfaster
32

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
libdaxOpenAPIforFree&OpenSourceSofware(FOSS)
• DesignedtoacceleratewidevarietyofOracle&FOSSsofware– Examples:
• SQLacceleraIonforOracleDatabasein-memory• ApacheSparkSQL
– DataFrames(Python,Scala,Java,R)– Parquetexperimentsinprogress
• Publishedsamplecodes
• OpenAPIforlibdax–signupforfreesystemstoactuallydevelop/trycode– hNps://swisdev.oracle.com– x86&SPARCversions(x86&genericoutsoon!)
Libdaxdesignedforkeyscan&dic0onaryopera0onstoaccelerateavarietyofsoxware
33

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Whatelseaferoneusesallofthebandwidth?ItcanbemadeaLOTFASTER:8xto20x!
34

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
In-MemoryPerformanceOpImizaIons
• ColumnarFormat• VectorProcessing
– DirectlyonDicIonary-encodedColumns
• OperaIonpushdown• JoinProcessingacceleraIons
– BloomFilters:bitvectorsetmembershiptesIng
• In-MemoryStorageIndex• PredicateOpImizaIon
– UsingDicIonaryvalues,Min,Max,…
35
T.Lahiri,et.al.OracleDatabaseIn-Memory:ADualFormatIn-MemoryDatabase.ProceedoftheICDE2015.
hNp://www.oracle.com/technetwork/database/in-memory/overview/twp-oracle-database-in-memory-2245633.html

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
In-MemoryColumnarFormat:FasterforAnalyIcsRow-formatrequiresskippingoverdataslowerforAnaly0cs
SELECT COL4 FROM MYTABLE
36
In-memoryColumnFormat
IMColumnStore
RESULT
With columnar we only Scan the data required by the query Spark does Push-down Predicates for Parquet Files … We need Columnar in-memory for Spark Internal format

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
LowerCardinalityDataisUsuallyMostInteresIngDataAnaly0csanalyzingfeaturesoflowercardinalitydata
AnalyIcsofendisIllsdatabygroupingaccordingtocombinaIonsoffeaturesInML,weofen“BuckeIze”toreducecardinality
37
UniqueorRandom
Data
Gender
Season
5-pointScale
MaritalStatus
Top10
10ranking
Month
Hour
State
Weeks
Minutes
Age
TestScore
Country
USCity>100k
Days
Top500 JobClassifica$onAreacode
Nasdaq NYSE
Top5,000
Schooldistricts zipcode
DOBlast150years
Temperature
RainfallWinddirec$on
Region
Price
Deliverystatus
MostInteres$ngdatahasfewerdic$onarybitsMake
Model
2-bit3-bit4-bit5-bit6-bit7-bit8-bit9-bit10-bit11-bit12-bit13-bit14-bit15-bit16-bit17-bit18-bit19-bit...Cardinalityn-bits(calculatedas2^n-bits)“Entropy”

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
In-MemoryColumnarCompression–PersistinMemory
• EfficientInMemoryColumnarTableScan– ConIguousstoragepercolumn
• DicIonaryencodinghugecompression– 50USonlyneed6bits(<1byte)– Spellingoutthestatenameismuchlonger
• “SouthDakota”needs12charactersor24unicodebytes(192bitsvs.6bits)
• Innova0ons:– Directlyscandic$onaryencodeddata!– SaveMin&MaxforscaneliminaIon– AddiIonalcompressiononcolumnalsopossible– CanusedicIonaryfor“featurizaIon”ofdataforML
38
0132023
ColumnMin:SouthDakotaMax:Utah
DicQonary
Dictencode
Columnvaluelist
SouthDakota
Tennessee
Utah
Texas
SouthDakota
Texas
Utah
DicQonaryVALUEID
SouthDakota0Tennessee1Texas2Utah3
Zip+
RLE)

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ApacheSpark:Objects&TungstenIn-memoryColumnarOracleincorpora0nglibdax&fixingmisalignmentsinApacheSpark
• TypesafeoperaIonsinScalaaccessJVMobjectformaNedrepresentaIon
• SQL&DataframeoperaIonsneedtoaccessin-memorycolumnformat– Tungsten:SQLoperatesoninternalformat– Needtopersistincolumnformat– Currentlynotusedic$onaryencodingtospeedSQL/DataFrameexecu$on
39
ApacheSparkCurrentlydoesn’tstorecolumnardataforreuse,OnlyregeneratescolumnseachQmeonflyeachQmeit’sused
JVMOff-heapMemory
SALES SALES
JVMObjectFormat
TempInternalColumnFormat
Scala,Python,R,…
Future?SPARK-15687DataFramesSQLexecu$on
Encode
Decode

