
La codifica digitale del testo -...
30
La codifica digitale del testo
Transcript of La codifica digitale del testo -...

La codifica digitale del testo

Elementi di InformaticaChiara Epifanio
La codifica
Il computer elabora esclusivamente numeri binari.
Le informazioni per essere trattate ed elaborate dal computer devono essere prima trasformate in numeri binari (sequenze di 0 e 1).
Il processo di trasformazione di una qualunque informazione in numeri si chiama “codifica”.
Se si usano numeri binari la codifica si chiama “codifica binaria”.
Codifica digitale

Elementi di InformaticaChiara Epifanio
I simboli 0 e 1 si chiamano anche bit (unità di informazione).
Il computer associa i valori binari di 1 e 0 al passaggio di corrente, alla polarizzazione di una sostanza magnetica, ecc.
8 bit formano un byte.
Con n bit si possono rappresentare 2n numeri binari distinti, quindi con n bit possiamo rappresentare 2n
informazioni distinte.
Codifica digitale
La codifica

Elementi di InformaticaChiara Epifanio
Il linguaggio e il testo
Il testo scritto è una trasposizione del linguaggio parlato.
Per convenzione si assegnano dei simboli ai fonemi, tali simboli sono i caratteri dell’alfabeto.
Ogni parola viene rappresentata con una sequenza di caratteri.
Ogni lingua ha il suo alfabeto che può essere radicalmente diverso da quello di altre lingue.
Testo

Elementi di InformaticaChiara Epifanio
Il testo
Il testo scritto è formato non solo da caratteri dell’alfabeto (necessari per formare le parole) ma anche da altri simboli necessari per rendere comprensibile, e quindi fruibile, il testo.
In particolare in un testo possiamo distinguere:
I limitatori di parola (spazi bianchi).I limitatori di frase (segni di interpunzione).I limitatori di pagina (margini).I simboli speciali (virgolette, simboli matematici ecc.).La disposizione e l’aspetto del testo (formattazione).
Testo

Elementi di InformaticaChiara Epifanio
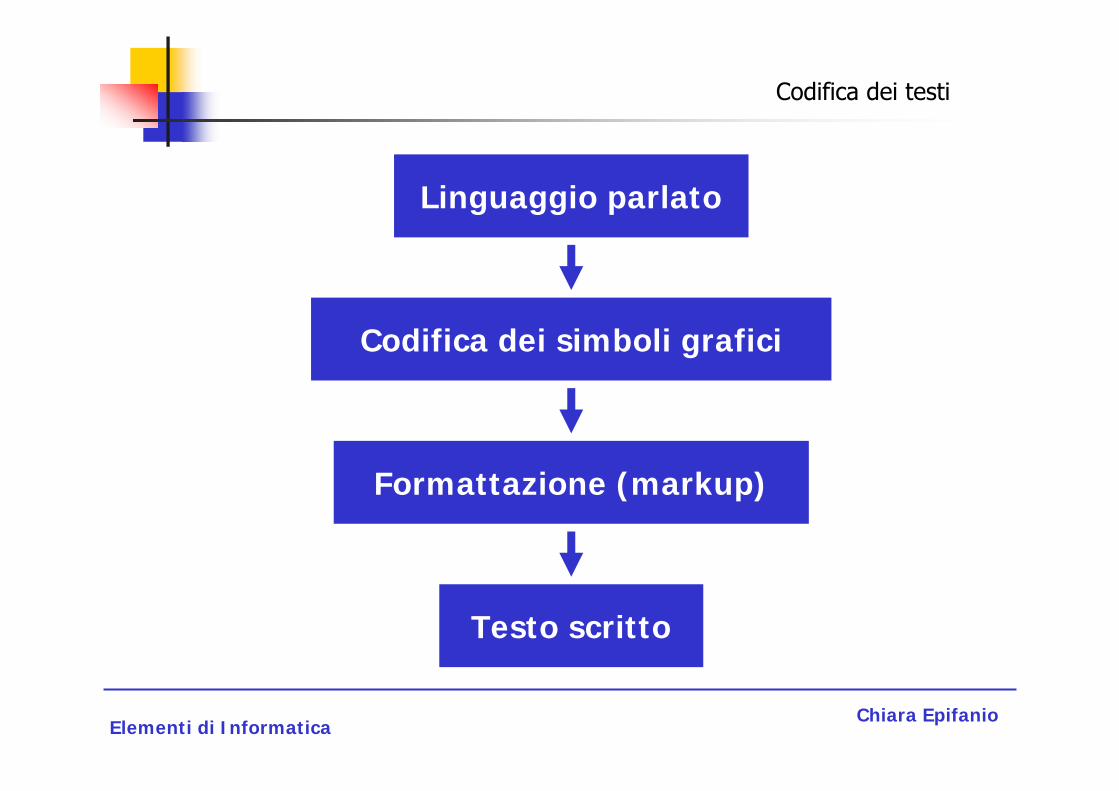
Quindi per passare da un testo (in linguaggio naturale) a un testo elettronico (in binario) è necessario un processo di codifica che deve essere composto da due parti:
La codifica dei caratteri e dei simboli grafici.
La codifica delle operazioni necessarie per esplicitare l’interpretazione del testo (markup).
Testo
La codifica del testo
Elementi di InformaticaChiara Epifanio
Linguaggio parlato
Codifica dei simboli grafici
Formattazione (markup)
Testo scritto
Codifica dei testi

