Hadoop Summit 2014: Processing Complex Workflows in Advertising Using Hadoop
24
SMART VIDEO ADVERTISING Processing Complex Workflows in Advertising Using Hadoop June 3 rd , 2014
-
Upload
bernardo-de-seabra -
Category
Technology
-
view
102 -
download
0
Transcript of Hadoop Summit 2014: Processing Complex Workflows in Advertising Using Hadoop

S M A R T V I D E O A D V E R T I S I N G
Processing Complex Workflows
in Advertising Using Hadoop
June 3rd, 2014

Who we are
Rahul Ravindran Bernardo de Seabra
Data Team Data Team
[email protected] [email protected]
@bseabra

Agenda
• Introduction to BrightRoll• Data Consumer Requirements • Motivation• Design
– Streaming log data into HDFS– Anatomy of an event– Event de-duplication– Configuration driven processing– Auditing
• Future

Introduction: BrightRoll
• Largest Online Video Advertisement Platform
• BrightRoll builds technology that improves and automates video advertising globally
• Reaching 53.9% of US audience, 168MM unique viewers
• 3+ Billion video ads / month
• 20+ Billion events processed / day

Data Consumer Requirements
• Processing results– Campaign delivery
– Analytics
– Telemetry
• Consumers of processed data– Delivery algorithms to augment decision behavior
– Campaign managers to monitor/tweak campaigns
– Billing system
– Forecasting/planning tools
– Business Analysts: long/short term analysis

Motivation – legacy data pipeline
• Not linearly scale-able
• Unit of processing was single campaign
• Not HA
• Lots of moving parts, no centralized control and monitoring
• Failure recovery was time consuming

Motivation – legacy data pipeline
• Lots of boilerplate code
– hard to onboard new data/computations
• Interval based processing
– 2 hour sliding window
– Inherited delay
– Inefficient use of resources
• All data must be retrieved prior to processing

Performance requirements
• Low end-to-end delivery of aggregated metrics
– Feedback loop into delivery algorithm
– Campaign managers can react faster to their campaign performance
• Linearly scalable

Design decisions
• Streaming model– Data is continuously being written
– Process data once
– Checkpoint states
– Low end-to-end latency (5 mins)
• Idempotent– Jobs can fail, tasks can fail, allows repeatability
• Configuration driven join semantics– Ease of on-boarding new data/computations

Overview Data Processing Pipeline
ProcessDe-duplicate Store
HDFS
M/R HBase
Data
Data Producers
Flume NG
Data Warehouse

Stream log data into HDFS using Flume
Adserv
Adserv
Adserv
HDFS
Flume
• Flume rolls files every 2 minutes
• Files lexicographically ordered
• Treat files written from flume to be a stream
• Maintain a marker which points to current location in the input stream
• Enables us to always process new data
logs
logs
logs

File.1239
File.1238
File.1237
File.1236
File.1235
File.1234
Marker
Files written by Flume

Event Header Event payload
Event ID Event timestamp
Event type Machine id
Anatomy of an event

De-duplication
Raw logs Hbase table
• We load raw logs into an hbase table
• We use hbase table as a stream
• We keep track of a time-based marker per table which represents a point in time up to which we have processed data
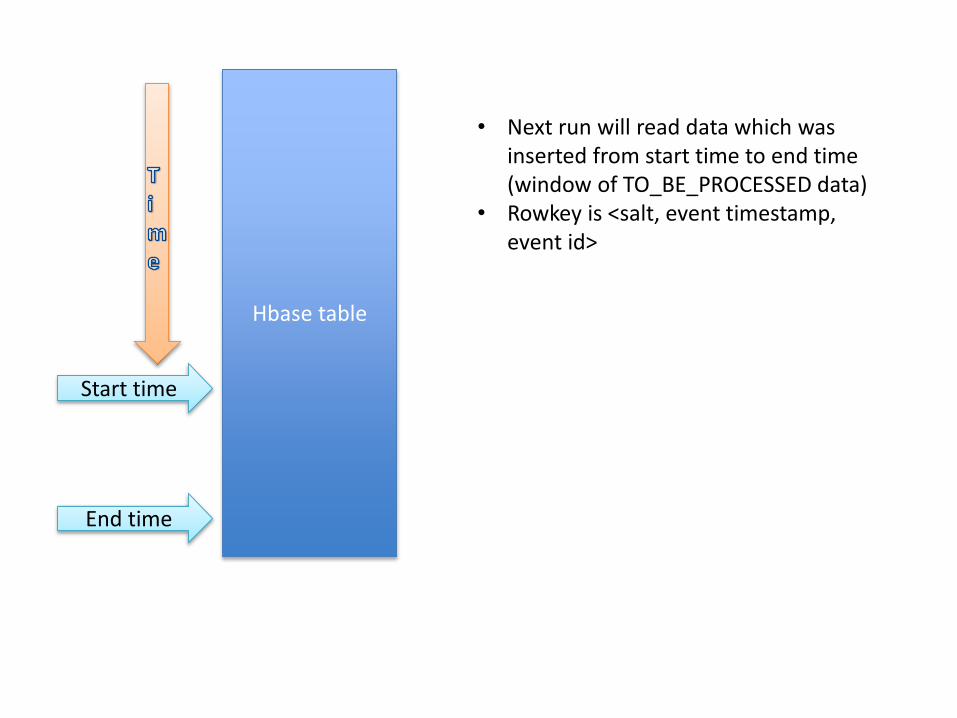
Hbase table
Start time
End time
• Next run will read data which was inserted from start time to end time (window of TO_BE_PROCESSED data)
• Rowkey is <salt, event timestamp, event id>

Chunk 1
Chunk 3
Chunk 2
• Break up data in WINDOW_TO_BE_PROCESSED into chunks
• Each chunk has same salt and contiguous event timestamp
• Each chunk is sorted – artifact of hbase storage
Salt time id
4 1234 Foobar1
4 1234 Foobar2
4 1235 Foobar3
6 1234 Foobar4
7 1235 Foobar5
7 1236 foobar6

StartRow
EndRow
Historical Scan without time range ,
multi-versions
• New Scan object gives historical view
• Perform de-duplication of data in chunk based on historical view
Key Event payload
4,1234, foobar1
4,1234, foobar2
4,1235, foobar3

De-duplication performance
• High Dedup throughput – 1.2+ million events per second
• Dedup across 4 days of historical data
StartRow/EndRowscan
TimeRange scan
Compaction co-processor to
compact files older than table start
Time

Processing - Joins
Impression Auction Computation

Arbitrary joins
• Use of an mechanism very similar to the de-duplication previously described
• Historical scan now checks for other events specified in the join
• Business level de-duplication – duplicate impressions for same auction performed here as well
• “Session debugging”

Auditing
Adserv
Adserv
Adserv
Metadata
Auditor
Metadata
Machine id #events
Time interval
Deduped.1 Deduped.2 Deduped.3
Disk Replay

What we have now
• All the stuff we have talked about plus system which
– Scales linearly
– HA within our data center
– HA across data centers (by switching traffic)
– Allows us to on-board new computations easily
– Provide guarantees on consumption on data in pipeline

Future
• Move to HBase 0.98/1.x
• Further improvements to De-duplication algorithm
• Dynamic definition of join semantics
• HDFS Federation

Questions