
Incremental Block Cholesky Factorization for Nonlinear ...roboticsproceedings.org/rss09/p42.pdf ·...
8
Incremental Block Cholesky Factorization for Nonlinear Least Squares in Robotics Lukas Polok, Viorela Ila, Marek Solony, Pavel Smrz and Pavel Zemcik Brno University of Technology, Faculty of Information Technology. Bozetechova 2, 612 66 Brno, Czech Republic ({ipolok,ila,isolony,smrz,zemcik}@fit.vutbr.cz) Abstract—Efficiently solving nonlinear least squares (NLS) problems is crucial for many applications in robotics. In online applications, solving the associated nolinear systems every step may become very expensive. This paper introduces online, incremental solutions, which take full advantage of the sparse- block structure of the problems in robotics. In general, the solution of the nonlinear system is approximated by incrementally solving a series of linearized problems. The most computationally demanding part is to assemble and solve the linearized system at each iteration. In our solution, this is mitigated by incrementally updating the factorized form of the linear system and changing the linearization point only if needed. The incremental updates are done using a resumed factorization only on the parts affected by the new information added to the system at every step. The sparsity of the factorized form directly affects the efficiency. In order to obtain an incremental factorization with persistent reduced fill-in, a new incremental ordering scheme is proposed. Furthermore, the implementation exploits the block structure of the problems and offers efficient solutions to manipulate block matrices, including a highly efficient Cholesky factorization on sparse block matrices. In this work, we focus our efforts on testing the method on SLAM applications, but the applicability of the technique remains general. The experimental results show that our implementation outperforms the state of the art SLAM implementations on all the tested datasets. I. I NTRODUCTION Many applications ranging from robotics, computer graph- ics, computer vision to physics rely on efficiently solving large nonlinear least squares (NLS) problems. The goal is to find the optimal configuration of a set of variables that maximally satisfy the set of soft nonlinear constraints. For instance in robotics, simultaneous localization and mapping (SLAM) estimates the optimal configuration of the robot positions and/or landmarks in the environment given a set of sensor measurements [6, 7, 10, 11, 14]. The variables can have several degrees of freedom (e.g. 3DOF for 2D problems or 6DOF for 3D problems). Therefore, the associated system matrix can be interpreted as partitioned into sections corresponding to each variable, called blocks, which can be manipulated at once. In practice, the initial problem is nonlinear and it is usually addressed by repeatedly solving a sequence of linear systems. The linear system can be solved either by matrix factorization or gradient methods. The latter are more efficient from the storage point of view, since they only require access to the gradient, but they can suffer from poor convergence, slowing down the execution. Matrix factorization, on the other hand, produces more accurate solutions and avoids convergence difficulties but typically requires a lot of storage. The problems in robotics are in general sparse, which means that the associated system matrix is primarily populated with zeros. Many efforts have been recently made to develop efficient methods to store and manipulate sparse matrices. CSparse [3], developed by Tim Davis [4] is one of the most used sparse linear algebra libraries. It is highly optimized in terms of run time and memory storage and it is also very easy to use. CSparse stores the sparse matrices in compressed column format (CCS) which considerably reduces the memory requirements and is suitable for matrix operations. The block structure and the sparsity of the matrices can bring important advantages in terms of storage and matrix manipulation. Some of the existing implementations rely on sparse block structure schemes [14, 13]. In the existing schemes, the block structure is maintained until the point of solving the linear system. Here is where CSparse [4] or CHOLMOD [5] libraries are used to perform the element-wise matrix factorization. Once it has been compressed, it becomes impractical and inefficient to change a matrix structurally or numerically. This motivated us to find efficient solutions to matrix storage and operations on matrices, especially the matrix factorization, to avoid the need of converting from blockwise to elementwise CCS format and back. In online applications the state changes every step. In SLAM, for example, the state is augmented with a new robot position or a new landmark from the environment and it is updated with the corresponding measurement. Every iteration of the nonlinear solver involves building a new linear system using the current linearization point and solving it using matrix factorization. For very large problems, updating and solving the nonlinear system every step can become very expensive. The literature proposes elegant incremental solutions, either by working directly on the matrix factorization [10] or by using a graphical model-based data structure called the Bayes tree, which allows efficient incremental algorithms [12, 11]. In their early work, Kaess et al. [10] introduced the idea of keeping the factorized form of the linear system and only recalculating parts that are affected by the incremental updates. This method becomes advantageous when the batch steps are performed periodically. The batch steps involve changing the linearization point by solving the nonlinear system and are needed for two important reasons; a) the error increases if the same linearization point is kept for a long time and b) the fill-in of the factorized form increases with the incremental updates, slowing down the backsubstitution. Later, they introduced the
Transcript of Incremental Block Cholesky Factorization for Nonlinear ...roboticsproceedings.org/rss09/p42.pdf ·...

Incremental Block Cholesky Factorizationfor Nonlinear Least Squares in Robotics
Lukas Polok, Viorela Ila, Marek Solony, Pavel Smrz and Pavel ZemcikBrno University of Technology, Faculty of Information Technology.
Bozetechova 2, 612 66 Brno, Czech Republic (ipolok,ila,isolony,smrz,[email protected])
Abstract—Efficiently solving nonlinear least squares (NLS)problems is crucial for many applications in robotics. In onlineapplications, solving the associated nolinear systems every stepmay become very expensive. This paper introduces online,incremental solutions, which take full advantage of the sparse-block structure of the problems in robotics. In general, thesolution of the nonlinear system is approximated by incrementallysolving a series of linearized problems. The most computationallydemanding part is to assemble and solve the linearized system ateach iteration. In our solution, this is mitigated by incrementallyupdating the factorized form of the linear system and changingthe linearization point only if needed. The incremental updatesare done using a resumed factorization only on the parts affectedby the new information added to the system at every step. Thesparsity of the factorized form directly affects the efficiency.In order to obtain an incremental factorization with persistentreduced fill-in, a new incremental ordering scheme is proposed.Furthermore, the implementation exploits the block structure ofthe problems and offers efficient solutions to manipulate blockmatrices, including a highly efficient Cholesky factorization onsparse block matrices. In this work, we focus our efforts ontesting the method on SLAM applications, but the applicabilityof the technique remains general. The experimental results showthat our implementation outperforms the state of the art SLAMimplementations on all the tested datasets.
