
Introduction to Data Modeling with Apache Cassandra
53
Introduction to Data Modeling with Apache Cassandra Luke Tillman (@LukeTillman) Language Evangelist at DataStax
-
Upload
luke-tillman -
Category
Technology
-
view
211 -
download
0
Transcript of Introduction to Data Modeling with Apache Cassandra

Introduction to Data Modeling with
Apache Cassandra
Luke Tillman (@LukeTillman)
Language Evangelist at DataStax

1 Relational Modeling vs. Cassandra
2 The Basics
3 CQL Collections
4 Relationships
5 Time Series Use Case
2

Relational Modeling vs. Cassandra
3

The Good ol’ Relational Database
• Been around a long time (first proposed in 1970)
• Data modeling is well understood (typically 3NF or higher)
• ACID guarantees are easy for developers to reason about
• SQL is ubiquitous and allows flexible querying
– JOINs, Sub SELECTs, etc.
4

Relational Data Modeling
• Five normal forms
• Foreign Keys
• Joins at read time
– Example SQL: Get employee
and department for user id 5
(Helena Edelson)
Id First Last DeptId
1 Luke Tillman 201
2 Jon Haddad 201
5 Helena Edelson 205
5
Id Dept
201 Evangelists
205 Engineering
Employees
Departments
SELECT e.First, e.Last, d.Dept FROM Employees e JOIN Departments d ON e.DeptId = d.Id WHERE e.Id = 5

Relational Data Modeling Thought Process
6
Data
Models
Application

Cassandra Data Modeling Thought Process
7
Models
Application
Data

CQL vs SQL
• Similar syntax in many
cases, but...
• No Joins
• No Aggregations
Id First Last DeptId
1 Luke Tillman 201
2 Jon Haddad 201
5 Helena Edelson 205
8
Id Dept
201 Evangelists
205 Engineering
Employees
Departments
SELECT e.First, e.Last, d.Dept FROM Employees e JOIN Departments d ON e.DeptId = d.Id WHERE e.Id = 5

Denormalization
• Combine table columns into single view at write time
• No joins necessary
9
Id First Last Dept
1 Luke Tillman Evangelists
2 Jon Haddad Evangelists
5 Helena Edelson Engineering
Employees
SELECT First, Last, Dept FROM Employees WHERE Id = 5

Sequences and Auto-Incrementing Ids
• Great for letting the RDBMS handle auto-generating Ids
• Guaranteed to be unique
• Needs ACID to work (uh oh)
10
INSERT INTO Employees (Id, First, Last) VALUES (seq.nextVal(), "Patrick", "McFadin")

No More Sequences
• Almost impossible in a distributed system like Cassandra
• Couple of great choices instead: – Natural Keys: Unique values like Email
– Surrogate Key: UUID (or GUID for MS folks)
• UUID: Universally Unique Identifier – 128-bit number represented in character form
– Can be generated easily on the client side
11
99051fe9-6a9c-46c2-b949-38ef78858dd0

The Basics
12

Cassandra Data Modeling Thought Process
• Start with your
application and the
queries it needs to
run
• Then build models to
satisfy those queries
13
Models
Application
Data

Entity Table
• Query: Find user by id
• Simple view of a single user
• UUID used for ID
• Simple primary key
14
CREATE TABLE users ( userid uuid, firstname text, lastname text, email text, created_date timestamp, PRIMARY KEY (userid) );
SELECT firstname, lastname FROM users WHERE userid = 99051fe9-6a9c-46c2-b949-38ef78858dd0

Entity Table – A reminder on Partition Keys
• First part of Primary Key is the
Partition Key
15
CREATE TABLE users ( userid uuid, firstname text, lastname text, email text, created_date timestamp, PRIMARY KEY (userid) );
firstname ...
Luke ...
Jon ...
Patrick ...
userid
689d56e5- …
93357d73- …
d978b136- …

