
Genetyka populacji
22
Wydział Ochrony Środowiska i Rybactwa UWM w Olsztynie Przewodnik do ćwiczeń z Genetyki populacji Ś Mirosław Łuczyński Sławomir Ciesielski Małgorzata Jankun Dariusz Kaczmarczyk Paweł Woźnicki www.genetics.wustl.edu/ Olsztyn 2009
Transcript of Genetyka populacji

Wydział Ochrony Środowiska i Rybactwa UWM w Olsztynie
Przewodnik do ćwiczeń z Genetyki populacji
ŚMirosław Łuczyński Sławomir Ciesielski Małgorzata Jankun Dariusz Kaczmarczyk Paweł Woźnicki
www.genetics.wustl.edu/
Olsztyn 2009

Szczegółowv program ćwiczeń z przedmiotu GENETYKA dla studentów II roku kierunku Ochrona Środowiska (prowadzący ćwiczenia: dr inż. Sławomir Ciesielski)
Ćwiczenie 1. Genetyka populacyjna: czynniki wpływające na równowagę genetyczną populacji: mutacje,
migracje, selekcja, dryf genetyczny. Frekwencja genów w populacji.
Ćwiczenie 2. Częstość występowania alleli i genotypów. Prawo Hardy-Weinberga.
Ćwiczenie 3. Genotyp a środowisko: wpływ zagęszczenia populacji na masę ciała Drosophila
melanogaster- zakładanie hodowli muszki owocowej (dwa różne zagęszczenia
populacji) (laboratorium).
Ćwiczenie 4. Modele doboru naturalnego w populacjach - symulacje komputerowe dotyczące
zmian frekwencji alleli w populacji pod wpływem doboru naturalnego (sala komputerowa).
Ćwiczenie 5. Efektywna liczebność populacji i współczynnik inbredu - rozwiązywanie zadań
rachunkowych.
Ćwiczenie 6. Wpływ zagęszczenia populacji na masę ciała Drosophila melanogaster- zamknięcie
doświadczenia (usypianie much i ważenie próby, określenie średniej masy much w każdym
zagęszczeniu) analiza wyników przy pomocy testu t-Studenta i wnioski (laboratorium).
Ćwiczenie 7. Kolokwium
dr inż. Sławomir Ciesielski Katedra Biotechnologii w Ochronie Środowiska Tel: 089 5234162 e-mail: [email protected]

Ćwiczenie 1
Ćwiczenie 1. Genetyka populacyjna: czynniki wpływające na równowagę genetyczną populacji: mutacje, migracje, selekcja, dryf genetyczny. Frekwencja genów w populacji.
Gdy gen ma dwa allele kodujące trzy fenotypy, a każdy genotyp koduje unikalny
fenotyp (dominacja niekompletna albo addytywne działanie genów), łatwo określić
frekwencje alleli genu w populacji. Frekwencja allelu to:
liczba ryb o fenotypie liczba ryb 2 homozygotycznym + o fenotypie kodowanym przez allel heterozygotyczny f (allelu ) = -------------------------------------------------------------------------------------- 2 (liczba ryb w populacji)
Liczba ryb o fenotypie homozygotycznym jest mnożona przez dwa gdyż każda ryba
ma dwie kopie allelu danego rodzaju; heterozygoty mają tylko po jednym allelu tego rodzaju.
Liczba ryb w populacji jest mnożona przez dwa gdyż każda ryba jest organizmem
diploidalnym i ma dwa allele w każdym locus.
Na przykład jeśli hodowca pstrągów znajduje ryby złociste oraz "palomino" i chce
wiedzieć, jakie są frekwencje alleli G i G' w hodowanej populacji, powinien policzyć ile jest
ryb o każdym fenotypie, zsumować allele i obliczyć ich frekwencje (w procentach).
Rozważmy przykład, w którym liczby ryb o poszczególnych
fenotypach (i przyporządkowanych im genotypach) były
następujące:
Fenotyp Genotyp Liczba
normalnie ubarwione GG ..............
złociste G’G’ ..............
palomino GG’ ..............
Każdy normalnie ubarwiony pstrąg ma dwa allele G, każdy pstrąg palomino ma jeden allel

Ćwiczenie 1
G, pstrągi złociste nie mają alleli G. Ogólna liczba alleli w locus G jest równa podwojonej
liczbie wszystkich ryb w populacji (normalnie ubarwionych + złocistych + palomino).
Czyli:
liczba alleli G f(G) = --------------------------------------------------- = całkowita liczba alleli w locus G 2 (... normalnie ubarwionych) + ....... palomino ............. alleli G = ----------------------------------------------------- = ---------------------------------------- = ............ 2 (....... pstrągów tęczowych razem) ............. wszystkich alleli
Podobnie można obliczyć frekwencję alleli G', która w tym przykładzie wynosi
Należy zauważyć iż
f(G) + f(G’) =------+-------= 1,0.
Frekwencja genów i genotypów w populacji. Geny autosomalne. Dominacja
kompletna (całkowita).
Przy założeniu, że rozpatrujemy 1 locus, w populacji osobników diploidalnych mogą
wystąpić:
Genotypy O liczebności O frekwencii AA D D/N=d Aa H H/N=h aa R RIN=r razem N 1
Frekwencję danego genotypu w określonej populacji definiuje się jako stosunek liczby
osobników posiadających dany genotyp do ogólnej liczby osobników w danej populacji. Dla
populacji nieokreślonej lecz o bardzo dużej liczebności, wygodniej jest określać frekwencję
jako prawdopodobieństwo występowania danego genotypu w populacji, albo jako
prawdopodobieństwo, że wybrany przypadkowo osobnik będzie miał dany genotyp.
Przykład:
W populacji stwierdzono 300 osobników homozygot dominujących (AA), 500
heterozygot(Aa) i 200 homozygot recesywnych (aa). Frekwenqe poszczególnych genotypów
będą miały wartości następujące: d(M)=300/1000=0,3; h (Aa)=500/1 000=0,5;

