
Lecture 04: Logistic Regression - University of Waterlooy328yu/mycourses/489/lectures/lec04.pdf5...
43
CS489/698: Intro to ML Lecture 04: Logistic Regression 9/21/17 Yao-Liang Yu 1
Transcript of Lecture 04: Logistic Regression - University of Waterlooy328yu/mycourses/489/lectures/lec04.pdf5...

CS489/698: Intro to ML Lecture 04: Logistic Regression
9/21/17 Yao-Liang Yu 1

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 2

Announcements
• Assignment 1 due next Tuesday
9/21/17 Yao-Liang Yu 3

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 4

Baseline
• Assuming Lin Alg Basics:
9/21/17 Francois Chaubard and Agastya Kalra 5 f calSystems

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 6

ML Pyramid
9/21/17 Francois Chaubard and Agastya Kalra 7
f calSystems
Deep Learning
Software Engineering Linear Algebra
Convex Optimization Probability and Statistics Information Theory
Machine Learning (anything fancier than simple Sklearn fit / predict calls)

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 8

Regression or Classif icat ion
9/21/17 Francois Chaubard and Agastya Kalra 9
f calSystems
or

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 10
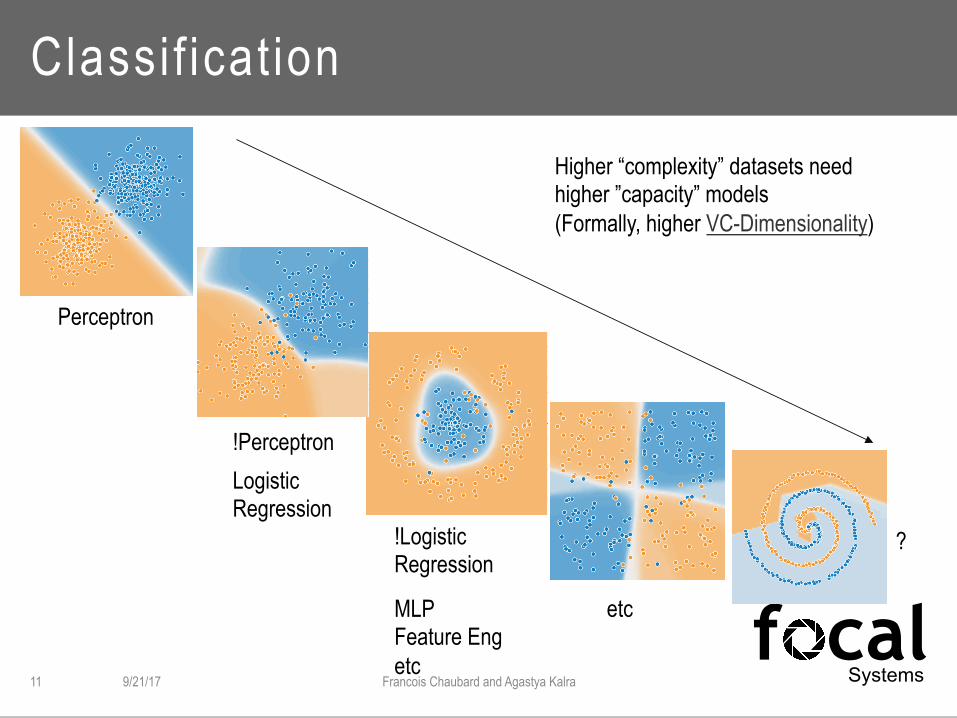
Classif icat ion
9/21/17 Francois Chaubard and Agastya Kalra 11
f calSystems
Higher “complexity” datasets need higher ”capacity” models (Formally, higher VC-Dimensionality)
Perceptron
!Perceptron Logistic Regression
!Logistic Regression
MLP Feature Eng etc
etc
?