More Complicated Primary Keys
• Query: Find comments for a video (most recent first)
16
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);
SELECT commentid, userid, comment FROM comments_by_video WHERE videoid = 0fe6ab76-cf17-4664-abcc-4e363cee273f LIMIT 10

Let's Break This Down
• TimeUUID: a UUID with a timestamp component
• Ordering by a TimeUUID is like ordering by its timestamp
17
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);
eeaca440-c745-11e4-8830-0800200c9a66 03/10/2015 16:53:09 GMT

Let's Break This Down
• The Primary Key uniquely identifies a row, so a comment is
uniquely identified by its videoid and commentid
18
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);

Let's Break This Down
• The first part of the Primary Key is the Partition Key, so
comments for a given video will be stored together in a partition
• When we query for a given videoid, we only need to talk to
one partition (and thus one node), which is fast
19
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);

Let's Break This Down
• The second part of the Primary Key is the Clustering Column(s)
• Inside a partition, comments for a given video will be ordered
by commentid
• Remember ordering by TimeUUID is ordering by timestamp
20
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);

Let's Break This Down
• We can specify a default clustering order when creating the
table which will affect the ordering of the data stored on disk
• Since our query was to get the latest comments for a video, we
order by commentid descending
21
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);

Let's Break This Down
22
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY (videoid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);
videoid='0fe6a...'
userid= 'ac346...'
comment= 'Awesome!'
commentid='82be1...' (10/1/2014 9:36AM)
userid= 'f89d3...'
comment= 'Garbage!'
commentid='765ac...' (9/17/2014 7:55AM)

This query will be fast
23
videoid='0fe6a...'
userid= 'ac346...'
comment= 'Awesome!'
commentid='82be1...' (10/1/2014 9:36AM)
userid= 'f89d3...'
comment= 'Garbage!'
commentid='765ac...' (9/17/2014 7:55AM)
SELECT commentid, userid, comment FROM comments_by_video WHERE videoid = 0fe6ab76-cf17-4664-abcc-4e363cee273f LIMIT 10
1. Locate
single
partition
2. Single seek
on disk 3. Slice 10 latest rows and return

Getting the most from queries
• Queries on Partition Key are fast
– Querying inside a single partition should be the goal
– Always specify a value for partition key when querying
• Queries on Partition Key and one or more Clustering Column(s)
are fast
– Again, inside a single partition should be the goal
– Use default ordering when creating the table to optimize if applicable
• Cassandra will give you errors if you try to stray
24

More than one way to query the same data
• New Query: Find comments made by a user (most recent first)
25
CREATE TABLE comments_by_user ( userid uuid, commentid timeuuid, videoid uuid, comment text, PRIMARY KEY (userid, commentid) ) WITH CLUSTERING ORDER BY (commentid DESC);
SELECT commentid, videoid, comment FROM comments_by_user WHERE userid = 99051fe9-6a9c-46c2-b949-38ef78858dd0 LIMIT 10

More than one way to query the same data
• Two views of the same data
• Use a batch when inserting to both tables
• Denormalize at write time to do efficient queries at read time
26
CREATE TABLE comments_by_user ( userid uuid, commentid timeuuid, videoid uuid, comment text, PRIMARY KEY ( userid, commentid) ) WITH CLUSTERING ORDER BY ( commentid DESC);
CREATE TABLE comments_by_video ( videoid uuid, commentid timeuuid, userid uuid, comment text, PRIMARY KEY ( videoid, commentid) ) WITH CLUSTERING ORDER BY ( commentid DESC);

CQL Collections
27

CQL Collection Basics
• Store a collection of related things in a column
• Meant to be dynamic part of a table
• Update syntax is very different from insert
• Reads require all of the collection to be read
28

CQL Set
• No duplicates, sorted by CQL type's comparator
29
INSERT INTO collections_example (id, set_example) VALUES (1, {'Patrick', 'Jon', 'Luke'});
set_example set<text>
Collection name
(column name)
Collection type CQL type

