
Boulder/Denver BigData: Cluster Computing with Apache Mesos and Cascading
Upload
paco-nathanCategory
view
1.679download
1
Paco Nathanliber118.com/pxn/
“Enterprise Data Workflows with Cascading and Mesos”
Licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
1Saturday, 27 July 13

Cascading / Cascalog / Scalding
Enterprise Data Workflows with Cascading
Cluster Computing with Mesos
Looking ahead…
2Saturday, 27 July 13

Cascading – origins
API author Chris Wensel worked as a system architect at an Enterprise firm well-known for many popular data products.
Wensel was following the Nutch open source project – where Hadoop started.
Observation: would be difficult to find Java developers to write complex Enterprise apps in MapReduce – potential blocker for leveraging new open source technology.
3Saturday, 27 July 13

Cascading – functional programming
Key insight: MapReduce is based on functional programming – back to LISP in 1970s. Apache Hadoop use cases are mostly about data pipelines, which are functional in nature.
To ease staffing problems as “Main Street” Enterprise firms began to embrace Hadoop, Cascading was introduced in late 2007, as a new Java API to implement functional programming for large-scale data workflows:
• leverages JVM and Java-based tools without anyneed to create new languages
• allows programmers who have J2EE expertise to leverage the economics of Hadoop clusters
4Saturday, 27 July 13

Cascading – functional programming
• Twitter, eBay, LinkedIn, Nokia, YieldBot, uSwitch, etc., have invested in open source projects atop Cascading – used for their large-scale production deployments
• new case studies for Cascading apps are mostly based on domain-specific languages (DSLs) in JVM languages which emphasize functional programming:
Cascalog in Clojure (2010)Scalding in Scala (2012)
github.com/nathanmarz/cascalog/wikigithub.com/twitter/scalding/wiki
Why Adopting the Declarative Programming Practices Will Improve Your Return from TechnologyDan Woods, 2013-04-17 Forbes
forbes.com/sites/danwoods/2013/04/17/why-adopting-the-declarative-programming-practices-will-improve-your-return-from-technology/
5Saturday, 27 July 13

Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
Cascading – integrations
• partners: Microsoft Azure, Hortonworks, Amazon AWS, MapR, EMC, SpringSource, Cloudera
• taps: Memcached, Cassandra, MongoDB, HBase, JDBC, Parquet, etc.
• serialization: Avro, Thrift, Kryo, JSON, etc.
• topologies: Apache Hadoop, tuple spaces, local mode
6Saturday, 27 July 13

Cascading – deployments
• case studies: Climate Corp, Twitter, Etsy, Williams-Sonoma, uSwitch, Airbnb, Nokia, YieldBot, Square, Harvard, Factual, etc.
• use cases: ETL, marketing funnel, anti-fraud, social media, retail pricing, search analytics, recommenders, eCRM, utility grids, telecom, genomics, climatology, agronomics, etc.
7Saturday, 27 July 13

Cascading – deployments
• case studies: Climate Corp, Twitter, Etsy, Williams-Sonoma, uSwitch, Airbnb, Nokia, YieldBot, Square, Harvard, Factual, etc.
• use cases: ETL, marketing funnel, anti-fraud, social media, retail pricing, search analytics, recommenders, eCRM, utility grids, telecom, genomics, climatology, agronomics, etc.
workflow abstraction addresses: • staffing bottleneck; • system integration; • operational complexity; • test-driven development
8Saturday, 27 July 13

DocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
1 map 1 reduce18 lines code gist.github.com/3900702
WordCount – conceptual flow diagram
cascading.org/category/impatient
9Saturday, 27 July 13

WordCount – Cascading app in Java
String docPath = args[ 0 ];String wcPath = args[ 1 ];Properties properties = new Properties();AppProps.setApplicationJarClass( properties, Main.class );HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink tapsTap docTap = new Hfs( new TextDelimited( true, "\t" ), docPath );Tap wcTap = new Hfs( new TextDelimited( true, "\t" ), wcPath );
// specify a regex to split "document" text lines into token streamFields token = new Fields( "token" );Fields text = new Fields( "text" );RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ \\[\\]\\(\\),.]" );// only returns "token"Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );// determine the word countsPipe wcPipe = new Pipe( "wc", docPipe );wcPipe = new GroupBy( wcPipe, token );wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flowFlowDef flowDef = FlowDef.flowDef().setName( "wc" ) .addSource( docPipe, docTap ) .addTailSink( wcPipe, wcTap );// write a DOT file and run the flowFlow wcFlow = flowConnector.connect( flowDef );wcFlow.writeDOT( "dot/wc.dot" );wcFlow.complete();
DocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
10Saturday, 27 July 13

