
Metody interpolacji w programie SAGA GIS -...
19
Metody interpolacji w programie SAGA GIS Krajowe warsztaty CASCADOSS Zastosowania oprogramowania Open Source GIS (FOSS4G ang. Free and Open Source Software for Geospatial) w ochronie przyrody 12-13 lutego 2009, Warszawa
-
Upload
duongnguyet -
Category
Documents
-
view
244 -
download
0
Transcript of Metody interpolacji w programie SAGA GIS -...

Metody interpolacji w programie SAGA GIS
Krajowe warsztaty CASCADOSS Zastosowania oprogramowania Open Source GIS
(FOSS4G ang. Free and Open Source Software for Geospatial) w ochronie przyrody
12-13 lutego 2009, Warszawa

2
1. Wprowadzenie do pracy z programem SAGA GIS SAGA (System for Automated Geoscientific Analyses), aplikacja open source, której
najistotniejszym elementem jest szeroki zestaw narzędzi do analizy danych przestrzennych
w tym głównie rastrowych. Program słuŜy równieŜ do przetwarzania danych wektorowych
i tabelarycznych.
SAGA została stworzona i jest rozwijana przez niewielki zespół specjalistów z Uniwersytetu
w Getyndze w Niemczech. Program wywodzi się od aplikacji DiGeM przeznaczonej do
analizy terenu. Pierwsza edycja SAGA GIS została opublikowana w lutym 2004, druga
we wrześniu 2007.
Kod źródłowy programu (napisany w języku C++) dostępny jest na licencji GNU General
Public License. Oznacza to, iŜ moŜe być on dowolnie modyfikowany, pod warunkiem
bezpłatnego udostępnienia zmienionej wersji na identycznych zasadach.
W najnowszej wersji programu (2.0) dostępnych jest około 120 modułów słuŜących m.in. do
analizy terenu, symulacji procesów dynamicznych, interpolacji i analiz geostatystycznych,
przetwarzania i analizy obrazów rastrowych, transformacji odwzorowań, importu, eksportu
i konwersji danych oraz ich wizualizacji.

3
Graficzny interfejs uŜytkownika (GUI) tworzą:
- Menu bar (pasek menu)
- Toolbar (pasek narzędzi)
- Workspace window (okno przestrzeni roboczej)
- Main Window (okno główne)
- Object properties window (okno właściwości obiektów)
- Message window (okno wiadomości)
- Tabs (zakładki)
Rysunek 1. Interfejs programu SAGA GIS 2.0.

4
2. Pojęcie interpolacji
Interpolacja to metoda numeryczna pozwalająca na oszacowanie wartości funkcji
w dowolnym miejscu danego przedziału, w którym występuje pewna, ograniczona liczba
punktów o znanej, np. z pomiarów, wartości z (x,y). Punkty te nazywane są węzłami
interpolacji . Na ich podstawie wyznaczana jest tzw. funkcja interpolacyjna z=f(x,y).
Stanowi ona przybliŜenie funkcji o nieznanym wzorze pierwotnie opisującej dane zjawisko.
Przechodzi przez te same punkty o zadanej z góry wartości z (x,y) (węzły interpolacji). Nie
moŜna jednak być pewnym, czy pomiędzy nimi przebiega w dokładnie ten sam sposób, co
funkcja pierwotna.
Metody interpolacji mają duŜe znaczenie w badaniach środowiska przyrodniczego.
Dysponując pomiarami ze skończonej liczby punktów w określonej przestrzeni geograficznej
moŜemy pomierzone wartości interpolować róŜnymi metodami na całą tę przestrzeń. W ten
sposób moŜemy oszacować wartości parametrów pomiędzy punktami, w których dokonano
pomiarów.
Interpolacja przestrzenna moŜe być zastosowana do róŜnego rodzaju danych, m.in.
z pomiarów zanieczyszczenia środowiska, właściwości fizycznych atmosfery, poziomu wód
gruntowych, topografii terenu lub zjawisk geologicznych i innych.
Metody interpolacji przestrzennej moŜna podzielić na deterministyczne, modelujące
powierzchnię w sposób jednoznacznie określony funkcjami matematycznymi oraz
stochastyczne (geostatystyczne), uwzględniające koncepcję zmienności losowej
interpolowanej powierzchni. Do tej drugiej grupy naleŜą przede wszystkim róŜne odmiany
krigingu.
RozróŜniane są równieŜ globalne i lokalne metody interpolacji. Metody globalne dokonują
interpolacji jedną funkcją matematyczną na podstawie danych ze wszystkich punktów ze
zbioru pomiarowego. SłuŜą szczególnie do ukazania ogólnych trendów w całym zbiorze
danych. Metody lokalne wykorzystują podczas obliczeń dane z punktów leŜących w bliskim
sąsiedztwie węzła interpolacji, bez uwzględnienia wpływu całego zbioru danych. Ta sama

