
On the Automatic Extraction of Data from the Hidden Web Stephen W. Liddle, Sai Ho Yau, David W....
30
On the Automatic Extraction of Data from the Hidden Web Stephen W. Liddle, Sai Ho Yau, David W. Embley Brigham Young University
-
Upload
samuel-lambert -
Category
Documents
-
view
219 -
download
0
Transcript of On the Automatic Extraction of Data from the Hidden Web Stephen W. Liddle, Sai Ho Yau, David W....

On the Automatic Extraction of Data from the Hidden Web
Stephen W. Liddle, Sai Ho Yau, David W. EmbleyBrigham Young University

The Hidden Web
Many Web documents are “hidden” in some form:
Requires user/password authenticationFirewall restricts accessSearch engines simply miss these pagesProprietary document format
A common cause of “hidden” documents:Page is dynamically generated from a query specified through an HTML form
Solution:Automatically fill in forms to retrieve records from underlying databases

Reasons to Crawl the Hidden Web
Why fill in forms automatically?Automated agents (“bots”)Site wrappers for higher-level queriesMulti-site information extraction and integration…

A Reference Model of Info Search Task
Formulate query or task descriptionFind sources that pertain to the taskFor each potentially useful source:
Fill in the source’s search formAnalyze the resultsGather any useful information supporting the taskRefine the query criteria and repeat if necessary

Issues in Automatic Form Filling
Wide variety of controls in forms:Text fields, radio buttons, check boxes, lists, push buttons, hidden fields, MIME encoded attachments, etc.
CGI request is fundamentally a list of name/value pairs
F = U, (N1,V1), (N2,V2), …, (Nn, Vn)
But there are other complications…

Difficulties in Automatic Form Filling
HTTP GET vs. POSTOne form leads to another, specialized form
Logical request is physically divided into sub-steps
State information captured on the serverSession structure required to enforce sequence of interactions
• Cookies• Hidden fields• Values encoded into the base URL

More Difficulties
Some fields may be requiredRely on user to supply required text values
Semantic constraints known to usersWhen searching for cars by location, “within 500 kilometers” is more inclusive than “within 50 kilometers”When searching by price, “$35,000 to $75,000” is less inclusive than “$0 to $35,000”Some combinations don’t make sense
• 4-door motorcycles

ScriptsSome forms rely on scripts to transform fields and then submit the form
Range checking, other field validationAutomatic calculation of certain fields
Understanding arbitrary scripts is computationally hard
Can watch what gets submitted when a user interacts with a formBut in general can’t predict what a script will do, or even guarantee that the script will halt

Our Approach
Within context of ontology-based data extraction systemAttempt to retrieve all data behind a particular form
Not directed search supporting a specific query
System Fills andSubmits Form
Validate Result
Filter DuplicateRecords
Extract StructuredData from
(Semistructured)Result Records
HTML Form
PopulatedDatabase

