
Apache Cassandra - Einführung
61
Referent: Andreas Finke Sichere Systeme Prof. Dr. Christoph Pleier WS2014/15 15. Januar 2015 Hochverfügbares NoSQL Datenbank System
-
Upload
andreas-finke -
Category
Software
-
view
377 -
download
5
Transcript of Apache Cassandra - Einführung

Referent: Andreas Finke
Sichere Systeme Prof. Dr. Christoph Pleier
WS2014/15
15. Januar 2015
Hochverfügbares NoSQL Datenbank System
• Aspekte IT-Sicherheit• Verfügbarkeit
• Datensicherheit
• Einsatz von Cassandra im Unternehmen seit 2012
• Finanzumfeld (Kurse, Charts)
• Vorher proprietäre Lösung• 600 Schreibzugriffe/Sek
• Cassandra• 26.000 Schreibzugriffe/Sek
2
Motivation
http://keyinvest-ch.ubs.com/marktuebersicht/ubs-deri-risk-indikator

• Apache Cassandra
• Cassandra Architektur
• Daten-Replikation
• Konsistenz
• Sicherheit
• Demo: Daten Modellierung mit CQL
3
Agenda

• Verteilte spaltenorientierte NoSQL Datenbank
• Entwickelt bei Facebook
• Open Source: 2008 (github.com/apache/cassandra)
• Aktuelle Version: 2.1.2 (Stand: 13.Januar 2015)
• Kein Master = Gleichwertige Nodes
• API• CQL (Cassandra Query Language)
• Apache Thrift
• Treiber• Java, Python, Ruby, NodeJS, C#
4
Apache Cassandra
A
D B
CCassandra Node
r/w
r/w
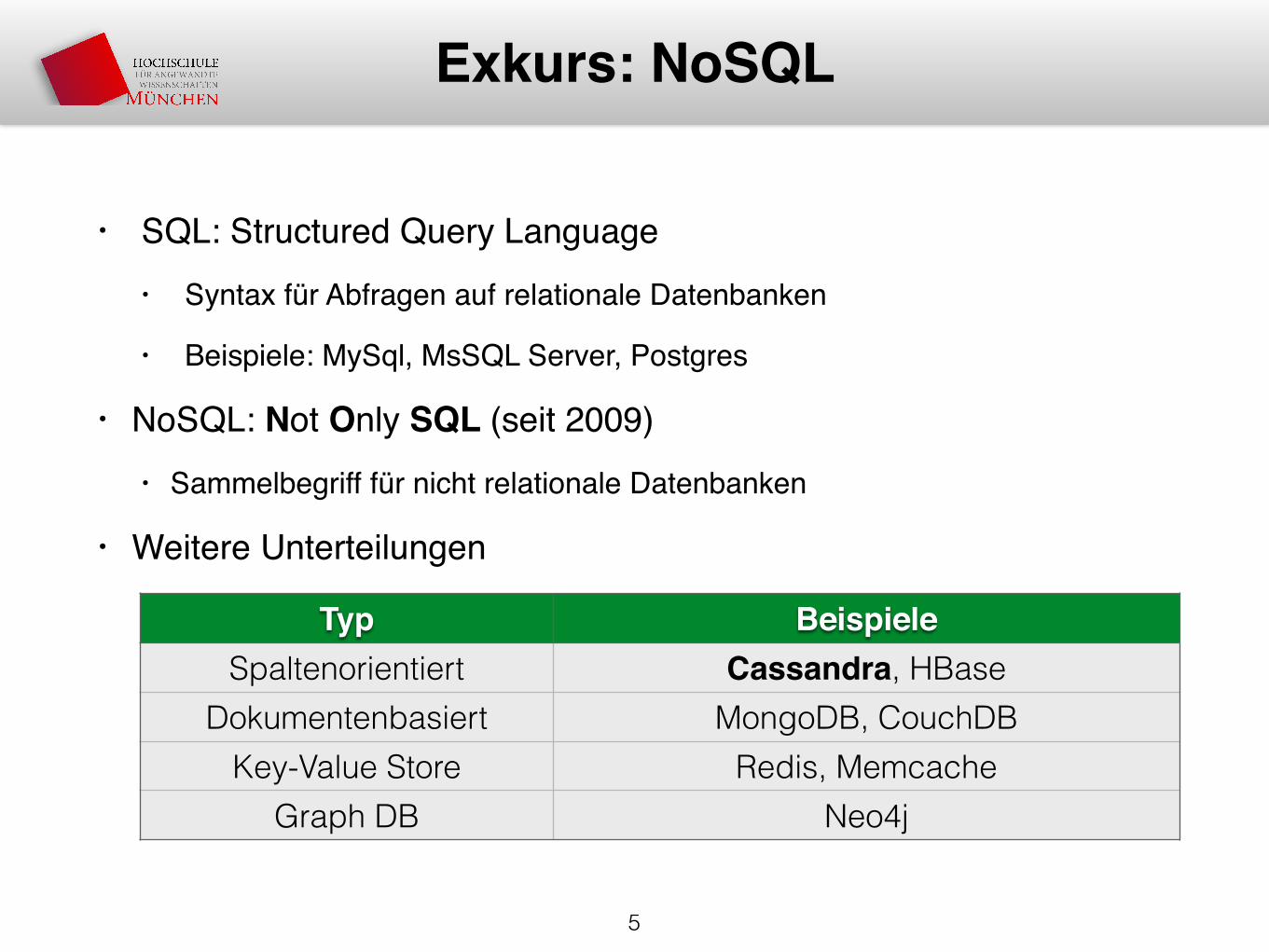
• SQL: Structured Query Language• Syntax für Abfragen auf relationale Datenbanken
• Beispiele: MySql, MsSQL Server, Postgres
• NoSQL: Not Only SQL (seit 2009)• Sammelbegriff für nicht relationale Datenbanken
• Weitere Unterteilungen
5
Exkurs: NoSQL
Typ BeispieleSpaltenorientiert Cassandra, HBase
Dokumentenbasiert MongoDB, CouchDBKey-Value Store Redis, Memcache
Graph DB Neo4j
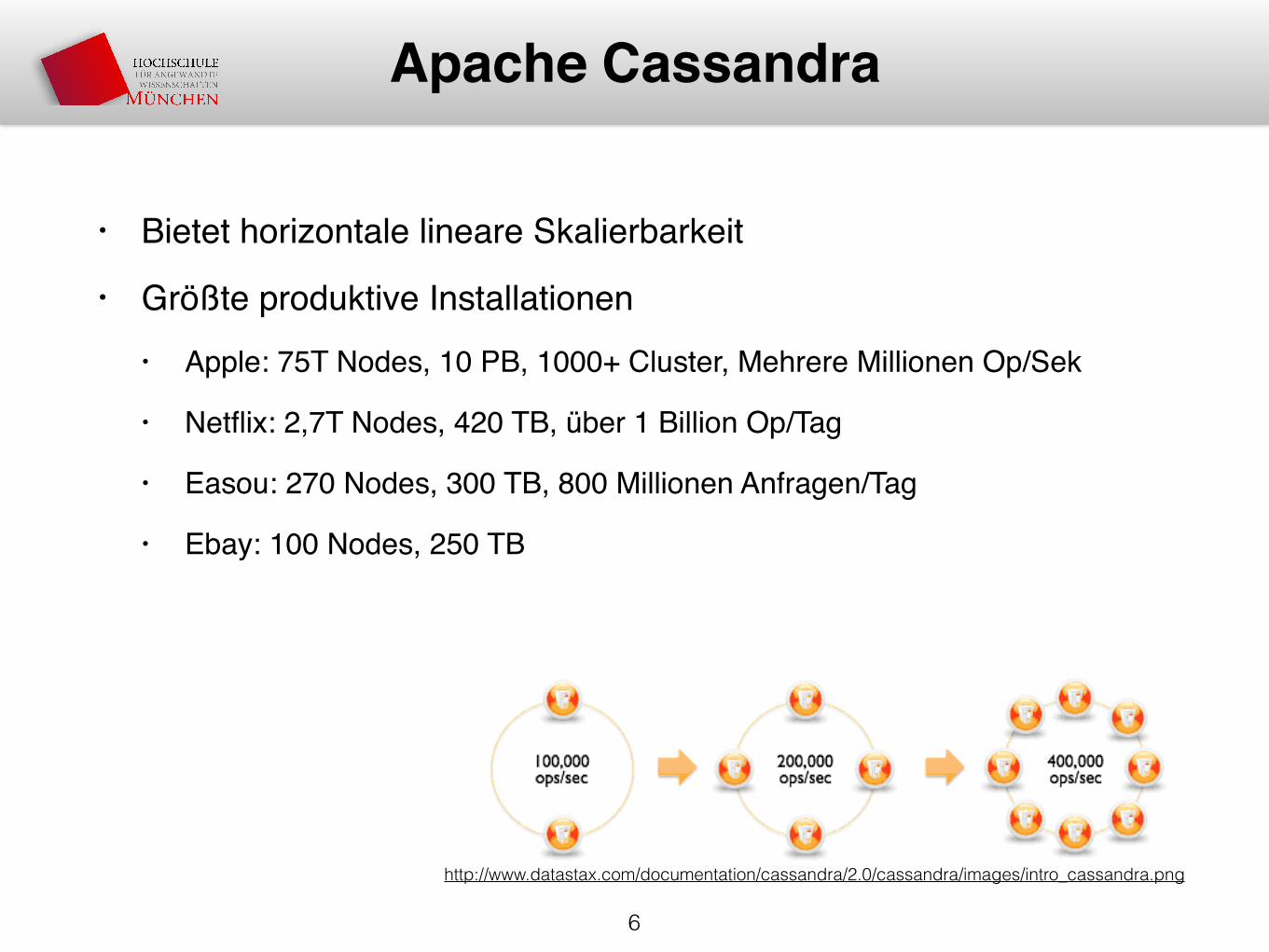
• Bietet horizontale lineare Skalierbarkeit
• Größte produktive Installationen• Apple: 75T Nodes, 10 PB, 1000+ Cluster, Mehrere Millionen Op/Sek
• Netflix: 2,7T Nodes, 420 TB, über 1 Billion Op/Tag
• Easou: 270 Nodes, 300 TB, 800 Millionen Anfragen/Tag
• Ebay: 100 Nodes, 250 TB
6
Apache Cassandra
http://www.datastax.com/documentation/cassandra/2.0/cassandra/images/intro_cassandra.png

7
Apache Cassandra
https://pbs.twimg.com/media/BxSWW9vCYAALQ58.jpg:large
Apple Vortrag auf Cassandra Summit 2014
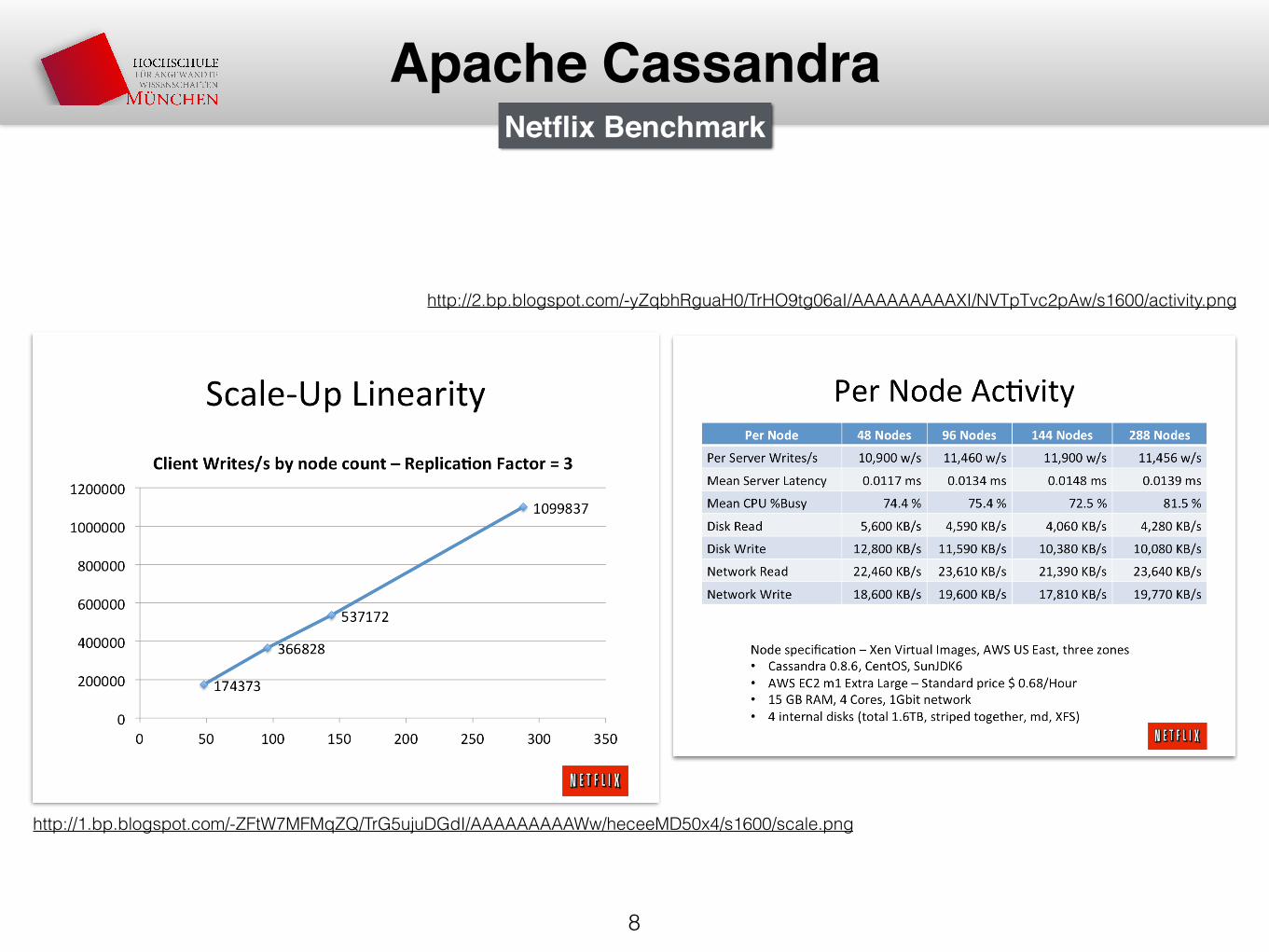
8
Apache Cassandra
http://1.bp.blogspot.com/-ZFtW7MFMqZQ/TrG5ujuDGdI/AAAAAAAAAWw/heceeMD50x4/s1600/scale.png
http://2.bp.blogspot.com/-yZqbhRguaH0/TrHO9tg06aI/AAAAAAAAAXI/NVTpTvc2pAw/s1600/activity.png
Netflix Benchmark

• Gegründet: April 2010 von Jonathan Ellis
• Enterprise Support für Apache Cassandra
• ~80% der Commits auf Github
• DataStax Enterprise • Apache Cassandra + Extra features
• Datastax Community (frei verfügbar)• OpsCenter (GUI)
• DevCenter (Daten Modellierung)
9
Apache Cassandra
http://www.datastax.com/wp-content/themes/datastax-2013/images/opscenter/opsc4-ring-view-c-hadoop-solr.jpg
Datastax

• Apache Cassandra
• Cassandra Architektur• Daten-Replikation
• Konsistenz
• Sicherheit
• Demo: Daten Modellierung mit CQL
10
Agenda
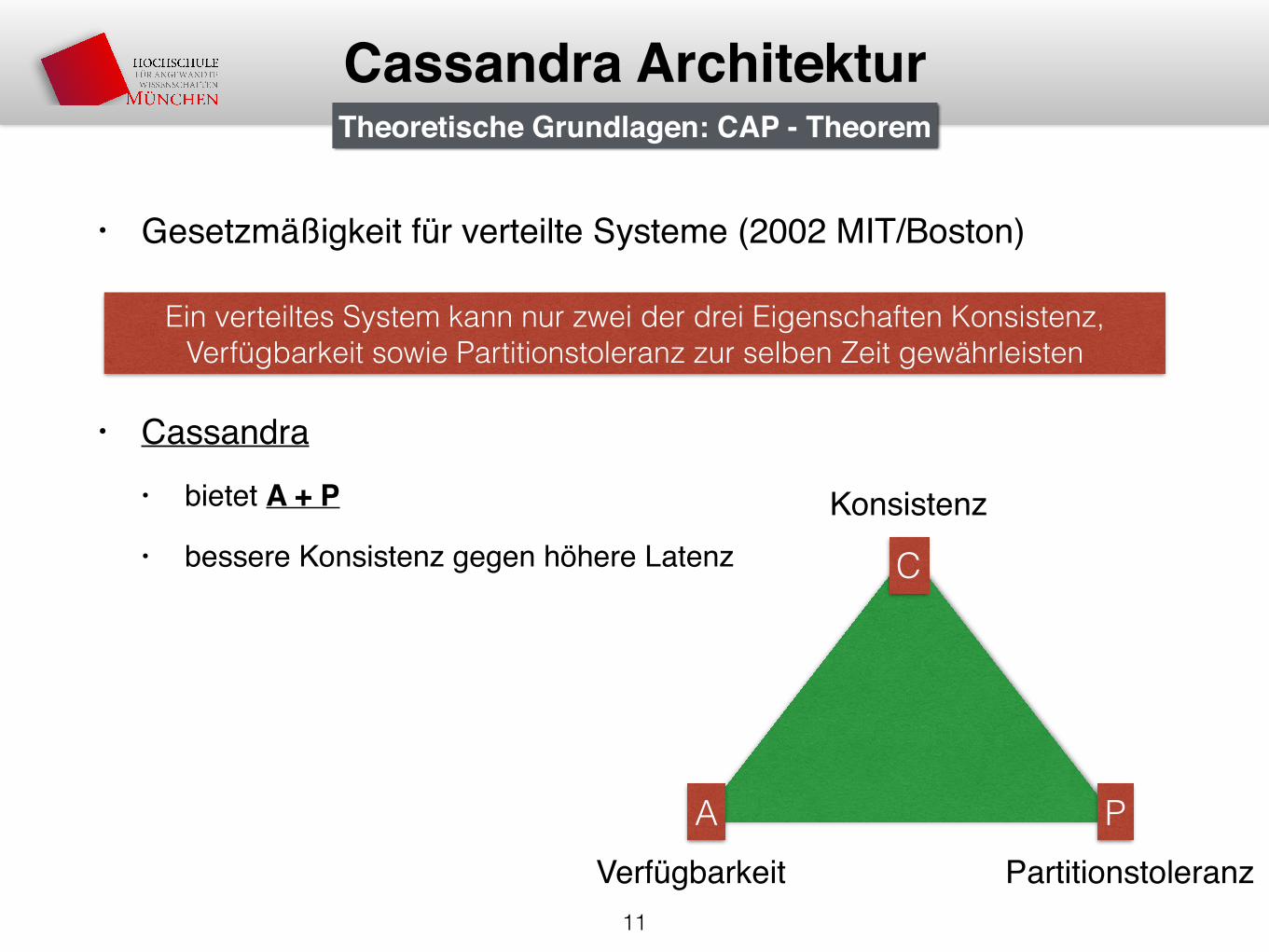
• Gesetzmäßigkeit für verteilte Systeme (2002 MIT/Boston)
• Cassandra• bietet A + P
• bessere Konsistenz gegen höhere Latenz
11
Cassandra Architektur
Konsistenz
Verfügbarkeit Partitionstoleranz
C
A P
Ein verteiltes System kann nur zwei der drei Eigenschaften Konsistenz, Verfügbarkeit sowie Partitionstoleranz zur selben Zeit gewährleisten
Theoretische Grundlagen: CAP - Theorem

• Quelle: Amazon (Oktober 2007)
• Problem: Notwendigkeit für ~100% Verfügbarkeit
• Lösung:• Partitionierung der Daten auf 1-n gleichwertige Nodes (masterless)
• Gleichmäßige Verteilung via Consistent Hashing
• Hohe Verfügbarkeit mittels n * Replikation der Daten
• Intra-Cluster Kommunikations Protokoll (Gossip)
12
Cassandra Architektur
“[…] even if disks are failing, network routes are flapping, or data centers are being destroyed by tornados […]”
Theoretische Grundlagen: Dynamo Paper