I. INTRODUCTION
Many applications ranging from robotics, computer graph-ics, computer vision to physics rely on efficiently solving largenonlinear least squares (NLS) problems. The goal is to findthe optimal configuration of a set of variables that maximallysatisfy the set of soft nonlinear constraints. For instancein robotics, simultaneous localization and mapping (SLAM)estimates the optimal configuration of the robot positionsand/or landmarks in the environment given a set of sensormeasurements [6, 7, 10, 11, 14]. The variables can have severaldegrees of freedom (e.g. 3DOF for 2D problems or 6DOF for3D problems). Therefore, the associated system matrix can beinterpreted as partitioned into sections corresponding to eachvariable, called blocks, which can be manipulated at once.
In practice, the initial problem is nonlinear and it is usuallyaddressed by repeatedly solving a sequence of linear systems.The linear system can be solved either by matrix factorizationor gradient methods. The latter are more efficient from thestorage point of view, since they only require access to thegradient, but they can suffer from poor convergence, slowingdown the execution. Matrix factorization, on the other hand,produces more accurate solutions and avoids convergencedifficulties but typically requires a lot of storage.
The problems in robotics are in general sparse, whichmeans that the associated system matrix is primarily populatedwith zeros. Many efforts have been recently made to developefficient methods to store and manipulate sparse matrices.CSparse [3], developed by Tim Davis [4] is one of the mostused sparse linear algebra libraries. It is highly optimized interms of run time and memory storage and it is also veryeasy to use. CSparse stores the sparse matrices in compressedcolumn format (CCS) which considerably reduces the memoryrequirements and is suitable for matrix operations.
The block structure and the sparsity of the matrices canbring important advantages in terms of storage and matrixmanipulation. Some of the existing implementations rely onsparse block structure schemes [14, 13]. In the existingschemes, the block structure is maintained until the pointof solving the linear system. Here is where CSparse [4] orCHOLMOD [5] libraries are used to perform the element-wisematrix factorization. Once it has been compressed, it becomesimpractical and inefficient to change a matrix structurallyor numerically. This motivated us to find efficient solutionsto matrix storage and operations on matrices, especially thematrix factorization, to avoid the need of converting fromblockwise to elementwise CCS format and back.
In online applications the state changes every step. InSLAM, for example, the state is augmented with a new robotposition or a new landmark from the environment and it isupdated with the corresponding measurement. Every iterationof the nonlinear solver involves building a new linear systemusing the current linearization point and solving it using matrixfactorization. For very large problems, updating and solvingthe nonlinear system every step can become very expensive.The literature proposes elegant incremental solutions, eitherby working directly on the matrix factorization [10] or byusing a graphical model-based data structure called the Bayestree, which allows efficient incremental algorithms [12, 11].In their early work, Kaess et al. [10] introduced the idea ofkeeping the factorized form of the linear system and onlyrecalculating parts that are affected by the incremental updates.This method becomes advantageous when the batch steps areperformed periodically. The batch steps involve changing thelinearization point by solving the nonlinear system and areneeded for two important reasons; a) the error increases if thesame linearization point is kept for a long time and b) the fill-inof the factorized form increases with the incremental updates,slowing down the backsubstitution. Later, they introduced the

Bayes tree data structure [12], which provides insights on theconnection between graphical model inference and sparse ma-trix factorization. This offered the possibility of eliminating theneed for periodic batch steps obtaining incremental variablere-ordering to reduce the fill-in and fluid relinearization toguarantee good linearization points [11].
The work introduced in this paper combines the efficiency ofoperating directly on the matrix factorization with the insightsgained from the Bayes tree data structure to produce highlyefficient incremental solutions. Our incremental solution isbased on directly updating the Cholesky factorization ofthe linear system and changing the linearization point onlyif the error increases. This guarantees both fast and highquality estimations. The proposed algorithm is based on aresumed Cholesky factorization which recalculates only theparts affected by the new updates, together with an incrementalreordering scheme which maintains the factorization sparsewithout the need of periodic batch steps.
Our implementation maximally exploits the sparse blockstructure of the problem. On one hand, the block matrixmanipulation is highly optimized, facilitating structural andnumerical matrix changes while also performing arithmeticoperations efficiently. On the other hand, the block structureis maintained in all the operations including the matrix fac-torization, eliminating the cost of converting between sparseelementwise and sparse blockwise. Our block Cholesky fac-torization implementation proves to be significantly faster thanthe existing state of the art elementwise implementations.
The contributions of this work are introduced as follows.The next section succinctly formalizes SLAM as a nonlinearleast squares problem. Incremental updates are described inSection III. Then, Section IV explains the details of theproposed algorithm and implementation. In the experimentalevaluation in Section V we show the increased efficiencyof our proposed scheme over the existing implementations.Conclusions and future work are given in Section VI.
