
High-level View of Web & WordPress Development (transcript)
53
Hi, my name is Alain Schlesser. I am a web developer specializing on the WordPress platform. I have done all sorts of development work in the past 25 years, on different platforms and in different programming languages, and pretty much covered all but the most obscure topics in development. In this session, my goal is to rip you out of your day-to-day technical nitty-gritty details and force you to consider the big picture. We web developers have a pretty complex job with a lot of moving parts, and I often see people trying to get to grips with small details while they still don’t grasp the fundamental basics of their job. They have started their journey with the famous 5-minute WordPress install, or have picked up an introductory PHP course. Maybe they even started with another CMS, or even with static HTML files… Some even start with the WordPress Editor you can find under Appearances. But how many of you have started by learning what a client/server architecture is, and how the HTTP protocol works? 1
-
Upload
alain-schlesser -
Category
Presentations & Public Speaking
-
view
162 -
download
0
Transcript of High-level View of Web & WordPress Development (transcript)

Hi, my name is Alain Schlesser.
I am a web developer specializing on the WordPress platform. I have done all sorts of development work in the past 25 years, on different platforms and in different programming languages, and pretty much covered all but the most obscure topics in development.
In this session, my goal is to rip you out of your day-to-day technical nitty-gritty details and force you to consider the big picture. We web developers have a pretty complex job with a lot of moving parts, and I often see people trying to get to grips with small details while they still don’t grasp the fundamental basics of their job. They have started their journey with the famous 5-minute WordPress install, or have picked up an introductory PHP course. Maybe they even started with another CMS, or even with static HTML files… Some even start with the WordPress Editor you can find under Appearances.
But how many of you have started by learning what a client/server architecture is, and how the HTTP protocol works?
1

So, as a change, instead of learning from the inside-out, as it is usually done, we’ll start with these basics. Don’t worry, I’m not trying to flood you with specification details here, I want to keep this as understandable and as visual as possible.
A small disclaimer: I don’t care if any of this is not 100% technically correct or omits small details. We’re talking concepts here, not implementations. I will over-simplify and I will use naïve analogies. So, although I appreciate any feedback, keep in mind that we really do want to skip the details here.
1

Ok, so first of all, let’s find out who we are and what our job is really about.
Web developer build websites.
But what does it mean to “build a website” ?
Take notice that I’m currently sitting behind this very slide doing air quotes.
2

Well, here’s what we’re doing:
We PROGRAM a COMPUTER so that it can SERVE HYPERTEXT to CONNECTING CLIENTS.
This is true for static web pages as it is for your latest WordPress showcase site.
It is a simple sentence, but it contains a lot of information already. Each of these underlined words represents a topic that could fill dozens of books.
My hopes are that, at the end of this presentation, you’ll have a much better understanding of this sentence, and that you can appreciate the technology that hides behind this simple phrase.
3

We program a computer so that it can SERVE HyperText to connecting CLIENTS.
This means that the computer we program acts as a server, and it produces content for clients.
We have a client/server architecture here.
And they communicate over the World Wide Web.
The name “World Wide Web” makes it sound as if it was a description of something that normally has a more technical name. But it is indeed a technical specification that defines how an information system of interlinked HyperText files is built.
The cables and routers that are connected across the globe communicate via the Internet protocol suite, abbreviated as (TCP/IP), which is a modern variant of a military network.
4

All the computers that wish to connect through the Internet protocol receive an IP address.
But remembering lots of IP addresses is not very fun.
That’s why we have domains and Domain Name Servers, which can point these domains to a given IP address.
When you enter genesis.camp into your browser, it first looks through your local hosts file if you have defined an IP address for this domain.
If it does not find one, it connects to a Domain Name Server to get the IP address associated with the domain. When it gets back an IP address, it can connect to that specific computer.
5

To connect to a server, your browser typically uses the HyperText Transfer Protocol, HTTP, or its encrypted variant, HTTPS.
We can once again find components of our sentence from the earlier slide: We program a computer so that it serve HYPERTEXT to CONNECTING clients. So, the HyperText Transfer Protocol was specifically built to enable connections that let you transfer HyperText.
So, to summarize, the above address establishes a connection over the HyperTextTransfer Protocol to the computer whose IP address has been attributed to the domain “genesis.camp”. This computer then acts as the server. But who exactly is the client?
6

You probably guessed it. The client is the one that started the request to connect to the server: it is your browser!
When you enter an address into your browser window, it queries the DNS server for the IP address of the Genesis Camp server, and establishes a connection with this server. The server then sends the content of the requested page to the browser.
7