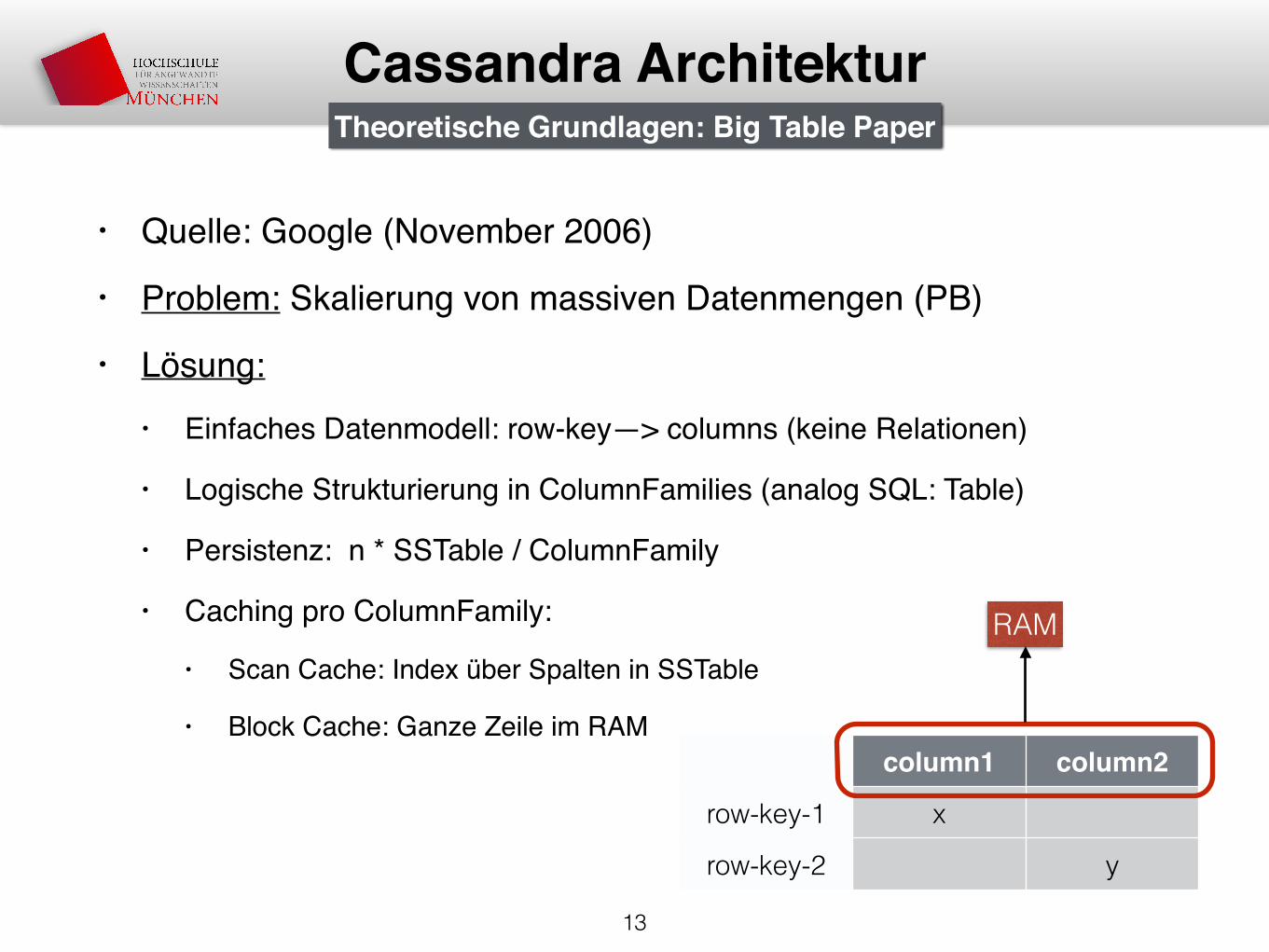
• Quelle: Google (November 2006)
• Problem: Skalierung von massiven Datenmengen (PB)
• Lösung: • Einfaches Datenmodell: row-key—> columns (keine Relationen)
• Logische Strukturierung in ColumnFamilies (analog SQL: Table)
• Persistenz: n * SSTable / ColumnFamily
• Caching pro ColumnFamily:
• Scan Cache: Index über Spalten in SSTable
• Block Cache: Ganze Zeile im RAM
13
Cassandra Architektur
column1 column2
row-key-1 x
row-key-2 y
Theoretische Grundlagen: Big Table Paper
• Quelle: Google (November 2006)
• Problem: Skalierung von massiven Datenmengen (PB)
• Lösung: • Einfaches Datenmodell: row-key—> columns (keine Relationen)
• Logische Strukturierung in ColumnFamilies (analog SQL: Table)
• Persistenz: n * SSTable / ColumnFamily
• Caching pro ColumnFamily:
• Scan Cache: Index über Spalten in SSTable
• Block Cache: Ganze Zeile im RAM
13
Cassandra Architektur
column1 column2
row-key-1 x
row-key-2 y
Theoretische Grundlagen: Big Table Paper
RAM
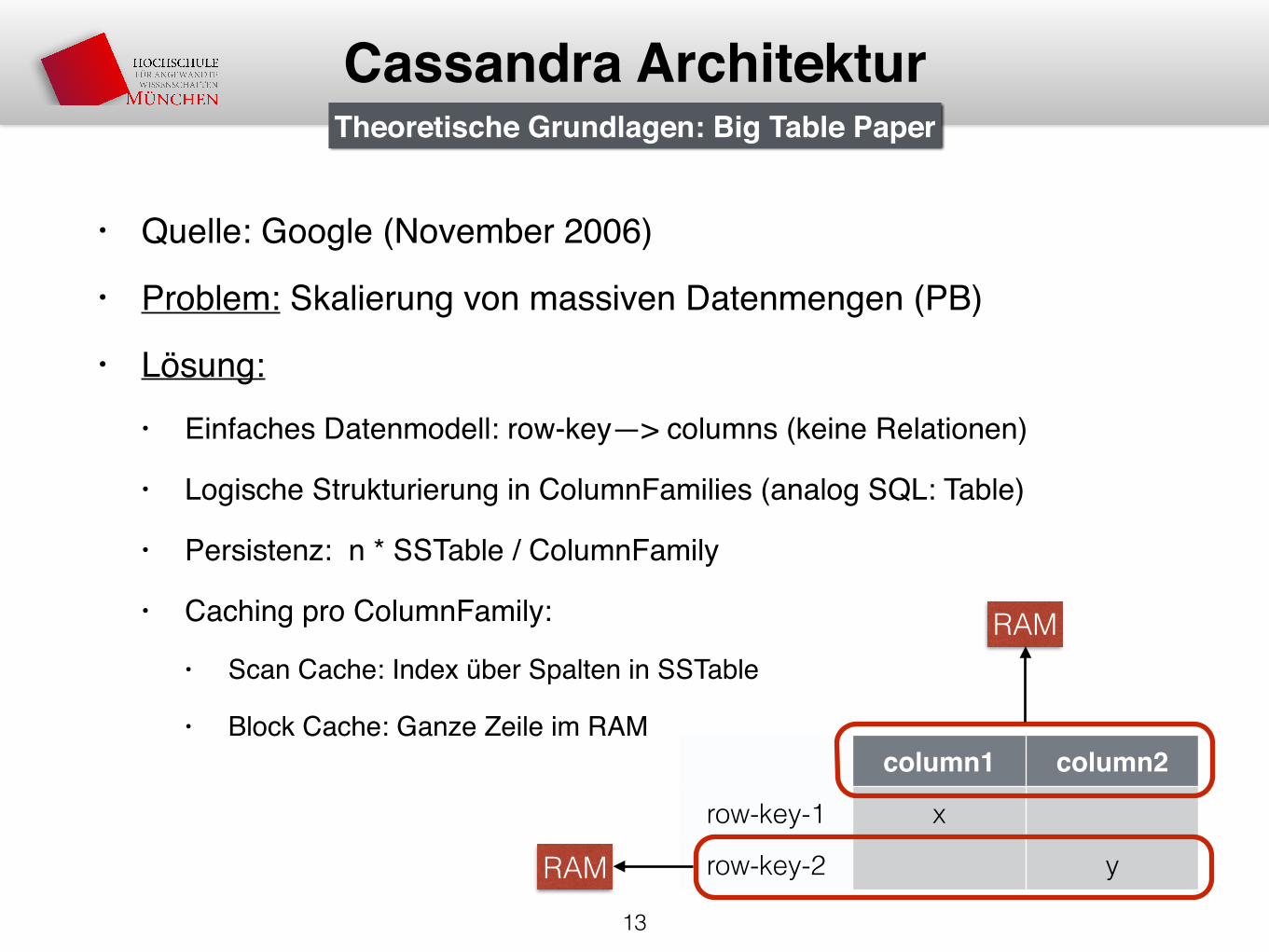
• Quelle: Google (November 2006)
• Problem: Skalierung von massiven Datenmengen (PB)
• Lösung: • Einfaches Datenmodell: row-key—> columns (keine Relationen)
• Logische Strukturierung in ColumnFamilies (analog SQL: Table)
• Persistenz: n * SSTable / ColumnFamily
• Caching pro ColumnFamily:
• Scan Cache: Index über Spalten in SSTable
• Block Cache: Ganze Zeile im RAM
13
Cassandra Architektur
column1 column2
row-key-1 x
row-key-2 y
Theoretische Grundlagen: Big Table Paper
RAM
RAM
14
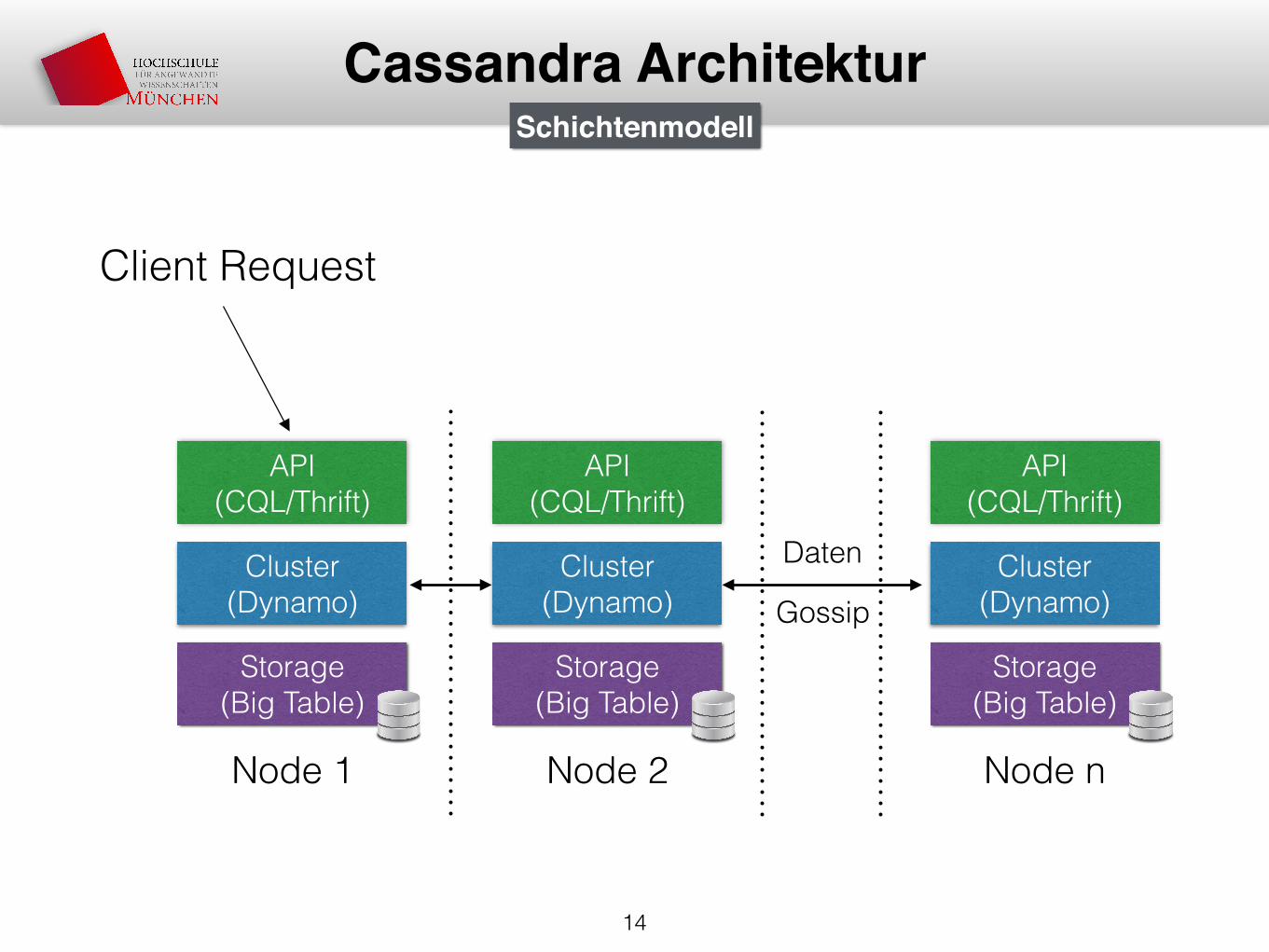
Cassandra Architektur
API (CQL/Thrift)
Cluster (Dynamo)
Storage (Big Table)
Node 1
API (CQL/Thrift)
Cluster (Dynamo)
Storage (Big Table)
Node 2
API (CQL/Thrift)
Cluster (Dynamo)
Storage (Big Table)
Node n
Client Request
Schichtenmodell
Daten
Gossip

