
H2O Open Source Deep Learning, Arno Candel 03-20-14
27
Deep Learning with H2O H2O.ai Scalable In-Memory Machine Learning H20 Meetup, Mountain View, 3/20/14 Arno Candel
-
Upload
srisatish-ambati -
Category
Technology
-
view
114 -
download
2
description
More information in our Deep Learning webinar: http://www.slideshare.net/0xdata/h2-o-deeplearningarnocandel052114 Latest slide deck: http://www.slideshare.net/0xdata/h2o-distributed-deep-learning-by-arno-candel-071614
Transcript of H2O Open Source Deep Learning, Arno Candel 03-20-14

Deep Learning with H2O
!
H2O.aiScalable In-Memory Machine Learning
!
H20 Meetup, Mountain View, 3/20/14
Arno Candel

Who am I?
PhD in Computational Physics, 2005from ETH Zurich Switzerland
!
6 years at SLAC - Accelerator Physics Modeling 2 years at Skytree, Inc - Machine Learning 3 months at 0xdata/H2O - Machine Learning
!
10+ years in HPC, C++, MPI, Supercomputing
Arno Candel

OutlineIntro
Theory
Implementation
Results
MNIST handwritten digits classification
Live Demo
Prostate cancer classification and age regression
text classification

Distributed in-memory math platform ➔ GLM, GBM, RF, K-Means, PCA, Deep Learning
Easy to use SDK / API➔ Java, R, Scala, Python, JSON, Browser-based GUI
!Businesses can use ALL of their data (w or w/o Hadoop)
➔ Modeling without Sampling
Big Data + Better Algorithms ➔ Better Predictions
H2O Open Source in-memoryPrediction Engine for Big Data

About H20 (aka 0xdata)Pure Java, Apache v2 Open Source Join the www.h2o.ai/community!

H2O w or w/o Hadoop
H2OH2O H2O
HDFS HDFS HDFS
YARN Hadoop MR
R Java Scala JSON Python
Standalone Over YARN On MRv1

H2O Architecture
in-memory K-V store MapReduce
compression
Machine Learning
Algorithms
R EngineNano fast
Scoring Engine
Prediction Engine
memory manager
e.g. Deep Learning

Wikipedia:
Deep learning is a set of algorithms in machine learning that attempt to model high-level abstractions in data by
using architectures composed of multiple non-linear transformations.
!!!!!
Facebook DeepFace (LeCun): “Almost as good as humans at recognising faces” !
Google Brain (Andrew Ng, Jeff Dean & Geoffrey Hinton) !
FBI FACE: $1 billion face recognition project
What is Deep Learning?
Example: Input data
(facial image)
Prediction (person’s ID)

