

Autoscaling Spark on AWS EC2 - 11th Spark London meetup
46
Autoscaling Spark for Fun and Profit Rafal Kwasny 11th Spark London Meetup 2015-11-26
-
Upload
rafal-kwasny -
Category
Technology
-
view
2.353 -
download
1
Transcript of Autoscaling Spark on AWS EC2 - 11th Spark London meetup

Autoscaling Spark for Fun and Profit
Rafal Kwasny11th Spark London Meetup
2015-11-26

Who am I
•DevOPS•Build a few platforms in my life•mostly adtech, in-game analytics for Sony Playstation
•Currently advising Investment Banks•CTO Entropy Investments

How do you run spark?
•Who runs on AWS?
•Who uses EMR?

So how to use autoscaling on AWS?

Overview
•typical architecture for AWS
•How autoscaling works
•Scripts to make your life easier

Typical architecture for AWS

Typical architecture for AWS
Generate some data

Typical architecture for AWS
Store it in S3

Typical architecture for AWS
or store it in a message queue

Typical architecture for AWS
Use your favourite tool for ETL

Typical architecture for AWS
Ship it back to S3

Typical architecture for AWS
Or send it somewhere

Typical architecture for AWS
- EMR- spark-ec2- build cluster from scratch

Map-reduce is about quickly writing very inefficient code and then running it at massive scale
(C) Someone

Problem
•EC2 is a pay-for-what-you-use model
•You just have to decide how much resources you want to use before starting a cluster

Problem
Most common problems while running on EC2
Scaling up•My team needs a new cluster, how big it should be?
Scaling down•Did I shut down the DEV cluster before leaving the office on Friday evening?

How to automate scaling?

Types of scaling
Vertical scaling - „Let’s get a bigger box”
•Change instance type•Change EBS parameters
Horizontal scaling - „Just add more nodes”

Autoscaling
•Automatic resizing based on demand•Define minimum/maximum instance count•Define when scaling should occur•Use metrics•Run your jobs and don’t worry about infrastructure

Architecture with autoscaling

Using RAM/local SSDs for caching
Only saving output into S3

Fault recovery

Autoscaling components
•AMI - machine image with installed spark•Launch configuration - defines:
•AMI•instance type•instance storage •public IP•security groups

Autoscaling components
•Autoscaling group•launch configuration•availability zones•VPC details•min/max servers•when to scale•metrics/health checks

Putting it all together
Then you can run your job

Complicated?
•AWS provides a lot of services

spark-cloud
• Better scripts to start spark clusters on EC2
• Alpha version
• https://github.com/entropyltd/spark-cloud



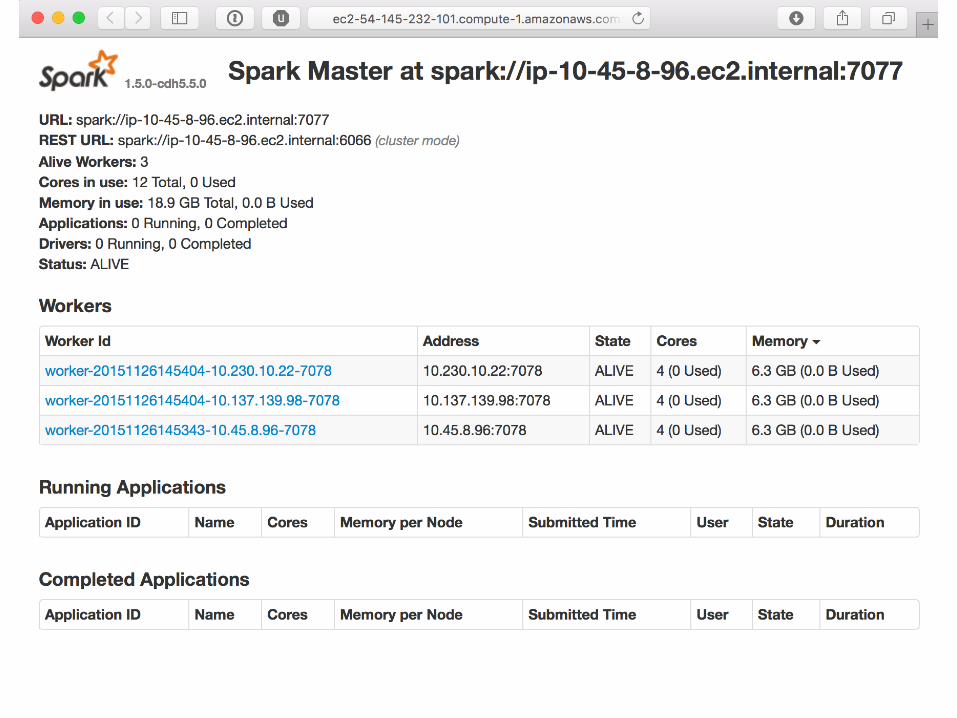







What’s inside spark-cloud
Building AMI’s through packer
Packer is a tool for creating machine and container images for multiple platforms from a single source configuration.
Supports AWS, DigitalOcean, Docker, OpenStack, Parallels, QEMU, VirtualBox, VMware

Current functionality
•Start cluster
•Shutdown cluster
•But more to come :)

Spot instances
•Spot instances

Spot instances
–On-Demand: $1.400
–Spot: $0.15–89% cheaper

Summary
•Spark and EC2 is a very common combination•Because it makes your life easier•And cheaper•spark-cloud script will help you•You can just worry about writing good Spark code!


Amazon S3 Tips
•Don’t use s3n://•Use s3a:// with hadoop 2.6
–Parallel rename, especially important for committing output–Supports IAM authentication–no „xyz_$folder$" files–input seek–multipart upload ( no 5GB limit )–Error recovery and retry
More info https://issues.apache.org/jira/browse/HADOOP-10400

Why not EMR?
•Why pay for EMR? It costs more than a spot instance
•vendor lock-in and proprietary libraries•netlib-java


