• Partitioner entscheiden über Platzierung auf Node• Murmur3Partitioner (MurmurHash), RandomPartitioner (MD5)
• Murmur3 Bereich: [-263, 263-1]
• Aufteilung des Bereichs in virtuelle Nodes
• Zuordnung von virtuellen Nodes zu “echten” Nodes• Node 1 —> n virtueller Node
• Verschiedene Anzahl von virtuellen Nodes möglich (Lastenverteilung)
• Erweiterung des Clusters = Minimale Daten-Neuverteilung
15
Cassandra ArchitekturConsistent Hashing und Virtual Nodes
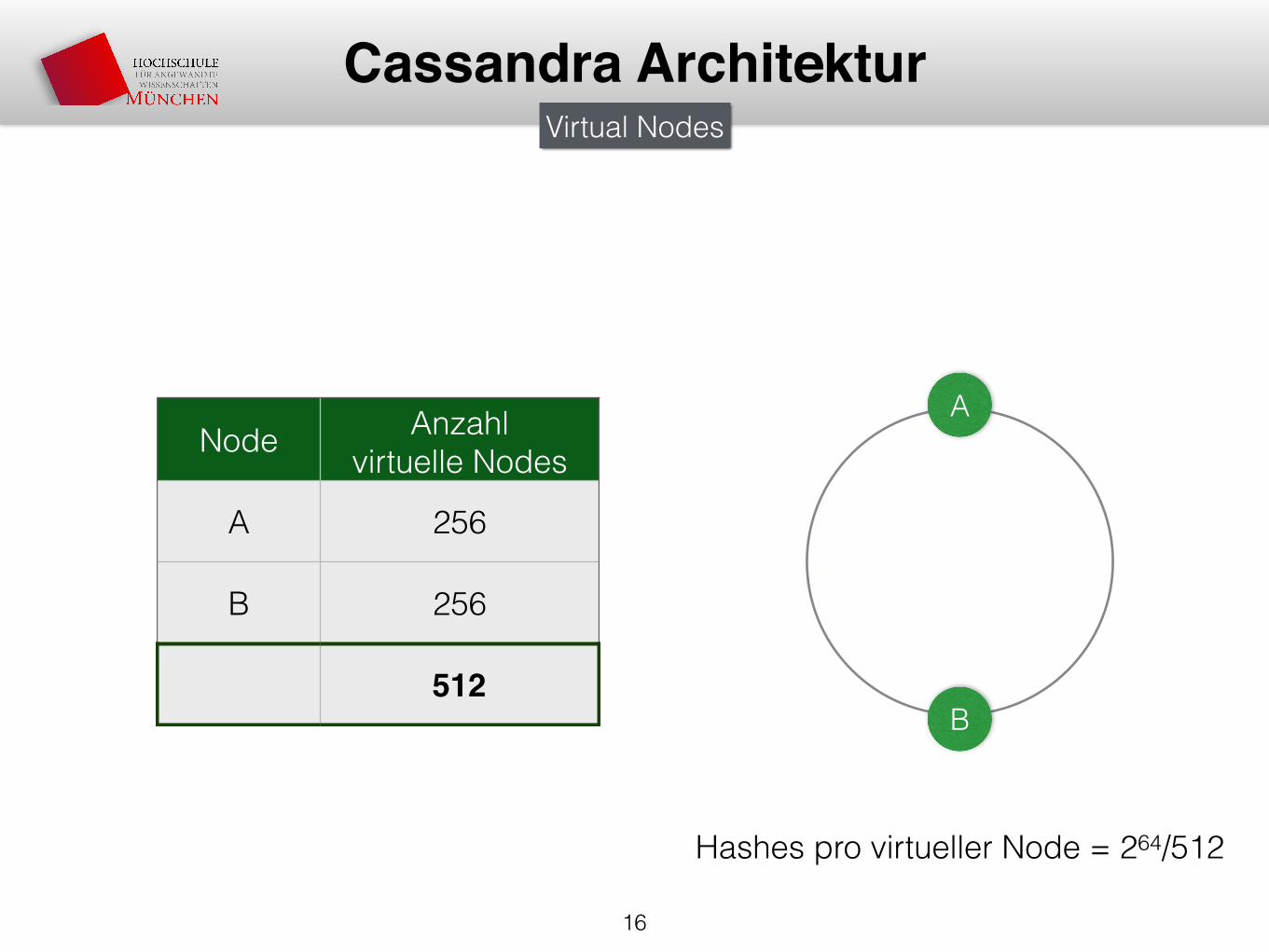
16
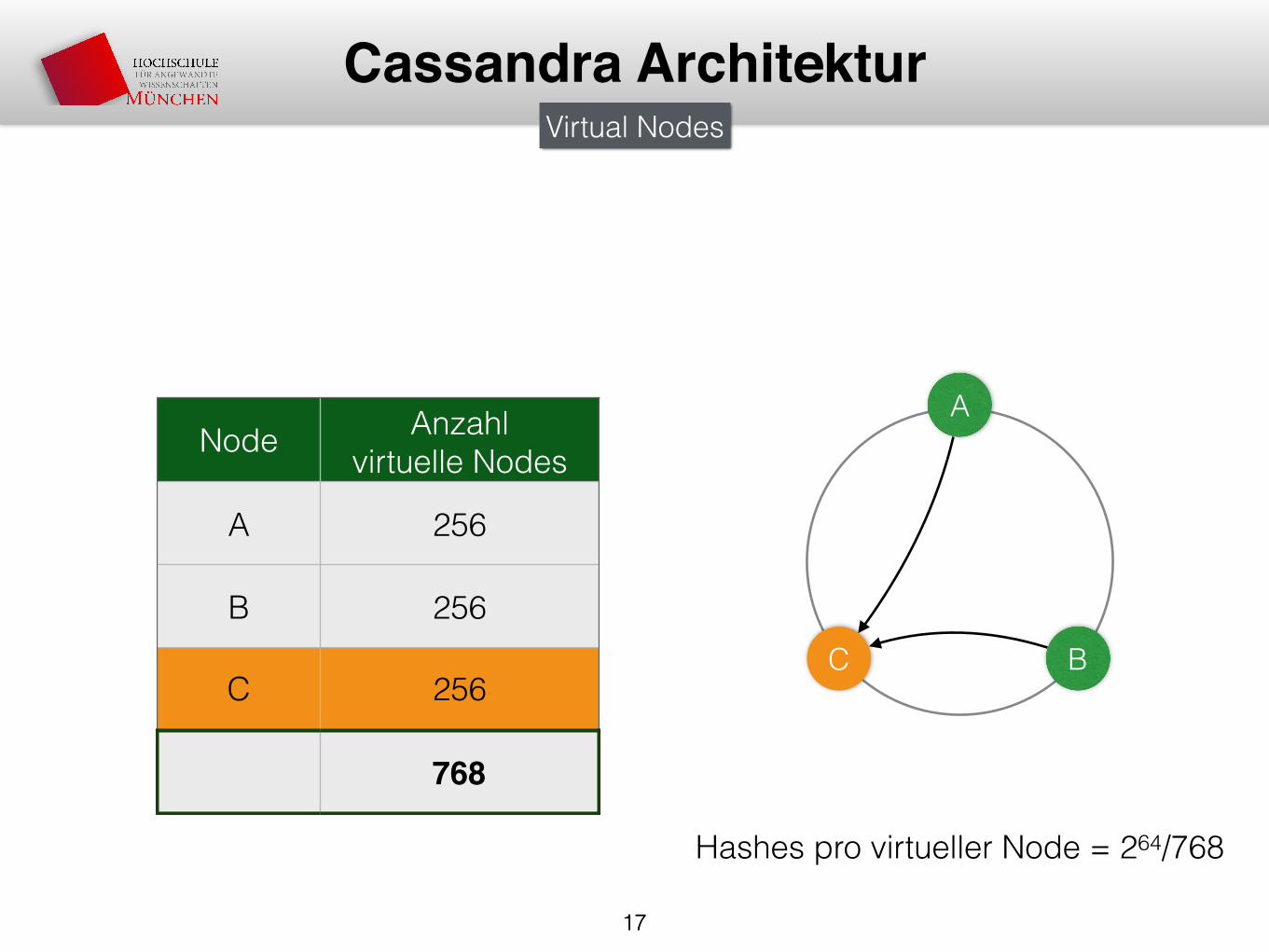
Cassandra ArchitekturVirtual Nodes
Node Anzahl virtuelle Nodes
A 256
B 256
512
A
B
Hashes pro virtueller Node = 264/512
17
Cassandra ArchitekturVirtual Nodes
17
Node Anzahl virtuelle Nodes
A 256
B 256
C 256
768
A
C
Hashes pro virtueller Node = 264/768
B
17
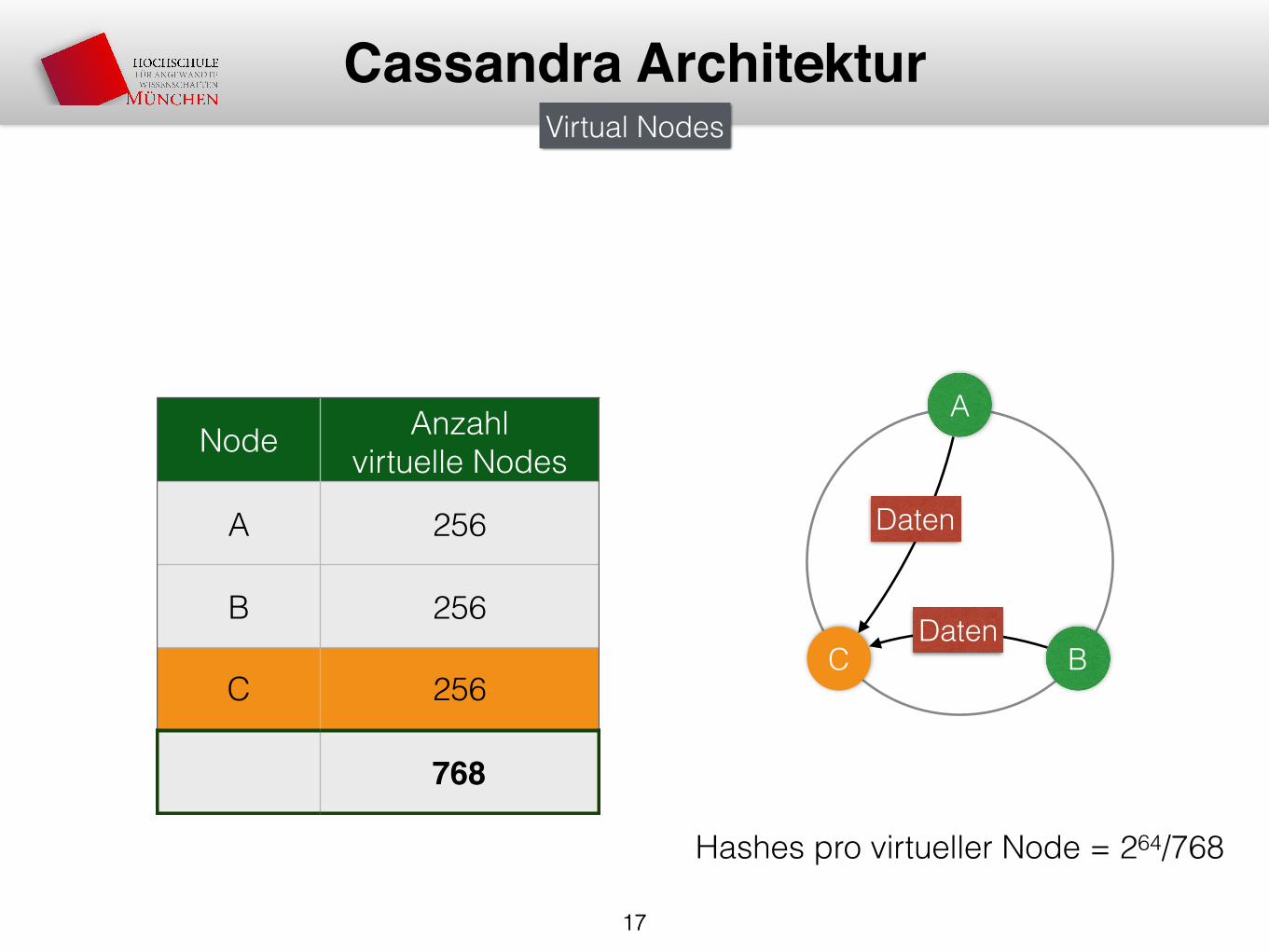
Cassandra ArchitekturVirtual Nodes
17
Node Anzahl virtuelle Nodes
A 256
B 256
C 256
768
A
C
Hashes pro virtueller Node = 264/768
B
Daten
Daten
18
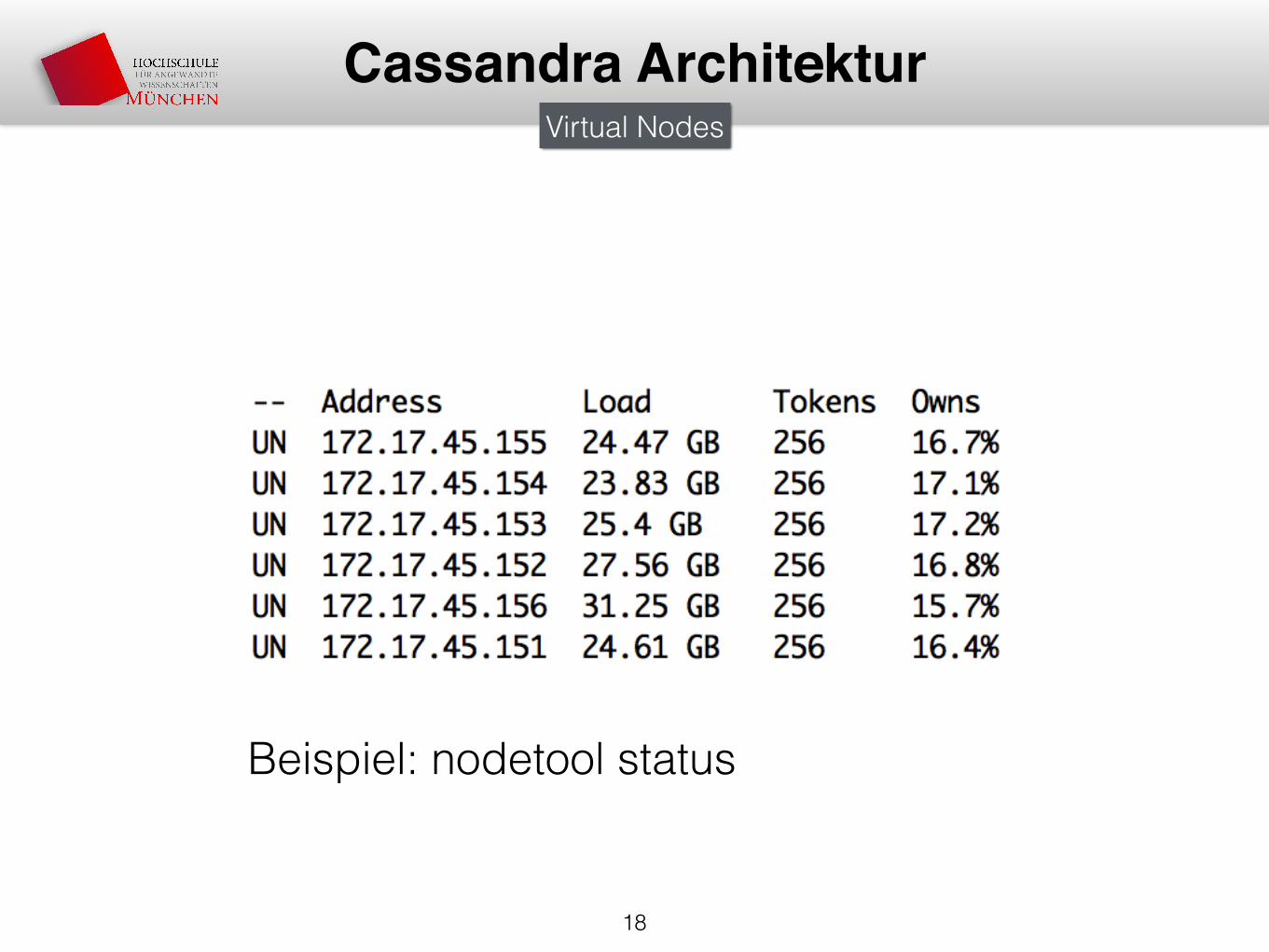
Cassandra ArchitekturVirtual Nodes
Beispiel: nodetool status
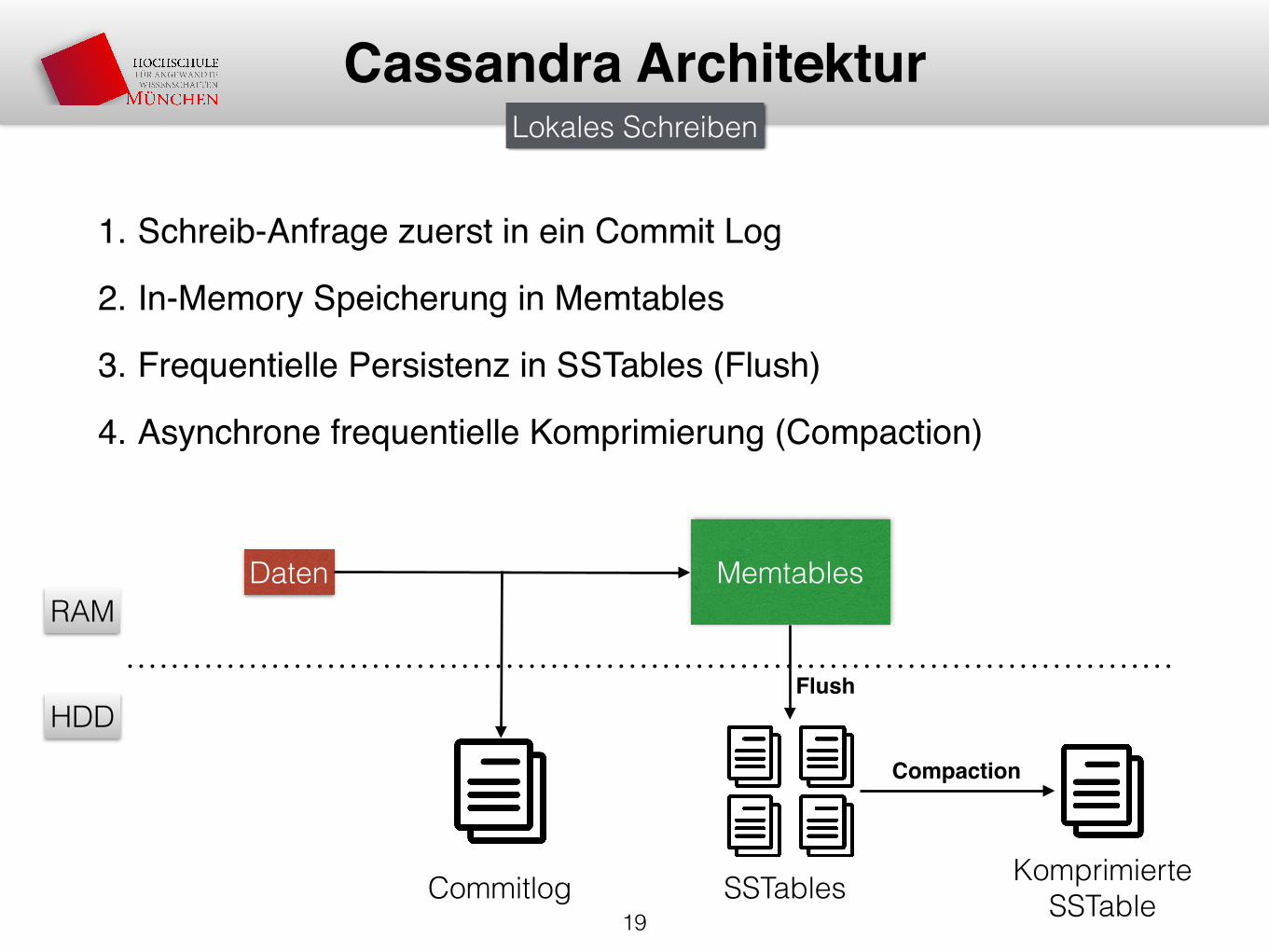
1. Schreib-Anfrage zuerst in ein Commit Log
2. In-Memory Speicherung in Memtables
3. Frequentielle Persistenz in SSTables (Flush)
4. Asynchrone frequentielle Komprimierung (Compaction)
19
Cassandra ArchitekturLokales Schreiben
RAM
HDD
Daten
Commitlog
Memtables
SSTables
Flush
Komprimierte SSTable
Compaction

• Apache Cassandra
• Cassandra Architektur
• Daten-Replikation• Konsistenz
• Sicherheit
• Demo: Daten Modellierung mit CQL
20
Agenda