Deep Learning is trending
20132012
Google trends
2011

1970s multi-layer feed-forward Neural Network (supervised learning with back-propagation) !+ distributed processing for big data (H2O in-memory MapReduce paradigm on distributed data) !+ multi-threaded speedup (H2O Fork/Join worker threads update the model asynchronously) !+ smart algorithms for accuracy (weight initialization, adaptive learning, momentum, dropout, regularization)
!
= Top-notch prediction engine!
Deep Learning in H2O
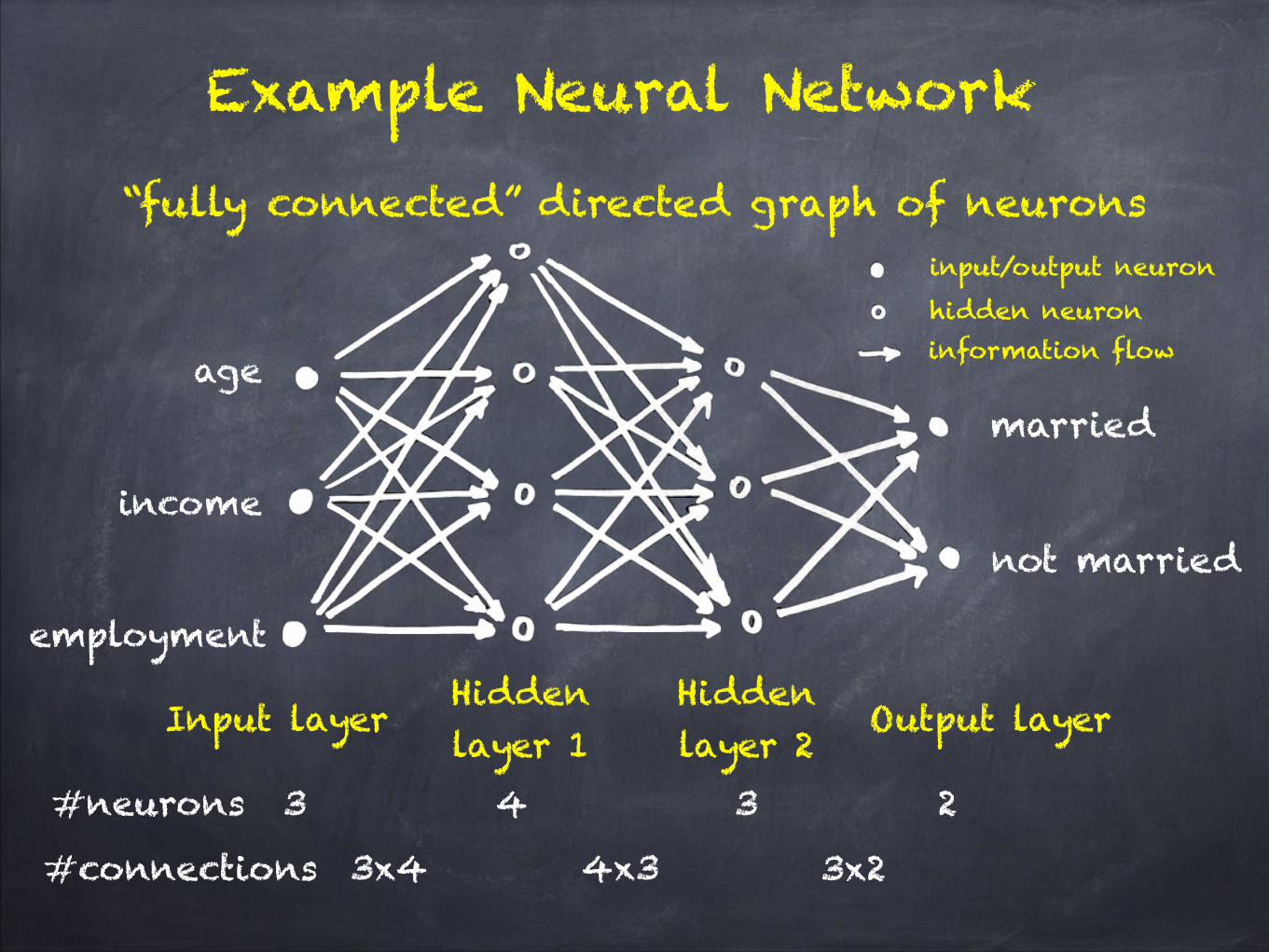
“fully connected” directed graph of neurons
age
income
employment
married
not married
Input layerHidden layer 1
Hidden layer 2
Output layer
3x4 4x3 3x2#connections
information flow
input/output neuronhidden neuron
4 3 2#neurons 3
Example Neural Network

age
income
employmentyj = tanh(sumi(xi*uij)+bj)
uij
xi
yj
per-class probabilities sum(pl) = 1
zk = tanh(sumj(yj*vjk)+ck)
vjk
zk pl
pl = softmax(sumk(zk*wkl)+dl)
wkl
softmax(xk) = exp(xk) / sumk(exp(xk))
“neurons activate each other via weighted sums”
Prediction: Forward Propagation
married
not married
activation function: tanh alternative:
x -> max(0,x) “rectifier”
pl is a non-linear function of xi: can approximate ANY function
with enough layers!
bj, ck, dl: bias values(indep. of inputs)

age
income
employment
xi
standardize input xi: mean = 0, stddev = 1 !
horizontalize categorical variables, e.g. {full-time, part-time, none, self-employed}
-> {0,1,0} = part-time, {0,0,0} = self-employed
Poor man’s initialization: random weights !
Better: Uniform distribution in+/- sqrt(6/(#units + #units_previous_layer))
Data preparation & InitializationNeural Networks are sensitive to numerical noise, operate best in the linear regime (not saturated)
married
not married

Mean Square Error = (0.2^2 + 0.2^2)/2 “penalize differences per-class” ! Cross-entropy = -log(0.8) “strongly penalize non-1-ness”
Stochastic Gradient Descent
SGD: improve weights and biases for EACH training row
married
not married
For each training row, we make a prediction and compare with the actual label (supervised training):
1
0
0.8
0.2
predicted actual
Objective: minimize prediction error (MSE or cross-entropy)
w <— w - rate * ∂E/∂w
1

Backward Propagation
!∂E/∂wi = ∂E/∂y * ∂y/∂net * ∂net/∂wi
= ∂(error(y))/∂y * ∂(activation(net))/∂net * xi
Backprop: Compute ∂E/∂wi via chain rule going backwards
wi
net = sumi(wi*xi) + b
xiE = error(y)
y = activation(net)
How to compute ∂E/∂wi for wi <— wi - rate * ∂E/∂wi ?
Naive: For every i, evaluate E twice at (w1,…,wi±∆,…,wN)… Slow!