Ćwiczenie 1
r(aa)=200/1000=0,2
Ważne jest poznanie frekwencji nie tylko genotypów ale i genów, gdyż to właśnie geny się
dziedziczą a nie genotypy.
Frekwencję genu rozumie się jako względną częstość występowania, proporcję loci zajętych
przez dany gen w populacji do wszystkich loei, które dany gen mógłby zajmować. Inaczej
można frekwencję genu zdefiniować jako prawdopodobieństwo występowania danego allelu
(genu) w populacji. Jeśli przez "p" oznaczymy frekwencję allelu dominującego genu A, przez
q oznaczymy frekwencję allelu recesywnego tego genu oznaczonego jako a, wtedy:
p+q=1 2D+H 2R+H gdzie: p = ------------------; q = ------------------ 2N 2N
Allele A oraz a kodominują daną cechę fenotypową. to znaczy że na podstawie fenotypów
możemy odróżnić od siebie osobniki o genotypach AA, Aa oraz aa. Frekwencja częstszych
homozygot AA wynosi p2, frekwencja heterozygot Aa wynosi 2pq, a frekwencja rzadszych
homozygot aa wynosi q2, co między innymi wynika z poniższego rozumowania.
Jeśli w populacji ryb rozważamy jeden locus genowy, w którym segregują dwa allele:
A oraz a, wówczas w czasie rozrodu krzyżują się ze sobą haploidalne gamety, jaja I plemniki,
które są nosicielami albo allelu A albo allelu a. Wyrzucone do wody gamety łączą się losowo
ze sobą w zygoty o trzech możliwych genotypach: AA, .Aa oraz aa, co można określić na
podstawie poniższej szachownicy genetycznej:
A a
A AA Aa
a Aa aa

Ćwiczenie 1
Jeśli allel A występuje w badanej populacji ryb z frekwencją p, podczas gdy allel a
występuje z frekwencją q, wówczas frekwencje zygot o poszczególnych genotypach (AA, Aa
oraz aa) można obliczyć również posługując się szachownicą genetyczną, w której polach w
miejsce nazw alleli (A, a) oraz genotypów (AA, Aa, aa) wstawimy obserwowane w populacji
frekwencje alleli (p, q) oraz wyliczone prawdopodobieństwa, iż powstaną ,zygoty o
poszczególnych genotypach (prawdopodobieństwo że powstaną zygoty o genotypie AA = p x
p = p2; Aa = p x q + q x p = 2pq; aa = q x q = q2.
p q
p pp=p2 pq
q pq qq=q2
Gdy między allelami występuje dominacja całkowita, frekwencję alleli trzeba
obliczać metodą pierwiastka kwadratowego, gdyż w takim przypadku trzy genotypy kodują
dwa fenotypy. Ponieważ fenotyp heterozygotyczny jest niemożliwy do odróżnienia od
dominującego fenotypu homozygotycznego, nie można obliczyć frekwencji alleli poprzez ich
zwykłe policzenie (nie wiadomo które ryby w populacji o dominującym fenotypie mają dwa,
a które mają jeden allel dominujący). Tylko genotyp recesywny jest tym, który można
rozpoznać na podstawie kodowanego przez niego fenotypu. Ponieważ frekwencja
recesywnego fenotypu to kwadrat frekwencji allelu recesywnego, pierwiastek kwadratowy z
frekwencji fenotypu recesywnego to frekwencja recesywnego allelu w populacji. Frekwencję
allelu dominującego oblicza się odejmując od jedności frekwencję allelu recesywnego.

Ćwiczenie 2
Ćwiczenie 2. Model Hardy’ego-Weinberga (H-W). Svmulowanie losoweao
kojarzenia gamet w populacii panmiktvcznei. Stosowanie testu χ2 (chi2) do
określenia czy obserwacje potwierdzają prawo H-W.
Proces analizy zmienności genetycznej składa się:
- ze zbadania jednego lub więcej typów markerów genetycznych,
- ilościowego wyrażenia frekwencji fenotypów,
- wywnioskowania na tej podstawie frekwencji genotypów kodujących zbadane fenotypy.
Następnie potrzebny jest określony model, który powiąże ze sobą frekwencje genotypów z
frekwencjami alleli i umożliwi wyciagnięcie wniosków na temat procesów, oddziałujących na
badaną populację. Użyteczność modelu polega na tym, iż pozwala on zidentyfikować
kluczowe obserwacje (lub eksperymenty) które należy poczynić, aby lepiej zrozumieć stan
obecny populacji oraz zaradzić ewentualnym kłopotom.
Najpowszechniej stosowanym modelem, wiążącym frekwencje genotypów z
frekwencjami alleli, jest model opracowany niezależnie przez G.H. Hardy'ego (1908) oraz W.
Weinberga (1908).
Model Hardy'ego-Weinberga opiera się na kilku ważnych założeniach:
- liczebność populacji jest wielka i stała w kolejnych pokoleniach,
- kojarzenie się osobników jest losowe (populacja jest panmiktyczna, albo bardzo dobrze
wymieszana),
- organizmy są diploidalne,
- pokolenia nie zazębiają się,
- rozród odbywa się drogą płciową,
- wpływy mutacji, migracji i selekcji sązaniedbywalne.
W przypadku autosomalnych (tych, które nie są ulokowane na chromosomach płci) loci
genowych o dwóch allelach, model Hardy'ego-Weinberga przyjmuje postać:
(p + q)2 = p2 + 2pq + q2 = 1
gdzie p to frekwencja częstszego allelu A podczas gdy q jest frekwencją rzadziej
występującego allelu a, natomiast p +q = 1. Proporcje genotypów będą odpowiadały
rozwinięciu dwumianu (p + q)2.
AA Aa aa