map
reduceEvery('wc')[Count[decl:'count']]
Hfs['TextDelimited[[UNKNOWN]->['token', 'count']]']['output/wc']']
GroupBy('wc')[by:['token']]
Each('token')[RegexSplitGenerator[decl:'token'][args:1]]
Hfs['TextDelimited[['doc_id', 'text']->[ALL]]']['data/rain.txt']']
[head]
[tail]
[{2}:'token', 'count'][{1}:'token']
[{2}:'doc_id', 'text'][{2}:'doc_id', 'text']
wc[{1}:'token'][{1}:'token']
[{2}:'token', 'count'][{2}:'token', 'count']
[{1}:'token'][{1}:'token']
WordCount – generated flow diagramDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
11Saturday, 27 July 13
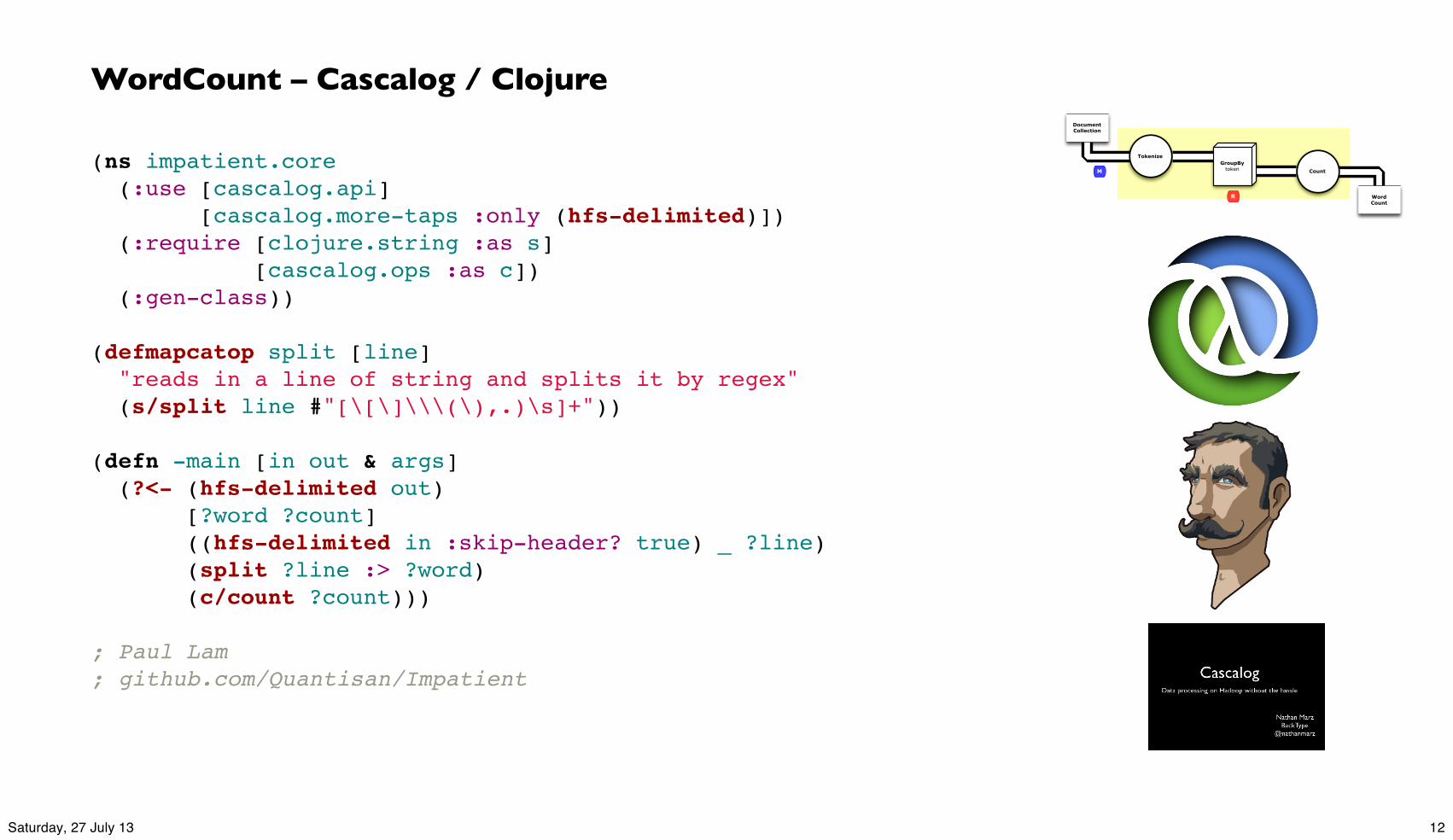
(ns impatient.core (:use [cascalog.api] [cascalog.more-taps :only (hfs-delimited)]) (:require [clojure.string :as s] [cascalog.ops :as c]) (:gen-class))
(defmapcatop split [line] "reads in a line of string and splits it by regex" (s/split line #"[\[\]\\\(\),.)\s]+"))
(defn -main [in out & args] (?<- (hfs-delimited out) [?word ?count] ((hfs-delimited in :skip-header? true) _ ?line) (split ?line :> ?word) (c/count ?count)))
; Paul Lam; github.com/Quantisan/Impatient
WordCount – Cascalog / ClojureDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
12Saturday, 27 July 13