Filling in the FormParsing an HTML form and encoding a particular request is straightforward
Fill in a form by choosing a value for each field
We could attempt to fill in the form in all possible ways
Text fields are practically, if not literally, unbounded in possibilitiesAside from text fields, the process may be too time consuming
• 50 choices in one list, 25 in another = 1250 HTTP transactions
We likely would have retrieved all data before exhausting all possible combinations
• Indeed some choices in lists represent “any”
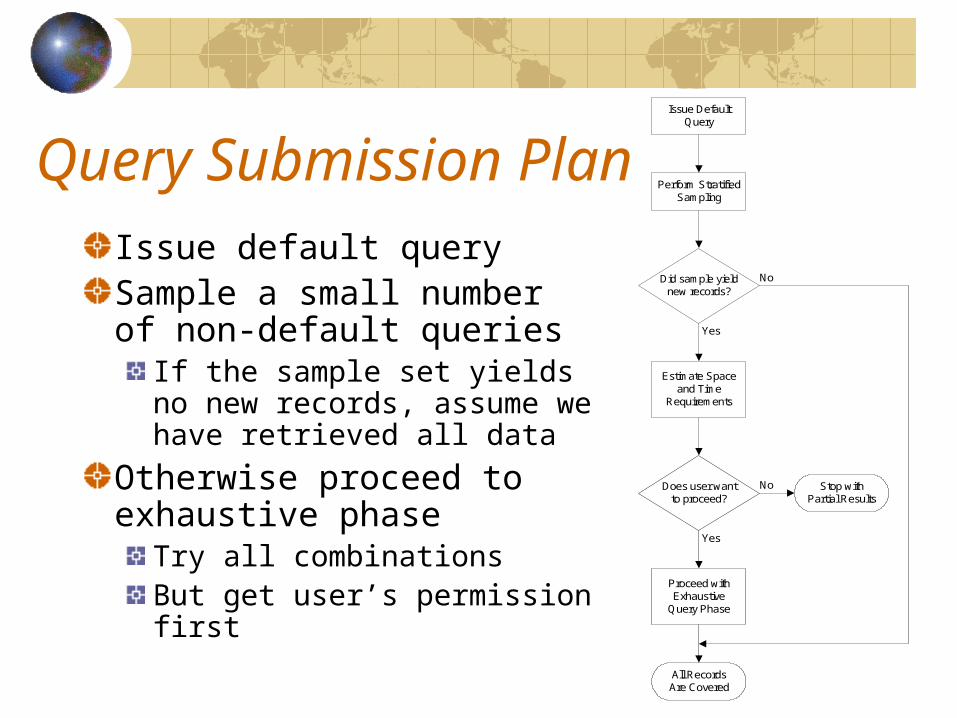
Query Submission PlanIssue Default
Query
Perform StratifiedSampling
Did sample yieldnew records?
All RecordsAre Covered
Estimate Spaceand Time
Requirements
Yes
No
Does user wantto proceed?
Stop withPartial Results
Proceed withExhaustive
Query Phase
Yes
No
Issue default querySample a small number of non-default queries
If the sample set yields no new records, assume we have retrieved all data
Otherwise proceed to exhaustive phase
Try all combinationsBut get user’s permission first

Using Default ValuesAssign default values to each field
The form always supplies a defaultOur system does allow user to provide specific choices for text fields
• Otherwise these retain their default value (usually the empty string)
Encode and submit default request to see what happens
This is like the user submitting the form without making any changes
Issue DefaultQuery
Perform StratifiedSampling
Did sample yieldnew records?
All RecordsAre Covered
Estimate Spaceand Time
Requirements
Yes
No
Does user wantto proceed?
Stop withPartial Results
Proceed withExhaustive
Query Phase
Yes
No

Result of Default Query
Often the default query is set to return all recordsSometimes the default query gives an error
Required fields• Sometimes text field must be given• Or a non-default selection is required in a list or
radio-button group
Time-out because default request is too large• Designers obviously expected the user to narrow the
search
Issue DefaultQuery
Perform StratifiedSampling
Did sample yieldnew records?
All RecordsAre Covered
Estimate Spaceand Time
Requirements
Yes
No
Does user wantto proceed?
Stop withPartial Results
Proceed withExhaustive
Query Phase
Yes
No
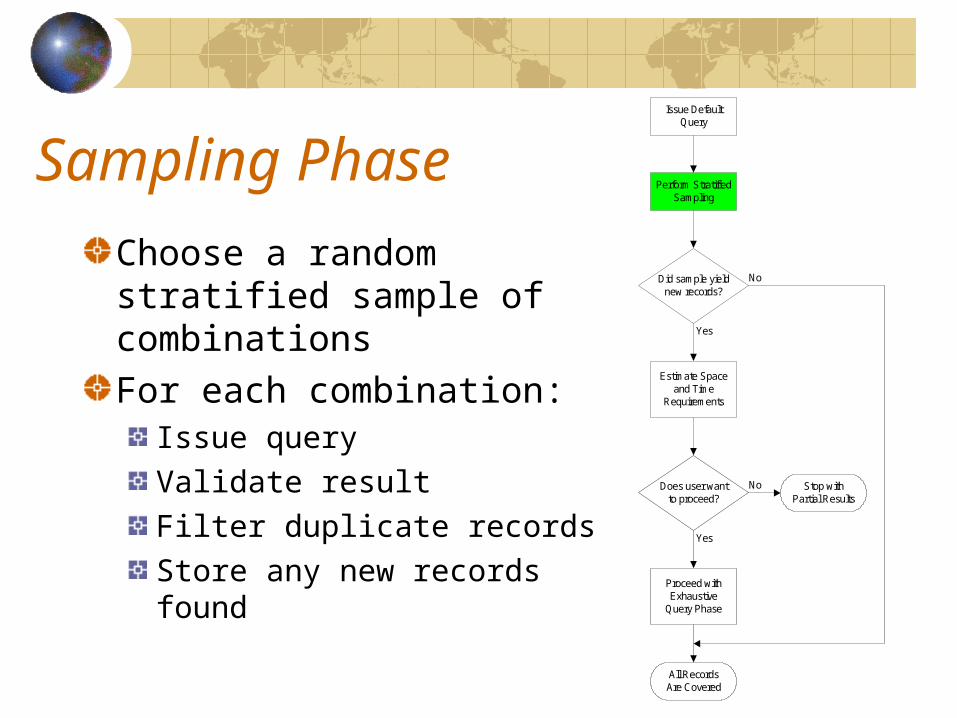
Sampling Phase
Choose a random stratified sample of combinationsFor each combination:
Issue queryValidate resultFilter duplicate recordsStore any new records found