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
Developers:AreasthatneedcontribuIon
• ContributeInnovaIveNewAlgorithmsthroughoutApacheSpark!• Contributethird-partypackagesthatintegratewithApacheSpark
– hNps://sparkhub.databricks.com/“FreeApp-storeforApacheSpark”
• Improvesingle-nodeperformance&scalability– Improveperformanceoflarge-coresystems
• x86processorcontains22-coresperchip,SPARCprocessorcontains32-coresperchip• Thistrendkeepsincreasing–HUGEBANDWIDTHonCHIP
– Networkbandwidthnotkeepingup
• Fixmis-alignmentswhichhurtperformance– Example:pre-appended4-bytesigned-intstostrings,causedmis-aligned,converttolongs
• hNps://issues.apache.org/jira/browse/SPARK-16962
40
ShoutouttoallDevelopers

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
ApacheSparkisExci0ng–MoreGreatWorktoCome!Spark’sWholeEcosystemtotallyappealstotheperformanceexpertinme!
• GreatEcosystemforAnalyIcs– SparkformsaconInuumwithothertechnologies(Kaaa,Solr,…)
• Sparkisfast&scalablebecauseofcleandesign– Spark’sin-memoryfocus
• Sparkcanbemuchfaster– PoisedformanyinnovaIonsthattakeadvantageofhardwaresystems– Oracle’sSofwareinSiliconcanbeusedonApacheSpark
• KeepUsing,ContribuIng,andSharing!
41

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
OracleSPARCM7&S7:InnovaIonsforCloud&AnalyIcs
• [email protected],512GBmemoryperchip– >160GB/sdeliveredmemorybandwidthperchip
• Java/JVM,Database,ApplicaIons,etc.SPARC1.6xto2.0xfastercorevs.x86– LiNlegrowthinx86percoreperformance
• SofwareinSiliconFeatures– In-MemorySQLAcceleraIon&Decompression– HardwareacceleratedEncrypIon– SiliconSecuredMemory
Deepinnova0onsdifferen0ateSPARCfromthegenericcompu0ng
hNps://blogs.oracle.com/bestperf
0.8x
1.0x
1.2x
1.4x
1.6x
1.8x
2.0x
2012 2013 2014 2015 2016
CorePerform
ancevs.x86E5v2
Java/JVMOLTPMemGB/s
X86:dashed

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
FirstPrincipleThinking:BandwidthforApacheSparkIn-memoryScanul0matelydeterminedbyMemoryBandwidth
• “…nomaperhowhighperformancemyengineis,ifIneedtoscanaTerabyteofdatatoanswermyqueryit’sgoingtobeslowevenifyouarereadingfrommemory”
– PatrickWendell,Databricks(June4,2015onO’ReillyDataShowPodcastwithBenLorica)
• Let’ssayIhave1TBIn-MemorythatIwanttoscanin1second– Weneed31C4.8xlarge(62chips)toscanin1second,(1024GB/33.6GB/s)– SPARCM7-8(8-chips)serverhas1.2TB/sdeliveredBandwidthin10RU
43
IBMPower8E880SPARCM7-8 x86E7v3Haswell
CirclesshowProcessorsInter-chipbandwidthsaretoscale
Fullyconnected 2-hop 2-hophNp://browser.primatelabs.com/geekbench3/5105516hNp://browser.primatelabs.com/geekbench3/1694602
4xE5v3Haswell
10GbEconnected

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
SPARCDAXSofwareinSiliconforAnalyIcs(OracleDB&Spark)
• IntegratedOffload– DataAnalyIcsAcceleraIon(DAX)– OPEN!AddtoyourownApplicaIons
• hNps://swisdev.oracle.com
• It’smoreimportanthowyouusetransistors,thanMoore’sLaw(#transistorsyoumake)
RadicalInnova0on:IntegratedOffloadoffers10xfasterperformance!
• OracleDatabaseAnalyIcQueries• SPARCM710.8xfasterperchipx86E5v3
• SametechniquesapplytoApacheSpark
Memory
HalfBW
Memory
x86E5v3
X86100%U0lizedNOOFFLOAD!NOOPENCores!
Band-Width
SPARCM7
DAXOFFLO
AD O
FFLOADDAX
44hNps://blogs.oracle.com/bestperf/entry/20151025_imdb_t7_1