• Design: Festplatten werden ausfallen
• Lösung: Replication Factor (RF = N) pro Keyspace
• Strategien bestimmen Ort der Kopien (Replica Set)
• SimpleStrategy: • Einfache Verteilung von N-1 Kopien auf die nächsten Nodes im Ring
• NetworkTopologyStrategy: • Zuordnung der Nodes zu Datacenter (DC) und Rack
• Verteilung von N-1 Kopien unter Beachtung der Netzwerk Topology
• Vermeidung der Speicherung von Kopien im selben Rack
• Verteilung der Kopien auf weitere Datencenter
21
Daten-ReplikationÜbersicht
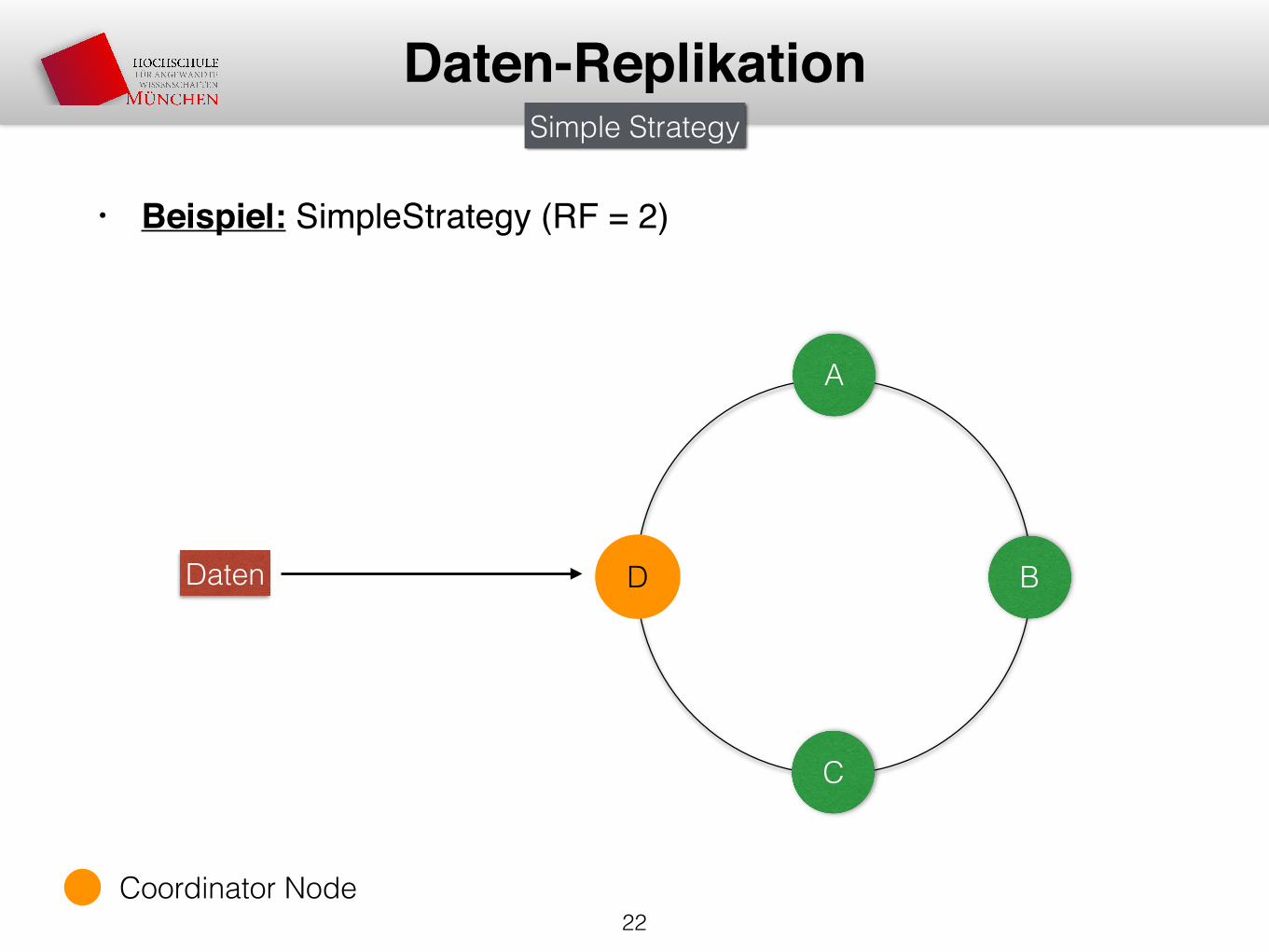
• Beispiel: SimpleStrategy (RF = 2)
22
Daten-Replikation
A
D B
C
Daten
Simple Strategy
Coordinator Node
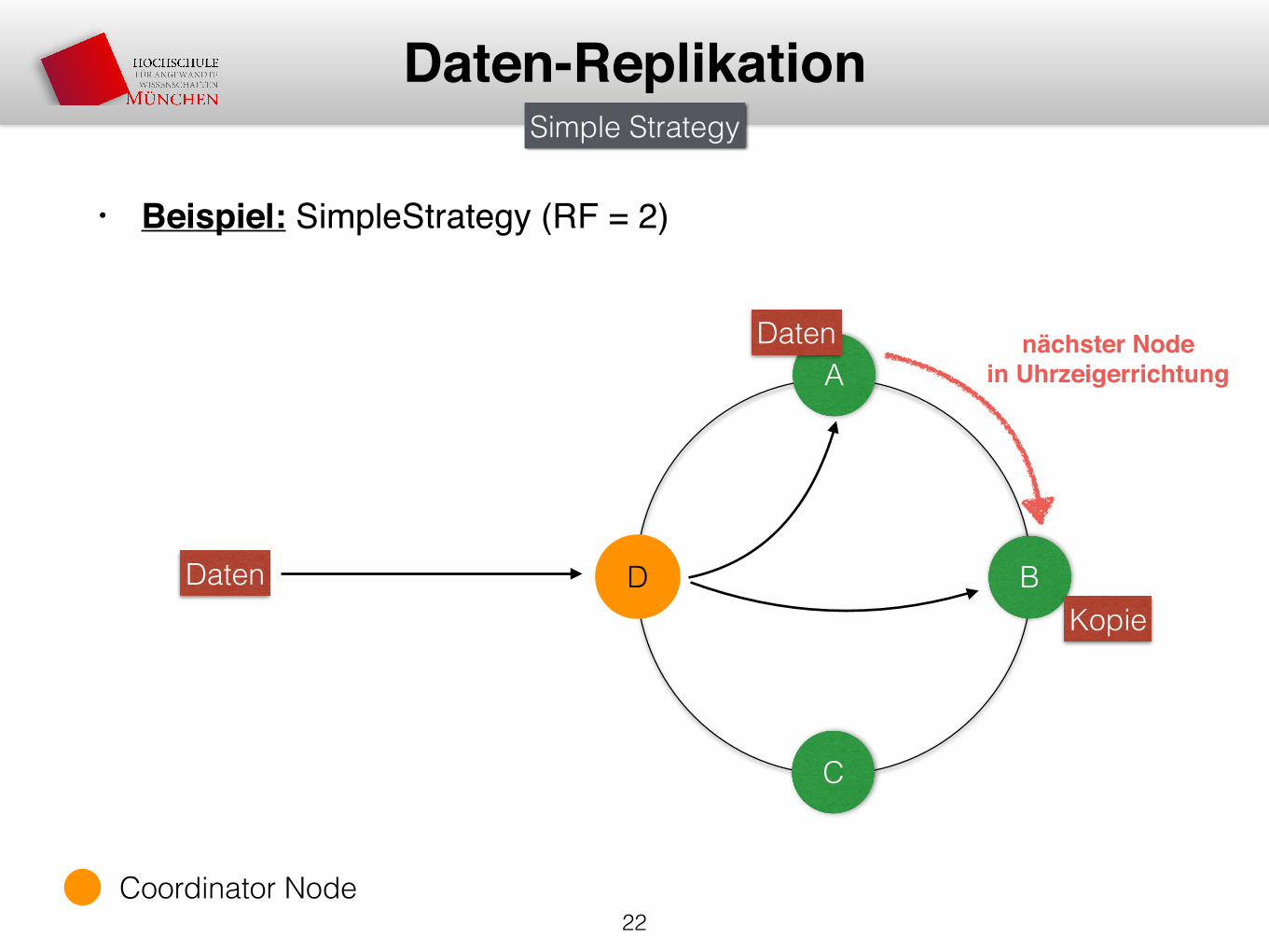
• Beispiel: SimpleStrategy (RF = 2)
22
Daten-Replikation
A
D B
C
Daten
Daten
Kopie
nächster Node in Uhrzeigerrichtung
Simple Strategy
Coordinator Node
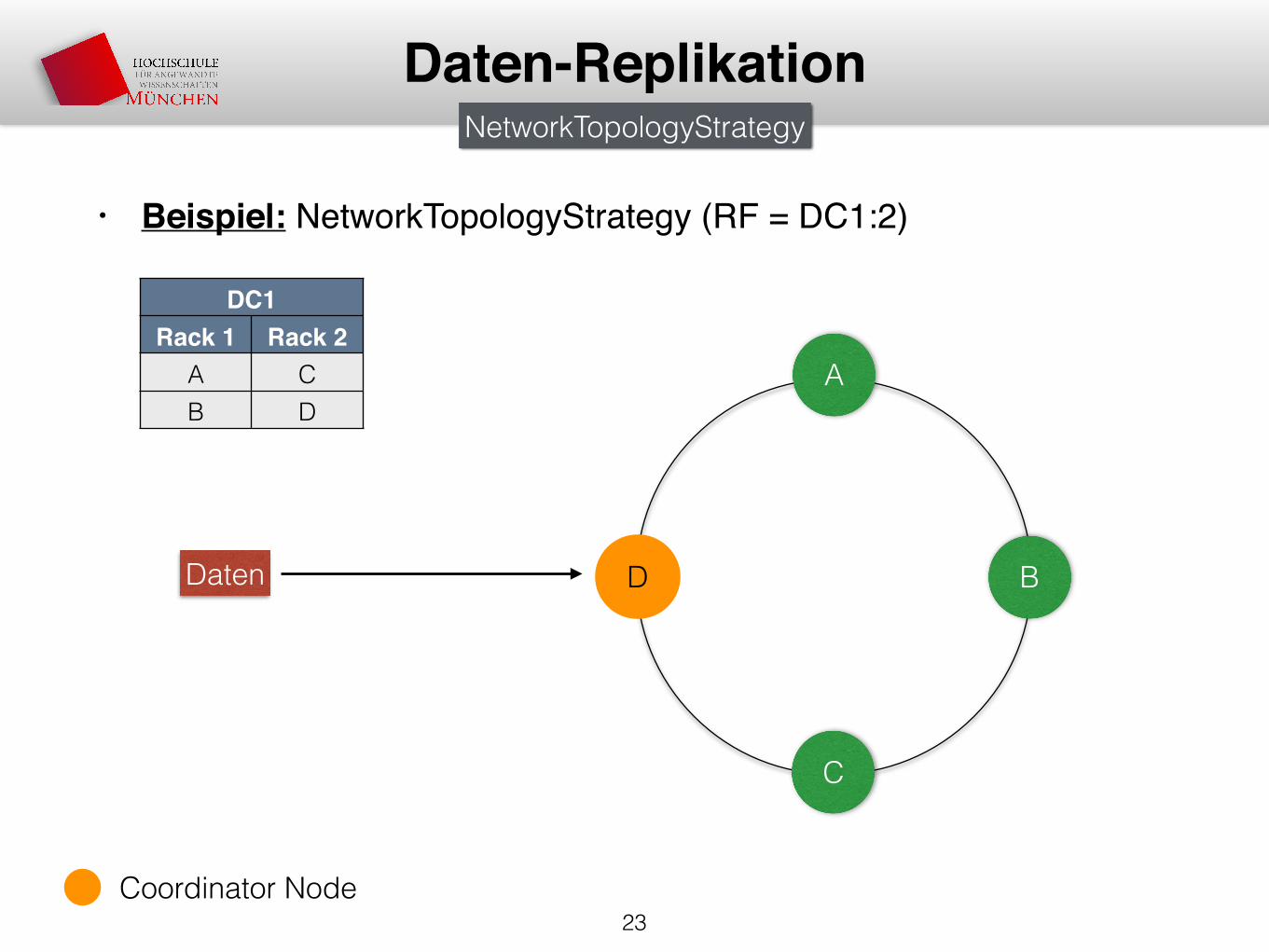
• Beispiel: NetworkTopologyStrategy (RF = DC1:2)
23
Daten-Replikation
A
D B
C
Daten
DC1Rack 1 Rack 2
A CB D
NetworkTopologyStrategy
Coordinator Node
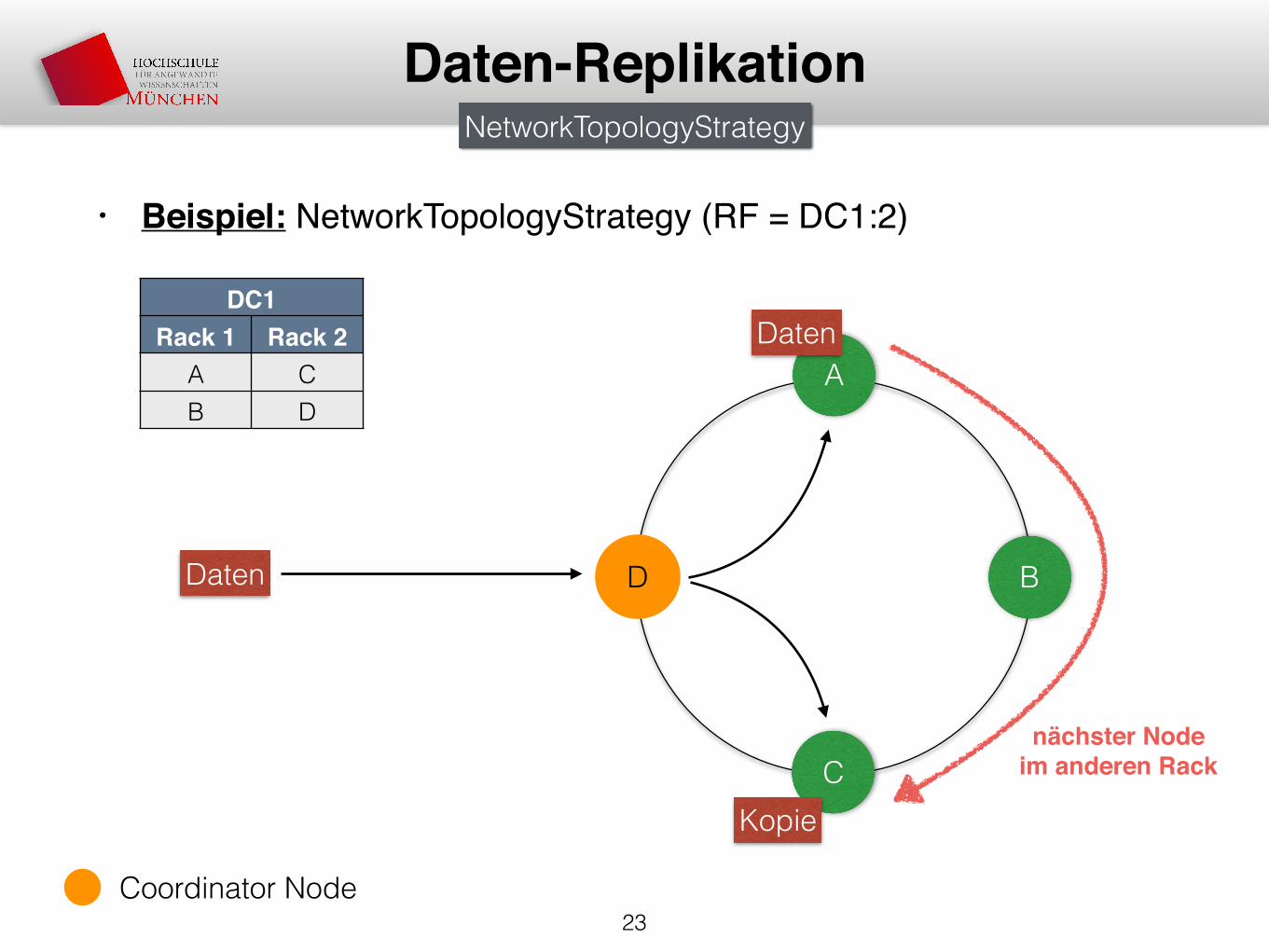
• Beispiel: NetworkTopologyStrategy (RF = DC1:2)
23
Daten-Replikation
A
D B
C
Daten
Daten
Kopie
DC1Rack 1 Rack 2
A CB D
nächster Node im anderen Rack
NetworkTopologyStrategy
Coordinator Node
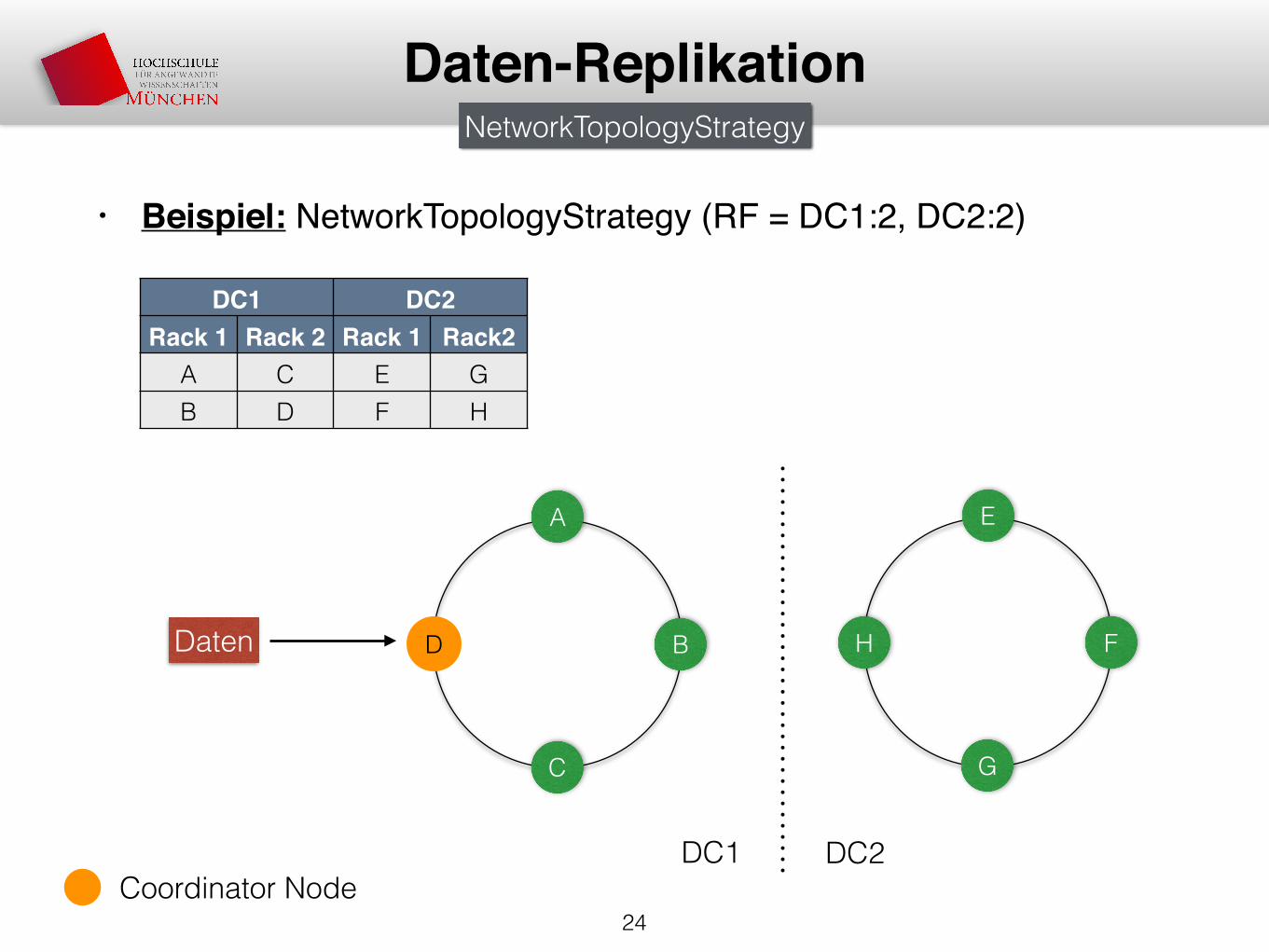
• Beispiel: NetworkTopologyStrategy (RF = DC1:2, DC2:2)
24
Daten-Replikation
Daten
A
D B
C
DC1 DC2Rack 1 Rack 2 Rack 1 Rack2
A C E GB D F H
NetworkTopologyStrategy
E
H F
G
DC1 DC2Coordinator Node
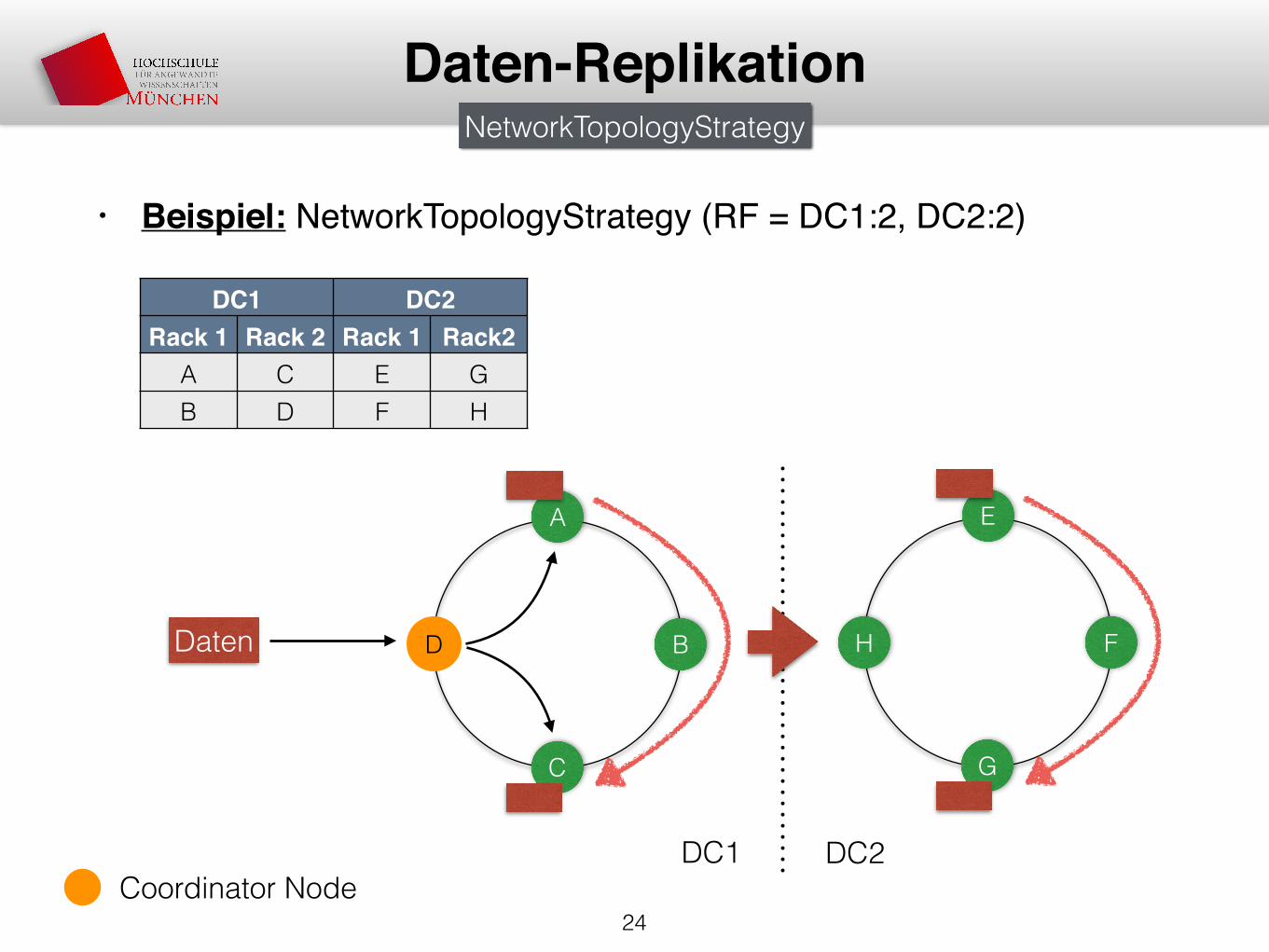
• Beispiel: NetworkTopologyStrategy (RF = DC1:2, DC2:2)
24
Daten-Replikation
Daten
A
D B
C
DC1 DC2Rack 1 Rack 2 Rack 1 Rack2
A C E GB D F H
NetworkTopologyStrategy
E
H F
G
DC1 DC2Coordinator Node
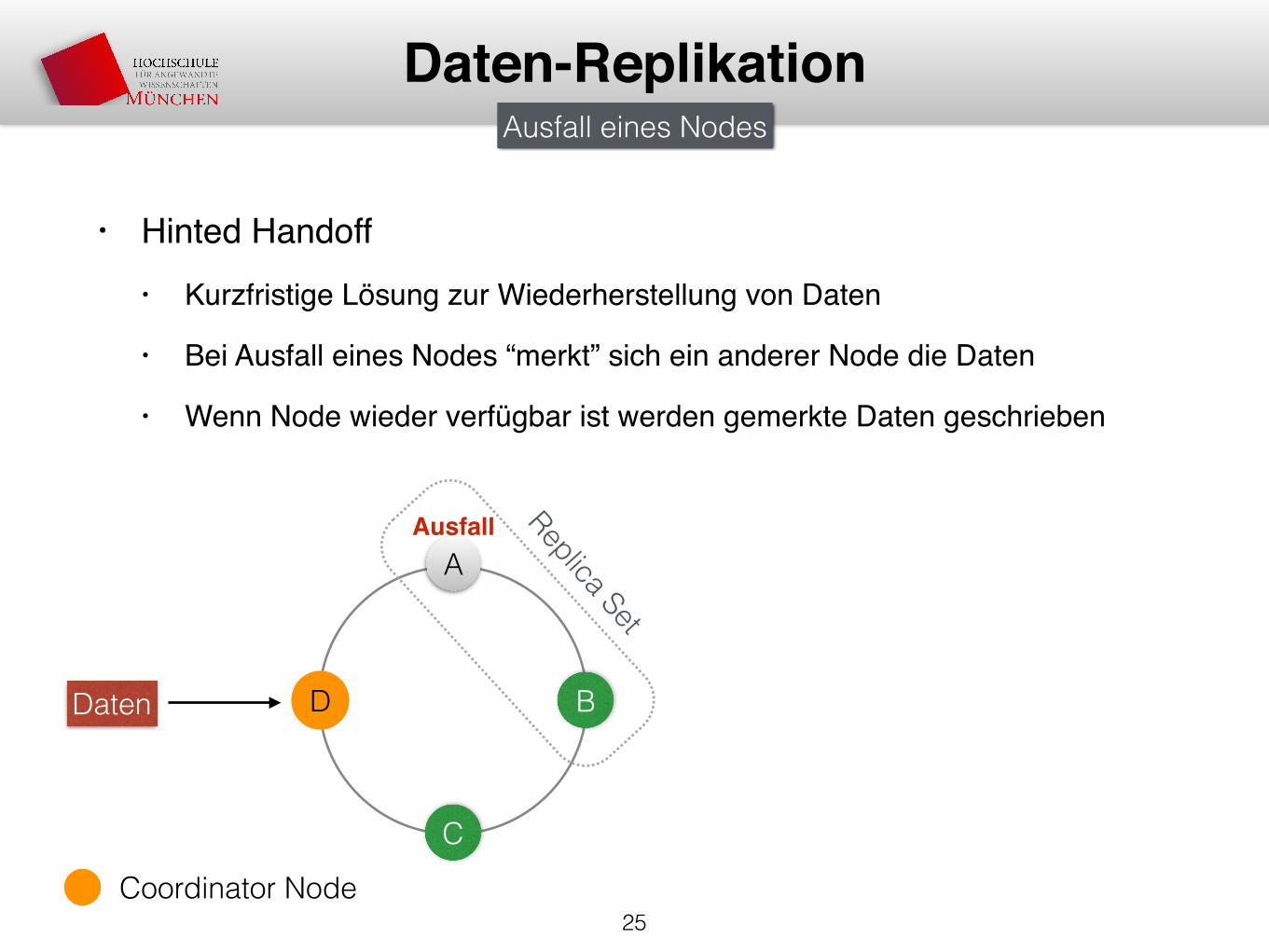
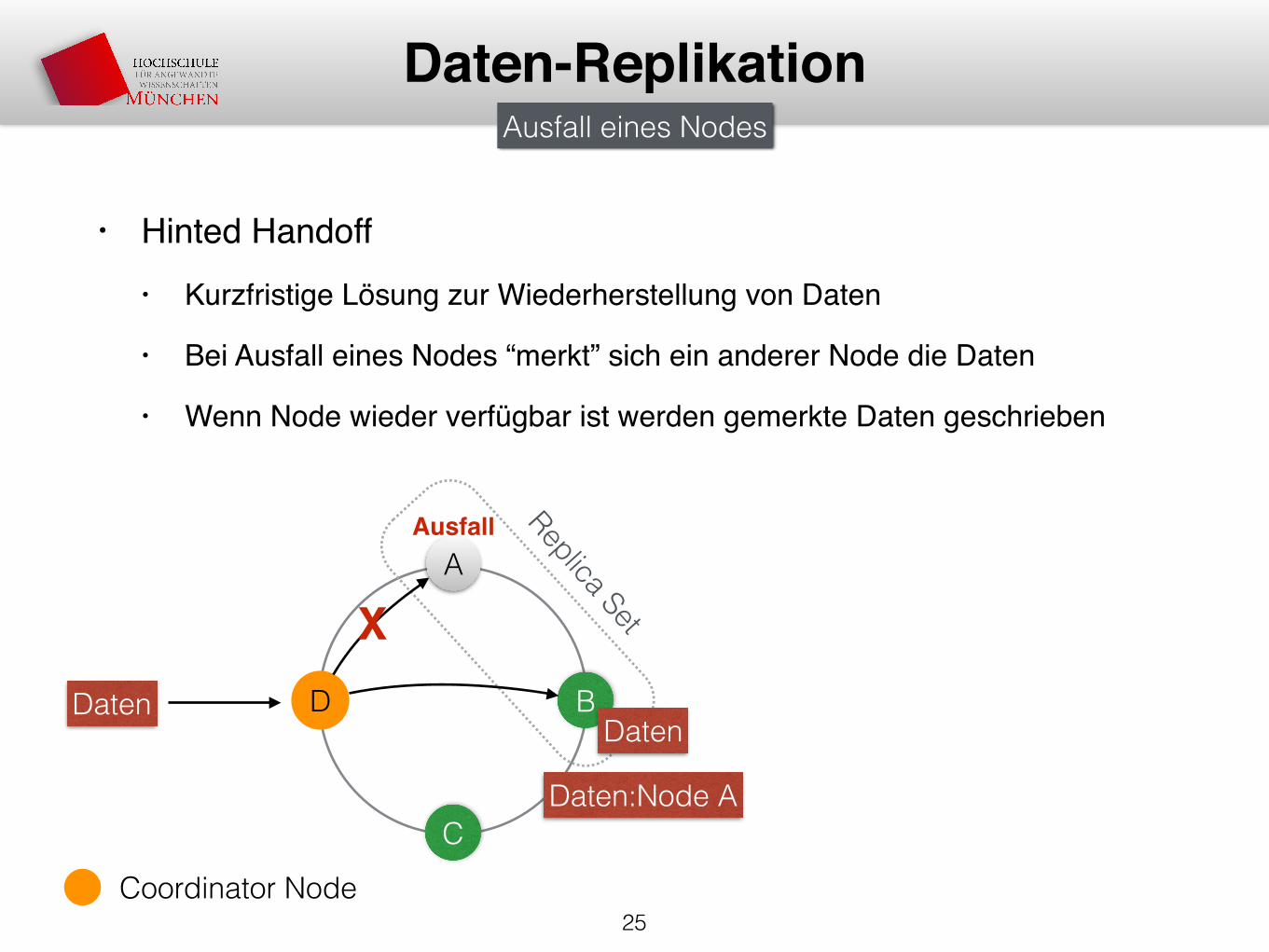
• Hinted Handoff• Kurzfristige Lösung zur Wiederherstellung von Daten
• Bei Ausfall eines Nodes “merkt” sich ein anderer Node die Daten
• Wenn Node wieder verfügbar ist werden gemerkte Daten geschrieben
25
Daten-Replikation
Daten
A
D B
C
Ausfall Replica Set
Ausfall eines Nodes
Coordinator Node
• Hinted Handoff• Kurzfristige Lösung zur Wiederherstellung von Daten
• Bei Ausfall eines Nodes “merkt” sich ein anderer Node die Daten
• Wenn Node wieder verfügbar ist werden gemerkte Daten geschrieben
25
Daten-Replikation
Daten
A
D B
C
Ausfall Replica Set
Daten
Daten:Node A
Ausfall eines Nodes
Coordinator Node
X
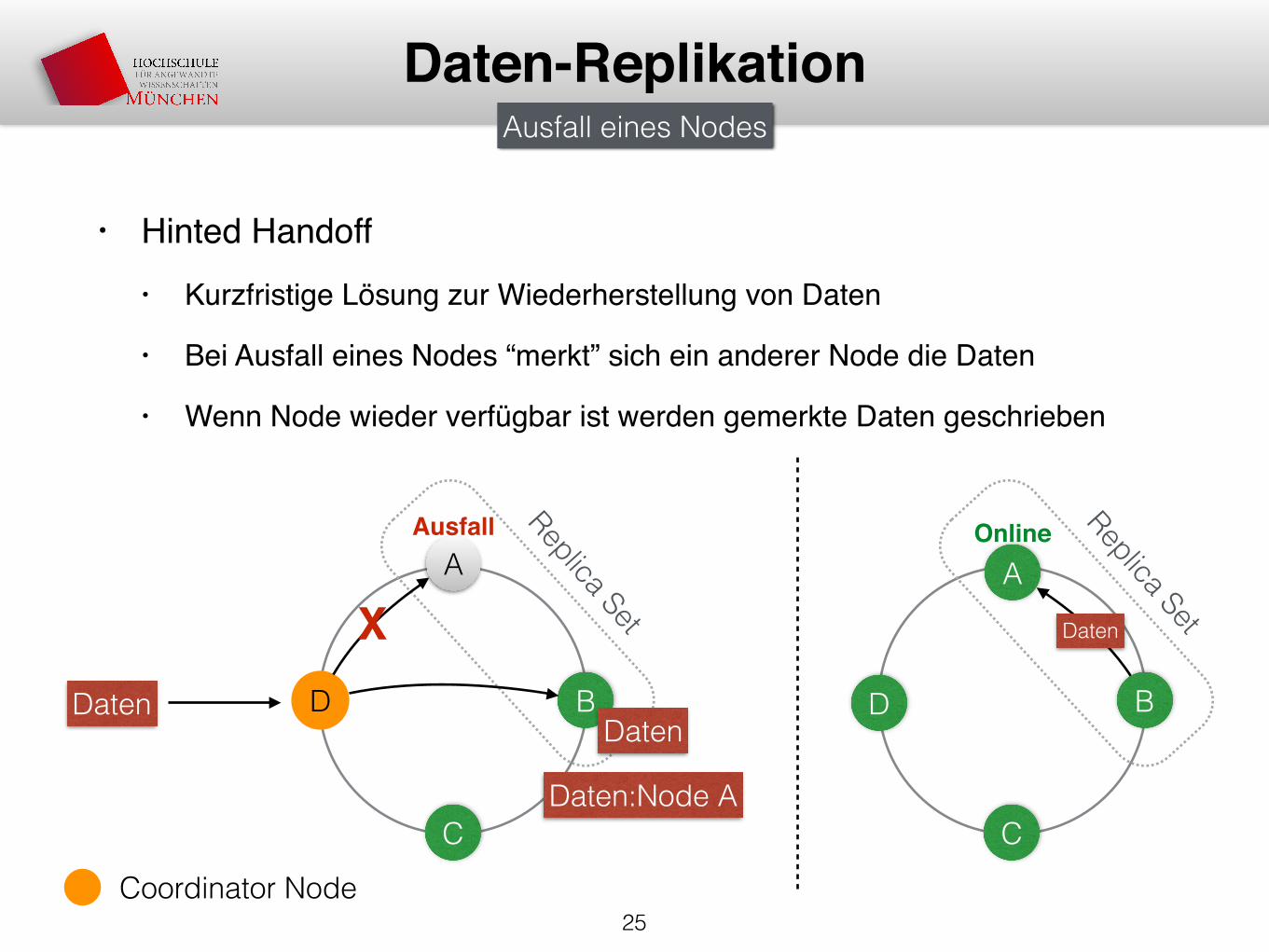
• Hinted Handoff• Kurzfristige Lösung zur Wiederherstellung von Daten
• Bei Ausfall eines Nodes “merkt” sich ein anderer Node die Daten
• Wenn Node wieder verfügbar ist werden gemerkte Daten geschrieben
25
Daten-Replikation
Daten
A
D B
C
Ausfall Replica Set
Daten
Daten:Node A
Online
B
C
Replica Set
A
D
Ausfall eines Nodes
Coordinator Node
X Daten
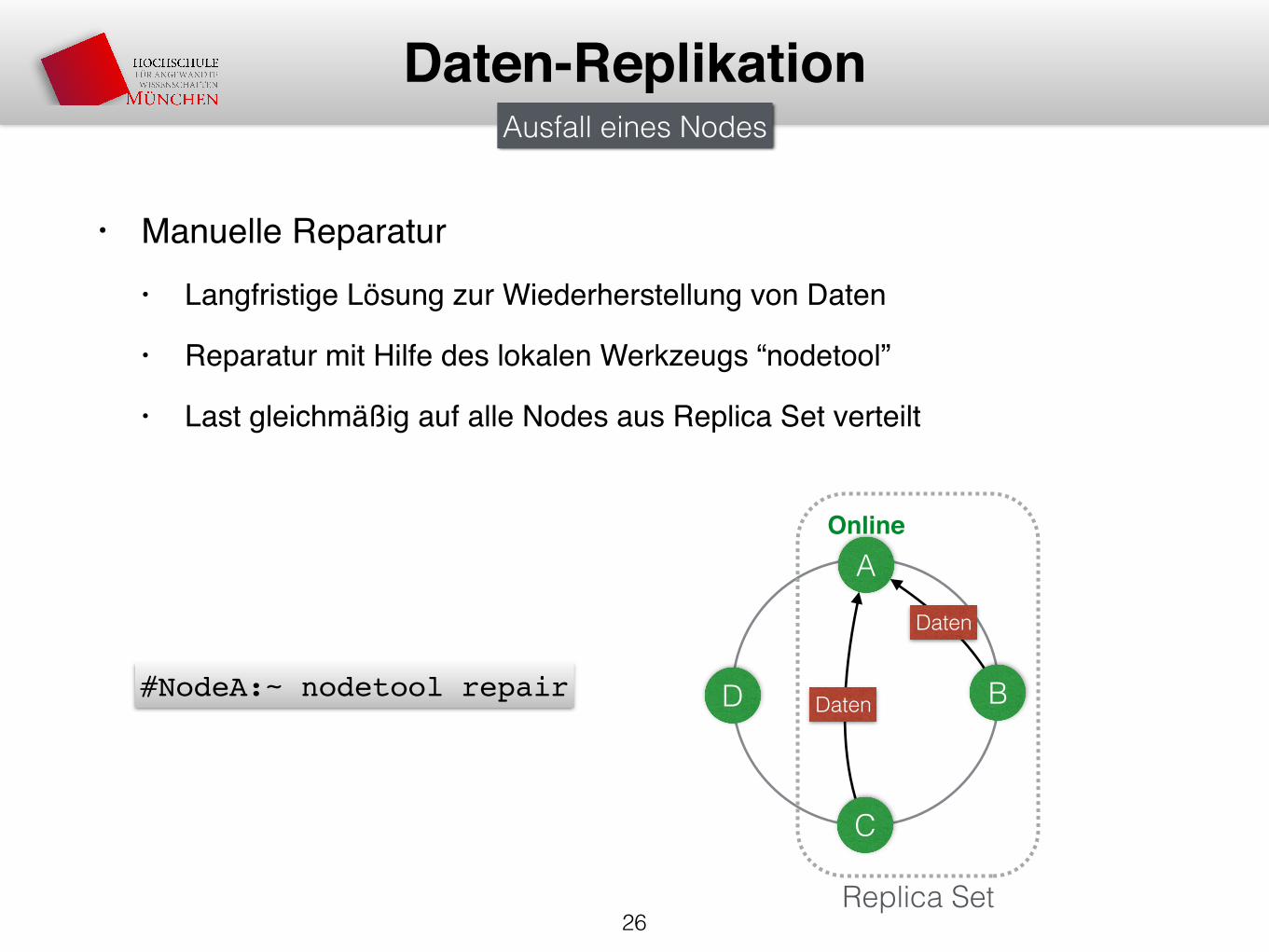
• Manuelle Reparatur• Langfristige Lösung zur Wiederherstellung von Daten
• Reparatur mit Hilfe des lokalen Werkzeugs “nodetool”
• Last gleichmäßig auf alle Nodes aus Replica Set verteilt
26
Daten-Replikation
B
C
Replica Set
AOnline
Daten
D
Ausfall eines Nodes
#NodeA:~ nodetool repairDaten