II. NONLINEAR LEAST SQUARES PROBLEM IN ROBOTICS
In robotics, simultaneously localizing a robot and mappingthe environment is often formulated as a nonlinear leastsquares problem (NLS) [6]. The goal is to obtain the maximumlikelihood estimate (MLE) of a set of variables θ = [θ1 . . . θn],usually containing the robot trajectory and/or the position oflandmarks in the surrounding environment, given the set ofmeasurements z:
θ∗ = argmaxθ
P (θ | z) = argminθ
− log(P (θ | z) . (1)
For every measurement zk = hk(θik , θjk)−vk we assume theGaussian distribution:
P (zk | θik , θjk) ∝ exp
(−1
2‖ hk(θik , θjk)− zk ‖2Σk
),(2)
where h(θik , θjk) is the nonlinear measurement function, andwhere vk is the normally distributed zero-mean noise with the
covariance Σk. Finding the MLE from (1) is done by solvingthe following nonlinear least squares problem:
θ∗ = argminθ
1
2
m∑k=1
‖hk(θik , θjk)− zk‖2Σk
. (3)
Methods such as Gauss-Newton or Levenberg-Marquardt areoften used to solve the NLS in (3) and this is usually addressedby iteratively solving the sequence of linear systems. Thoseare obtained by linear approximations of the nonlinear residualfunctions around the current linearization point θi:
r(θi) = r(θi) + J(θi)(θ − θi) , (4)
where r(θ) = [r1, . . . , rm]> is the set of all nonlinear residuals
of type rk = hk(θik , θjk) − zk and J is the Jacobian matrixwhich gathers the derivative of the components of r(θi). Thelinearized problem to solve becomes:
δ∗ = argminδ
1
2‖A δ − b‖2 , (5)
where the A = Σ−>\2J is the system matrix, b = −r(θi) theright hand side (r.h.s.) and δ = (θ − θi) the correction to becalculated [6]. This is a standard linear least squares problemin δ. For SLAM problems, the matrix A is in general sparse,since every measurement depends only on a few variables,but it can become very large when the robot performs longtrajectories. The normal system equation has the advantageof remaining of the size of the state even if the number ofmeasurements increases:
δ∗ = argminδ
1
2‖Λδ − η‖2 , (6)
where Λ = A>A is the information matrix and η = A>b isthe information vector.
The solution of the linear system can be obtained by sparsematrix factorization followed by backsubstitution. In general,QR factorization of A has slightly better numerical properties,but Cholesky factorization on Λ performs much faster. In thispaper we are interested in obtaining very fast online solutions,therefore we apply Cholesky factorization.
The Cholesky factorization of a square symmetric positivedefinite matrix Λ has the form LL> = Λ , where L is a lowertriangular matrix with positive diagonal entries. The forwardand backsubstitutions on Ld = A>b and L> δ = d firstrecovers d, then the actual solution δ. After computing δ,the new linearization point becomes θi+1 = θi ⊕ δ, where⊕ is the exponential map operator [14]. The Gauss-Newtoniterates until the norm of the correction becomes smaller thana tolerance.
III. INCREMENTAL SYSTEM UPDATES
In online robotic applications such as SLAM, new variables(robot poses and/or landmarks) are integrated every step andnew measurements frequently update the system. Integratinga new variable involve augmenting the system with the size ofthe new variable and updating it with the corresponding mea-surement. Integrating a measurement may become expensive,without carefully performing the involved operations.

Λ− system L− system
Fig. 1. Incremental updates on Λ-system and L-system. The blocks are color-coded according to the way they are affected by the update. Green - NOTaffected, red - affected, pink - affected by performing resumed factorization.
A. Incrementally updating the system matrix
Updating the system with a new measurement is additivein information form. We denote Ω = H>Σ−1
k H and ω =
−HΣ−1\2k rk to be the increments in information, where H is
the Jacobian of the new measurement. In general, in SLAM,the measurement function hk(·) involves only two variables,(θi, θj). For this reason and for simplicity, the followingformulation will be restricted to measurements between twovariables but its application remains general. The correspond-ing Jacobian, H , is very sparse H =
[0 . . . Jj
i . . . 0 . . . J ij
]and this translates into a sparse Ω and ω. The update step onlypartially changes the information matrix Λ and the informationvector η. For simplicity of the notations, in the followingformulations, the system matrices are split in parts that change(Λ11, η1) and parts that remain unchanged (Λ00, Λ10 and η0):
Λ =
[Λ00 Λ>10
Λ10 Λ11 + Ω
]; η =
[η0
η1 + ω
], (7)
In the formulation above we deliberately considered that thecurrent measurement to be integrated involves the last variableadded to the system. This is the situation usually encounteredin incremental SLAM problem. Note that this assumption isnot necessarily needed, the formulation in (7) stays general.Fig. 1 illustrates the unaffected part of the system matrix andr.h.s in green and the affected in red. When the measurementinvolves a new variable, the state is augmented with a zeroblock-row and a zero block-column (block-size depending onthe size of the new variable) and updated with the correspond-ing measurement. This is an inexpensive process since the newvariable always links to variables recently added to the system,but the update step, in general, can become very expensive ifthe new measurement links variables far apart.
B. Incrementally updating the Cholesky factor
As shown above, only a small part of the information matrixand the information vector are changed in the update processand the same happens with its factorized form L. The updatedL factor and the corresponding r.h.s. d can be written as:
L =
[L00 0
L10 L11
]; d =
[d0
d1
]. (8)
From Λ = L L>, (7) and (8) the updated part of the Choleskyfactor and the r.h.s can be easily computed:
L11 = chol(L11 L>11 + Ω) (9)
d1 = L11\(η1 − L10 d0) . (10)
The part unaffected by the update is shown in green inthe Fig. 1, and the affected parts are shown in red andpink. Variable ordering plays an important role in the matrixfactorization, and this directly influences the fill-in of the Lfactor. Later in the paper it is shown that, in order to maintainthe factorization sparse, we will recalculate both, L10 and L11
using a resumed Cholesky factorization applied to a reorderedΛ. This is illustrated in Fig. 1 using pink color for L10.