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
QuesIons?
45

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.| 46

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
BackupSlidesOracleDatabase12cIn-memoryDatabaseInnova0ons…allinnova0onsthatcanapplytoApacheSpark
47
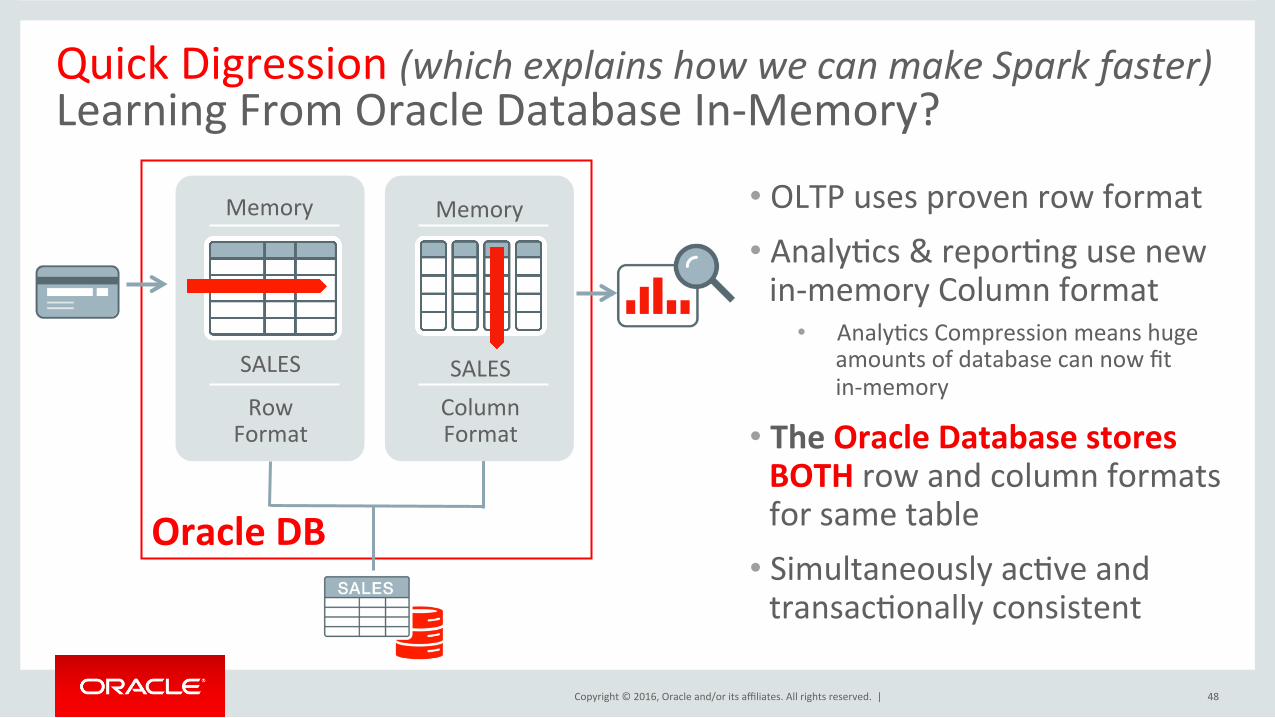
Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
OracleDB
QuickDigression(whichexplainshowwecanmakeSparkfaster)LearningFromOracleDatabaseIn-Memory?
• OLTPusesprovenrowformat• AnalyIcs&reporIngusenewin-memoryColumnformat
• AnalyIcsCompressionmeanshugeamountsofdatabasecannowfitin-memory
• TheOracleDatabasestoresBOTHrowandcolumnformatsforsametable
• SimultaneouslyacIveandtransacIonallyconsistent
48
Memory Memory
SALES SALESRow
FormatColumnFormat

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
OperaIonPushdown:ReduceRowsProcessedbyPlan• Whenpossible,pushoperaIonsdowntoIn-Memoryscan
– Greatlyreduces#rowsflowingupthroughtheplan
• Forexample:– PredicateEvaluaIon(forqualifyingpredicates–equality,range,etc.):
• InlinepredicateevaluaIonwithinthescan• EachIMCUscanonlyreturnsqualifyingrowsinsteadofallrows
• Anotherexample– AggregaIon(forqualifyingaggregates,e.g.sum(),min/max(),etc.):
• IMCUisaggregatedduringthescan.• EachIMCUscanreturnsonlytheaggregate(e.g.thesum)• Upperplannodesaggregatestheaggregates(e.g.sumofsums)
IMscanProducts
Sales>1000
IMscanStores
49
State=CA
SALES>1000
STATE=CA