• Apache Cassandra
• Cassandra Architektur
• Daten-Replikation
• Konsistenz• Sicherheit
• Demo: Daten Modellierung mit CQL
27
Agenda

• Konzept: Eventuell Konsistent (Eventual Consistency)
• Konfigurierbare Anforderungen an Konsistenz pro Request• Lesen, Schreiben (Updaten, Löschen)
• Lesen: Anzahl der Nodes die kontaktiert werden
• Schreiben: Anzahl der Nodes bei dehnen Schreiben erfolgreich
28
KonsistenzÜbersicht
Level Erläuterung
ALL Alle Nodes aus einem Replica Set müssen antworten
QUORUM Die Mehrheit der Nodes aus einem Replica Set müssen
antwortenONE Mindestens ein Node aus einem
Replica Set muss antworten
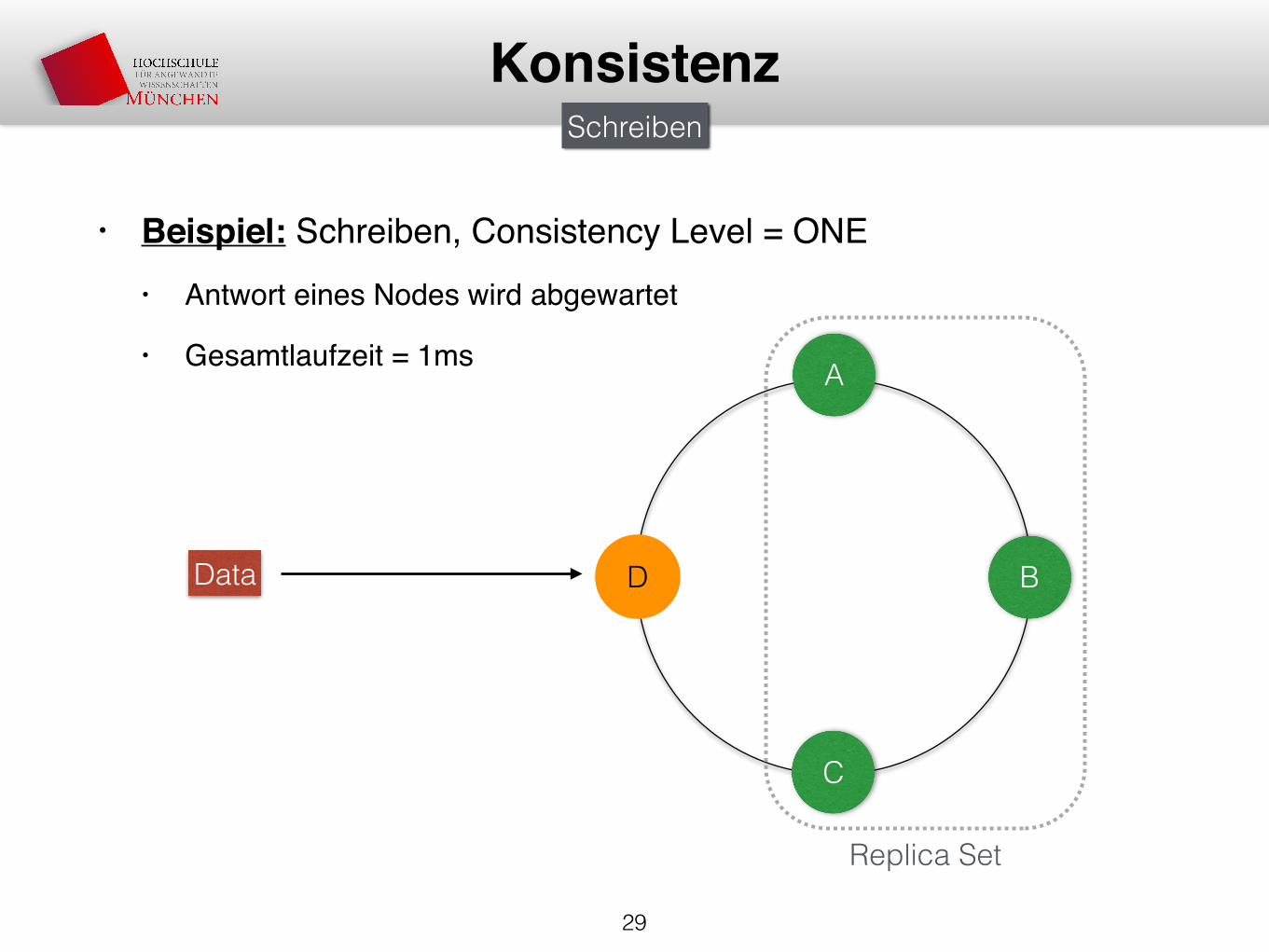
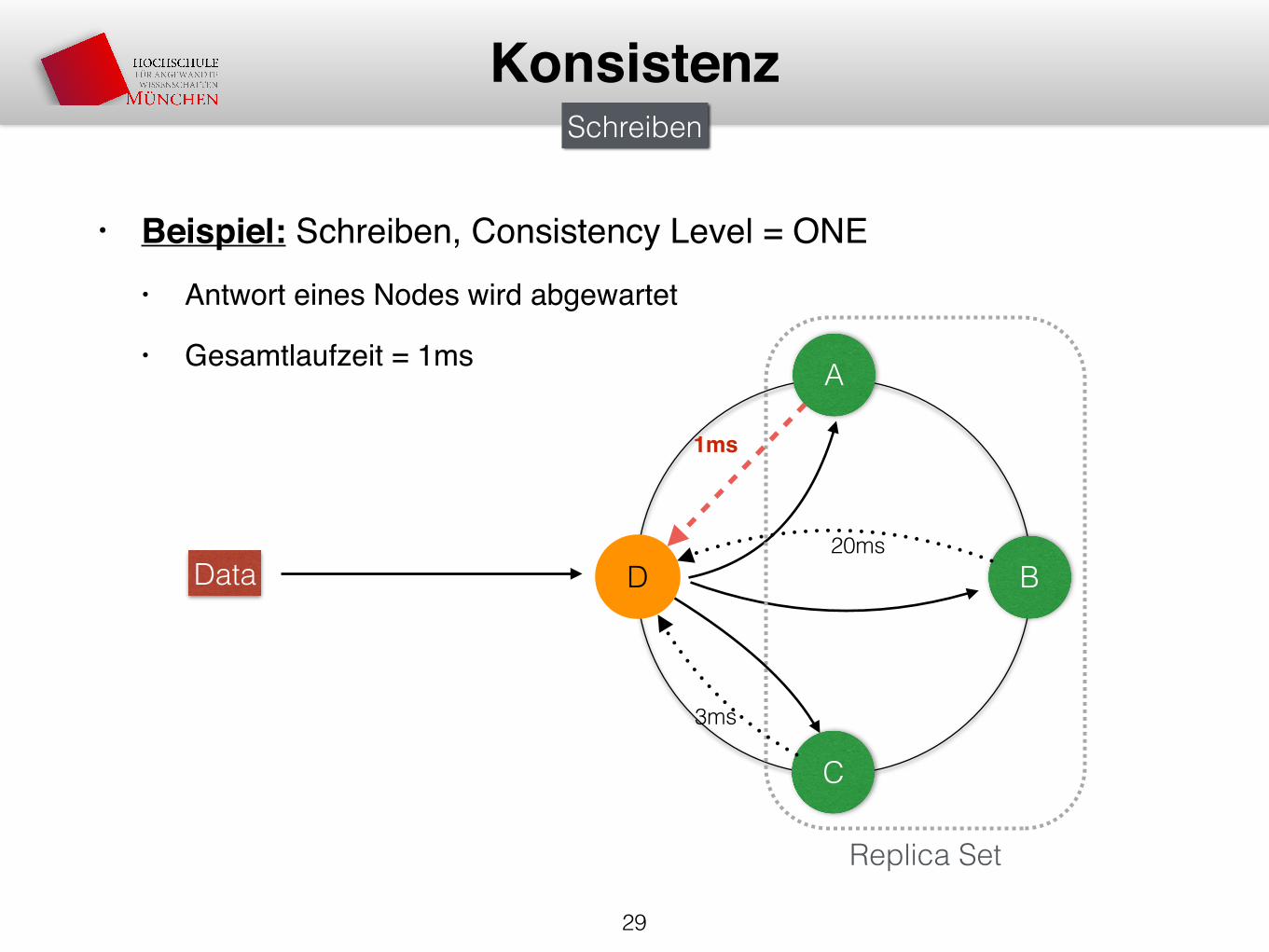
• Beispiel: Schreiben, Consistency Level = ONE• Antwort eines Nodes wird abgewartet
• Gesamtlaufzeit = 1ms
29
KonsistenzSchreiben
A
D B
C
Data
Replica Set
• Beispiel: Schreiben, Consistency Level = ONE• Antwort eines Nodes wird abgewartet
• Gesamtlaufzeit = 1ms
29
KonsistenzSchreiben
A
D B
C
Data
Replica Set
• Beispiel: Schreiben, Consistency Level = ONE• Antwort eines Nodes wird abgewartet
• Gesamtlaufzeit = 1ms
29
KonsistenzSchreiben
A
D B
C
Data
Replica Set
1ms
20ms
3ms
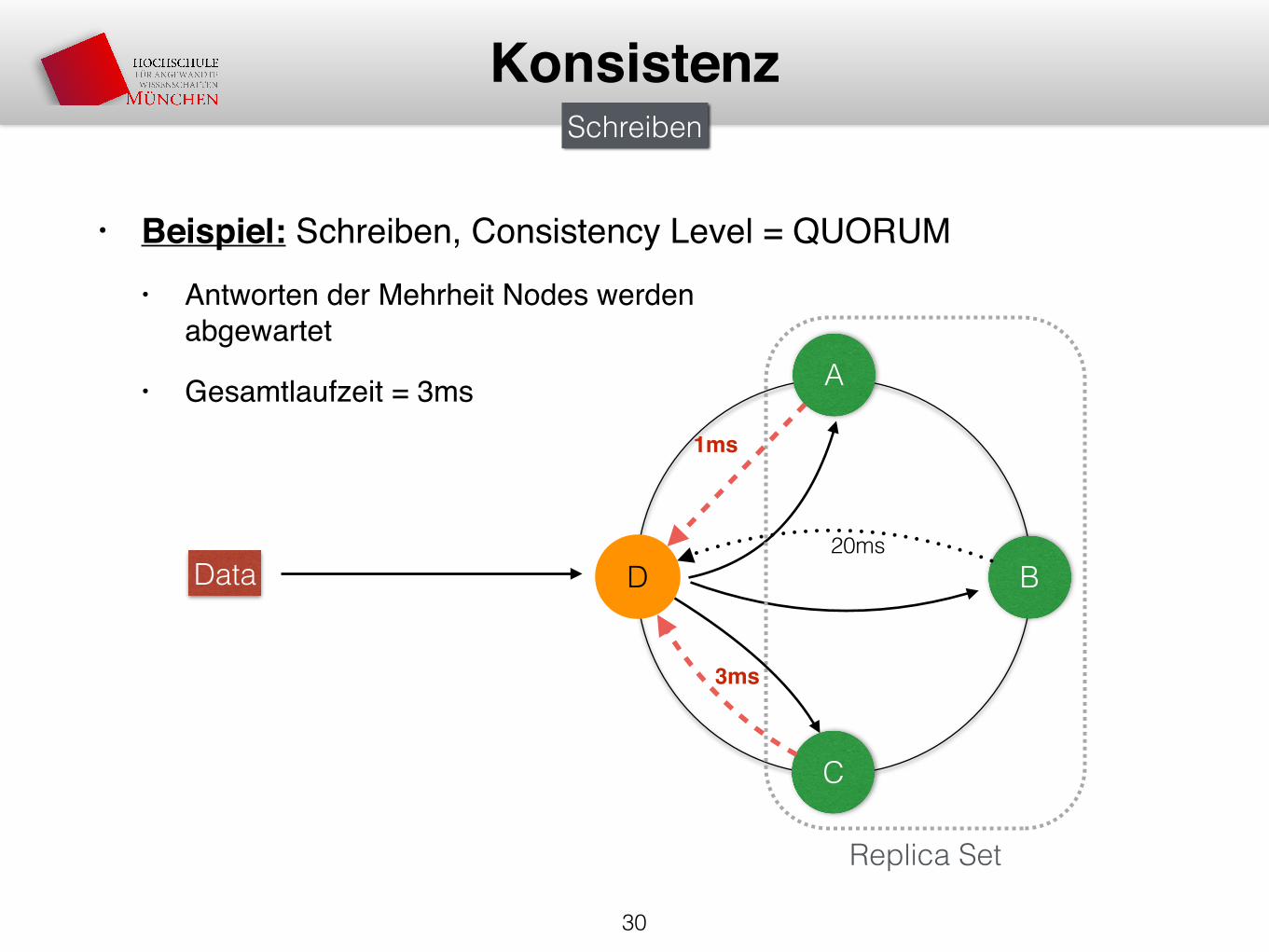
• Beispiel: Schreiben, Consistency Level = QUORUM• Antworten der Mehrheit Nodes werden
abgewartet
• Gesamtlaufzeit = 3ms
30
KonsistenzSchreiben
A
D B
C
Data
Replica Set
• Beispiel: Schreiben, Consistency Level = QUORUM• Antworten der Mehrheit Nodes werden
abgewartet
• Gesamtlaufzeit = 3ms
30
KonsistenzSchreiben
A
D B
C
Data
Replica Set
• Beispiel: Schreiben, Consistency Level = QUORUM• Antworten der Mehrheit Nodes werden
abgewartet
• Gesamtlaufzeit = 3ms
30
KonsistenzSchreiben
A
D B
C
Data
Replica Set
1ms
20ms
3ms