github.com/nathanmarz/cascalog/wiki
• implements Datalog in Clojure, with predicates backed by Cascading – for a highly declarative language
• run ad-hoc queries from the Clojure REPL –approx. 10:1 code reduction compared with SQL
• composable subqueries, used for test-driven development (TDD) practices at scale
• Leiningen build: simple, no surprises, in Clojure itself
• more new deployments than other Cascading DSLs – Climate Corp is largest use case: 90% Clojure/Cascalog
• has a learning curve, limited number of Clojure developers
• aggregators are the magic, and those take effort to learn
WordCount – Cascalog / ClojureDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
13Saturday, 27 July 13

import com.twitter.scalding._ class WordCount(args : Args) extends Job(args) { Tsv(args("doc"), ('doc_id, 'text), skipHeader = true) .read .flatMap('text -> 'token) { text : String => text.split("[ \\[\\]\\(\\),.]") } .groupBy('token) { _.size('count) } .write(Tsv(args("wc"), writeHeader = true))}
WordCount – Scalding / ScalaDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
14Saturday, 27 July 13

github.com/twitter/scalding/wiki
• extends the Scala collections API so that distributed lists become “pipes” backed by Cascading
• code is compact, easy to understand
• nearly 1:1 between elements of conceptual flow diagram and function calls
• extensive libraries are available for linear algebra, abstract algebra, machine learning – e.g., Matrix API, Algebird, etc.
• significant investments by Twitter, Etsy, eBay, etc.
• great for data services at scale
• less learning curve than Cascalog
WordCount – Scalding / ScalaDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
15Saturday, 27 July 13

Workflow Abstraction – pattern language
Cascading uses a “plumbing” metaphor in the Java API, to define workflows out of familiar elements: Pipes, Taps, Tuple Flows, Filters, Joins, Traps, etc.
Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Data is represented as flows of tuples. Operations within the flows bring functional programming aspects into Java
A Pattern LanguageChristopher Alexander, et al.amazon.com/dp/0195019199
16Saturday, 27 July 13

Workflow Abstraction – literate programming
Cascading workflows generate their own visual documentation: flow diagrams
in formal terms, flow diagrams leverage a methodology called literate programming
provides intuitive, visual representations for apps –great for cross-team collaboration
Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Literate ProgrammingDon Knuthliterateprogramming.com
17Saturday, 27 July 13

Workflow Abstraction – business process
following the essence of literate programming, Cascading workflows provide statements of business process
this recalls a sense of business process management for Enterprise apps (think BPM/BPEL for Big Data)
Cascading creates a separation of concerns between business process and implementation details (Hadoop, etc.)
this is especially apparent in large-scale Cascalog apps:
“Specify what you require, not how to achieve it.”
by virtue of the pattern language, the flow planner then determines how to translate business process into efficient, parallel jobs at scale
18Saturday, 27 July 13

Follow-Up…
blog, developer community, code/wiki/gists, maven repo, commercial products, etc.:
cascading.org
zest.to/group11
github.com/Cascading
conjars.org
goo.gl/KQtUL
concurrentinc.com
19Saturday, 27 July 13

Cascading / Cascalog / Scalding
Enterprise Data Workflows with Cascading
Cluster Computing with Mesos
Looking ahead…
20Saturday, 27 July 13

Anatomy of an Enterprise app
Definition a typical Enterprise workflow which crosses through multiple departments, languages, and technologies…
ETL dataprep
predictivemodel
datasources
enduses
21Saturday, 27 July 13

Anatomy of an Enterprise app
Definition a typical Enterprise workflow which crosses through multiple departments, languages, and technologies…
ETL dataprep
predictivemodel
datasources
enduses
ANSI SQL for ETL
22Saturday, 27 July 13

Anatomy of an Enterprise app
Definition a typical Enterprise workflow which crosses through multiple departments, languages, and technologies…
ETL dataprep
predictivemodel
datasources
endusesJ2EE for business logic
23Saturday, 27 July 13

Anatomy of an Enterprise app
Definition a typical Enterprise workflow which crosses through multiple departments, languages, and technologies…
ETL dataprep
predictivemodel
datasources
enduses
SAS for predictive models
24Saturday, 27 July 13

Anatomy of an Enterprise app
Definition a typical Enterprise workflow which crosses through multiple departments, languages, and technologies…
ETL dataprep
predictivemodel
datasources
enduses
SAS for predictive modelsANSI SQL for ETL most of the licensing costs…
25Saturday, 27 July 13

Anatomy of an Enterprise app
Definition a typical Enterprise workflow which crosses through multiple departments, languages, and technologies…
ETL dataprep
predictivemodel
datasources
endusesJ2EE for business logic
most of the project costs…
26Saturday, 27 July 13