This form of incrementally updating the Cholesky factoris very similar to the incremental updates proposed in [10],where the authors use Givens rotations to update R = L>
and d. Even if this is one of the fast incremental approaches,there are still two important problems. Firstly, without peri-odic reorderings, the factorized form becomes less and lesssparse, slowing down the solving. Another problem is thatwithin an iterative nonlinear solver the linearization point canchange every iteration, invalidating the entire factorization.The recently introduced data structure, the Bayes tree [12],offers the possibility to develop incremental algorithms wherereordering and re-linearization are performed fluidly, withoutthe need of periodic updates. Inspired by the above-mentionedincremental strategies, this paper proposes an elegant andhighly efficient solution which combines the efficiency ofmatrix implementation and considers the insights gained usingthe Bayes tree data structure.
IV. INCREMENTAL BLOCK-CHOLESKY FACTORIZATION
This section will discuss several aspects to be considered inthe proposed incremental solution such as the block structureof the targeted problems and the importance of the incrementalreordering; then, it will describe the block-factorization itselfand will conclude proposing an efficient incremental algorithmfor the SLAM problem.
A. Block Matrix Scheme
SLAM, and similar problems such as structure from motion(SfM) and bundle adjustment (BA), involve operations withmatrices having a block structure, where the size of theblocks corresponds to the number of degrees of freedomof the variables. Sparsity of such problems plays an impor-tant role, therefore, sparse linear algebra libraries such asCSparse [4] or CHOLMOD [5] are commonly used to performthe matrix factorization. Those are state of the art element-wise implementations of operations on sparse matrices. Theelement-wise sparse matrix schemes provide efficient ways tostore the sparse data in the memory and perform arithmeticoperations. The disadvantage is their inability or impracticalityto change matrix structurally or numerically once it has beencompressed. The block-wise schemes are complementary, theiradvantages include both, easy numeric and structural matrix
0.0E+0
5.0E+4
1.0E+5
1.5E+5
2.0E+5
2.5E+5
3.0E+5
0 500 1000 1500 2000 2500 3000 3500
num
ber o
f non
-zer
o el
emen
ts
variables
AMD by elements AMD by blocks Constrained AMD by blocks Inc_L Reorder100 Inc_L
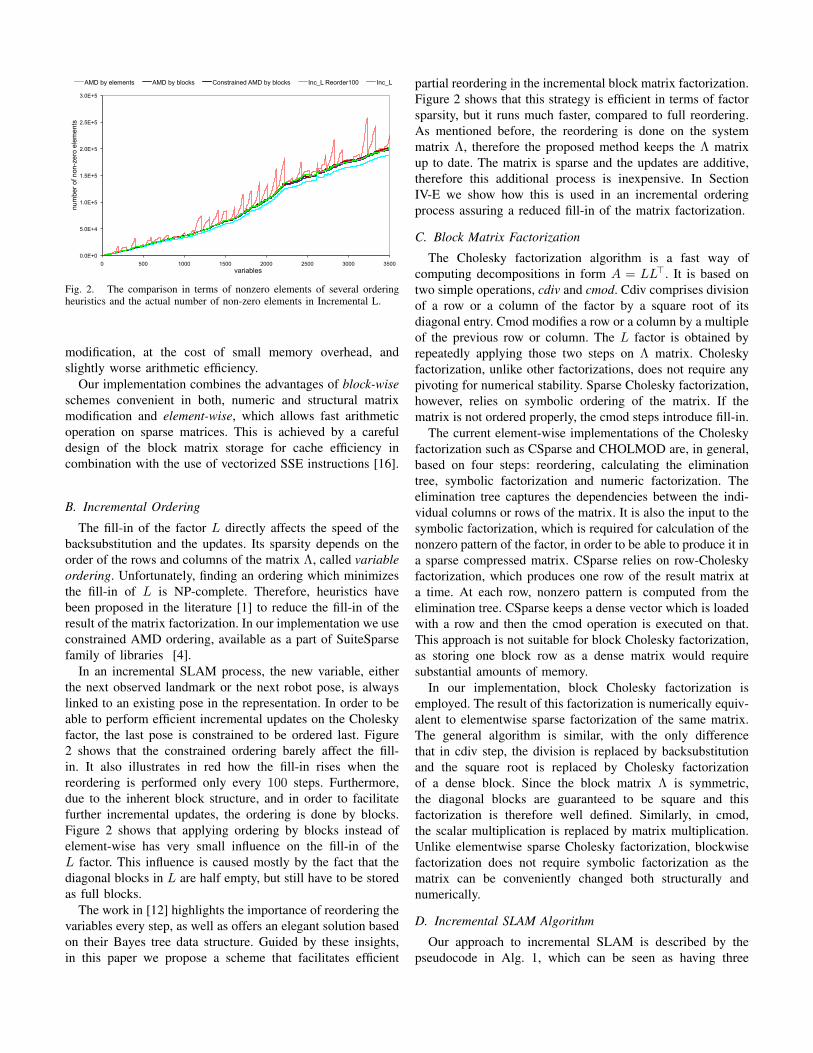
Fig. 2. The comparison in terms of nonzero elements of several orderingheuristics and the actual number of non-zero elements in Incremental L.
modification, at the cost of small memory overhead, andslightly worse arithmetic efficiency.
Our implementation combines the advantages of block-wiseschemes convenient in both, numeric and structural matrixmodification and element-wise, which allows fast arithmeticoperation on sparse matrices. This is achieved by a carefuldesign of the block matrix storage for cache efficiency incombination with the use of vectorized SSE instructions [16].
B. Incremental Ordering
The fill-in of the factor L directly affects the speed of thebacksubstitution and the updates. Its sparsity depends on theorder of the rows and columns of the matrix Λ, called variableordering. Unfortunately, finding an ordering which minimizesthe fill-in of L is NP-complete. Therefore, heuristics havebeen proposed in the literature [1] to reduce the fill-in of theresult of the matrix factorization. In our implementation we useconstrained AMD ordering, available as a part of SuiteSparsefamily of libraries [4].