Ćwiczenie 2
p2 2pq q2
Model Hardy'ego-Weinberga zakłada, że jeśli zostaną spełnione ww. założenia, to frekwencje
alleli i genotypów w populacji nie będą się zmieniały z pokolenia na pokolenie. Zgodnie z
tym założeniem, model może być stosowany do przewidywania frekwencji genotypów na
podstawie obecnej frekwencji alleli. Zastosowania modelu Hardy'ego-Weinberga dostarczają
podstawy do oceny sił ewolucyjnych, wpływających na wachlarz genotypów w populacji.
Jeśli stwierdzamy że obserwowane frekwencje genotypów są inne niż frekwencje
przewidywane przez model, można stawiać hipotezy co do przyczyn tych odchyleń. Idąc
dalej, można zaplanować nowe obserwacje lub eksperymenty, których celem będzie
wyjaśnienie procesów, które spowodowały różnice między obserwowanymi i
przewidywanymi frekwencjami alleli w populacji. Rozumowanie takie opiera się na
przypuszczeniu, iż w rezultacie rozmaitych mechanizmów ekologicznych jedno lub więcej
założeń modelu nie jest spełnione w przypadku obserwowanej populacji.
Jednym z założeń modelu Hardy'ego-Weinberga jest losowe kojarzenie się osobników
w procesie rozrodu. To założenie często nie jest spełniane wskutek najrozmaitszych
zachowań rozrodczych. Wybiórcze krzyżowanie się osobników to wybór partnera
rozrodczego na podstawie jego fenotypu. Dodatnie krzyżowanie wybiórcze występuje wtedy.
gdy osobniki krzyżują się z podobnymi do siebie częściej niż gdyby było to wyłącznie
dziełem przypadku. Inbreeding to krzyżowanie się ze sobą osobników spokrewnionych, co
stanowi szczególny przypadek pozytywnego krzyżowania się wybiórczego. Negatywne
wybiórcze kojarzenie się występuje wówczas, gdy częściej niż wynikałoby to z przypadku
osobniki krzyżują się z partnerami niepodobnymi do siebie fenotypowo jak w przypadku
"korzyści rzadkich samców" [rare-male advantage] Drosophila). Genetyczny podział
populacji gatunku jest również odmianą krzyżowania wybiórczego, w którym na pulę genową
gatunku składają się pule genowe grupy subpopulacji (stad), których osobniki krzyżują się
panmiktycznie w ramach subpopulacji (stad).
W niektórych przypadkach wpływ doboru naturalnego na frekwencje genotypów nie
jest zaniedbywalny. Dobrze znanym przykładem u człowieka jest korzystne dostosowanie
heterozygot w locus B-hemoglobiny, kiedy to genotyp +s (odporny na malarię, nie
anemiczny) jest lepiej dostosowany niż ++ (podatny na malarię) i genotyp ss (cierpi na
anemię związaną z sierpowatością erytrocytów).
Złamanie założeń prawa Hardy'ego-Weinberga może wyniknąć z rozmaitych innych

Ćwiczenie 2
mechanizmów ekologicznych. W rzeczywistości, model Hardy'ego-Weinberga jest dość
odporny na niewielkie odstępstwa od jego założeń, co czyni go użytecznym w
zastosowaniach praktycznych. Trzeba jednak zaznaczyć, iż jeśli obserwowane frekwencje
genotypowe spełniają oczekiwania Hardy'ego-Weinberga, to nie musi to koniecznie oznaczać
że wszystkie założenia modelu są spełnione.
Symulowanie losowego kojarzenia gamet w populacji
panmiktvcznej. Stosowanie testu χ2 (chi2) do określenia. czy
obserwacie potwierdzaja spodziewania H-W
Populację określamy jako pamniktyczną, jeżeli kojarzenia należących do niej osobników
zachodzą całkowicie losowo. Rozkład genotypów w populacji zależy od wielu czynników. W
najprostszym przypadku może on być losowy i bezpośrednio wynikać z frekwencji
występujących w tej populacji alleli.
Załóżmy, że populacja spełnia następujące warunki:
1. organizmy są diploidalne,
2. rozmnażają się płciowo,
3. pokolenia nie zachodzą na siebie,
4. osobniki kojarzą się losowo (populacja jest panmiktyczna),
5. populacja jest bardzo duża,
6. nie ma migracji,
7. nie ma mutacji,
8. dobór naturalny nie wpływa na badany locus.
Populacja będzie spełniała te warunki także wtedy, gdy czynniki wymienione w pkt. 6, 7 i 8
będą się równoważyć. W takich warunkach proporcje genotypów, dla locus o dwu allelach A
i a, których frekwencje wynoszą odpowiednio p i q, (przy czym p + q = 1), będą odpowiadały
rozwinięciu dwumianu (p + q)2.
Powyższe stwierdzenie jest zwane prawem Hardy'ego i Weinberga. Prawo to mówi, że jeśli
zostaną spełnione założenia 1-8, to frekwencje alleli i genotypów w populacji nie będą się
zmieniały z pokolenia na pokolenie; dla dwu alleli frekwencje genotypów będą
odpowiadały rozwinięciu dwumianu (p + q)2.
Każdy ze studentów losuje dwie. "gamety" z locus A i dwie z locus B.
Następnie każdy odczytuje swój "genotyp".
Jakie są liczebności poszczególnych genotypów w locus A a jakie w

Ćwiczenie 2
locus B?
Jakie są oczekiwane liczebności tych genotypów z równania Hardy'ego i
Weinberga?
Czy frekwencje obserwowane odpowiadają oczekiwanym - sprawdzenie za pomocą testu
chi-kwadrat.
Test χ2 stosuje się do określania, czy obserwowane liczby osobników o danych genotypach
są takie same, jakich spodziewalibyśmy się na podstawie H-W (to znaczy, czy spełniają
oczekiwania H-W, otrzymane wartości z obu (obserwowane i oczekiwane) kolumn
podstawiamy do wzoru i obliczamy według modelu
(Obs - Exp) 2 χ2=Σ ------------------ Exp
gdzie: Obs to liczba obserwowanych osobników o określonym fenotypie
Exp to liczba oczekiwanych osobników o określonym fenotypie
suma (Σ) będzie zawierała 3 składniki - odpowiednio dla trzech genotypów w każdym
z badanych loci genowych (oddzielnie M, Aa i aa oraz BB, Bb i bb).
Liczba stopni swobody, związana z tą wielkością χ2 , równa się liczbie klas danych (w tym
przykładzie trzy klasy, czyli liczby AA, Aa oraz aa) minus jeden, minus liczba parametrów
oszacowanych na podstawie danych (w tym przykładzie jeden parametr, p, oszacowano na
podstawie danych), czyli 3 - 1 - 1 = 1. Zauważmy, że stopień swobody nie jest pomniejszany
z powodu oszacowania na podstawie danych wielkości parametru q, gdyż kiedy już
oszacowaliśmy p. wówczas q można otrzymać z zależności q = 1 - p. Przy jednym stopniu
swobody otrzymana wyżej wartość χ2 jest wysoce istotna (P < 0,01).
Wartość krytyczna statystyki χ2 na poziomie istotności a = 0,05 wynosi w tym przypadku
3,84
Obliczanie frekwencji alleli w locus przy pełnej dominacji. Rozpatrujemy dwie cechy:
1. barwa oczu: brązowe. piwne lub zielone - genotyp M lub Aa niebieskie lub szare -
genotyp aa
2. ucho: wolny koniec - genotyp BB lub Sb, przyrośnięty koniec - genotyp bb.