What do you get returned to your browser when you build a connection to a server over the HyperText Transfer Protocol? Right, a document coded in HyperText Markup Language, or how you normally call it, an HTML file.
So this is what we want our server to serve to connecting clients. It is a text file that has a special syntax, so that its contents can be semantically interpreted by the client.
So, the client does not get the visual representation of a website.
The client gets the HTML file, which is basically a semantical blueprint of how to assemble the visual representation of the website.
This is an important distinction. You can contrast this to sending someone a PDF file. The PDF file is an exact visual representation, but it can only be used as it was initially generated. It can not be put into another context, such as adapting it to another page format, as it lacks information on how to rebuild it. The HTML file however contains this information only, and needs to be rebuilt for every viewing. This enables it to adapt to a different context, but has the disadvantage that we are now at the mercy of the client’s interpretation. So we cannot guarantee that it always looks exactly the
8

same, as would be the case with a PDF file.
8

Earlier I said that an HTML file is a text file with a special syntax. So why is it not simply called “Text Markup Language” ? What makes it “Hyper” ?
Well, simply put, it can contain links to other files…
Yes, this sounds only moderately “hyper” nowadays, but this simple concept is what powers the entire World Wide Web and has managed to quickly share and expand upon knowledge over the entire globe. And when the first notions of this concept were written down, which you can trace back to 1945, it was indeed “hyper”, or well above and superior to regular text.
9

What does it mean, exactly, that the HTML file is a semantical blueprint?
Imagine a standard text file.
There’s no way for a computer to know how to display this in a more meaningful way. It is only two lines of letter sequences for the computer. If the computer would want to change the font of the paragraph text, it would not know where this paragraph starts and where it ends, it could only guess.
So if we wrap this text in a HTML file, we still have only text at first. But HTML allows us to add “tags” to the content, to give them a semantic meaning.
So, we can tell a computer, what the heading is, and what the paragraph text is. We can even add metadata, which is not directly part of the content, but adds additional semantical meaning for the computer.
We can even add attributes to the tags, to further specify what we are dealing with here.
10

The computer now has a much better understanding of the structure of the content. If we now ask it to display this properly, chances are much higher that it will succeed.
10

I’ve mentioned that the HTML file is a semantical blueprint. But, semantics alone are not sufficient to rebuild a complete representation of a webpage. We’ll also need to know about the aesthetics as well as the interactions.
The aesthetics are handled by Cascading Stylesheets, or CSS.
They can target individual elements and tell the client what visual properties these have.
The interaction part is handled by a scripting language that can be included inside HTML called JavaScript.
This language allows us to write real code inside the HTML file, for whatever purposes we might need.
11

HTML allows you to put the Cascading Stylesheets, as well as the JavaScript, into separate files, that can be linked to as external resources.
A Stylesheet that is inline will need to be completely transferred with every page request. Same goes for the JavaScript we’ve included.
So, to keep things modular, and to allow the browser to say: “Oh, I’ve already got that part of the site, I don’t need to download it again.”, we can put this code into separate files and link to them from the HTML.
When you load the next page, and the browser sees “css/styles.css”, it already has a local copy of this file and won’t download it again.
12

Another thing that modern HTML allows us to do is to adhere to a common design principle called “Separation of Concerns”. It basically means in this context that you should have separate isolated layers for content, presentation and interaction, instead of mixing it all up.
As you can see in this example code, with add CSS styles as an attribute to each tag. We have clearly mixed the content layer and the presentation layer here. This leads to all sorts of problems. Making changes to the presentation makes you run through the entire content, and you risk missing some instances. And for the paragraph font size, we have duplicated information, that adds unnecessary bandwidth consumption.
But we can extract this presentation information out of the content layer and put it in a conceptually isolated presentation layer of its own.
You can now see that the content is cleaner, we only have to look in one place if we want to make changes to the content, and the duplicated information has gone as well.
If we combine this with the concept of external files discussed before, we’ll get an
13