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
OperaIonPushdown:BloomFilter• BloomFilter:
• CompactbitvectorforsetmembershiptesIng
• 10gopImizerfeature
• Bloomfilterpushdown:• FilteringpusheddowntoIMCUscan
• Returnsonlyrowsthatarelikelytobejoincandidates
• Joinstables10xfaster
50
Example:FindtotalsalesinoutletstoresSalesStores
StoreID
StoreIDin15,38,64
Type=‘Outlet’
Type
Sum
StoreID
Amou
nt
BloomFilter

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
In-MemoryStorageIndex:EliminateIMCUsfromScan• Min-MaxPruning
– Min/Maxvaluesserveasstorageindex– Checkpredicateagainstmin/maxvalues– SkipenIreIMCUifpredicatenotsaIsfied– EliminatesprocessingunnecessaryIMCUs– Canpruneforpredicatesincludingequality,range,inlist,…
• DicIonarypruning– DicIonariesalsoserveasstorageindex– CheckpredicateagainstdicIonaryvalues
• “FindsalesfromstoresinNevada”
– SkipenIreIMCUifpredicatenotsaIsfied
Min$4000Max$7000
Min$8000Max$12000
Min$13000Max$15000
Example:Findstoreswithsalesgreaterthan$10,000
51

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
• AvoidevaluaIngpredicatesagainsteverycolumnvalue– Checkrangepredicateagainstmin/maxvalues
• Asbefore,skipIMCUswheremin/maxdisqualifiespredicate
– Ifmin/maxindicatesallrowswillqualify,noneedtoevaluatepredicatesoncolumnvalues
Min$4000Max$7000
Min$8000Max$13000
Min$13000Max$15000
Example:Findstoreswithsalesbetween$8000and$14000
NOROWSSkipIMCU
SOMEROWSNeedsevalua0on
ALLROWSSkipEvalua0on
PredicateOpImizaIon:ReducePredicateEvaluaIons
?
52

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
PredicateOpImizaIon:ReducePredicateEvaluaIons
• Ifmin/maxcannoteliminatepredicate– EvaluatepredicateonceperdicIonaryvalue– CreatelistofqualifyingdicIonaryvalues
• UsevectorinstrucIonstofindqualifyingvaluesincolumn
• GreatlyreducespredicateevaluaIons– OnceperdisInctvaluevs.ofoncepervalue
• Alsoformorecomplexpredicates…– LIKEpredicates:ex:Findsalesofproductnamescontaining“mustard”
Example:Findstoreswithsalesbetween$8000and$14000
514334455301
VectorCom
pare
{0,1,2,3}
$13,000
$13,500
$13,800
$13,900
$14,500
0
1
2
3
4
Dic0onary ColumnCU
$15,0005
53
Apple
EnglishMustard
MustardGreens
0
1
2
Dic0onary

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
BackupSlidesOracle’sSPARCProcessor
54

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
(1) Factoryconfiguredwithone(upto8processors)ortwo(upto4processorseach)sta$cphysicaldomains(2) 1,2,3or4reconfigurablephysicaldomains(3)Maximummemorycapacityisbasedon32GBDIMMs,capacitycandoubleinfuturewith64GBDIMMs
SPARCT7&M7Systems-AllShippingNow“-#”indicateshowmanychipsinserver
T7-1 T7-2 T7-4 M7-8 M7-16
Processors 1 2 2or4 Upto81 Upto162
MaxCores 32 64 128 256 512
MaxThreads 256 512 1,024 2,048 4,096
MaxMemory3 .5TB 1TB 2TB 4TB 8TB
FormFactor 2U 3U 5U Rack/10U Rack
Domaining LDOMs LDOMs LDOMs LDOMs,PDOMs1 LDOMs,PDOMs2
ConfidenIal:OracleRestricted55

Copyright©2016,Oracleand/oritsaffiliates.Allrightsreserved.|
(1) Maximummemorycapacityisbasedon64GBDIMMs.
SPARCS7Servers
SPARCS7-2Server SPARCS7-2LServerProcessors 1or2 2MaxCores/Threads 16/128 16/128MaxMemory1 1TB 1TBFormFactor 1U 2UMaxDiskDrives 8 26PCIeSlotsAvailable 3 6
IntegratedEthernet 4x10GBase-T 4x10GBase-T
S7-2L
Storage
Storage
S7-2L



