Ćwiczenie 2
Każdy ze studentów określa genotyp sąsiada (na podstawie jego fenotypu) jako Ax lub aa
oraz Bx lub bb.(gdzie x oznacza dowolny allel z danego locus). Zauważmy. że tylko
homozygoty recesywne są wyróżnialne (dotyczy to obu badanych /oci genowych). Obliczamy
udział homozygot recesywnych (dla każdej cechy oddzielnie) w całej grupie studenckiej.
Dodajemy również w miarę możliwości wyniki z grup poprzednich, aby zwiększyć
liczebność próby i zminimalizować błąd statystyczny.
Przykładowo, jeżeli liczba homozygot w locus A wynosiła 5 na 20 osób, to frekwencja
homozygot recesywnych w próbie wyniosi 5/20 czyli 0.25. Z równania Hardy'ego i
Weinberga wiemy. że frekwencja homozygot recesywnych w populacji wynosi q2, a zatem
frekwencja allelu recesywnego q = √q2 = 0,5. Frekwencja allelu dominującego wynosi zaś
p = 1-q = 0,5 Mamy już frekwencje alleli A i a (p i q) oraz B i b (p1 i q1). Możemy teraz obliczyć, jaki
procent w populacji stanowią heterozygoty - nosiciele cech recesywnych. Obliczamy to ze
wzoru:
liczba heterozygot Aa = 2pq
liczba heterozygot Bb = 2p1q1.
Każdy ze studentów, szczególnie potencjalnych heterozygot w badanych loci
przypomni sobie jak wyglądają wspomniane cechy u jego rodziców i rodzeństwa, a następnie
wyciągnie wnioski co do swojego genotypu w loci A i B.

Ćwiczenie 3
Ćwiczenie 3. Wpływ zagęszczenia populacji na masę ciała muszki owocowej
(Drosophila melanogaster).
B. Genotyp a środowisko. Wpływ zagęszczenia populacji na masę ciała muszki
owocowej (Drosophila melanogaster). Założenie doświadczenia
Każda podgrupa (połowa grupy) zakłada 2 hodowle (o wyższym i niższym zagęszczeniu
much):
• 2 samce + 2 samice (4 hodowle w całej grupie) (zagęszczenie 1)
• 6 samców + 6 samic (4 hodowle w całej grupie) (zagęszczenie 2)
Po 48 godzinach muchy rodzicielskie zostaną usunięte z próbówek przez osobę prowadząca
ćwiczenia. Wszystkie muchy potomne uzyskane po 3 tygodniach będą należały do pokolenia
F1.

Ćwiczenie 4
Ćwiczenie 4. Modele doboru naturalnego w populacjach - symulacje komputerowe dotyczące zmian frekwencji alleli w populacji pod wpływem doboru naturalnego.
Współczynnik reprodukcji (R):
R = FxP, gdzie F oznacza liczbę potomków przypadających na jednego osobnika
rodzicielskiego a P to prawdopodobieństwo przeżycia potomka do wieku reprodukcyjnego.
Wartość przystosowawcza genotypu:
jest to stosunek współczynnika reprodukcji danego genotypu do współczynnika reprodukcji
najkorzystniejszego genoypu: W = R/Rmax.
Dobór przeciw homozygotom recesywnym:
(np. melanizm przemysłowy Biston betularia na obszarach zanieczyszczonych).
WAA = WAa = 1, Waa = 1-s ∆q = -pq2s/1-sq2 p,q – frekwencje alleli A i a
∆q – zmiana frekwencji allelu a
Dobór przeciw homozygotom dominującym i heterozygotom:
(np. forma nie-melanistyczna motyla Biston betularia na obszarach nie zanieczyszczonych)
WAA = WAa = 1-s, Waa = 1 ∆q = -pq2s/1-ps(1+q)
Dobór przeciw obu homozygotom:
(np. anemia sierpowata u człowieka na obszarach malarycznych)
WAa = 1, WAA = 1 – sAA, Waa = 1 - saa
Dobór przeciw heterozygotom:
WAa = 1, WAA = 1 + sAA, Waa = 1 + saa
∆q = pq(qsaa-psAA)/1+p2sAA+q2saa ∆q=0 – punkt równowagi nietrwałej, przy
niewielkim odchyleniu występuje tendencja do jego pogłębienia (dodatnie sprzężenie
zwrotne).
Dwa punkty równowagi trwałej: q=1, p=0 oraz q=0, p=1.