even cleaner file.
So, now our HTML is only concerned about semantic content, and delegates the rest to other files. This basic structure forms the basis of how HTML results are laid out in WordPress, too.
13
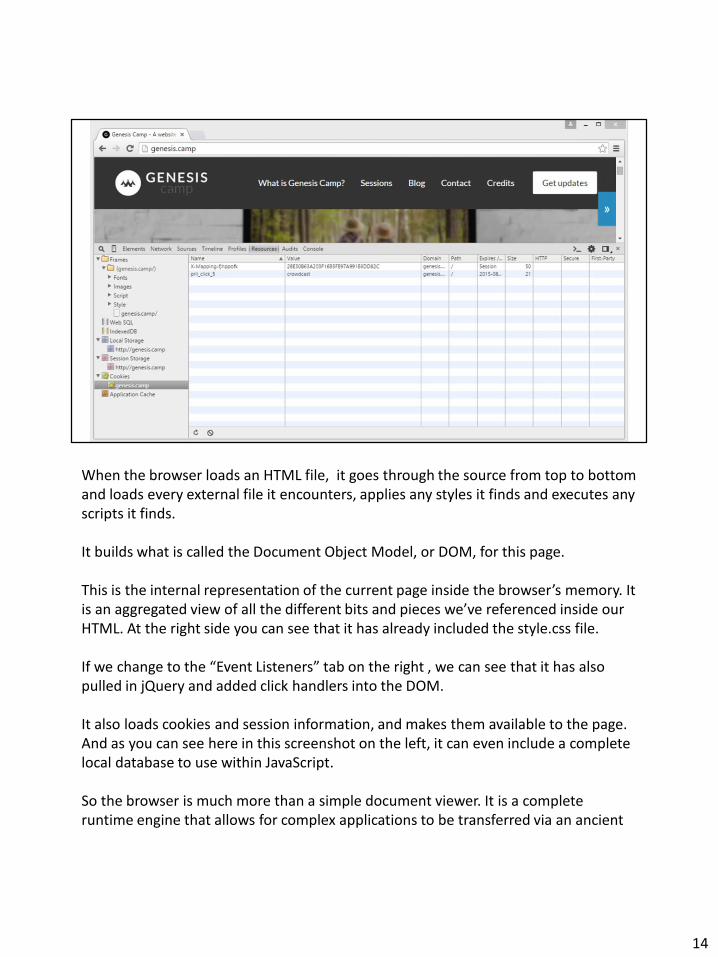
When the browser loads an HTML file, it goes through the source from top to bottom and loads every external file it encounters, applies any styles it finds and executes any scripts it finds.
It builds what is called the Document Object Model, or DOM, for this page.
This is the internal representation of the current page inside the browser’s memory. It is an aggregated view of all the different bits and pieces we’ve referenced inside our HTML. At the right side you can see that it has already included the style.css file.
If we change to the “Event Listeners” tab on the right , we can see that it has also pulled in jQuery and added click handlers into the DOM.
It also loads cookies and session information, and makes them available to the page. And as you can see here in this screenshot on the left, it can even include a complete local database to use within JavaScript.
So the browser is much more than a simple document viewer. It is a complete runtime engine that allows for complex applications to be transferred via an ancient
14

protocol and manages to run everything smoothly behind the scenes.
14
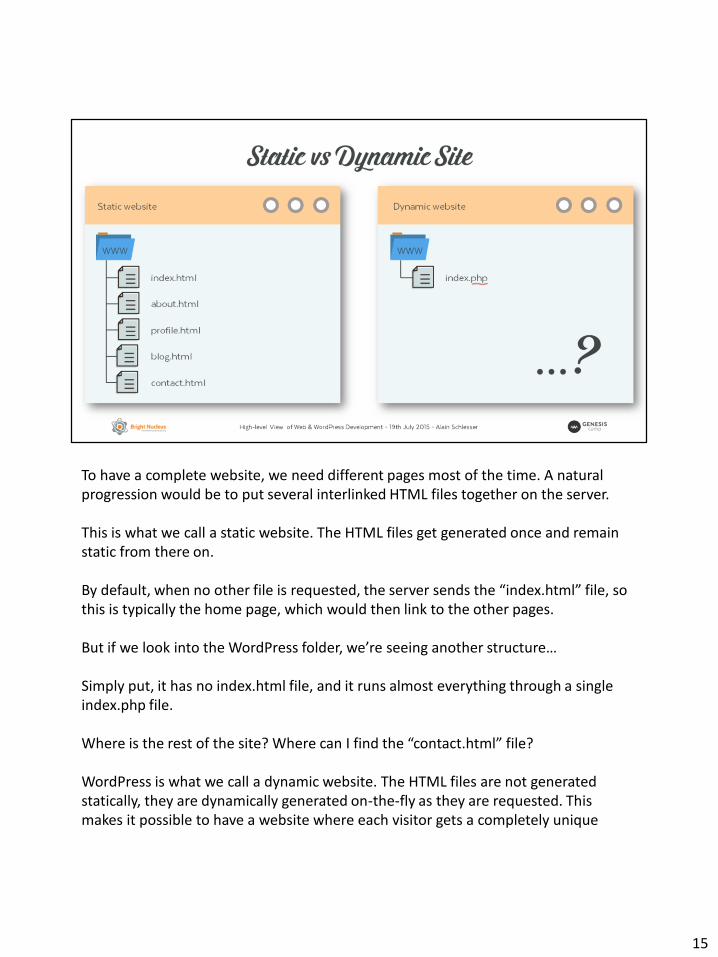
To have a complete website, we need different pages most of the time. A natural progression would be to put several interlinked HTML files together on the server.
This is what we call a static website. The HTML files get generated once and remain static from there on.
By default, when no other file is requested, the server sends the “index.html” file, so this is typically the home page, which would then link to the other pages.
But if we look into the WordPress folder, we’re seeing another structure…
Simply put, it has no index.html file, and it runs almost everything through a single index.php file.
Where is the rest of the site? Where can I find the “contact.html” file?
WordPress is what we call a dynamic website. The HTML files are not generated statically, they are dynamically generated on-the-fly as they are requested. This makes it possible to have a website where each visitor gets a completely unique
15

version of the website. For example, a logged-in user will get another version of the site than an anonymous visitor.
This is all made possible because the website is generated on the fly through a scripting language, which is PHP in the case of WordPress.
15