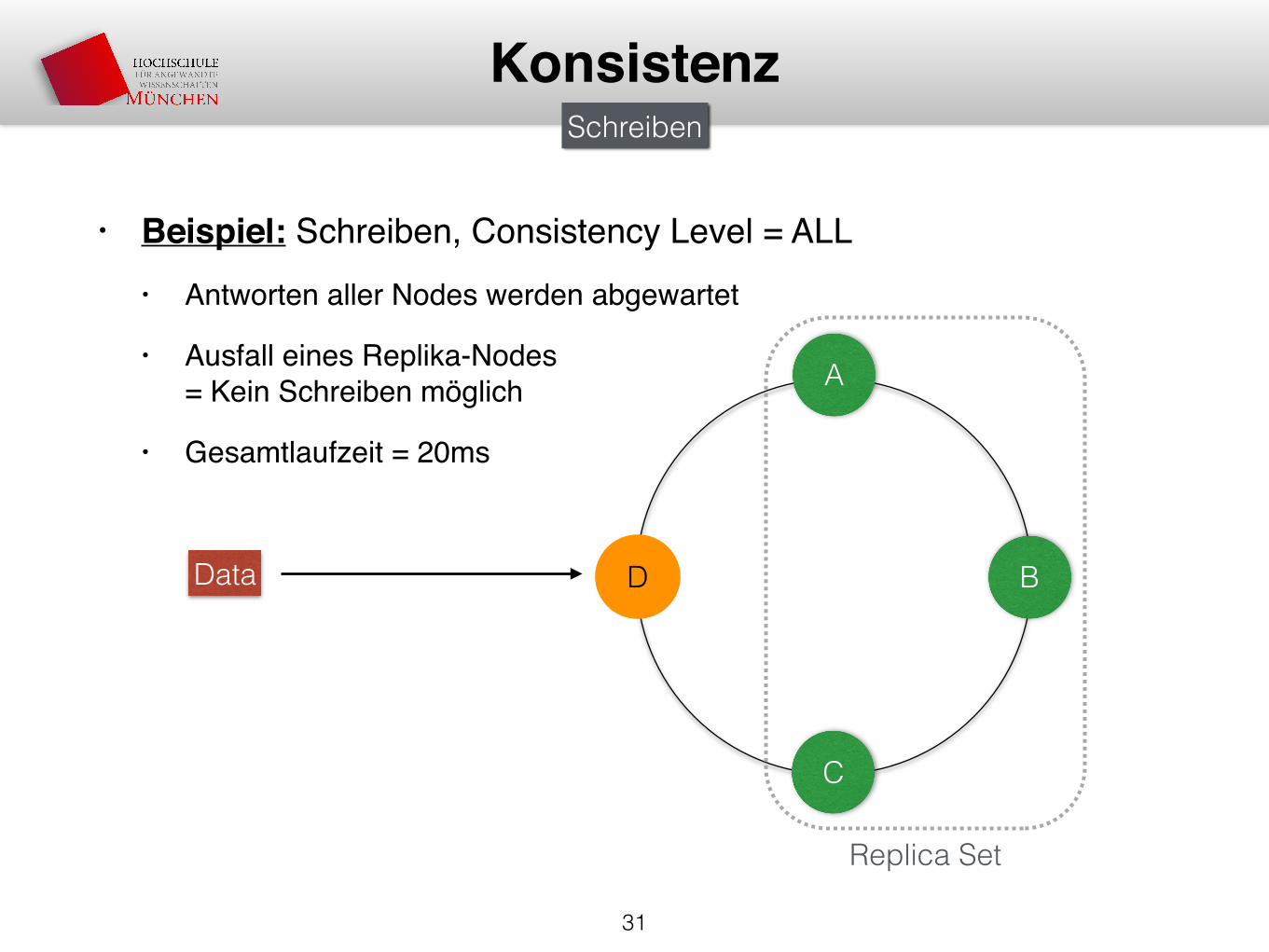
• Beispiel: Schreiben, Consistency Level = ALL• Antworten aller Nodes werden abgewartet
• Ausfall eines Replika-Nodes= Kein Schreiben möglich
• Gesamtlaufzeit = 20ms
31
KonsistenzSchreiben
A
D B
C
Data
Replica Set
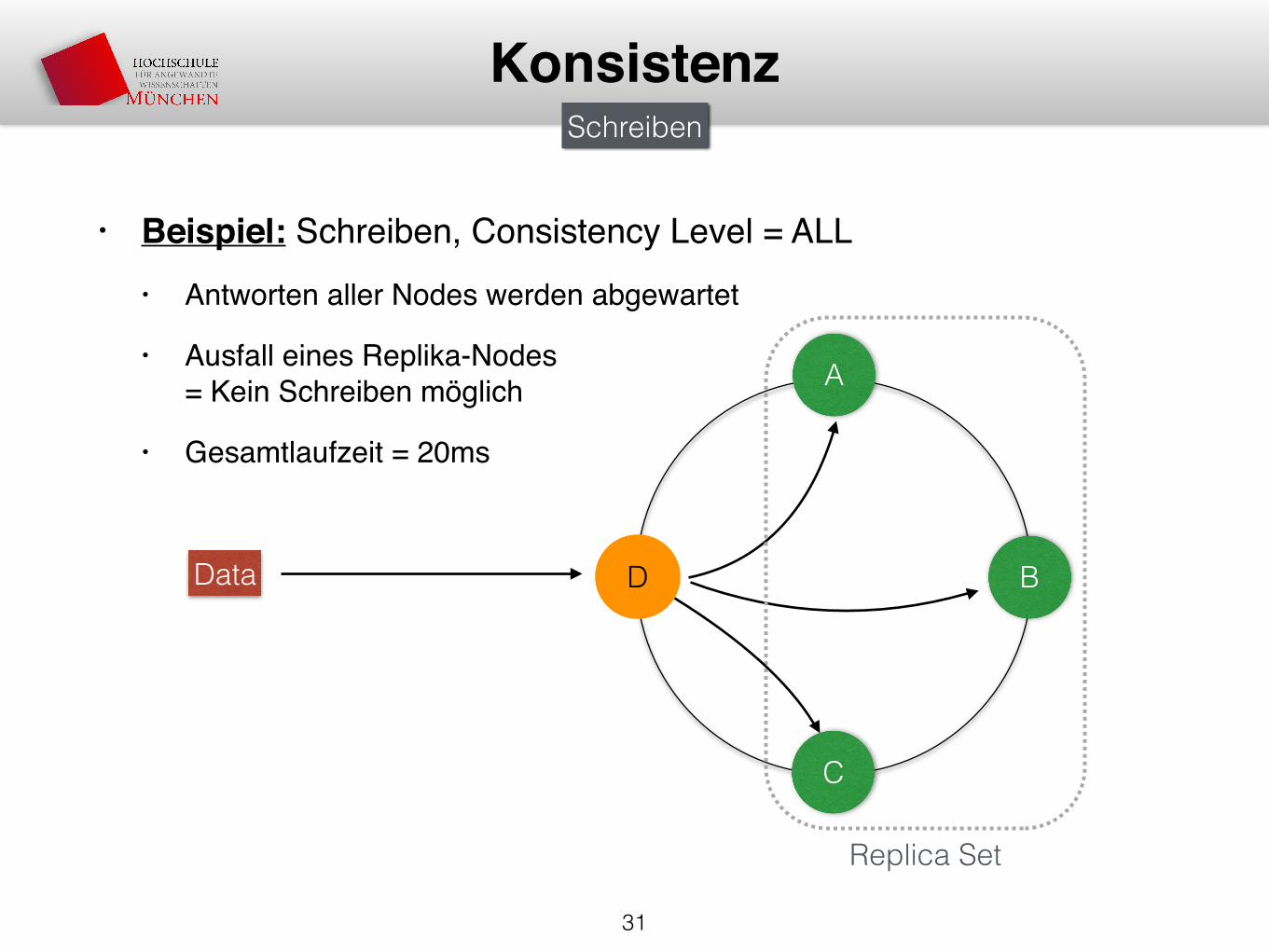
• Beispiel: Schreiben, Consistency Level = ALL• Antworten aller Nodes werden abgewartet
• Ausfall eines Replika-Nodes= Kein Schreiben möglich
• Gesamtlaufzeit = 20ms
31
KonsistenzSchreiben
A
D B
C
Data
Replica Set
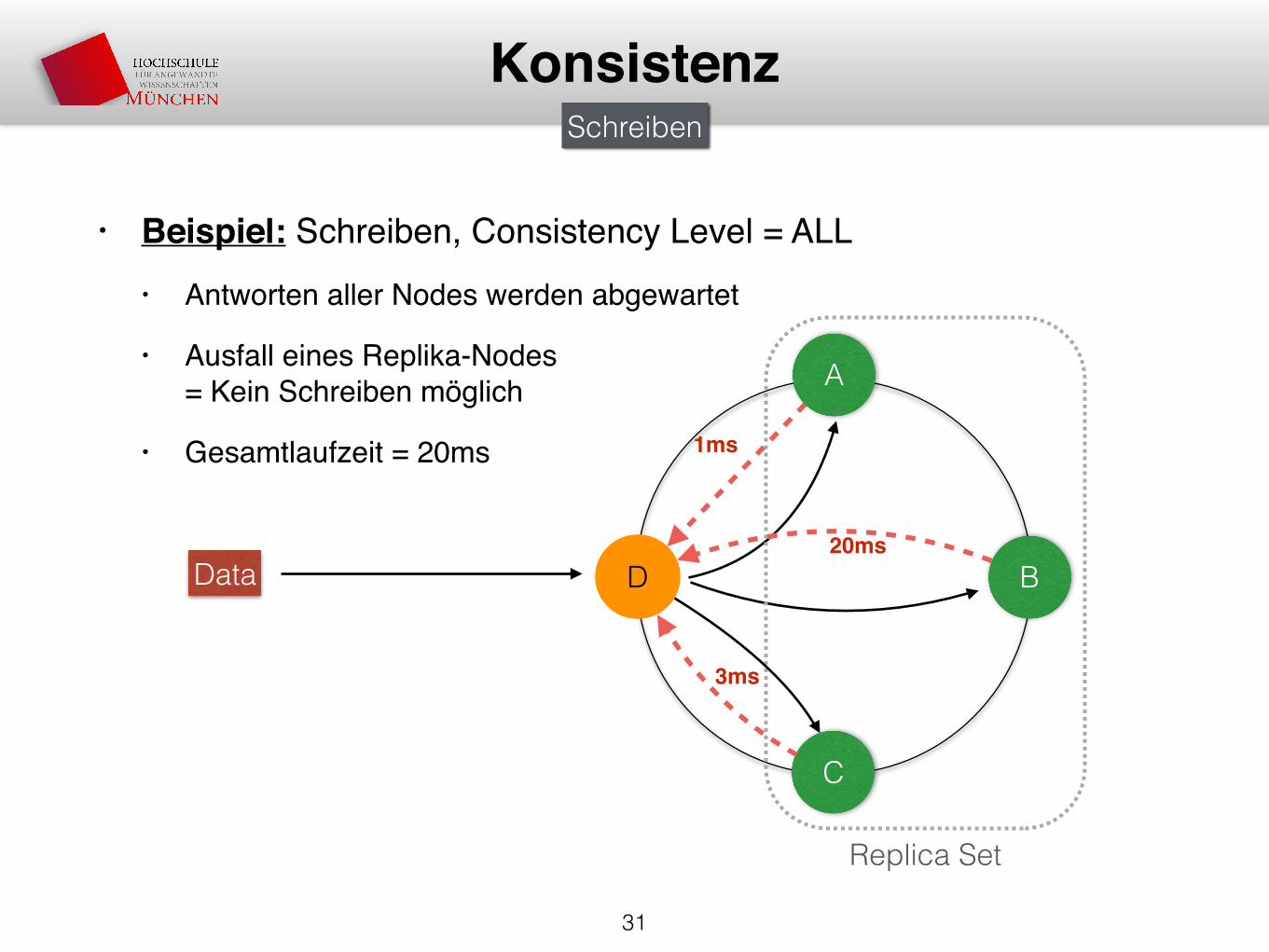
• Beispiel: Schreiben, Consistency Level = ALL• Antworten aller Nodes werden abgewartet
• Ausfall eines Replika-Nodes= Kein Schreiben möglich
• Gesamtlaufzeit = 20ms
31
KonsistenzSchreiben
A
D B
C
Data
Replica Set
1ms
20ms
3ms
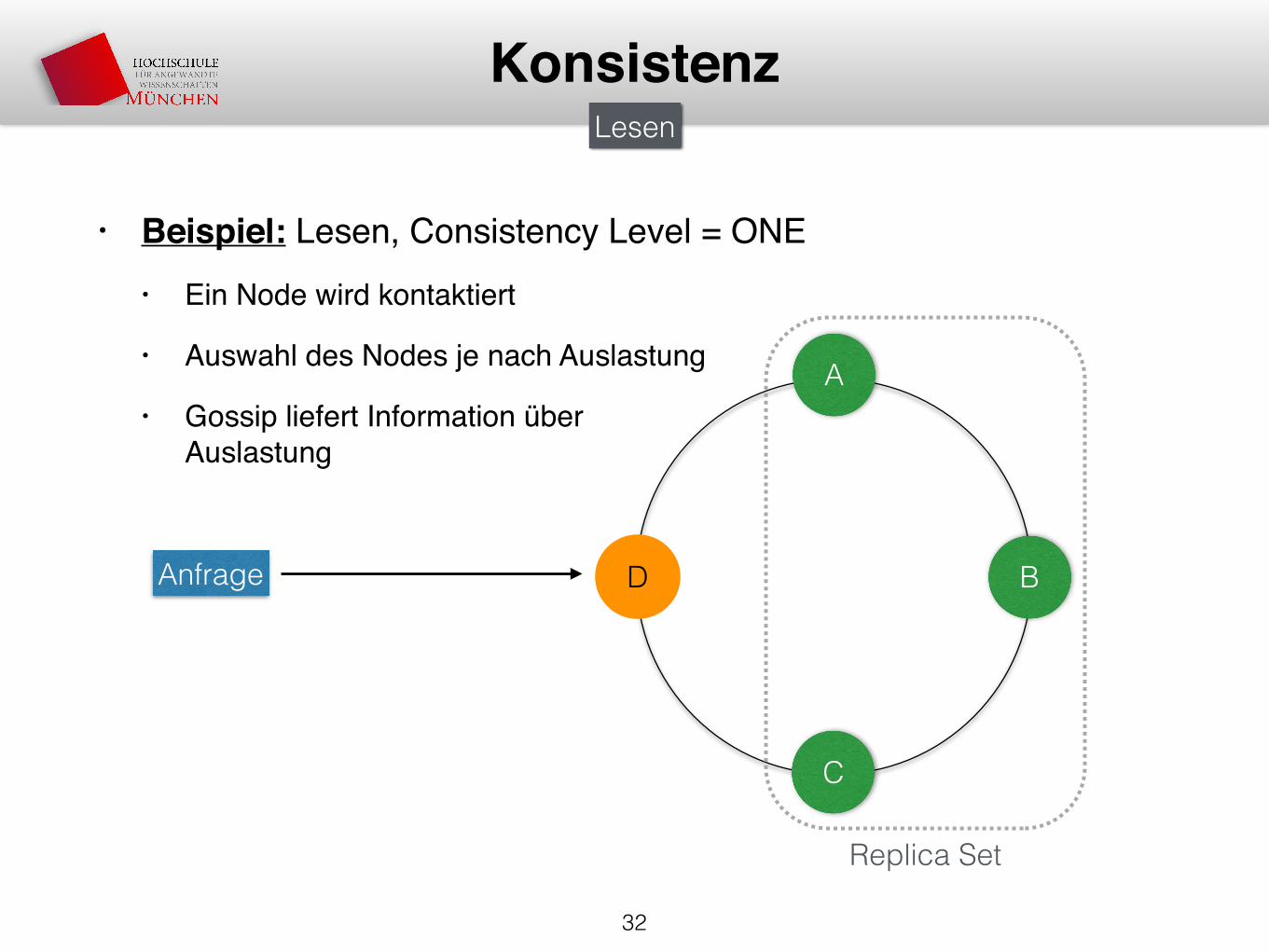
• Beispiel: Lesen, Consistency Level = ONE• Ein Node wird kontaktiert
• Auswahl des Nodes je nach Auslastung
• Gossip liefert Information überAuslastung
32
KonsistenzLesen
A
D B
C
Anfrage
Replica Set
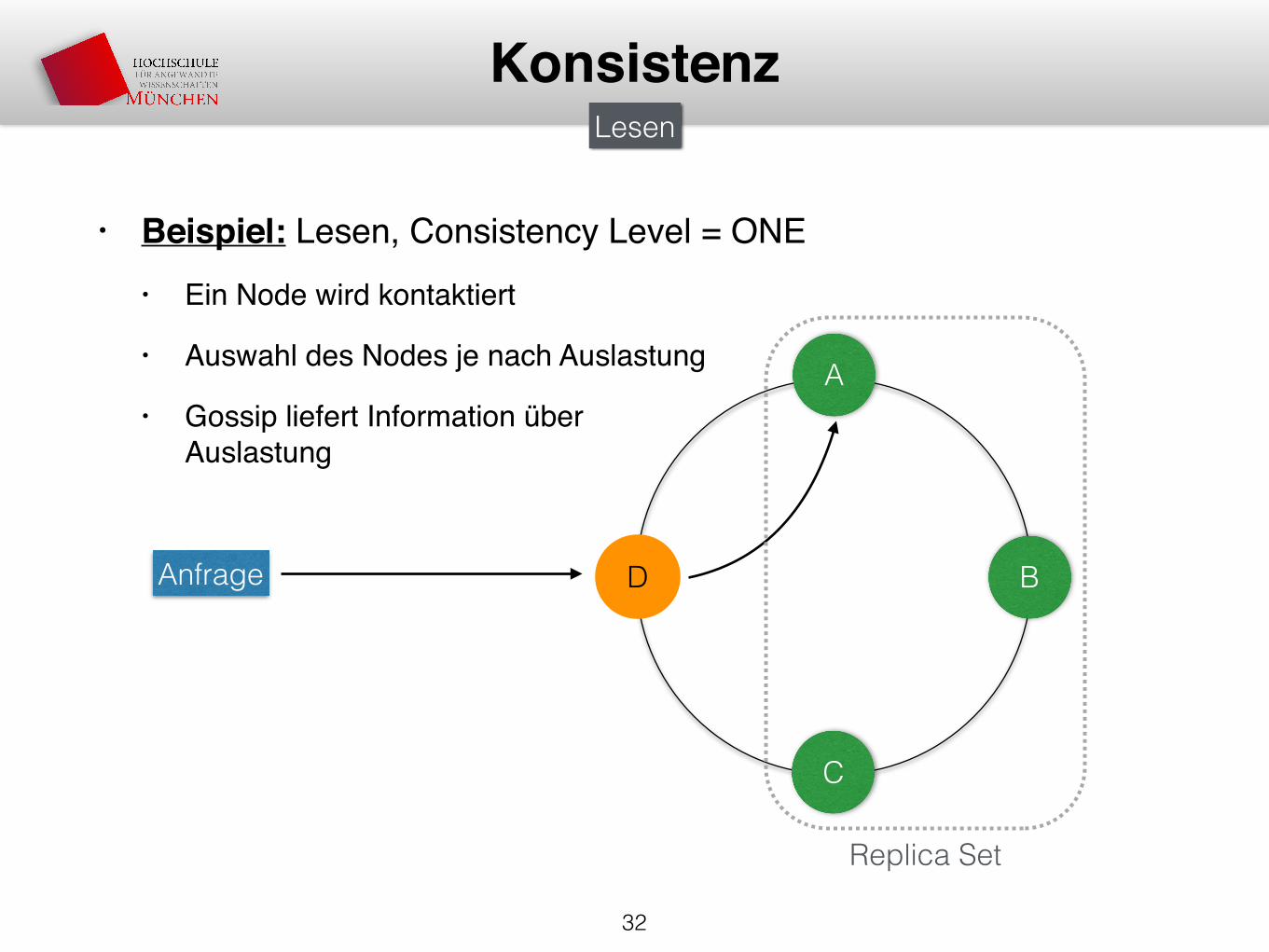
• Beispiel: Lesen, Consistency Level = ONE• Ein Node wird kontaktiert
• Auswahl des Nodes je nach Auslastung
• Gossip liefert Information überAuslastung
32
KonsistenzLesen
A
D B
C
Anfrage
Replica Set
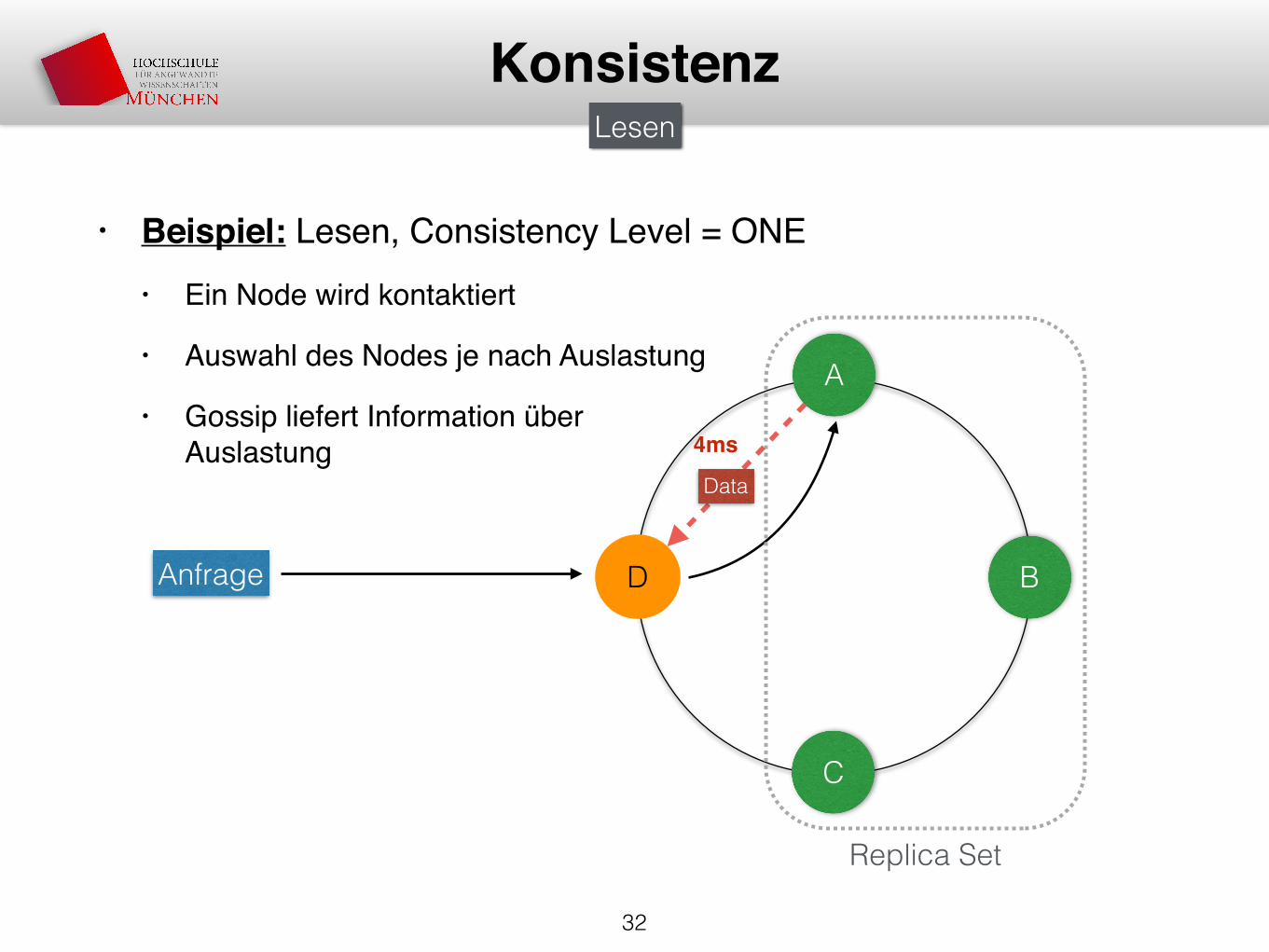
• Beispiel: Lesen, Consistency Level = ONE• Ein Node wird kontaktiert
• Auswahl des Nodes je nach Auslastung
• Gossip liefert Information überAuslastung
32
KonsistenzLesen
A
D B
C
Anfrage
Replica Set
4ms
Data
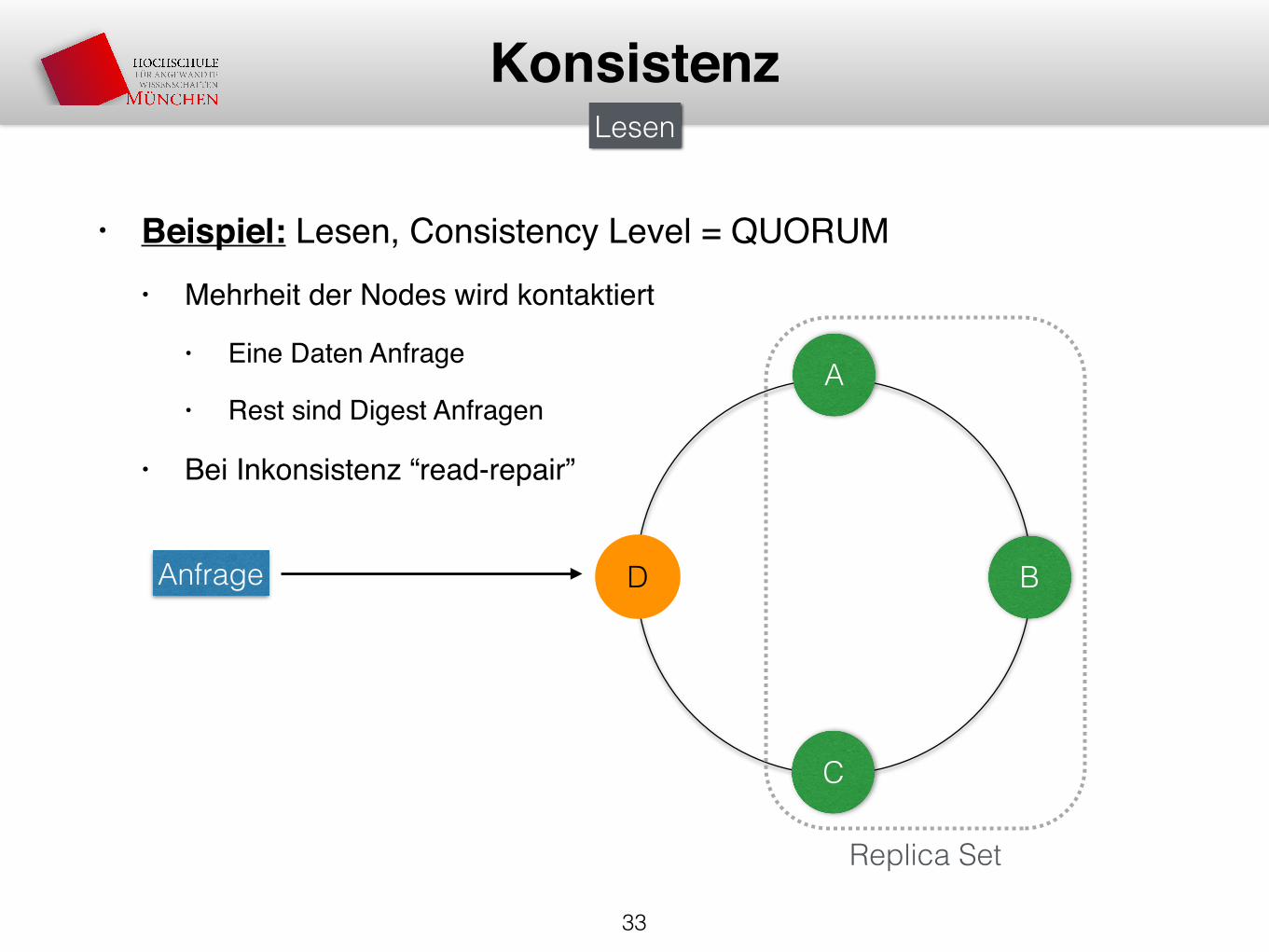
• Beispiel: Lesen, Consistency Level = QUORUM• Mehrheit der Nodes wird kontaktiert
• Eine Daten Anfrage
• Rest sind Digest Anfragen
• Bei Inkonsistenz “read-repair”
33
KonsistenzLesen
A
D B
C
Anfrage
Replica Set