Ćwiczenie 4
POPULUS Celem ćwiczeń jest analiza wpływu naturalnej selekcji, dryfu genetycznego, migracji, mutacji oraz ich kombinacji na częstość występowania alleli w populacji. W ćwiczeniu analizowana będzie populacja myszy. Kolor sierści myszy kontrolowany jest przez jeden gen posiadający dwa allele. W przypadku tej cechy występuje nie pełna dominacja: homozygoty dominujące (AA) posiadają sierść koloru czarnego, heterozygoty (Aa) posiadają sierść koloru szarego a homozygoty recesywne (aa) mają sierść koloru białego. Zakłada się, że myszy żyją na wyspie bez drapieżnika. Frekwencja obu alleli jest identyczna, chyba że podane jest inaczej. Symulacja I Na bardzo dużą, odizolowana populację myszy, swobodnie się krzyżujących nie działają żadne czynniki mutagenne. Jeśli na wyspę przedostanie się drapieżnik (np. mysz) bardziej zagrożone są białe myszy. Celem symulacji jest określenie kierunku ewolucji wobec działania powyższego czynnika selekcyjnego. 1. Uruchom program Populus i przejdź do Model > Natural selections. Wybierz Selection on
Diallelic Autosomal Locus. 2. Zaznacz opcję genotypic frequencies vs. t. 3. Wybierz Fitness (przystosowanie) i określ je dla każdego genotypu:
AA przystosowanie 1.0 Aa przystosowanie 1.0 aa przystosowanie 0.7
4. Wybierz jedną początkową frekwencję (One Initial Frequency) i wpisz 0.5. Ustaw liczbę generacji (Generations) na 130.
5. Naciśnij View. 6. Odpowiedz na następujące pytania:
a) Określ linie dotyczące poszczególnych genotypów. Jak należy je interpretować? b) Jeśli przystosowanie genotypów AA i Aa jest takie same dlaczego frekwencja
genotypu AA wzrasta a genotypu Aa obniża się? c) Jeśli genotyp aa jest "zły" dlaczego nie zanikł zupełnie? Wróć do Plot Options i
zaznacz "p vs. t". Pozwoli to zbadać jak zmienia się frekwencja allelu A (p) w czasie. Co można zaobserwować?
d) Zmień początkową frekwencję allelu A na 0.1 i zaznacz ponownie genotypic frequencies vs. t (pozostaw resztę bez zmian). Przypuszczamy, iż ilość białych myszy (genotyp aa) przewyższała ilość ciemnych myszy na wyspie przed przybyciem drapieżnika. Dlaczego linia genotypu aa obniżyła się tak szybko. Dlaczego frekwencja genotypu Aa początkowo wzrastała a potem się obniżyła?
e) Jakie wnioski dotyczące działania selekcji można wyciągnąć na podstawie przeprowadzonych symulacji.
Symulacja II Symulacji poddana będzie ta sama, duża, odizolowana, swobodnie krzyżująca się populacja myszy, w której nie występują żadne mutacje wpływające na kolor ich sierści. Najbardziej narażone na działanie drapieżnika są osobniki białe, potem czarne a na końcu szare. Wybierz opcję Selection on a Diallelic Autosomal Locus ustawiając resztę opcji jak w poprzedniej symulacji (initial frequency 0.5) Przystosowanie (Fitness) ustaw w następujący sposób:

Ćwiczenie 4
AA - 0.9 Aa - 1.0 aa - 0.7
Jakie są główne różnice między wynikami tej a poprzedniej symulacji ? Symulacja III W niniejszej symulacji ta sama odizolowana populacja myszy, swobodnie krzyżująca się ma niewielką liczebność. Brakuje mutacji wpływających na kolor sierści nie ma też różnic w przeżywalności różnych form barwnych. 1. Wybierz model Mendelian Genetics i Genetic Drift . Wybierz zakładkę Monte Carlo i ustaw opcję w następujący sposób:
a) Runtime = 3N generations b) Loci = 6 c) Initial frequency = 0.5 d) Population size = 500
2. Naciśnij View. Linia każdego koloru oznacza przypadkowo wybrany allel genomu myszy. Allele te są niezależne od siebie i nie wpływają one na przeżywalność. 3. Przeprowadź 18 prób (Iterate): sześć dla populacji 500 osobników, sześć dla populacji 50 osobników i sześć dla populacji liczącej 5 osobników. 4. Dla każdej próby zanotuj następujące informacje:
a) Wielkość populacji (Population size - N) b) Liczbę generacji do momentu osiągnięcia frekwencji równej 1 lub zero przez pierwszy z
alleli (Fixation) c) Kolor allelu który jako pierwszy osiągnął frekwencję 1 lub zero d) W ilu przypadkach doszło najpierw do osiągnięcia frekwencji 0 a w ilu przypadkach
frekwencji 1 5. Odpowiedz na następujące pytania:
a) Czy we wszystkich próbach frekwencje alleli przebiegały w ten sam sposób? Dlaczego tak, dlaczego nie? b) Czy frekwencje poszczególnych alleli wyglądały tak samo w różnych próbach?
Dlaczego tak, dlaczego nie? c) Jak duże były różnice w czasie osiągnięcia przez pierwszy allel frekwencji 1 lub zero? d) Jeśli allele te nie są związane z selekcją to dlaczego zmienia się ich frekwencja? e) Bardzo często uważa się dryft genetyczny związany jest tylko z małymi populacjami.
Jednakże ma on również wpływ na duże populacje ale wpływa na nie w sposób mniej zauważalny.
f) Symulacja ta pokazuje zmianę frekwencji alleli w czasie. Czy można powiedzieć, że w taki sposób przebiega ewolucja?
g) Czy można przewidzieć dla danej populacji kiedy dojdzie do utraty konkretnego allelu? Symulacja IV Dryf genetyczny a selekcja. W rzeczywistości dryf genetyczny i selekcja działają zazwyczaj jednocześnie, są one dwoma najważniejszymi czynnikami ewolucyjnymi. W omawianej populacji myszy wraz z przybyciem na wyspę drapieżnika selekcja działa przeciwko białym myszom (aa), jednakże nie jest to cecha letalna - myszy białych jest o 10% mniej niż ciemnych. 1. W opcji Mendelian Genetics zaznacz Drift and Selection. Wprowadź dane:
a) N = 500, p = 0.1, Generations = 500 b) AA = 1, Aa = 1, aa = 0.9

Ćwiczenie 4
2. Zanim sprawdzisz wynik rozważ: jeśli nie działa dryf genetyczny czy allel a zostanie wyparty z populacji? 3. Naciśnij View i zobacz co stanie się po 500 generacjach. Przeprowadź 5 symulacji
obserwując za każdym wyniki. Jaki jest wynik? Czy za każdym razem wyniki były takie same? Dlaczego wartość allelu A osiągnęła 1?
4. Selekcja (obecność drapieżnika) spowodowała że frekwencja allelu A wzrosła. Jednakże jak widać było w symulacji pierwszej linia wzrostu frekwencji tego allelu nie jest prosta. Wzrost jest bardzo niejednorodny - jest to wynikiem działania dryfu genetycznego.
5. Teraz zmień wielkość populacji na 50 i naciśnij View. Co się dzieje w mniejszej populacji?
6. Przeprowadź 5 symulacji. Czy otrzymane wyniki podobne są do tych, które były uzyskane dla większej populacji.
7. Gdy wielkość populacji wynosiła 500 bez wątpienia można było zauważyć, że frekwencja allelu A wzrastała do momentu przekroczenia wartości 1. Najprawdopodobniej sytuacja powtórzyła się, gdy wielkość populacji wynosiła 50.
8. Czy populacja myszy na wyspie ewoluowała? Jeśli tak to jakie były mechanizmy tej ewolucji?
9. Co otrzymane wyniki mogą powiedzieć o działaniu dryfu genetycznego i selekcji w małej i dużej populacji?

