
Peer-to-Peer Computing CS587x Lecture Department of Computer Science Iowa State University.
26
Peer-to-Peer Computing CS587x Lecture Department of Computer Science Iowa State University
-
Upload
damon-boone -
Category
Documents
-
view
222 -
download
0
Transcript of Peer-to-Peer Computing CS587x Lecture Department of Computer Science Iowa State University.

Peer-to-Peer Computing
CS587x LectureDepartment of Computer Science
Iowa State University

What to Cover
Review on some P2P applications Napster Gnutella Freenet
Discussion and summary
Resource Sharing
Questions to answer in order to design a resource-sharing network How to add new nodes to the network How can one node know about others How can a node find and retrieve data How to manage the shared data
users

Client/Server ArchitectureCreate a server to store the information that these nodes want to share
The server is the only data source Clients request data from serverExample: mp3.com
A client registers to mp3.com and uploads its music files to the server
The songs are then stored and indexed on a server that is part of the web site
Other uses can connect to the web site and downloads the songs they are interested in
Limitation of C/S model Scalability is hard to achieve Presents a single point of failure Requires administration Unused resource at the network edge

Some P2P Applications
NapsterGnutellaFreenet
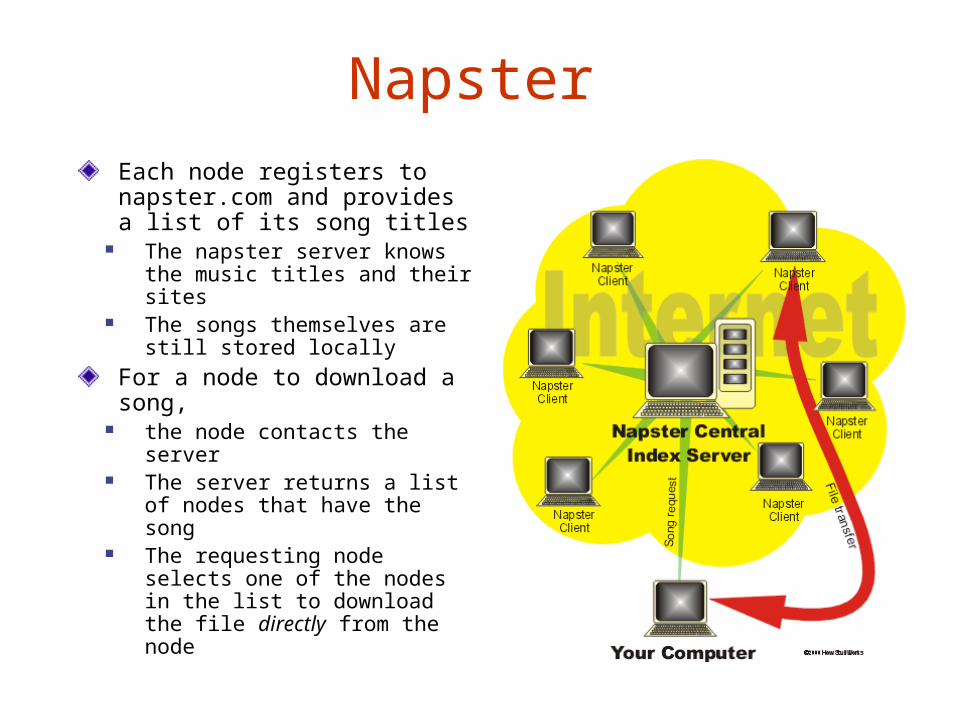
NapsterEach node registers to napster.com and provides a list of its song titles
The napster server knows the music titles and their sites
The songs themselves are still stored locally
For a node to download a song,
the node contacts the server
The server returns a list of nodes that have the song
The requesting node selects one of the nodes in the list to download the file directly from the node

Highlights of Napster
Main innovation: a client downloads a music directly from another client, i.e., P2P communication
After a client downloads a music, it can serves other clientsNapster server itself does not have any music files
It acts as a directory or brokerAdvantages
Each consumer contributes its resource (disk and bandwidth) and content to the community
Contents are more reliable because the same file is stored in many nodes, which are geographically distributed
Administration and service cost are minimalDrawback
Napster is a hybrid P2P system since a central server is required to coordinate file sharing
The central server presents a single point of failure