In an incremental SLAM process, the new variable, eitherthe next observed landmark or the next robot pose, is alwayslinked to an existing pose in the representation. In order to beable to perform efficient incremental updates on the Choleskyfactor, the last pose is constrained to be ordered last. Figure2 shows that the constrained ordering barely affect the fill-in. It also illustrates in red how the fill-in rises when thereordering is performed only every 100 steps. Furthermore,due to the inherent block structure, and in order to facilitatefurther incremental updates, the ordering is done by blocks.Figure 2 shows that applying ordering by blocks instead ofelement-wise has very small influence on the fill-in of theL factor. This influence is caused mostly by the fact that thediagonal blocks in L are half empty, but still have to be storedas full blocks.
The work in [12] highlights the importance of reordering thevariables every step, as well as offers an elegant solution basedon their Bayes tree data structure. Guided by these insights,in this paper we propose a scheme that facilitates efficient
partial reordering in the incremental block matrix factorization.Figure 2 shows that this strategy is efficient in terms of factorsparsity, but it runs much faster, compared to full reordering.As mentioned before, the reordering is done on the systemmatrix Λ, therefore the proposed method keeps the Λ matrixup to date. The matrix is sparse and the updates are additive,therefore this additional process is inexpensive. In SectionIV-E we show how this is used in an incremental orderingprocess assuring a reduced fill-in of the matrix factorization.
C. Block Matrix Factorization
The Cholesky factorization algorithm is a fast way ofcomputing decompositions in form A = LL>. It is based ontwo simple operations, cdiv and cmod. Cdiv comprises divisionof a row or a column of the factor by a square root of itsdiagonal entry. Cmod modifies a row or a column by a multipleof the previous row or column. The L factor is obtained byrepeatedly applying those two steps on Λ matrix. Choleskyfactorization, unlike other factorizations, does not require anypivoting for numerical stability. Sparse Cholesky factorization,however, relies on symbolic ordering of the matrix. If thematrix is not ordered properly, the cmod steps introduce fill-in.
The current element-wise implementations of the Choleskyfactorization such as CSparse and CHOLMOD are, in general,based on four steps: reordering, calculating the eliminationtree, symbolic factorization and numeric factorization. Theelimination tree captures the dependencies between the indi-vidual columns or rows of the matrix. It is also the input to thesymbolic factorization, which is required for calculation of thenonzero pattern of the factor, in order to be able to produce it ina sparse compressed matrix. CSparse relies on row-Choleskyfactorization, which produces one row of the result matrix ata time. At each row, nonzero pattern is computed from theelimination tree. CSparse keeps a dense vector which is loadedwith a row and then the cmod operation is executed on that.This approach is not suitable for block Cholesky factorization,as storing one block row as a dense matrix would requiresubstantial amounts of memory.
In our implementation, block Cholesky factorization isemployed. The result of this factorization is numerically equiv-alent to elementwise sparse factorization of the same matrix.The general algorithm is similar, with the only differencethat in cdiv step, the division is replaced by backsubstitutionand the square root is replaced by Cholesky factorizationof a dense block. Since the block matrix Λ is symmetric,the diagonal blocks are guaranteed to be square and thisfactorization is therefore well defined. Similarly, in cmod,the scalar multiplication is replaced by matrix multiplication.Unlike elementwise sparse Cholesky factorization, blockwisefactorization does not require symbolic factorization as thematrix can be conveniently changed both structurally andnumerically.
D. Incremental SLAM Algorithm
Our approach to incremental SLAM is described by thepseudocode in Alg. 1, which can be seen as having three

INCREMENTAL-L(θ, r,Σk, L,Λ,η,o,maxIT, tol, newLP )
1: (Ω,ω) ← COMPUTEOMEGA((θi, θj) , rk ,Σk)2: if newLP then3: (Λ, η) ← LINEARSYSTEM(θ , r)4: else5: (Λ, η) ← UPDATELINEARSYSTEM(Λ, η,Ω,ω)6: end if7: (L, d, o) ← UPDATE-L(i, j,Ω,ω, L,Λ,η,o, newLP )8: newLP ← FALSE9: if maxIT ≤ 0 ‖ ¬ hadLoop then
10: exit11: end if12: it = 013: while it < maxIT do14: if it > 0 then15: (Λ, η) ← LINEARSYSTEM(θ , r)16: (L, d, o) ← UPDATE-L(i, j,Ω,ω, L,Λ,η,o, newLP )17: newLP ← FALSE18: end if19: δ ← LSOLVE(L , d)20: if norm(δ) ≥ tol then21: θ ← θ ⊕ δ22: newLP ← TRUE23: else24: exit25: end if26: it+ +27: end while
Algorithm 1: Incremental SLAM algorithm.
distinct parts. The first part is keeping the Λ matrix up todate. This can be done incrementally by adding Ω, unless thelinearization point changed. The change in the linearizationpoint is stored in the newLP flag. The second part of thealgorithm updates the L factor along with the associatedordering and it is explained in detail in the next section.The third part of the algorithm is basically a simple Gauss-Newton nonlinear solver. An important point to note is thatthe nonlinear solver only needs to run if the residual grewafter the last update. This is due to two assumptions; oneis that the allowed number of iterations maxIT is alwayssufficiently large to reach the local minima, and the other isthat good initial priors are calculated. Without a loop closure,the norm of δ would be close to zero and the system wouldnot be updated. The first iteration uses updated L factor, andthe subsequent iterations use Λ as it is much faster to berecalculated after the linearization point changed.
E. Incremental Block Cholesky Factorization
In order to update the L factor and the r.h.s. vector b, it ispossible to use (9) and (10), respectively. Without a properordering, L will quickly become dense, slowing down thecomputation. Λ can be reordered to reduce the fill-in. Thishas one major disadvantage that L factor changes completelywith the new ordering, impeding incremental factorization.