Yes, the above slide title is what the acronym PHP stands for. PHP is a recursive acronym, it contains itself.
The important bit here is not the linguistic particularity, though, but rather the combination of the last two words. We’re dealing with HyperText again here, so PHP might be a good fit for our goal we set out in the beginning: serving HyperText.
The other word stands for something even a lot of experienced developers might not be totally aware of. PHP is a preprocessor. Although it can be used as a programming language, going so far as to producing stand-alone binaries, it is at its core a preprocessor.
When you have an HTML file that you will run through your PHP preprocessor, you can include PHP tags that will get executed, and the value that gets returned by the code inside the tags gets put in place of the tag.
This lets you put dynamic code in place of the static HTML content. Because the HTML file containing PHP tags is not complete yet and will not be sent to the client in this form, we call this a template.
16

Although the extension might mislead you, PHP files are NOT source code files for the PHP programming language, PHP files are HTML templates that get run through the PHP preprocessor. Every PHP file is a more or less valid HTML file. This is the reason why you need to start your PHP files with the opening PHP tag, even if you’re not including any HTML.
17

If you’re omitting the starting PHP tag, your file be rendered as a slightly malformed HTML file, even though it has a PHP extension.
18

So remember this when you come across code that looks like this. I admit, it is a contrived example, but I found things like these more than once at the bottom of a long PHP file.
As you can see, my text editor, which is usually smarter than me, can’t even do any syntax highlighting for the HTML code, because we put everything in dumb strings.
Don’t do this!
19

Here’s the same file, with the PHP tags switched around.
Now we have complete syntax highlighting and code completion in all parts, so our text editor is happy. This is much easier to maintain and to debug. So, when you find yourself putting HTML inside your PHP into strings, that you will echo to get HTML back out, remember that you’re working in an HTML file already, just stop your preprocessor!
20

Uniform Resource Locators, or URLs specify the location of a resource on a computer network and a mechanism for retrieving it.
Here’s the complete syntax for an URL.
It starts with the “scheme”. This is normally the protocol that is used to communicate. For a normal web access, it is HTTP or HTTPS.
Then we have an optional user & password combo. This can be used for rudimentary access security but should be avoided in favor of other means, as transmitting the password in clear text is inherently insecure.
Now comes the domain. This can also be an IP address.
We can also add a port number to the domain. If we omit the port number, the default port for the current scheme will be used. For HTTP, this is port 80.
Then follows the path. It tells the server behind the domain your contacting, what resource you’re trying to get. This can be a combination of real files & folders on the
21

server, but it can also be a virtual representation of an arbitrary resource. Pretty URLs in WordPress are an example for this, as a specific post does not exist as file on the server, but you can nevertheless iterate this virtual representation of posts and pages.
You can add an arbitrary query string to the request by following the path with a question mark and name/value pairs that are separated by an ampersand. These pairs get put into GET variables and can be retrieved through PHP. As an example in WordPress, when you use the search box, the search results page gets loaded with a query string that contains the lowercase letter ‘s’ as the name and the text you’re looking for as the value.
Last but not least, we have the fragment identifier, which allows you to request a specific part or section within the resource. Within HTML files, you can target anchor elements or ID attributes with this identifier. The browser will then immediately scroll to the specified location within the document.
For each request, this URL specifies HOW you want to retrieve, WHERE you want to retrieve and WHAT you want to retrieve.
21

On a typical WordPress site, the URLs do not point to physical files. As we’ve seen earlier, the different posts and pages on our site do not have a corresponding HTML file on the server. So, what does the URL exactly point to, in this case?
WordPress has rewrite rules in place that define a specific pattern to look for and a URL template it can rewrite them into.
The cryptic pattern on the left are called regular expressions. I won’t bore you with the exact details here, they are a very dark art to master. The important bit you should note, though, is that they contain groups of symbols that are contained within parentheses. Both of the examples shown here contain two groups. When you now look at the URL templates in the second column, you can see that they contain a variable called “matches” that is followed by an index. This simply means that these variables get replaced by the corresponding groups that were found through our pattern.
The end result, after some more dark magic has happened, is that we get a new URL that points to a real physical file, in this case our index.php. It also includes arguments to the PHP file so that it knows what you want it to do.
22