H2O Deep Learning Architecture
K-V
K-V
HTTPD
HTTPD
nodes/JVMs: sync
threads: async
communication
w
w w
w w w w
w1 w3 w2w4
w2+w4w1+w3
w* = (w1+w2+w3+w4)/4
map: each node trains a copy of the weights
and biases with (some* or all of) its
local data with asynchronous F/J
threads
initial weights and biases w
updated weights and biases w*
H2O atomic in-memoryK-V store
reduce: average weights and biases from
all nodes
Keep iterating over the data (“epochs”), score from time to time
Query & display the model via
JSON, WWW
2
2 431
1
1
1
43 2
1 2
1
i
*mini-batch: number of total rows per iteration, can be less than 1 epoch

“Secret” Sauce to Higher Accuracy
Momentum training:keep changing weights and biases (even if there’s no error)
“find other local minima, and go faster along valleys”
Adaptive learning rate - ADADELTA (Google):automatically set learning rate for each neuron based on its training history, combines annealing and momentum features
Learning rate annealing: rate r = r0 / (1+ß*N), N = training samples
“dig deeper into local minimum”
Grid Search and Checkpointing: Run a grid search over multiple hyper-parameters,
then continue training the best model
L1/L2/Dropout/MaxSumWeights regularization: L1: penalizes non-zero weights, L2: penalizes large weights
Dropout: randomly ignore certain inputs “train exp. many models at once” MaxSumWeights: Reduce all incoming weights if the sum > max value
“regularization avoids overtraining and improves generalization error”

MNIST: digits classification
Train: 60,000 rows 784 integer columns 10 classes Test: 10,000 rows 784 integer columns 10 classes
MNIST: Digitized handwritten digits database (Yann LeCun) Data: 28x28=784 pixels with values in 0…255 (gray-scale) One of the most popular multi-class classification problems
Without distortions or convolutions (which help), the best-ever published error rate on test set: 0.83% (Microsoft)

most frequent mistakes: confuse 4 with 6 and 9, and 7 with 2
test set error: 1.5% after 40 epochs 1.02% after 400 epochs 0.95% after 4000 epochs
H2O Deep Learning on MNIST: 0.95% test set error (so far)
1 node

Prostate Cancer Dataset

Live Demo: Cancer Prediction
Interactive ROC curve with real-
time updates

Live Demo: Cancer Prediction
0% training error with only 322
model parameters in seconds!

Live Demo: Grid Search RegressionDoing a grid search to find good hyper-parameters
to predict AGE from other 7 features
Then continue training the best model 5 hidden 50 tanh layers, rho=0.99, epsilon = 1e-10
MSE < 1 for test set ages in 44…79
Regression: 1 linear output
neuron

Live Demo: ebay Text Classification
Users enter a description when selling an item Task: Predict the type of item Data prep: Binary word vector 0,0,1,0,0,0,0,0,1,0,0,0,1,…,0 H2O parses SVMLight sparse format: label 3:1 9:1 13:1 … !
“Small” sample dataset on jewelry and watches: Train: 578,361 rows 8,647 cols 467 classes Test: 64,263 rows 8,647 cols 143 classes !H2O compressed columnar in-memory store: Only needs 60MB to store 5 billion entries (never inflated)

Live Demo: ebay Text Classification
Work in progress, shown results are for illustration only! Default parameters, no tuning, 4 nodes (16-cores each)
Train: 578,361 rows 8,647 cols 467 classes Test: 64,263 rows 8,647 cols 143 classes

Tips for H2O Deep Learning!General: More layers: more complex functions (non-linearity) More neurons per layer: detect finer structure in data More regularization: less overfitting (better validation error) !Do a grid search to get a feel for convergence, then continue training. Try Tanh first. For Rectifier, try max_w2 = 50 and/or L1=1e-5. Try TanhDropout or RectifierDropout with test/validation set after finding good parameters for convergence on training set. Distributed: Smaller mini-batch: more comm., slower, but higher accuracy. With ADADELTA: Try epsilon = 1e-4,1e-6,1e-8,1e-10, rho = 0.9,0.95,0.99 Without ADADELTA: Try rate = 1e-4…1e-2, rate_annealing = 1e-5…1e-8 Try momentum_start = 0.5, momentum_stable = 0.99, momentum_ramp = 1/rate_annealing Try balance_classes = true for imbalanced classes. Try force_load_balance for small datasets.

SummaryH2O is a distributed in-memory math platform that allows fast prototyping in Java, R, Scala and Python. !H2o enables the development of enterprise-quality blazing fast machine learning applications. !H2O Deep Learning is distributed, easy to use, and early results compete with the world’s best. !Deep Learning makes better predictions! !Try it yourself and join our next meetup! git clone https://github.com/0xdata/h2o


