CQL Set
• Adding an element to a set
• Removing an element from a set
30
UPDATE collections_example SET set_example = set_example + {'Rebecca'} WHERE id = 1
UPDATE collections_example SET set_example = set_example - {'Luke'} WHERE id = 1

CQL List
• Allows duplicates, sorted by insertion order
• Use with caution
31
INSERT INTO collections_example (id, list_example) VALUES (1, ['Patrick', 'Jon', 'Luke']);
list_example list<text>
Collection name
(column name)
Collection type CQL type

CQL List
• Adding an element to the end of a list
• Adding an element to the beginning of a list
• Removing an element from a list
32
UPDATE collections_example SET list_example = list_example + ['Rebecca'] WHERE id = 1
UPDATE collections_example SET list_example = ['Rebecca'] + list_example WHERE id = 1
UPDATE collections_example SET list_example = list_example - ['Luke'] WHERE id = 1
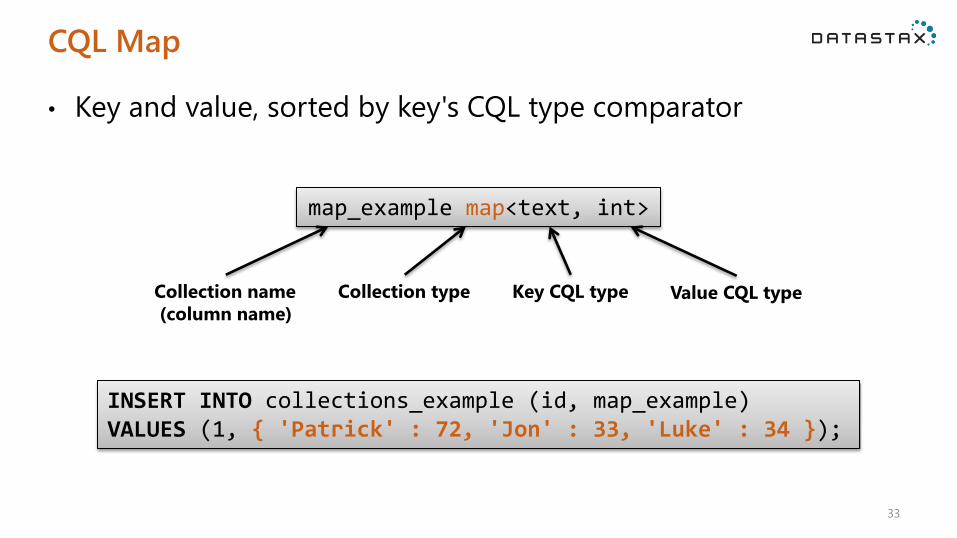
CQL Map
• Key and value, sorted by key's CQL type comparator
33
INSERT INTO collections_example (id, map_example) VALUES (1, { 'Patrick' : 72, 'Jon' : 33, 'Luke' : 34 });
map_example map<text, int>
Collection name
(column name)
Collection type Key CQL type Value CQL type

CQL Map
• Adding an element to a map
• Updating an existing element in a map
• Removing an element from a map
34
UPDATE collections_example SET map_example['Rebecca'] = 29 WHERE id = 1
UPDATE collections_example SET map_example['Jon'] = 34 WHERE id = 1
DELETE map_example['Luke'] FROM collections_example WHERE id = 1

Relationships
35

Revisiting our One-to-Many Relationship
36
Id First Last DeptId
7bc7a... Luke Tillman 5078c...
d7463... Jon Haddad 5078c...
8c26b... Helena Edelson 1d0f3...
Id Dept
5078c... Evangelists
1d0f3... Engineering
Employees Departments
Department Employee has n 1

Revisiting our One-to-Many Relationship
• Query: Get an employee and
his/her department by
employee id
– Denormalize department data
37
First Last Dept
Luke Tillman Evangelists
Jon Haddad Evangelists
Helena Edelson Engineering
Id
7bc7a...
d7463...
8c26b...
Employees
CREATE TABLE employees ( id uuid, first text, last text, dept text, PRIMARY KEY (id) );
SELECT first, last, dept FROM employees WHERE id = 7bc7a...