5
funkcja matematyczna stosowana jest wielokrotnie do lokalnych zbiorów danych
pomiarowych, co ma zapewnić jej lepsze dopasowanie.
Istnieje takŜe podział na funkcje interpolacyjne wierne i wygładzające. W przypadku tych
pierwszych, jeŜeli punkt, w którym szacowana jest wartość funkcji (punkt estymacji) wypada
w punkcie pomiaru, pozostawiana jest wartość oryginalna. Wszystkie dane pomiarowe są
ściśle uwzględniane, tak, Ŝe znajdują się dokładnie na powierzchni interpolacji. W przypadku
funkcji wygładzających, jeŜeli punkt estymacji wypada w punkcie pomiaru, wyniki estymacji
i pomiaru mogą się róŜnić. Dane pomiarowe nie są ściśle uwzględniane przy konstruowaniu
powierzchni interpolacji. Metody wygładzające są wskazane do zastosowania w przypadku
niepewności, co do jakości danych pomiarowych.
Ostatni podział, który warto odnotować dotyczy metod ciągłych i nieciągłych. Metody ciągłe
dają płynną zmienność wartości na powierzchni między punktami pomiaru. Są one wskazane
do interpolacji danych cechujących się małą lokalną zmiennością stosujemy je do prezentacji
zjawisk o charakterze ciągłym i ich rozkładu przestrzennego np. wysokości opadów
atmosferycznych. Metody nieciągłe tworzą powierzchnie interpolacji, na których mogą
występować skokowe zmiany wartości. Stosuje się je do interpolacji danych o duŜej lokalnej
zmienności lub danych nieciągłych (z wyraźnymi skokowymi zmianami wartości) np. do
określania stref występowania danego zjawiska.
3. Ćwiczenie z wykorzystaniem programu SAGA GIS
3.1. Cel ćwiczenia:
W ćwiczeniu na podstawie danych z pomiarów punktowych utworzona zostanie powierzchnia
interpolowana w postaci rastrowej. Przetestujemy trzy metody interpolacji wybrane spośród
szeregu dostępnych w programie SAGA GIS i dokonamy oceny ich przydatności. Wybranymi
metodami są:
− Metoda najbliŜszego sąsiedztwa (Nearest neighbour),
− Metoda odwrotnych odległości (Inverse distance),
− Kriging zwykły (Ordinary kriging).

6
Na koniec, bazując na obrazie powierzchni otrzymanej w wyniku zastosowania wybranej
metody interpolacji, utworzymy mapę izoliniową.
3.2 Wprowadzenie do ćwiczenia
1. Uruchom program SAGA GIS.
2. W menu File wybierz Shapes � Load Shapes. Otwórz plik pomiary.shp.
3. W Workspace przejdź na zakładkę Data*.
4. Kliknij dwukrotnie na obrazek z danymi punktowymi z pomiarów. Zostanie dodany
do widoku jako nowa mapa (01.map). Zmienimy teraz właściwości jej wyświetlania.
5. W oknie Object Properties Window przejdź do opcji Display: Color Classification, a następnie: − Po kliknięciu w polu Type wybierz z listy rozwijanej „Graduated Color” .
− Po kliknięciu w polu Attribute wybierz z listy rozwijanej atrybut „ID”.
− Wybierz pole Graduated Color � Colors. Kliknij na mały kwadrat, jaki pojawi
się z prawej strony. Otworzy się nowe okno ze skalami barwnymi. Wybierz
Presets i zmień skalę na „white > red”. Dwukrotnie zatwierdź OK.
6. W oknie Object Properties Window przejdź do opcji Display: Label, a następnie
w polu Attribute wybierz atrybut „ wartosc”.
7. Zatwierdź zmiany w Object Properties Window przyciskiem Apply.
8. Zmaksymalizuj okno mapy 01.map, klikając ikonę z kwadratem w prawej górnej
części okna. Punkty na mapie oznaczone są teraz w skali barwnej w zaleŜności od
wartości parametru (czerwony – wyŜsza, biały – niŜsza). Skalę barwną „czerwony –
biały” będziemy stosować w całym ćwiczeniu. Wartości liczbowe przy
poszczególnych punktach pomiarowych oznaczają wartość parametru.
Bazując na wczytanych punktach pomiarowych zastosujemy róŜne metody interpolacji
i dokonamy porównania wyników.