Gnutella
Creating a Gnutella network A node joins the network with a PING to
announce self IP address, port, number/size of shared files
Receivers forward the Ping to their neighbors Receivers back-propagate a PONG to announce
self Each Pong includes sender’s IP address, number/size of
shared files
Maintaining a Gnutella network PING neighbors periodically PING Well-known root nodes if starting from
scratch

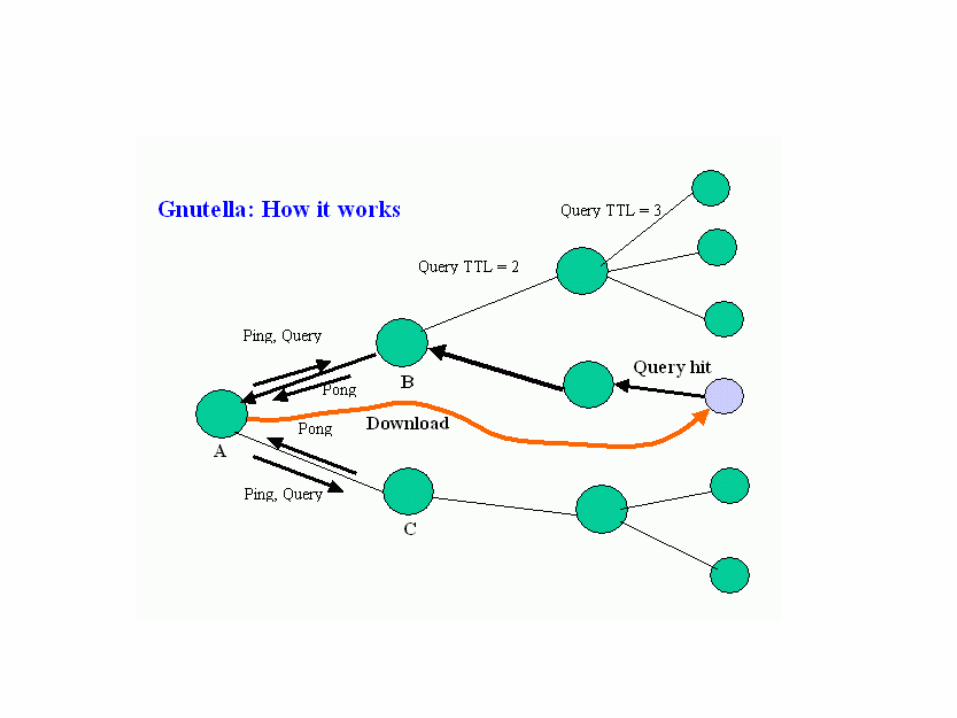
Search Protocol
For node A to request a file (any kind), itcreates a query (A, S, N, T), where S is search string, N unique request ID, T Time-to-Livechecks local system, if not found
Sends (A, S, N, T) to all Gnutella neighbors
B receives a query (A, S, N, T) If B has already received query N or T = 0, drops the
query Otherwise, B looks up S locally and sends (N, Result) to A
if anything found Any kind of look up (could simply grep, or construct some sql
cmd) If not found locally,
B sends (B, S, N, T-1) to all of its Gnutella neighbors B records the fact that A has made the request N
When B receives a response of the form (N, Result) from one of its neighbors, it forwards the response to A

Gnutella Messages
PING request the transitive closure of connected nodes to identify
them, essentially asking the question "Are you there?“PONG
response by a node upon receiving a PING; the responding node provides its IP address and number of sharable files it contains. This gives the answer that "Yes, I am here….“
QUERY request to locate a set of files matching some filter criteria.
These are messages stating, "I am looking for x".HITS
response to a query giving a list of files matching the filter criteria and the IP address of the provider, can be many in number.
GET/PUSH request a file provider to contact the requester. This
provides a simple mechanism to attempt to get through firewalls

Partial Map of a Gnutella Network

Highlights of Gnutella
Pure P2P Unlike Napster, Fully decentralized, no single
point of failure
Limitations Scalability: if you send out a request with a
TTL of 10, and each site contacts six other sites, up to 61+62+63+64+65 +66+67+68+69+610 messages could be exchanged
Not anonymous: since result contains the URL string, the source provider can be tracked – this is addressed in Freenet