• Beispiel: Lesen, Consistency Level = QUORUM• Mehrheit der Nodes wird kontaktiert
• Eine Daten Anfrage
• Rest sind Digest Anfragen
• Bei Inkonsistenz “read-repair”
33
KonsistenzLesen
A
D B
C
Anfrage
Replica Set
Digest Request
Data Request
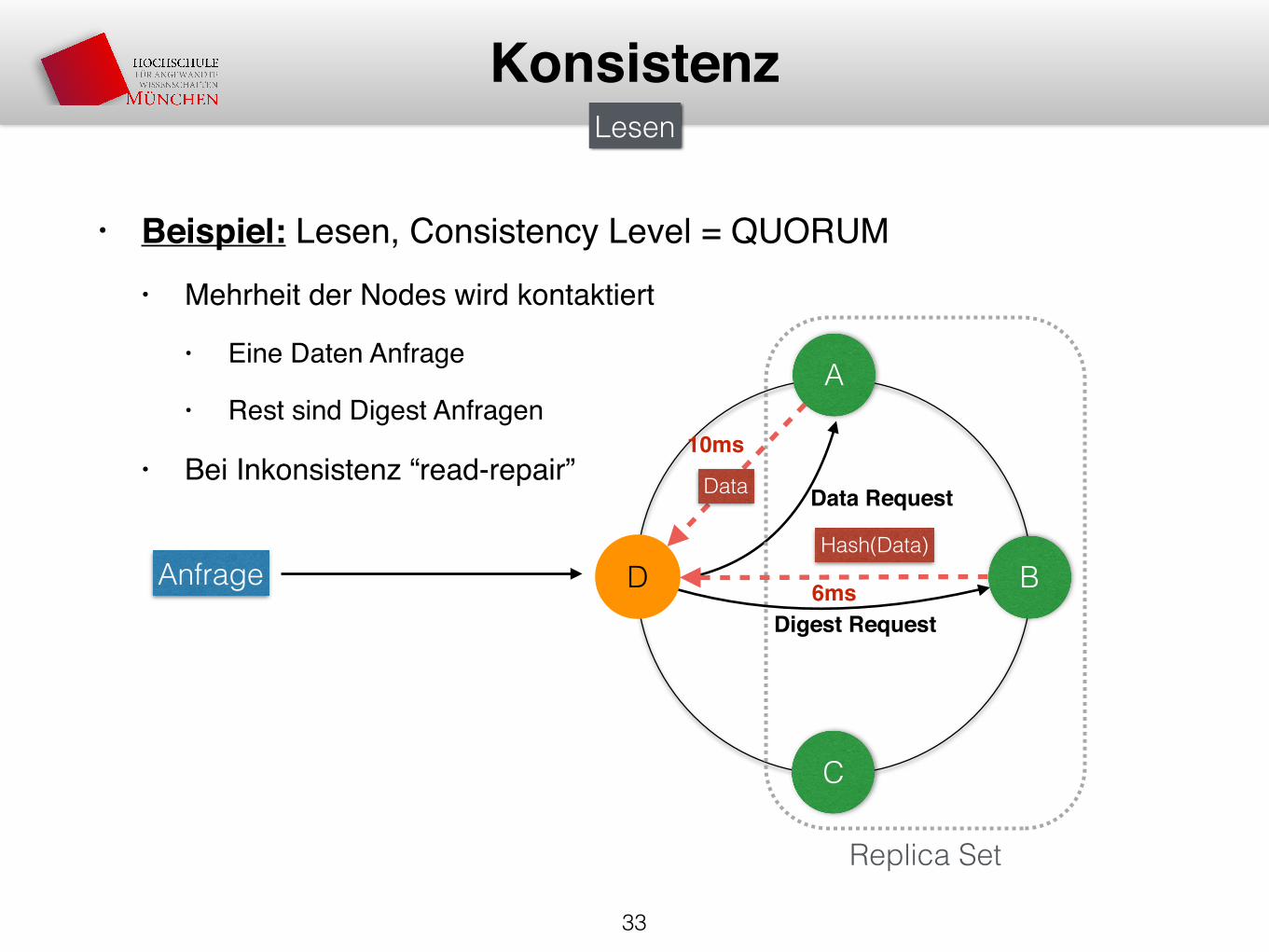
• Beispiel: Lesen, Consistency Level = QUORUM• Mehrheit der Nodes wird kontaktiert
• Eine Daten Anfrage
• Rest sind Digest Anfragen
• Bei Inkonsistenz “read-repair”
33
KonsistenzLesen
A
D B
C
Anfrage
Replica Set
10ms
Data
Digest Request
Data Request
Hash(Data)
6ms
34
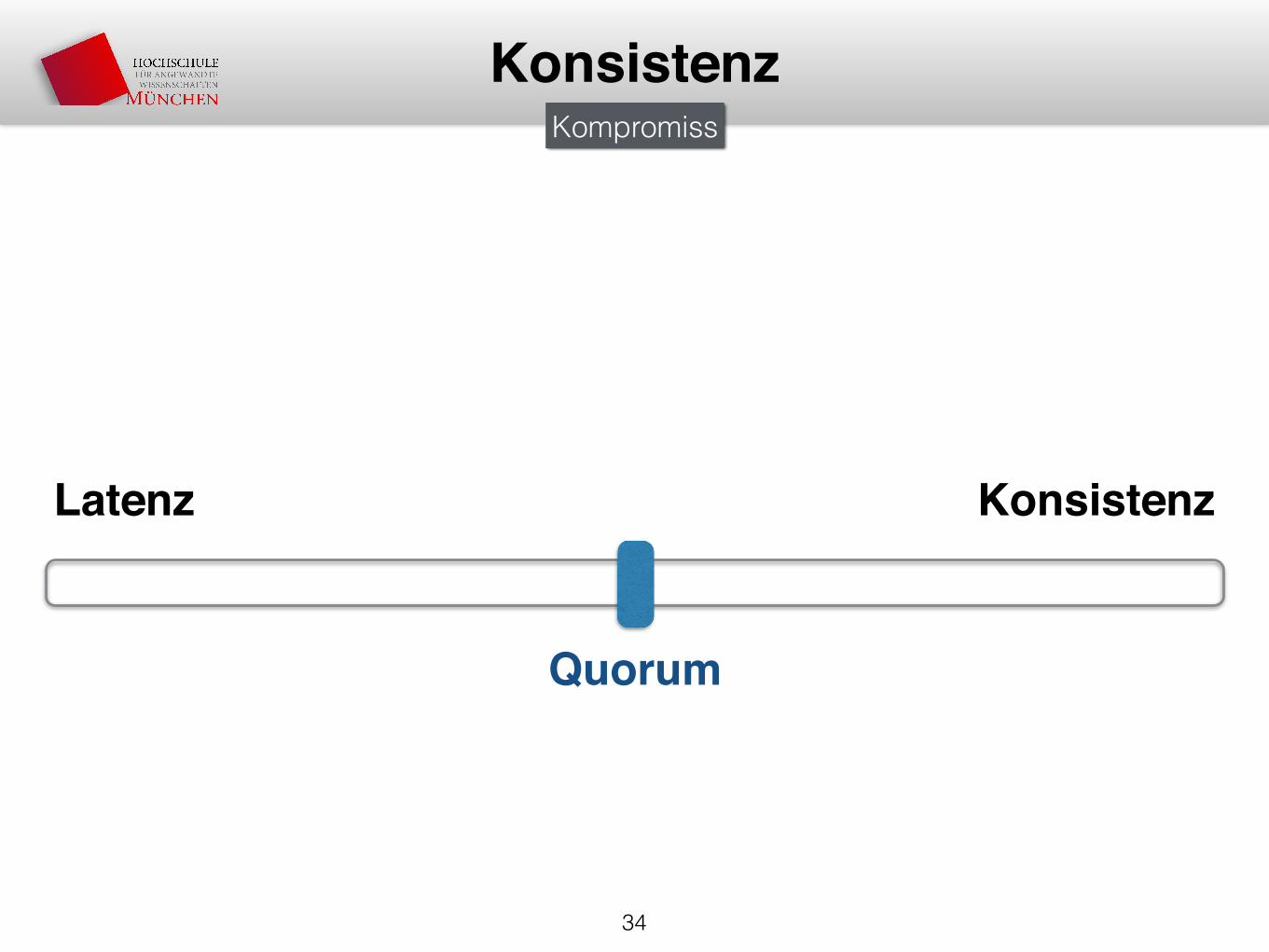
KonsistenzKompromiss
Latenz Konsistenz
Quorum
35
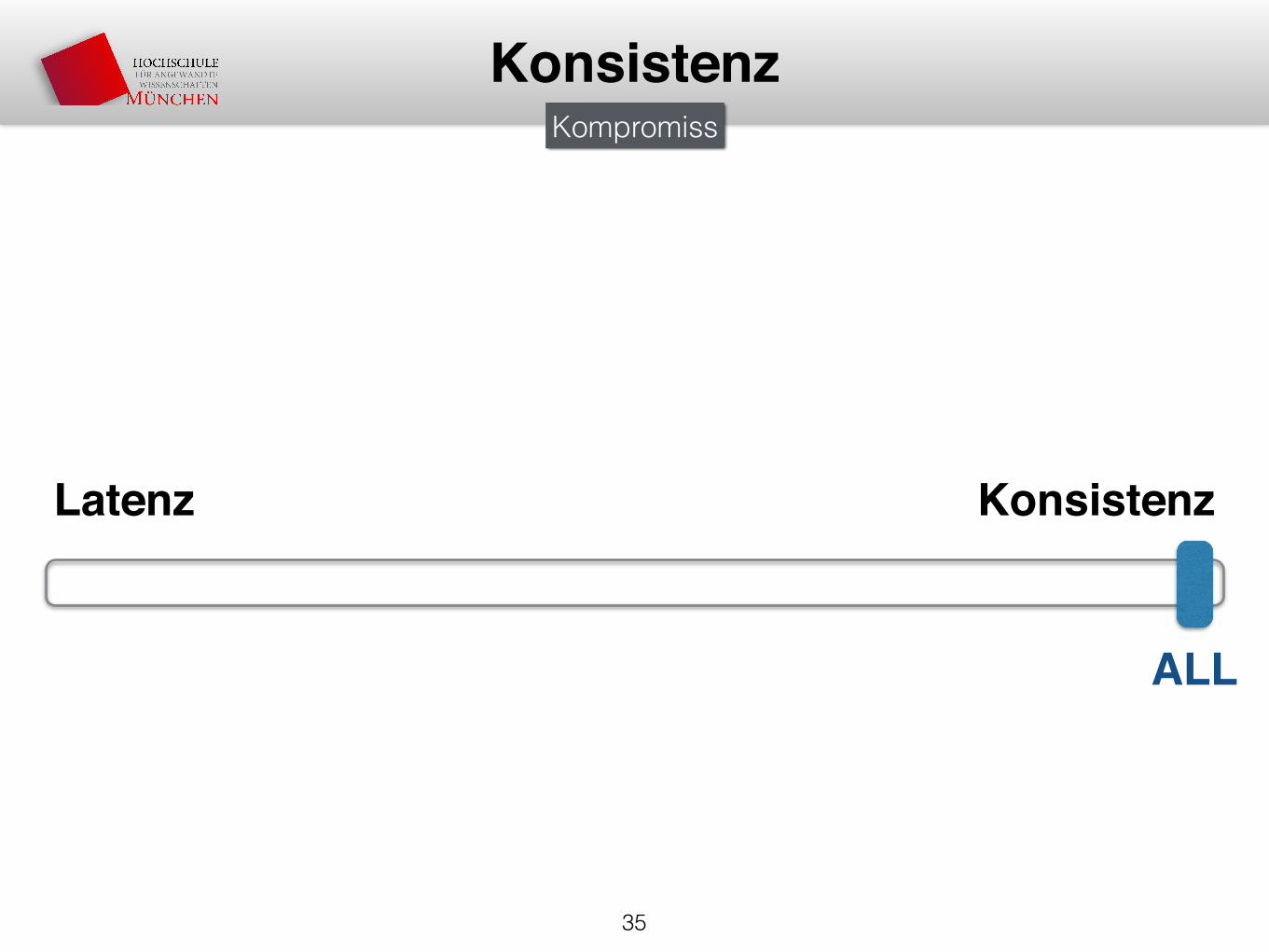
KonsistenzKompromiss
Latenz Konsistenz
ALL
36
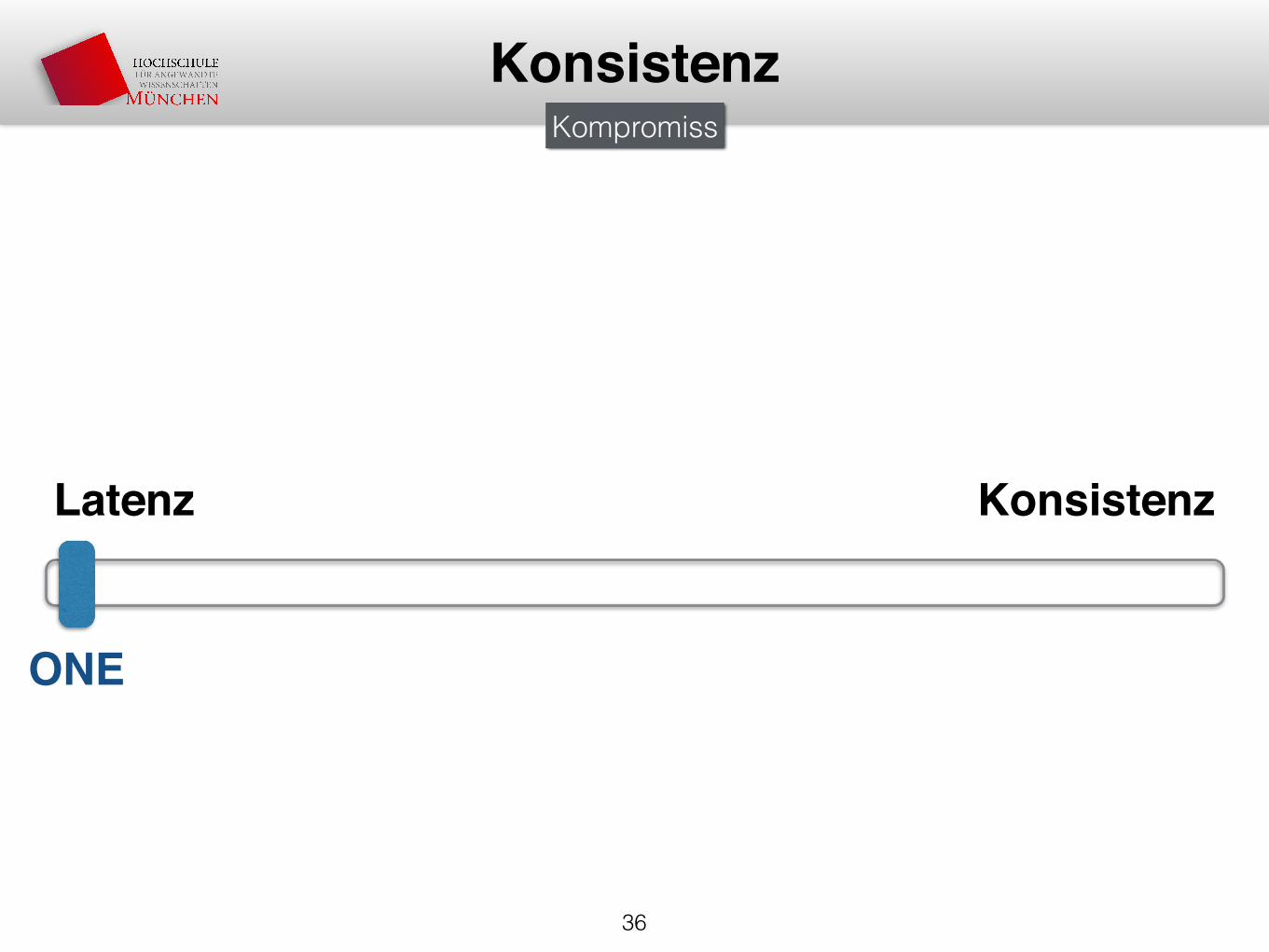
KonsistenzKompromiss
Latenz Konsistenz
ONE