7
Rysunek 2. Wartość parametru w punktach pomiarowych.
3.3. Porównanie wybranych metod interpolacji danych przestrzennych
1. Metoda najbliŜszego sąsiedztwa (Nearest neighbour)
W trakcie interpolacji tą metodą kaŜdemu punktowi przestrzeni przypisana zostaje taka
wartość, jaka występuje w najbliŜszym punkcie pomiarowym. Efektem jest podział
przestrzeni na jednorodne, co do wartości danego parametru poligony (poligony Thiessena).
Na granicy poligonów zmiana wartości następuje w sposób skokowy. Jest to
deterministyczna, lokalna, wierna, nieciągła metoda interpolacji.
1. W Workspace wybierz zakładkę Modules, a w niej, Grid � Gridding � Nearest
Neighbour. Kliknij podwójnie na ikonę symbolizującą wybrany moduł. Alternatywnie

8
moŜesz wybrać z paska menu Modules: Grid � Gridding � Interpolation from
Points � Nearest Neighbour.
2. Po wybraniu modułu Nearest Neighbour pojawi się okno, w którym podaj następujące
parametry:
Objaśnienia wybranych parametrów:
Shapes : Points – plik .shp z danymi pomiarowymi do interpolacji,
Points [Options]: Attribute – atrybut przypisany punktom pomiarowym, na którym chcemy oprzeć interpolację,
Options: Target Grid – docelowy grid (raster) z wynikami interpolacji (opcja „user defined” oznacza, Ŝe
utworzony zostanie zupełnie nowy grid).
3. Zatwierdź przyciskiem Okay. W oknie User defined grid, które się pojawi, pozostaw
wszystkie parametry bez zmian. Ponownie zatwierdź przyciskiem Okay. Tworzony
obraz rastrowy przedstawia wyniki interpolacji pomiarów metodą najbliŜszego
sąsiedztwa.
4. Wybierz zakładkę Data*, a w niej nowo utworzony obraz z wynikiem interpolacji.
5. W oknie Object Properties Window wybierz Display: Color Classification �
Graduated Color � Colors. Otworzy się nowe okno ze skalami barwnymi. Wybierz
Presets i zmień skalę na „white > red”. Dwukrotnie zatwierdź OK.
6. Zatwierdź zmiany w Object Properties Window, przyciskiem Apply.
7. W zakładce Data* dwukrotnie kliknij na obrazek symbolizujący raster z wynikiem
interpolacji. Pojawi się okno Add layer to selected map z zaznaczoną opcją „New”.
Kliknij Okay. Nowa mapa zostanie dodana do widoku jako 02.map.
8. MoŜna zaobserwować, Ŝe rozdzielczość obrazu rastrowego, który otrzymaliśmy jest
mało zadowalająca. Aby uzyskać lepszy obraz interpolacji, powtórz kroki 1-6, jednak
w kroku 3, w oknie User defined grid zmień wartość Grid Size na 10. W ten sposób
dokładność próbkowania obszaru wokół punktów pomiarowych podczas interpolacji
będzie większa, a w efekcie otrzymamy raster o wyŜszej rozdzielczości.
9. Dodaj nową mapę do widoku jako 03.map.

9
Rysunek 3. Wynik interpolacji metodą najbli Ŝszego sąsiedztwa. OCENA:
� Metoda prosta pod względem obliczeniowym i wymagająca od uŜytkownika
wprowadzania niewielkiej liczby parametrów.
� Metoda mało przydatna do modelowania wielu zjawisk przyrodniczych, które
zmieniają się w przestrzeni w sposób ciągły, ze względu skokowe zmiany wartości.
� Metoda wykorzystywana przy wyszukiwaniu stref oddziaływania róŜnych obiektów,
gdy potrzebna jest informacja, do którego najbliŜszego obiektu danego typu w
przestrzeni przyporządkować poszczególne punkty (np. które miasto jest najbliŜej).
Metoda przydatna m.in. do analizy zjawisk społeczno-ekonomicznych lub
definiowania strefy wpływu obiektów punktowych.
� Ograniczeniem metody jest fakt, iŜ układ wynikowych poligonów Thiessena zaleŜy
znacząco od rozmieszczenia punktów z danymi; w obrębie poligonów wartości są
jednorodne.

10
2. Metoda odwrotnych odległości (Inverse distance)
W metodzie tej, wartość przypisana punktowi w przestrzeni jest wynikiem interpolacji
wartości z punktów pomiarowych z wyznaczonego wcześniej sąsiedztwa. SAGA GIS
umoŜliwia dobranie jako sąsiedztwa okręgu o promieniu, który sami definiujemy. Brana jest
pod uwagę średnia waŜona z obserwacji z tego sąsiedztwa. Przyznane wagi są odwrotnie
proporcjonalne do odległości do poszczególnych punktów pomiarowych. ZaleŜność ta moŜe
być liniowa lub podniesiona do potęgi, najczęściej 2 lub 3. Jest to deterministyczna, lokalna,
wierna metoda interpolacji.
1. W Workspace wybierz zakładkę Modules, a w niej Grid – Gridding – Interpolation
From Points � Inverse Distance
2. Po wybraniu modułu Inverse Distance, pojawi się okno, w którym podaj następujące
parametry:
Objaśnienia wybranych parametrów:
Inverse Distance: Power – wykładnik potęgi funkcji odwrotnej odległości
Search Radius – promień, w zasięgu którego funkcja wyszukuje punkty na których ma być oparta interpolacja
(„promień sąsiedztwa”)
Maximum Points – maksymalna liczba punktów w obrębie sąsiedztwa uwzględniana przy interpolacji W oknie dialogowym zmień domyślną wartość Search Radius na 1500.
3. Zatwierdź Okay. W oknie, które się pojawi zmień wartość Grid Size na 10. Resztę
parametrów pozostaw bez zmian. Ponownie zatwierdź Okay. Tworzony jest obraz
rastrowy przedstawiający wyniki interpolacji pomiarów metodą odwrotnych
odległości.