ETL dataprep
predictivemodel
datasources
enduses
Lingual:DW → ANSI SQL
Pattern:SAS, R, etc. → PMML
business logic in Java, Clojure, Scala, etc.
sink taps for Memcached, HBase, MongoDB, etc.
source taps for Cassandra, JDBC,Splunk, etc.
Anatomy of an Enterprise app
Cascading allows multiple departments to combine their workflow components into an integrated app – one among many, typically – based on 100% open source
a compiler sees it all…
cascading.org
27Saturday, 27 July 13

a compiler sees it all…
ETL dataprep
predictivemodel
datasources
enduses
Lingual:DW → ANSI SQL
Pattern:SAS, R, etc. → PMML
business logic in Java, Clojure, Scala, etc.
sink taps for Memcached, HBase, MongoDB, etc.
source taps for Cassandra, JDBC,Splunk, etc.
Anatomy of an Enterprise app
Cascading allows multiple departments to combine their workflow components into an integrated app – one among many, typically – based on 100% open source
FlowDef flowDef = FlowDef.flowDef() .setName( "etl" ) .addSource( "example.employee", emplTap ) .addSource( "example.sales", salesTap ) .addSink( "results", resultsTap ); SQLPlanner sqlPlanner = new SQLPlanner() .setSql( sqlStatement ); flowDef.addAssemblyPlanner( sqlPlanner );
cascading.org
28Saturday, 27 July 13

a compiler sees it all…
ETL dataprep
predictivemodel
datasources
enduses
Lingual:DW → ANSI SQL
Pattern:SAS, R, etc. → PMML
business logic in Java, Clojure, Scala, etc.
sink taps for Memcached, HBase, MongoDB, etc.
source taps for Cassandra, JDBC,Splunk, etc.
Anatomy of an Enterprise app
Cascading allows multiple departments to combine their workflow components into an integrated app – one among many, typically – based on 100% open source
FlowDef flowDef = FlowDef.flowDef() .setName( "classifier" ) .addSource( "input", inputTap ) .addSink( "classify", classifyTap ); PMMLPlanner pmmlPlanner = new PMMLPlanner() .setPMMLInput( new File( pmmlModel ) ) .retainOnlyActiveIncomingFields(); flowDef.addAssemblyPlanner( pmmlPlanner );
29Saturday, 27 July 13

cascading.orgETL data
preppredictivemodel
datasources
enduses
Lingual:DW → ANSI SQL
Pattern:SAS, R, etc. → PMML
business logic in Java, Clojure, Scala, etc.
sink taps for Memcached, HBase, MongoDB, etc.
source taps for Cassandra, JDBC,Splunk, etc.
Anatomy of an Enterprise app
Cascading allows multiple departments to combine their workflow components into an integrated app – one among many, typically – based on 100% open source
visual collaboration for the business logic is a great way to improve how teams work together
FailureTraps
bonusallocation
employee
PMMLclassifier
quarterlysales
Join Countleads
30Saturday, 27 July 13

Lingual – CSV data in local file system
cascading.org/lingual
31Saturday, 27 July 13

Lingual – shell prompt, catalog
cascading.org/lingual
32Saturday, 27 July 13
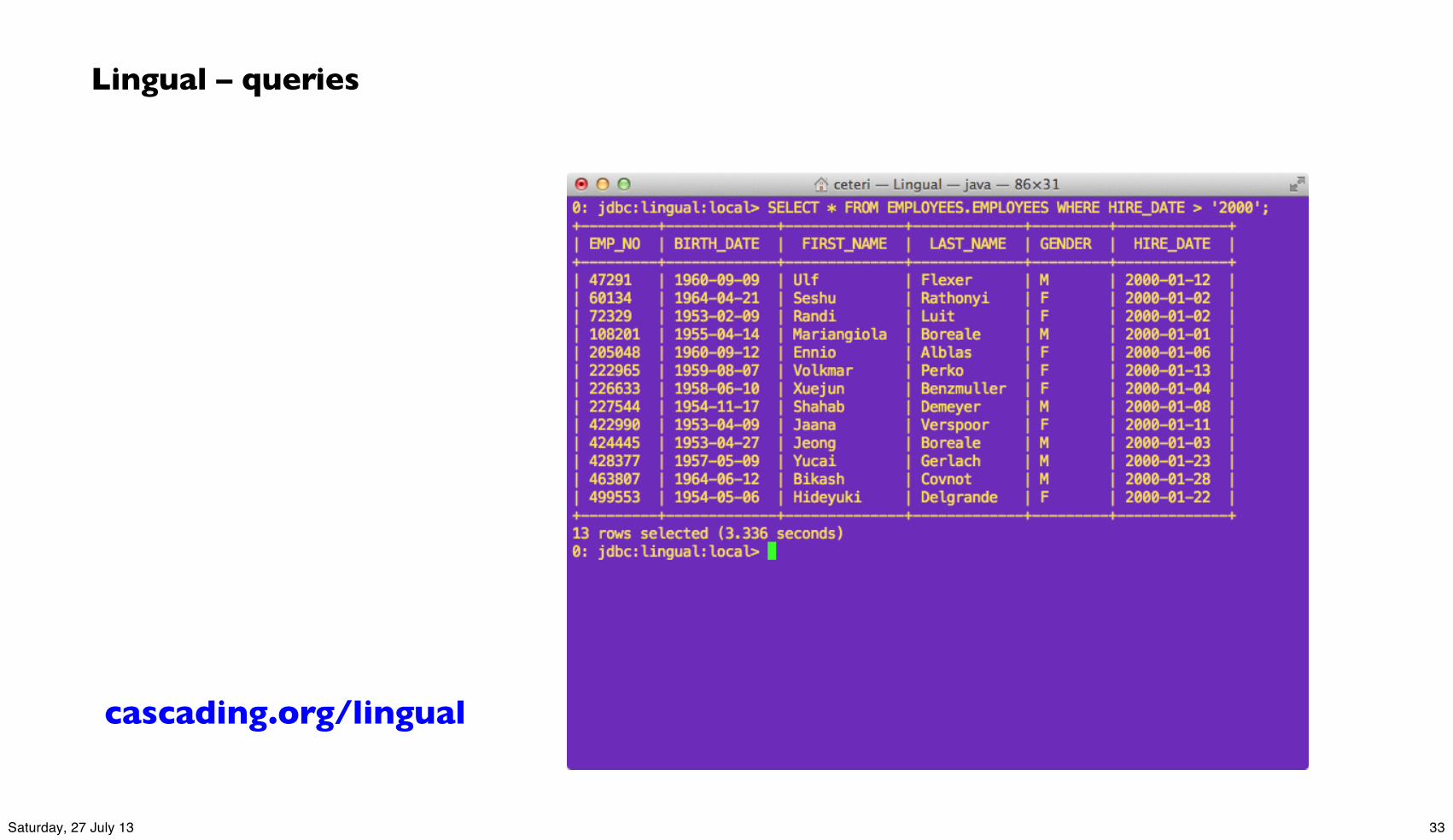
Lingual – queries
cascading.org/lingual
33Saturday, 27 July 13