Elementi di InformaticaChiara Epifanio
I vantaggi del testo elettronico
I vantaggi più evidenti del testo elettronico, rispetto a un testo tradizionale, sono:
le operazioni di manipolazione (modifica, cancellazione ecc.) di un testo elettronico sono molto semplici e veloci.le ricerche effettuate sono più veloci e precise.la conservazione delle informazioni è più sicura, grazie alla possibilità di effettuare delle copie (a costo praticamente nullo) dei file che contengono il testo.Nel caso di un testo elettronico la condivisione e lo scambio diinformazioni viene agevolato rispetto ad un testo tradizionale (cartaceo).
Testo

Elementi di InformaticaChiara Epifanio
Acquisizione di un testo
Per trattare elettronicamente il testo è necessario acquisirlo, ovvero fornirlo come input al computer.
Per acquisire il testo si può operare in diversi modi:
Digitare il testo tramite la tastiera.Usare uno scanner e un software di OCR (Optical CharacterRecognition),Copiare il testo precedentemente acquisito o creato da altri tramite la copia di file memorizzati su qualche tipo di supporto(floppy disk, CD-ROM ecc.).
Testo

La codifica dei caratteri

Elementi di InformaticaChiara Epifanio
La codifica dei caratteri
I caratteri sono i componenti fondamentali di un qualunque scritto umano.
I caratteri hanno una natura (ossia il fonema che rappresentano) e un glifo (ossia il modo in cui sono rappresentati).
Codifica dei caratteri
A a A a A aI caratteri rappresentati sopra hanno la stessa natura ma glifi diversi.

