
Longest Increasing Subsequence and Distance to Monotonicity in Data Stream Model Hossein Jowhari...
20
Longest Increasing Subsequence and Distance to Monotonicity in Data Stream Model Hossein Jowhari Simon Fraser University Joint work with Funda Ergun Dagstuhl August 2008
-
Upload
jada-hayre -
Category
Documents
-
view
217 -
download
0
Transcript of Longest Increasing Subsequence and Distance to Monotonicity in Data Stream Model Hossein Jowhari...

Longest Increasing Subsequence and Distance to Monotonicity in Data Stream Model
Hossein Jowhari Simon Fraser University
Joint work with Funda ErgunDagstuhl
August 2008

Problem Definitions
Longest Increasing Subsequence (LIS)
LIS(A)= length of longest increasing subsequence of sequence A
A = 5,3,0,7,10,8,2,13,15,9,2,20,2,3. LIS(A)=6
(ε-LIS) Approximate LIS(A) within 1- ε factor for ε<1
Distance to Monotonicity
DM(A)= minimum number of elements needed to be deleted from A to get a sorted sequence = |A|-LIS(A)
Approximate the length of DM(A) within 1+ ε factor for ε>0

LIS problem in data stream model
An exact algorithm in space O(|LIS|). [LVZ05]
Every exact algorithm needs Ω(n) space. [GJKK07],[WS07]
There is a O(ε-1/2n1/2) space deterministic streaming algorithm [GJKK07]
[GJKK07] Conjecture: Every deterministic streaming algorithm for ε-LIS needs Ω(n1/2) space.
This Talk: A proof for the above conjecture (constant ε ).
A lower bound of Ω (ε-1/2n1/2) was discovered independently by Gal and Gopalan (FOCS 07). (Next talk!)

Distance to Monotonicity in Data Stream Model
Complexity of exact computations is the same as the LIS computation.
A deterministic (1+ε) approximation algorithm using O(ε-1/2n1/2) space [GJKK07]
A randomized (4+ε) approximation algorithm using O(ε-2 log2n) space [GJKK07]
Our Result: There is a deterministic (2+ε) approximation algorithm which uses O(ε-
2 log2n) space. (A brief description in this talk)

Space Lower Bound for Approximating LIS
an Algorithm for Approximating
Distance to Monotonicity

Communication Complexity of ε-LIS[GJKK07]
1096702153 10487831019
There is an O(ε-1logn) deterministic protocol for 2 Players. 2-player model does not help.
There is an extension of the protocol to √n - players,where each player sends O(√n) bits.
Let’s consider O(√n) player setting.

Lower Bound using multiplayer communication complexity (general idea)
We split the input equally among √n players.
The players compute a function g which is reducible to ε-LIS.
We decompose g into primitive functions hi with high communication complexity
Finally using a direct-sum approach, we show a lower bound total communication complexity of g
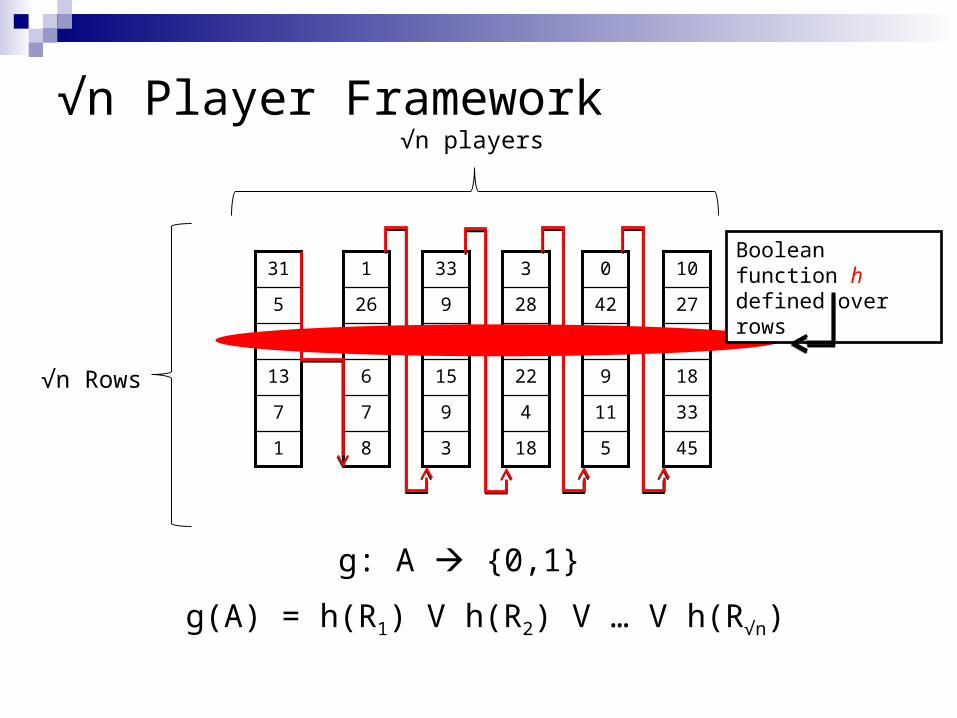
√n Player Framework
1
7
13
3
5
31
8
7
6
4
26
1
3
9
15
10
9
33
18
4
22
22
28
3
5
11
9
56
42
0
45
33
18
24
27
10
g: A {0,1}
Boolean function h defined over rows
g(A) = h(R1) V h(R2) V … V h(R√n)
√n Rows
√n players

Description of the primitive function h
h(R) =
0 if no consecutive nonzero elements in R.
1 if there are at least β√n nonzero elements in R. (β > 0.5)
g(A) = h(R1) V h(R2) V … V h(R√n)