# load the JDBC packagelibrary(RJDBC) # set up the driverdrv <- JDBC("cascading.lingual.jdbc.Driver", "~/src/concur/lingual/lingual-local/build/libs/lingual-local-1.0.0-wip-dev-jdbc.jar") # set up a database connection to a local repositoryconnection <- dbConnect(drv, "jdbc:lingual:local;catalog=~/src/concur/lingual/lingual-examples/tables;schema=EMPLOYEES") # query the repository: in this case the MySQL sample database (CSV files)df <- dbGetQuery(connection, "SELECT * FROM EMPLOYEES.EMPLOYEES WHERE FIRST_NAME = 'Gina'")head(df) # use R functions to summarize and visualize part of the datadf$hire_age <- as.integer(as.Date(df$HIRE_DATE) - as.Date(df$BIRTH_DATE)) / 365.25summary(df$hire_age)
library(ggplot2)m <- ggplot(df, aes(x=hire_age))m <- m + ggtitle("Age at hire, people named Gina")m + geom_histogram(binwidth=1, aes(y=..density.., fill=..count..)) + geom_density()
Lingual – connecting Hadoop and R
34Saturday, 27 July 13

> summary(df$hire_age) Min. 1st Qu. Median Mean 3rd Qu. Max. 20.86 27.89 31.70 31.61 35.01 43.92
Lingual – connecting Hadoop and R
cascading.org/lingual
35Saturday, 27 July 13

Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
Pattern – model scoring
• migrate workloads: SAS,Teradata, etc., exporting predictive models as PMML
• great open source tools – R, Weka, KNIME, Matlab, RapidMiner, etc.
• integrate with other libraries –Matrix API, etc.
• leverage PMML as another kind of DSL
cascading.org/pattern
36Saturday, 27 July 13

• established XML standard for predictive model markup
• organized by Data Mining Group (DMG), since 1997 http://dmg.org/
• members: IBM, SAS, Visa, NASA, Equifax, Microstrategy, Microsoft, etc.
• PMML concepts for metadata, ensembles, etc., translate directly into Cascading tuple flows
“PMML is the leading standard for statistical and data mining models and supported by over 20 vendors and organizations. With PMML, it is easy to develop a model on one system using one application and deploy the model on another system using another application.”
PMML – standard
wikipedia.org/wiki/Predictive_Model_Markup_Language
37Saturday, 27 July 13

PMML – vendor coverage
38Saturday, 27 July 13

• Association Rules: AssociationModel element
• Cluster Models: ClusteringModel element
• Decision Trees: TreeModel element
• Naïve Bayes Classifiers: NaiveBayesModel element
• Neural Networks: NeuralNetwork element
• Regression: RegressionModel and GeneralRegressionModel elements
• Rulesets: RuleSetModel element
• Sequences: SequenceModel element
• Support Vector Machines: SupportVectorMachineModel element
• Text Models: TextModel element
• Time Series: TimeSeriesModel element
PMML – model coverage
ibm.com/developerworks/industry/library/ind-PMML2/
39Saturday, 27 July 13

## train a RandomForest model f <- as.formula("as.factor(label) ~ .")fit <- randomForest(f, data_train, ntree=50) ## test the model on the holdout test set print(fit$importance)print(fit) predicted <- predict(fit, data)data$predicted <- predictedconfuse <- table(pred = predicted, true = data[,1])print(confuse) ## export predicted labels to TSV write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"), quote=FALSE, sep="\t", row.names=FALSE) ## export RF model to PMML saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/"))
Pattern – create a model in R
40Saturday, 27 July 13