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but
smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 12

History of Solvers
9/21/17 Francois Chaubard and Agastya Kalra 13
f calSystems
Closed Form <1950s Iterative Methods+Convex 1950-2012 Iterative Methods+Smooth 2012+
Least Squares etc
Interior Point Methods Log Barrier etc
Deep Learning etc

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 14

Convexity
9/21/17 Francois Chaubard and Agastya Kalra 15
f calSystems
Jensen’s Inequality

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 16

SGD
9/21/17 Francois Chaubard and Agastya Kalra 17
f calSystems

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 18

Perceptron
9/21/17 Francois Chaubard and Agastya Kalra 19
f calSystems
Issues:

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 20

Bernoul l i model
• Let P(Y=1 | X=x) = p(x; w), parameterized by w
• Conditional likelihood on {(x1, y1), … (xn, yn)}:
• simplifies if independence holds
• Assuming yi is {0,1}-valued
9/21/17 Yao-Liang Yu 21
P(Y1 = y1, . . . , Yn = yn|X1 = x1, . . . , Xn = xn)
nY
i=1
P(Yi = yi|Xi = xi) =nY
i=1
p(xi;w)yi(1� p(xi;w))1�yi

Naïve solut ion
• Find w to maximize conditional likelihood
• What is the solution if p(x; w) does not depend on x?
• What is the solution if p(x; w) does not depend on ?
9/21/17 Yao-Liang Yu 22
nY
i=1
p(xi;w)yi(1� p(xi;w))1�yi

General ized l inear models (GLM)
• y ~ Bernoulli(p); p = p(x; w) natural parameter • Logistic regression
• y ~ Normal(µ, σ2); µ = µ(x; w) • (weighted) least-squares regression
• GLM: y ~ exp( θ φ(y) – A(θ) )
9/21/17 Yao-Liang Yu 23
sufficient statistics
log-partition function

Logit transform
• p(x; w) = wTx? p >=0 not guaranteed…
• log p(x; w) = wTx? better! • LHS negative, RHS real-valued…
• Logit transform
• Or equivalently
9/21/17 Yao-Liang Yu 24
log
p(x;w)
1� p(x;w)
= w
>x
p(x;w) =
1
1 + exp(�w
>x)
odds ratio

Predict ion with confidence
• ŷ = 1 if p = P(Y=1 | X=x) > ½ iff wTx > 0
• Decision boundary wTx = 0
• ŷ = sign(wTx) as before, but with confidence p(x; w)
9/21/17 Yao-Liang Yu 25
p(x;w) =
1
1 + exp(�w
>x)

Not just a classif icat ion algori thm
• Logistic regression does more than classification • it estimates conditional probabilities • under the logit transform assumption
• Having confidence in prediction is nice • the price is an assumption that may or may not hold
• If classification is the sole goal, then doing extra work • as shall see, SVM only estimates decision boundary
9/21/17 Yao-Liang Yu 26
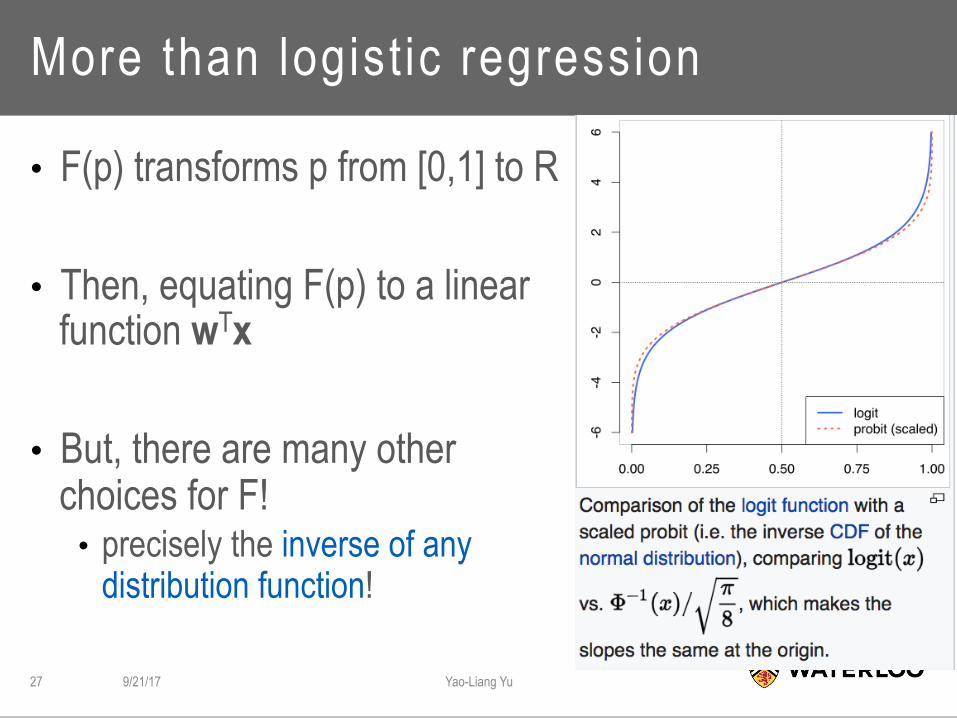
More than logist ic regression
• F(p) transforms p from [0,1] to R
• Then, equating F(p) to a linear function wTx
• But, there are many other choices for F! • precisely the inverse of any
distribution function!
9/21/17 Yao-Liang Yu 27