Elementi di InformaticaChiara Epifanio
La codifica dei caratteri
Per codificare i simboli grafici bisogna associare ad ogni carattere un numero naturale.
In questo modo costruiamo una corrispondenza biunivoca tra l’insieme dei caratteri e un insieme di numeri.
Questa corrispondenza può essere rappresentata per mezzo di una tabella detta “set di caratteri”.
Ad ogni carattere si associa un codice numerico detto “code position”.
Codifica dei caratteri
Elementi di InformaticaChiara Epifanio
La codifica dei caratteri
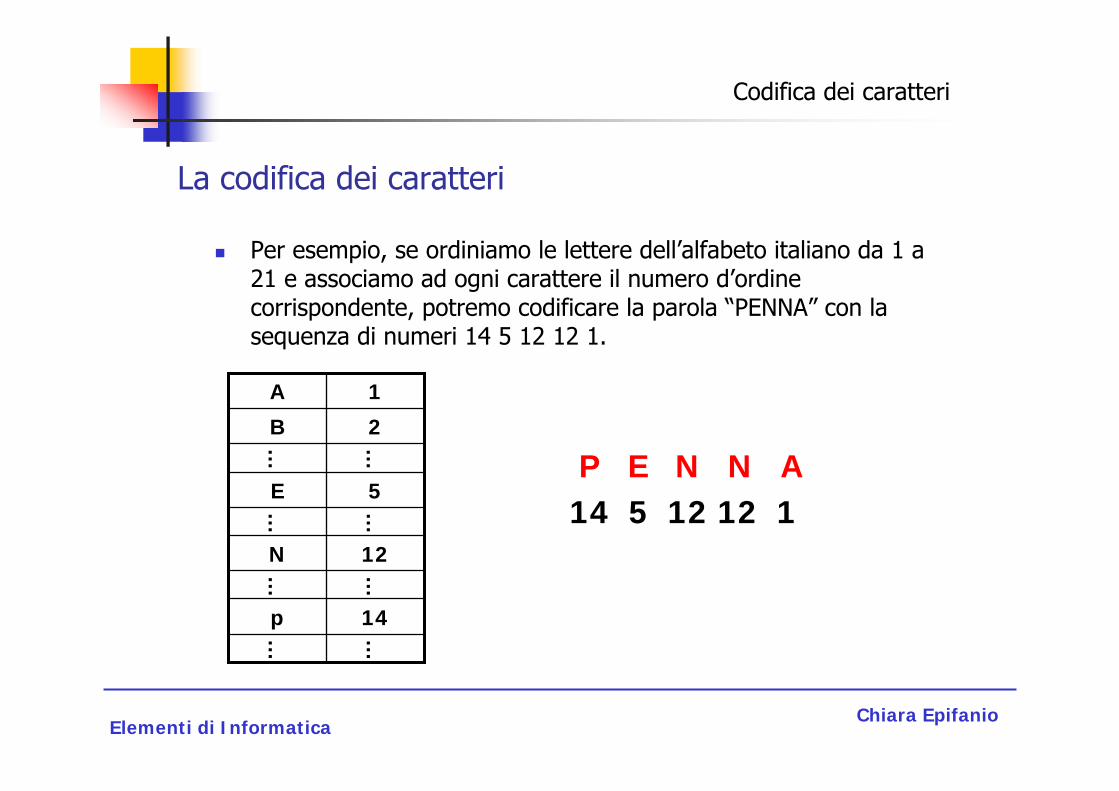
Per esempio, se ordiniamo le lettere dell’alfabeto italiano da 1 a 21 e associamo ad ogni carattere il numero d’ordine corrispondente, potremo codificare la parola “PENNA” con la sequenza di numeri 14 5 12 12 1.
Codifica dei caratteri
……
12N
14p
……
5E
……
……
2B
1A
P E N N A14 5 12 12 1

Elementi di InformaticaChiara Epifanio
La codifica ASCII
La prima standardizzazione della codifica dei caratteri venne fatta dall’American Standard Code for InformationInterchange, o ASCII, nel 1968, tuttavia essa era giàesistente nella sua forma definitiva dalla fine degli anni cinquanta.
La codifica ASCII usa solo 7 bit degli 8 disponibili in un byte, quindi permette solo 27 = 128 combinazioni diverse, e lascia un bit libero (ai tempi la scarsa qualità dell’hardware questo bit serviva per verificare la corretta memorizzazione e trasmissione di ogni singolo byte).
Codifica ASCII