What about the other side of the relationship?
• Query: Get all the employees for a given department
38
CREATE TABLE employees_by_dept ( dept_id uuid, emp_id uuid, first text, last text, dept text, PRIMARY KEY (dept_id, emp_id) );
SELECT first, last, dept FROM employees_by_dept WHERE dept_id = 5078c...

What about the other side of the relationship?
39
CREATE TABLE employees_by_dept ( dept_id uuid, emp_id uuid, first text, last text, dept text, PRIMARY KEY (dept_id, emp_id) );
dept_id= '5078c...'
emp_id='7bc7a...'
dept= 'Evangelists'
first= 'Luke'
last= 'Tillman'
emp_id='d7463...'
dept= 'Evangelists'
first= 'Jon'
last= 'Haddad'

Static Columns
• Department name (dept)
will be the same across all
rows in the partition
• This is a good candidate
for a static column
40
CREATE TABLE employees_by_dept ( dept_id uuid, emp_id uuid, first text, last text, dept text, PRIMARY KEY (dept_id, emp_id) );
dept_id= '5078c...'
emp_id='7bc7a...'
dept= 'Evangelists'
first= 'Luke'
last= 'Tillman'
emp_id='d7463...'
dept= 'Evangelists'
first= 'Jon'
last= 'Haddad'

Static Columns
• For data that is shared across
all rows in a partition, use
static columns
• Updates to the value will
affect all rows in the partition
41
CREATE TABLE employees_by_dept ( dept_id uuid, emp_id uuid, first text, last text, dept text STATIC, PRIMARY KEY (dept_id, emp_id) );
dept_id= '5078c...'
dept= 'Evangelists'
emp_id='7bc7a...'
first= 'Luke'
last= 'Tillman'
emp_id='d7463...'
first= 'Jon'
last= 'Haddad'

Time Series Use Case
42

Weather Station
• Weather station collects data
• Cassandra stores in sequence
• Application reads in sequence
43

Weather Station
Needed Queries
• Get all data for one weather
station
• Get data for a single date
and time
• Get data for a range of dates
and times
Data Model for Queries
• Store data per weather
station
• Store time series in order:
first to last
44

Weather Station
• Weather station id and
time are unique
• Store as many as needed
45
CREATE TABLE temperatures ( weather_station text, year int, month int, day int, hour int, temperature double, PRIMARY KEY ( weather_station, year, month, day, hour) );
INSERT INTO temperatures (weather_station, year, month, day, hour, temperature) VALUES ('10010:99999', 2005, 12, 1, 7, -5.6); INSERT INTO temperatures (weather_station, year, month, day, hour, temperature) VALUES ('10010:99999', 2005, 12, 1, 8, -5.1); INSERT INTO temperatures (weather_station, year, month, day, hour, temperature) VALUES ('10010:99999', 2005, 12, 1, 9, -4.9); INSERT INTO temperatures (weather_station, year, month, day, hour, temperature) VALUES ('10010:99999', 2005, 12, 1, 10, -5.3);

Storage Model: Logical View
46
SELECT weather_station, hour, temperature FROM temperatures WHERE weather_station = '10010:99999'
10010:99999
10010:99999
10010:99999
10010:99999
weather_station
7
8
9
10
hour
-5.6
-5.1
-4.9
-5.3
temperature

Storage Model: Disk Layout
47
SELECT weather_station, hour, temperature FROM temperatures WHERE weather_station = '10010:99999'
10010:99999 2005:12:1:7
-5.6 2005:12:1:8
-5.1 2005:12:1:9
-4.9 2005:12:1:10
-5.3