WordPress is a full-fledged Content Management System, or CMS. It provides website authoring, collaboration and administration tools that allow users to manage dynamic website content. So, you don’t produce HTML files directly, you produce the different pieces of information that WordPress needs to produce the HTML file for you.
It has two main storage areas: The database and the filesystem.
The database contains the page content that you write for your pages and blog posts, metadata about this content, like what category it belongs to, or at what date it was published, user information about the users that can log into the site and make changes and configuration data like how the widgets are laid out or what the RSS feed will publish.
The filesystem contains the theme files that tell it how to properly display the different pages and posts, plugin files to extend existing WordPress functionality as well as the media files that are referenced in your pages and posts.
What does a typical request to WordPress look like, then? What does this index.phpand all of the additional code that it pulls in do?
23

Well, it considers all of its data in the context of the URL that has been requested, runs this data through its active theme, let’s all of the active plugins do their work, and sends the generated result to the browser.
When the page is rendered inside the browser, it contains links to external files. The browser then requests these files from the filesystem of the server. This request bypasses WordPress, as the index.php is not executed in this instance.
23
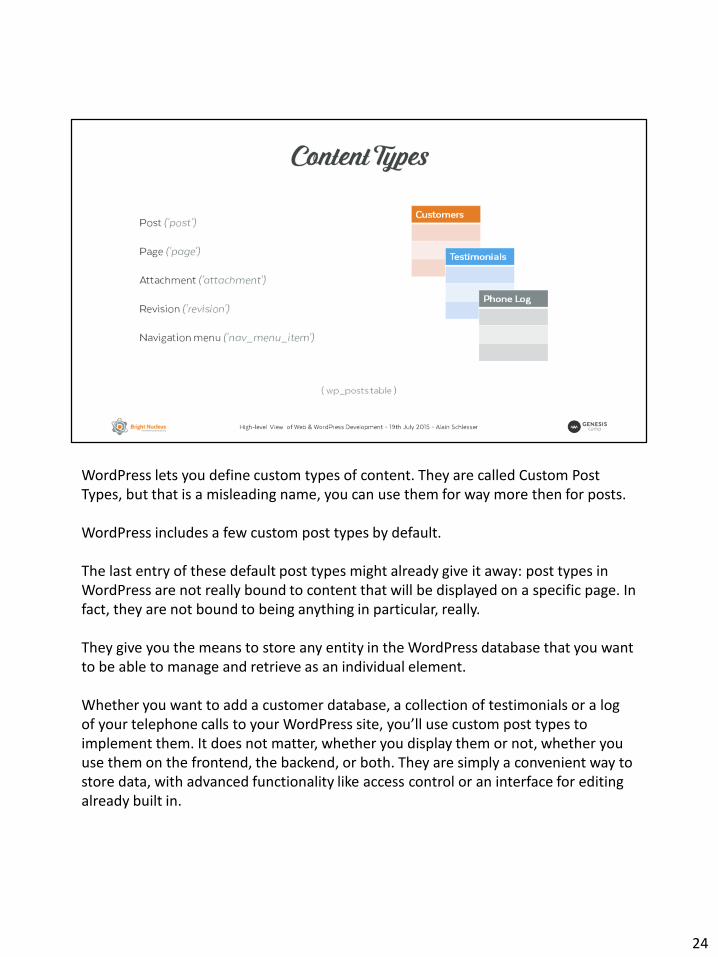
WordPress lets you define custom types of content. They are called Custom Post Types, but that is a misleading name, you can use them for way more then for posts.
WordPress includes a few custom post types by default.
The last entry of these default post types might already give it away: post types in WordPress are not really bound to content that will be displayed on a specific page. In fact, they are not bound to being anything in particular, really.
They give you the means to store any entity in the WordPress database that you want to be able to manage and retrieve as an individual element.
Whether you want to add a customer database, a collection of testimonials or a log of your telephone calls to your WordPress site, you’ll use custom post types to implement them. It does not matter, whether you display them or not, whether you use them on the frontend, the backend, or both. They are simply a convenient way to store data, with advanced functionality like access control or an interface for editing already built in.
24

Custom post types get stored in the wp_posts table.
24

If you create a custom post type in WordPress, it includes a fixed set of fields that can be stored for each entry, like the title, the content, the author, the status, and so on.
This is all information ABOUT posts. A post HAS A title. A post HAS A status. But what if the predefined fields are not enough? Let’s say, we implemented the phone log we talked about in the previous slide, and we now want to also store the duration of each call. The existing fields don’t quite fit for this. So we simply add a CUSTOM METADATA field, that gets associated with the phone calls.
So, we can store custom data inside the WordPress database, and we can store custom attributes about this data inside the WordPress database. But there’s one more entity you need to know about.
Custom metadata gets stored in the wp_postmeta table.
25

