

Autoscaling Kubernetes
20
-
Upload
craigbox -
Category
Technology
-
view
474 -
download
2
Transcript of Autoscaling Kubernetes
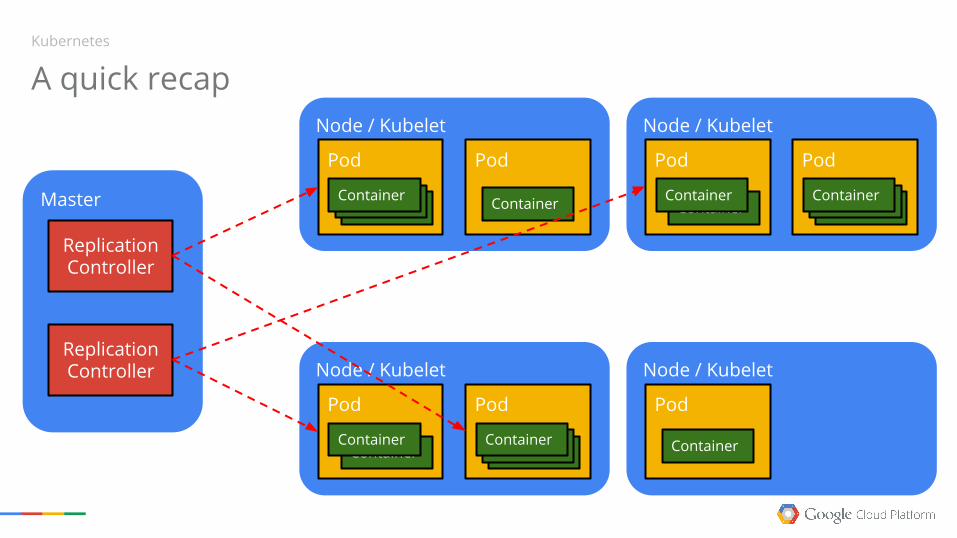
A quick recapNode / Kubelet
Pod
ContainerContainerContainer
Pod
Container
Node / Kubelet
Pod
ContainerContainer
Pod
ContainerContainerContainer
Node / Kubelet
Pod
Node / Kubelet
Pod
ContainerContainer
Pod
Master
ReplicationController
ReplicationController
ContainerContainerContainerContainer
Kubernetes

Revision
Autoscaling
Autoscaling: the ability of a system to automatically adjust the amount of used computational resources based on the load
Benefits:
● reduce cost (on cloud provider)● reduce power consumption
Horizontal: scale the number of instances
Vertical: scale the resources used by an instance

Autoscaling KubernetesKubernetes
Nodes Pods
Horizontal # of nodes # of pods
Vertical resources for a node resources for a pod

Kubernetes
Horizontal autoscaling of nodes
Nodes Pods
Horizontal # of nodes # of pods
Vertical resources for a node resources for a pod

Example: on Google Cloud PlatformAutoscaling nodes
Google Compute Engine:
● Infrastructure as a Service (IaaS)● user can create virtual machines on demand● charged on a base of per-minute cost
Google Compute Engine is an exemplary platform for Kubernetes:
● user may set-up his own cluster on Google Compute Engine● user may buy a predefined cluster (Google Container Engine)
In both cases, Google Compute Engine virtual machine are used as hosts for Kubernetes master and nodes.

Managed Instance GroupAutoscaling nodes
Manage virtual machines in bulk!
Managed Instance Groups (Google Compute Engine) collectively manage groups of similar virtual machine instances (in the same zone).
A Managed Instance Group creates virtual machines on a base of instance template:
‒ image (e.g.: debian distribution)‒ startup script (e.g.: install pkgs and start services)‒ shutdown script (e.g: gracefully stop services)‒ + more...
Managed Instance Groups can be manually resized.
Managed Instance Groups are now available for Google Compute Engine users.