11
4. Wybierz zakładkę Data*, a w niej nowo utworzony raster z wynikiem interpolacji.
5. W oknie Object Properties Window wybierz w Display: Color Classification �
Graduated Color � Colors. Otworzy się nowe okno ze skalami barwnymi. Wybierz
Presets i zmień skalę na „white > red”. Dwukrotnie zatwierdź OK.
6. Zatwierdź zmiany w Object Properties Window klikając na Apply.
7. W zakładce Data* dwukrotnie kliknij na obrazek symbolizujący raster z wynikiem
interpolacji. Pojawi się okno Add layer to selected map z zaznaczoną opcją „New”.
Kliknij Okay. Nowa mapa zostanie dodana do widoku, jako 04.map.

12
OCENA:
� Metoda prosta pod względem obliczeniowym, wykorzystująca intuicyjnie zrozumiałą
zasadę malejącego proporcjonalnie do wzrostu odległości podobieństwa (lub
zaleŜności) między wartościami punktów.
� Metoda bardziej realistyczna niŜ metoda najbliŜszego sąsiedztwa, gdyŜ uwzględniany
jest wpływ większej liczby stanowisk pomiarowych na wynik w danym punkcie (a nie
tylko najbliŜszego stanowiska).
� Metoda interpolacji, która sprawdza się dobrze, gdy stanowisk pomiarowych jest duŜo
i są one względnie równomiernie rozmieszczone.
� Wybrane podczas interpolacji parametry mają istotny wpływ na wynik obliczeń.
WaŜny jest m.in. dobór odpowiedniej wielkości „sąsiedztw” branych pod uwagę przy
interpolacji. Wybór zbyt małych „sąsiedztw” moŜe spowodować powstanie luk w
powierzchni interpolowanej, w miejscach gdzie oszacowanie wartości parametru nie
jest moŜliwe.
3. Kriging zwykły (Ordinary kriging)
Kriging to grupa geostatystycznych metod interpolacji. Kriging zakłada istnienie
autokorelacji przestrzennej – zaleŜności między oddaleniem punktów a stopniem ich
podobieństwa. Zgodnie z tą zaleŜnością wielkości zmierzone w bliskich sobie punktach
powinny być bardziej zbliŜone niŜ wielkości zmierzone w punktach bardziej oddalonych.
Zgodnie z załoŜeniami krigingu, zróŜnicowanie przestrzenne zmiennej (tzw. zmiennej
regionalnej) moŜna podzielić na trzy główne składowe:
a. ogólny trend zmienności danych, o stałej średniej,
b. lokalną zmienność losową skorelowaną przestrzennie,
c. nieskorelowany przestrzennie „szum” (wynikający np. z błędów pomiarowych).

13
Rysunek 4. ZróŜnicowanie przestrzenne zmiennej regionalnej.
(źródło: Burrough P., McDonnell R., 1998, Principles of Geographical Information Systems, Oxford University Press Inc., New York)
ZróŜnicowanie przestrzenne zmiennej zawiera zatem element losowy i nie jest prostą
zaleŜnością matematyczną. Opisywane jest ono metodami statystycznymi i przedstawiane na
wykresie zwanym semiwariogramem. Wykres jest dopasowany do danych w taki sposób, aby
przybliŜyć w postaci funkcji liniowej zaleŜność między oddaleniem punktów (Lag), a
stopniem ich podobieństwa (γ).
Rysunek 5. Semiwariogram – przykładowy wykres.
(źródło: Burrough P., McDonnell R., 1998, Principles of Geographical Information Systems, Oxford University Press Inc., New York)