• Apache Cassandra
• Cassandra Architektur
• Daten-Replikation
• Konsistenz
• Sicherheit• Demo: Daten Modellierung mit CQL
37
Agenda

• Authentifikation• Wer darf sich zu einem Node verbinden
• Standardmäßig nicht aktiviert (AllowAllAuthenticator)
• Einfache Benutzer/Passwort Authentifikation konfigurierbar (PasswordAuthenticator)
• Erweitert: Eigener Authentifikator (Erweiterung Interface IAuthenticator)
• Authorisierung• Auf was (Keyspaces, Tabellen) darf man auf einem Node zugreifen
• Standardmäßig nicht aktiviert (AllowAllAuthorizer)
• “Object Permission” Authorisierung konfigurierbar (CassandraAuthorizer)
• Erweitert: Eigene Authorisierung (Erweiterung Interface IAuthorizer)
38
Sicherheit
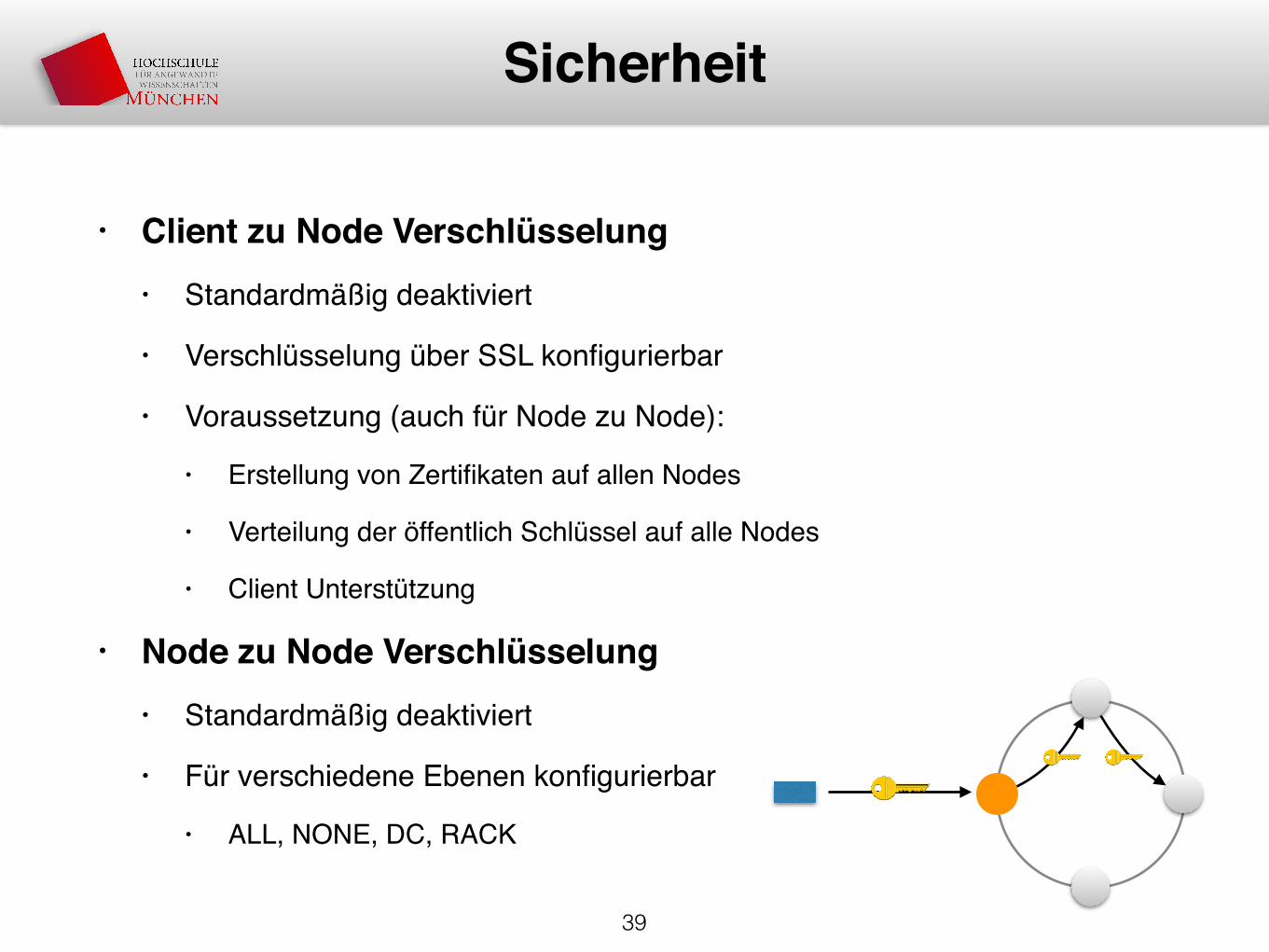
• Client zu Node Verschlüsselung• Standardmäßig deaktiviert
• Verschlüsselung über SSL konfigurierbar
• Voraussetzung (auch für Node zu Node):
• Erstellung von Zertifikaten auf allen Nodes
• Verteilung der öffentlich Schlüssel auf alle Nodes
• Client Unterstützung
• Node zu Node Verschlüsselung• Standardmäßig deaktiviert
• Für verschiedene Ebenen konfigurierbar
• ALL, NONE, DC, RACK
39
Sicherheit

• Apache Cassandra
• Cassandra Architektur
• Daten-Replikation
• Konsistenz
• Sicherheit
• Demo: Daten Modellierung mit CQL
40
Agenda
• http://static.googleusercontent.com/media/research.google.com/de//archive/bigtable-osdi06.pdf
• http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
• https://twitter.com//levwalkin/status/510197979542614016/photo/1
• http://www.infoq.com/news/2014/10/netflix-cassandra
• http://www.datastax.com/documentation/cassandra/2.0/cassandra/gettingStartedCassandraIntro.html
41
Quellen
• http://pixabay.com/static/uploads/photo/2012/04/13/01/23/key-31667_640.png
• http://upload.wikimedia.org/wikipedia/commons/thumb/5/5e/Cassandra_logo.svg/2000px-Cassandra_logo.svg.png
42
Bild Quellen

43
Fragen?


