The solution is to only calculate the new ordering for partsof L which are being affected by the update. In order to beable to calculate ordering incrementally, the updated Λ matrix
(L, d, o) ← UPDATE-L(i, j,Ω,ω, L, Λ, η,o, newLP )
1: if newLP ‖ COLUMNS(Ω) = COLUMNS(Λ) then2: o← CAMD(Λ)3: L← CHOL(Λ,o)4: d← LSOLVE(L , η)5: else6: olo ← MIN(o[i],o[j])7: ohi ← COLUMNS(Λ)8: Λp ← PERMUTE(Λ,o)9: ocut ← MIN(WAVEFRONT(Λp)[olo : ohi])
10: Λp11 ← Λp[ocut : ohi, ocut : ohi]11: onew ← CAMD(Λp11)[olo − ocut : end]12: o← [o[0 : olo],onew]13: if onew = Identity then14: L ←
[L00, 0; L10, CHOL(Ω + L11 L
>11
)]
15: d ←[d0, LSOLVE(L11, η1 − L10 d0)
]16: else17: Λord1 ← PERMUTE(Λ, o)[olo : ohi, :]18: L← RESUMEDCHOL(L[0 : olo, :], Λord1 , olo)19: d← RESUMEDLSOLVE([L10, L11], η1,d, olo)20: end if21: end if
Algorithm 2: Incremental Block Cholesky Factorization.
is permuted with the ordering from the previous step, leadingto Λp (see Fig. 3).
To delimit the area in Λp affected by the update, two indicesare introduced. The first one, olo is given by the minimumvariable index after the ordering (line 6 of the Alg. 2). Thesecond one, ohi, is simply the size of the matrix. Let Λp11
bethe lower right submatrix of Λp delimited by those indices.
Calculating the new ordering as AMD on Λp11 is notsufficient and also leads to massive fill-in. This is causedby the AMD library not having any information about thenonzero entries in Λp10
= Λ>p01, which are also affected bythis ordering (depicted by the blue blocks in Fig. 3).
A useful ordering can be calculated as AMD of full Λp
with constraints applied to make sure that the ordering ofthe elements unaffected by the update is not disturbed. Thisis, however, a computationally expensive operation since theupdate is typically much smaller than Λp, and a significantnumber of ordering constraints needs to be applied.
Fortunately, it is not necessary to calculate the orderingusing the entire Λp. It is possible to use a slightly expandedΛp11 (see Fig. 3) that satisfies the conditions of being squareand not having any nonzero elements above or left fromit (Λp10
= Λ>p01are null). The ordering calculated on this
submatrix is then combined with the original ordering (lines11 and 12 in Alg. 2), yielding a similar result as constrainedordering on full Λp in much smaller time. The minimal sizeof the expanded Λp11
can be calculated in worst-case O(n)time. First, a matrix wavefront is calculated. This is a vectorcontaining the lowest positions of the nonzero elements pereach column of Λp. Only a part of this vector is used, theone between olo and ohi, and its minimum will give us the

10Λ
Λ
min(i, j)
o
onew
ResChol
L
11Λocut
olo
ohi
00Λ
10Λ
Λ Λ p
00L
Λord
Λord110L
L
11Λ
11Lolo
Λ p10Λ p11
Fig. 3. Dataflow diagram of incremental block Cholesky factorization. Greenparts of the matrices do not change, red parts represent the update and pinkrepresents the parts that will change. The explanation is simplified to updatesinvolving only two variables. Note that the green parts in Λp are unchangedrespect to the previous step not respect to original Λ.
index of the highest nonzero element, ocut. This is done inAlg. 2 on line 9, and in the Fig. 3 it is depicted as the line,keeping the blue nonzero blocks out of Λp10 . Extending Λp11
guarantees that AMD knows about all the nonzero elementsthat will cause fill-in, leading to a better ordering.
Once the new ordering is calculated, factorization can beperformed. In the case that the ordering is identity, it is pos-sible to only update L11 and d1 using (9, 10). Otherwise, theresumed Cholesky algorithm is employed. The row Choleskyis capable of calculating one row of the factor at a time,while only reading the values above it. This algorithm canbe used to ”resume” the factorization in the lower part of Lwhile only using the corresponding part of Λp and L00 asinputs. The advantage of this algorithm is overall simplicityof the incremental updates to the factor, while also savingsubstantial time by avoiding recalculation of L00, comparedto the conventional approach.
Please note, that this is a simplified version of the algorithm,handling the type of updates where no new variables areintroduced in the system. It is here where the fill-in isintroduced and where the ordering is really needed.
V. EXPERIMENTAL EVALUATION
This section evaluates both, the implementation of theincremental algorithm and of the incremental block Choleskyfactorisation by comparing timing and the quality of the resultwith similar state of the art implementations. The evaluationwas performed on five standard simulated datasets - Manhat-tan [15], 10k, City10k [9], CityTrees10k [9] and Sphere [14]and four real datasets - Intel [8], Killian Court [2], Victoriapark and Parking Garage [14]. Fig.4 shows the final solutionsfor all the tested datasets. All the tests were performed on anIntel Core i5 CPU 661 with 8 GB of RAM and running at
3.33 GHz. This is a quad-core CPU without hyperthreadingand with full SSE instruction set support. During the tests, thecomputer was not running any time-consuming processes inthe background. Each test was run ten times and the averagetime was calculated in order to avoid measurement errors.
A. Tested Implementations
We compared the proposed incremental algorithm andits implementation with state of the art implementationssuch as g2o [14], iSAM [10] and the gtsam implementationof the iSAM2 algorithm [11, 12]. For SPA the svnrevision 39478 of ROS (http://www.ros.org/) was used;for g2o, we tested the version 91A858D available athttps://github.com/RainerKuemmerle/g2o.1 For iSAM weused the version 1.6 from https://svn.csail.mit.edu/isamand for gtsam we used the version 2.3 fromhttps://collab.cc.gatech.edu/borg/gtsam.