<?xml version="1.0"?><PMML version="4.0" xmlns="http://www.dmg.org/PMML-4_0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.dmg.org/PMML-4_0 http://www.dmg.org/v4-0/pmml-4-0.xsd"> <Header copyright="Copyright (c)2012 Concurrent, Inc." description="Random Forest Tree Model"> <Extension name="user" value="ceteri" extender="Rattle/PMML"/> <Application name="Rattle/PMML" version="1.2.30"/> <Timestamp>2012-10-22 19:39:28</Timestamp> </Header> <DataDictionary numberOfFields="4"> <DataField name="label" optype="categorical" dataType="string"> <Value value="0"/> <Value value="1"/> </DataField> <DataField name="var0" optype="continuous" dataType="double"/> <DataField name="var1" optype="continuous" dataType="double"/> <DataField name="var2" optype="continuous" dataType="double"/> </DataDictionary> <MiningModel modelName="randomForest_Model" functionName="classification"> <MiningSchema> <MiningField name="label" usageType="predicted"/> <MiningField name="var0" usageType="active"/> <MiningField name="var1" usageType="active"/> <MiningField name="var2" usageType="active"/> </MiningSchema> <Segmentation multipleModelMethod="majorityVote"> <Segment id="1"> <True/> <TreeModel modelName="randomForest_Model" functionName="classification" algorithmName="randomForest" splitCharacteristic="binarySplit"> <MiningSchema> <MiningField name="label" usageType="predicted"/> <MiningField name="var0" usageType="active"/> <MiningField name="var1" usageType="active"/> <MiningField name="var2" usageType="active"/> </MiningSchema>...
Pattern – capture model parameters as PMML
41Saturday, 27 July 13

public static void main( String[] args ) throws RuntimeException { String inputPath = args[ 0 ]; String classifyPath = args[ 1 ]; // set up the config properties Properties properties = new Properties(); AppProps.setApplicationJarClass( properties, Main.class ); HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties ); // create source and sink taps Tap inputTap = new Hfs( new TextDelimited( true, "\t" ), inputPath ); Tap classifyTap = new Hfs( new TextDelimited( true, "\t" ), classifyPath ); // handle command line options OptionParser optParser = new OptionParser(); optParser.accepts( "pmml" ).withRequiredArg(); OptionSet options = optParser.parse( args ); // connect the taps, pipes, etc., into a flow FlowDef flowDef = FlowDef.flowDef().setName( "classify" ) .addSource( "input", inputTap ) .addSink( "classify", classifyTap ); if( options.hasArgument( "pmml" ) ) { String pmmlPath = (String) options.valuesOf( "pmml" ).get( 0 ); PMMLPlanner pmmlPlanner = new PMMLPlanner() .setPMMLInput( new File( pmmlPath ) ) .retainOnlyActiveIncomingFields() .setDefaultPredictedField( new Fields( "predict", Double.class ) ); // default value if missing from the model flowDef.addAssemblyPlanner( pmmlPlanner ); } // write a DOT file and run the flow Flow classifyFlow = flowConnector.connect( flowDef ); classifyFlow.writeDOT( "dot/classify.dot" ); classifyFlow.complete(); }
Pattern – score a model, within an app
42Saturday, 27 July 13

CustomerOrders
Classify ScoredOrders
GroupBytoken
Count
PMMLModel
M R
FailureTraps
Assert
ConfusionMatrix
Pattern – score a model, using pre-defined Cascading app
cascading.org/pattern
43Saturday, 27 July 13

Roadmap – existing algorithms for scoring
• Random Forest
• Decision Trees
• Linear Regression
• GLM
• Logistic Regression
• K-Means Clustering
• Hierarchical Clustering
• Multinomial
• Support Vector Machines (prepared for release)
also, model chaining and general support for ensembles
cascading.org/pattern
44Saturday, 27 July 13

Roadmap – next priorities for scoring
• Time Series (ARIMA forecast)
• Association Rules (basket analysis)
• Naïve Bayes
• Neural Networks
algorithms extended based on customer use cases – contact groups.google.com/forum/?fromgroups#!forum/pattern-user
cascading.org/pattern
45Saturday, 27 July 13

Cascading / Cascalog / Scalding
Enterprise Data Workflows with Cascading
Cluster Computing with Mesos
Looking ahead…
46Saturday, 27 July 13

Q3 1997: inflection point
Four independent teams were working toward horizontal scale-out of workflows based on commodity hardware
This effort prepared the way for huge Internet successesin the 1997 holiday season… AMZN, EBAY, Inktomi (YHOO Search), then GOOG
MapReduce and the Apache Hadoop open source stack emerged from this
47Saturday, 27 July 13

RDBMS
Stakeholder
SQL Queryresult sets
Excel pivot tablesPowerPoint slide decks
Web App
Customers
transactions
Product
strategy
Engineering
requirements
BIAnalysts
optimizedcode
Circa 1996: pre- inflection point
48Saturday, 27 July 13

RDBMS
Stakeholder
SQL Queryresult sets
Excel pivot tablesPowerPoint slide decks
Web App
Customers
transactions
Product
strategy
Engineering
requirements
BIAnalysts
optimizedcode
Circa 1996: pre- inflection point
“throw it over the wall”
49Saturday, 27 July 13