Ćwiczenie 5
Ćwiczenie 5. Efektywna wielkość populacji i współczynnik inbredu –
rozwiązywanie zadań.
Efektywna wielkość populacji:
Ne= 4NmNf/ Nm+Nf Nm- liczba samców, Nf- liczba samic
Współczynnik inbredu:
Ft = 1-(1-1/2Ne)t F - współczynnik inbredu
t - liczba pokoleń
Ne - efektywna wielkość populacji
zmiana częstości w pokoleniu t
AA po2 +PoqoFt
Aa 2poqo -2poqoFt
aa qo2 +PoqoFt
Im wyższa wartość współczynnika inbredu tym szybciej wzrasta nadwyżka homozygot w
populacji. Inbred nie ma wpływu na frekwencje alleli A i a, natomiast ma znaczny wpływ na
frekwencje poszczególnych
genotypów AA, Aa, i aa.
1) Oblicz efektywną wielkość populacji, w której jest:
a) 150 samic i 50 samców,
b) 180 samic i 20 samców,
c) 280 samic i 20 samców,
d) 380 samic i 20 samców,
e) 170 samic i 30 samców.
2) Oblicz efektywną wielkość populacji złożonej z 10 kur i 1 koguta.
3) Efektywna wielkość pewnej populacji wynosi 20. Frekwencje alleli A i a wynoszą
odpowiednio 0,6 i 0,4.

Ćwiczenie 5
Oblicz współczynnik inbredu oraz frekwencje genotypów w tej populacji w dziesiątym
pokoleniu. Oblicz to samo dla populacji liczącej 1000 samic i 1000 samców.

Ćwiczenie 6
Ćwiczenie 6. Genotyp a środowisko. Wpływ zagęszczenia populacji na masę
ciała muszki owocowej (Drosophila melanogaster). Analiza statystyczna
wyników doświadczenia.
Po 2 tygodniach w każdej grupie doświadczalnej oddzielnie:
-muchy usypiamy i rozdzielamy według płci,
-liczymy samce i samice,
-ważymy oddzielnie samce i samice w ramach grupy doświadczalnej,
-obliczmy średnia masę w próbie samców i samic dzieląc całkowitą masę próby przez liczbę
much w próbie.
Jeżeli średnia masa muchy będzie mniejsza niż 0,5 mg lub większa niż 2 mg, powtórzyć
ważenie.
Zanotować uzyskane dane w zeszycie. Wszystkie obliczenia prowadzimy oddzielnie dla
samców i samic, ponieważ średnia masa samców jest o około 20% niższa niż samic.
ZADANIE
Porównaj testem t-Studenta masę ciała samic z najmniejszego i największego zagęszczenia.
podgrupa zagęszczenie 2+2 zagęszczenie 6+6
samce samice samce samice
1
2
3
4
Wartość statystyki t obliczoną przez nas porównujemy z krytyczna wartością z tabeli ,,poziom
istotności dla testu dwustronnego dla poziomu istotności 0,05. Liczba stopni swobody
df=N1+N2-2, gdzie N1 i N2 to liczby powtórzeń, odpowiednio dla zagęszczenia 1 (2+2) i 2
(6+6)