Storage Model: Disk Layout
48
SELECT weather_station, hour, temperature FROM temperatures WHERE weather_station = '10010:99999'
10010:99999 2005:12:1:7
-5.6 2005:12:1:8
-5.1 2005:12:1:9
-4.9 2005:12:1:10
-5.3 2005:12:1:11
Merged, Sorted, and Stored Sequentially
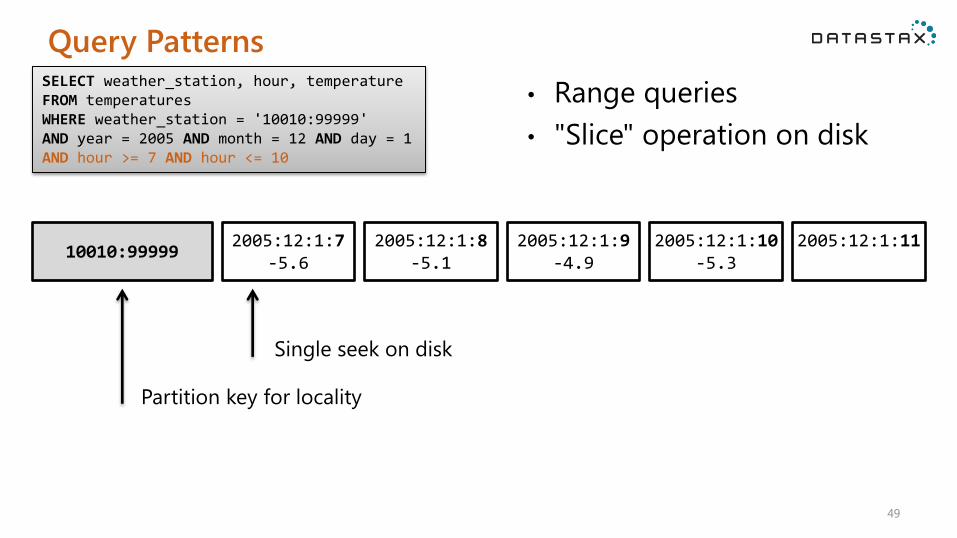
Query Patterns
• Range queries
• "Slice" operation on disk
49
SELECT weather_station, hour, temperature FROM temperatures WHERE weather_station = '10010:99999' AND year = 2005 AND month = 12 AND day = 1 AND hour >= 7 AND hour <= 10
10010:99999 2005:12:1:7
-5.6 2005:12:1:8
-5.1 2005:12:1:9
-4.9 2005:12:1:10
-5.3 2005:12:1:11
Partition key for locality
Single seek on disk

Query Patterns
50
• Range queries
• "Slice" operation on disk
10010:99999
10010:99999
10010:99999
10010:99999
weather_station hour temperature
7
8
9
10
-5.6
-5.1
-4.9
-5.3
SELECT weather_station, hour, temperature FROM temperatures WHERE weather_station = '10010:99999' AND year = 2005 AND month = 12 AND day = 1 AND hour >= 7 AND hour <= 10

Query Patterns
51
• Programmers like this
10010:99999
10010:99999
10010:99999
10010:99999
weather_station hour temperature
7
8
9
10
-5.6
-5.1
-4.9
-5.3
SELECT weather_station, hour, temperature FROM temperatures WHERE weather_station = '10010:99999' AND year = 2005 AND month = 12 AND day = 1 AND hour >= 7 AND hour <= 10
Sorted in
time order

Takeaway: Goals of Cassandra Data Modeling
• Spread data evenly around the cluster
– Choose a good Primary Key (particularly, the Partition Key portion)
• Minimize the number of partitions read for a given query
– Remember: Partitions are spread out around the cluster
• Do not worry about:
– Minimizing the number of writes: Cassandra is really fast at writes
– Minimizing data duplication: this is not 3NF from RDBMS, disk is cheap
52

Questions?
Follow me for updates or to ask questions later: @LukeTillman
53


