14
Objaśnienia parametrów: Nugget (wartość semiwariancji dla dystansu zbliŜonego do zera) to wielkość nieskorelowanego przestrzennie
„szumu”, występującego, gdy mierzymy wartości punktów połoŜonych bardzo blisko siebie. MoŜe on wynikać
np. z niewielkich błędów pomiarowych związanych z dokładnością samego sprzętu pomiarowego.
Range (dystans powyŜej którego semiwariancja jest wartością stałą) to maksymalny zakres odległości między
punktami, w którym moŜna zaobserwować występowanie istotnej statystycznie korelacji między odległością
między punktami a róŜnicą ich wartości.
Sill to wartość progowa funkcji odpowiadająca zasięgowi oddziaływania wyznaczonemu przez range.
Interpolacja dokonywana jest na podstawie danych pomiarowych oraz wartości
semiwariancji.
MoŜliwe jest określenie istotności statystycznej konstruowanej powierzchni interpolacji
i zarazem niepewności szacowanych danych. MoŜliwość określenia błędów estymacji naleŜy
do podstawowych zalet metod geostatystycznych. Wielu autorów wykazało, Ŝe metody
statystyczne (kriging) dają lepsze rezultaty interpolacji przestrzennej niŜ metody
deterministyczne.
Kriging zwykły zakłada, Ŝe funkcja autokorelacji przestrzennej jest jednorodna we wszystkich
kierunkach (załoŜenie izotropowości). Nieznane wartości są szacowane przez waŜoną
kombinację wartości w punktach znanych. Podstawą do wyliczenia wag jest semiwariogram.
Kriging zwykły naleŜy do wiernych i ciągłych metod interpolacji. MoŜe występować
zarówno w odmianie lokalnej, jak i globalnej. W ćwiczeniu wypróbujemy globalną odmianę
krigingu zwykłego.
1. W Workspace wybierz zakładkę Modules, a w niej Geostatistics � Kriging �
Ordinary Kriging (Global). Kliknij podwójnie na ikonę symbolizującą wybrany
moduł.
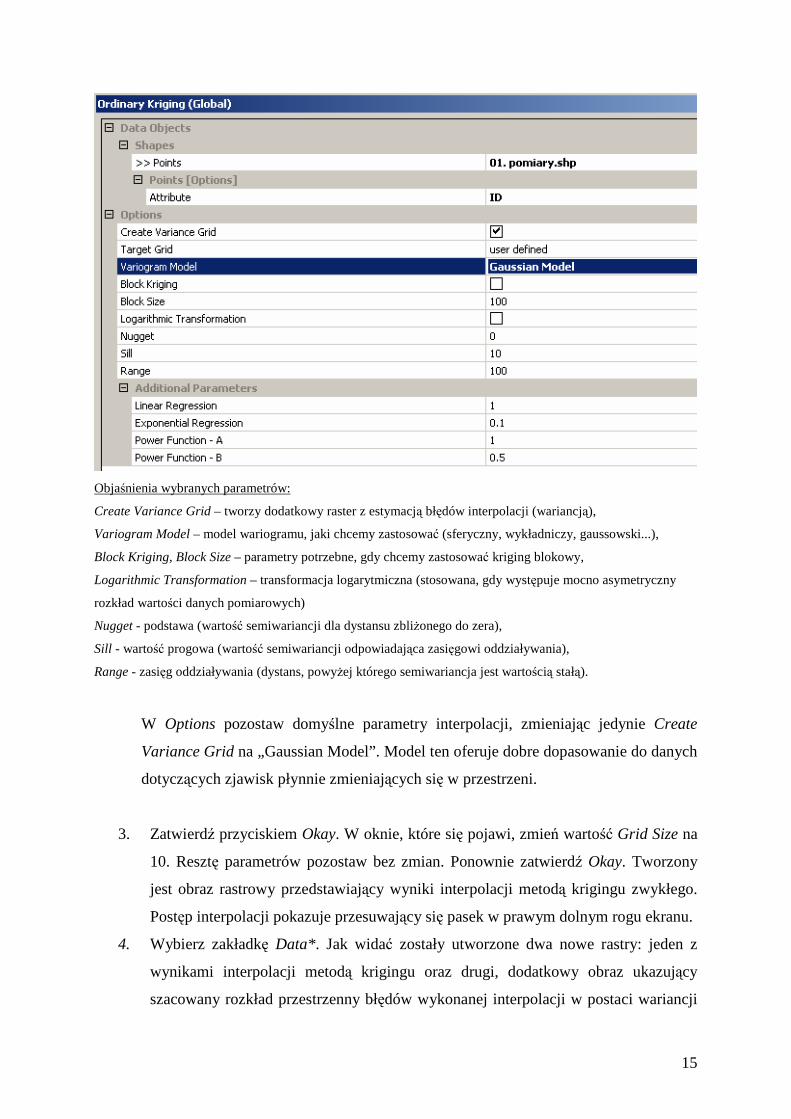