Elementi di InformaticaChiara Epifanio
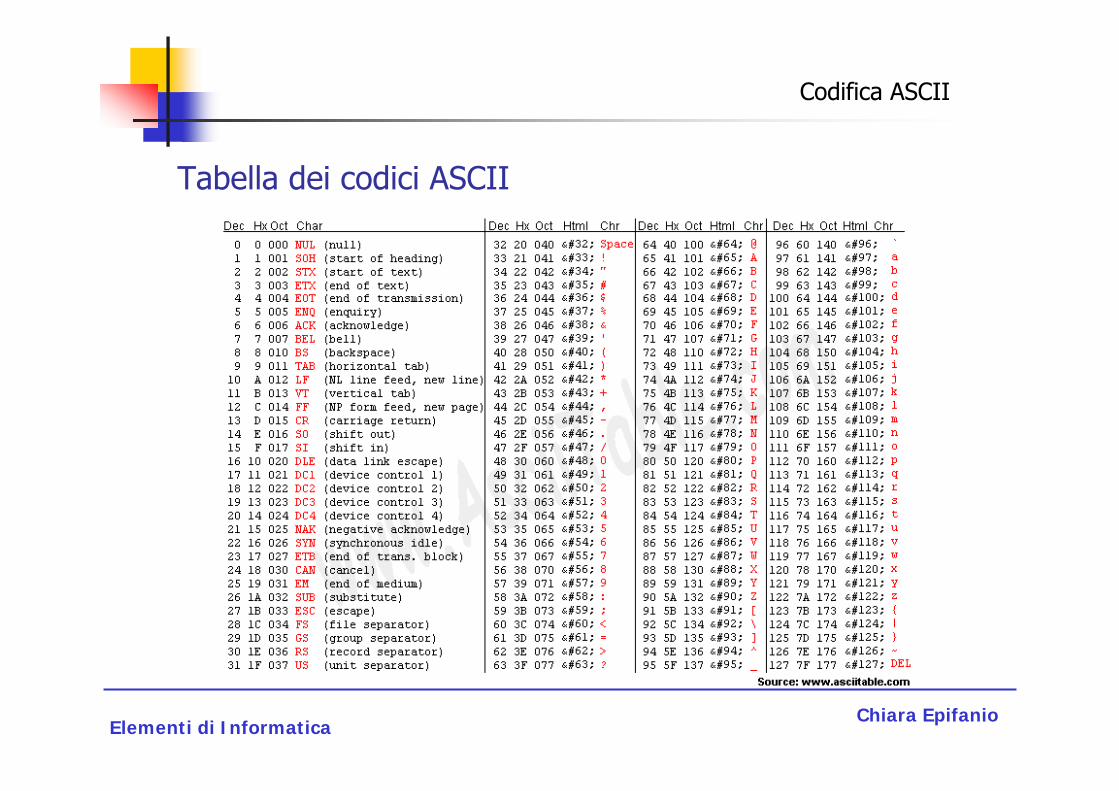
Delle 128 combinazioni possibili le prime 32 sono riservate a codici di controllo, vale a dire caratteri particolari di uso nelle telescriventi e nei terminali dell’epoca a disposizione, mentre dalla 33a posizione in poi trovano una codifica le lettere maiuscole e minuscole dell’alfabeto latino, i numeri, i principali caratteri di punteggiatura, le parentesi e vari simboli (&, >, <, /, +, *, ecc).
Mancano in ASCII tutte le varianti dell’alfabeto latino usate nelle altre lingue europee (ad esempio le vocali accentate o con la dieresi, i simboli delle monete, ecc).
La codifica ASCII
Codifica ASCII

Elementi di InformaticaChiara Epifanio
La codifica ASCII standard viene detta anche ISO-646.
Nella codifica ASCII i principali caratteri dell’alfabeto sono trasformati in un numero decimale e quindi in un numero binario o esadecimale.
La tabella di codifica ASCII è uno standard accettato da tutti i paesi.
La codifica ASCII
Codifica ASCII
Elementi di InformaticaChiara Epifanio
Tabella dei codici ASCII
Codifica ASCII

Elementi di InformaticaChiara Epifanio
In seguito al miglioramento della qualità dell’hardware era più necessario riservare un bit per il controllo, quindi si cominciò ad utilizzare il bit libero per codificare altri caratteri (per esempio i caratteri tipici di ogni lingua).
Con i 7 bit della codifica ASCII più il nuovo bit si potevano codificare 28 = 256 caratteri.
Ogni produttore pensò di codificare i caratteri che riteneva più utili dando vita ad una codifica ASCII estesa. Le due estensioni più comuni erano quella dell’ANSI (American National Standard Institute) e del sistema operativo MS-DOS (Microsoft Disk Operating System).
La codifica ASCII estesa
Codifica ASCII estesa