SPA and g2o are both based on similar sparse block matrixscheme which is maintained until the matrix factorization isperformed. At this point, they switch to CCS format to be ableto use CSparse or CHOLMOD to perform the factorization.This is a time consuming process which is avoided in ourapproach. While SPA implementation is optimized for thespecific 2D SLAM problem, g2o is general, allowing any typeof SLAM and BA.
iSAM and iSAM2 are based on completely different algo-rithms. The one used in iSAM is very similar to our algorithmbut it requires periodic batch steps to reduce the fill-in. Thealgorithm used in iSAM2 is based on the Bayes tree datastructure and the factorization is done through elimination onfactor graphs. One important characteristic is that it allowsincremental reordering and fluid relinearization. In this direc-tion, our algorithm allows similar incremental reordering butchanges the entire linearization point when needed. In orderto test the iSAM2 we used the incremental test example fromthe library and extended it to work with landmark-based and3D SLAM datasets.
The proposed block Cholesky (BC) factorization is part ofa new nonlinear least squares open-source library available fordownload at http://sourceforge.net/projects/slam-plus-plus/.The main characteristic of this new library is its ability tomanipulate block matrices and to produce efficient incrementalsolutions. In this paper we test the BC factorization on both,an algorithm that operates only on the information matrix Λperforming batch updates every step (denoted Inc Λ) and anincremental algorithm, which maintains the matrix factoriza-tion L up to date (denoted Inc L). The latter corresponds tothe algorithm in 1. The new library offers the possibility toswitch between the native BC factorization and the Choleskyfactorization form CSparse (CS) and CHOLMOD (CM).
B. Performance and Accuracy
Table I shows the execution times and accuracy of theabove described implementations evaluated on the datasets in
1We thank the authors for providing the link and support
Manhattan 10k City10k CityTrees10k Sphere Intel Killian V ictoriaPark GarageParking
Fig. 4. The datasets used in our evaluations. ”Sphere“and ”Garrage Parking“ datasets are 3D pose graphs.
Manhattan 10K City10k CityTrees10k Sphere Intel Killian Victoria Park Parking GarageSPA 24.161 518.339 309.562 N/A N/A 1.486 5.669 N/A N/Ag2o 22.514 500.374 302.495 175.124 145.486 1.298 5.019 81.194 20.372
iSAM (b100) 4.829 279.926 77.572 22.926 36.220 1.287 4.213 11.921 52.2167iSAM2 4.932 91.738 60.978 32.687 31.274 0.618 1.196 16.349 3.658
Inc Λ − CS 8.603 287.702 202.839 19.531 216.487 0.651 1.705 23.162 17.317Inc Λ − CM 10.725 236.276 181.139 24.478 71.487 0.786 2.100 28.264 23.929Inc Λ −BC 7.209 242.209 188.849 17.566 78.375 0.508 1.242 18.707 11.342Inc L−BC 3.046 79.651 53.951 19.308 9.865 0.353 1.045 11.202 3.410
χ2 iSAM2 6205.92 171600 31951.6 794.868 775.28 559.07 0.00008 370.14 1.2635χ2 Inc L−BC 6119.83 171919 31931.4 12062.6 727.72 558.83 0.00005 144.91 1.3106
TABLE IPERFORMANCE AND ACCURACY TESTS ON MULTIPLE DATASETS.
0
5
10
15
20
25
30
35
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
χ2
× 10000
vertex
iSAM(b100) iSAM2 allBatch-‐Λ Inc-‐L
Fig. 5. Quality of the estimations measured on 10k dataset.
Fig.4. For every test we evaluate both, building the systemand computing the solution. The first one is necessary becausechanging the matrix numerically and structurally is differentfor each implementation and this makes significant differencein an incremental approach.
The proposed incremental algorithm is different from theone employed in SPA and g2o, where the batch solve is doneevery n new variables added to the system and no solutionsare available in between. Therefore, the time comparison withthese implementation is orientative. The comparison stays onlyfor n = 1, where the solution is available every step andour Inc Λ solver. iSAM, iSAM2 and Inc L provide solutionevery step. The main difference is that iSAM requires theperiodic batch solves, the default setting of n = 100 is usedin the comparison. But keeping the same linearization pointfor too long deteriorate the estimation. This can be seen byplotting the the sum of squared errors (χ2 in Fig. 5). Spikesappear when performing periodic batch solve due to the factthat the error increases between the batch steps and dropsafterwards. Observe that Inc−L (in red in Fig. 5) and iSAM2nicely follow the Inc−Λ (in green in Fig. 5), which represent
Fig. 6. Cholesky factorization benchmark.
the most accurate solution one can get solving the nonlinearproblem.
Our implementation reaches the best times for the bestaccuracy on all evaluated datasets and this is shown in bold intable I. Except for the CityTrees10k dataset, the execution ofthe Inc L outperforms all the implementations. This particu-lar result is given by the dense structure of the problem. In thiscase, reordering every step is slightly more advantageous thanincremental ordering. The closest time to Inc L is reachedby the iSAM2. The difference between iSAM2 and Inc L isthat iSAM2 changes only the affected blocks of the L factorand relinearizes only affected variables, while Inc L changesparts of the L factor and relinearizes all the affected variableswhen needed. iSAM2 was run with a defaull reliniarizationthreshold set to 10. This leads to slightly better accuracy ofthe estimation provided by Inc L (see the last two rows of thetable I) and favours iSAM2 in the execution time comparison.