WordPress has two built-in taxonomies that you can use: ‘Categories’ and ‘Tags’.
Taxonomies are a way to divide your content into subsets, so you can retrieve them easily based on this criteria.
Of course you can also create custom taxonomies, that let you define other types of subsets. For our Phone Log example, we might want to filter the calls by Country. Although we could add a custom metadata field for the country, this would not be the best way to do it. Data you need for grouping should go into taxonomies, because this lets WordPress know that the main purpose of it is to be used as a query filter, so WordPress adds all kinds of stuff in the database to makes this faster.
So, our phone log now gets completed by adding a custom taxonomy called “Countries”.
Custom taxonomy terms get stored in the wp_terms table, while the relationships between terms and posts gets stored in both the wp_term_taxonomy and the wp_term_relationships table.
26
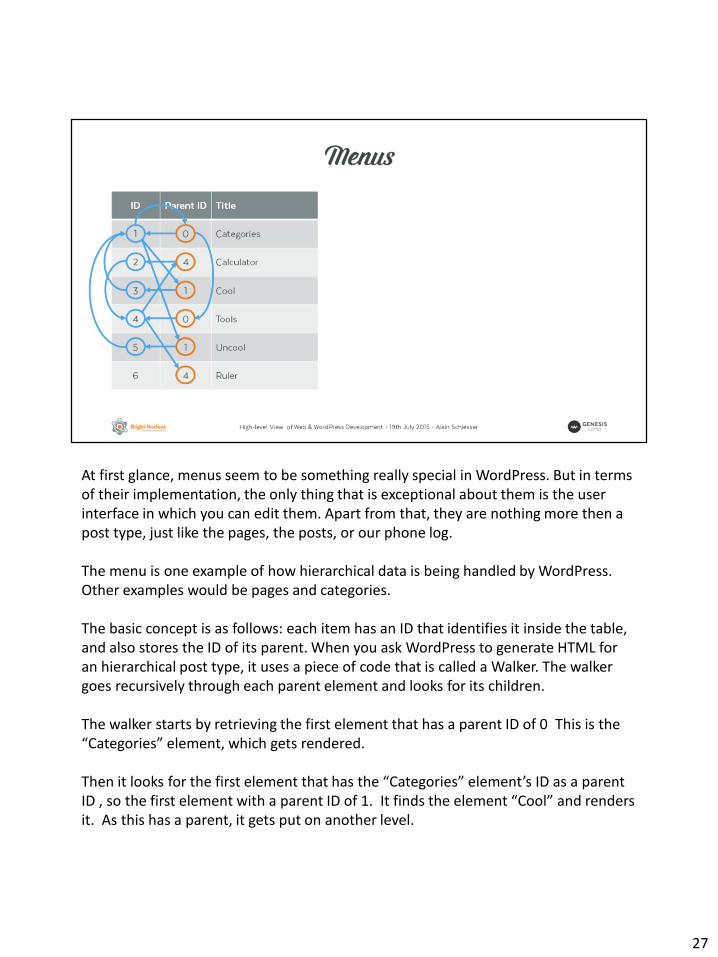
At first glance, menus seem to be something really special in WordPress. But in terms of their implementation, the only thing that is exceptional about them is the user interface in which you can edit them. Apart from that, they are nothing more then a post type, just like the pages, the posts, or our phone log.
The menu is one example of how hierarchical data is being handled by WordPress. Other examples would be pages and categories.
The basic concept is as follows: each item has an ID that identifies it inside the table, and also stores the ID of its parent. When you ask WordPress to generate HTML for an hierarchical post type, it uses a piece of code that is called a Walker. The walker goes recursively through each parent element and looks for its children.
The walker starts by retrieving the first element that has a parent ID of 0 This is the “Categories” element, which gets rendered.
Then it looks for the first element that has the “Categories” element’s ID as a parent ID , so the first element with a parent ID of 1. It finds the element “Cool” and renders it. As this has a parent, it gets put on another level.
27

Then it looks for an element that has the parent ID 3. As it does not find any elements with this parent ID, it goes back to the level above. It nows looks for the next element with a parent ID of 1. It finds “Uncool” at renders it at the appropriate level.
Next, it checks for an element with a parent ID of 5. No element found, so it goes back to the level above. It now looks for another element with the parent ID 1. As it does not find more elements like this, it goes back up to the root parent 0. So now it looks for the element that has a parent ID of 0 and finds “Tools”. “Tools” gets rendered as another top-level item.
Now it checks for the first element with the parent ID 4 and finds “Calculator” and renders it.
Next, it checks for elements with the parent ID 2. As it finds none, it returns to the previous level.
It then looks for the next element with the parent ID 4 and finds “Ruler” and renders it.
Okay… I’ll stop here. This system simply goes on until it has run out of child elements to its root parent.
The walker has four methods that are used to render the tree: “Start level”, “End level”, “Start Element” and “End Element”. This makes it easy to generate an unordered HTML list, for example.
27