2. Po wybraniu modułu Ordinary Kriging (Global) pojawi się okno, w którym podaj
następujące parametry:
15
Objaśnienia wybranych parametrów:
Create Variance Grid – tworzy dodatkowy raster z estymacją błędów interpolacji (wariancją),
Variogram Model – model wariogramu, jaki chcemy zastosować (sferyczny, wykładniczy, gaussowski...),
Block Kriging, Block Size – parametry potrzebne, gdy chcemy zastosować kriging blokowy,
Logarithmic Transformation – transformacja logarytmiczna (stosowana, gdy występuje mocno asymetryczny
rozkład wartości danych pomiarowych)
Nugget - podstawa (wartość semiwariancji dla dystansu zbliŜonego do zera),
Sill - wartość progowa (wartość semiwariancji odpowiadająca zasięgowi oddziaływania),
Range - zasięg oddziaływania (dystans, powyŜej którego semiwariancja jest wartością stałą).
W Options pozostaw domyślne parametry interpolacji, zmieniając jedynie Create
Variance Grid na „Gaussian Model”. Model ten oferuje dobre dopasowanie do danych
dotyczących zjawisk płynnie zmieniających się w przestrzeni.
3. Zatwierdź przyciskiem Okay. W oknie, które się pojawi, zmień wartość Grid Size na
10. Resztę parametrów pozostaw bez zmian. Ponownie zatwierdź Okay. Tworzony
jest obraz rastrowy przedstawiający wyniki interpolacji metodą krigingu zwykłego.
Postęp interpolacji pokazuje przesuwający się pasek w prawym dolnym rogu ekranu.
4. Wybierz zakładkę Data*. Jak widać zostały utworzone dwa nowe rastry: jeden z
wynikami interpolacji metodą krigingu oraz drugi, dodatkowy obraz ukazujący
szacowany rozkład przestrzenny błędów wykonanej interpolacji w postaci wariancji
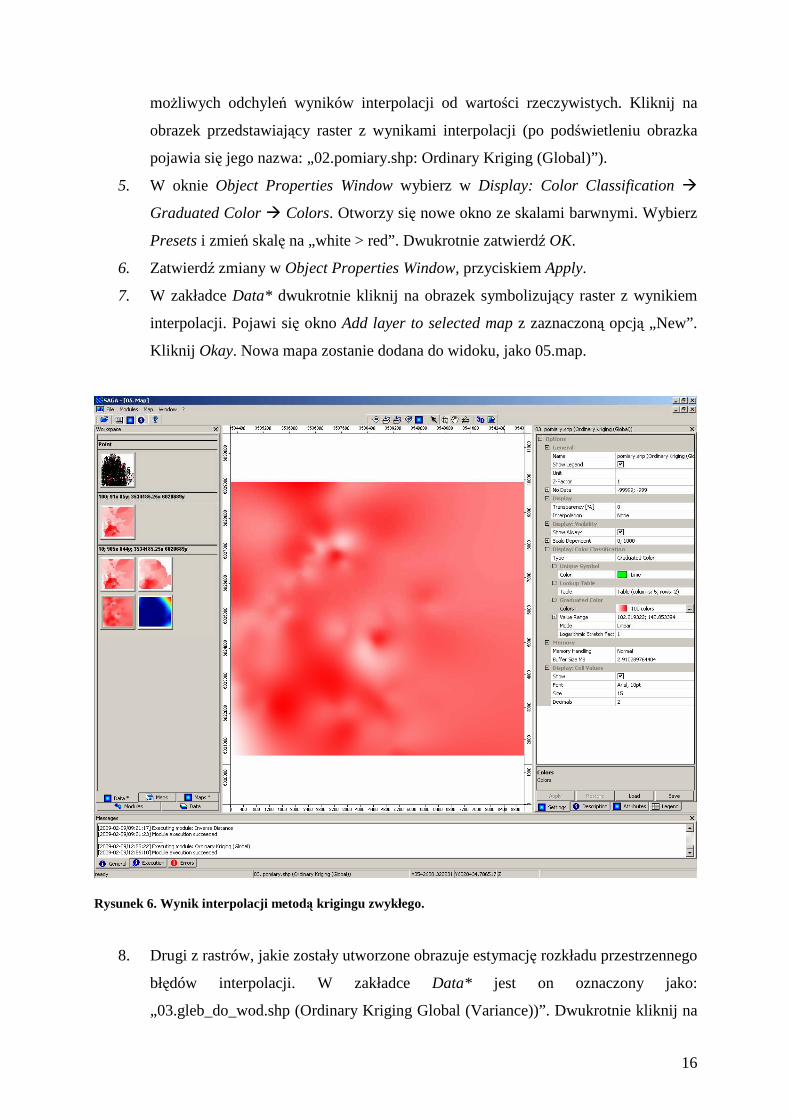
16
moŜliwych odchyleń wyników interpolacji od wartości rzeczywistych. Kliknij na