RDBMS
SQL Queryresult sets
recommenders+
classifiersWeb Apps
customertransactions
AlgorithmicModeling
Logs
eventhistory
aggregation
dashboards
Product
EngineeringUX
Stakeholder Customers
DW ETL
Middleware
servletsmodels
Circa 2001: post- big ecommerce successes
50Saturday, 27 July 13

RDBMS
SQL Queryresult sets
recommenders+
classifiersWeb Apps
customertransactions
AlgorithmicModeling
Logs
eventhistory
aggregation
dashboards
Product
EngineeringUX
Stakeholder Customers
DW ETL
Middleware
servletsmodels
Circa 2001: post- big ecommerce successes
“data products”
51Saturday, 27 July 13

Workflow
RDBMS
near timebatch
services
transactions,content
socialinteractions
Web Apps,Mobile, etc.History
Data Products Customers
RDBMS
LogEvents
In-Memory Data Grid
Hadoop, etc.
Cluster Scheduler
Prod
Eng
DW
Use Cases Across Topologies
s/wdev
datascience
discovery+
modeling
Planner
Ops
dashboardmetrics
businessprocess
optimizedcapacitytaps
DataScientist
App Dev
Ops
DomainExpert
introducedcapability
existingSDLC
Circa 2013: clusters everywhere
52Saturday, 27 July 13

Workflow
RDBMS
near timebatch
services
transactions,content
socialinteractions
Web Apps,Mobile, etc.History
Data Products Customers
RDBMS
LogEvents
In-Memory Data Grid
Hadoop, etc.
Cluster Scheduler
Prod
Eng
DW
Use Cases Across Topologies
s/wdev
datascience
discovery+
modeling
Planner
Ops
dashboardmetrics
businessprocess
optimizedcapacitytaps
DataScientist
App Dev
Ops
DomainExpert
introducedcapability
existingSDLC
Circa 2013: clusters everywhere
“optimize topologies”
53Saturday, 27 July 13

Amazon“Early Amazon: Splitting the website” – Greg Lindenglinden.blogspot.com/2006/02/early-amazon-splitting-website.html
eBay“The eBay Architecture” – Randy Shoup, Dan Pritchettaddsimplicity.com/adding_simplicity_an_engi/2006/11/you_scaled_your.htmladdsimplicity.com.nyud.net:8080/downloads/eBaySDForum2006-11-29.pdf
Inktomi (YHOO Search)“Inktomi’s Wild Ride” – Erik Brewer (0:05:31 ff)youtu.be/E91oEn1bnXM
Google“Underneath the Covers at Google” – Jeff Dean (0:06:54 ff)youtu.be/qsan-GQaeykperspectives.mvdirona.com/2008/06/11/JeffDeanOnGoogleInfrastructure.aspx
MIT Media Lab“Social Information Filtering for Music Recommendation” – Pattie Maespubs.media.mit.edu/pubs/papers/32paper.psted.com/speakers/pattie_maes.html
Primary Sources
54Saturday, 27 July 13

Operating Systems, redux
meanwhile, GOOG is 3+ generations ahead, with much improved ROI on data centers
John Wilkes, et al.Borg/Omega: data center “secret sauce”youtu.be/0ZFMlO98Jkc
0%
25%
50%
75%
100%
RAILS CPU LOAD
MEMCACHED CPU LOAD
0%
25%
50%
75%
100%
HADOOP CPU LOAD
0%
25%
50%
75%
100%
t t
0%
25%
50%
75%
100%
Rails MemcachedHadoop
COMBINED CPU LOAD (RAILS, MEMCACHED, HADOOP)
Florian Leibert, Chronos/Mesos @ Airbnb
Mesos, open source cloud OS – like Borggoo.gl/jPtTP
55Saturday, 27 July 13

Mesos
mesos.apache.org
Return of the Borg: How Twitter Rebuilt Google’s Secret WeaponCade Metzwired.com/wiredenterprise/2013/03/google-borg-twitter-mesos/
56Saturday, 27 July 13

Mesos
a common substrate for cluster computing
heterogenous assets in your data center or cloud made available as a homogenous set of resources
• leverages OS features in Linux/Unix
• obviates the need for virtual machines
• written in C++, with API for Python, Java, Scala, etc.
• available for Linux, Mac OSX, OpenSolaris
• developed by UC Berkeley, Twitter, Airbnb, Mesosphere, etc.
• deployments at Twitter, Airbnb, Conviva, Foursquare, Vimeo, Shopify, UCSF, UC Berkeley, etc.
57Saturday, 27 July 13

Mesos
a common substrate for cluster computing
• scale to 10,000s of nodes using fast, event-driven C++ impl
• maximize utilization rates, minimize latency for data updates
• combine batch, real-time, and long-lived services on the same nodes and share resources
• reshape clusters on the fly based on app history and workload requirements
• run multiple Hadoop versions, Spark, MPI, Heroku, HAProxy, etc., on the same cluster
• build new distributed frameworks without reinventing low-level facilities
• enable new kinds of apps, which combine frameworks with lower latency
• hire top talent out of Gxxxxx, providing a familiar data center env
58Saturday, 27 July 13