WordPress provides you with something called Sidebars. Unfortunately, as with most things in WordPress, the name is misleading. As WordPress started as a blogging platform, sidebars were exactly that: bars at the side of your blog.
So, to give you the means to insert something into this area, you get a placeholder that can be filled with widgets, which we’ll cover later.
Most people envision Sidebars as a means to define areas somewhere on the page where you can put stuff into. But that is not exactly what happens.
PHP and HTML files are linear , they do not have two dimensions. One element cannot be besides another one, it can only ever be BEFORE or AFTER another element. The browser might display elements side by side, but while you’re coding, everything is a simple linear text file.
So, what really happens with sidebars, is that, despite their very specific name, they are a completely generic placeholder that you can put anywhere in your HTML. You can use a sidebar to display sidebars, of course. But you can also use a sidebar to display a navigation bar. You can use a sidebar to display the footer. You can use a
28

sidebar to display an ad in the middle of a post. You can use a sidebar to generate your SEO fields. You can use a sidebar to insert JavaScript into a page. You can… well, you can do a lot of things with sidebars.
28

We mentioned widgets before when I told you that you can use them inside sidebars. What exactly are they?
Well, you can think of them as interactive HTML snippets. Wherever they get executed, they check their current parameters and then return an HTML snippet that has been adapted according to these parameters.
You can freely choose in what sidebar you wish to put them.
This makes it possible to have reusable snippets of HTML that can be freely positioned within the document using drag & drop.
29

Actions are a mechanism that allows you to place markers in your code that allows other plugins or themes to insert their own code in addition to yours.
Here we have a rather silly example of an action that has been defined. This is done through the do_action function. The parameter you pass to the do_action function acts as a label of sorts. Other developers who know about this label can write code that gets executed at that exact moment of execution.
So, let’s say we have two different functions in two different plugins.
When the code on the left gets executed, it runs through its statements like any other normal PHP file.
When it hits the do_action function , it asks WordPress to execute all the callback function that have been registered with the “print_footer” label.
These actions have priorities so that we have control over the order in which they are run. When you omit to define a priority, the default value of 10 is used.
30

So, in this case, we have a function with the default priority of 10, and a function with the priority 5. The lowest priority gets executed first, so our code execution jumps to func2 and executes it.
Once this is done, it jumps to func1 and executes this as well.
Finally, it returns to resume normal code execution.
30

Filters are similar to hooks, in that they can be registered for a specific “label”. The main difference is that they pass a value to the callback function, and use whatever they get back as return value.
So in this example, we have defined a filter labelled “name_of_captain”. It allows other plugins or themes to change the name of the captain before it is returned.
In another plugin, we could now add a callback function to this filter. Here, we change the abbreviated name “Mal” into “Malcolm”. If we had not added this filter, the default name would have simply been used.
Actions & Filters together are commonly referred to as hooks.
31

A WordPress Theme is basically a collection of templates. WordPress has a hierarchy that it walks through to see what template gets called. It looks first for the most specialized template file that could fit the current context, and the gradually looks for more and more generic templates. If no other specialized template file is found, it falls back to the general index.php.
Here we have the basic structure of a template file.
There are two functions that call other templates, one for the header and one for the footer .
Between these two, we are executing something called “The Loop” within WordPress.
32

The Loop is the mechanism that allows you to iterate through a collection of posts. Remember that posts does not only include the built-in post type called “post”, but all built-in and custom defined post types. So, whatever post type we’re dealing with, we can use The Loop to cycle through it, even our Phone Log post type.
It basically works like this:
WordPress defines a global variable called $post. When you are outside The Loop, this variable is empty.
Running The Loop inside a template starts by examining the current query to see if the database returned some elements.
If it has, we keep cycling as long as this is true.
We now execute a function called “the_post”. This retrieves the next post and sets up the global variable.
Now we can use the functions that render parts of the current post like the title, or
33

the <content>. These only work inside The Loop, because they retrieve their data from the global $post variable.
Then we get back to our while condition and check if it is still true.
If it is we retrieve the next post and can then render this one too .
So, if you encounter functions where the WordPress Codex tells you that they can only be used within The Loop, it is because they are using the global $post variable to get their data.
33