obrazek przedstawiający raster z wynikami interpolacji (po podświetleniu obrazka
pojawia się jego nazwa: „02.pomiary.shp: Ordinary Kriging (Global)”).
5. W oknie Object Properties Window wybierz w Display: Color Classification �
Graduated Color � Colors. Otworzy się nowe okno ze skalami barwnymi. Wybierz
Presets i zmień skalę na „white > red”. Dwukrotnie zatwierdź OK.
6. Zatwierdź zmiany w Object Properties Window, przyciskiem Apply.
7. W zakładce Data* dwukrotnie kliknij na obrazek symbolizujący raster z wynikiem
interpolacji. Pojawi się okno Add layer to selected map z zaznaczoną opcją „New”.
Kliknij Okay. Nowa mapa zostanie dodana do widoku, jako 05.map.
Rysunek 6. Wynik interpolacji metodą krigingu zwykłego.
8. Drugi z rastrów, jakie zostały utworzone obrazuje estymację rozkładu przestrzennego
błędów interpolacji. W zakładce Data* jest on oznaczony jako:
„03.gleb_do_wod.shp (Ordinary Kriging Global (Variance))”. Dwukrotnie kliknij na
17
obrazek symbolizujący ten raster. Pojawi się okno Add layer to selected map z
zaznaczoną opcją „New”. Kliknij Okay. Nowa mapa zostanie dodana do widoku,
jako 06.map.
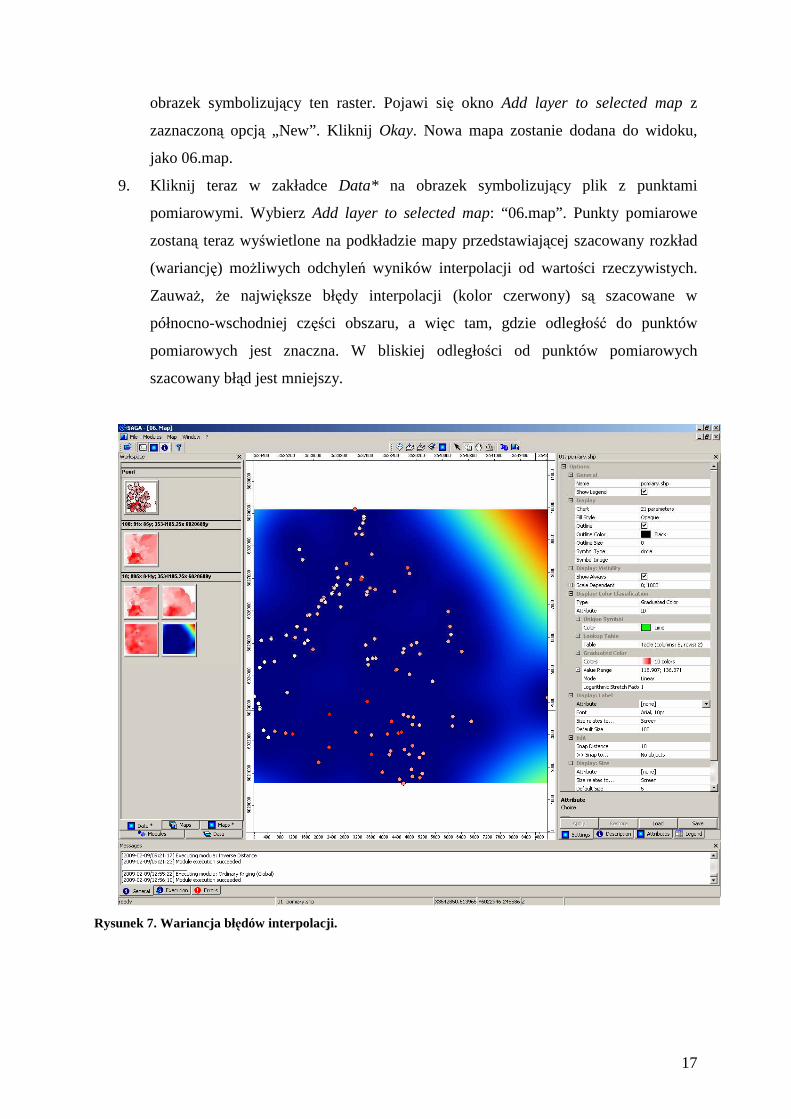
9. Kliknij teraz w zakładce Data* na obrazek symbolizujący plik z punktami
pomiarowymi. Wybierz Add layer to selected map: “06.map”. Punkty pomiarowe
zostaną teraz wyświetlone na podkładzie mapy przedstawiającej szacowany rozkład
(wariancję) moŜliwych odchyleń wyników interpolacji od wartości rzeczywistych.
ZauwaŜ, Ŝe największe błędy interpolacji (kolor czerwony) są szacowane w
północno-wschodniej części obszaru, a więc tam, gdzie odległość do punktów
pomiarowych jest znaczna. W bliskiej odległości od punktów pomiarowych
szacowany błąd jest mniejszy.
Rysunek 7. Wariancja błędów interpolacji.