Sampling Approach
Random sample might ignore some fields and overemphasize others

Sampling Approach
Regular stratified sample is biased

Sampling Approach
Random stratified sample seems reasonable
If N is total number of combinations, our sample size should be log2N

Exhaustive Phase
For each combination:Issue queryValidate resultRemove duplicatesStore any new records found
Don’t repeat combinations that were already sampled
Issue DefaultQuery
Perform StratifiedSampling
Did sample yieldnew records?
All RecordsAre Covered
Estimate Spaceand Time
Requirements
Yes
No
Does user wantto proceed?
Stop withPartial Results
Proceed withExhaustive
Query Phase
Yes
No

User Input
First we get permission from our userEstimate maximum required space:
And time:
n
iin
N bS1
size of ith sample
n
ii
n
iin
N ttT11
time to process ith sample

Validating Results
Possible results:HTTP errorPage contains no records
• Determined based on size of unique portion of the page
Page contains links to more result records
• E.g., displaying 1 to 10 of 47• Need to follow “next” links to get
complete results
Page contains all records• No “next” links found
Issue Query
Validate Result
Filter Duplicates
Store NewRecords (if any)

Retrieving More Results
Presence of “next” or “more” in a hyperlink or button often signals a link to more resultsOften a numeric sequence signals more results
1 2 3 4 …10 20 30 …
We follow these links, assemble all the results, and consider this a single query
But multiple HTTP requests

Filtering Duplicates
Compare records and discard duplicates
Based on string comparisonCompute hash value for each candidate record stringIdentical hash values indicate duplicate records
Issue Query
Validate Result
Filter Duplicates
Store NewRecords (if any)

Filtering DuplicatesSeparate records heuristically
HTML tags that constitute likely record separators mark boundaries:
• <HR>, <P>, </TR>, …
Strip non-boundary tagsSometimes there are minor variations in tags or their attributes that interfere with duplicate detection
Now calculate hash values and remove any duplicate stringsIf ratio of unique strings to total document size is < 5%, we assume no new records are present
There is noise in page headers, footers, advertisements, etc.

Experimental Results
Roughly 80% of forms in our test set were automatically processed correctly
Sources of failure:• Missing required fields (user must supply)• No records from default and sample queries• Invalid URL (Web site error)
For 1/3 of forms, the default query returned all records

Experimental Results
Processing a single HTTP request took between 2 and 25 seconds on averageA single query (including following links) took between 5 seconds and 14 minutesThe number of “next” links ranged from none to more than 140Sampling took from 30 seconds to 3 hours per formIn all cases, manual verification corroborated what the system reported

Time Saved
When the sampling phase successfully returned all records, considerable time was saved compared to exhaustive query
15 minutesAlmost 3 hours> 4 days> 40 days

Future Work
Conduct more experimentsTo further validate our initial resultsTo learn how to improve
Better metricsIntegrate this tool into our ontology-based data extraction framework
Upstream automatic selection of domain-appropriate formsDownstream automatic record-boundary detection and extraction

Intent of Form
Is the purpose of the form transactional or informational?Transactional:
Purchase a DVDTransfer money between accountsUpdate customer informationRequest contact from a sales representative
Goal of transactional form is to interact with a business partner to support a business process of some kind

Transactional vs. Informational
Informational formIssues a queryFind documents or records matching given criteria
Goal of informational form is to retrieve data, not execute a business processWe’re typically interested only in the informational forms
But eventually agents will need to handle transactional forms also

ConclusionWe have presented the prototype of a synergistic tool that
Automatically retrieves data behind HTML forms• Including following links to retrieve multiple pages of
results associated with a single query
Is domain-independentCan easily integrate with our source ontology-based source discovery and data extraction tools
The world is ready for tools that understand and access the Hidden Web


