Logist ic distr ibut ion
• Cumulative Distribution Function
• Mean mu, variance s2π2/3
9/21/17 Yao-Liang Yu 28
F (x;µ, s) =
1
1 + exp(�x�µ
s
)

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 29

Playground
9/21/17 Francois Chaubard and Agastya Kalra 30
f calSystems

Tensorf low coding example
9/21/17 Francois Chaubard and Agastya Kalra 31
f calSystems

Outl ine • Announcements • Baseline • Learning “Machine Learning” Pyramid • Regression or Classification (that’s it!) • History of Classification • History of Solvers (Analytical to Convex to “Non-Convex but smooth”) • Convexity • SGD • Perceptron Review • Bernoulli model / Logistic Regression • Tensorflow Playground / Demo code • Multiclass
9/21/17 Yao-Liang Yu 32

More than 2 classes
• Softmax
9/21/17 Yao-Liang Yu 33
P(Y = c|x,W ) =
exp(w
>c x)Pk
q=1 exp(w>q x)

More than 2 classes
• Softmax
• Again, nonnegative and sum to 1
• Negative log-likelihood (y is one-hot)
9/21/17 Yao-Liang Yu 34
P(Y = c|x,W ) =
exp(w
>c x)Pk
q=1 exp(w>q x)
� log
nY
i=1
kY
c=1
pyicic = �
nX
i=1
kX
c=1
yic log pic

Questions?
9/21/17 Yao-Liang Yu 35

backup
9/21/17 Yao-Liang Yu 36

Classif icat ion revisi ted
9/21/17 Yao-Liang Yu 37
• ŷ = sign( xTw + b )
• How confident we are about ŷ?
• |xTw + b| seems a good indicator • real-valued; hard to interpret • ways to transform into [0,1]
• Better(?) idea: learn confidence directly

Condit ional probabi l i ty
• P(Y=1 | X=x): conditional on seeing x, what is the chance of this instance being positive, i.e., Y=1? • obviously, value in [0,1]
• P(Y=0 | X=x) = 1 – P(Y=1 | X=x), if two classes • more generally, sum to 1
9/21/17 Yao-Liang Yu 38
Notation (Simplex). Δk-1 := { p in Rk: p ≥ 0, Σi pi = 1 }

Reduction to a harder problem
• P(Y=1 | X=x) = E(1Y=1 | X=x)
• Let Z = 1Y=1, then regression function for (X, Z) • use linear regression for binary Z?
• Exploit structure! • conditional probabilities are in a simplex
• Never reduce to unnecessarily harder problem 9/21/17 Yao-Liang Yu 39
1A =
(1, A is true
0, A is false

Maximum l ikel ihood
• Minimize negative log-likelihood
9/21/17 Yao-Liang Yu 40
nY
i=1
p(xi;w)yi(1� p(xi;w))1�yi
p(x;w) =
1
1 + exp(�w
>x)
X
i
log(e(1�yi)w>xi
+ e�yiw>xi) ⌘
X
i
log(1 + e�yiw>xi)

Newton’s algori thm
• η = 1: iterative weighted least-squares
9/21/17 Yao-Liang Yu 41
wt+1 wt � ⌘t[r2f(wt)]�1 ·rf(wt)
PSD
pi =1
1 + e�w
>t xi
Uncertain predictions get bigger weight
rf(wt) = X>(p� y)
r2f(wt) =X
i
pi(1� pi)xix>i

A word about implementat ion
• Numerically computing exponential can be tricky • easily underflows or overflows
• The usual trick • estimate the range of the exponents • shift the mean of the exponents to 0
9/21/17 Yao-Liang Yu 42

Robustness
• Bounded derivative
• Variational exponential
9/21/17 Yao-Liang Yu 43
L(y, y) = `(�yy)`(t) = log(1 + et) y = w
>x
`0(t) =et
1 + et=
1
1 + e�t
log(1 + et) = min
0⌘1⌘et � log(⌘) + ⌘ � 1
Larger exp loss gets smaller weights


