Elementi di InformaticaChiara Epifanio
Il risultato di queste estensioni non standard fu che i testi diventavano incomprensibili trasportandoli da una macchina ad un’altra.
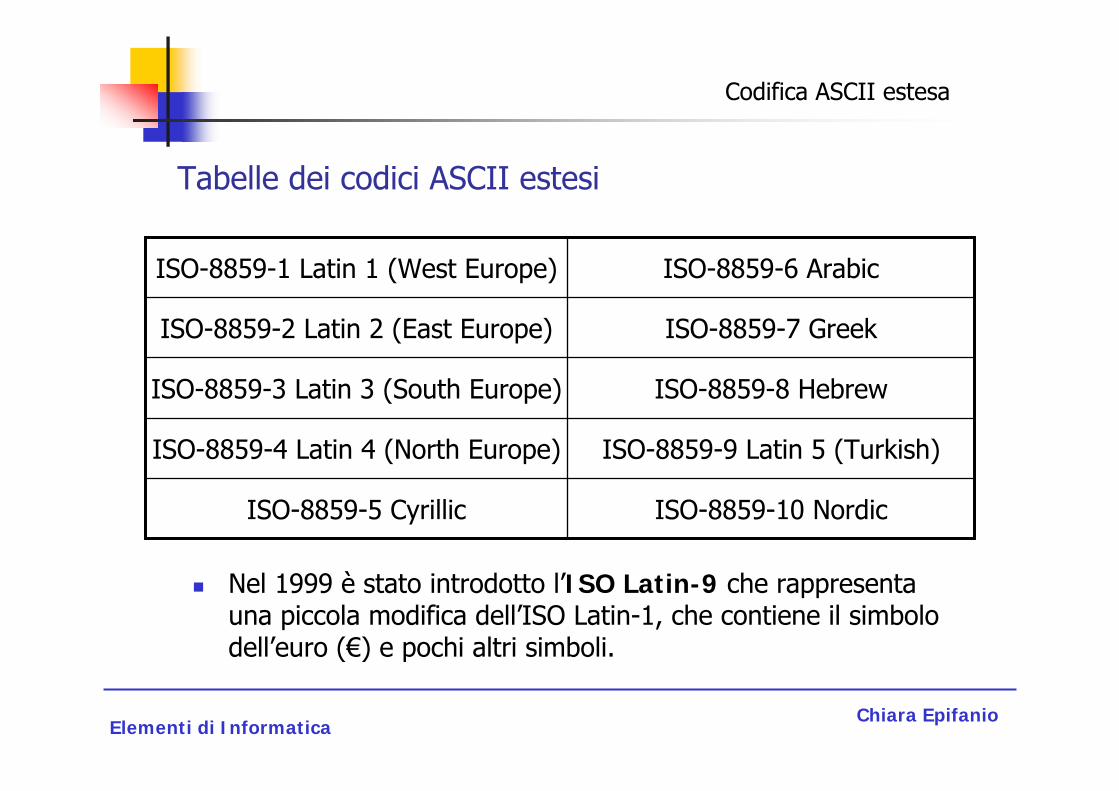
Nel 1990 si pensò di standardizzare le estensioni ASCII a 8 bit, nacque così lo standard ISO Latin-n o ISO-8859-n dove n indica la tabella estesa utilizzata (necessaria per rappresentare i caratteri delle varie lingue).
La codifica ASCII estesa nelle prime 128 posizioni èidentica alla codifica ASCII standard a 7 bit.
La codifica ASCII estesa
Codifica ASCII estesa

Elementi di InformaticaChiara Epifanio
Per analogia con la codifica ASCII standard le prime 32 posizioni dopo la 128a sono riservate a caratteri di controllo, mentre nelle successive 96 posizioni sono codificati i simboli e i caratteri tipici di ogni lingua (à, ã, è, è, ë, æ, ì, ï, î, ò, ö, ø, õ, ù, ü, À, Á, Â, Ã, È, Ë, É, Ê, Æ, Ì, Í, Î, Ï, Ø, Ö, Ó, Ò, Õ, č, Č, ç, ecc.)
Il risultato della nuova codifica fu una tabella per ogni lingua, inoltre questi set di caratteri erano tutti reciprocamente incompatibili (per esempio il codice 232 in ISO-8859-1 (Latin-1) = “è” mentre in ISO-8859-6 (Cyrillic) = “ш”).
La codifica ASCII estesa
Codifica ASCII estesa
Elementi di InformaticaChiara Epifanio
Tabelle dei codici ASCII estesi
ISO-8859-9 Latin 5 (Turkish)ISO-8859-4 Latin 4 (North Europe)
ISO-8859-10 NordicISO-8859-5 Cyrillic
ISO-8859-8 HebrewISO-8859-3 Latin 3 (South Europe)
ISO-8859-7 GreekISO-8859-2 Latin 2 (East Europe)
ISO-8859-6 ArabicISO-8859-1 Latin 1 (West Europe)
Nel 1999 è stato introdotto l’ISO Latin-9 che rappresenta una piccola modifica dell’ISO Latin-1, che contiene il simbolo dell’euro (€) e pochi altri simboli.
Codifica ASCII estesa