18
OCENA:
� Kriging zwykły (odmiana globalna) to metoda przydatna do modelowania zjawisk
zmieniających się w przestrzeni w sposób ciągły, w tym wielu zjawisk
przyrodniczych. Wartości nie zmieniają się skokowo, lecz w sposób płynny.
� Kriging oferuje szereg parametrów, które moŜna zmieniać, aby jak najlepiej
dopasować funkcję interpolującą do danych, jakimi dysponujemy.
� Autokorelacja przestrzenna wyznaczona jest metodami statystycznymi. MoŜliwe jest
określenie wiarygodności dokonanej estymacji. Jest to bardzo duŜa zaleta metod
geostatystycznych.
3.4. Mapa izoliniowa
Wynikiem przeprowadzonych interpolacji są mapy w formacie rastrowym. Na podstawie
jednej z nich utworzymy wektorową mapę izoliniową. Izolinie łączą miejsca o jednakowej
wartości parametru..
1. W Workspace wybierz zakładkę Modules, a w niej Shapes – Grid � Contour Lines
from Grid. Kliknij podwójnie na ikonę symbolizującą wybrany moduł.
2. Po wybraniu modułu Contour Lines from Grid pojawi się okno, w którym podaj
następujące parametry:
Objaśnienia parametrów:
Grid – raster wynikowy interpolacji, na podstawie, którego zamierzamy utworzyć mapę izoliniową (w tym
przypadku raster wynikowy interpolacji metodą Ordinary Kriging Global)
Minimum Contour Value – minimalna wartość izolinii (wstaw wartość 100).,
Maximum Contour Value – maksymalna wartość izolinii (wstaw wartość 150),
Equidistance - róŜnica wartości między sąsiednimi izoliniami (wstaw wartość 2).
19
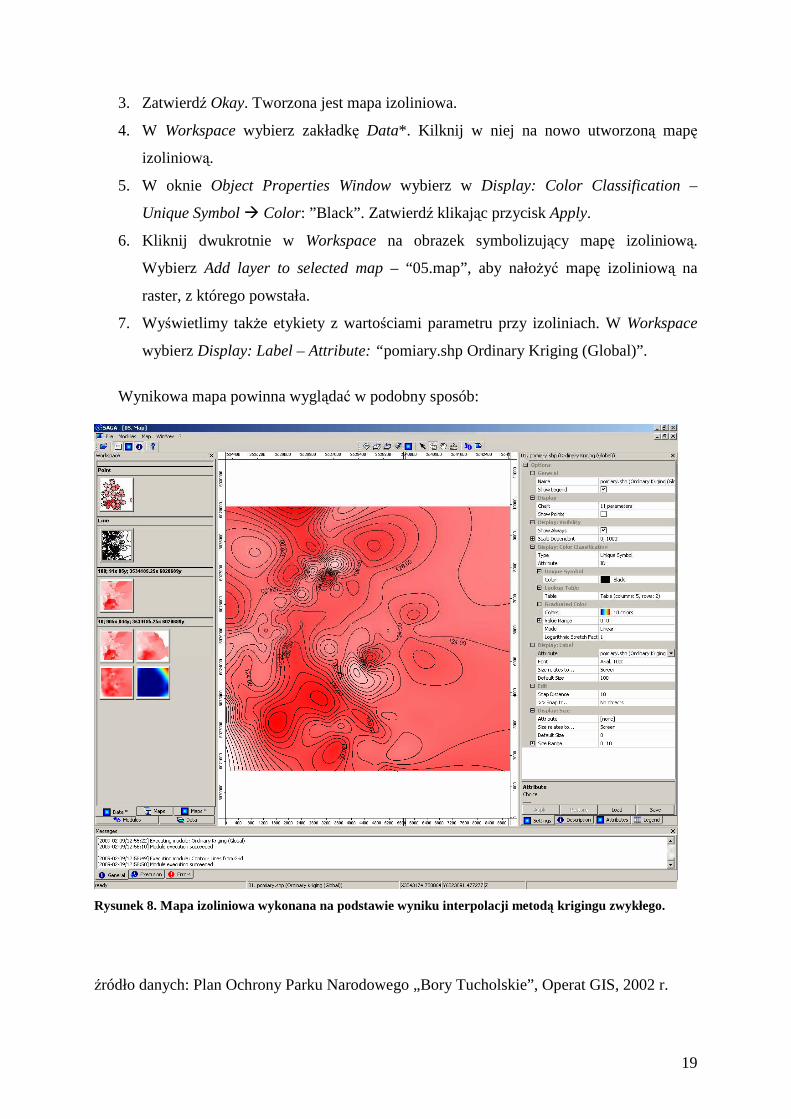
3. Zatwierdź Okay. Tworzona jest mapa izoliniowa.
4. W Workspace wybierz zakładkę Data*. Kilknij w niej na nowo utworzoną mapę
izoliniową.
5. W oknie Object Properties Window wybierz w Display: Color Classification –
Unique Symbol � Color: ”Black”. Zatwierdź klikając przycisk Apply.
6. Kliknij dwukrotnie w Workspace na obrazek symbolizujący mapę izoliniową.
Wybierz Add layer to selected map – “05.map”, aby nałoŜyć mapę izoliniową na
raster, z którego powstała.
7. Wyświetlimy takŜe etykiety z wartościami parametru przy izoliniach. W Workspace
wybierz Display: Label – Attribute: “pomiary.shp Ordinary Kriging (Global)”.
Wynikowa mapa powinna wyglądać w podobny sposób:
Rysunek 8. Mapa izoliniowa wykonana na podstawie wyniku interpolacji metodą krigingu zwykłego.
źródło danych: Plan Ochrony Parku Narodowego „Bory Tucholskie”, Operat GIS, 2002 r.


