Ćwiczenie 6
X1, X2 - średnie arytmetyczne
xSXXt 21 −=
Sx - błąd standardowy
Błąd standardowy obliczamy ze wzoru:
2
2
1
1
NS
NS
Sx +=
gdzie S1 i S2 to wariancje, odpowiednio dla zagęszczenia 1 (2+2) oraz 2 (6+6).
Aby obliczyć Sx musimy mieć najpierw S1 i S2 (wariancje). Obliczamy je ze wzoru:
1/)( 22
−
−= ∑ ∑
NNXX
S
Gdy obliczymy wariancję S1 i S2, wstawiamy je do wzoru na błąd standardowy (N1 i N2 są
liczbami powtórzeń w każdym zagęszczeniu). Obliczamy każdą wariancję oddzielnie
wstawiając dla S1 odpowiednio X1 i N1 a dla S2 - X2 oraz N2. Gdy obliczymy Sx, wstawiamy
do wzoru na t i obliczamy wartość statystyki t. Znajdujemy w tabeli wartość krytyczna.:
Liczba stopni swobody df = N1+ N2 -2. Poziom istotności dla testu dwustronnego
α = 0,05
Następnie możemy zweryfikować hipotezę zerowa, która brzmi:
HO = ,,Brak jest istotnych różnic pomiędzy średnimi masami ciała muszek
owocowych hodowanych w różnych zagęszczeniach".
Jeżeli obliczona przez nas wartość statystyki t jest niższa od wartości krytycznej, to:
Nie ma podstaw do odrzucenia hipotezy zerowej.
Jeżeli obliczona wartość t jest wyższa od krytycznej to:
Hipotezę zerowa należy odrzucić na rzecz hipotezy alternatywnej, która brzmi:
,,Występują istotne różnice pomiędzy średnimi masami ciała muszek owocowych
hodowanych w różnych zagęszczeniach".
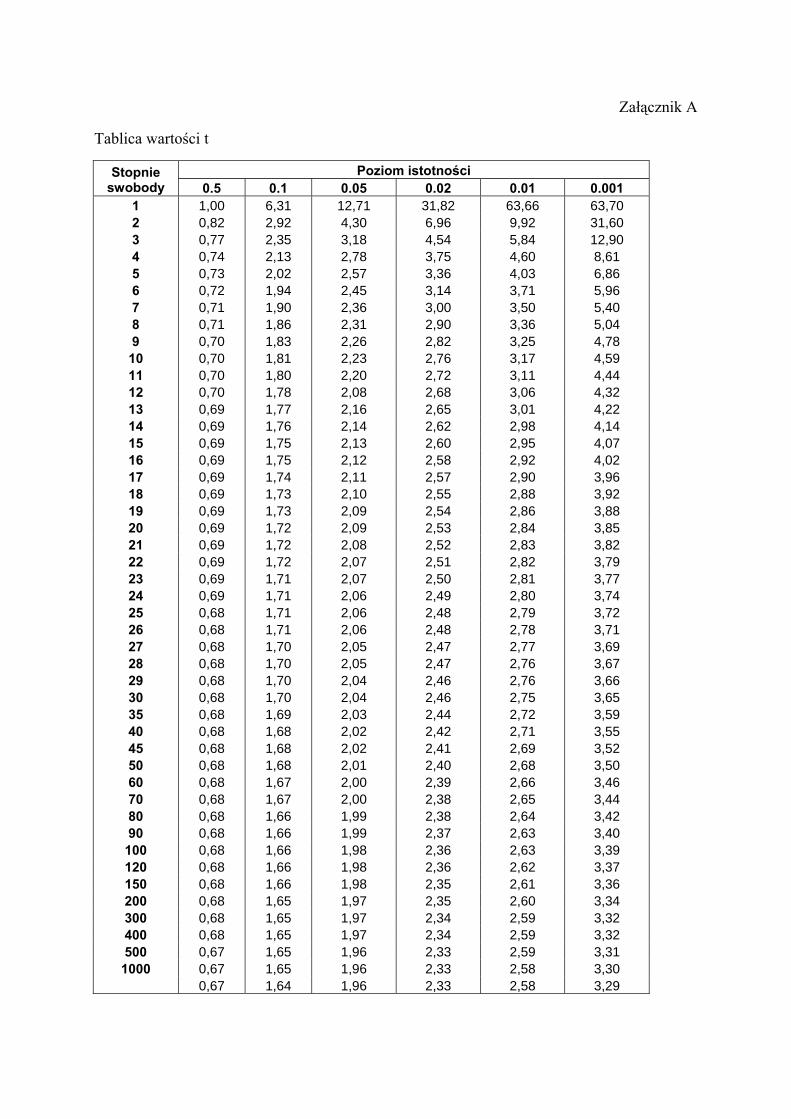
Załącznik A
Tablica wartości t
Poziom istotności Stopnie swobody 0.5 0.1 0.05 0.02 0.01 0.001
1 1,00 6,31 12,71 31,82 63,66 63,70 2 0,82 2,92 4,30 6,96 9,92 31,60 3 0,77 2,35 3,18 4,54 5,84 12,90 4 0,74 2,13 2,78 3,75 4,60 8,61 5 0,73 2,02 2,57 3,36 4,03 6,86 6 0,72 1,94 2,45 3,14 3,71 5,96 7 0,71 1,90 2,36 3,00 3,50 5,40 8 0,71 1,86 2,31 2,90 3,36 5,04 9 0,70 1,83 2,26 2,82 3,25 4,78 10 0,70 1,81 2,23 2,76 3,17 4,59 11 0,70 1,80 2,20 2,72 3,11 4,44 12 0,70 1,78 2,08 2,68 3,06 4,32 13 0,69 1,77 2,16 2,65 3,01 4,22 14 0,69 1,76 2,14 2,62 2,98 4,14 15 0,69 1,75 2,13 2,60 2,95 4,07 16 0,69 1,75 2,12 2,58 2,92 4,02 17 0,69 1,74 2,11 2,57 2,90 3,96 18 0,69 1,73 2,10 2,55 2,88 3,92 19 0,69 1,73 2,09 2,54 2,86 3,88 20 0,69 1,72 2,09 2,53 2,84 3,85 21 0,69 1,72 2,08 2,52 2,83 3,82 22 0,69 1,72 2,07 2,51 2,82 3,79 23 0,69 1,71 2,07 2,50 2,81 3,77 24 0,69 1,71 2,06 2,49 2,80 3,74 25 0,68 1,71 2,06 2,48 2,79 3,72 26 0,68 1,71 2,06 2,48 2,78 3,71 27 0,68 1,70 2,05 2,47 2,77 3,69 28 0,68 1,70 2,05 2,47 2,76 3,67 29 0,68 1,70 2,04 2,46 2,76 3,66 30 0,68 1,70 2,04 2,46 2,75 3,65 35 0,68 1,69 2,03 2,44 2,72 3,59 40 0,68 1,68 2,02 2,42 2,71 3,55 45 0,68 1,68 2,02 2,41 2,69 3,52 50 0,68 1,68 2,01 2,40 2,68 3,50 60 0,68 1,67 2,00 2,39 2,66 3,46 70 0,68 1,67 2,00 2,38 2,65 3,44 80 0,68 1,66 1,99 2,38 2,64 3,42 90 0,68 1,66 1,99 2,37 2,63 3,40