So, after all we’ve seen, now… what are plugins, then?
To adapt WordPress to your needs, you want to be able to make lots of changes. But changing the source file of the WordPress core itself is a bad idea, as these changes will be overwritten with the next update.
This is why WordPress has a folder for plugins where you can put PHP files into that contain special comments to tell WordPress that it is dealing with a plugin.
Here you can see the basic setup of such a plugin. The comments are important for the plugin to correctly load, and you need to make sure that there’s no spelling errors in the terms that WordPress is looking for.
What can you do inside a plugin? Well, WordPress just wants to know where to find the entry point into your plugin, and then executes it with every request. The rest is up to you. You can use pretty much everything that we’ve covered so far in your plugins, and much more.
In this example, our plugin adds a callback function to the wp_header action, which
34

echoes a string when it gets called.
34

WordPress has been much more than a blogging platform for years now, and it has a lot of great features that make it a suitable backend for not only simple websites, but entire web applications.
You can manage all sorts of content inside your WordPress site.
This example shows a league management system. You can see that we can easily add all elements to the WordPress database that are needed to manage the teams, the players, the matches, and everything else.
35
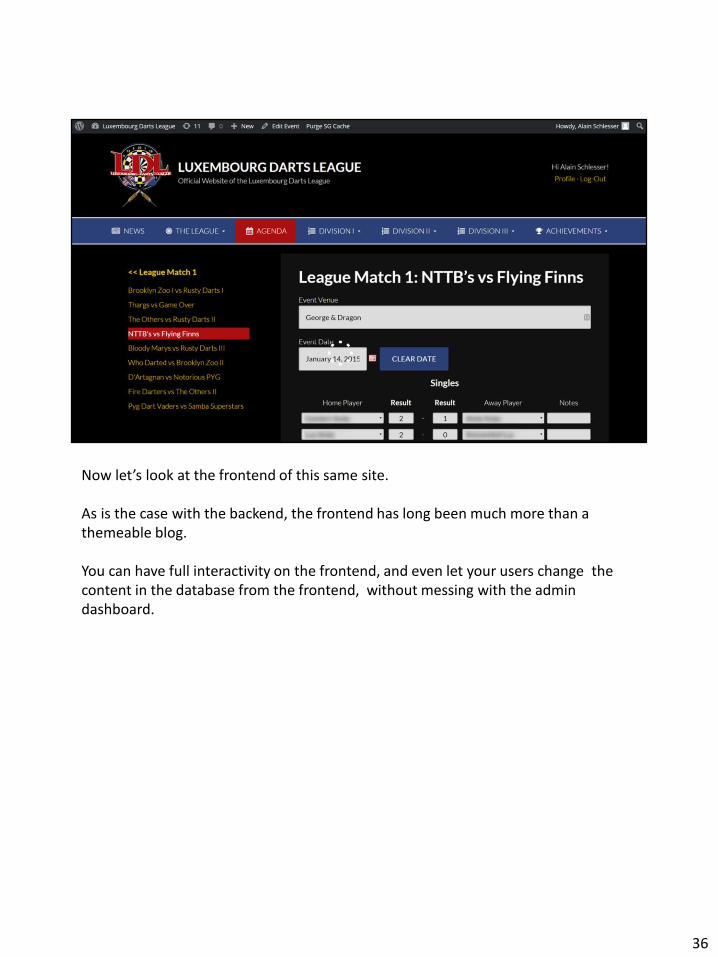
Now let’s look at the frontend of this same site.
As is the case with the backend, the frontend has long been much more than a themeable blog.
You can have full interactivity on the frontend, and even let your users change the content in the database from the frontend, without messing with the admin dashboard.
36

As a last topic I want to discuss the output that WordPress generates, the HTML file that gets sent to the browser.
As I already mentioned in an earlier slide, the entire HTML output that gets sent to the browser is one single, linear file. You don’t send a package of files that contains HTML, images, JavaScript, and so on. Although you can include a resource inline in the HTML file, the result will then still only be one single, linear file.
WordPress does not send any HTML content to the browser, this is all done in the theme. Without theme, WordPress will not return anything to the browser.
So, knowing, that, if you see something on your site that you’d like to change, the question “Can this be done with WordPress?” can always be answered with ‘yes’. WordPress lets your theme control what gets sent to the browser, so you have complete control over the final result. It might be a lot of work, though, if you’re trying to go completely against what WordPress offers out-of-the-box.
Just compare the current HTML output with the future HTML output you’d like to have. You’ll get a set of necessary changes. As long as you find a way to incorporate
37

these changes with any or all of the mechanisms I just mentioned in this session, you’re good to go.
For good maintainability, you might prefer to make the changes in way that is update-proof and reuses as much existing WordPress code as possible. But if WordPress does not offer any obvious way to do it this way, you can always completely replace parts of it. Can’t get the navigation into the shape you want it to have? Just write one from scratch and hook it up in your theme.
Please note that I don’t want you to think that you need to replace entire parts of WordPress all over. But it doesn’t hurt to get creative from time to time.
37

38


