Freenet
Freenet is a pure P2P system mainly designed to support distributed information storage and retrieval anonymity for producers, consumers and
holders of information adaptive respond to usage patterns
Freenet differentiates from Gnutella mainly in Retrieving data Storing data Managing data

ArchitectureEach file is identified by a binary key The key is generated using some hash function Every file is stored, retrieved, and maintained with
its file key
Each node maintains a local data store and a routing table data store maintains a set of files routing table keeps information about neighboring
nodes and the keys that they are thought to hold A sequence of (file key, node address) Used for file retrieval
key neighbor
30 123.234.456.1
100 888.234.456.2
65 999.234.456.3

Retrieving dataA user first obtains or calculates a keyThe user sends a search request message (key+TTL) to local nodeWhen a node receives a request, it checks its own data storage
If the specified data is found, returns it Otherwise, the node looks up its routing table and
forwards the request to the node that has the nearest key
why do this - the similarity of two keys actually has nothing to do with that of their corresponding files?
If this request is successful, the node that has the target data
returns the data through the search path, caches the file in its own data store, and creates a new entry in its routing table
key neighbor
30 123.234.456.1
100 888.234.456.2
65 999.234.456.3

Example
A B
C
1. Check datastore for file
Data reply + actual data source
FOUND
DE
NOT FOUND
2. Check routing table for node with nearest key to requested one
File request (key, hops to live)
Failure message
Cache file in datastoreCreate new entry in routing table
Cache file in datastoreCreate new entry in routing table
Cache file in datastoreCreate new entry in routing table
NOT FOUND
FAILURE
3. Try the node with second nearest key
1. Calculate binary file key2. Check routing table for node with nearest key

Effect of Retrieving Mechanism
Anonymity Uncontrolled replication allows one to deny
responsibility of having the fileQuality of routing improved over time: Nodes specialize in locating sets of similar keys Files with similar keys are stored in clustering
(why?) Files are key-clustering instead of subject-clustering
Transparent replication of popular data Improved data availability Replication degree depends on data popularity
Increasing connectivity The graph becomes more and more connected

Effect of Retrieving Mechanism
Major difference from Gnutella searching Breadth-first search vs. Depth-first
search Replication over the retrieval path
Limitation Searching for a document that does
not exist?

Storing data
Calculate binary file key and send insert message like request (key, hops to live)When a node receives an insert proposal, it first checks its own data store
If the key already exists, the users need to try again using different key
Otherwise, the node looks up the nearest key in its routing table and forwards the insert to the corresponding node
If key collision occurs at the adjacent node, the node notifies the inserted to try another key
If TTL expires without a key collision, an “all clear” result will be backwarded to the original inserter

Storing data
Effects of insert mechanism: New files are placed on nodes possessing
files with similar keys
Limitation How long it takes to insert a file? How about version management? Two different files could have the same key
and both may exist in network Different users must have different name space The same user must use different file description
(e.g., keywords) for different file Security is a concern

Managing data
File replacement is done using LRU Data items sorted in decreasing order by time
of most recent request/insert Outdated documents fade away naturally as
routing table entry will remain for a time
File lifetime The time period of keep a file is unknown You cannot delete a file from a Freenet – a file
will not disappear unless it is not accessed for a while
No guarantee that a document you submit today will exist tomorrow

Highlights of Freenet
Pure P2P - similar to Gnutella, Provides anonymity
Neither data producer and retriever can be identified
Searching/Storing/Managing are all different for anonymity and performance purpose

P2P Advantages
Efficient use of resources Client/Server architecture cannot take advantage of the
unused bandwidth, storage, processing power at the edge of network
Scalability Each user contributes its resource to the entire
community, instead of just a burden
Reliability Replicas Geographic distribution No single point of failure
Ease of Administration Nodes self organize No need to deploy servers to satisfy demand Built-in fault tolerance, replication, and load balancing

P2P Computing SummaryP2P computing is the sharing of computer resources by direct exchange between systems
Such resource includes information, processing cycles, storage, etc.
A P2P network has the following characteristics Each node behaves as client, server, and router Nodes are autonomous (no administrative authority) Network is dynamic: nodes enter and leave the
network frequently Nodes collaborate directly with each other (not
through well-known servers) Nodes have widely varying capabilities

Homework 3 (Due 04/20)
Implement a Gnutella network Network maintenance (60/100 points)
ping and pong Nodes being able to retrieve files
(40/100) query, hit, get


