Going from g to LIS
13 0 30 0 0 52
0 28 0 29 0 0
0 0 0 25 0 31
0 15 22 0 0 27
12 0 20 0 21 0
3 0 8 0 10 0
√n × √n matrix
1 0 1 0 0 1
0 1 0 1 0 0
0 0 0 1 0 1
0 1 1 0 0 1
1 0 1 0 1 0
1 0 1 0 1 0
Numbers are increasing in each column (upward) and each row (leftward)

1 0 1 0 0 0 1
1 0 0 1 0 0 1
1 0 0 1 0 0 1
1 0 1 0 1 0 1
1 0 1 0 0 0 1
1 0 0 1 0 0 1
1 0 0 0 1 0 1
1 0 1 0 0 0 1
1 0 0 1 0 0 1
1 1 1 1 1 1 1
1 0 1 0 0 0 1
1 0 1 0 1 0 1
1 0 0 0 0 0 1
1 0 1 0 1 0 1
A0
no consecutive 1’s in a row.
g(A0) = 0
LIS(A0) ≤ 3/2 √n
A1There is one row
with β√n number of 1’s
g(A1)=1
LIS(A1) ≥ (1+β) √n
Description of function g in terms of binary matrices

Description of the fooling set for h
A is a k-Fooling set for h if
• A is a collection of subsets of {1,..,√n}.
• For all u in A, no consecutive member of [√n] appear in u.
• The union of every k members of A has size at least β√n.
Using the probabilistic method we can prove that there exists a fooling set for h of size c√n where c>1
If A is a k-fooling set for f then CCtot(f) ≥ log (|A|/k-1)

Let F1, F2, …, F√n be the fooling sets for h.
F1 × F2 × … × F√n is a k√n-fooling set for g
Each Fi has size c√n
CCtot(g) ≥ log cn/k√n = Ω (n)
CCmax(g) = Ω(√n)
Fooling set for g
CCmax(ε-LIS) = Ω(√n)

Space Lower Bound for Approximating LIS
an Algorithm for Approximating
Distance to Monotonicity

An approximate characterizationbased on inversion
High level idea:
We detect a set of elements that highly violate the monotonicity of the sequence. (bad elements)
These elements form a set of disjoint decreasing subsequences (lower bound)
Deleting twice the number of these elements from the sequence results in a sorted sequence (upper bound)

An approximate characterizationbased on inversion
σ(i) is red if
there is a interval I=[j,i-1] such that number of inversions in I (with respect to σ(i)) is bigger than number of red elements in that interval.
7 1 5 6 7 0 2 8 9 3 4 5 6 7 0
Definition of a bad (red) element.

Number of red elements is smaller than DM(σ) |R| <= DM(σ)
(Idea) We can decompose the red elements into disjoint decreasing subsequences of σ.
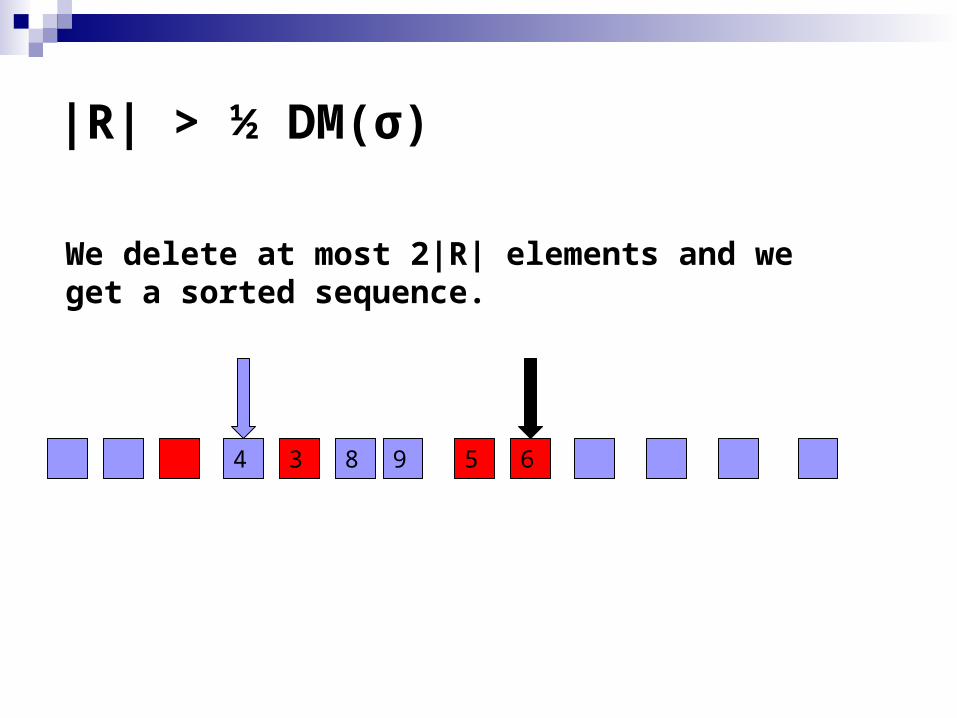
|R| > ½ DM(σ)
We delete at most 2|R| elements and we get a sorted sequence.
4 3 8 9 5 6

A streaming friendly characterization
σ(i) is red if most of the elements in the interval are inverted with respect to σ(i) and red elements in the interval are far from being the majority.
This gives a 2+ε approximation
We can do this using existing deterministic algorithms for quantile approximation in all intervals [LLXY, ICDE04].

Open Questions
• Is randomness useful in approximating LIS?
• Is there a polylog approximation scheme for distance to monotonicity?


