Mesos
Apache Projectmesos.apache.org
Mesospheremesosphe.re
Getting Startedmesosphe.re/tutorials
Documentationmesos.apache.org/documentation
Research Paperusenix.org/legacy/event/nsdi11/tech/full_papers/Hindman_new.pdf
Collected Notes/Archivesgoo.gl/jPtTP
59Saturday, 27 July 13

Cascading / Cascalog / Scalding
Enterprise Data Workflows with Cascading
Cluster Computing with Mesos
Looking ahead…
60Saturday, 27 July 13

A Crash Course in Machine Learning…
consider ML as an approach for generalization…
here’s a great introduction to ML, plus a proposed categorization for comparing different machine learning approaches:
A Few Useful Things to Know about Machine LearningPedro Domingos, U Washingtonhomes.cs.washington.edu/~pedrod/papers/cacm12.pdf
key points:
• representation: a classifier must be represented in some formal language that the computer can handle (algorithms, data structures, etc.)
• evaluation: an evaluation function (objective function, scoring function) is needed to distinguish good classifiers from bad ones
• optimization: a method to search among the classifiers in the language for the highest-scoring one
61Saturday, 27 July 13

Algorithms
many algorithm libraries used today are based on implementationsback when people used DO loops in FORTRAN, 30+ years ago
MapReduce is Good Enough?Jimmy Lin, U Marylandumiacs.umd.edu/~jimmylin/publications/Lin_BigData2013.pdf
astrophysics and genomics are light years ahead in sophisticated algorithms work – as Breiman suggested in 2001 – which may take a few years to percolate into industry
other game-changers:
• streaming algorithms, sketches, probabilistic data structures
• significant “Big O” complexity reduction (e.g., skytree.net)
• better architectures and topologies (e.g., GPUs and CUDA)
• partial aggregates – parallelizing workflows
62Saturday, 27 July 13

Make It Sparse…
also, take a moment to check this out… (IMHO most interesting algorithm work recently)
QR factorization of a “tall-and-skinny” matrix
• used to solve many data problems at scale, e.g., PCA, SVD, etc.
• numerically stable with efficient implementation on large-scale Hadoop clusters
suppose that you have a sparse matrix of customer interactions where there are 100MM customers, with a limited set of outcomes…
cs.purdue.edu/homes/dgleich
stanford.edu/~arbenson
github.com/ccsevers/scalding-linalg
David Gleich, slideshare.net/dgleich
Tristan Jehan
63Saturday, 27 July 13

Sparse Matrix Collection
for when you really need a wide variety of sparse matrix examples…
University of Florida Sparse Matrix Collectioncise.ufl.edu/research/sparse/matrices/
Tim Davis, U Floridacise.ufl.edu/~davis/welcome.html
Yifan Hu, AT&T Researchwww2.research.att.com/~yifanhu/
64Saturday, 27 July 13

A Winning Approach…
consider that if you know priors about a system, then you may be able to leverage low dimensional structure within high dimensional data… that works much, much better than sampling!
1. real-world data ⇒
2. graph theory for representation ⇒
3. sparse matrix factorization for production work ⇒
4. cost-effective parallel processing for machine learning app at scale
65Saturday, 27 July 13

Suggested Reading
when you have time, take a look through these selected articles…
A Few Useful Things to Know about Machine LearningPedro Domingos, U Washingtonhomes.cs.washington.edu/~pedrod/papers/cacm12.pdf
Probabilistic Data Structures for Web Analytics and Data MiningIlya Katsov, Grid Dynamicshighlyscalable.wordpress.com/2012/05/01/probabilistic-structures-web-analytics-data-mining/
MapReduce is Good Enough?Jimmy Lin, U Maryland + Twitterumiacs.umd.edu/~jimmylin/publications/Lin_BigData2013.pdf
66Saturday, 27 July 13

algorithmic modeling + machine data + curation, metadata + Open Data
⇒ data products, as feedback into automation
⇒ evolution of feedback loops
less about “bigness”, more about complexity
internet of things + A/D conversion + complex analytics ⇒ accelerated evolution, additional feedback loops
⇒ orders of magnitude higher data rates
Internet of Things accelerates this process of disruption
Business Drivers
source: National Geographic
“A kind of Cambrian explosion”
source: National Geographic
67Saturday, 27 July 13

Trendlines
Big Data? we’re just getting started:
• ~12 exabytes/day, jet turbines on commercial flights
• Google self-driving cars, ~1 Gb/s per vehicle
• National Instruments initiative: Big Analog Data™
• 1m resolution satellites skyboximaging.com
• open resource monitoring reddmetrics.com
• Sensing XChallenge nokiasensingxchallenge.org
consider the implications of Jawbone, Nike, etc., plus the secondary/tertiary effects of Google Glass
7+ billion people, instrumented better than … how we have Nagios instrumenting our web servers right now
technologyreview.com/...
68Saturday, 27 July 13

newsletter for updates: http://liber118.com/pxn/
shop.oreilly.com/product/0636920028536.do
69Saturday, 27 July 13


