Elementi di InformaticaChiara Epifanio
La tabella ASCII estesa con i suoi 256 caratteri era più che sufficiente per codificare gli alfabeti di molti paesi occidentali, tuttavia non era sufficiente per rappresentare tutti i caratteri di tutte le lingue del mondo. Così nel 1991 si pensò di introdurre una nuova codifica che potesse comprendere tutti gli alfabeti di tutte le lingue (presenti e passate) del mondo.
Il nuovo standard è noto come Unicode o ISO 10646 e prevede l’utilizzo di più byte per ogni carattere.
Ci sono tre tipi di codifica Unicode in relazione al numero di byte utilizzati per la codifica.
La codifica unicode (www.unicode.org)
Codifica Unicode

Elementi di InformaticaChiara Epifanio
Lo standard Unicode è sufficiente per rappresentare i caratteri di tutti i sistemi grafici.
Unicode permette la realizzazione di documenti multilingua.
Lo standard Unicode si basa sui principi di composizione dinamica dei caratteri
ç = c + ¸
La codifica unicode (www.unicode.org)
Codifica Unicode

Elementi di InformaticaChiara Epifanio
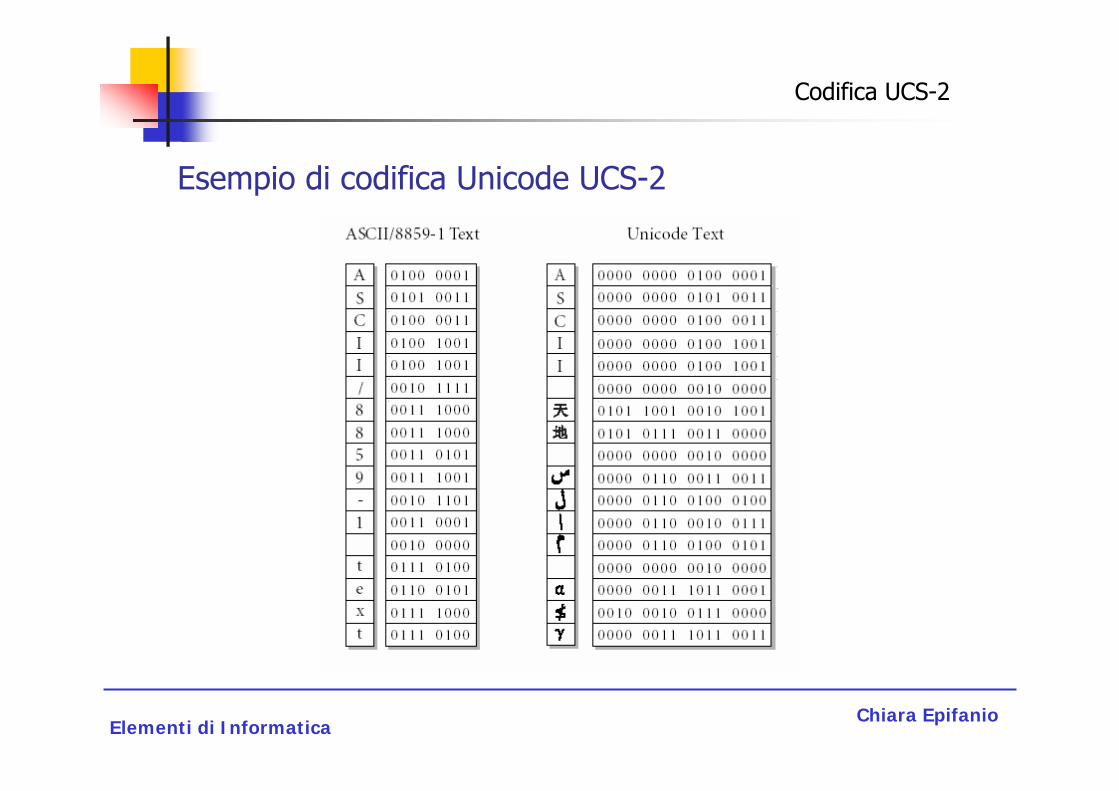
Lo standard UCS-2 (Unified o Universal Character Set a 2 byte) utilizza due byte (16 bit) per ogni carattere, quindi è in grado di rappresentare 216 = 65.536 caratteri diversi, in questo modo si riescono a codificare la maggior parte degli alfabeti moderni.
Lo standard UCS-2 non è sufficiente per codificare il cinese e altre lingue orientali.
La codifica UCS-2
Codifica UCS-2
Elementi di InformaticaChiara Epifanio
Esempio di codifica Unicode UCS-2
Codifica UCS-2