100 0,68 1,66 1,98 2,36 2,63 3,39 120 0,68 1,66 1,98 2,36 2,62 3,37 150 0,68 1,66 1,98 2,35 2,61 3,36 200 0,68 1,65 1,97 2,35 2,60 3,34 300 0,68 1,65 1,97 2,34 2,59 3,32 400 0,68 1,65 1,97 2,34 2,59 3,32 500 0,67 1,65 1,96 2,33 2,59 3,31 1000 0,67 1,65 1,96 2,33 2,58 3,30
0,67 1,64 1,96 2,33 2,58 3,29
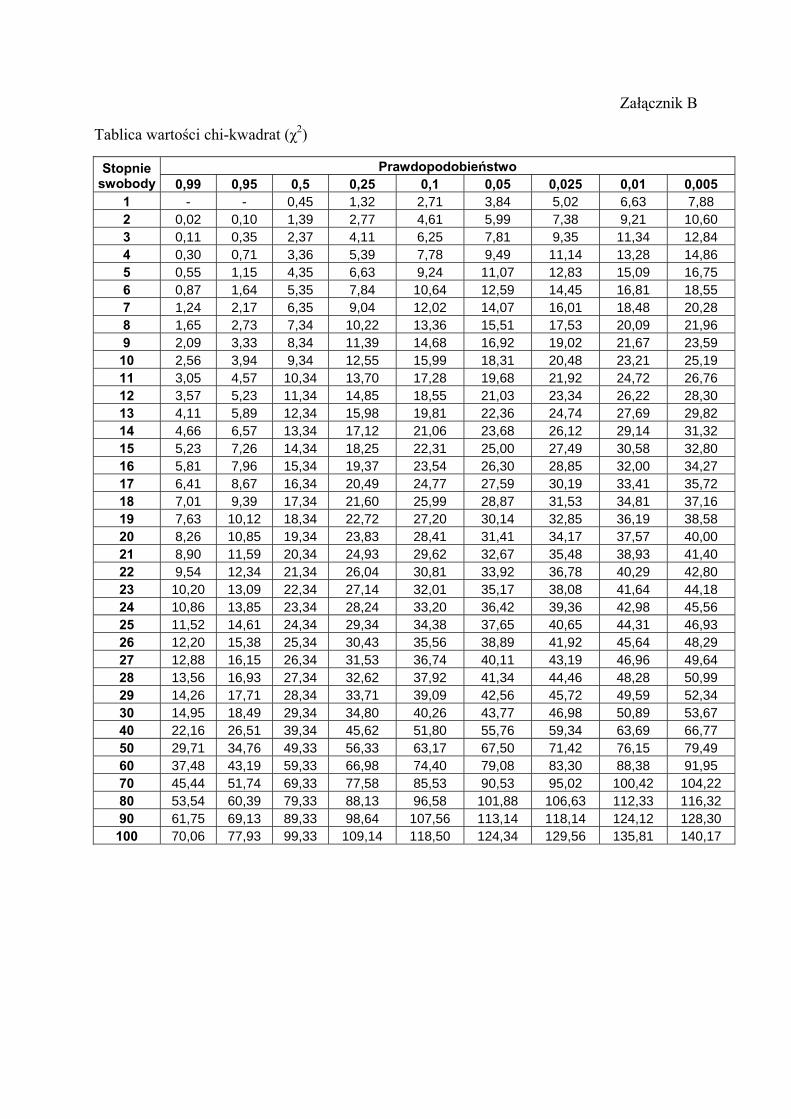
Załącznik B
Tablica wartości chi-kwadrat (χ2)
Prawdopodobieństwo Stopnie swobody 0,99 0,95 0,5 0,25 0,1 0,05 0,025 0,01 0,005
1 - - 0,45 1,32 2,71 3,84 5,02 6,63 7,88 2 0,02 0,10 1,39 2,77 4,61 5,99 7,38 9,21 10,60 3 0,11 0,35 2,37 4,11 6,25 7,81 9,35 11,34 12,84 4 0,30 0,71 3,36 5,39 7,78 9,49 11,14 13,28 14,86 5 0,55 1,15 4,35 6,63 9,24 11,07 12,83 15,09 16,75 6 0,87 1,64 5,35 7,84 10,64 12,59 14,45 16,81 18,55 7 1,24 2,17 6,35 9,04 12,02 14,07 16,01 18,48 20,28 8 1,65 2,73 7,34 10,22 13,36 15,51 17,53 20,09 21,96 9 2,09 3,33 8,34 11,39 14,68 16,92 19,02 21,67 23,59
10 2,56 3,94 9,34 12,55 15,99 18,31 20,48 23,21 25,19 11 3,05 4,57 10,34 13,70 17,28 19,68 21,92 24,72 26,76 12 3,57 5,23 11,34 14,85 18,55 21,03 23,34 26,22 28,30 13 4,11 5,89 12,34 15,98 19,81 22,36 24,74 27,69 29,82 14 4,66 6,57 13,34 17,12 21,06 23,68 26,12 29,14 31,32 15 5,23 7,26 14,34 18,25 22,31 25,00 27,49 30,58 32,80 16 5,81 7,96 15,34 19,37 23,54 26,30 28,85 32,00 34,27 17 6,41 8,67 16,34 20,49 24,77 27,59 30,19 33,41 35,72 18 7,01 9,39 17,34 21,60 25,99 28,87 31,53 34,81 37,16 19 7,63 10,12 18,34 22,72 27,20 30,14 32,85 36,19 38,58 20 8,26 10,85 19,34 23,83 28,41 31,41 34,17 37,57 40,00 21 8,90 11,59 20,34 24,93 29,62 32,67 35,48 38,93 41,40 22 9,54 12,34 21,34 26,04 30,81 33,92 36,78 40,29 42,80 23 10,20 13,09 22,34 27,14 32,01 35,17 38,08 41,64 44,18 24 10,86 13,85 23,34 28,24 33,20 36,42 39,36 42,98 45,56 25 11,52 14,61 24,34 29,34 34,38 37,65 40,65 44,31 46,93 26 12,20 15,38 25,34 30,43 35,56 38,89 41,92 45,64 48,29 27 12,88 16,15 26,34 31,53 36,74 40,11 43,19 46,96 49,64 28 13,56 16,93 27,34 32,62 37,92 41,34 44,46 48,28 50,99 29 14,26 17,71 28,34 33,71 39,09 42,56 45,72 49,59 52,34 30 14,95 18,49 29,34 34,80 40,26 43,77 46,98 50,89 53,67 40 22,16 26,51 39,34 45,62 51,80 55,76 59,34 63,69 66,77 50 29,71 34,76 49,33 56,33 63,17 67,50 71,42 76,15 79,49 60 37,48 43,19 59,33 66,98 74,40 79,08 83,30 88,38 91,95 70 45,44 51,74 69,33 77,58 85,53 90,53 95,02 100,42 104,22 80 53,54 60,39 79,33 88,13 96,58 101,88 106,63 112,33 116,32 90 61,75 69,13 89,33 98,64 107,56 113,14 118,14 124,12 128,30 100 70,06 77,93 99,33 109,14 118,50 124,34 129,56 135,81 140,17


