The proposed Cholesky factorization algorithm was testedon full system matrices of the same datasets used in theincremental algorithm evaluation. The results are shown inFig. 6. Our block Cholesky implementation (BC) is always

faster than the CSparse (v3.0.2) and CHOLMOD (v2.1.2).Also note that the speedup grows with the block size, for 6×6blocks it is more than double. The quality of the factorizationis also good, the worst norm of difference between blockCholesky and CSparse was 2.6016 · 10−13 and occurred onthe City10k dataset.
VI. CONCLUSION AND FUTURE WORK
A new incremental NLS algorithm with applications torobotics was proposed in this paper. We targeted problemssuch as SLAM, which have a particular block structure, wherethe size of the blocks corresponds to the number of degrees offreedom of the variables. This enabled several optimizationswhich made our implementation faster than the state-of-the-artimplementations, while achieving very good precision. Thiswas demonstrated through the comparison with the existingimplementations on several standard datasets.
Recently, many efforts have been made to develop both,efficient incremental algorithms and implementations. Thispaper complements the recent advances by introducing newincremental ordering scheme which allows to incrementallyupdate the factorized form of the linearized system whilemaintaining a reduced fill-in. The incremental updates aredone using a resumed block Cholesky factorization only onthe parts affected by the new information. The block Choleskyfactorization itself proved to be more efficient than the currentimplementations of elementwise Cholesky factorizations whilethe precision is equally high.
Several further algorithmic improvements can be made. Itis possible to update only the affected blocks in L, insteadof a whole part of the factor, and to change only the affectedvariables in a similar way iSAM2 does. Also, similarly tohow the matrix factorization and the associated ordering areupdated incrementally, other parts of the algorithm can beoptimized, such as the calculation of the AMD orderingheuristic.
The data structure was designed with hardware accelerationin mind. This is very important for large scale problems, whichcan run faster on a wide range of accelerators, from multicoreCPUs to clusters of GPUs.
ACKNOWLEDGMENTS
The research leading to these results has received fundingfrom the EU 7th FP, grants 316564-IMPART and 247772-SRS,Artemis JU grant 100233-R3-COP, and the IT4InnovationsCentre of Excellence, grant n. CZ.1.05/1.1.00/02.0070, sup-ported by Operational Programme Research and Developmentfor Innovations funded by Structural Funds of the EuropeanUnion and the state budget of the Czech Republic.
REFERENCES
[1] P. Amestoy, T. A. Davis, and I. S. Duff. Amd, anapproximate minimum degree ordering algorithm). ACMTransactions on Mathematical Software, 30(3):381–388,2004.
[2] M.C. Bosse, P.M. Newman, J.J. Leonard, and S. Teller.Simultaneous localization and map building in large-scale cyclic environments using the Atlas framework.Intl. J. of Robotics Research, 23(12):1113–1139, Dec2004.
[3] Tim Davis. Csparse. http://www.cise.ufl.edu/research/sparse/CSparse/, 2006.
[4] Timothy A. Davis. Direct Methods for Sparse Lin-ear Systems (Fundamentals of Algorithms 2). Societyfor Industrial and Applied Mathematics, 2006. ISBN0898716136.
[5] Timothy A. Davis and William W. Hager. Modifying asparse cholesky factorization, 1997.
[6] F. Dellaert and M. Kaess. Square Root SAM: Simultane-ous localization and mapping via square root informationsmoothing. Intl. J. of Robotics Research, 25(12):1181–1203, Dec 2006.
[7] G. Grisetti, C. Stachniss, S. Grzonka, and W. Burgard. Atree parameterization for efficiently computing maximumlikelihood maps using gradient descent. In Robotics:Science and Systems (RSS), Jun 2007.
[8] A. Howard and N. Roy. The robotics data set repository(Radish), 2003. URL http://radish.sourceforge.net/.
[9] M. Kaess, A. Ranganathan, and F. Dellaert. iSAM:Fast incremental smoothing and mapping with efficientdata association. In IEEE Intl. Conf. on Robotics andAutomation (ICRA), pages 1670–1677, Rome, Italy, April2007. ISBN 1-4244-0601-3.
[10] M. Kaess, A. Ranganathan, and F. Dellaert. iSAM: Incre-mental smoothing and mapping. IEEE Trans. Robotics,24(6):1365–1378, Dec 2008.
[11] M. Kaess, H. Johannsson, R. Roberts, V. Ila, J. Leonard,and F. Dellaert. iSAM2: Incremental smoothing andmapping with fluid relinearization and incremental vari-able reordering. In IEEE Intl. Conf. on Robotics andAutomation (ICRA), Shanghai, China, May 2011.
[12] M. Kaess, H. Johannsson, R. Roberts, V. Ila, J. J.Leonard, and F. Dellaert. iSAM2: Incremental smoothingand mapping using the Bayes tree. Intl. J. of RoboticsResearch, 31:217–236, February 2012.
[13] K. Konolige, G. Grisetti, R. Kummerle, W. Burgard,B. Limketkai, and R. Vincent. Efficient sparse poseadjustment for 2d mapping. In Proc. of the IEEE/RSJ Int.Conf. on Intelligent Robots and Systems (IROS), Taipei,Taiwan, October 2010.
[14] R. Kummerle, G. Grisetti, H. Strasdat, K. Konolige,and W. Burgard. g2o: A general framework for graphoptimization. In Proc. of the IEEE Int. Conf. on Roboticsand Automation (ICRA), Shanghai, China, May 2011.
[15] Edwin Olson. Robust and Efficient Robot Mapping. PhDthesis, Massachusetts Institute of Technology, 2008.
[16] L. Polok, M. Solony, V. Ila, P. Zemcik, and P. Smrz.Efficient implementation for block matrix operations fornonlinear least squares problems in robotic applications.In Proceedings of the IEEE International Conference onRobotics and Automation. IEEE, 2013.


