Autoscaling MIGsAutoscaling nodes
Let the Cloud Autoscaler choose the best size of Managed Instance Group for you!
Intent based:
● User specifies average target utilization level for VMs.● Cloud Autoscaler collects and interprets utilization data and determines how many VMs should be added
or removed from the Managed Instance Group to achieve close to the target utilization.
Autoscaling policies (currently supported):
● CPU utilization,● HTTP load balancing serving capacity,● Custom Cloud Monitoring Metrics.
Autoscaling behaviour: increase rapidly, decrease gracefully.
Cloud Autoscaler is now available as for Google Compute Engine users.

Kubernetes on a MIGAutoscaling nodes
NodeController automatically discovers nodes by querying cloud provider(based on a regular expression for node names).
Let’s create a Managed Instance Group for nodes!
Resize of Managed Instance Group → resize of cluster.
Master remains on a separate VM (not in the Managed Instance Group), unaffected by resize.
The idea is good, but there are some problems...

ProblemsAutoscaling nodes
● Each node needs to have an IP range (for pods):NodeController distributes IP ranges to nodes during assimilation of a new node.
● Graceful removal of node:○ mark node an unschedulable in spec (no new pods will be scheduled on it)○ notify containers that the nodes will be removed
(they can stop accepting new traffic, finish writing persistent data, etc)○ wait for a while before removal
May be triggered by shutdown script in Managed Instance Group.
● Rebalancing of pods on node addition:○ adding new node will not affect already schedule pods○ the new node may be empty, potentially for a long time○ first add node, then increase replication controllers
May be solved by rescheduling/rebalancing.
Done
Proposal
???

Autoscaling Kubernetes nodesAutoscaling nodes
Just use Cloud Autoscaler to scale Managed Instance Group for nodes!
Considered signals for scaling:
● resource utilization (CPU, memory)● signals from scheduler (e.g.: # of pending pods)

Horizontal autoscaling of PodsKubernetes
Nodes Pods
Horizontal # of nodes # of pods
Vertical resources for a node resources for a pod

Autoscaling Replication ControllersAutoscaling pods
Effort started by Red Hat.
AutoScaler:
● abstraction on the top of ReplicationController,● calls resize on RC,● RC is unaware of AutoScaler.
Two approaches:
● intention based - try to maintain the given value;● rule based - if the given value is reached, execute the given action
(increment/decrement).
Proposal

ProblemsAutoscaling pods
Simplest solution: AutoScaler acts on a single ReplicationController.
However: we often have many RCs for service (e.g.: rolling update).
Improved solution: AutoScaler acts on set of RCs (with matching labels):
● monitor selector - RCs to monitor● target selector - RCs to act on (the largest of them)● during deployment / rolling update - option to disable decrement
How to collect signals:
● cAdvisor → Heapster → InfluxDB● Google Cloud Monitoring (Google Container Engine)
Proposal
???

Autoscaling during rolling updateAutoscaling pods
ReplicationControllerversion 1.4
AutoScaler
PodPodPodPod
↕

Autoscaling during rolling updateAutoscaling pods
ReplicationControllerversion 1.4
AutoScaler
PodPodPod
↑ReplicationControllerversion 1.6
PodPod

Autoscaling during rolling updateAutoscaling pods
ReplicationControllerversion 1.4
AutoScaler
PodPod
ReplicationControllerversion 1.6
PodPod
Pod
↑

Autoscaling during rolling updateAutoscaling pods
ReplicationControllerversion 1.6
AutoScaler
PodPodPodPod
↕

ProblemsAutosclaing pods
Simplest solution: AutoScaler acts on a single ReplicationController.
However: we often have many RCs for service (e.g.: rolling update).
Improved solution: AutoScaler acts on set of RCs (with matching labels):
● monitor selector - RCs to monitor● target selector - RCs to act on (the largest of them)● during deployment / rolling update - option to disable decrement
How to collect signals:
● cAdvisor → Heapster → InfluxDB● Google Cloud Monitoring (Google Container Engine)
Proposal
???

Questions?


