Elementi di InformaticaChiara Epifanio
Lo standard UCS-4 (Unified o Universal Character Set a 4 byte) utilizza quattro byte (32 bit) per ogni carattere, quindi èin grado di rappresentare 232 = 4.294.967.296 caratteri diversi, in questo modo si riescono a codificare tutti gli alfabeti di tutte le lingue compreso il cinese, i geroglifici e l’alfabeto cuneiforme.
Poiché le esigenze degli alfabeti umani sono molto piùbasse degli oltre 4 miliardi di caratteri permessi, di fatto lo standard UCS-4 ha il 90% dei codici non assegnati.
La codifica UCS-4
Codifica UCS-4

Elementi di InformaticaChiara Epifanio
Lo standard UCS-4 è compatibile con UCS-2 che a sua volta è compatibile con ASCII standard.
La codifica Unicode
Codifica Unicode
Codifica del carattere A
ASCII
UCS-2
UCS-4
65
65
65
0
000

Elementi di InformaticaChiara Epifanio
Il problema principale dello standard UCS-4 è lo spazio occupato dai documenti.
Infatti: se consideriamo un documento scritto solo con caratteri ASCII esso occuperà un certo spazio di memoria. Se il documento lo scriviamo con caratteri UCS-2 occuperàuno spazio doppio e se lo scriviamo con caratteri UCS-4 esso occuperà uno spazio quadruplo.
Lo spazio in eccesso inoltre è costituito da bit tutti impostati a zero, quindi si tratta di spazio sprecato inutilmente.
La codifica UTF-8
Codifica UTF-8

Elementi di InformaticaChiara Epifanio
Per ovviare al problema dello spreco di spazio e mantenere la compatibilità della trasmissione dei documenti, è stato introdotto il sistema UTF-8 (Unified o UniversalTransformation Format a 8 bit).
Lo standard UTF-8 codifica i caratteri usando una lunghezza variabile tra 1 e 4 byte (da 8 a 32 bit).
UTF-8 (ed altre codifiche a lunghezza variabile) fanno comunque riferimento a UCS-4 che è la mappatura piùcompleta e organizzata di tutti i caratteri di Unicode.
La codifica UTF-8
Codifica UTF-8

Elementi di InformaticaChiara Epifanio
Se un carattere è rappresentabile in ASCII, allora la sua codifica UTF-8 rimane la stessa (un singolo byte).
Se il carattere è rappresentabile in UCS-2 o UCS-4, allora la sua codifica UTF-8 sarà costituita da due o quattro byte, il primo dei quali specificherà la lunghezza della sequenza.
In generale, se la codifica occupa n byte (2 ≤n ≤6), allora il primo byte avrà i primi n bit impostati a 1, poi uno 0 ed infine i bit della rappresentazione del carattere.
La codifica UTF-8
Codifica UTF-8


















